
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Привет, Habr! Меня зовут Лыщенко Константин. Я QA automation engineer в компании Garage Eight. В этой статье я расскажу о том, как мы улучшали нашу автотестовую систему: дорабатывали pipeline с прогоном тестов, делали отчёты в Slack удобнее и внедряли автоматизированный сбор метрик с использованием Grafana и MySQL.
Архитектура продукта
Наш продукт состоит более чем из 200-от микросервисов, большая часть из которых развёрнута в kubernetes-кластере. Для хранения данных используем MySQL и Redis, а для обмена сообщениями — RabbitMQ. В качестве репозитория и CI\CD платформы — Gitlab. Новые версии микросервисов выкатываем на прод по несколько раз за день.
Как мы пишем автотесты
В подготовке автотестов используем подход BDD (Behaviour Driven Development). То есть пишем тесты со стороны пользователя: если пользователь совершает действие, то он получает результат. В качестве тестового фреймворка используем Robot Framework + Python. Customer Facing тесты храним в отдельном репозитории Gitlab. На данный момент у нас больше 1000 таких тестов. Новые тесты и правки в старые тесты добавляем через Merge Request, для прогона тестов используем Gitlab CI.
Customer Facing тесты (CFT) запускаем по расписанию через Gitlab Schedules, мы не запускаем весь набор CFT на каждый деплой т.к. прогон только тестов занимает около 20 минут. Для запуска тестов по расписанию у нас используются два выделенных стейджа: один — для проверки микросервисов, второй — тестов. Pipeline с тестами для проверки микросервисов запускается каждые 3 часа: раскатываются самые свежие версии микросервисов и запускаются тесты из ветки master. Упавшие в этом прогоне тесты говорят о том, что у нас баг или проблема в инфраструктуре, например падает микросервис. Второй стейдж используется для проверки тестов: pipeline с полным разворотом стейджа запускается каждую ночь в 01:00 по МСК. На этом стейдже гоняются не master-ветки репозитория с тестами – здесь мы проверяем любые изменения в тестах. Упавшие тесты обычно означают, что они написаны неправильно, либо задеты правками.
Наша АТ-система. Как это было
Pipeline: нет проверки состояния деплоя микросервисов в dev kubernetes;
Отчёты в Slack неудобны и не информативны;
Метрики и отчёты: собираем только общую статистику один раз в месяц, нет статистики по последнему прогону.

Наш Pipeline состоял из пяти разделов: Build, clean, create, tests и slack_notify. При этом часть job зависела от других job. То есть зависимая job не запускалась, если не была выполнена job’a от которой она зависела.
Разворот Шрёдингера
Мы перенесли часть микросервисов в kubernetes и при их развороте в pipeline столкнулись с проблемой: при запуске разворота микросервиса job’а считалась выполненной, но по факту микросервис ещё разворачивался. Так происходило потому, что Gitlab-CI не проверяет статус pod’a. То есть после отправки команды на деплой микросервиса job’а считалась выполненной успешно и запускалась job с тестами. Тесты обращались к микросервису, pod которого ещё не был создан, получали ошибку и падали. Упавшая job перезапускалась, и из-за этого росло время прохождения pipeline.
Отчёты в Slack и устройство Slack-бота
После каждого прогона тестов в отдельный канал в Slack отправлялся отчёт с информацией о прогоне. Он содержал: pipeline ID, название ветки с тестами, статус выполнения инфраструктурных и автотестовых job.
Работает скрипт так:
скрипт бота храним в репо с тестами;
скрипт запускается в последнем шаге pipelin’a;
для отчётов используется отдельный канал в Slack;
для работы скрипта используем токены Slack (для отправки сообщений в Slack) и Gitlab (для работы с Gitlab API).
Отчёты в Slack. Как тесты упали?
При работе с отчётами в Slack мы столкнулись со сложностями коммуникаций внутри и между командами:
Команды игнорировали сообщения в канале. В канал приходит большое количество сообщений и часть команд видя, что их тесты не упали мьютили канал, чтобы не получать ложных сообщений о падении;
Упавшие тесты не чинили. Команда, чьи тесты упали, не читала канал и не видела сообщений об этом, а другие команды не чинили чужие тесты;
Не было подробностей. Чтобы понять, почему тесты упали, нужно было открывать Gitlab-CI, искать упавшую job и смотреть вывод консоли или скачивать логи.

Метрики и отчёты
Собирали только основные метрики: часть тестировщиков собирались раз в месяц и считали сколько всего у нас тестов (прирост относительно прошлого месяца), сколько из них API и UI тестов, какие технологии мы использовали (есть что-то новое или отказались от чего-то) и какие ветки продукта тестируем.
При таком подходе у нас не было возможности быстро и просто посмотреть, как прошёл последний pipeline. Например, сколько job прошли успешно, а сколько – упало. Или сколько тестов прошли успешно и с какими ошибками они упали. Но самое главное: мы не видели причины падений тестов наглядно и в одном месте, чтобы понять почему тесты упали в 3-х сьютах нужно было скачать логи этих сьютов. Не было метрики pass rate (отношение упавших тестов к пройденным тестам) по pipelin’ам и job’ам.
Хватит это терпеть!
Время шло, росло количество тестов и появлялись новые проблемы. Мы понимали, что так продолжаться больше не может и начали вносить изменения. Сначала внесли правки в pipeline и добавили Healthcheck-тесты. Затем расширили функционал Slack-бота, реализовали сбор и отображение актуальной информации о статусе прохождения тестов. Дальше расскажу, как мы это реализовали и что получилось в итоге.
Правим pipeline. Добавляем линтеры
В pipeline не из master ветки (любые ветки с изменениями) мы добавили шаг с линтерами. Линтеры и проверки запускаются сразу за шагом Build, здесь мы проверяем, что написанные тесты соответствуют style guide Robot Framework. Если проверки падают — остальные job’ы не запускаются, чтобы тестировщики не вливали в master код, который не соответствует Style Guide.
