
Привет! Я Александр Иванов, Android-разработчик в компании KODE. Недавно мы проводили митап для студентов лаборатории VibeLab (университет «ЛЭТИ»), где отвечали на вопросы. В статье приведена содержательная часть этой Q&A сессии, которая может оказаться полезной начинающим Android-разработчикам.
Вот о чём меня спрашивали:
Какие сложности бывают с многопоточностью при разработке Android-приложений?
Сабкомпоненты в Dagger DI. Когда есть резон их использовать?
RxJava или Kotlin Coroutines/Flow?
Какой подход использовать для навигации в Android-приложениях?
Сложности с многопоточностью при разработке Android-приложений
Для начала короткий экскурс в проблематику. Корни любой проблемы с многопоточностью с точки зрения Android-разработчика лежат в необходимости решать длительные задачи: сетевые запросы, валидация данных, операции чтения и записи файловой системы и так далее. Если делать это на главном (main) потоке, то он не сможет рендерить пользовательский интерфейс, Android-приложение выбросит ANR ошибку и процесс нашего приложения умрёт. Чтобы этого не произошло, необходимо убрать тяжелые операции с главного потока. Для этого существуют два основных механизма — асинхронность и многопоточность.
Под асинхронностью в контексте нашего обсуждения я предлагаю понимать механизм делегирования решения такой длительной задачи, который позволяет получить результат ее выполнения с помощью обратного вызова (callback).

Не вдаваясь в академические определения, многопоточность я предлагаю условно определить как механизм, который позволяет выделить (в том числе для решения длительных задач) отдельные потоки.

Обычно асинхронность и многопоточность используются вместе: мы делегируем задачу отдельному потоку, он решает её и возвращает результат с помощью обратного вызова.
Поскольку проблемы с написанием асинхронного кода и кода многопоточного имеют различную природу, в рамках ответа на этот вопрос я предлагаю сосредоточиться непосредственно на многопоточности. Механизм многопоточности имеет одну базовую проблему платформенного характера, которую можно проиллюстрировать следующим классическим примером.
Предположим, у нас есть два потока: один смотрит на флаг и читает файл, если флаг true, второй поток устанавливает значение флага в true. В этой задаче события могут развиваться двумя очевидными способами:
Сначала выполнится поток 2, поставит флаг в true, и только затем выполнится поток 1, посмотрит на него и считает файл.
Сначала поток 1 посмотрит на флаг, не прочитает файл, и уже потом поток 2 установит флаг в true.

Это состояние неопределенности, которое возникает, когда задачу выполняют два и более потоков, называется состоянием гонки (race condition). Оно не уникально для Android или JVM, но вообще характерно для всех платформ, где есть многопоточность. Само явление обусловлено структурой памяти. Для нас это выглядит так: на процесс, в котором запускается приложение, выделена общая область памяти (heap), внутри процесса запускается произвольное число потоков, у каждого из которых есть своя локальная память (stack). С локальной памятью потока (stack) всё будет хорошо: она изолирована, с ней ничего не может пойти не так. Общая же память (heap) доступна всем потокам, то есть не изолирована и следовательно уязвима к такого рода ошибкам. Если мы одновременно пишем и читаем в эту общую для всех потоков область памяти, то можем получить состояние гонки.

Из этого следует основное и главное правило борьбы с race condition — по возможности ничего не писать в существующие объекты, только читать и создавать новые объекты.
В отсутствие операций записи читать можно со скольки угодно потоков, двух или тысячи, не имеет значения — память организована таким образом, что просто ничего не может сломаться. Это одна из основных причин по которой Kotlin как язык программирования всячески мотивирует нас использовать иммутабельные (immutable) конструкции языка и структуры данных.

