
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Привет, меня зовут Олег Свидченко, я — Chief Data Scientist. Работаю в ассоциации «Искусственный интеллект в промышленности» (с ноября мы - Ассоциация “Цифровые технологии в промышленности”). Если вы недавно перешли из крупной технологической компании в нефтегазовую или только планируете этот переход, либо слышали про машинное обучение только в теории, но у вас нет практики его применения в конкретных, особенно промышленных проектах, эта статья для вас.
Расскажу:
впечатления от перехода в нефтегазовую отрасль;
что такое ML и как происходит;
особенности применения ML и конкретные кейсы;
BigData в нефтегазовой промышленности;
нестандартные решения в промышленности;
процесс разработки решений на основе ML в нефтегазовых компаниях.
Как я пришёл в нефтянку из крупной IT-компании
Я пришёл в промышленность из JetBrains. Когда искал новое место работы, сперва рассматривал крупные IT-компании. Я решил, что мне будет неинтересно допиливать 0,1% к точности поиска. А в промышленности — непаханное поле, можно внедрять интересные технологии крупными мазками и решать задачи, которые еще не исследовались.
Меня пугали страшилками, что будет строгий дресс-код, жесткий график, неудобный офис и скучные проекты. Но на самом деле всё оказалось не так. Дресс-кода нет, рубашку я надевал лишь пару раз в год на супер-важные встречи. График тоже оказался гибким: можно спать до обеда, проснуться, сходить на встречу, которая привязана ко времени, а затем дальше лечь спать, чтобы ночью писать код.
Офис оказался классным и современным, как в любой IT компании. Здесь есть фрукты, кофе. Да и задачи — интересные. Многие думают, что в нефтянке приходится возиться в сложной физике, а машинное обучение почти не применяется. На самом деле это не так. Просто нужно понимать, как машинное обучение и математическая теория связаны с реальным физическим миром.
Единственный нюанс, с которым приходится сталкиваться — это долгие процессы и бюрократия. От этого сложно уйти, но мы обсудим, как выходить из этой ситуации в процессе разработки решений.
Что умеет машинное обучение?
В промышленности много сфер, где применимо машинное обучение и Computer Science.
Мы пытаемся построить алгоритм, в который можно поместить данные и получить решение задачи. Речь про модель, которая делает это на основе данных. Дальше мы увидим, что ключевой аспект и краеугольный камень машинного обучения — именно данные.
Этот подход отличается от классических алгоритмов тем, что мы не пытаемся строить решение исключительно на эвристиках. Хотя верим в статистику и математику, и располагая достаточно хорошими данными, загрузим их в алгоритм, и на выходе получим достаточно хорошее решение. А измеряем всё это при помощи различных метрик. Давайте выясним, в каких сферах в принципе применяется машинное обучение, помимо классического финтеха либо IT-индустрии, где с его помощью реализуют поиск или что-то оптимизируют.

Машинное обучение занимается предиктивной аналитикой, оптимизацией бизнес-процессов, поиском оптимальных решений, улучшением инфраструктуры для сотрудников компании и ещё много чем. Например, строить оптимальные планы-графики для проведения работ или предсказывать срок службы оборудования.
Особенно важны возможности, которые приносят value — предиктивный анализ и оценка рисков. Когда мы можем предсказать, что на производстве что-то пойдёт не так, например, сломается оборудование или возникнет дефект, эти риски можно снизить. Что в свою очередь снизит издержки, которые возникают при поломке или другом внештатном событии. В результате уменьшатся расходы и повысится общий MPV системы.
Улучшая внутреннюю инфраструктуру, мы повышаем привлекательность компании для потенциальных сотрудников и получаем доступ к более квалифицированным экспертам. Это помогает компании развиваться и расти.
Оптимизация решений позволяет ускорить их принятие. Когда для подбора оптимальных параметров, например, по капитальному строительству или логистике приходится тратить несколько месяцев на согласование, подбор, выбор расчёта, это долго, сложно, требует много времени и ресурсов. Использование искусственного интеллекта позволяет ускорить процесс принятия решения в десятки раз и сокращает расходы. ИИ помогает эксперту составить несколько оптимальных планов, и выбирать из них. Это важно ещё и потому, что современный мир быстрый и хочется, чтобы компания не отставала.
Ограничения ML
У машинного обучения есть ряд ограничений, преимущественно связанные с данными.
Потребность в данных — базовая. Без данных машинное обучение невозможно. Если у вас нет данных, придётся посадить команду из физиков и математиков, чтобы они следили за бизнес-процессом, вручную выписывали формулы и придумывали эвристики. Если у вас достаточное количество данных, вы можете применить машинное обучение и сэкономить время, силы, ресурсы, возможно, получить более эффективный результат.
