Недавно мне посчастливилось заниматься переносом кластера PostgreSQL под управлением Patroni на новое железо. Задача казалась простой — я и не думал, что могут возникнуть проблемы.

Но в процессе реализации встретились некоторые сложности, которые натолкнули на мысль поделиться полученным опытом. В этой работе описываются практические шаги и нюансы, которые встретились во время переноса кластера на новую платформу. Использовались следующие версии ПО: PostgreSQL 11.13, Patroni 2.1.1, etcd 3.2.17 (API version 2).
Итак, поехали!
Введение
Patroni — это известный Open Source-проект для СУБД PostgreSQL от Zalando, написанный на Python и созданный для автоматизации построения кластеров высокой доступности. По своей сути его можно назвать своеобразным фреймворком. В основе Patroni стоит механизм потоковой репликации (streaming replication), работа которого строится на WAL (Write-Ahead Log). Когда мы вносим изменения в базу данных, все изменения сперва записываются в WAL. После записи в WAL СУБД производит системный вызов fsync, в результате чего данные записываются на диск. Это обеспечивает возможность сохранения незавершенных операций, например, в случае аварийного завершения работы сервера. При включении сервера СУБД прочитает последние записи из WAL и применит к базе данных соответствующие изменения.
Потоковая репликация — это механизм, который реализует передачу записей из WAL от мастера к репликам. При такой конфигурации репликации право на запись есть только у мастера, а читать возможно как с мастера, так и с реплик (если разрешено). Для разрешения чтения с реплики она должна работать в режиме hot_standby. Так как большинство запросов к СУБД — запросы на чтение, репликация позволяет масштабировать базу данных горизонтально. Потоковая репликация имеет два режима работы:
асинхронная — запросы выполняются на мастер-узле сразу же, в то время как изменения из WAL репликам передаются отдельно;
синхронная — данные записываются в WAL на мастере и как минимум на одной реплике. Только в этом случае транзакция считается выполненной. Конкретные условия устанавливаются в настройках PostgreSQL.
Для того, чтобы все члены кластера Patroni знали о состоянии друг друга, предусмотрено хранение данных в Distributed Configuration Store (DCS) — распределенном хранилище конфигурации. В качестве DCS могут использоваться различные хранилища типа key-value, например: Consul, etcd (v3), ZooKeeper. В контексте статьи мы будем рассматривать работу с etcd.
Постановка задачи. Исходное состояние инфраструктуры
Предоставляя клиентам обслуживание инфраструктуры под ключ, мы столкнулись с довольно типичной ситуацией: на сервере базы данных заканчивалось место, но работающий в ЦОДе сервер физически не позволял подключить дополнительный диск. Как быть в такой ситуации? Ответ довольно прост — мигрировать сервис с СУБД на новый сервер, предусмотрев возможность расширения. В результате было заказано 3 более мощных физических сервера для переезда.
Исходное состояние инфраструктуры:
кластер PostgreSQL на базе Patroni, состоящий из трех серверов и работающих в режиме асинхронной репликации;
кластер etcd (для хранения состояния Patroni), состоящий из трех инстансов (по одному на каждом из серверов кластера Patroni);
серая сеть внутри контура с PostgreSQL с адресацией 192.168.0.0/24;
load balancer, передающий трафик на master-узел кластера PgSQL.
Для удобства ниже я буду проводить все действия и рассматривать узкие места в конфигурации на тестовом стенде. Условная схема взаимодействия сервисов представлена ниже:

Между всеми узлами и load balancer’ом существует сетевая связанность, то есть каждый хост доступен для всех остальных по IP.
