
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Привет, Хабр! Меня зовут Артём Шубский, я техлид в компании AGIMA. Заметили, что на Хабре и на конференциях часто рассказывают, как перешли с монолита на микросервисы. Мы тоже всем сердцем любим микросервисы, но в этой статье я расскажу об обратном примере: как и почему на одном из проектов шли от микросервисов к монолиту. Это поучительная история о том, почему не страшно поменять архитектуру, даже когда кажется, что поздно.

С чего всё началось
Многие разработчики, выбирая между микросервисами и монолитом, выбирают микросервисы. Почти всегда это решение продиктовано требованиями: микросервисы доступнее, их проще масштабировать, они подходят для высоких нагрузок. А высоконагруженные проекты — популярные герои статей и конференций.
Но в нашей практике был случай, когда на таком проекте нам пришлось следовать другой логике. Это был один из наших крупных заказчиков — PetTech-сервис. Изначально проект задумывался как максимально гибкий. Была задача быстро реализовать сервис и проверить много гипотез. В требования хотели заложить идеи быстрого роста и разнообразия фичей. Однако позже требования изменились, бизнес переориентировал свои ценности и цели. Стартап превратился в продукт.
Спустя какое-то время мы осознали, что возможности микросервисов не дают существенных преимуществ, однако их недостатки сильно влияют на качество и скорость разработки. Как это привело нас обратно к монолиту, я и расскажу в этой статье.
Почему микросервисы
Сам сервис появился из слияния двух отдельных систем — абсолютно разных сайтов. Изначально у заказчика не было плана сделать что-то единое. Обе системы преследовали разные цели и работали независимо друг от друга. Вот они:
Информационный сайт со статьями о питомцах и мобильное приложения для этих статей.
CRM-система управления расписанием (СУР) клиник — для автоматизации работы ветеринарных клиник.
Но скоро у бизнес-заказчика родилась гипотеза: возможно, эти системы могут кооперироваться между собой и обоюдно увеличивать трафик. Тогда-то перед нами впервые поставили задачу объединить их в один сервис.
Обе системы были полностью готовы и хорошо работали, поэтому мы решили сделать так, чтобы они общались между собой. Тем самым мы заложили основу микросервисной архитектуры.
Развитие микросервисов
Так как проект задумывался как стартап, бизнес преследовал цель изучать рынок и проверять гипотезы. В этот момент не было четкого направления развития. А микросервисы отлично подходили для неопределенных целей — ограниченная логика и самобытные сервисы прекрасно справлялись с гипотезами и делали свое дело.
В какой-то момент проверка этих гипотез привела к тому, что стартап перерос в самобытный продукт со своей командой и миссией. Изменился подход к проекту и изменились задачи. Одной из них стало расширение функций CRM, чтобы пользователи могли записываться в клиники.
Логика была такая: новостной сайт (первая система) пользовался популярностью. С его помощью можно было создать неплохой трафик для клиник (из второй системы). Обычные пользователи хранились в базе знаний, а клиники и расписание их работы — в СУР. Пришлось думать, как заставить эти кусочки работать вместе. Было ясно, что трафик с новостного сайта будет большим. В этом смысле микросервисы тоже были полезны — их проще масштабировать.
Рефакторинг в одну систему требовал полного переписывания одного из сервисов, а мы еще не понимали, насколько это необходимо и в какой продукт всё это вырастет. И выбрали вариант, который был быстрее: сделать двусторонний REST между ними. Поэтому всё, что потенциально относилось к записям, мы складывали в СУР, а всё, что к новостям и мобильному приложению, в базу знаний.