Есть хороший пример из прошлого: машинный перевод начинался как эвристическая область. Множество лингвистов тогда придумывали правила, по которым производится перевод, писали сложные алгоритмы. А потом пришло машинное обучение с анализом естественных языков и решило эту задачу лучше и быстрее лингвистов.
В нефтегазовой промышленности также: вы можете попытаться построить сложные эвристические алгоритмы для сложных задач, но, лучше применить машинное обучение, если для этого есть нужные данные.
Данные должны быть качественные и обычно их должно быть много. Скорее всего, вы не можете применить машинное обучение из коробки, если у вас данных за неделю — пара десятков примеров. Так не работает. Данных требуется много. Совет для тех, у кого данных сейчас нет — изобретите машину времени, переместитесь в прошлое лет на 5 назад, и начинайте собирать. По большинству бизнес-процессов данные нужно собирать долго. Например, если хочется оптимизировать обработку технических отчетов или аудита, то потребуются данные за несколько лет. Ведь такие отчеты формируют не очень часто. Раз в месяц — это еще оптимистичная история. В результате за год для построения модели наберётся слишком мало данных.
Для решения задачи нужно погружение в предметную область. Вряд ли человек сможет решать бизнес задачу в вакууме, не погрузившись в бизнес-процесс. Когда в компанию приходит дата-сайентист, нужно погрузить его в бизнес-процесс, для которого он должен построить решение. Например, чтобы работать с отчётной документацией, нужно понимать, откуда она берётся и зачем нужна. И это ещё не самый специфический для отрасли пример. Техническая документация и многие другие кейсы потребует действительно глубоко погрузиться в применяемые технологии и специфику их работы. А предиктивная аналитика и оптимальное погружение в то, как работает сложная система, часто требуют глубокого в неё погружения.
Особенности ML в нефтегазе
BigData в нефтегазе. Спойлер: нефтегаз не про BigData.
В нефтегазе, конечно, много данных, но для большинства бизнес-процессов их недостаточно. BigData — это несколько терабайт данных, причем хорошо структурированных и качественных.
Лишь в некоторых бизнес-процессах нефтегаза есть большие данные:
показания датчиков;
видеоаналитика;
внутренние технические сервисы.
Там, где есть BigData, можно обучить серьезную нейронную сеть и получить результат. Например, определять на видеоаналитике, что происходит на рабочей площадке, чтобы выявлять потенциальные угрозы безопасности и предотвращать ЧП.
В остальных областях приходится изобретать велосипед. И это точно не нейронные сети, поскольку данных на них просто не хватит.
В большинстве процессов больших данных нет:
техническая документация;
юридическая практика;
HR;
капитальное строительство;
разработка месторождений.
Если бы 10 лет назад по ним начали собирать структурированные данные, то сейчас можно было применять более сложные методы машинного обучения. Поэтому давайте начинать собирать — вперёд к светлому будущему!
Если больших данных нет, а очень хочется применять нейросети можно:
Генерировать и использовать синтетические данные, цифровые двойники.
Использовать аугментации. Можно использовать модификации уже существующих данных. Например, добавлять искусственный шум в изображения, использовать зеркальное отображение, и т.д.
Регламентировать сбор данных и ждать. Если из перечисленного ничего не подходит, нужно регламентировать сбор данных и лет 5 подождать, а потом применить машинное обучение. За это время, другие компании уйдут вперед, но зато у вас появится машинное обучение.
Использовать классические методы машинного обучения. Если какие-то данные есть, но их не много, можно применить классическое машинное обучение. Естественно, круг задач, которые оно решает без глубокого обучения, несколько уже, но, это лучше, чем ничего.
Особенности данных
В отличие от больших IT-компаний, в которых данные — это, скорее всего, какие-то логи и пользовательские заявки, в нефтегазе это, как правило, не так:
Очень часто данные разнородны, даже если есть четкий шаблон, как они должны оформляться.
Часто данные не структурированы.
Данные могут быть неполными и не содержать нужной информации.
Со всем этим приходится как-то жить. Но давайте перейдём к конкретным примерам.
Задача 1
Разработать алгоритм и составить по нему оптимальный план проведения работ по обустройству месторождения.
Например, построить дома, инфраструктуру, провести трубопроводы, то есть построить месячно-суточный план-график.
Цели:
Оптимизировать время и/или ресурсы. Возможно, сделать условную оптимизацию с ограничениями.
Добиться консистентности плана. То есть мы не начинаем строить крышу до тех пор, пока не возвели стены, иначе ничего не получится.
Прогнозировать затраты ресурсов — сколько людей и техники нам потребуется, в какие даты, и т.д.