Правим pipeline. Добавляем Healthcheck-тесты
Сразу после деплоя микросервисов мы запускаем Healthcheck-тесты. Это набор из восьми коротких API-тестов, которые проверяют работу основных микросервисов. Например, мы проверяем, что главная страница сайта доступна и на сайт можно залогиниться, что CRM (внутрення админка для support’a) доступна и в неё можно залогиниться, а также работу RabbitMQ. Если хотя бы один healthcheck-тест упадёт (микросервис ещё разворачивается или упал с ошибкой), то job’a считается упавшей и зависящие от неё тесты не будут запущены. Это позволяет нам не тратить время на прогон тестов, которые всё равно упадут. Т.к. большей части тестов для корректной работы нужен один из сервисов, работу которого проверяем с помощью healthcheck-тестов.
Правим Slack-бота
Чтобы сделать отчёты более информативными и помочь командам вовремя увидеть упавшие тесты, мы доработали бота. Теперь помимо общей информации о прохождении последнего pipeline, бот призывает тегом команду, тесты которой упали (только в рабочее время). Помимо этого в тред сообщения об упавших тестах приходит ссылка на job’у в pipeline, ссылка на скачивание артефактов (логи тестов) и вывод консоли с информацией о прохождении тестов (берём из job). Для отправки сообщений используем библиотеку slack_sdk, метод chat_postMessage. Для отправки сообщений в тред в метод chat_postMessage нужно передать timestamp (ts) последнего отправленного сообщения. Также во время выполнения скрипта информацию о статусе прохождения pipeline мы отправляем в базу данных MySQL (нужно для сбора метрик).

Метрики. Собираем и отображаем
Здесь я подробно расскажу о том, как настроить сбор и отображение метрик, используя MySQL и Grafana для тестов на Robot Framework.
Для начала нужно установить и настроить MySQL 8 — для этого лучше использовать отдельную машину. Инструкцию по установке MySQL 8 смотрите, например, здесь
После установки и настройки MySQL нужно создать базу данных, для этого выполните команду:
CREATE DATABASE название_БД CHARACTER SET ucs2 DEFAULT COLLATE ucs2_general_ci;Далее для сбора метрик нужно создать несколько таблиц:test_results – в неё записываем информацию о пройденных тестах:
CREATE TABLE test_results(id INT PRIMARY KEY AUTO_INCREMENT, started_at INT, pipeline_id INT(10),
branch_name VARCHAR(100), job_name VARCHAR(100), suite_name TEXT, test_name TEXT, test_status VARCHAR(20),
response_code INT, keyword_name TEXT, test_message TEXT, test_elapsed_time INT);jobs_results – в неё записываем информацию о пройденных job’ах:
CREATE TABLE jobs_results(id INT PRIMARY KEY AUTO_INCREMENT, pipeline_id INT(10), branch_name VARCHAR(100),
job_name VARCHAR(100), job_status VARCHAR(10));pipeline_results – в неё записываем информацию о пройденных pipelin’ах:
CREATE TABLE pipeline_results(id INT PRIMARY KEY AUTO_INCREMENT, created_at TIMESTAMP, pipeline_id INT(10),
branch_name VARCHAR(100), pipeline_status VARCHAR(15), quantity_failed_jobs INT(5), total_jobs INT(5));suite_results – в неё записываем информацию о пройденных suit'ах:
CREATE TABLE suite_results(id INT PRIMARY KEY AUTO_INCREMENT, pipeline_id INT(10), branch_name VARCHAR(100),
job_name VARCHAR(100), suite_name VARCHAR(300), suite_status VARCHAR(20) suite_elapsed_time INT(10));Затем, для отображения метрик нужно установить и настроить Grafana. Используйте Grafana версии 7.0 или выше. Её лучше разместить на одном инстансе с базой данных. Инструкцию по установке смотрите здесь.
После установки Grafana нужно добавить источник данных (откуда брать данные для отображения). Для этого в меню настроек Grafana кликните на Data Sources, Add Data Source и в появившемся списке выберите MySQL.
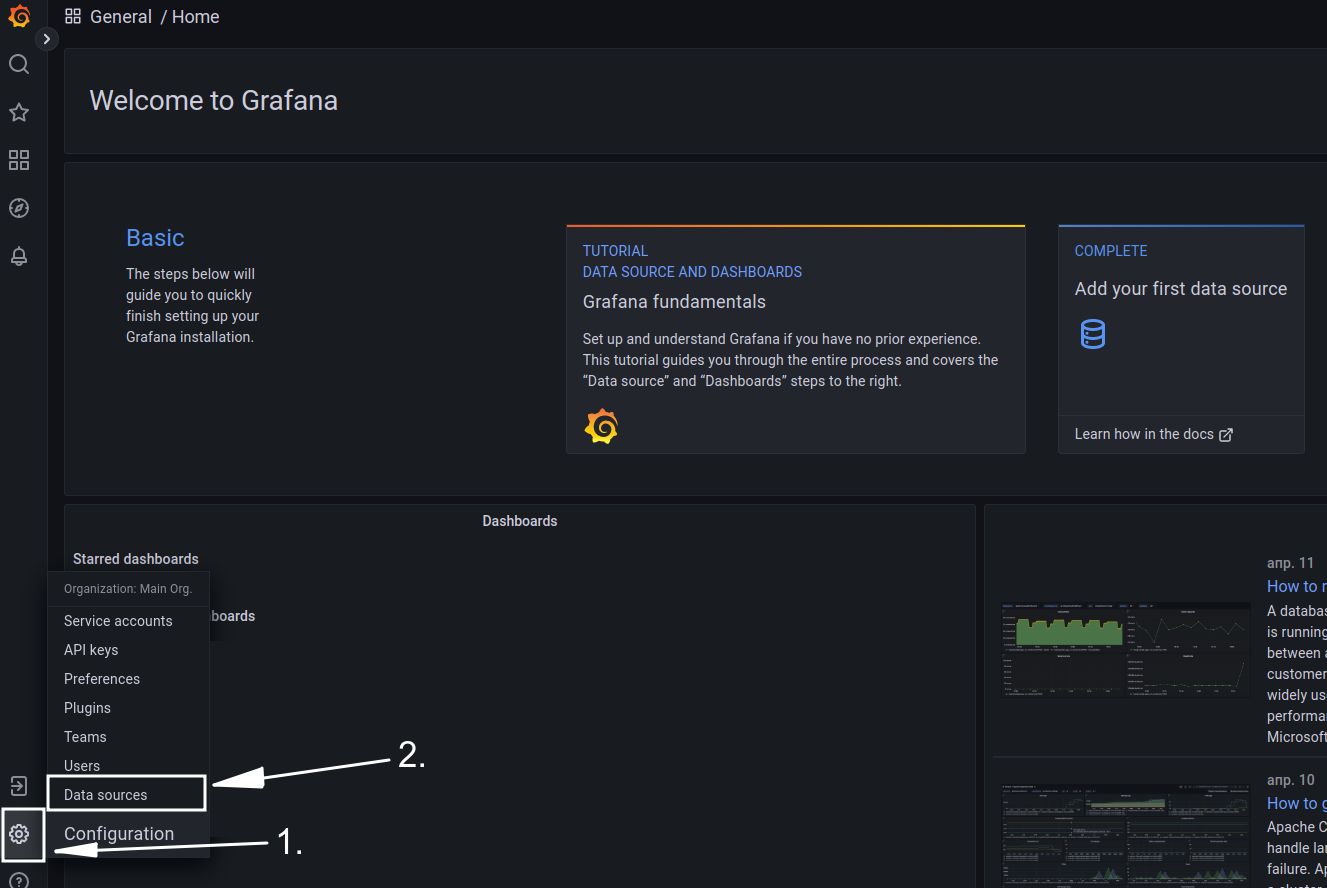
В открывшемся окне в разделе 1 в поле Name указываем название источника данных. В разделе 2 в поле Host нужно указать полный путь к базе данных, включая порт. В поле Database написать название базы данных, из которой будем брать данные для отображения. В поле Login вводим логин для доступа к БД. В поле Password — пароль. После этого кликаем на Save&Test.
