
При работе с Kubernetes в облаке через интерфейс платформы видно только кластеры и виртуальные машины, которые под ними крутятся. Это усложняет управление и мониторинг: пользователь просто не видит ресурсы внутри кластера и не знает, какая полезная нагрузка в нем обрабатывается.
Меня зовут Алексей Волков, я продакт-менеджер Kubernetes aaS и Backup, VK Cloud. В этой статье я расскажу, как мы реализовали управление ресурсами кластера в сервисе Kubernetes, какой стек и почему выбрали, а также сколько ресурсов на это ушло.
Суть проблемы
Ключевым компонентом управления кластером, который позволяет просматривать, редактировать и получать информацию о ресурсах в нем, являются манифесты. Но в зависимости от выбранных параметров конфигурации сетевой доступности кластера могут быть разными, в том числе без прямого доступа к ресурсам извне (через белый IP из публичных сетей). В ряде случаев это создает ограничения: например, для мониторинга ресурсов и их визуализации в панели управления облачного провайдера нужно постоянное транслирование данных из кластера наружу. Например, раньше в VK Cloud не была реализована подобная функциональность, и пользователи в панели управления облаком могли видеть только IP, сущность кластера и виртуалки под ним. При таком сценарии ресурсы внутри кластера оставались для пользователя в Black box: из интерфейса облака о них ничего не известно, а для получения любой информации надо идти непосредственно в кластер. Это проблематично, если таких кластеров десятки.
Чтобы обеспечить такой доступ и организовать передачу информации от кластера к интерфейсу облачной платформы вне зависимости от конфигурации сетевой доступности, нам нужен был промежуточный слой, который безопасно связывает кластер и панель управления облака. Мы реализовали такой кейс — научили нашу инфраструктуру показывать ресурсы внутри кластеров и даже сделали это с помощью стандартных инструментов K8s, то есть максимально нативным способом без изменения API Kubernetes.
Реализация управления ресурсами кластера
Чтобы организовать безопасный обмен данными со всеми кластерами и получать информацию без необходимости напрямую обращаться к ним, мы реализовали решение со схемой, которая включает следующие сущности:
- Пользователь — в нашем случае конечный пользователь или API панели управления облака.
- Кластер-HTTP — сущность, которая содержит запрос от интерфейса платформы к бэкенду.
- RabbitMQ — брокер очередей, который отвечает за маршрутизацию запросов от роутера к подписчику, реализует протокол AMQP.
- Агент — сущность, которая развернута на каждой виртуальной машине кластера и нужна для выполнения сервисных операций с кластером: обновления, обслуживания, поддержки, мониторинга и других. За агентом есть сам API Kubernetes, который вызывается локально в ноде. Передача сообщений от агента к подписчику реализована через фреймворк gRPC.
- Magnum-rapid — сущность, которая реализует основную функциональность бэкенда и обеспечивает взаимодействие агента, пользователя и брокера очередей RabbitMQ.
- Роутер — сущность внутри Magnum-rapid, которая отвечает за прием сообщений от пользователя, передачу их к брокеру очередей RabbitMQ и пересылку сообщений в обратном направлении.
- Подписчик — сущность внутри Magnum-rapid, которая отвечает за прием сообщений от брокера очередей RabbitMQ, пересылку их к агентам на нодах и отправку сообщений в обратном направлении.