Сама передача данных тоже была довольно проста: мы собирали несколько вариаций ответов (minimal, short, maximum) и запрашивали нужный в зависимости от ситуаций.
minimal: https://pastebin.com/TwQKqBmu
short: https://pastebin.com/6ETaaZ7J
maximum: https://pastebin.com/m7buAan8
Иными словами, мы делали набор разных уровней вьюх для API — разной расширенности для каких-то конкретных действий. У нас появлялась необходимость запросить какие-то данные (ID, например), и мы делали minimal API_view. Если у нас появлялся более полный short (например, мы добавили контакт и город) и если там появлялся какой-то четвертый, мы просто меняли наборы полей. У нас получались очень раздутые контроллеры, которые отдают по сути наборы полей, которые нужны для одного конкретного действия. В какой-то момент мы начали делать различные вариации вроде extendedApiView, а учитывая, что каждая связанная сущность имела свои уровни View, получалась огромная путаница.
extended: https://pastebin.com/1KTkJjYR
Бум микросервисов
По итогам этой работы мы имели уже два связанных друг с другом сервиса. В каждом были данные пользователей (логин, пароль, ФИО, контакты и др.). При изменении в одном месте приходилось через API менять синхронно в другом месте. Это привело к тому, что у нас начали возникать ошибки синхронизации, а работать с ними стало сложнее.
Мы поняли, что такое хранение пользователей неудобно и, так как полностью рефакторить обе системы в одну по-прежнему казалось нецелесообразным, решили вынести пользователей в отдельный микросервис, отвечающий чисто за их хранение и авторизацию. Так возник User API.
Со временем сервис начал расти, появлялись новые фичи и функциональности. И мы продолжили выделять их в отдельные сервисы:
аналитика;
маркетинг;
оплата;
промокоды;
уведомления;
хранилище файлов;
сервис для онлайн-консультаций и т. д.
На этом этапе мы уже приняли как факт, что в основе проекта микросервисная архитектура. Во-первых, потому что это уже работало. Во-вторых, потому что команда росла вместе с проектом, и в итоге мы пришли к простой схеме: один разработчик — один микросервис. Кроме того, это позволяло быстро проверять бизнес-теории и выкидывать неподходящие.

Попытка стандартизировать микросервисы
Проект быстро рос и набирал пользователей. Поэтому, разрабатывая новые микросервисы, мы параллельно обращали внимание и на их недостатки.
Как только сервисы начинают общаться друг с другом, начинают появляться вопросы согласованности и идемпотентности сервисов. Требуются клиенты для общения друг с другом, общие пагинаторы, форматтеры, логеры и т. д. Появляется общая логика обработки данных и многое другое.
Любое изменение или добавление функционала требовало правок во всех микросервисах. Например, реализация оплаты. Нам нужно было на микросервисе мобильного API добавить запросы для добавления карты — Request-Response. После этого абсолютно такие же Request-Response добавить в billing-API. Потом эти же запросы добавить в Gateway’ях, связанных с CloudPayments. А после добавления карты всё это вернуть обратно. И потом такие же запросы делать в сервисе онлайн-консультаций (телевете), чтобы указать, какую карту мы будем использовать при оплате. Для каждого из адаптеров приходилось добавлять в обработку этот реквест.