Для комфортного чтения конфигурации на каждом из узлов добавлены следующие записи в файл /etc/hosts:
# etcd
192.168.0.16 server-1 etcd1
192.168.0.9 server-2 etcd2
192.168.0.12 server-3 etcd3Состояние кластера Patroni:

Листинг файла конфигурации /etc/patroni.yaml на узле server-1:
scope: patroni_cluster
name: server-1
namespace: /patroni/
restapi:
listen: 192.168.0.16:8008 # IP-адрес узла и порт, на котором будет работать Patroni API
connect_address: 192.168.0.16:8008
authentication:
username: patroni
password: 'mysuperpassword'
etcd:
hosts: etcd1:2379,etcd2:2379,etcd3:2379
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
synchronous_mode: false
postgresql:
use_pg_rewind: true
use_slots: true
parameters:
wal_level: hot_standby
synchronous_commit: off
hot_standby: "on"
initdb:
- encoding: UTF8
- data-checksums
pg_hba:
- local all postgres trust
- host postgres all 127.0.0.1/32 md5
- host replication replicator 0.0.0.0/0 md5
- host replication all 192.168.0.16/32 trust # server-1
- host replication all 192.168.0.9/32 trust # server-2
- host replication all 192.168.0.12/32 trust # server-3
- host all all 0.0.0.0/0 md5
users:
admin:
password: 'mysuperpassword2'
options:
- createrole
- createdb
postgresql:
listen: 192.168.0.16:5432 # IP-адрес интерфейса и порт, на которых будет слушать postgresql
connect_address: 192.168.0.16:5432
data_dir: /data/patroni
bin_dir: /usr/lib/postgresql/11/bin
config_dir: /data/patroni
pgpass: /tmp/pgpass0
authentication:
replication:
username: replicator
password: 'mysuperpassword3'
superuser:
username: postgres
password: 'mysuperpassword4'
rewind:
username: rewind_user
password: 'mysuperpassword5'
parameters:
unix_socket_directories: '/tmp'
tags:
nofailover: false
noloadbalance: false
clonefrom: false
nosync: falseСостояние кластера etcd:

Листинг файла конфигурации /etc/default/etcd на узле server-1:
ETCD_LISTEN_PEER_URLS="http://127.0.0.1:2380,http://192.168.0.16:2380"
ETCD_LISTEN_CLIENT_URLS="http://127.0.0.1:2379,http://192.168.0.16:2379"
ETCD_INITIAL_CLUSTER="etcd1=http://etcd1:2380"
ETCD_INITIAL_CLUSTER_STATE="new-cluster"
ETCD_INITIAL_CLUSTER_TOKEN="myclustertoken"
ETCD_DATA_DIR="/var/lib/etcd"
ETCD_ELECTION_TIMEOUT="5000"
ETCD_HEARTBEAT_INTERVAL="1000"
ETCD_NAME="etcd1"
ETCD_ADVERTISE_CLIENT_URLS="http://192.168.0.16:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.0.16:2380"Примечание: файл конфигурации /etc/default/etcd используется для бутстрапа кластера etcd, т. е. параметры, описанные в нём, применяются в момент инициализации (первого запуска) процесса etcd. После того, как кластер инициализирован, конфигурация читается из рабочего каталога, заданного параметром ETCD_DATA_DIR.
Наша задача — перенести данные с серверов #1, 2 и 3 на новые серверы без простоя в работе сервиса. Для достижения результата мы начнем постепенно расширять кластер PostgreSQL и кластер etcd, наделяя новые узлы небольшими отличиями от оригинальных узлов PgSQL:
Не будем добавлять endpoint’ы новых серверов в распределение трафика load balancer’ом.
Новые узлы PostgreSQL не будут принимать участие в выборе master-узла при failover.
В реальной задаче сетевая связность между узлами была организована через интернет, что было неприемлемо с точки зрения безопасности. Поэтому средствами ЦОДа был подготовлен VPN для достижения L2-связности между узлами. Не буду подробно описывать этот этап подготовки к переезду, и для удобства и упрощения схемы помещу новые серверы в сеть 192.168.0.0/24, чтобы обеспечить всем узлам связь в пределах broadcast-домена.
Таким образом, промежуточная схема взаимодействия узлов в кластере будет выглядеть следующим образом:
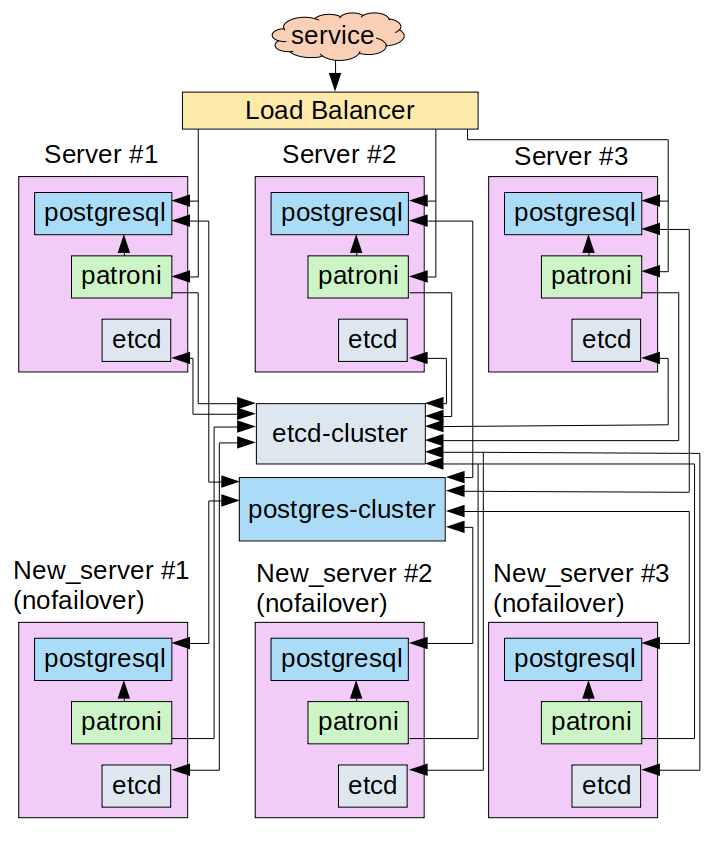
Реализация
План по реализации задуманного таков:
расширение etcd-кластера;
расширение PostgreSQL-кластера средствами Patroni;
вывод из PostgreSQL-кластера «старых» узлов;
вывод из etcd-кластера «старых» инстансов.
