Tensorflow, хотя и сдаёт свои позиции в исследовательской среде, всё ещё остаётся популярным в практической разработке. Одна из сильнейших сторон TF, из-за которой он держится на плаву — возможность оптимизации моделей для развертывания в условиях ограниченных ресурсов. Для этого существуют специальные фреймворки: Tensorflow Lite для мобильных устройств и Tensorflow Serving для промышленной эксплуатации. В Сети (и даже на Хабре) достаточно туториалов по их использованию. В этой статье мы собрали наш опыт оптимизации моделей без использования этих фреймворков. Мы рассмотрим некоторые методы и библиотеки, выполняющие поставленную задачу, опишем, как можно сэкономить пространство на диске и RAM, сильные и слабые стороны каждого подхода, а также некоторые неожиданные эффекты, с которыми мы столкнулись.
В каких условиях мы работаем
Одна из классических задач NLP — тематическая классификация коротких текстов. Классификаторы представлены множеством разнообразных архитектур, начиная от классических методов типа SVC и заканчивая transformer-архитектурами типа BERT и его производных. Мы будем рассматривать CNN — свёрточные модели.
Важным ограничением для нас является необходимость обучать и использовать модели (в составе продукта) на машинах без GPU. В первую очередь это влияет на скорость обучения и инференса.
Другим условием является то, что модели для классификации обучаются и используются комплектами по несколько штук. Комплект моделей, даже простых, может использовать достаточно много ресурсов, особенно оперативной памяти. Мы используем собственное решение для сервинга моделей, однако, если вам необходимо оперировать комплектами моделей, обратите внимание на Tensorflow Serving.
Мы столкнулись с необходимостью выполнить оптимизацию модели на TF версии 1.x, сейчас официально считающейся устаревшей. Для TF 2.x многие из рассматриваемых техник либо неактуальны, либо интегрированы в стандартный API, и поэтому процесс оптимизации достаточно прост.
Давайте в первую очередь рассмотрим структуру нашей модели.
Как устроена TF-модель
Рассмотрим так называемую Shallow CNN — сеть с одним сверточным слоем и несколькими фильтрами. Эта модель достаточно хорошо себя зарекомендовала для текстовой классификации поверх векторных представлений слов.

Для простоты будем использовать фиксированный предобученный набор векторных представлений размерностью v x k, где v — размер словаря, k — размерность эмбеддингов.
Наша модель содержит:
- Embedding-слой, отображающий слова предложения в их векторные представления.
- Несколько параллельных слоёв двумерных свёрток w x k. Например, набор окон (1, 1, 2, 3) будет соответствовать 4 параллельным сверткам, две из которых обрабатывают 1 слово, а другие по 2 и по 3 слова, как показано на рисунке.
- Max-pooling по каждой свертке.
- Объединяющий результаты пулинга единый длинный вектор, к которому добавлена dropout-регуляризация и softmax-слой для осуществления классификации.
Для обучения модели мы применяем оптимизатор Adam, который использует всю историю градиентов весов.
Легко вычислить размер этой модели: для этого достаточно перемножить все измерения тензора каждого слоя и перевести в байты через используемый тип данных.
Например, свёртка, обрабатывающая входную последовательность и продуцирующая 128 фильтров c w = 2 и k = 300 при нотации тензора ядра (фильтра) [filter_height, filter_width, in_channels, output_channels] — это тензор, содержащий 2*300*1*128 = 76800 чисел формата типа float32, и соответственно, обладающий размером 76800*(32/8) = 307200 байт.
Для чего мы проводим эти подсчеты? При достаточно большом словаре (в нашем случае около 220 тыс. слов) размер слоя эмбеддингов размерностью 300 достигает примерно 265 МБ. Это неотъемлемая часть модели, и при использовании комплекта моделей потребление ресурсов может значительно вырасти.