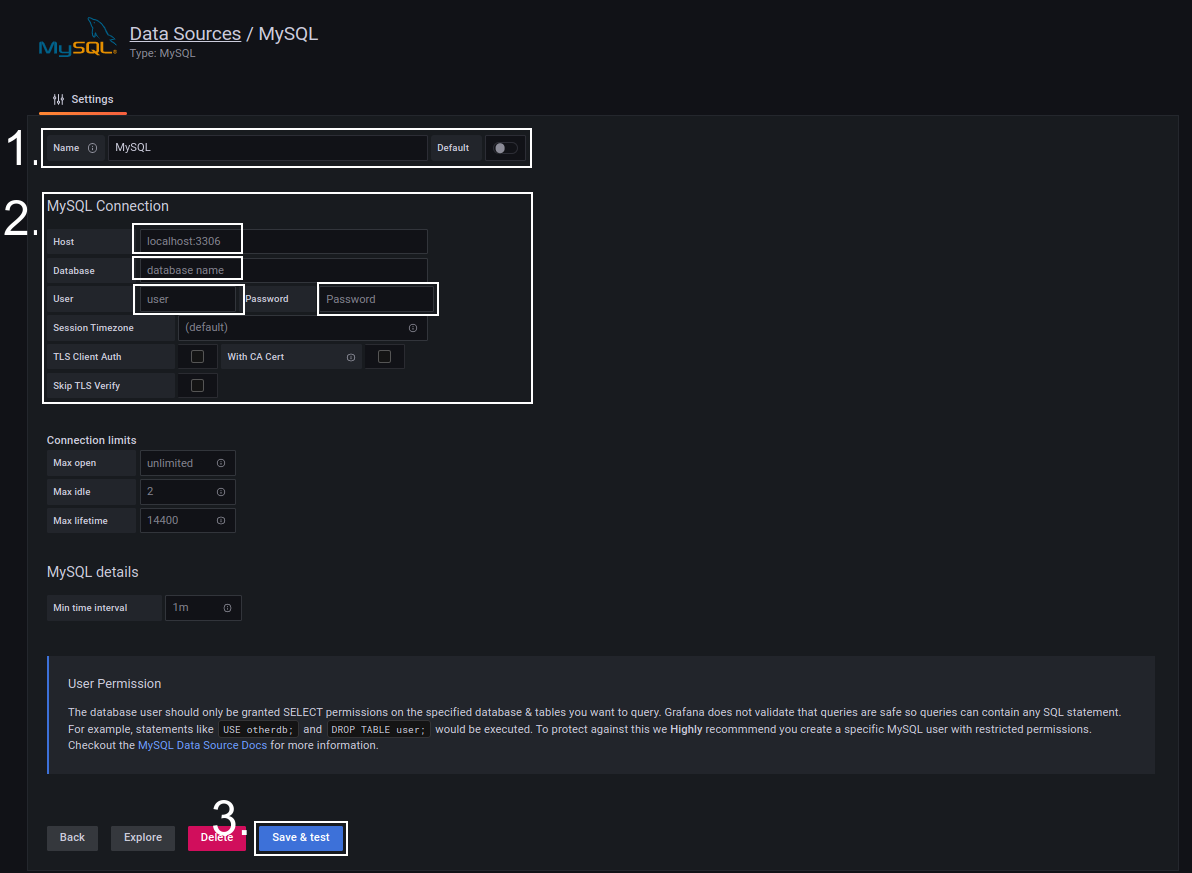
Далее нужно создать Dashboard, на котором будут отображаться метрики. Для этого в меню Grafana выбираем New dashboard – появится пустая Dashboard.