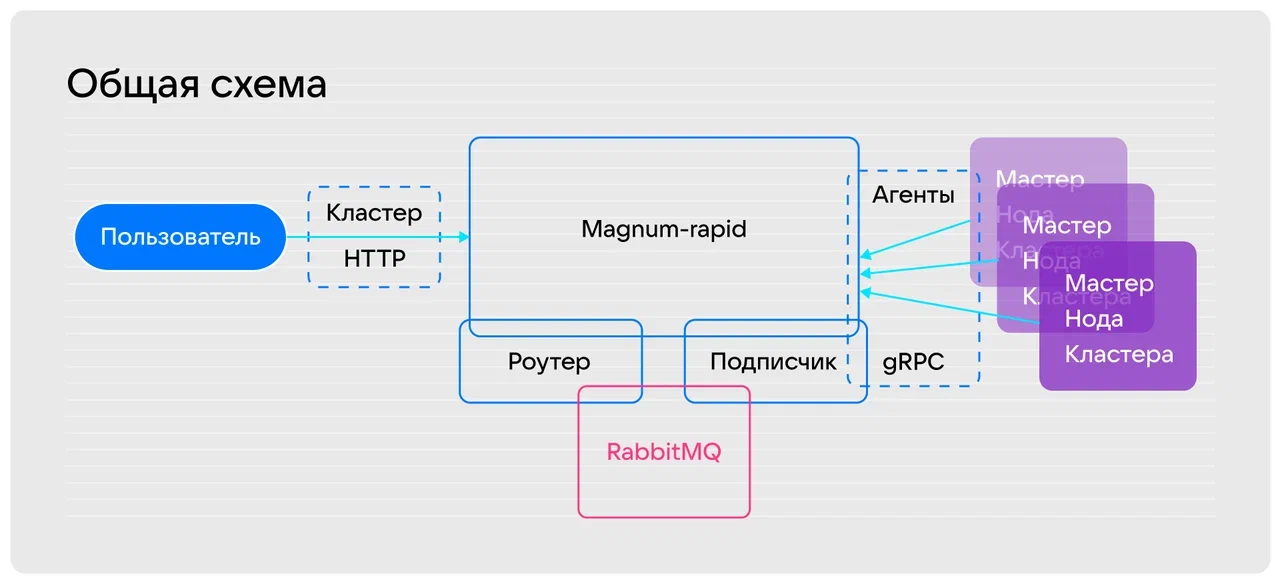
Алгоритм работы решения:
- Пользователь отправляет на хост облака API-запрос, чтобы получить информацию о кластере и его ресурсах. Запрос обязательно содержит идентификатор нужного кластера. Для передачи используется протокол HTTP.
- На виртуальных машинах на кластерах запускаются компоненты Kubernetes и наш агент, который нужен для реализации системных функций и передачи данных о кластерах. Соединение инициирует именно агент. Это позволяет нам работать из закрытых контуров, когда мы не знаем, где вообще агент находится. Агент инициирует установление связи своим первичным коннектом и готов через этот двусторонний коннект получать сообщения. За агентом есть сам API Kubernetes, который вызывается локально в ноде.
- Роутер получает запрос в API Kubernetes и идентификатор кластера, после чего отправляет его в RabbitMQ. Также роутер выполняет массив подготовительной работы. Например, конвертирует HTTP в gRPC и обратно, стерилизует сообщения и форматирует их.
- RabbitMQ создает очередь к подписчику с идентификатором кластера и передает в нее сообщение, которое конвертируется в запрос к нужному кластеру.
- Подписчик, который реализует gRPC-сервер, через gRPC держит соединение с агентом, отправляет к нему запрос, получает ответ и отправляет его обратно к RabbitMQ.
- Цикл повторяется в обратном порядке.
При такой реализации, с точки зрения самого Kubernetes, в его API нет никаких изменений — они есть только в алгоритме доступа к нему. Получается, что вместо подключения через внешний IP, который пользователь должен был знать и самостоятельно делать запросы, мы внедрили все инструменты в общую панель управления.
Стоит отметить, что Magnum-rapid также обеспечивает валидацию, авторизацию и агрегацию данных и обеспечивает поддержание и мониторинг соединений со всеми подключенными агентами. Именно через него реализуется функциональность управления ресурсами.
Фактически мы смогли реализовать упрощенную схему без сложных манипуляций и запроса kubeconfig. Это стало возможным, потому что в Kubernetes от VK Cloud внедрена SSO (single sign-on, система единого входа) — благодаря этому пользователь полагается на механизмы авторизации и распределения прав облака. Сам механизм авторизации становится гораздо прозрачнее: пользователь, как и раньше, авторизуется сначала в личном кабинете, а дальше использует авторизующие хедеры, которые мы доносим прямо до кластера, не влияя на процесс.
Стек решений: аргументация выбора
Для реализации проекта нам нужно было два решения: брокер очередей и инструмент для связи между ним и агентом. При их выборе мы отталкивались от компетенций команды, нашего опыта и доступных решений.
В первом случае (с выбором фреймворка) все было просто: мы уже использовали gRPC для получения от агентов системных данных о кластерах, и это решение нас полностью устраивало. Кроме того, gRPC легко справляется с большими сообщениями и многопоточной обработкой операции. В качестве альтернативы gRPC можно было рассматривать WebSocket, но для нашего кейса он не подходит: из-за проблем с HTTP-стеком он плохо справляется с мультиплексированием сообщений, что для нас критично.
При выборе брокера очередей или способа маршрутизации сообщений мы рассматривали несколько вариантов:
- RabbitMQ,
- Redis,
- прямые коннекты между инстансами Magnum-rapid.