В TF архитектура сети представляется в виде графа вычислений. Мы не будем подробно останавливаться на его устройстве (есть масса материалов на этот счет), однако отметим, что граф как правило компилируется отдельно от весов модели, то есть в базовом варианте у нас есть две сущности — граф и веса (параметры модели), которые хранятся отдельно. Граф состоит из узлов (нод). В нашем случае граф вычислений имеет следующее строение:
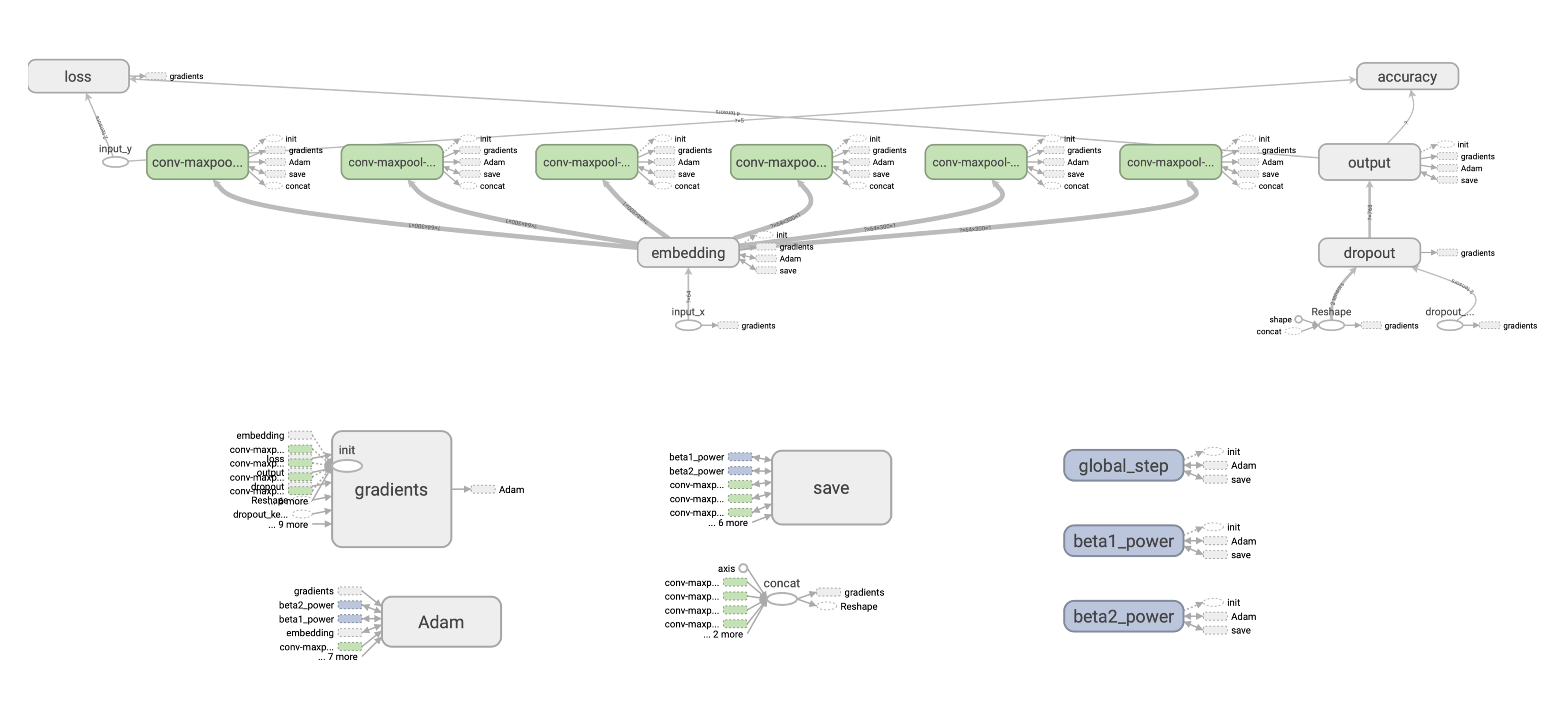
Как модель хранится на диске
После обучения модель нужно сохранить. Существует несколько способов это сделать, рассмотрим два основных: чекпоинт и формат SavedModel. Это очень близкие по своему внутреннему строению форматы, оба сохраняют граф и веса в отдельных файлах.
Checkpoint
Чтобы сохранить чекпоинт, нужно обратиться к Saver API:
saver = tf.train.Saver(save_relative_paths=True)
ckpt_filepath = saver.save(sess, "cnn.ckpt"), global_step=0)Здесь параметр global_step указывает шаг, на котором было сохранено состояние модели, и дописывает этот шаг в название файла — получаем файлы cnn-ckpt-0.
