
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Любая программа состоит из данных и алгоритмов их обработки. Для написания программ на C++ в начале 90-х годов прошлого века Александр Степанов с коллегами разработал библиотеку STL. Я, Михаил Полукаров из команды разработки VK Teams, заглянул под капот этой библиотеки чтобы разобраться, как правильно ей пользоваться, в каких случаях лучше использовать другие библиотеки, а в каких стоит написать что-то своё.
В первую очередь я поделюсь своим опытом «граблей и багов STL», а также расскажу о почёрпнутом на бескрайних просторах интернета чужом опыте. В перспективе такие знания помогут не только решать поставленные задачи, но и делать это максимально эффективно.
Немного об STL
Эта библиотека была задумана как набор универсальных структур данных и алгоритмов, избавляющий программистов от бесконечного написания собственных велосипедов. Один из основных принципов, заложенных в STL разработчиками — максимальная гибкость и обобщённость. Например, алгоритму сортировки не важно, что именно сортировать — числа, строки или плюшевых медвежат. Единственное условие: тип данных, с которым работает алгоритм, должен поддерживать операцию сравнения.
Библиотека получилась настолько удачной, что практически сразу стала частью стандарта С++. Это исключительно важно — на всех платформах, которым доступен С++, код с STL работает автоматически, без внесения изменений. Для команды разработки VK Teams это несомненное преимущество. Нашим продуктом пользуется как VK, так и внешние заказчики, которые предъявляют собственные требования к ПО, поэтому код должен запускаться и работать на разнообразных платформах, включая Windows, Linux и MacOS.
За прошедшие 30 лет STL расширяли, улучшали и тестировали, и на текущий момент это одна из самых надёжных и высокопроизводительных библиотек, доступных для языка С++.
Однако, у любого решения есть свои достоинства и недостатки. В случае с STL достоинство обернулось недостатком . Это не серебряная пуля, она решает задачи максимально эффективно, но только в «среднем» случае. Тем не менее, это полностью соответствует изначальному замыслу авторов — предоставить набор только базовых примитивов, на основе которых можно создавать более конкретные и сложные реализации для конечного продукта.
Поскольку библиотека является частью стандарта, надо понимать, как он влияет на STL. Дело в том, что стандарт языка С++ разрабатывает не один человек или компания, а целая международная организация, в которую входят лучшие программисты со всего света. Пожалуй, по этой причине стандарт в части STL регламентирует не подробности реализации алгоритмов или структур данных, а только общий интерфейс и теоретические оценки трудоёмкости или потребления памяти. В результате, каждый поставщик компилятора волен реализовывать структуры данных и алгоритмы как хочет, часто со своими неочевидными особенностями и багами.
Исторически существует несколько реализаций, которые многие вендоры используют как основу для создания собственных:
HP — фактически, референсная реализация самого А. Степанова;
Dinkumware — легла в основу STL от Microsoft;
SGI — легла в основу GCC.
Рассмотрим эти реализации и то, как в них работают ключевые элементы.
Хеш-таблицы
Существует много способов внутреннего представления этого класса структур данных: separate chaining, open addressing и многие другие. Они связаны в первую очередь с основной проблемой любой хеш-таблицы — разрешением коллизий. Хотя стандарт не регламентирует конкретный способ, он задаёт другие ограничения, например, container traversal и iterator invalidation. Они не позволяют использовать никакой другой способ кроме separate chaining. Но даже в таких условиях реализации GCC и Microsoft разительно отличаются.
Прямая реализация
Давайте для начала рассмотрим самый наивный и прямолинейный способ реализации:
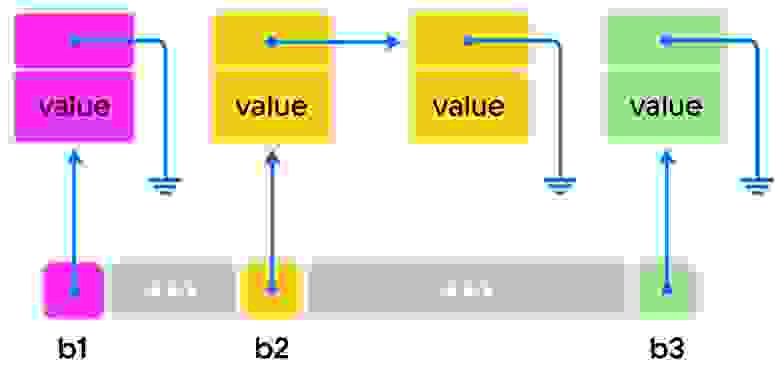
В этой структуре данных каждый bucket указывает на односвязный список элементов, оканчивающийся нулем. Если хэш-функция работает должным образом, то количество элементов в каждом bucket`е лишь изредка превышает предопределённый фактор загрузки, поэтому временна̒я сложность вставки и удаления элементов в среднем составляет O(1).