Итак, начнём!
Шаг №1. Расширяем кластер etcd
Важно! Так как etcd (или любое другое хранилище типа key-value) является фундаментальным компонентом в функционировании Patroni, лучше всего проектировать систему так, чтобы кластер работал на отдельных инстансах, имел свою собственную подсеть и не зависел от самих узлов с Patroni. Но в рамках рассматриваемого стенда я сэкономил и разместил кластер etcd на тех же серверах, что и PostgreSQL с Patroni.
Первым делом нужно расширить кластер etcd так, чтобы при переключении лидера всем узлам (и новым, и старым) был доступен новый лидер. Для этого сначала внесем изменения в конфигурационный файл /etc/hosts на каждом из шести узлов и приведем его примерно к следующему виду (в сегменте ранее добавленных строк):
# etcd
192.168.0.16 server-1 etcd1
192.168.0.9 server-2 etcd2
192.168.0.12 server-3 etcd3
192.168.0.13 new_server-1 etcd-1 # IP-адрес первого нового сервера
192.168.0.17 new_server-2 etcd-2 # ... второго
192.168.0.18 new_server-3 etcd-3 # ... третьегоДалее начинаем по очереди добавлять инстансы в кластер etcd. На машине new_server-1 (192.168.0.13) проверим, что сервис etcd не запущен:
root@new_server-1:~# systemctl status etcd
● etcd.service - etcd - highly-available key value store
Loaded: loaded (/lib/systemd/system/etcd.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: https://github.com/coreos/etcd
man:etcdНа всякий случай очистим каталог /var/lib/etcd, чтобы быть уверенными в том, что конфигурация будет получена из файла /etc/default/etcd:
root@new_server-1:~# rm -rf /var/lib/etcd/*Теперь приведём файл /etc/default/etcd к следующему виду:
ETCD_LISTEN_PEER_URLS="http://192.168.0.13:2380,http://127.0.0.1:2380"
ETCD_LISTEN_CLIENT_URLS="http://192.168.0.13:2379,http://127.0.0.1:2379"
ETCD_INITIAL_CLUSTER_TOKEN="myclustertoken"
ETCD_DATA_DIR="/var/lib/etcd"
ETCD_ELECTION_TIMEOUT="5000"
ETCD_HEARTBEAT_INTERVAL="1000"
ETCD_ADVERTISE_CLIENT_URLS="http://192.168.0.13:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.0.13:2380"Переходим на один из серверов etcd-кластера (например, server-1) и смотрим список членов кластера:
root@server-1:~# etcdctl member list
862db4122a92dc3: name=etcd3 peerURLs=http://etcd3:2379 clientURLs=http://192.168.0.12:2379 isLeader=false
46d7a702fdb60fff: name=etcd1 peerURLs=http://etcd1:2380 clientURLs=http://192.168.0.16:2379 isLeader=true
d129ecfd4c627e1f: name=etcd2 peerURLs=http://etcd2:2379 clientURLs=http://192.168.0.9:2379 isLeader=falseДобавляем нового члена кластера:
root@server-1:~# etcdctl member add etcd-1 http://etcd-1:2380
Added member named etcd-1 with ID 6d299012c6ad9595 to cluster
ETCD_NAME="etcd-1"
ETCD_INITIAL_CLUSTER="etcd1=http://etcd1:2380,etcd-1=http://etcd-1:2380,etcd2=http://etcd2:2380,etcd3=http://etcd3:2380"
ETCD_INITIAL_CLUSTER_STATE="existing"Etcd сообщил параметры, которые мы должны использовать в новом инстансе для подключения к существующему кластеру. Добавляем эти параметры в /etc/default/etcd на сервере etcd-1 (new_server-1). В конечном итоге получаем такой файл конфигурации (к изначальному конфигу добавились три последние строки):
ETCD_LISTEN_PEER_URLS="http://192.168.0.13:2380,http://127.0.0.1:2380"
ETCD_LISTEN_CLIENT_URLS="http://192.168.0.13:2379,http://127.0.0.1:2379"
ETCD_INITIAL_CLUSTER_TOKEN="myclustertoken"
ETCD_DATA_DIR="/var/lib/etcd"
ETCD_ELECTION_TIMEOUT="5000"
ETCD_HEARTBEAT_INTERVAL="1000"