Выглядит это так (в таблице приведены синтетические данные):
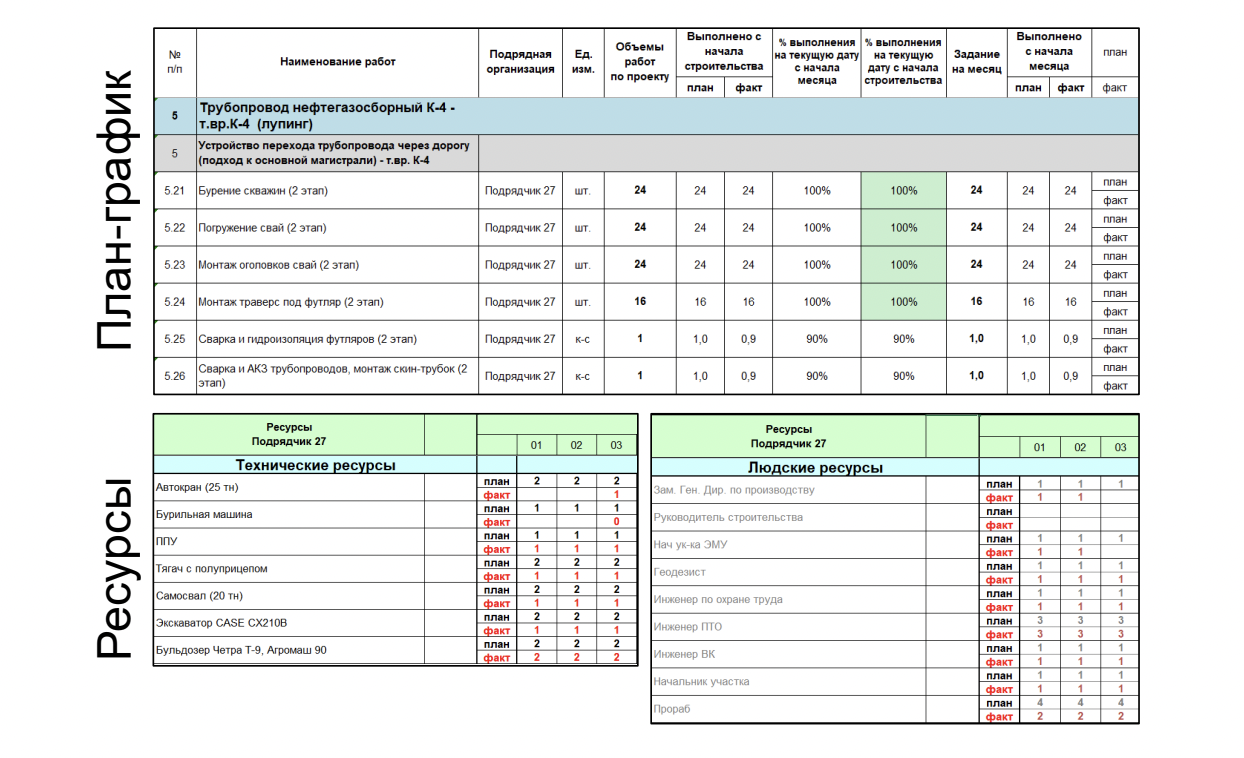
Таблица с план-графиком, в котором указаны и пронумерованы названия работ, содержит несколько столбцов с суточными нормами, в какой день, что выполняется. Это и есть план внутри месяца. Также есть несколько таблиц с техническими и человеческими ресурсами, где указаны конкретные позиции и сколько ресурсов потребовалось.
Обращаю внимание, что в таблице нет никаких связей. Мы знаем, сколько за месяц потрачено ресурсов, какие работы проведены, а к какой работе какой ресурс относится, не знаем. Нужно научиться это предсказывать. Более того, важно понимать, что один и тот же вид работ можно выполнять с разным набором ресурсов. Но стоимость тоже будет разная, потому что ресурсы и сроки будут различаться. Эти связи предстоит восстановить, но как это сделать — непонятно.
Начав работать как с историческими данными, так и с реальными план-графиками, понимаешь, что просто взять и использовать их в машинном обучении нельзя. Кроме отсутствия связей, отличаются форматы оформления.