Тогда содержимое папки <model_path>/cnn_ckpt выглядит следующим образом:

Файл checkpoint — текстовый и содержит путь к последнему чекпоинту модели. Состояние модели может записываться несколько раз в процессе обучения, и TF при считывании этого файла сразу найдёт путь к нужному чекпоинту. В нашем случае чекпоинт только один, поэтому проблемы накопления чекпоинтов у нас не возникло.
Файл .data представляет собой непосредственно значения весов модели, сохранённые на указанном шаге обучения. Заметим, что его размер — около 800 МБ. Выше мы рассчитали, что большую часть весов модели занимает слой эмбеддингов (≈265 МБ). Остальной объём занимают параметры оптимизатора (значения первого и второго момента градиентов). Они обновляются каждый раз, когда градиенты пересчитываются.
Файл .index содержит является вспомогательным и содержит имена нод и их индексы.
Файл .meta является так называемым метаграфом — это структура, содержащая граф вычислений (операции, переменные, их размерности и связи между ними), заданный в виде GraphDef, дополнительную информацию для загрузки модели и метаданные. Структуру графа можно описать в текстовом виде, и это вряд ли бы заняло больше пары килобайт. Но возникает вопрос — почему тогда файл .meta занимает практически столько же места, сколько слой эмбеддингов? После профилирования мы обнаружили, что TF зачем-то сохраняет начальное состояние embedding-слоя. Возможно, это было бы полезно, но нам эта информация не нужна, поэтому, вообще говоря, эту ноду можно удалить из графа. Вы также можете проинспектировать ноды графа, например, так:
with tf.Session() as sess:
saver = tf.train.import_meta_graph('models/ckpt_model/cnn_ckpt/cnn.ckpt-0.meta') # load meta
for n in tf.get_default_graph().as_graph_def().node:
print(n.name, n['attr'].shape)С актуальной документацией по чекпоинтам можно ознакомиться здесь.
SavedModel
Формат, удобный для разворачивания и сервинга моделей. Является расширением концепции чекпоинта. Реализуется через API tf.saved_model. Взаимодействовать с сохранённой таким образом моделью можно как через tf.saved_model, так и через различные сервисы TF-экосистемы (TFLite, TensorFlow.js, TensorFlow Serving, TensorFlow Hub).
Сохранённая модель на диске выглядит следующим образом:
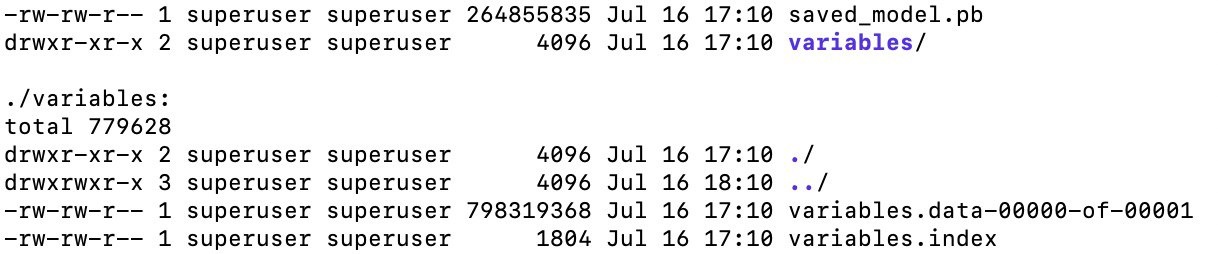
Файл saved_model.pb, по сути, содержит тот же метаграф, но отличается от .meta тем, что поддерживает хранение нескольких метаграфов (например, если нужно сохранить версию для последующего обучения и для инференса), а также предоставляет универсальный API, позволяющий взаимодействовать с моделью в различных фреймворках (и даже через CLI, то есть проверить работу вашей модели можно без дополнительного кода).
Ещё одной удобной фичей SavedModel является механизм ассетов — различных дополнительных данных, необходимых для работы модели. Эти данные можно “прикрепить” к модели. Например, для классификатора это может быть список меток, словарь стоп-слов — в общем, всё что угодно.
Основные методы оптимизации модели
Итак, мы имеем CNN-классификатор, написанный на TF версии 1.x, и необходимость при обучении и инфере работать с комплектом из нескольких моделей. Поэтому перед нами встал вопрос уменьшения объёма модели.