На рисунке выше bucket`ы b1 и b3 содержат по одному элементу, а bucket b2 — два элемента. Эта структура проста и эффективно использует память, но аналогичные контейнеры C++ не могут работать с ней напрямую. Контейнеры должны иметь возможность обходить все элементы, то есть предоставлять такой тип итератора, который может проходить через все элементы контейнера в диапазоне [c.begin(), c.end()).
Каким же образом итератор может реализовывать переход, скажем, из b1 в b2? Очевидное решение — сканирование массива bucket`ов до тех пор, пока не будет найден следующий непустой bucket — не сработает. Среднее время выполнения этой операции увеличивается по мере роста массива bucket`ов, и необходимо пройти больше buket`ов, чтобы добраться до следующего элемента. А стандарт требует, чтобы сложность перехода к следующему элементу для итератора составляла O(1). Приходим к выводу, что такой подход не применим, потому что нужно как-то связывать элементы соседних bucket`ов.
Реализация Microsoft
Вот как решает описанную выше проблему реализация STL в Microsoft Visual Studio C++. Их хеш-таблицы построены по следующему принципу:
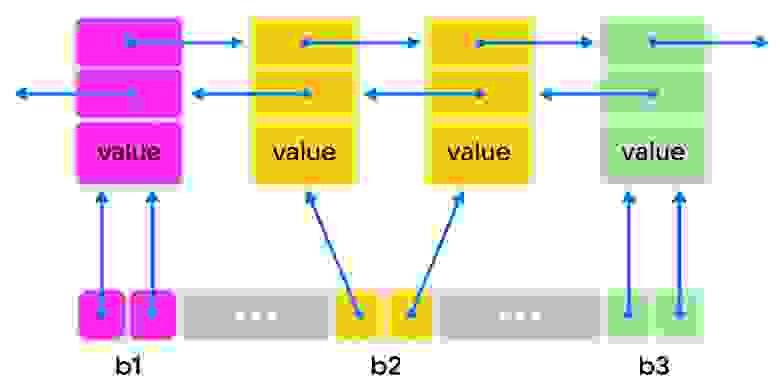
Внутреннее представление. В данном случае используется двусвязный список, что избыточно. Однако такая реализация позволяет выполнять двунаправленную итерацию (из начала в конец и наоборот) благодаря ещё одному указателю на элемент. И, что более важно, чрезвычайно упрощает удаление элементов.
Способ вычисления индекса в массиве bucket`ов. Для этого используется наложение битовой маски, полученной из длины массива bucket`ов, на результат хеш-функции от вставляемого ключа. Такой способ вычисления требует, чтобы размер bucket`ов всегда был кратен степени 2, из-за чего таблица при превышении фактора загрузки всегда увеличивается в два раза.
Для большей наглядности приведу код (упрощён для облегчения понимания) функции unordered_map::find():
template <class _Keyty>
iterator find(const _Keyty& _Keyval) {
return _List._Make_iter(_Find(_Keyval,_Traitsobj(_Keyval)));
}Обратите внимание, что _Traitsobj(_Keyval) здесь вычисляет значение хеш-функции от ключа и передаёт это значение далее во внутренний метод _Find(). Копнём поглубже, заглянем в сам _Find() и, преодолев несколько уровней вложенности, увидим такой код:
template <class _Keyty>
_Nodeptr _Find_first(const _Keyty& _Keyval, const size_t _Hashval) const
{
const size_type _Bucket = _Hashval & _Mask;
_Nodeptr _Where = _Vec._Mypair._Myval2._Myfirst[_Bucket << 1]._Ptr;
// ... rest of the code ...
}Код говорит сам за себя, остаётся только понять, какие значения принимает переменная _Mask. Немного поискав, находим такой код
const unsigned long _Max_storage_buckets_log2 = _Floor_of_log_2(static_cast<size_t>(_Vec.max_size() >> 1));
const auto _Max_storage_buckets = static_cast<size_type>(1) << _Max_storage_buckets_log2;
_Buckets = static_cast<size_type>(1) << _Ceiling_of_log_2(static_cast<size_t>(_Buckets));
_Mask = _Buckets - 1;Теперь хорошо видно что на хэш-значение от ключа накладывается битовая маска _Mask размера 2n-1 на хеш-значение от ключа. Фактически это не отличается от операции взятия модуля, но ускоряет вычисления за счёт своей простоты и использования только побитовых операций.
