
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
По данным Barc, ещё в 2015 году компании, использующие Big Data & Analytics, смогли на 8% увеличить доходы и на 10% снизить затраты. Сегодняшний тренд на цифровизацию и импортозамещение подталкивает руководителей активнее изучать и внедрять аналитику данных в работу своих предприятий. Такие технологии позволяют оптимизировать затраты, точнее оценивать риски, прогнозировать спрос и повышать эффективность бизнес-процессов. И если раньше анонсы о внедрении Big Data в основном были связаны с пилотными проектами, то сегодня промышленные компании всё чаще рассматривают работу с данными как важную часть корпоративной стратегии развития.
Мы занимаемся разработкой ПО для промышленных предприятий, и сегодня обладаем достаточной экспертизой о трудностях, которые могут возникать на каждом из этапов внедрения анализа данных, а также об инструментах для их решения. В этой статье мы разберём весь путь внедрения анализа больших данных на предприятии с использованием этих продуктов.
Эволюция аналитики данных в промышленной компании
Путь, который должна пройти компания до промышленного внедрения анализа данных, мы условно делим на пять этапов: генерирование гипотез, эксперимент (Proof-of-Concept), пилотный проект, масштабирование и промышленное внедрение (реализация data-driven подхода).
Предпосылкой, как правило, служит стремление принимать решения на основе данных, чтобы сохранять и улучшать позиции на рынке. Это происходит на фоне понимания того, что определённые процессы в компании перестали быть слаженными. На этом этапе формируются гипотезы, которые проверяются далее.
Проект по внедрению аналитики данных требует вложений, несёт за собой финансовые и временные риски, которые в случае неудачи могут обернуться потерей позиций на рынке. Поэтому развитием идеи, как правило, занимаются сотрудники-энтузиасты.
Второй этап внедрения – эксперимент, проверка гипотезы о решаемости задач компании с помощью анализа данных. Используются open-source инструменты анализа данных, проводится защита проекта перед руководством. При успешном согласовании выделяется бюджет на дальнейшие этапы.
На третьем этапе выявляют ценность проекта – запускают пилотный проект, который поможет подтвердить экономический эффект. На этом этапе к сотрудникам-энтузиастам могут подключиться дата-сайентисты и дата-инженеры (в случае, если их нет в штате, компания дополнительно нанимает этих специалистов). Все вместе они наращивают экспертизу и стремятся получить бизнес-выгоду от пилота.
Четвёртый этап – развитие аналитических компетенций. Цель – масштабирование пилотного проекта на уровень всей компании. К сконструированному на open-source ПО добавляются пробные продукты с элементами data-science и машинного обучения. Итог этапа – получение бизнес-выгоды в рамках всей компании. Так достигаются пределы возможности open-source.
Цель пятого, заключительного этапа — переход от вопроса «что сейчас?» к вопросу «что будет?». Штат проекта может пополниться командой внутренней разработки, чтобы создать платформу, на базе которой будут реализовываться все дальнейшие проекты. Это позволит выйти на новый уровень анализа данных и достичь конкурентного преимущества за счет его использования.
Мировая статистика показывает, что далеко не все гипотезы подтверждаются, и даже не все пилотные проекты показывают экономический эффект. Компаниям стоит быть к этому готовыми — генерировать больше гипотез и проводить больше пилотов, чтобы нужное количество проектов доходило до внедрения и промышленной эксплуатации.
Для этого:
- На ранних этапах (2, 3) необходимы простые и легкие инструменты прогнозной аналитики, которыми могут пользоваться не только дата-сайентисты (обычно их мало и может вообще не быть), но и бизнес-аналитики, или даже рядовые сотрудники — носители экспертизы конкретного подразделения компании.
- На поздних этапах (4, 5) необходимы удобные и мощные платформенные продукты, так как не у всех компаний есть время и деньги на разработку собственных платформ. Тем более, что большинство задач на этих этапах лежит не в аналитической, а инженерной плоскости: подключение к источникам данных, настройка процессов обработки, обеспечение безопасности, управление вычислительными ресурсами, пользователями и так далее.
Мы в Factory5 на собственном опыте наблюдаем, как гипотезы и пилоты превращаются в промышленные решения, поэтому предлагаем заказчикам и системным интеграторам инструменты для работы на всех этапах анализа данных.
Проверяем гипотезы за три шага с помощью F5 Future
F5 Future — это набор готовых приложений, использующих алгоритмы машинного обучения. Приложения помогут быстро решить бизнес-задачи, требующие обработки больших данных: проверить гипотезы, оценить промежуточные результаты исследований или рассчитать итоговые цифры по проекту.
Примерами таких задач являются прогнозирование потребления электроэнергии на будущий период времени, классификация дефектов по заданным признакам, поиск аномалий в данных. В целом заложенные типовые алгоритмы помогают справиться и со многими другими задачами, требующими с прогнозированием каких-либо параметров, классификацией и выявлением аномалий.
Благодаря no-code подходу воспользоваться сервисом и получить результат всего за три шага сможет даже стажёр. Здесь реализован интуитивно понятный интерфейс, который позволяет минимизировать ручной труд, ускорить время проверки гипотез и повысить качество работы.
В основу приложений F5 Future заложены no-code подход и концепция «трех шагов». Приложения не нужно настраивать, а получение результата сводится к 3 кликам: загрузить данные – обучить модель – получить результат.