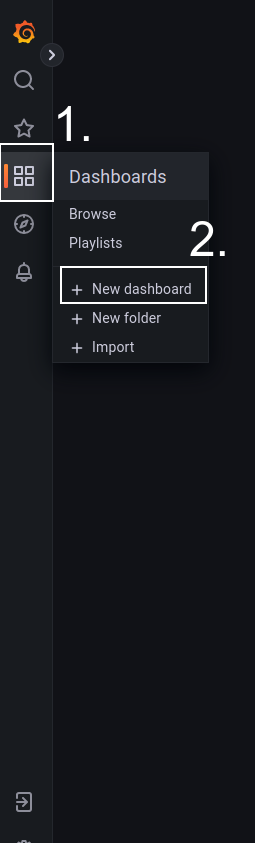
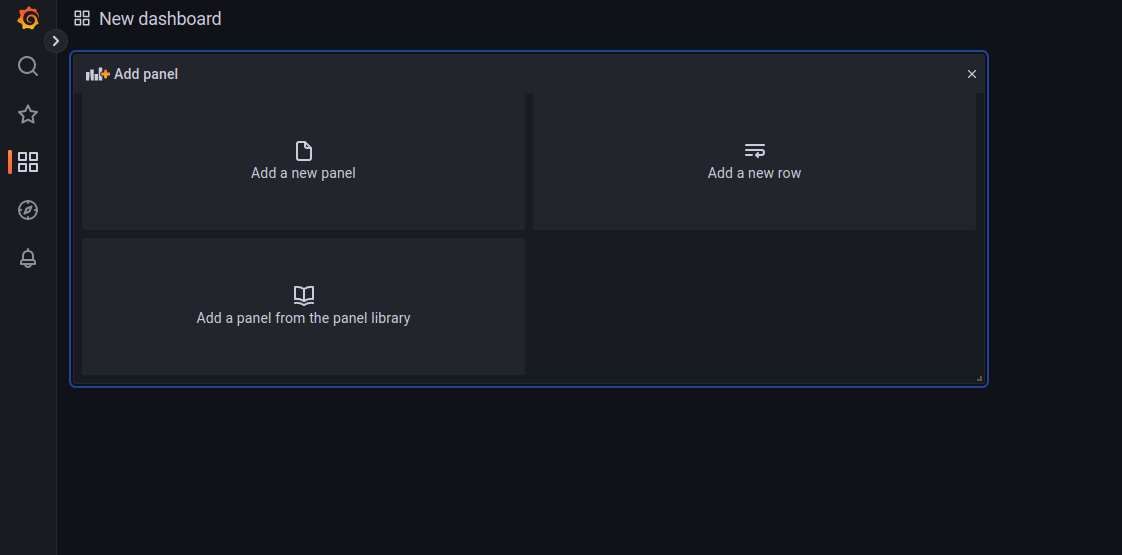
Для отображения чего-либо в Grafana используются панели (panel), которые можно преобразовать в график, таблицу, диаграмму и прочее. Для добавления панели нужно кликнуть на кнопку Add new panel (для построения доски аналогичной нашей понадобится 5 панелей).
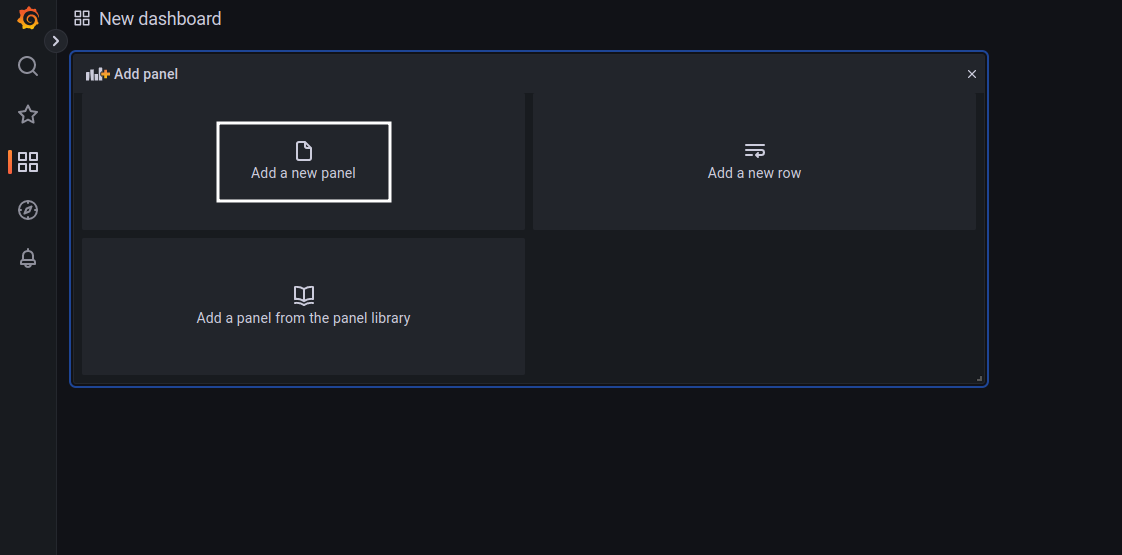
После добавления панели откроется меню настройки панели. Здесь в качестве источника данных нужно указать источник созданный ранее (MySQL).