Мы заметили, что параметры нашей относительно небольшой свёрточной модели занимают около 1 ГБ, и рассмотрели следующие способы оптимизации:
- Заморозка графа
Веса и структура модели экспортируются в один файл. Метод позволяет избавиться от элементов графа, не использующихся в инференсе, а также оптимизировать скорость обработки данных ( tools.optimize_for_inference ). - Сохранение лёгкого чекпоинта
Выборочное сохранение переменных графа. Фактически, мы удаляем данные, требующиеся только на стадии обучения — узлы графа, связанные с оптимизацией и не входящие в tf.trainable_variables(). - Прунинг
Обнуление весов, слабо влияющих на конечное предсказание. Очень эффективный метод, если наша модель содержит избыточное число параметров (напр. BERT). - Квантизация
Переход к вычислениям с более низкой точностью. Может применяться как во время, так и после обучения. Часто используется в сочетании с прунингом. - Использование типов данных меньшей точности
Заморозка графа
Это способ сериализации, позволяющий сохранить в один файл сам граф, переменные и их веса в виде констант. Заморозка подразумевает удаление всех нод графа, которые не нужны для forward pass, то есть для непосредственного инференса модели. Следовательно, замороженную модель нельзя дообучить классическими способами. В нашем случае мы сократили размер модели с 1 ГБ до 265 МБ.
В TF 1.x эту операцию можно проделать различными способами, все они сводятся к следующим шагам.
Сначала нужно получить доступ к графу вычислений (загрузка с диска или из текущей сессии) и представление его в формате GraphDef:
graph = tf.get_default_graph()
input_graph_def = graph.as_graph_def()Затем непосредственная заморозка. Мы попробовали два метода: tf.python.tools.freeze_graph и tf.graph_util.convert_variables_to_constants. Оба метода принимают в том или ином виде граф (первый метод может загрузить уже сохранённый чекпоинт с диска) и список выходных нод (например, ['output/predictions']), на основе которого происходит вычисление, какие ноды нужны для инференса, а какие нужны только для обучения. При подаче одного и того же графа и списка выходных нод результат работы методов идентичен.
output_graph_def = graph_util.convert_variables_to_constants(self.sess, input_graph_def, output_node_names)Наконец, граф нужно сериализовать.
freeze_graph() сериализует граф во время выполнения (имя файла, который будет записан, подаётся как аргумент). Результат graph_util.convert_variables_to_constants() необходимо дополнительно сериализовать:
with tf.io.gfile.GFile('graph.pb', 'wb') as f:
f.write(output_graph_def.SerializeToString())Полученный файл весит всего 266 МБ, при этом эту модель можно загрузить на инференс следующим образом:
# считываем GraphDef из файла
with tf.io.gfile.GFile(graph_filepath, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
with tf.Graph().as_default() as graph:
# задаём входные плейсхолдеры
self.input_x = tf.placeholder(tf.int32, [None, self.properties.max_len], name="input_x")
self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")
# заполняем текущий вычислительный граф значениями из считанного graph_def
input_map = {'input_x': self.input_x, 'dropout_keep_prob': self.dropout_keep_prob}
tf.import_graph_def(graph_def, input_map)К любой ноде можно обращаться прямо в текущем графе, по умолчанию к названию нод добавляется префикс import:
predictions = graph.get_tensor_by_name('import/output/predictions:0')И мы можем сделать предсказание:
feed_dict = {self.input_x: encode_sentence(sentence), self.dropout_keep_prob: 1.}
sess.run(self.predictions, feed_dict)При работе с замороженными графами мы столкнулись с некоторыми неожиданными эффектами, а именно:
- Задержка при первом предсказании. После того как граф поднимается в память и инициализируется в сессии, для получения предсказания достаточно вызывать
sess.run(...). При том, что одно предсказание на CPU выполнялось примерно за 20 ms, для первого предсказания время выполнения доходило до ~2700 ms. Вероятно, это связано с кэшированием графа на устройстве. При загрузке из чекпоинта или из SavedModel такого эффекта не наблюдалось. - Накопление занимаемой во время загрузки RAM. При загрузке модели на инференс из замороженного графа потребляется больше RAM, чем при загрузке из чекпоинта. При этом разница составляет те самые ~265 МБ, то есть память дублируется. Выглядит так, как будто TF не утилизирует память при загрузке из GraphDef оптимальным образом.