Перерасход памяти для хранения одного элемента. Посчитаем его с учётом идеального заполнения хеш-таблицы: два указателя в двусвязном списке + два указателя в массиве bucket`ов — получается четыре указателя на каждый элемент.
Реализация GCC и Clang
Подход в GCC и Clang, за исключением незначительных подробностей реализации, одинаков и основан больше на классической модели, рассмотренной выше:
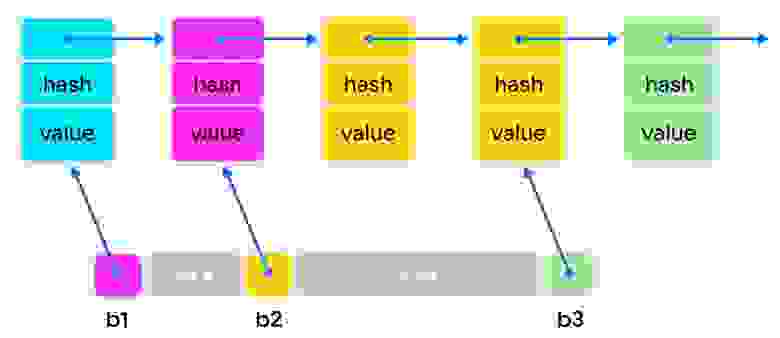
Внутреннее представление. Чтобы удовлетворить требованиям, регламентированным стандартом, используется интересный трюк: указатели в массиве bucket`ов ссылаются на последний элемент от предыдущего bucket`а в односвязном списке элементов.
Хеш-значения. В каждом элементе односвязного списка может храниться вычисленное хеш-значение от ключа. Это ещё один довольно сложный и хитрый трюк: используя type traits (характеристики типа) для ключа мы можем определить, нужно ли дополнительно хранить хеш-значение в узле односвязного списка.
Исходный код для основных характеристик можно найти в include/bits/functional_hash.h:
// Hint about performance of hash functor. If not fast the hash-based
// containers will cache the hash code.
// Default behavior is to consider that hashers are fast unless specified
// otherwise.
template<typename _Hash>
struct __is_fast_hash
: public std::true_type { };
template<>
struct __is_fast_hash<hash<long double>>
: public std::false_type { };По умолчанию для простых фундаментальных типов ключа вроде целочисленных хеш-функция определена так, что она возвращает сам ключ, и нет необходимости тратить дополнительную память на это поле. Для пользовательских же типов используется дополнительное поле, хранящее хеш-значение:
template<typename _Tp, typename _Hash>
using __cache_default
= __not_<__and_<// Do not cache for fast hasher.
__is_fast_hash<_Hash>,
// Mandatory to have erase not throwing.
__is_nothrow_invocable<const _Hash&, const _Tp&>>>;Результат __cache_default вычисляется во время компиляции, и результирующая константа далее передаётся в структуру узла хеш-таблицы, в шаблонный аргумент _Cache_hash_code, который определён следующим образом:
/**
* Primary template struct _Hash_node.
*/
template<typename _Value, bool _Cache_hash_code>
struct _Hash_node;
/**
* Specialization for nodes with caches, struct _Hash_node.
*/
template<typename _Value>
struct _Hash_node<_Value, true> : _Hash_node_value_base<_Value>
{
std::size_t _M_hash_code;
_Hash_node*
_M_next() const noexcept
{ return static_cast<_Hash_node*>(this->_M_nxt); }
};
/**
* Specialization for nodes without caches, struct _Hash_node.
*/
template<typename _Value>
struct _Hash_node<_Value, false> : _Hash_node_value_base<_Value>
{
_Hash_node*
_M_next() const noexcept
{ return static_cast<_Hash_node*>(this->_M_nxt); }
};Такой подход в первую очередь влияет на операцию перехеширования, когда необходимо увеличить или уменьшить массив bucket`ов и переразместить все элементы. В этом случае, если хеш-значение хранится вместе с самим элементом, не нужно вычислять хеш-функцию для каждого элемента заново:
std::size_t
_M_bucket_index(const _Hash_node_value<_Value, false>& __n,
std::size_t __bkt_count) const
{
return _RangeHash{}(_M_hash_code(_ExtractKey{}(__n._M_v())), __bkt_count);
}
std::size_t
_M_bucket_index(const _Hash_node_value<_Value, true>& __n,
std::size_t __bkt_count) const
{
return _RangeHash{}(__n._M_hash_code, __bkt_count);
}В этом отличие от реализации Microsoft, где хеширование выполняется всегда. Такой подход увеличивает производительность в случае использования, например, строк в качестве ключа, так как трудоемкость вычисления хеш-значения от строки, очевидно, зависит от длины самой строки.