F5 Future может служить инструментом и для команд Data Science, заменяя open-source за счет сокращения времязатрат на написание кода и индивидуальную настройку программ.
Преимущества no-code приложений F5 Future

Оценить все возможности решения и ознакомиться с примерами задач, решаемых с помощью F5 Future, можно здесь.
Промышленное внедрение: разрабатываем необходимые приложения с помощью платформенного решения
Когда все гипотезы проверены, наступает этап промышленного внедрения анализа больших данных. У каждого предприятия своя специфика внутренних процессов, которые требуют индивидуальных аналитических решений. Для создания приложений под конкретные задачи бизнеса мы разработали платформу для анализа данных промышленных предприятий F5 Platform. С её помощью можно:
- объединять большое количество разрозненных данных из разных баз и хранилищ;
- обеспечить процессинг данных, их комплексную аналитику, визуализацию и интеграцию;
- разрабатывать аналитические приложения под конкретные задачи бизнеса;
- интегрировать ML-модели в ИТ-окружение и операционную деятельность.
Возможности для быстрой разработки бизнес-приложений
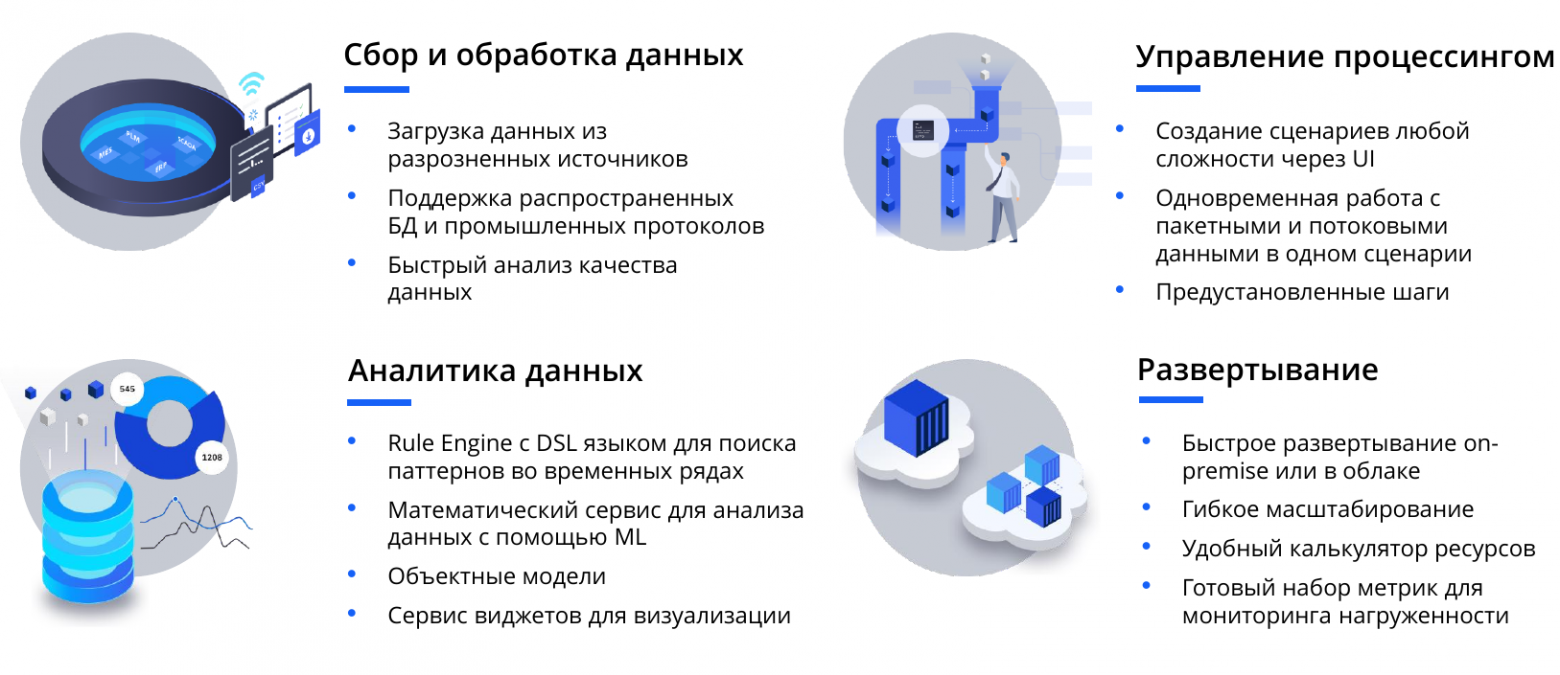
В платформе реализован подход End-to-end — от сбора данных до интеграции.

F5 Platform позволяет достичь следующих эффектов:
– ускорение разработки аналитических приложений;
– извлечение бизнес-ценности из данных;
– снижение затрат на разработку и снижение требований к специалистам.
Платформа входит в Реестр российского ПО и успешно используется на предприятиях разных отраслей промышленности. Так, например, в энергетических компаниях с использованием F5 Platform достигается снижение энергопотребления и экономия ресурсов — с помощью моделирования работы энергоемкого оборудования и выдачи советов персоналу по изменению режимов его работы. В лесной промышленности F5 Platform применяется для автоматизации анализа спутниковых снимков леса — классификации участков по породам деревьев и автоматического формирование статистических отчетов. Также эффективно платформу можно использовать при решении задач экомониторинга — повысить скорость реакции на инциденты и снижение последствий загрязнений с помощью мониторинга состояния атмосферного воздуха, прогнозировать развитие загрязнений и автоматизировать расчет параметров качества воздуха.