ETCD_ADVERTISE_CLIENT_URLS="http://192.168.0.13:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.0.13:2380"
ETCD_NAME="etcd-1"
ETCD_INITIAL_CLUSTER="etcd1=http://etcd1:2380,etcd-1=http://etcd-1:2380,etcd2=http://etcd2:2380,etcd3=http://etcd3:2380"
ETCD_INITIAL_CLUSTER_STATE="existing"Проверяем на сервере состояние кластера etcd:
root@new_server-1:~# etcdctl member list
46d7a702fdb60fff: name=etcd1 peerURLs=http://etcd1:2380 clientURLs=http://192.168.0.16:2379 isLeader=true
6d299012c6ad9595: name=etcd-1 peerURLs=http://etcd-1:2380 clientURLs=http://192.168.0.13:2379 isLeader=false
c32185ccfd4b4b41: name=etcd2 peerURLs=http://etcd2:2380 clientURLs=http://192.168.0.9:2379 isLeader=false
d56f1524a8fe199e: name=etcd3 peerURLs=http://etcd3:2380 clientURLs=http://192.168.0.12:2379 isLeader=falseКак мы видим, etcd-1 успешно добавлен в кластер. Повторяем все действия для следующего сервера, заранее подготовив для него шаблон конфигурации (/etc/default/etcd), где потребуется поменять адреса сетевых интерфейсов в соответствии с адресом сервера. На выходе получаем:
root@new_server-2:~# etcdctl member list
40ebdfb25cac6924: name=etcd-2 peerURLs=http://etcd-2:2380 clientURLs=http://192.168.0.17:2379 isLeader=false
46d7a702fdb60fff: name=etcd1 peerURLs=http://etcd1:2380 clientURLs=http://192.168.0.16:2379 isLeader=true
6d299012c6ad9595: name=etcd-1 peerURLs=http://etcd-1:2380 clientURLs=http://192.168.0.13:2379 isLeader=false
c32185ccfd4b4b41: name=etcd2 peerURLs=http://etcd2:2380 clientURLs=http://192.168.0.9:2379 isLeader=false
d56f1524a8fe199e: name=etcd3 peerURLs=http://etcd3:2380 clientURLs=http://192.168.0.12:2379 isLeader=false… и такой файл конфигурации /etc/default/etcd:
ETCD_LISTEN_PEER_URLS="http://192.168.0.17:2380,http://127.0.0.1:2380"
ETCD_LISTEN_CLIENT_URLS="http://192.168.0.17:2379,http://127.0.0.1:2379"
ETCD_INITIAL_CLUSTER_TOKEN="myclustertoken"
ETCD_DATA_DIR="/var/lib/etcd"
ETCD_ELECTION_TIMEOUT="5000"
ETCD_HEARTBEAT_INTERVAL="1000"
ETCD_ADVERTISE_CLIENT_URLS="http://192.168.0.17:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.0.17:2380"
ETCD_NAME="etcd-2"
ETCD_INITIAL_CLUSTER="etcd-2=http://etcd-2:2380,etcd1=http://etcd1:2380,etcd-1=http://etcd-1:2380,etcd2=http://etcd2:2380,etcd3=http://etcd3:2380"
ETCD_INITIAL_CLUSTER_STATE="existing"Повторяем процедуру для третьего сервера и проверяем результат:
root@new_server-3:~# etcdctl member list
40ebdfb25cac6924: name=etcd-2 peerURLs=http://etcd-2:2380 clientURLs=http://192.168.0.17:2379 isLeader=false
46d7a702fdb60fff: name=etcd1 peerURLs=http://etcd1:2380 clientURLs=http://192.168.0.16:2379 isLeader=true
6c2e836d0c3a51c3: name=etcd-3 peerURLs=http://etcd-3:2380 clientURLs=http://192.168.0.18:2379 isLeader=false
6d299012c6ad9595: name=etcd-1 peerURLs=http://etcd-1:2380 clientURLs=http://192.168.0.13:2379 isLeader=false
c32185ccfd4b4b41: name=etcd2 peerURLs=http://etcd2:2380 clientURLs=http://192.168.0.9:2379 isLeader=false
d56f1524a8fe199e: name=etcd3 peerURLs=http://etcd3:2380 clientURLs=http://192.168.0.12:2379 isLeader=falseФайл конфигурации /etc/default/etcd:
ETCD_LISTEN_PEER_URLS="http://192.168.0.18:2380,http://127.0.0.1:2380"
ETCD_LISTEN_CLIENT_URLS="http://192.168.0.18:2379,http://127.0.0.1:2379"
ETCD_INITIAL_CLUSTER_TOKEN="myclustertoken"
ETCD_DATA_DIR="/var/lib/etcd"
ETCD_ELECTION_TIMEOUT="5000"
ETCD_HEARTBEAT_INTERVAL="1000"
ETCD_ADVERTISE_CLIENT_URLS="http://192.168.0.18:2379"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.0.18:2380"