Увеличение самого массива bucket`ов. В отличие от реализации Microsoft увеличение происходит не в два раза, а с округлением до ближайшего простого числа. Такое поведение выбрано по умолчанию, поскольку простые числа позволяют использовать как можно больше бит хеш-значения при вычислении индекса в массиве bucket`ов — это позволяет равномернее его заполнить.
У такого подхода есть и очевидный недостаток: нельзя использовать побитовые операции. Вместо них доступно относительно медленное деление по модулю простого числа. Эта низкоуровневая операция может быть оптимизирована как самим компилятором, так реализацией инструкций в процессоре, но в общем случае мы не можем полагаться на это.
Настройки аспектов работы хеш-таблиц. Некоторые аспекты работы хеш-таблицы, например, способ увеличения массива bucket`ов или замешивание хеш-значений, могут быть настроены отдельно. Для этого существуют шаблонные параметры — так называемые политики (policy-based подход), причем можно использовать пользовательские типы политик. С одной стороны, это усложняет реализацию, но с другой — получается намного гибче, чем реализация Microsoft. Внутри класса unordered_map<> находится определение внутреннего типа, который принимает шаблонные аргументы политик. Вот как выглядит это объявление:
template<typename _Key,
typename _Tp,
typename _Hash = hash<_Key>,
typename _Pred = std::equal_to<_Key>,
typename _Alloc = std::allocator<std::pair<const _Key, _Tp> >,
typename _Tr = __ummap_traits<__cache_default<_Key, _Hash>::value>>
using __ummap_hashtable =
_Hashtable<_Key, std::pair<const _Key, _Tp>,
_Alloc, __detail::_Select1st,
_Pred, _Hash,
__detail::_Mod_range_hashing,
__detail::_Default_ranged_hash,
__detail::_Prime_rehash_policy, _Tr>;Поскольку вычисление индекса и перехеширование тесно связаны между собой, нам доступны следующие пары политик (вычисление индекса-перехеширование):
_Mod_range_hashingи_Prime_rehash_policy(используются по умолчанию)_Mask_range_hashingи_Power2_rehash_policy
В последнем случае получим реализацию, аналогичную реализации Microsoft.
Помимо стандартной, для GCC доступны альтернативные нестандартные реализации. Они также используют policy-based подход и позволяют выбирать внутреннее представление между separate chaining и open-addressing. Например, следующий код создаёт хеш-таблицу с открытой адресацией:
#include <ext/pb_ds/assoc_container.hpp>
using namespace __gnu_pbds;
gp_hash_table<int, int> table;Эти реализации нарушают некоторые требования стандарта и доступны только для компилятора GCC, что плохо для кроссплатформенных решений. Более подробную информацию по этим и некоторым другим расширениям STL в GCC можно найти здесь.
Перерасход памяти для хранения одного элемента. Один указатель в односвязном списке + один указатель в массиве bucket`ов + одно значение хеш-функции — чаще всего равно размеру указателя. Получается три указателя на элемент против четырёх указателей в реализации Microsoft.
«Грабли» реализации Microsoft
Приведу пример не очень приятных «граблей» в реализации Microsoft, с которыми пришлось столкнуться лично. Нужно было реализовать дедупликацию элементов online. Каждый элемент представлял собой категорию и уникальный номер. Всего категорий было несколько десятков, в то время как номера гарантированно были уникальными. Предполагалось использовать реализацию только на 64-разрядных процессорах. Для номеров мы использовали 32-битное целое без знака. Первым и самым очевидным решением было создать хеш-функцию, которая объединяет два 32-битных целых в одно 64-битное целое.
struct item
{
uint32_t ucode_, category_;
};
struct item_hash
{
inline size_t operator()(const item& _i) const
{ return _i.category_ | (_i.ucode_ << 32); }
};
using mapping_type = std::unordered_set<item, item_hash>;На первый взгляд такая хеш-функция полностью отвечает требованиям: все значения будут уникальными и более-менее равномерно рассеянными. При использовании GCC производительность была вполне ожидаемой, но вот для Microsoft — примерно в 10 (!) раз ниже. Это оказалось связано с особенностями увеличения размера хеш таблицы — используются только младшие биты от всего хеш-значения. В моём случае оказалось, что практически все элементы отображались на один и тот же элемент массива bucket`ов, поэтому трудоёмкость поиска вместо ожидаемой amort. O(1) выродилась в O(N).
Для устранения этих недостатков необходимо изменить функцию хеширования. Тут есть как минимум два пути:
Просто поменять местами код и категорию, чтобы младшие биты оказались более равномерно рассеяны.
Оставить вычисления как есть, но дополнительно «перемешать» биты.