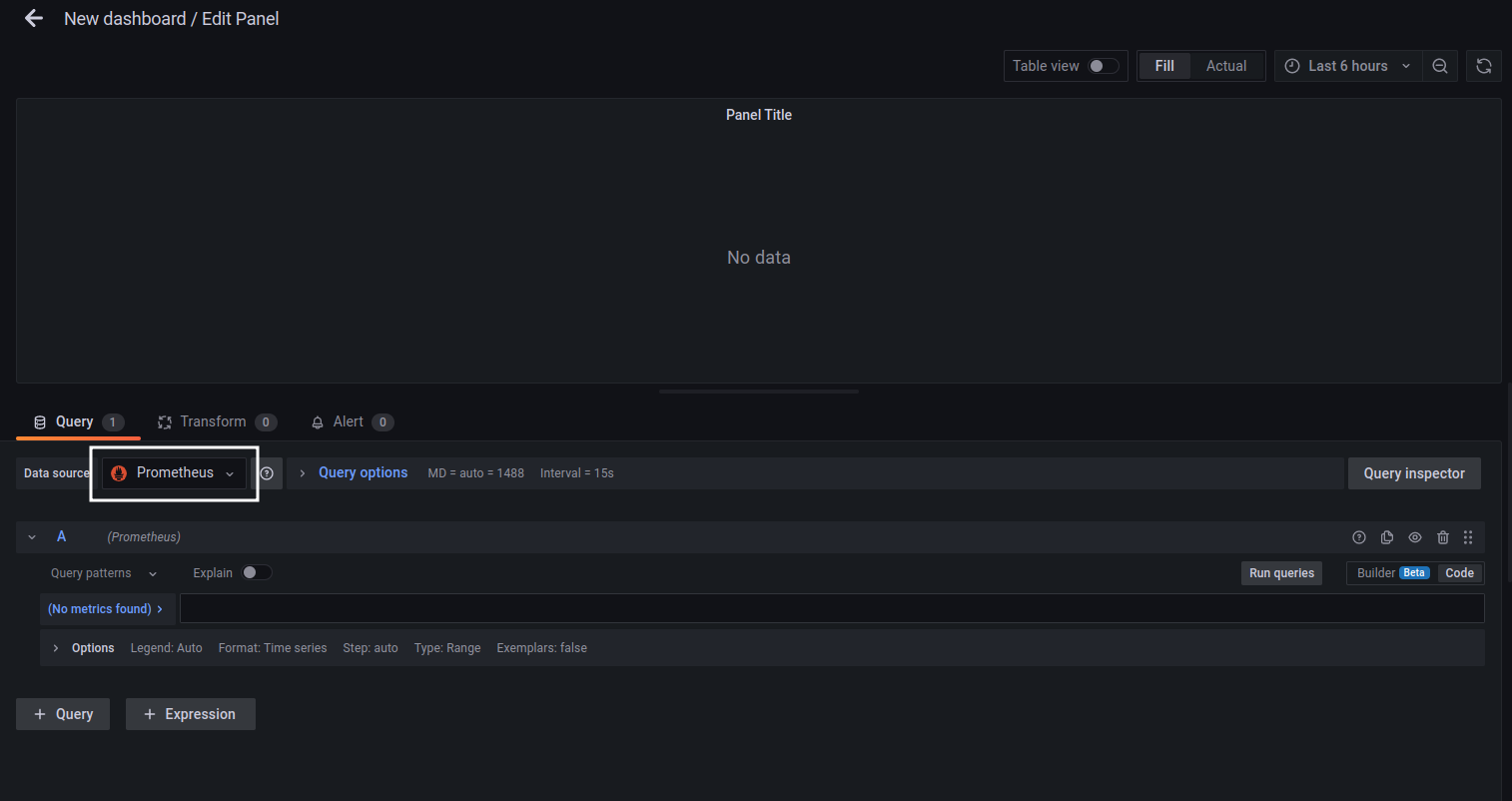
В разделе Visualization можно выбрать тип панели (график, таблица, диаграмма и проч.) – для вывода числового значения выбираем тип Stat.
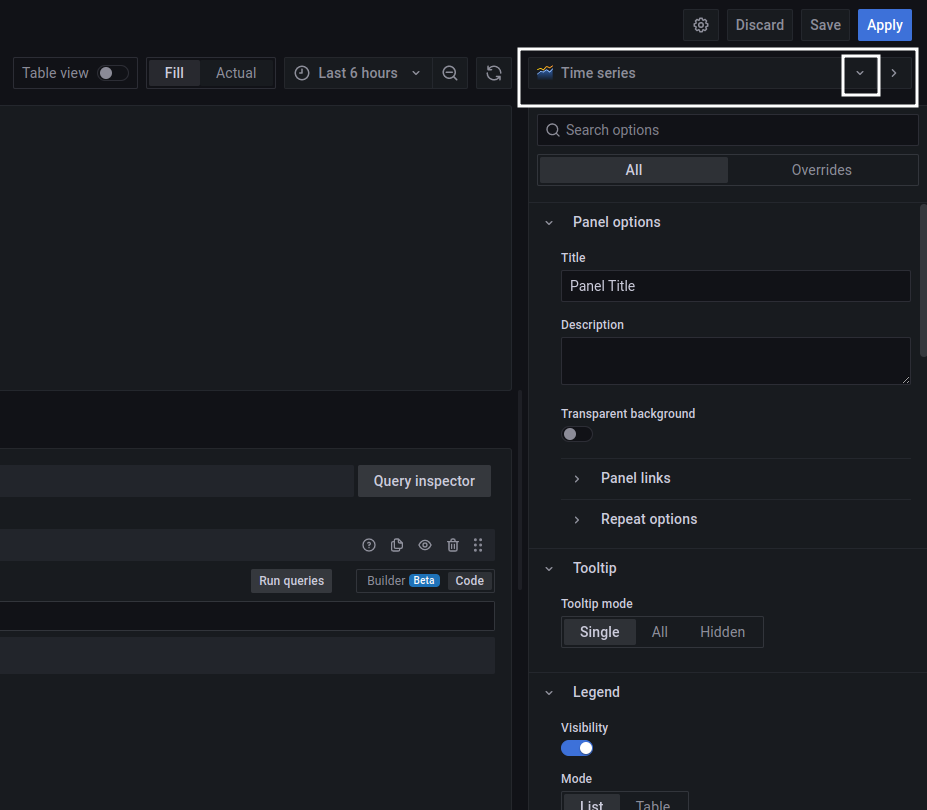
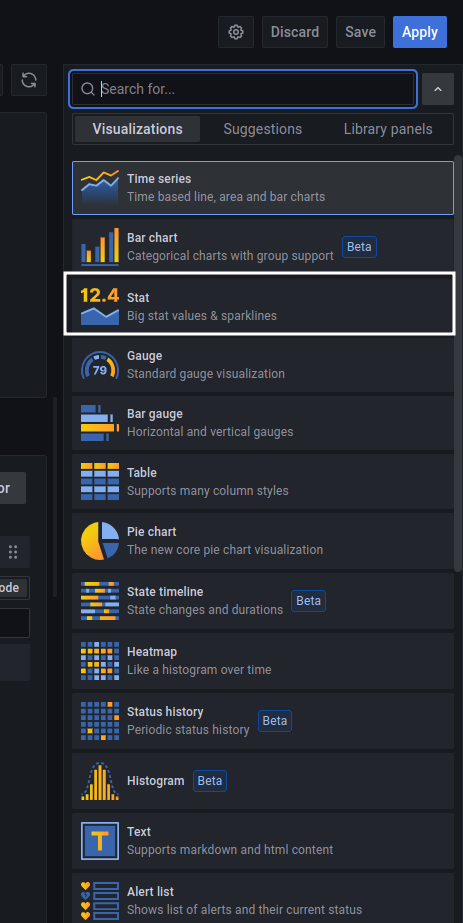
Format с Time series меняем на Table и кликаем на Edit SQL для описания условий в формате SQL. Здесь описывается запрос на получение конкретного значения метрики.