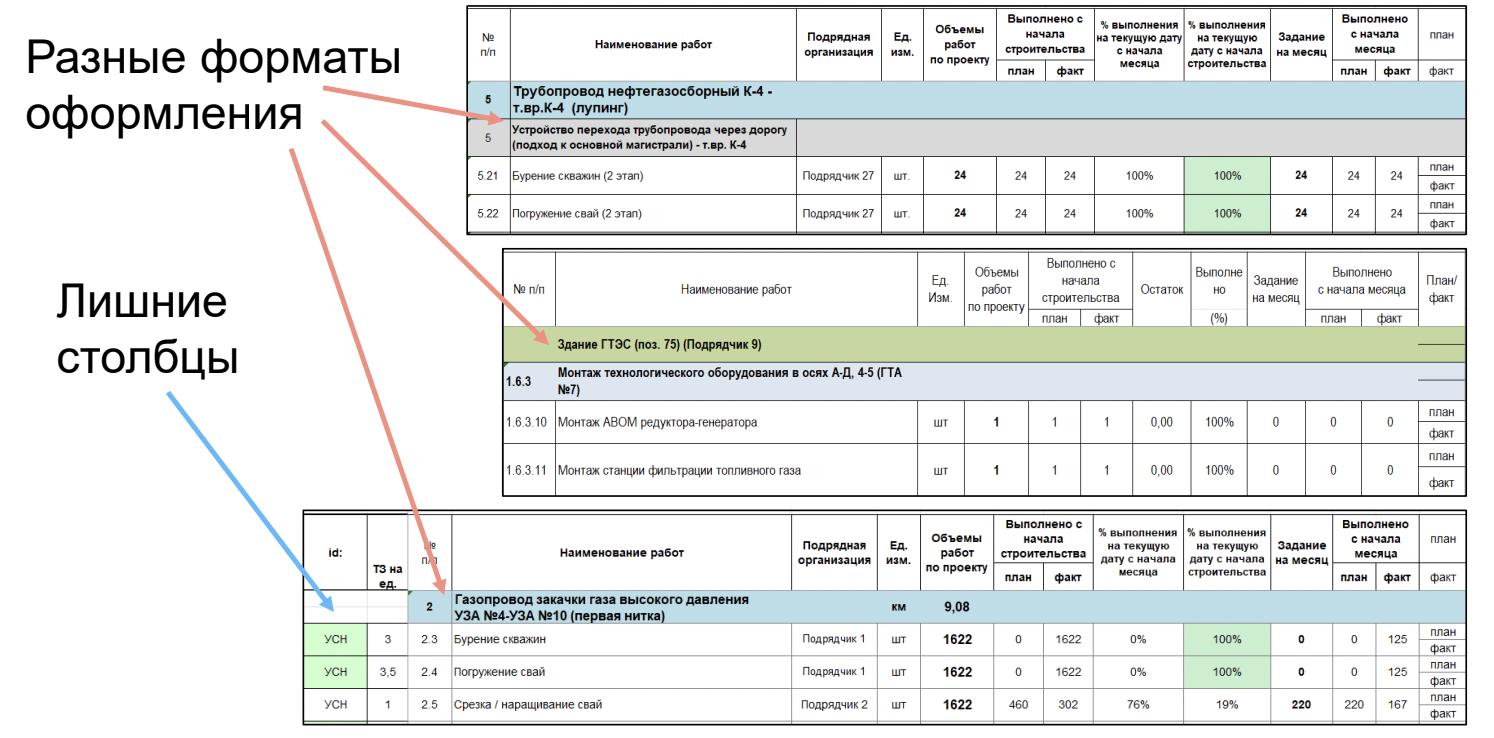
Может меняться нумерация, добавляться новые строки в заголовки групп работ или новые столбцы, меняться названия работ. Например, в одной таблице написано «Бурение скважин», а в другой — «Бурение скважин. Этап 2». По факту, это одна и та же работа — бурение скважин. Но кто-то решил добавить, что это второй этап. В итоге с точки зрения машинного обучения это две разные работы, потому что данные категориальны.
Очевидно, что таких данных много и заставлять людей преобразовывать их в единый формат — нереально. Придётся писать парсеры. В больших IT-компаниях таких ситуаций, скорее всего, нет, потому что там хорошо структурированные логи и чётко описанный формат, как эти логи должны выглядеть. В нефтянке бывает в таком виде, потому что таблицы заполняют люди, а на местах всегда лучше знают как нужно, несмотря на общий регламент.
Решение
Автоматизация парсинга план-графиков в единый формат. Естественно, мы составили большой сложный парсер, который охватывает все возможные случаи, как люди могут изменить таблицу. Парсеры преобразуют всё в единый формат, чтобы с этим можно было работать. Работа над парсерами заняла у нас несколько недель. Большую часть времени мы пытались выловить все возможные случаи, как люди могут поменять таблицы. Делали это вручную, вникая в результаты парсинга и корректируя алгоритм. Итераций было много — мы их даже не считали.
Использование методов NLP и кластеризации для выделения сущностей. Отдельный объёмный и сложный пласт работ — объединение работ в общие сущности, ведь названия как только не меняли и не коверкали. Пришлось использовать методы анализа языков и кластеризации, чтобы выделить сущности.