У первого пути есть небольшое преимущество: код, по очевидным причинам, исполняется быстрее, чем во втором варианте. Но второй предпочтительнее, поскольку не зависит от конкретного случая. Для замешивания можно использовать, например, функции библиотеки boost или, если целевая платформа поддерживает SSE 4.2, intrinsic-функцию _mm_crc32_u64, подсчитывающую CRC32. В последнем случае само замешивание будет быстрее за счёт аппаратного ускорения.
Выводы
Реализация хеш-таблиц в Microsoft потребляет больше памяти, чем Clang и GCC.
Реализация хеш-таблиц в Microsoft отображает хэш-значения в индекс в массиве bucket`ов, используя наложение битовой маски. Это определяет использование только первых n бит хеш-значения, где 2n — размер массива bucket`ов. Это означает, что задействовано будет, скорее всего, мало бит.
Будьте осторожны при написании собственной хеш-функции, например при использовании пользовательского типа в качестве ключа хеш-таблицы. Имейте в виду, что для Microsoft STL будут использованы только первые n бит от всего хэш-значения.
Получение хеш-значения объединением нескольких чисел в 64-битное значение — не самое удачное решение для кроссплатформенного кода, поскольку производительность будет зависеть от конкретной реализации STL на каждой платформе. Один из возможных подходов к решению этой проблемы — дополнительное «замешивание» бит.
Реализации STL в Clang и GCC не имеют этих недостатков и используют хитрые трюки, позволяющие сократить использование памяти и повысить производительность при изменениях размера хеш-таблицы.
Для реализаций STL в Clang и GCC некоторые операции с хеш-таблицами, инстанцированными с параметрами по умолчанию, могут потенциально работать немного медленнее из-за использования вычислительно «тяжелой» операции деления по модулю простого числа.
Реализации STL в GCC поддерживают fine-tuning через использование policy-based подхода или альтернативных реализаций. Если ваш продукт использует только этот компилятор, то можно рассмотреть такой подход для достижения наилучшей производительности.
Алгоритмы
Одна из основных сильных сторон библиотеки STL — обобщённые алгоритмы. Но и в них встречаются особенности и неожиданности. Начнём с совсем простого — функции std::fill(). Её задача — заполнить диапазон [first, last) одинаковыми значениями. Кажется, ошибиться или реализовать неэффективно такой простой алгоритм просто невозможно.
Реализация GCC
Здесь есть особенности, которые могут сделать код неэффективным. В VK Teams мы много работаем с текстом, и использование стандартных алгоритмов для символов и строк играет важную роль в нашей работе. Однажды мы столкнулись с таким сценарием:
void zeroize0(char* _data, size_t _length)
{
std::fill(_data, _data + _length, 0);
}Этот, на первый взгляд, безобидный и корректный код приводил к ощутимой просадке производительности. Мы изменили его на такой:
void zeroize1(char* _data, size_t _length)
{
std::fill(_data, _data + _length, '\0');
}После этого производительность взлетела в десятки раз! Чтобы разобраться в том, что здесь происходит, придётся копнуть глубже. Давайте сперва взглянем на ассемблер, полученный после компиляции первого варианта:
zeroize0(char*, unsigned long):
add rsi, rdi
cmp rsi, rdi
je.L1
.L3:
mov BYTE PTR [rdi], 0; store 0 into memory at [rdi]
add rdi, 1 ; increment rdi
cmp rsi, rdi ; compare rdi to size
jne .L3 ; keep going if rdi < size
.L1:
retМы получили просто побайтовое присваивание в цикле. Второй же вариант гораздо интереснее:
zeroize1(char*, unsigned long):
test rsi, rsi
jne .L8 ; skip the memset call if size == 0
ret
.L8:
mov rdx, rsi
xor esi, esi
jmp memset ; call to memsetЗдесь цикл отсутствует вовсе, вместо него вызывается memset(). Мы сейчас не будем рассматривать все тонкости реализации этой функции. Скажу лишь, что она максимально использует все возможности процессора, и едва ли получится сделать что-то лучше.
Теперь возникает вопрос: как получилось, что столь незначительные изменения привели к огромной разнице в производительности? Ответ кроется в самой реализации STL. Давайте взглянем на реализацию std::fill() в GCC — код я немного упростил для понимания:
/*
*...
*
*This function fills a range with copies of the same value.For char
*types filling contiguous areas of memory, this becomes an inline call
*to @c memset or @c wmemset.