Обдумав варианты решения проблемы, мы пришли к SDK— набор бандлов для работы с каждым из микросервисов. Общие части, такие как форматтеры логов, базовые клиенты, интерфейсы, мы вынесли в отдельный CoreBundle, предназначенный для уменьшения дублирования.
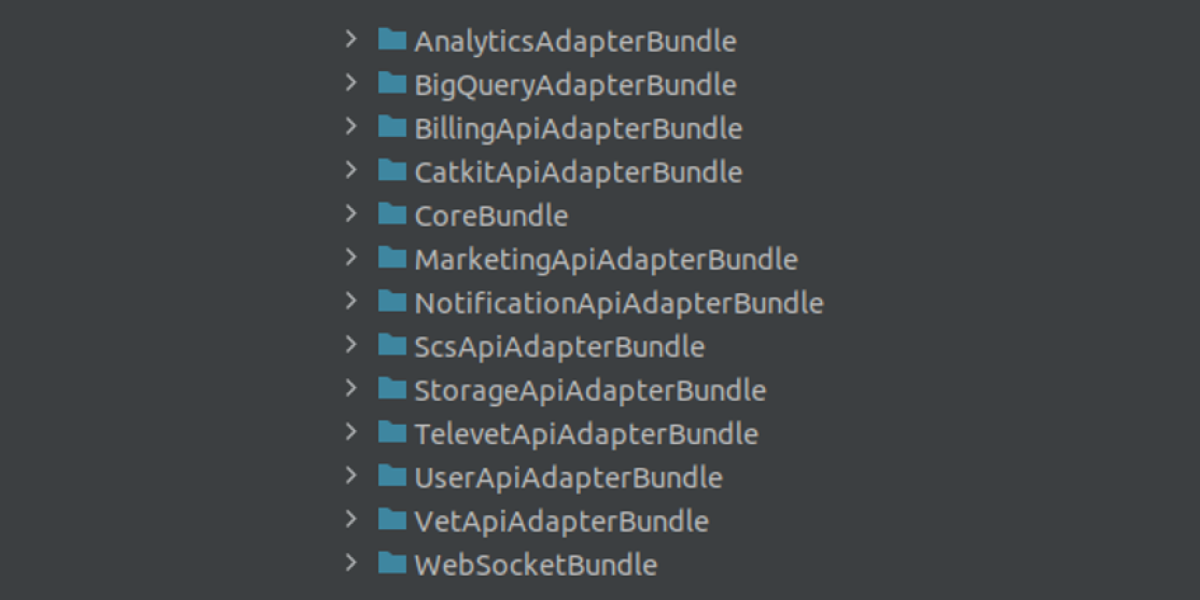
Помимо выноса дублирующего кода, в нем мы также стандартизировали запросы и ответы. В SDK лежали сущности, которые каждый из микросервисов использовал при ответе и аналогичным образом получал при запросе в другой микросервис. В качестве примера создание и обновление плана заботы в SDK используют две сущности запросов:
\TelevetApiAdapterBundle\Request\Catkit\CreateSubscriptionFromPetRequest и \TelevetApiAdapterBundle\Request\Catkit\SubscriptionRequest
https://pastebin.com/XyGSK0ZX
Эти же сущности определённые микросервисы использовали в качестве базовых при получении запроса: https://pastebin.com/TXyBWYqx
И при подготовке ответа:
https://pastebin.com/w77pK2GB
https://pastebin.com/fSFEGNgx
Как пришли к монолиту
Новый подход с единым SDK был удобным, но имел свои минусы.
Сроки реализации многих фичей оказались весьма сжатыми. С каждым новым сервисом мы дорабатывали SDK, выстраивали общие паттерны. Однако старые сервисы оставались нетронутыми. Они требовали рефакторинга, на который не хватало времени. Из-за этого начали появляться проблемы со стандартизацией запросов. Новые сервисы работали по новому стандарту, старые нет.
Помимо этого, нагрузка на наш сервис оказалась не такой высокой, как мы рассчитывали. За всё время работы проекта нам не потребовалось более одного сервиса на каждый из микросервисов.
Возможность использовать разные технологии для микросервисов тоже почти не пригодилась. От идей сложных вычислений и Highload-сервисов отказались, а без них исчезла необходимость в более «выносливых» языках типа Java, Golang и пр. Мы остановились на одном стеке.
Еще одним немаловажным фактором оказался DevOps. У нас не было Kubernetes или Docker Swarm, поэтому процессы CI/CD не были простыми. Приходилось довольно много времени тратить на поддержку инфраструктуры.
Несмотря на солидный возраст проекта, мы всё ещё были стартапом в понимании бизнеса, поэтому микросервисы надо было делать быстро, проверять гипотезы и либо принимать решение развивать дальше, либо выкидывать функционал. Но был и уже устоявшийся функционал, который в таком режиме приходилось постоянно рефакторить.
В какой-то момент мы поняли, что изначально микросервисы нам не полностью подходили. И в конце концов решили, что основные функции, которые концептуально соединены вместе, нам нет смысла разделять. Во-первых, это неудобно для разработки. А во-вторых, когда всё в одном месте, с этим проще работать.
Начали реализовать монолит
Мы взяли один из наших API, который, как нам казалось, сложнее всего переписать, и попробовали на базе него объединить какой-то функционал.