Байесовские сети для определения соответствия ресурсов работам. Все связи между ресурсами и работами восстанавливались с помощью Байесовских сетей, не путать с Байесовскими нейронными сетями, отдельным видом алгоритмов.
Эволюционные алгоритмы с эвристиками для оптимизации. Оптимизировать данные можно с помощью эволюционных алгоритмов. Многие считают, что эволюционные алгоритмы устарели, но эту задачу они решают.
Рассмотрим другую задачу, для решения которой эволюционные алгоритмы не работают.
Задача 2
Необходимо определить оптимальное расположение нефтедобывающих скважин нерегулярного фонда с учетом параметров гидродинамической модели.
Обычно скважины размещаются регулярной сеткой с некоторым шагом. Количество оптимизируемых параметров в этом случае не большое, соответственно, оптимизацию провести вполне реально.
Проблемы начинаются, когда мы пытаемся разместить нерегулярный фонд, то есть, расставить скважины практически произвольным образом, чтобы максимизировать добычу.
Симуляция гидродинамической модели для оценки качества размещения происходит медленно. Вы не можете проверить много разных расстановок, потому что подсчёт лишь одной займёт от нескольких десятков минут до нескольких часов. Это причина, почему эволюционные алгоритмы тут не подойдут.
Реальных параметров гидродинамической модели мало. Месторождений не так много, соответственно, разных реальных параметров гидродинамической модели — тоже. В результате приходится работать с синтетикой.
Гидродинамическая модель — сложная система. Классические методы машинного обучения тут не подойдут.
Нестандартные решения
Это тепловая карта — вид сверху среза гидродинамической модели по проницаемости.

Здесь каждый параметр представлен в виде трёхмерной тепловой карты. Фактически это трехмерный кубик, нарезанный на кусочки — как двумерная координатная сетка. Таких тепловых карт можно составить много — проницаемость, пористость, насыщенность и пр.
Вышки задаются конкретными координатами. Понятно, что скважины бывают не только вертикальные, но и горизонтальные. Попробуем решить задачу хотя бы с вертикальными и тогда поймём, что делать с горизонтальными.
Итоговое качество оценивают при помощи симуляции, потому что без неё непонятно, как определить, насколько хорошее размещение.
Поскольку эволюционные алгоритмы не подходят, мы сделаем это при помощи обучения с подкреплением. Это подобласть машинного обучения, которая фокусируется на взаимодействии с некоторым окружением.
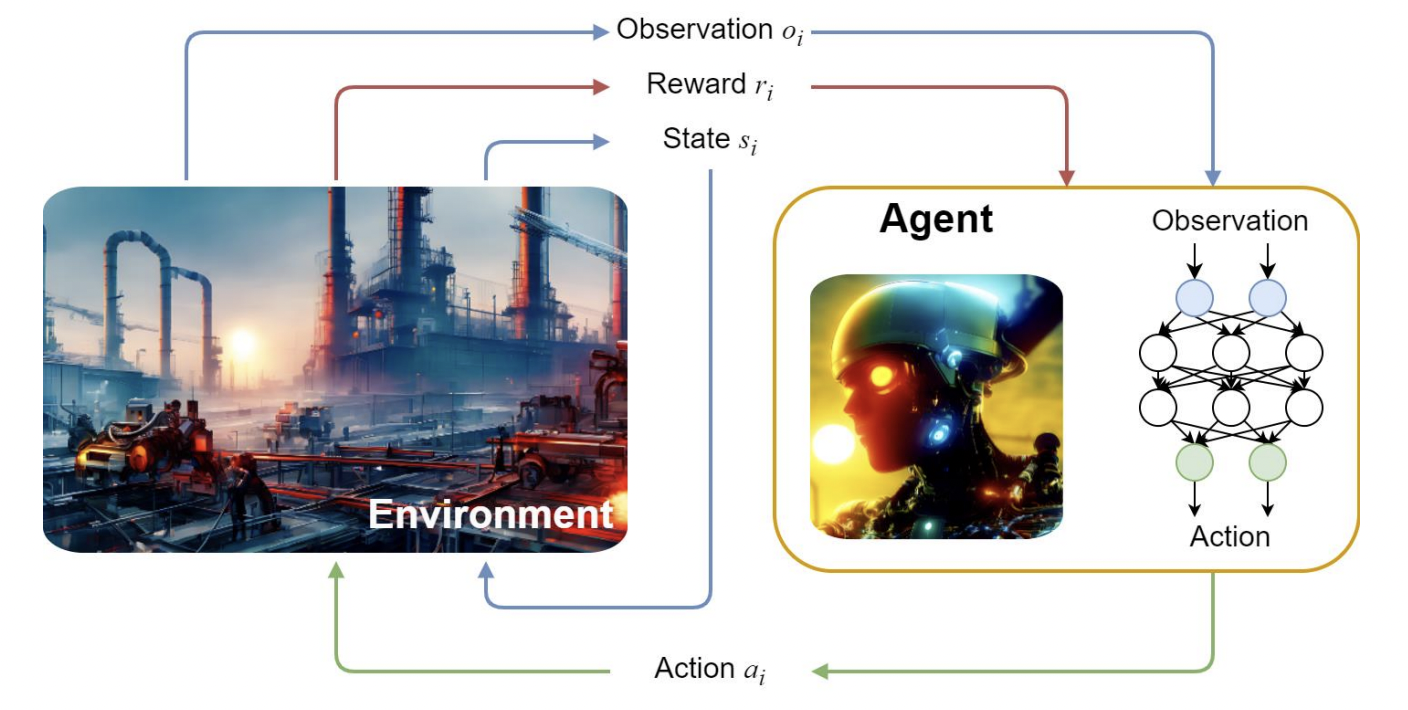