*/
template<typename _ForwardIterator, typename _Tp>
inline void fill(_ForwardIterator __first, _ForwardIterator __last, const _Tp& __value)
{
std::__fill_a(std::__niter_base(__first), std::__niter_base(__last), __value);
}В комментариях к коду уже содержится часть ответа. Программисты из команды GCC продумали сценарии, когда можно использовать более эффективный вызов memset(), нежели поэлементное присваивание в цикле. Давайте копнём ещё глубже и посмотрим на реализацию этих сценариев:
template<typename _ForwardIterator, typename _Tp>
inline typename
__gnu_cxx::__enable_if<!__is_scalar<_Tp>::__value, void>::__type
__fill_a(_ForwardIterator __first, _ForwardIterator __last, const _Tp& __value)
{
for (; __first != __last; ++__first)
*__first = __value;
}
// Specialization: for char types we can use memset.
template<typename _Tp>
inline typename
__gnu_cxx::__enable_if<__is_byte<_Tp>::__value, void>::__type
__fill_a(_Tp* __first, _Tp* __last, const _Tp& __c)
{
const _Tp __tmp = __c;
if (const size_t __len = __last - __first)
__builtin_memset(__first, static_cast<unsigned char>(__tmp), __len);
}Теперь можно увидеть, в каких случаях появляется memset() — он будет явно вызван для второй реализации, выбранной с помощью enable_if, когда SFINAE-условие __is_byte<_Tp> истинно. Но в отличие от обобщённой первой версии здесь используется только один шаблонный параметр _Tp. Следовательно, этот второй, оптимизированный вариант будет выбран только если указатели __first и __last, ограничивающие диапазон, имеют тот же тип, что и значение для заполнения. Таким образом, для std::fill(_data, _data + _length, 0); значение 0 по правилам синтаксиса языка С++ будет неявно преобразовано к int, и компилятор выберет неоптимальную версию с циклом.
У вас может возникнуть закономерный вопрос: «А почему вообще понадобилась версия с циклом? Почему нельзя использовать настолько оптимизированный memset() для всех типов?» Дело в том что, пользовательские типы могут быть довольно сложными и поддерживать не побайтовое заполнение, а только поэлементное присваивание.
Реализация Microsoft
Тут отличия в лучшую сторону. Реализация намного сложнее: распознаёт случаи, когда тип поддерживает тривиальное копирование или присваивание, а также когда для заполнения используется именно нулевой элемент. Для таких случаев используется std::memset(). Это позволяет использовать не только байты, но и другие скалярные типы для получения максимальной производительности, например, int, double и даже POD-структуры. Вот немного упрощенный код этой функции c дополнительными комментариями:
template <class _FwdIt, class _Ty>
void fill(const _FwdIt _First, const _FwdIt _Last, const _Ty& _Val)
{
if constexpr (_Is_vb_iterator<_FwdIt, true>) {
_Fill_vbool(_First, _Last, _Val); // версия для итераторов от vector<bool>
} else {
auto _UFirst = _Get_unwrapped(_First);
const auto _ULast = _Get_unwrapped(_Last);
if constexpr (_Fill_memset_is_safe<decltype(_UFirst), _Ty>) {
// версия для char-like типов
_Fill_memset(_UFirst, _Val, static_cast<size_t>(_ULast - _UFirst));
return;
} else if constexpr (_Fill_zero_memset_is_safe<decltype(_UFirst), _Ty>) {
if (_Is_all_bits_zero(_Val)) { // проверка что все биты _Val нулевые
_Fill_zero_memset(_UFirst, static_cast<size_t>(_ULast - _UFirst));
return;
}
}
for (; _UFirst != _ULast; ++_UFirst) {
*_UFirst = _Val;
}
}
}Здесь стоит отметить несколько моментов:
_Fill_memset_is_safeразворачивается в константу времени компиляции_Is_character_or_byte_or_bool<T>— название говорит само за себя.Функция
_Is_all_bits_zero()реализована через вызовstd::memcmp().Функция
_Fill_vbool()реализует заполнение диапазона отstd::vector<bool>, речь про который пойдёт ниже.
Выводы
Реализация std::fill() GCC и Microsoft различаются оптимизациями. Для реализации GCC оптимизации для любых типов, кроме char, отсутствуют, в отличие от реализации Microsoft.
С другими алгоритмами всё сложнее. Допустим, вы реализуете парсер текстового формата с односимвольными разделителями. При использовании С++ STL алгоритм std::find() — очевидный выбор. Это ещё одна крайне простая по назначению функция: она ищет указанный элемент в диапазоне и для сравнения элементов использует оператор ==. Как и прочие алгоритмы STL мы подразумеваем, что std::find() высокооптимизирована и специализирована для различных типов аргументов. Можно ожидать, что для итераторов произвольного доступа и типа char, например, будет использован вызов низкоуровневой функции memchr() (по аналогии с std::fill(), как описывалось выше). Однако на практике ни одна из реализаций STL так не делает. Это означает, что использование STL-алгоритмов для строк становится неэффективным. Можно надеяться на автовекторизацию — оптимизацию, выполняемую самим компилятором с целью использования, например, SIMD-инструкций, повышающих производительность алгоритма. Но она не всегда возможна и сильно зависит от целевого процессора или платформы и возможностей самого компилятора.