ETCD_NAME="etcd-3"
ETCD_INITIAL_CLUSTER="etcd-2=http://etcd-2:2380,etcd1=http://etcd1:2380,etcd-3=http://etcd-3:2380,etcd-1=http://etcd-1:2380,etcd2=http://etcd2:2380,etcd3=http://etcd3:2380"
ETCD_INITIAL_CLUSTER_STATE="existing"Мы расширили etcd-кластер с трех инстансов до шести.
Шаг №2. Расширяем кластер PostgreSQL
Следующим нашим шагом будет расширение кластера PgSQL. Так как кластер управляется Patroni, нужно подготовить файл конфигурации /etc/patroni.yaml с примерно следующим содержанием:
scope: patroni_cluster
name: new_server-1
namespace: /patroni/
restapi:
listen: 192.168.0.13:8008
connect_address: 192.168.0.13:8008
authentication:
username: patroni
password: 'mynewpassword'
etcd:
hosts: etcd-1:2379,etcd-2:2379,etcd-3:2379
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
synchronous_mode: false
postgresql:
use_pg_rewind: true
use_slots: true
parameters:
wal_level: hot_standby
synchronous_commit: off
hot_standby: "on"
initdb:
- encoding: UTF8
- data-checksums
pg_hba:
- local all postgres trust
- host postgres all 127.0.0.1/32 md5
- host replication replicator 0.0.0.0/0 md5
- host replication all 192.168.0.16/32 trust # server-1
- host replication all 192.168.0.9/32 trust # server-2
- host replication all 192.168.0.12/32 trust # server-3
- host all all 0.0.0.0/0 md5
users:
admin:
password: 'mynewpassword2'
options:
- createrole
- createdb
postgresql:
listen: 192.168.0.13:5432
connect_address: 192.168.0.13:5432
data_dir: /data/patroni
bin_dir: /usr/lib/postgresql/11/bin
config_dir: /data/patroni
pgpass: /tmp/pgpass0
authentication:
replication:
username: replicator
password: 'mynewpassord3'
superuser:
username: postgres
password: 'mynewpassord4'
rewind:
username: rewind_user
password: 'mynewpassword5'
parameters:
unix_socket_directories: '/tmp'
tags:
nofailover: true
noloadbalance: true
clonefrom: false
nosync: falseПримечания:
Мы изменяем настройки etcd для Patroni на новых серверах (см. значение
hostsв секцииetcd), ограничивая endoint’ы только новыми серверами, так как в дальнейшем мы планируем выводит старые инстансы etcd из кластера. Если сейчас сервер обратится к инстансу etcd-1 для записи значения, а лидером будет, скажем, etcd2 (его endpoint мы явно не указываем в конфигурации Patroni), то etcd сам отдаст нужный endpoint лидера и, поскольку сетевая видимость между всеми членами кластера существует, работа системы не нарушится.Мы устанавливаем 2 тега в конфигурации:
nofailover: trueиnoloadbalance: true. Пока не планируется добавлять новые серверы в качестве target для load balancer, поэтому явно запрещаем им участвовать в гонке за лидерство.На новых серверах должны быть правильно определены параметры
data_dirиconfig_dir. Желательно, чтобы эти параметры не отличались от оригинальных значений. Возможна ситуация, когда в файлеpostgresql.base.confкто-то явно указал пути к этим директориям, и в момент бутстрапа новой реплики эти параметры приедут на новый сервер.Важно убедиться, что файл конфигурации
pg_hba.conf— одинаковый на всех узлах и содержит разрешающие правила для подключения как новых, так и старых серверов. Да, мы описываем эти правила вpatroni.yaml, но они используются только на этапе бутстрапа кластера. После этого добрый кто-то может изменить его, а Patroni не будет приводить его в соответствие своему конфигу… Это очень важный момент, с которым я столкнулся при реализации переноса.