- Ещё одно наблюдение – потребление RAM пустой сессией в разных версиях TF разное. В 1.15, последней версии TF 1.x, пустая сессия потребляет 118 MiB, тогда как в 1.14 – всего 3 MiB.
Лёгкий чекпоинт
Основным преимуществом замороженного графа над чекпоинтом для нас была возможность удаления узлов графа, не используемых в инференсе. Но что если сохранением чекпоинта можно также гибко управлять и сохранять только необходимую информацию? На странице документации представлено описание доступного функционала модуля сохранения/восстановления TF-модели tf.train.Saver. Он обеспечивает возможность сделать две оптимизации, которые, подобно заморозке графа, позволяют убрать из чекпоинта всё лишнее:
- Выборочное сохранение переменных графа
- Выключение сохранения MetaGraph
Модуль tf.train.Saver позволяет при инициализации указать переменные которые мы хотим сохранить. Для инференса нам нужны только веса модели, таким образом данный функционал можно описать всего одной строкой кода:
saver = tf.train.Saver(var_list=tf.trainable_variables())MetaGraph содержит информацию о структуре графа и позволяет автоматически строить граф при загрузке модели из чекпоинта. Однако мы можем продублировать код построения графа из обучения в инференсе, и тогда необходимость в сохранении meta данных пропадает. Отключить сохранение данных MetaGraph можно передав соответствующий флаг в метод save:
ckpt_filepath = saver.save(self.sess, filepath, write_meta_graph=False)В результате таких преобразований мы сократили исходный размер чекпоинта 1014 MБ до 265 MБ (так же, как и в случае с замороженным графом).
Прунинг
Pruning — это один из основных методов уменьшения объема используемой памяти на диске для нейронных сетей, который стремится вызвать разреженность в матрицах весов глубокой нейронной сети, тем самым уменьшая число ненулевых параметров в модели. Результаты исследований показывают, что ценой незначительной потери точности прунинг позволяет достичь значительного уменьшения размера модели.
Существует несколько возможных вариантов реализации прунинга, которые работают в TF 1.x:
- Grappler: cистема оптимизации графов tensorflow по умолчанию
- Pruning API: реализация google-research
- Graph Transform Tool: утилита оптимизации замороженного графа
Первое, что мы попробовали — стандартные средства оптимизации графа tensorflow, реализуемые системой Grappler. Описание возможностей Grappler представлено на странице документации. Он работает из коробки и не требует никаких действий для активации, однако для настройки применяемых оптимизаций необходимо использовать метод set_experimental_options. Мы провели эксперименты с включенным и выключенным прунингом, оценивая в ходе эксперимента размер сжатого с помощью zip чекпоинта. Ожидалось, что размер zip архива в случае применения прунинга будет меньше за счёт большего количества нулевых значений в исходном файле, однако на деле результат оказался идентичным для обоих экспериментов. На данном этапе было решено отказаться от Grappler и попробовать другие реализации прунинга.
Реализация прунинга от google-research заключается в добавлении в вычислительный граф дополнительных переменных mask и threshold, соответствующих свёрточным слоям нейронной сети. В процессе обучения в этих переменных накапливается информация об использовании соответствующих весов модели для верного предсказания. После обучения модели производится прунинг, который использует информацию, накопленную в процессе обучения в переменных mask и threshold, для зануления весов, дающих наименьший вклад в верное предсказание модели, при этом уровень разреженности указывается в качестве гиперпараметра. Дополнительные переменные после прунинга удаляются и результат сохраняется в виде разреженного замороженного графа.
Были проведены эксперименты аналогичные экспериментам с Grappler, результат также оказался аналогичным. Возник вопрос: как проверить работает прунинг или нет? Если работает, почему размер не изменяется? Для ответа на этот вопрос мы сохранили два замороженных графа с прунингом и без, при этом коэффициент разреженности установили 0.99 для наглядности. Далее, используя утилиту mc, посмотрели содержимое файлов замороженного графа в hex формате:

Как видно, на изображении слева у нас разреженный файл, справа обычный. Это позволило ответить на оба вопроса. Во-первых, прунинг работает. Во-вторых, мы обнаружили, что параметры модели, к которым мы применяем прунинг, занимают очень малую часть сохраняемого замороженного графа и не оказывают какого бы то ни было влияния на конечный размер. Все параметры свёрточных слоёв модели занимают менее процента общего размера файла, остальное же место занимают эмбеддинги.