Вывод: Использование STL-алгоритмов для простых типов может быть неэффективным, потребуются дополнительные измерения и исследования, если использование этих алгоритмов не даст желаемого эффекта. В случае со строками и символами существует кроссплатформенный способ обойти ограничения обобщённых алгоритмов STL: можно использовать статические методы из std::char_traits<T> или функции из std::string/std::string_view. Эти методы гарантированно используют все возможные оптимизации и, в большинстве случаев, напрямую применяют низкоуровневые вызовы memset(), memchr(), memcpy() и прочие.
Управление памятью и «умные» указатели
В сложных проектах нельзя недооценить удобство использования «умных» указателей, которые появились в 11 версии C++ и сильно помогают в разработке. Проект VK Teams здесь не исключение — в нашем коде мы активно используем практически все «умные» указатели, предоставляемые STL. Однако здесь могут поджидать неочевидные на первый взгляд особенности.
Работа с ресурсами и std::shared_ptr
Об std::shared_ptr и особенностях его работы написано очень много. Я не буду подробно рассматривать работу «умных» указателей, но остановлюсь на одном моменте, которому почему-то уделено мало внимания.
Хорошим тоном при использовании std::shared_ptr является его создание через std::make_shared(). В этом случае контрольный блок и сам разделяемый ресурс выделяются в одной области памяти.

Контрольный блок при создании через std::make_shared().
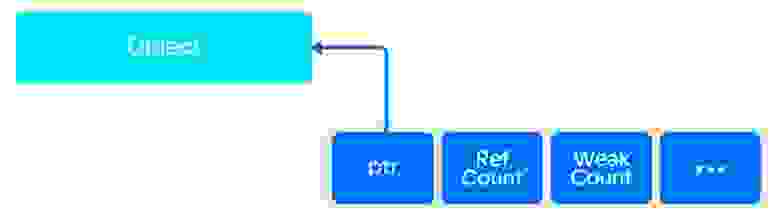
Контрольный блок при создании через new.
Напомню, что в контрольном блоке располагаются, помимо прочего, два счётчика ссылок: слабых и сильных. Разберёмся теперь, что происходит при обращении каждого из них в 0.
Когда значение счётчика сильных ссылок достигает 0, вызывается деструктор ресурса. Если при этом счётчик слабых ссылок также равен нулю, занимаемая ресурсом и контрольным блоком память освобождается. Ситуация меняется, когда счётчик сильных ссылок равен нулю, а счётчик слабых ссылок больше нуля. При этом вызывается только деструктор ресурса, но сама память не освобождается. Её освобождение происходит только тогда, когда счётчик слабых ссылок также станет равен нулю. Это очевидно, поскольку и ресурс, и контрольный блок находятся в одной области памяти. Мы не можем освободить часть выделенного фрагмента, только целиком. В большинстве случаев это не приводит к большой трате памяти; но если ресурс сам по себе большой, то занимаемая им память не будет освобождена, пока все слабые ссылки не будут удалены. Особенно важным это становится, если у нас имеется динамический массив из «умных» указателей на такие ресурсы.
Поэтому будьте внимательными при использовании крупных разделяемых ресурсов для std::shared_ptr и особенно динамических массивов из таких «умных» указателей.
Взаимодействия с потоками исполнения
В нашем продукте мы уделяем особое внимание отзывчивости интерфейса. Поэтому для нас важно использовать многопоточность, чтобы исключить блокирование интерфейса пользователя при выполнении длительных операций, операций с сетью, жёстким диском и тому подобным. Чтобы держать всё под контролем, различные категории операций выполняются в своих потоках, которые собраны в отдельные пулы. Однако и здесь в коде, который на первый взгляд выглядит максимально корректно, обнаруживаются трудноуловимые баги.
У нас часто возникает необходимость создавать дочерние потоки из одного потока родителя — так называемая «модель fork-join». Как ни странно, в этом случае дочерний поток может «пережить» своего родителя и попытаться «присоединиться» (через std::thread::join()) к нему. Итог — падение всего приложения. Такое возможно при использовании std::shared_ptr и его особенностей, описанных выше.
Основная сложность такого рода багов — нестабильность воспроизведения. Невозможно предугадать, как планировщик потоков ОС распределит процессорное время и успеет ли дочерний поток завершить свою работу до того, как его родитель будет удалён.