Для решения взяли стандартную структуру Symfony и начали в нее раскладывать все остальные папки, весь остальной функционал. Но было не очень понятно, как это всё структурировать, где лежит функционал, ответственный за фичу. Как пример, папка с сервисами — трудно понять, что относится к какому сервису, где просто деление одного функционала, а где отдельные фичи:
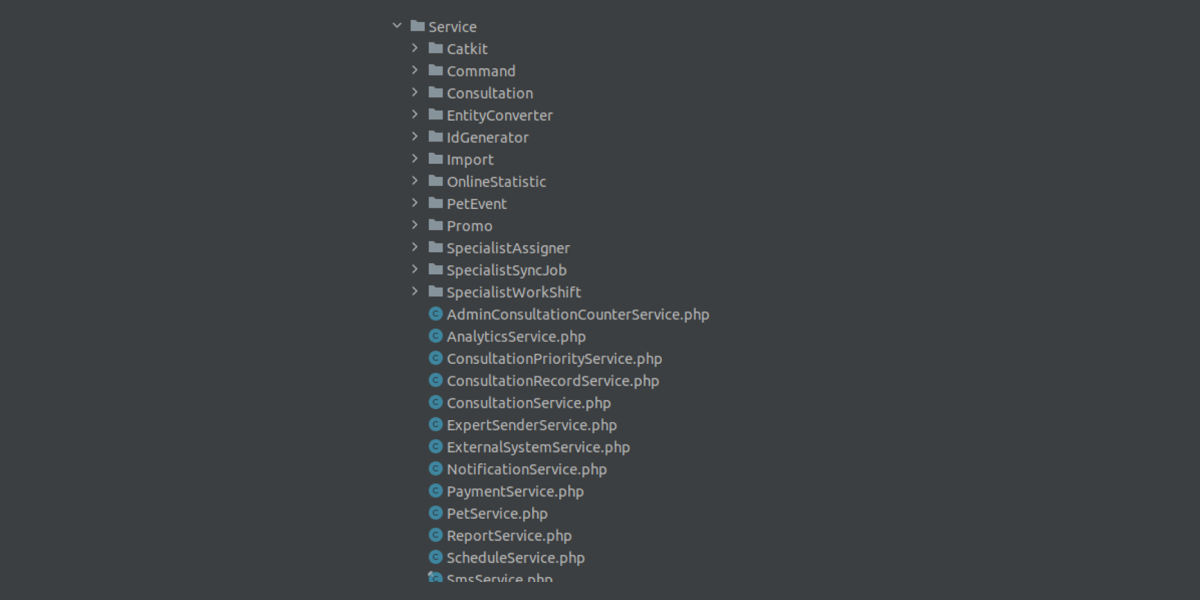
Всё смешалось. Было неясно, какая часть относится к одной части, а какая к другой. Появились очень похожие классы и сущности, которые хотелось положить в общие неймспейсы, но, когда мы их выносили, получалась еще большая путаница.
Например, у нас была подписка на доставку корма, а также подписки на страховку, подписки на консультации и т. д. Когда мы складывали в один неймспейс Entity, становилось сложно отличать их друг от друга. Учитывая, что в корне неймспейса лежали сущности базового сервиса, получалась совсем каша.
Мы поняли, что это чревато ошибками. Поэтому решили найти вариант, который позволит объединить нужные нам сервисы, не переписывая всё разом. В поисках решения пришли к гейтвеям и доменным областям. Они позволяли всё объединить без тотального рефакторинга, решали нашу проблему с многофункциональными контроллерами (которые отвечали за кучу вещей сразу) и в будущем позволяли безболезненно перейти с Symfony 3 на Symfony 4 и дальше.
Мы создали отдельный неймспейс. Туда складывали, как в микросервисы, свой уникальный функционал, но делали это в рамках монолита. Помимо обычных неймспейсов с функционалом, у нас есть два специализированных: General и Gateway. Первый отвечал за общие части, которые используются по всему проекту — базовые типы и расширения доктрины, расширения сериализатора, обработка логов и исключений и т.д. Второй — за взаимодействие с Frontend-частью: мобильным приложением, вебом, различными встраиваемыми виджетами.

По сути, мы получили набор классов — ядро проекта в виде доменных областей, и отдельно — контроллеры, сущности, конвертеры, ошибки и т. д. Это позволяло очень гибко и независимо от других фронтов менять поведение системы, уменьшить размеры запросов и ответов, оставив только необходимые поля, отделить представление от базовой логики всего приложения.