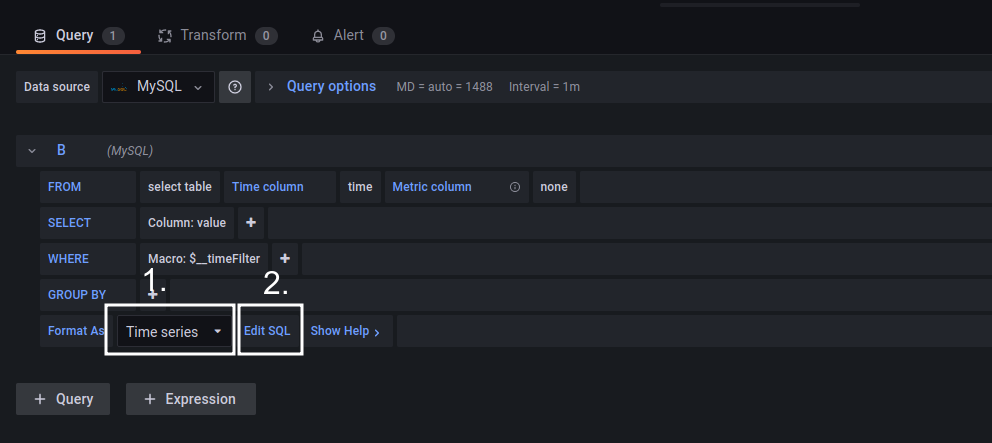
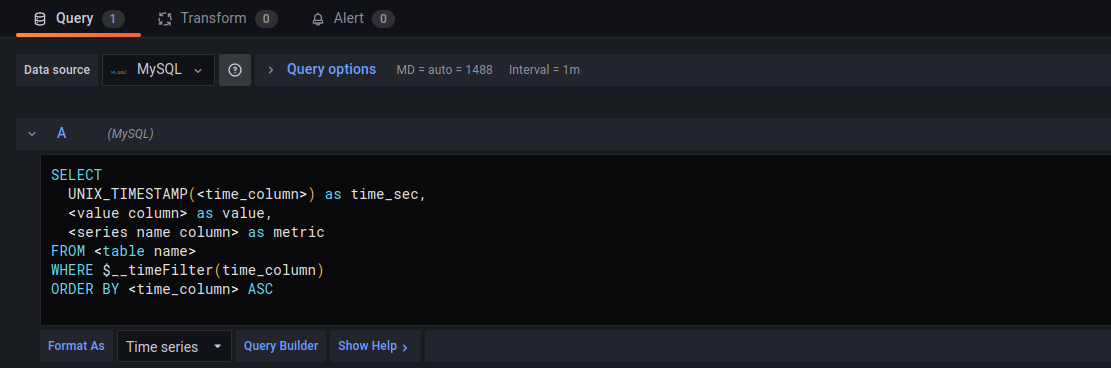
В панели Stat каждый блок запроса выводит отдельный текст. Для добавления блока в настройках панели нужно кликнуть +Query. Нам понадобятся 6 блоков, образцы SQL-запросов для них можно найти на Github. Когда все блоки добавлены, кликаем Apply, чтобы применить изменения.
Добавляем диаграммы.
После создания панели Stat нужно создать 3 диаграммы, для чего они нужны я расскажу в конце статьи:
Passed to failed jobs
Passed to failed tests
Error distribution
Для вставки диаграммы нужно добавить новую панель и выбрать источник данных. В разделе Visualization выбрать Pie Chart, тип используемых диаграмм donut. Образцы SQL запросов доступны на Github.
Помимо панелей Stat и диаграмм нам нужна таблица, в которую будем собирать общую информацию о прогоне тестов. В наборе Grafana нет подходящей таблицы, чтобы изменять ширину столбцов, фильтровать и сортировать по значениям, поэтому установим её как плагин. Для этого в настройках Grafana нужно кликнуть Configuration, перейти на вкладку Plugins и установить плагин Datatable panel (в случае, если такого плагина там нет — его можно скачать по ссылке, распаковать полученный архив и установить по пути /var/lib/grafana/plugins). После добавления плагина его можно добавить как любую другую панель (он появится в разделе Visualization). После добавления всех панелей нужно сохранить нашу Dashboard, для этого кликаем Save dashboard. Доска, отображающая информацию по последнему прогону, Pipeline готова.
Теперь аналогичным образом создадим Dashbord со статистикой по тестам за период. На доску нужно добавить панели gauge, graph и таблицу datatable panel. Код запросов для их работы доступен на Github.
Robot Framework listeners
Итак, доски в Grafana созданы, БД для сбора метрик настроена – теперь нужно настроить отправку автотестовых метрик в БД, для этого используем Listeners (слушатели) Robot Framework. Это встроенные в Robot Framework функции позволяющие получить статус выполнения теста, название выполняемого кейворда, статус выполнения тест-сьюта и др. Подробнее о том, как использовать слушателей, можно прочесть в документации. Для использования их нужно объявить в отдельном файле и при запуске тестов передать команду - - listener путь_к_файлу, где они объявлены. В тестах слушатели вызываются по событию, в зависимости от типа слушателя: при запуске сьюта, при запуске теста, после выполнения теста, после выполнения кейворда и т.д.
Какие слушатели мы используем и для чего
start_suite — выполняется при старте тестов, используем для получения названия test-suit’a, в котором выполняется тест:
def start_suite(self, name, attrs):
self.suite_name = nameend_keyword — выполняется при завершении выполнения кейворда, используем для получения названия ключевого слова, если тест упал:
def end_keyword(self, name, attrs):
if attrs['status'] == 'FAIL':
if attrs['libname'] in self.business_libs:
self.keyword = namestart_test — получаем время запуска теста:
def start_test(self, name, attrs):
self.started_at = int(datetime.now().timestamp())end_test — выполняется при завершении выполнения теста, используем для получения последнего кода ответа от сервера, получения названия теста, сообщения (с которым тест упал — пустое, если тест PASS), статус и время выполнения теста, записи результатов в базу данных:
def end_test(self, name, attrs):
built_in = BuiltIn()
try:
self.response_code = built_in.get_variable_value('${RESP.status_code}')
except:
self.response_code = None
self.test_name = name
self.test_message = attrs["message"]
self.test_elapsed_time = attrs["elapsedtime"]
self.test_status = attrs["status"]
query, values = self._query_for_tests_results()
self._write_results_in_db(query, values)end_suite — выполняется по завершении выполнения всех тестов в сьюте, используем для получения статуса и времени выполнения тест-сьюта, записываем результаты в БД:
def end_suite(self, name, attrs):
self.suite_status = attrs["status"]
self.suite_elapsed_time = attrs["elapsedtime"]
query, values = self._query_for_suite_results()
self._write_results_in_db(query, values)Полный код слушателей доступен на GitHub.