Такой вариант оптимизации оказался не применим к используемой нами архитектуре CNN. Вопрос возможности применения прунинга к эмбедингам нами рассмотрен не был.
Квантизация
Метод, который помогает сильно сократить количество памяти на диске и в памяти. В нашем случае для квантизации использовался Graph transform tool.
Преобразование quantize_weights сначала сжимает существующие весовые коэффициенты в модели до 8 бит. После этого выполняется операция декомпрессии, которая преобразует 8-битные весовые коэффициенты обратно в числа с плавающей запятой. Это приводит к значительному уменьшению размера модели, но не приводит к соответствующему ускорению, поскольку вычисления по-прежнему выполняются с плавающей запятой.
Более сложная оптимизация quantize_nodes фактически преобразует все выполняемые с весами вычисления в 8-битные с преобразованиями с плавающей запятой до и после каждого вычисления. Это может помочь значительно ускорить вывод.
В теории, оба преобразования могут ухудшать точность модели из-за снижения точности веса. Однако после применения операции quantize_weights мы не получили какого-либо ухудшения по качеству, при этом размер модели на диске в уменьшился в 4 раза.
Если вы работаете с моделями, развернутыми на мобильных устройствах, советуем обратить внимание на TensorFlow Lite, который специально предназначен для выполнения квантования на мобильных устройствах и поддерживает одновременно оба режима.
Использование типов данных меньшей точности
Использование типов данных меньшей точности — это один из самых очевидных, но достаточно действенных подходов для уменьшения объема модели в оперативной памяти. При инициализации массивов по умолчанию используются 64 (32) разрядные числа в зависимости от операционной системы, но при векторизации данных такая точность может быть избыточной.
После перехода к новым типам данных мы получили заметные на больших датасетах сокращения в потреблении RAM на Ubuntu (где numpy по дефолту использует int64) за счет изменения типа данных на этапе индексации слов и меток лейблов. Поскольку размер словаря составлял 220 тысяч слов, то для индексации использовался int32, а для массива лейблов int16. В таблице можно увидеть результаты этой оптимизации в зависимости от количества классов и примеров на класс при обучении модели.

Как дополнительный эксперимент над типами данных мы пробовали менять точность внутри tf-графа. Точность каждого узла в данном эксперименте понижалась до float16. При этом, с исходными параметрами обучения, мы получили совсем незначительные изменения в потреблении памяти (меньше 10%), но значительно увеличилось время обучения (до 10 раз). На первый взгляд кажется, что этот эффект связан с неправильными настройками оптимизатора, хотя просто изменения epsilon и learning_rate не помогли. Поэтому вопрос, с чем именно связано увеличение времени обучения, остается открытым.
Влияние оптимизации на RAM
После всех вышеперечисленных махинаций мы решили сравнить объём, занимаемый в оперативной памяти различными моделями при использовании разных форматов. Это важный для нас показатель, так как есть необходимость загружать несколько моделей в память одновременно.
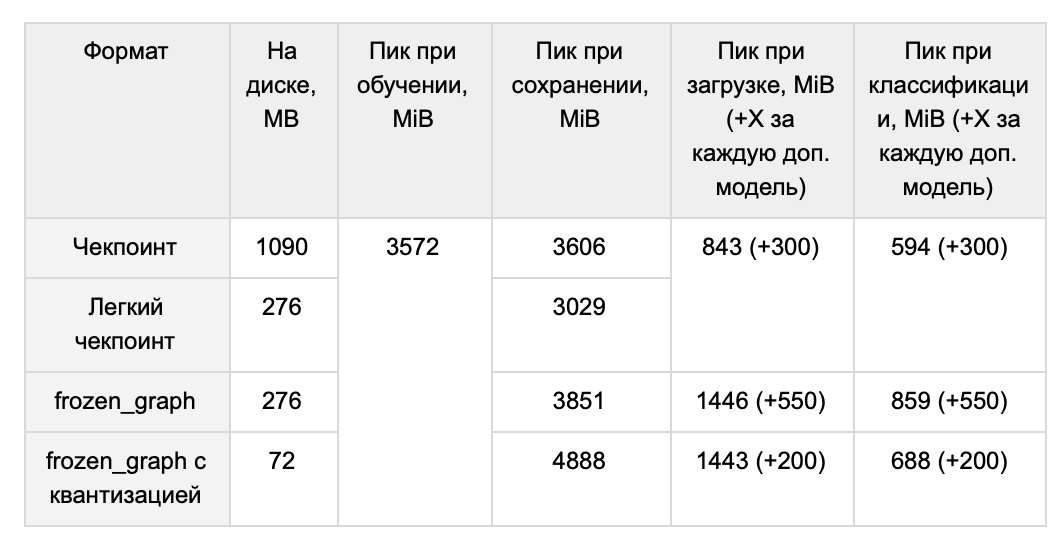
В результате мы решили использовать легкий чекпоинт для хранения модели, т. к. он предполагает менее острые пики при сохранении и разворачивании модели.