Проверяем, что каталог /data/patroni — пустой и принадлежит пользователю postgres. Если это не так, то очищаем и устанавливаем нужные права:
root@new_server-1:~# rm -rf /data/patroni/*
root@new_server-1:~# chown -R postgres:postgres /data/patroniСтартуем Patroni и проверяем состояние кластера:
root@new_server-1:~# systemctl start patroni
root@new_server-1:~# patronictl -c /etc/patroni.yml list
Новая реплика — в состоянии running. Отлично!
Обратите внимание! При запуске Patroni он читает информацию из etcd и, если обнаруживает, что уже есть работающий кластер (а это наш случай!), пытается провести бутстрап от лидера. При этом используется pg_basebackup. Если существующая база — большая, может потребоваться много времени для завершения этой операции. Например, в реальном кейсе, который дал начало этой статье, была база объёмом в 2,8 ТБ, и её бутстрап занимал около 10 часов на гигабитном канале.
Также важно понимать, что в период бутстрапа мы создадим дополнительную нагрузку на сетевой интерфейс, поэтому для добавления новой реплики в кластер рекомендуется выбирать время минимальной нагрузки на БД.
Дождавшись, когда новая реплика завершила бутстрап, мы можем поочередно повторить процедуру для оставшихся серверов. После завершающей итерации должен получиться следующий результат:
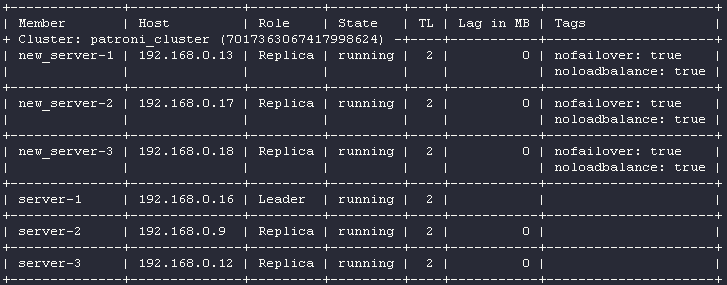
Важно! Каждый узел в кластере создает пассивную нагрузку на лидера, потому что по умолчанию подтягивает все изменения от него. Это значит, что если база испытывает большую сетевую нагрузку со стороны сервисов, то добавление сразу 3 реплик в кластер может сыграть злую шутку. Я наблюдал среднюю загрузку сетевого интерфейса лидера кластера ~500 Мбит/сек на исходящий трафик, когда в кластере было три члена. Добавление четвертого узла увеличило нагрузку, но явных пиков не было. Однако после добавления пятого узла ситуация изменилась: некоторые узлы начали отставать от лидера (параметр Lag in MB постоянно увеличивался). Причина проста: в этот момент нагрузка на сетевой интерфейс достигла максимума (1 Гбит/сек).
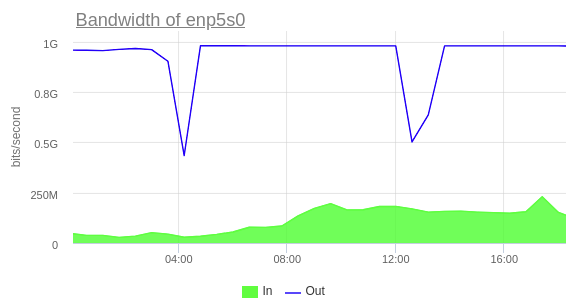
Решить эту проблему удалось, настроив каскадную репликацию, которая позволила бутстрапить новую реплику от уже существующей. Для реализации этого метода в конфигурации Patroni нужно установить на одну из существующих реплик специальный тег — clonefrom: true, а перед запуском бутстрапа новой реплики в её конфигурационном файле установить тег: replicatefrom: <название_узла>.
Если ваша production-база достаточно нагружена, после добавления новой реплики может быть полезным выключение одной из старых (эта операция рассматривается дальше — см. шаг №4) либо конфигурация каскадной репликации. Так будет поддерживаться общее количество реплик в стандартном количестве.
Отступление про балансировку
Так как у нас в схеме используется load balancer, то перед тем, как переходить к следующим шагам, стоит рассказать, каким образом он принимает решение, куда нужно отправить трафик.