В этом случае окружение — наша симуляция, а её состояние будет отображать текущее состояние гидродинамической модели с учётом всех параметров вышек — где находится нефть, какое давление и т.д., Принимающим решение агентом станет сама модель, которую мы обучим в ML. Она будет совершать действия, в данном случае — размещать скважины. В награду за размещение скважин агент получит изменение метрики Если мы повысим количество добываемой нефти, то награда — положительная. Если наоборот — отрицательной.
Заметим, что метрику можно менять, как захочется. Она может быть экономической или физической.
Раз уж мы заговорили про обучение с подкреплением, давайте поговорим про наивное решение.
Наивное решение
Мы выбрали обучение с подкреплением для решения задачи. Давайте каждую вышку задавать координатами на сетке — двумя вещественными числами.
Возьмём классический алгоритм обучения с подкреплением, умеющий работать с вещественным пространством действий, и попробуем применить его из коробки, как есть:
Proximal Policy Optimization.
Deep Deterministic Policy Gradient.
Soft Actor-Critic.
Ничего не заработает, потому что задача сложная, и алгоритмы из коробки не помогут её решить. А ещё у таких алгоритмов есть проблемы:
Отсутствие масштабируемости на инференсе. Гидродинамическая модель пласта может быть разных размеров. Для каждого месторождения — своя. Хотелось бы не переобучать наше решение для каждого размера модели. В идеале должно быть одно и то же решение для пластов разных размеров. А наивные решения не позволяют организовать хорошую масштабируемость на инференсе. Даже при обучении модель масштабируется достаточно плохо.
В целом работает так себе. Можно сделать вывод, что не надо применять обучение с подкреплением для таких задач. Но лучше вместо классического алгоритма с непрерывным пространством действий, придумать новое решение.
Работающее решение
Давайте используем обучение с подкреплением для решения задачи, но кардинально изменим пространство действий.
Пространство действий – координатная дискретная сетка. Вместо непрерывного пространства действий, где скважина задавалась двумя вещественными координатами, мы поделим всю координатную плоскость сеткой, то есть сделаем сетку с дискретными действиями.
За основу берём алгоритм Dueling Deep Q-Network.
Используем архитектуру UNet для обучения модели. Так у нас сохранится семантика действий, будем использовать архитектуру UNet.
Аргументируем данные — это увеличит количество данных в 8 раз.