QA-секция
Q: У вашей модели тяжеленный эмбеддинг-слой, вы пробовали с ним что-нибудь сделать?
A: Основной вес нашей модели занимает слой эмбеддингов, поэтому было логично также обратить внимание на уменьшение размерности этого слоя. Для обучения эмбеддингов мы используем word2vec. После проведения серии экспериментов с различными значениями параметров (размер векторов, количество эпох, min count, learning rate), мы пришли к размеру словаря в 220 тысяч слов (размер слоя эмбедддингов — 265 MB) без ухудшения качества работы нашей CNN, тогда как в более ранней реализации размер словаря составлял 439 тысяч слов (510 MB).
Уменьшение размера эмбеддинг-слоя в два раза, конечно, не может не радовать, и всё же он по-прежнему является очень тяжелым. Поэтому мы обратили своё внимание на эмбеддинги, использующие сабворды (или кусочки слов). В таких эмбеддингах словарь состоит не из слов, а из их частей. Мы использовали токенайзер YouTokenToMe, который на основе входного текста сначала добавляет в словарь только отдельные символы, потом пары символов, т.е. биграммы, затем триграммы и т.д., пока в конце концов не начинает добавлять целые слова. Такие кусочки слов выбираются на основе анализа частотности появления во входном тексте определенных наборов символов. При этомы мы сами можем ограничить размер словаря, потому что все целые слова, которые не попали в словарь, могут быть составлены из имеющихся кусочков слов. Экспериментально мы пришли к размеру словаря в 30 тысяч сабвордов (37 MB) без существенных потерь качества, а время обучения уменьшилось в 3.7 раза на CPU и в 2.6 раза на GPU. Использование такого подхода позволило не только значительно сократить размер словаря (что привело к уменьшению занимаемой памяти и ускорению времени работы), но и решить проблему OOV-слов.
Q: Окей, модели сжали, но они теперь годятся только для инференса?
A: Нет, мы умеем дообучать замороженный граф и легкий чекпоинт.
Для дообучения замороженного графа:
Шаг 1. Восстанавливаем граф в памяти:
with tf.gfile.GFile(path_to_pb, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
with tf.Graph().as_default() as graph:
tf.import_graph_def(graph_def, name='')
return graphШаг 2. "Вытаскиваем" веса из графа:
sess.run(restored_variable_names)Шаг 3. Удаляем всё, кроме вытащенных из памяти весов.
Шаг 4. Перестраиваем граф, передавая веса в соответствующие переменные, например:
tf.Variable(tensors_to_restore["output/W:0"], name="W")Для дообучения легкого чекпоинта потребуется восстановить граф, используя код его построения из обучения.
Несмотря на потерю данных о весах оптимизаторов, качество дообучения в нашем случае остается таким же, как и при использовании стандартной несжатой модели.
Сжатые остальными описанными способами модели мы дообучать не пробовали, но теоретически с этим не должно возникнуть каких-либо проблем.
Q: Есть ли какие-то еще способы уменьшения оптимизации, которые вы не рассмотрели?
A: У нас есть несколько идей, до реализации которых мы так и не дошли. Во-первых, constant folding — это “свёртывание” подмножества узлов графа, предвычисление значения частей графа, слабо зависящих от входных данных. Во-вторых, в нашей модели хорошим решением кажется применить прунинг эмбеддингов.