Когда мы готовили конфигурацию Patroni, описывали следующий сегмент:
restapi:
listen: 192.168.0.13:8008
connect_address: 192.168.0.13:8008
authentication:
username: patroni
password: 'mynewpassword'Здесь указано, на каком интерфейсе и на каком порту будет работать Patroni API. Через API можно определить, является ли на данный момент узел leader’ом или replica’ой. Зная это, мы можем настроить health check для балансера так, чтобы в момент переключения лидера балансер знал, на какой target нужно переключить трафик.
Например: на картинке выше видно, что узел с адресом 192.168.0.16 (server-1) является лидером на данный момент. Отправим пару GET-запросов по следующим URL:
root@new_server-2:~# curl -I -X GET server-1:8008/leader
HTTP/1.0 200 OK
Server: BaseHTTP/0.6 Python/3.6.9
Date: Sun, 10 Oct 2021 11:40:38 GMT
Content-Type: application/json
root@new_server-2:~# curl -I -X GET server-1:8008/replica
HTTP/1.0 503 Service Unavailable
Server: BaseHTTP/0.6 Python/3.6.9
Date: Sun, 10 Oct 2021 11:37:57 GMT
Content-Type: application/jsonПолучили коды ответов 200 и 503 соответственно. Отправим ещё пару запросов в API сервера с Patroni, который не является лидером на данный момент:
root@new_server-2:~# curl -I -X GET new_server-1:8008/leader
HTTP/1.0 503 Service Unavailable
Server: BaseHTTP/0.6 Python/3.6.9
Date: Sun, 10 Oct 2021 11:41:14 GMT
Content-Type: application/json
root@new_server-2:~# curl -I -X GET new_server-1:8008/replica
HTTP/1.0 503 Service Unavailable
Server: BaseHTTP/0.6 Python/3.6.9
Date: Sun, 10 Oct 2021 11:41:17 GMT
Content-Type: application/jsonВ обоих случаях мы получили 503. Почему так? Потому мы использовали тег noloadbalance: true. Изменим значение этого тега на false на новых узлах и перезапустим Patroni:

А теперь попробуем ещё раз:
root@new_server-2:~# curl -I -X GET new_server-1:8008/leader
HTTP/1.0 503 Service Unavailable
Server: BaseHTTP/0.6 Python/3.6.9
Date: Sun, 10 Oct 2021 11:45:40 GMT
Content-Type: application/json
root@new_server-2:~# curl -I -X GET new_server-1:8008/replica
HTTP/1.0 200 OK
Server: BaseHTTP/0.6 Python/3.6.9
Date: Sun, 10 Oct 2021 11:45:44 GMT
Content-Type: application/jsonВсё корректно. Настроив health check для load balancer’а через Patroni API, мы можем распределять трафик на мастер-узел (для запросов на запись) и на реплики (для запросов на чтение). Это очень удобно.
В нашем случае использовался load balancer от облачного провайдера, и заниматься какими-то особыми настройками (помимо health check) не пришлось. Но в общем случае для балансировки можно использовать HAproxy в режиме TCP. Тогда его примерный конфиг будет выглядеть так:
global
maxconn 100
defaults
log global
mode tcp
retries 2
timeout client 30m
timeout connect 4s
timeout server 30m
timeout check 5s
listen stats
mode http
bind *:7000
stats enable
stats uri /
listen leader
bind *:5000
option httpchk
http-check expect status 200
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
server server_1 192.168.0.16:5432 maxconn 100 check port 8008
server server_2 192.168.0.9:5432 maxconn 100 check port 8008
server server_3 192.168.0.12:5432 maxconn 100 check port 8008Шаг №3. Донастраиваем кластер PostgreSQL
Вернемся к нашей реализации. Мы добавили новые реплики в кластер PostgreSQL. Теперь нужно разрешить всем членам кластера принимать участие в гонке за лидерство и добавить новые endoint’ы кластера в tagets у load balancer’а. Меняем значение тега nofailover на false и перезапускаем Patroni:

Добавляем в список targets для load balancer’а новые серверы и назначаем лидером сервер new_server-1:
root@new_server-1:~# patronictl -c /etc/patroni.yml switchover
Master [server-1]:
Candidate ['new_server-1', 'new_server-2', 'new_server-3', 'server-2', 'server-3'] []: new_server-1
When should the switchover take place [now]: now
Current cluster topology
Are you sure you want to switchover cluster patroni_cluster, demoting current master server-1? [y/N]: y
Successfully switched over to "new_server-1"
Шаг №4. Выводим серверы из кластера Patroni
Выведем server-1, server-2 и server-3 из кластера и уберем их из targets для load balancer’а — они своё отработали:
root@server-3:~# systemctl stop patroni
root@server-3:~# systemctl disable patroni
Removed /etc/systemd/system/multi-user.target.wants/patroni.service.