Какие сложности
Из минусов такого подхода — большое количество дублирования кода. Например, среди фич сервиса были консультации и возможность умного подбора корма для домашних животных. Обе фичи одинаково работали как в мобильной, так и в веб-версии. Сущности этого функционала практически идентичны, потому что мы по прежнему должны внедрять новые фичи и иметь возможность быстро их проверять. Любая фича может выйти как MVP, а потом трансформироваться до неузнаваемости или вообще заброситься. За возможность подобной гибкости нам приходится платить дублированием. Но при этом есть и большой плюс. Если вдруг в какой-то момент мы захотим на вебе что-то поменять, это никак не затронет приложение.
Почему вопрос гибкости стал важен для нас? У нас была фича по умному подбору корма, которая умела делать 3 вещи:
обновлять план ухода за питомцем по шагам, заполняя его данные;
генерировать предложение на основе заполненных данных;
выбирать предложение и оплачивать этот план ухода.
Когда мы начали делать для этого админку, мы столкнулись с проблемой, что бизнес-заказчик захотел в ней тоже редактировать предложение, потому что каких-то товаров может не быть. И нам пришлось на основе тех же методов делать административную часть. Так как у администратора было больше возможностей по сравнению с мобильным приложением, приходилось выкручиваться, добавляя новые поля. Это не очень хорошо сказывалось на читаемости и понятности кода. Возникали странные ошибки.
Есть и другие минусы, кроме дублирования. После изменений в фронтовой части нам приходится переделывать еще и Backend. Например, в сервисе есть возможность купить консультации пакетом. У нас был один формат, но дизайнеры его поменяли — сделали другие поля. Поэтому нам пришлось добавить новый контроллер, переделать сущности ответов и конвертеры. То есть, по сути, любое изменение фронта в плане набора данных требовало небольшой переработки бэка. Это из больших минусов, которые мы сейчас решаем — пытаемся уменьшить дублирование кода, придумываем, как избавиться от зависимости от клиентской части и дизайна.
К чему пришли
По сути, теперь у нас микросервисы внутри монолита. Каждая фича — это микросервис в виде доменной области, которая отвечает за свою часть. Эти области мы объединили в рамках одного проекта, чтобы нам было проще с этим работать.
В итоге мы пришли к гибридному подходу. Микросервисы остались. Они заняли свою нишу, прекрасно работают и полностью нас устраивают. Например, сервисы аналитики, хранения файлов, уведомлений и авторизации очень хорошо себя зарекомендовали, с ними удобно работать.
Однако ядро системы стало монолитным. Мы не отказываемся от идеи сервисной архитектуры, однако подход к каждому конкретному сервису сильно изменился.
Вот какие преимущества у такого подхода для разработки:
Мы получили преимущества микросервисов в части системы, где они самобытны.
Упростили CI/CD и DevOps.
Получили более управляемое ядро системы, где удалось стабилизировать и стандартизировать логику.
Экономия на ресурсах.
При этом сохранилась возможность быстро и качественно проверять гипотезы.
Что в итоге
Наш проект не был высоконагруженным. Бизнесу было важно проводить много экспериментов, что поражало хаос как в сервисах, так и в логике взаимодействия. Фича могла выйти в прод, проработать неделю и умереть. Накладные расходы на микросервисы оказались высокими, поэтому мы пришли к грамотной инкапсуляции кода, что позволило спокойно переваривать все теории и фичи бизнеса в монолитной архитектуре.
В совокупности со слабой гибкостью на инфраструктуре мы приняли непростое решение. И оно оказалось весьма удачным. Монолит прекрасно справился, микросервисы стали его поддержкой.
Микросервисы не являются волшебной пилюлей, которая позволяет делать что угодно и снимает с вас головную боль. Микросервисы и есть головная боль. С их гибкостью и масштабированием в проект приходят множество дополнительных проблем: согласованность данных, CAP-теоремы, сложность поддержки, трассировка запросов, требования к инфраструктуре и многое другое.
Тщательно оценивайте проект на старте. Зачастую, даже если кажется, что микросервисы отлично подходят, запускать MVP стоит на монолитной архитектуре.
P.S. Рассказывайте в комментариях, как и почему вы двигались от микросервисов к монолиту или наоборот. Интересно узнать про ваш опыт.



")