Redis Server хорошо известен как распределенный кэш. Но он не адаптирован для нашей задачи: нам нужно фильтровать много сообщений. Поэтому пришлось бы дополнительно делать синхронизацию.
Вариант с прямыми соединениями роутера и подписчика хорош и позволяет сократить Latency с помощью уменьшения цепочки передачи сообщений. Но реализовать прямое подключение сложно: надо научить все инстансы Magnum-rapid знать друг о друге, придумать протокол обмена информацией об агентах.
RabbitMQ оказался лучшим из вариантов. Во-первых, он хорошо реализовывает маршрутизацию с помощью функциональности очередей и гарантирует доставку сообщений нужному подписчику. Это упрощает работу всей цепочки: маршрутизация сводится к тому, что нам нужно положить запрос пользователя с нужным идентификатором кластера в нужную очередь. Кроме того, RabbitMQ хорошо масштабируется и у нашей команды была экспертиза в работе с ним.
Подводные камни
Реализованная нами схема асинхронная и параллельно-конкурентная: в обе стороны параллельно передается много разных запросов. Особенно это касается подписчика, у которого с двух сторон недетерминированное подключение: с одной стороны у него двунаправленный стрим в агент, с другой — двунаправленный стрим в RabbitMQ. То есть из одной очереди он получает сообщения, а в другую отправляет. И в один поток он посылает сообщения в агент, из другого получает. В результате подписчик должен управлять четырьмя коннекторами, которые работают независимо. Главный недостаток такой реализации в ненадежности соединений: они могут разрываться по разным причинам, в том числе инфраструктурным.
На этапе финальной реализации мы столкнулись с тем, что для официальной библиотеки RabbitMQ, которую мы используем, частые HTTP-соединения и их обрыв допустимы: никакой функциональности по восстановлению соединений нет, да и сделать это сложно из-за их асинхронности. Более того, сам RabbitMQ-сервер плохо реагирует на большое количество подключений и их нестабильность. Оставлять подобную реализацию было недопустимо как со стороны нашего решения, так и со стороны RabbitMQ.
Для решения этой проблемы мы:
- реализовали механизмы, которые позволяют делать воспроизводимые соединения;
- создали «обертку», которая автоматически переподключает и в то же время лояльно относится к количеству и частоте подключений к RabbitMQ.
Разработанная нами «обертка» представляет собой библиотечную структуру, которая связывает роутер, подписчика и RabbitMQ — все запросы перед подключением к библиотеке RabbitMQ попадают в «прослойку», поэтому проблем с разрывами и переподключениями нет.
Сроки внедрения
Благодаря тому, что мы использовали стандартные инструменты и компоненты Kubernetes, на реализацию и внедрение новой функциональности у нас ушло около четырех месяцев. За это время мы:
- выработали идею добавления фичи управления ресурсами кластера в рамках развития Fully Managed-подхода;
- провели research решений задачи, выбрали вариант технической реализации — решение с gRPC;
- выполнили Proof of concept и создали прототип решения;
- запустили рабочую бету, которую проверили с помощью нагрузочных тестов.
В реализации проекта были задействованы две команды, которые работали параллельно:
- фронтенды, которые занимались UI и логикой с учетом предоставленной бэкендом спецификации API Kubernetes, который стал основой решения;
- бэкенды, которые занимались непосредственно разработкой «прослойки» (Reverse proxy) для организации безопасного и стабильного взаимодействия между агентом в кластере и учетной записью пользователя.
Что получили в итоге
Реализация проекта и добавление новой фичи позволили нам безопасно перейти в мониторинге K8s-кластеров от Black box к White box. Теперь пользователи VK Cloud могут через личный кабинет отслеживать не только кластеры K8s, но и ресурсы в них: не обращаясь напрямую в кластер, видеть, какие нагрузки, где и как выполняются. В перспективе это позволяет расширить возможности управления, чтобы пользователь через панель управления облака мог не только мониторить сущности внутри кластеров, но и управлять ими без сложных и рутинных манипуляций.
Вы прямо сейчас можете воспользоваться Kubernetes от VK Cloud. Для тестирования мы начисляем новым пользователям 3000 бонусных рублей и будем рады вашей обратной связи.
Stay tuned
Присоединяйтесь к телеграм-каналу «Вокруг Kubernetes», чтобы быть в курсе новостей из мира K8s! Регулярные дайджесты, полезные статьи, а также анонсы конференций и вебинаров.