root@server-2:~# systemctl stop patroni
root@server-2:~# systemctl disable patroni
Removed /etc/systemd/system/multi-user.target.wants/patroni.service.
root@server-1:~# systemctl stop patroni
root@server-1:~# systemctl disable patroni
Removed /etc/systemd/system/multi-user.target.wants/patroni.service.Проверим состояние кластера:
root@new_server-1:# patronictl -c /etc/patroni.yml list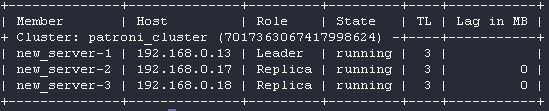
Остались только новые серверы. Мы почти закончили!
Шаг №5. Приводим в порядок кластер etcd
Последний шаг — разбираем кластер etcd:
root@new_server-1:~# etcdctl member list
40ebdfb25cac6924: name=etcd-2 peerURLs=http://etcd-2:2380 clientURLs=http://192.168.0.17:2379 isLeader=false
46d7a702fdb60fff: name=etcd1 peerURLs=http://etcd1:2380 clientURLs=http://192.168.0.16:2379 isLeader=true
6c2e836d0c3a51c3: name=etcd-3 peerURLs=http://etcd-3:2380 clientURLs=http://192.168.0.18:2379 isLeader=false
6d299012c6ad9595: name=etcd-1 peerURLs=http://etcd-1:2380 clientURLs=http://192.168.0.13:2379 isLeader=false
c32185ccfd4b4b41: name=etcd2 peerURLs=http://etcd2:2380 clientURLs=http://192.168.0.9:2379 isLeader=false
d56f1524a8fe199e: name=etcd3 peerURLs=http://etcd3:2380 clientURLs=http://192.168.0.12:2379 isLeader=false
root@new_server-1:~# etcdctl member remove d56f1524a8fe199e
Removed member d56f1524a8fe199e from cluster
root@new_server-1:~# etcdctl member remove c32185ccfd4b4b41
Removed member c32185ccfd4b4b41 from cluster
root@new_server-1:~# etcdctl member remove 46d7a702fdb60fff
Removed member 46d7a702fdb60fff from cluster
root@new_server-1:~# etcdctl member list
root@new_server-1:~# etcdctl member list
40ebdfb25cac6924: name=etcd-2 peerURLs=http://etcd-2:2380 clientURLs=http://192.168.0.17:2379 isLeader=true
6c2e836d0c3a51c3: name=etcd-3 peerURLs=http://etcd-3:2380 clientURLs=http://192.168.0.18:2379 isLeader=false
6d299012c6ad9595: name=etcd-1 peerURLs=http://etcd-1:2380 clientURLs=http://192.168.0.13:2379 isLeader=falseВсё! Переезд окончен! Итоговая схема взаимодействия выглядит следующим образом:

Заключение
В результате проведенных манипуляций удалось перевезти кластер PostgreSQL на базе Patroni на новое железо. И в целом весь процесс получился довольно предсказуемым, контролируемым — пожалуй, во многом это заслуга Patroni. Я постарался описать в статье все сложности и узкие моменты в конфигурации, с которыми столкнулся по ходу миграции. Надеюсь, что этот опыт будет кому-нибудь полезным.
Простой при переключении был минимальным: составил около 8 секунд и был обусловлен тем, что в момент переключения лидера health check нашего load balancer’а сделал три попытки (с интервалом в три секунды и таймаутом в две секунды) с целью убедиться, что leader действительно изменился. Сервис, обращающийся к базе данных, поддерживал переподключение, поэтому соединение было восстановлено автоматически. (А вообще, хорошим тоном при переездах является остановка всех подключений к отключаемому узлу.)
P.S.
Читайте также в нашем блоге:
«Обзор операторов PostgreSQL для Kubernetes»: часть 1 (наш опыт и выбор) и часть 2 (дополнения и итоговое сравнение);
«Мониторинг PostgreSQL. Расшифровка аудиочата Data Egret и Okmeter»;
«Postgres-вторник №5: PostgreSQL и Kubernetes. CI/CD. Автоматизация тестирования».

![[Личный опыт] «Кремниевая долина Европы»: что делает Берлин особенным в мире IT](/upload/resize_cache/iblock/5e6/105_70_0/5e6421a1841c4757f76b1d927f84ccb0.png "[Личный опыт] «Кремниевая долина Европы»: что делает Берлин особенным в мире IT")