Выглядит это примерно так:
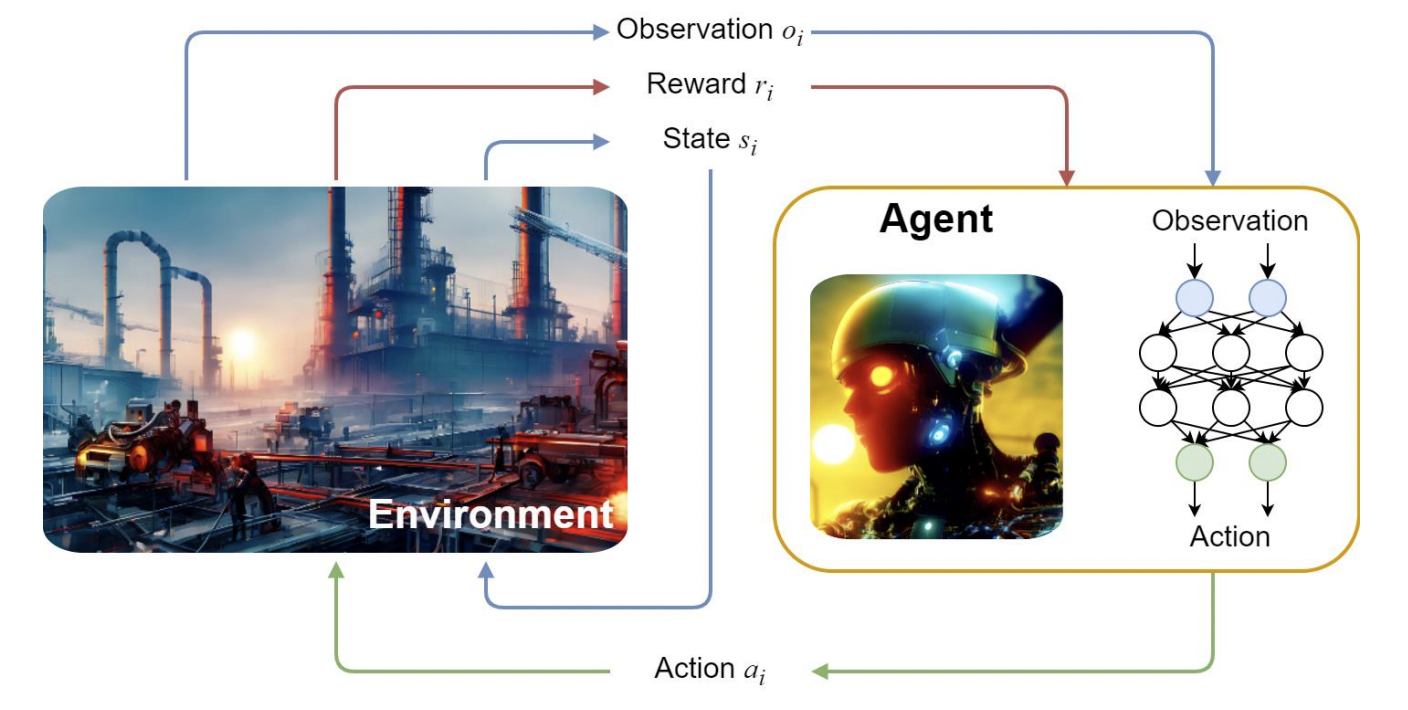
Желтым отмечена свёрточная сеть, есть skip connections. Важно, что на входе,и выходе — тепловая карта. Фактически это координатная сетка, где каждой ячейке соответствует, насколько выгодно ставить скважину именно в этот участок или ячейку. Для обучения возьмем кусочек полносвязной сети. На инференсе нужна желтая часть, ведь она будет отлично масштабироваться. В результате можно поменять размер входных данных, и такого же размера будет тепловая карта на выходе. На неё можно ориентироваться при выборе места для скважины.
Мы обсудили кейсы и нестандартные подходы к их решению, потому что стандартные, чаще не работают. Теперь поговорим про долгие процессы и как их можно обходить.
Бюрократия против Agile
Есть бюрократия и гибкие методологии.
В бюрократическом мире больших промышленных компаний много времени и внимания тратится на утверждения и документацию. Из-за этого процессы очень-очень долгие. А разработчики привыкли к гибким подходам разработки. Вместо большого количества документации и согласований можно использовать таск-трекеры и обсуждение внутри команд. Поговорил с тимлидом 5 минут, он утвердил решение и ты пошёл делать фичу. Не нужно месяц ждать согласования и апрува на всех уровнях иерархии.
Важно найти рабочее решение — неважно, в машинном обучении или разработке. А согласование лучше проговорить голосом, чем документировать. В отличие от бюрократии, где месяцами можно ждать ответа, при гибких методологиях есть спринты, которые длятся неделю, и за это время вы успеваете сделать очень много.
Давайте посмотрим как в этом мире противоречий и бюрократии живёт гибкая методология.