Я лично столкнулся с такого рода проблемой. Воспроизвести падение удалось, только вставив принудительную задержку при исполнении функции в потоке. В результате выяснилось, что при написании кода была допущена ошибка: одна из функций выполнялась в соседнем пуле «в обход» того, в котором должна была выполняться. Кроме того, в коде использовался std::shared_ptr, созданный через std::make_shared. Далее от shared_ptr брался weak_ptr и с ним производилась необходимая работа. В итоге дочерний поток иногда «переживал» своего родителя и пытался «присоединиться» к уже аннигилировавшему предку.
Поэтому будьте особенно внимательны при использовании модели fork-join многопоточного программирования совместно с std::shared_ptr/std::weak_ptr и пулами потоков.
Битовые массивы
Для некоторых прикладных задач оказывается незаменимым использование такой, на первый взгляд, простой структуры данных, как битовый массив (или битовый вектор). Он обладает двумя важными свойствами: потребляет мало памяти и по быстродействию сравним с std::vector. Но STL предлагает весьма ограниченные возможности по работе с битовыми векторами. На сегодняшний день «из коробки» доступно только два класса: std::bitset<> и std::vector<bool>. Причем последний сообщество активно критикует и не рекомендует использовать.
Почему его так критикуют? Одна из особенностей языка C++ заключается в том, что минимальной единицей памяти, доступной программисту, является байт. Но в данном случае мы имеем дело с отдельным битом. Чтобы обращение к битам было возможно, их упаковывают в машинные слова, так что каждый отдельный бит можно получить путём нехитрых побитовых операций над словом. Таким образом, std::vector<bool>, несмотря на имя класса, вектором не является, поскольку нарушает требования, предъявляемые к std::vector<T>. В стандарте сказано, что внутреннее представление и реализация std::vector<bool> зависит от поставщика и может использовать оптимизации. Но никаких гарантий в этом случае стандарт не даёт. Это означает, что все стандартные алгоритмы STL могут работать крайне неэффективно для std::vector<bool>. Например, если итератор для sdt::vector<bool> реализован наивным образом, то любой алгоритм будет выполняться над каждым отдельным битом, вместо того, чтобы использовать машинные слова целиком.
Я проанализировал некоторые реализации std::vector<bool> и выяснил, что:
Все рассматриваемые компиляторы (GCC, Clang и Microsoft) используют упаковку в машинные слова — есть выигрыш по памяти.
GCC не предоставляет оптимизированных для
std::vector<bool>алгоритмов.Microsoft предоставляет оптимизированные версии алгоритмов
std::fill(),std::find()иstd::count().Clang предоставляет оптимизированные версии алгоритмов:
std::fill(),std::find(),std::count(),std::equal(),std::copy(),std::copy_backward(),std::swap_ranges(),std::rotate().
Отличие std::bitset заключается в том, что его размер фиксирован на этапе компиляции. И, следовательно, не может быть изменён во время исполнения. Если требуется динамический вектор битов, то STL не предоставляет такой функциональности — не считая std::vector<bool>, который нам настоятельно не рекомендуют. Но такая реализация есть в библиотеке boost — класс dynamic_bitset<>. Он позволяет задать тип машинного слова для хранения упакованных бит и тип распределителя памяти, если требуется тонкое управление памятью, и, по большей части, его интерфейс схож с std::vector<bool>.
Но наличие в арсенале dynamic_bitset — это необходимое, но недостаточное условие для решения практических задач. Нужны также совместимые с этой структурой данных алгоритмы. К сожалению, dynamic_bitset<> не может похвастаться их обилием. Его реализация предоставляет только функции, позволяющие выполнять операции над множествами, искать и подсчитывать выставленные биты и получать копии внутреннего массива машинных слов. По всей видимости, разработчики оставили реализацию STL-совместимых алгоритмов в качестве упражнения для пользователя.
Исходя из всего сказанного выше, реализация собственного битового вектора уже не кажется настолько провальной затеей. Видимо, это тот самый случай, который только подтверждает правило: иногда и свой велосипед может оказаться вполне пригодным.
Правильная и эффективная реализация такого вектора — весьма непростая задача и настолько обширная тема, что ей можно посвятить отдельную статью. Очевидно одно: собственная реализация такого класса открывает возможности для более широкого спектра алгоритмов, использования суперскалярности процессора и многих других оптимизаций. Все они в итоге приведут к гарантированной эффективности на любой платформе и колоссальному увеличению производительности решений.
Общий итог
Разработка ПО никогда не станет ровным шоссе без светофоров. Скорее, это горный серпантин с обрывами, тупиками и неожиданными поворотами. Если мне удалось хоть немного приоткрыть завесу тайны над реализацией STL с её особенностями и предостеречь читателя от обрывов и неожиданных провалов, значит цель статьи достигнута.