Как наша АТ-система выглядит сейчас
Pipeline с прогоном тестов
После шага Build (собираем контейнер с тестами) запускаем шаг с линтерами: проверяем, что тесты соответствуют Robot Framework Style Guide, отсутствуют пробелы в конце строки и т.п. После того, как на стейдж были задеплоены микросервисы, необходимые для работы тестов, запускаем Healthcheck-тесты. Если хотя бы один Healthcheck-тест упадёт, то Customer Facing Tests тесты запущены не будут.

Отчёты в Slack
Сейчас, помимо отправки простого отчёта о статусе прохождения job в pipeline бот оповещает команду, тесты которой упали; в треде к сообщению об упавших тестах отправляет ссылку на упавшую job’у, ссылку на логи тестов (теперь их можно скачать не выходя из слака) и вывод из консоли (только то, что касается тестов) внутри автотестовой job’ы. Чтобы бот оповещал команду, если job c тестами упала, команды в отдельном файле, который затем импортируется в скрипте бота, указывают какие тесты они написали.

Что изменилось в метриках
Мы по-прежнему раз в месяц собираем основные автотестовые метрики. Такие, как прирост тестов, какие части продукта покрыты автотестами, количество UI и API-тестов, используемые инструменты. Но помимо этого у нас появились две доски в Grafan’e с информацией о прохождении последнего Pipeline: только для тестов из ветки master и с общей статистикой по прогонам тестов за период времени (неделя).
Метрики. Доска с информацией о последнем прогоне тестов
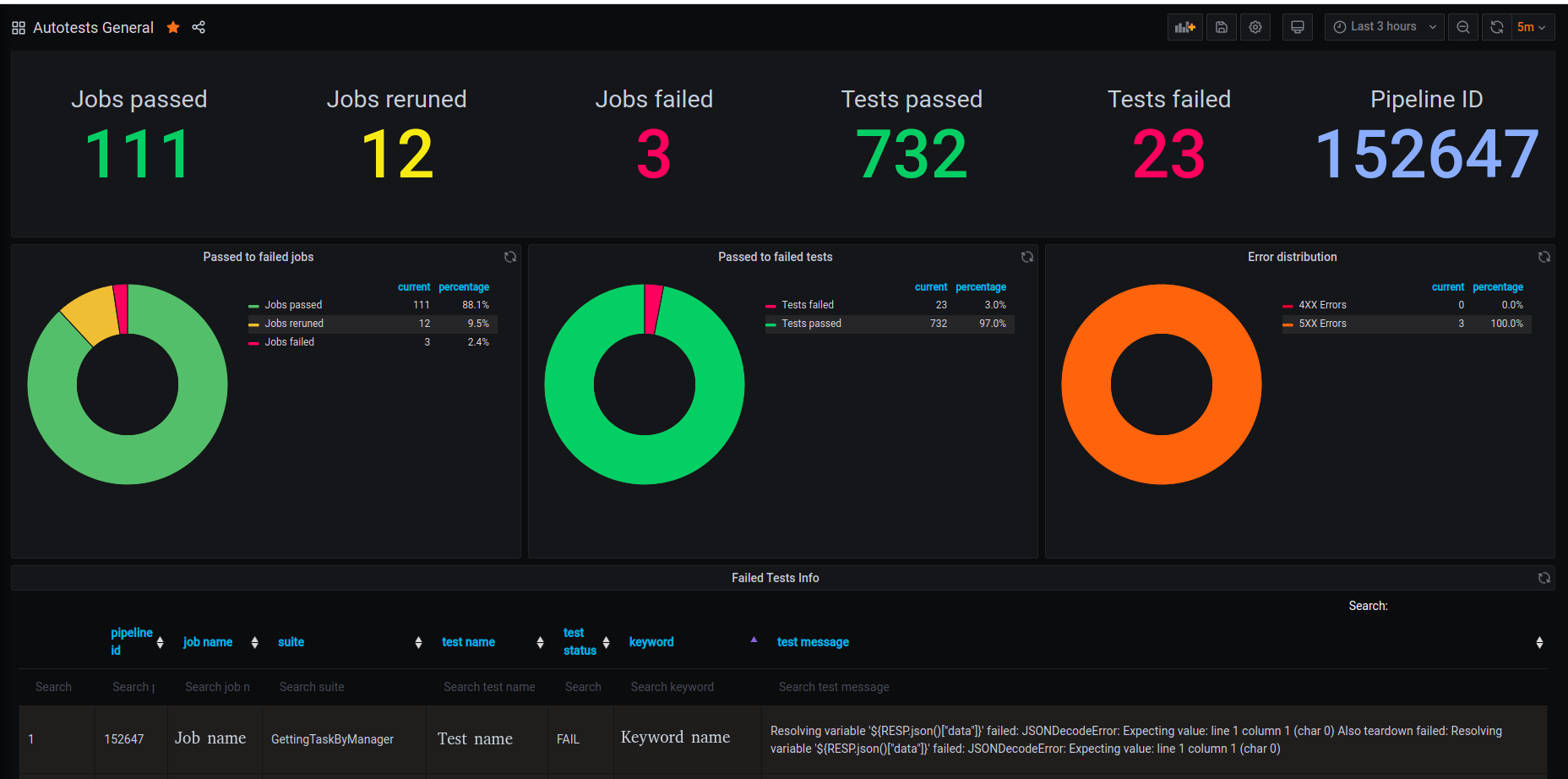
Доска содержит 5 блоков, включая диаграммы:
Блок с общей информацией о прогоне — сколько job прошло успешно (job’a не была перезапущена), сколько job прошло успешно после перезапуска, сколько упало (job’a упала трижды), сколько тестов прошло и сколько упало, а также pipeline Id.