КИП, НИОКР и ЦП
Бюрократия управляет всем сверху, это может выглядеть так:
Естественно, это не единственный формат организации. А вот что по срокам:
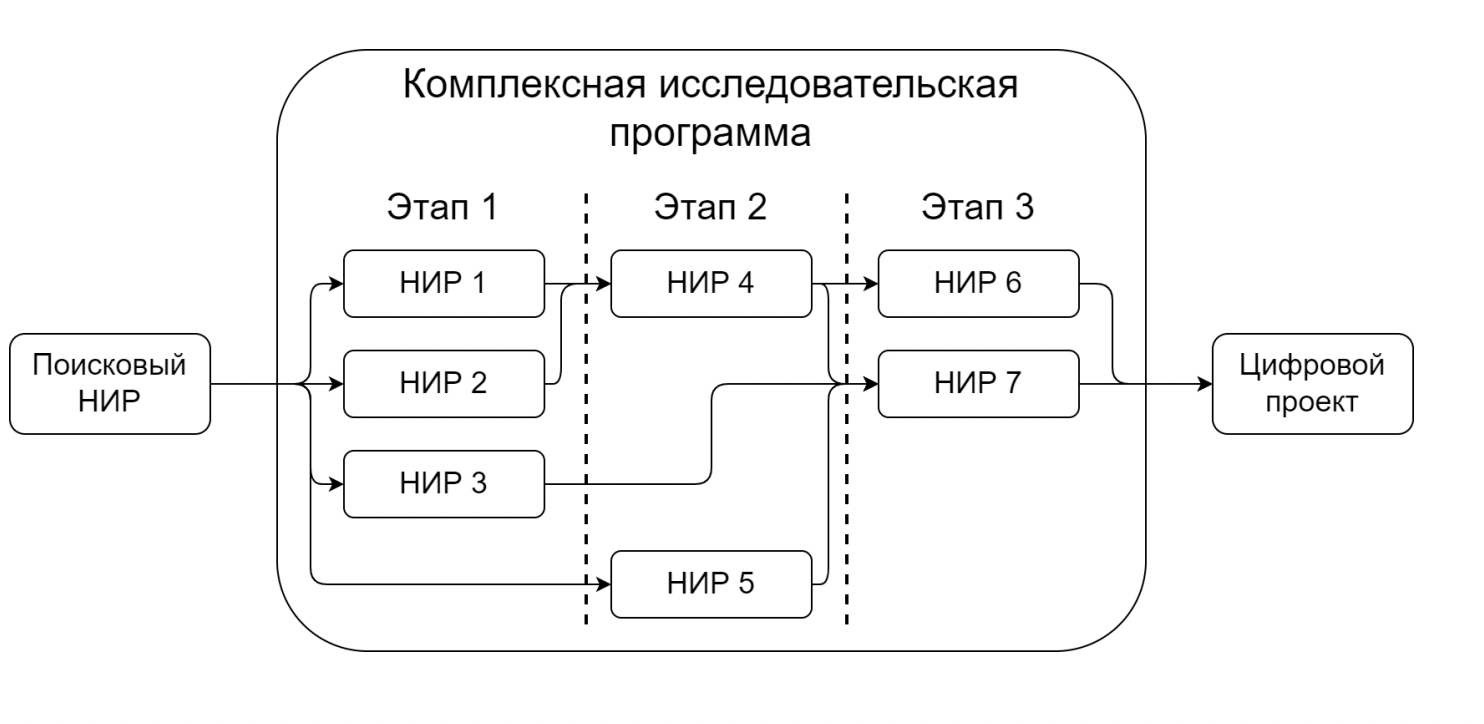
КИП (1.5 – 2 года) — комплексно-исследовательская программа, общее направление разработки и исследований, которое делится на несколько этапов.
НИР/НИОКР (3 – 6 мес.) — научно-исследовательские работы/ научно-исследовательские и опытно-конструкторские работы, проект в рамках этапа КИП.
Спринт (1 неделя) — одна итерация в рамках НИР.
Создадим комплексно-исследовательскую программу и сообщим, что нам нужна технология, которая умеет глобально решать следующие задачи. Разобьем программу на несколько этапов и отметим, что именно нужно сделать на каждом. КИП длится несколько лет, каждый этап — 3-6 месяцев. В рамках каждого этапа уже есть отдельные НИРы и НИОКРы, которые позволяют решить конкретную небольшую задачу. Они длятся столько же, сколько этап. Внутри каждого НИОКРа живёт Agile со спринтами.
Внутри НИОКРов живут разработчики, и там они чувствуют себя комфортно — ведь используются гибкие методологии. Бюрократическая часть разработчикам, как правило, не видна. Её видят менеджеры и лиды команд разработчиков, но с этим можно жить.
Перед КИП начинается поисковая научно-исследовательская работа, чтобы спланировать программу, а потом, когда продукт катится в прод, стартует цифровой проект. В результате на выходе получаем готовое продуктовое решение для компании. Такая система позволяет эффективно работать в мире бюрократии.
Вывод
Существует популярное мнение, что разработка в нефтянке — это бюрократия, строгий дресс-код и отсутствие интересных задач. На самом деле это совсем не так: задачи интересные, особенно с использованием ML, надевать костюм не требуют, а бюрократию можно победить, по крайней мере, на уровне программистов.
Главная проблема машинного обучения в нефтяной промышленности — нехватка данных, но тем интереснее находить выход из этой ситуации. В этой статье мы рассмотрели два кейса, когда данных не хватает, а построить модель — нужно. И рассмотрели, как именно это можно сделать. Если вы тоже жаждете решать интересные задачи нетривиальными способами — добро пожаловать в нефтянку.

")