Диаграмма, отображающая соотношения пройденных, перезапущенных и упавших автотестовых job.
Диаграмма, отображающая соотношения пройденных и упавших тестов.
Диаграмма с распределением ошибок (количество ошибок с кодом 40X и 50X) – позволяет быстро понять причину падения тестов: большое количество ошибок с кодом 40X говорит нам о том, что в тестах ошибка (допустили при написании тестов или изменился\устарел метод у API); большое кол-во 50X ошибок сигнализирует о проблеме с работой микросервисов на стейдже.
Таблица с информацией об упавших тестах из последнего pipeline – содержит pipeline id, название job в которой выполнялся тест, название теста, название тест-сьюта, кейворд на котором тест упал и сообщение с причиной падения.
Статистика прохождения тестов за период
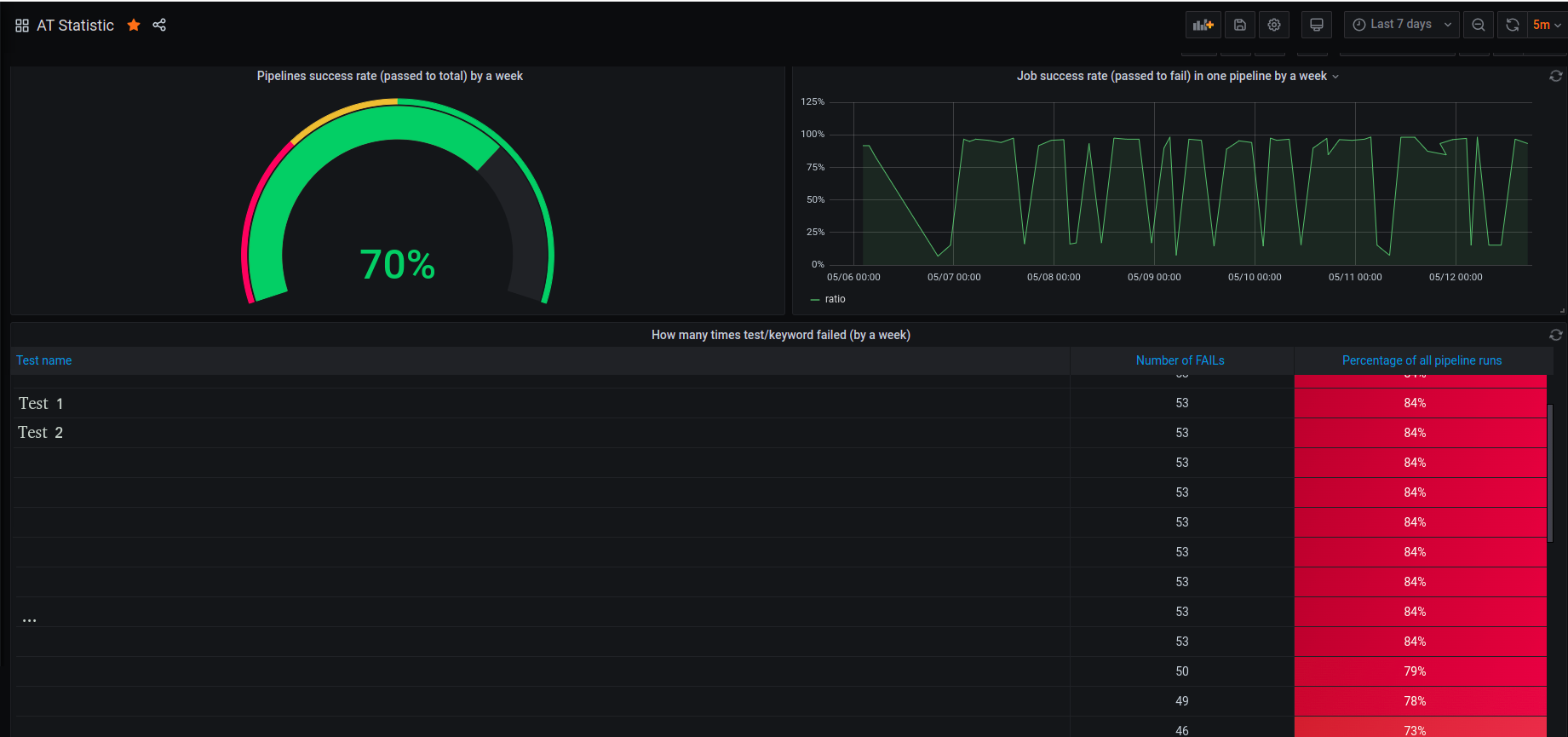
На этой доске отображаем информацию о состоянии нашей АТ-системы за прошедшую неделю (скользящее окно).
Здесь собраны:
диаграмма, отображающая соотношение зелёных pipeline к красным, которая показывает насколько хорошо проходили pipeline и можно ли ориентироваться на отчёты о прохождении тестов,
график, отображающий соотношение пройденных job к упавшим внутри pipeline,
таблица, в которой собраны самые падающие тесты (можно отобразить кейворды) за период времени. Таблица отсортирована по убыванию и самые падающие тесты находятся вверху. Т.к. для падения всей job достаточно чтобы всего один тест упал, то правка тестов из вершины списка позволяет добиться успешного прохождения большого количества job’ов.
Выводы
Благодаря улучшениям, которые мы внесли, pipelin’ы с автотестами стали проходить быстрее (не запускаем тесты, если заранее известно, что они упадут), а вывод информации в Grafana позволяет нам быстро понять, что пошло не так или оценить состояние наших тестов в целом. Также мы стали чаще и быстрее реагировать на падения тестов, а следовательно и находить баги в продукте.
А с какими трудностями в работе с автотестовой системой сталкивались вы? Буду рад обсудить в комментариях.

![[Личный опыт] Стоит ли программисту «покорять» Америку](/upload/resize_cache/iblock/883/105_70_0/883192c9c7a35132b1899d207a924954.jpg "[Личный опыт] Стоит ли программисту «покорять» Америку")

")