К сожалению, в реальности без мутабельных объектов иногда всё же не обойтись. Для решения проблемы состояния гонки с мутабельными объектами в многопоточном окружении у нас есть следующие средства:
примитивы синхронизации (synchronized, volatile);
относительно «низкоуровневые» инструменты java.util.concurrent: CountDownLatch, Semaphore, CyclicBarrier и так далее;
относительно «высокоуровневые» инструменты — потокобезопасные коллекции, например всеми любимый ConcurrentHashMap.
Код, который написан с использованием «низкоуровневых» инструментов, обычно плохо читается, поэтому в продакшн-среде они встречаются достаточно редко. Чаще всего проблему можно решить используя примитивы синхронизации и потокобезопасные структуры данных.
Если посмотреть на код приложений, при разработке которых применяется подход к построению чистой архитектуры (Clean Architecture) в том или ином его виде, то мы увидим, что проблемы с многопоточностью проявляются главным образом на слое данных (data слое), там, где расположены репозитории и источники данных, потому что сами источники данных могут работать на разных потоках. Более того, если мы видим, что инструменты синхронизации или в целом работа с многопоточностью выходит далеко за пределы слоя данных, то это повод задуматься, что мы сделали неправильно с точки зрения архитектуры — возможно, детали реализации источников данных «протекли» куда не следовало. Естественной средой обитания всего, что связано с многопоточностью, я бы назвал data слой или место сосредоточения и взаимодействия источников данных приложения.
Например до некоторого времени наиболее распространенный паттерн проектирования слоя данных включал в себя кэш на потокобезопасной коллекции в качестве источника данных (in-memory cache). Классический случай использования: мы получаем данные с API бэкэнда, складываем их в кэш, чтобы потом синхронно прочитать когда это будет необходимо. В этом случае естественным образом может возникнуть состояние гонки, когда кто-то из кэша читает данные на одном потоке и в это же самое время другой поток сходил в сеть и решил этот кэш обновить. Отсюда потребность в потокобезопасной коллекции, например ConcurrentHashMap.
У такого подхода есть неприятная особенность: после того как мы записали в кэш новые данные, нам надо с помощью какого-то другого механизма уведомить об этом тех, кто эти данные использует. Проще говоря, этот подход не обладает свойством реактивности.
В настоящее время наиболее распространенным решением в качестве кэша является реактивный источник данных, вроде MutableStateFlow (flow) или BehaviorSubject (rx). Каждый раз когда мы получаем данные из сети и складываем их в кэш, этот источник данных уведомляет своих подписчиков, что про старые данные можно забыть и теперь у нас есть новые. Вместо того чтобы заменять старые данные новыми в некоторой коллекции, наш кэш просто отдает новый объект подписчикам.
Вопрос реактивности как и сколь угодно детальное рассмотрение многопоточности — тема для отдельного обсуждения. Но сам подход хорошо иллюстрирует основную мысль: главный способ борьбы с разного рода проблемами многопоточности — стараться писать код без мутабельных состояний. Понятно, что внутри условный MutableStateFlow сам по себе состоит из примитивов синхронизации, но на уровне клиентской разработки, как правило, следует ограничиться именно тем, чтобы включать иммутабельность везде, где можно. В оставшихся случаях достаточно использовать «высокоуровневые» инструменты вроде потокобезопасных коллекций, Atomic и прочего, но всегда стоит отдавать себе отчёт, не является ли потребность использования таких механизмов синхронизации признаком некорректного проектирования.
К этому вопросу часто примешивают корутины (kotlin coroutines). В некотором смысле они — своего рода абстракция над потоками, поэтому в отношении многопоточности для них справедливо то же самое, что справедливо для потоков, они никак не защищены от состояния гонки. Отличие с точки зрения клиентской разработки — в небольшом количестве специфичных инструментов для синхронизации (это Mutex и Semaphore). Они отличаются от своих товарищей из java.util.concurrent тем, что когда корутина наступает в Mutex или Semaphore, она не блокирует поток, в котором исполняется, а вместо этого сама прерывается (suspends).
RxJava или Kotlin Coroutines/Flow
Начну опять же с постановки проблемы: оба фреймворка предназначены для решения проблем с асинхронностью. Природа проблем с асинхронным программированием происходит не от самой платформы, как в случае с многопоточностью, а связана непосредственно с организацией кода.

Когда мы выполняем асинхронную операцию, то есть делегируем часть работы отдельной сущности, для получения результатов мы используем механизм колбэков — когда наш метод вызывает кто-то извне, передавая в него результат некоторой работы. Когда это происходит однократно никакой проблемы нет, однако если это нужно сделать несколько раз, то мы получаем колбек, вложенный в колбек, вложенный в колбек, что в коде выглядит несколько нелицеприятно. Эту особенность вложенных вызовов принято называть callback hell.

Для борьбы с этой проблемой есть средства только уже не языка, а архитектуры (в противоположность многопоточности: грубо говоря, с платформенными проблемами боремся языком, а с организацией кода — архитектурой). Таким средством можно считать так называемый реактивный подход.
В Android реактивность пришла вместе с RxJava. В настоящее время популярность Rx быстро снижается из-за того, что появились Coroutines Flow.
Для разработки локальных или pet-проектов сейчас лучше не использовать Rx, а смотреть сразу в сторону Coroutines Flow. В реальности у вас вряд ли будет выбор: на больших проектах в продуктовой разработке к вашему приходу туда уже будет что-то использоваться — или Rx, или Coroutines Flow, или и то, и другое сразу (чаще в силу миграции с Rx на Coroutines Flow).
Я могу привести два аргумента, почему большинство проектов используют Coroutines Flow, и мне кажется, что вам тоже стоит:
Rx все асинхронные операции превращает в реактивные вне зависимости от обстоятельств. Если вы когда-то использовали Rx, то вспомните, что когда мы получаем какие-то данные запросом через условный Retrofit, он представляет из себя Single — это данные, которые поэмитятся один раз. Хотя это явно асинхронная, одноразовая операция, мы работаем с ней так, как будто это подписка на реактивный источник данных, несмотря на то что мы заранее знаем, что он эмитит данные всего один раз и потом сразу заканчивается, то есть, в каком-то смысле Single — это реактивный источник данных, раскрывающий детали своей реализации. В Coroutines/Flow понятия «асинхронность» и «реактивность» разделены. Для асинхронности есть suspend-функции, suspension-механизм, который позволяет описывать асинхронные операции декларативным образом. Реактивность же в виде Flow выделена в качестве отдельной абстракции. Писать код с помощью корутин проще, поскольку более естественно ощущается в каком месте нужна реактивность, а в каком она не нужна и достаточно асинхронности.
Второе важное отличие — structured concurrency, это подход, который позволяет «привязывать» scope к логическому жизненному циклу компонента приложения. В Rx такой концепции не было, эту реализацию приходилось делать вручную, что могло привести (и регулярно приводило) к багам и утечкам памяти. Если вы не знакомы с концепцией structured concurrency, то в любом случае следует почитать про это отдельно, это значительное отличие, которое упрощает написание кода в рамках реактивного подхода.
Когда использовать сабкомпоненты в Dagger DI
Следующий вопрос был про DI. Dagger как DI фреймворк отличается от остальных фреймворков тем, что дает нам compile-time гарантии: достаточно ли зависимостей для функционирования всех классов и сущностей, создающихся с помощью DI, видно на этапе компиляции. Это отличие является основной причиной, почему люди вообще используют Dagger — в остальном он не самый удобный фреймворк с точки зрения API.
Помимо непосредственно предоставления зависимостей, у DI-фреймворков есть и другая, не менее важная задача — управление этими зависимостями. Мало того, что мы гарантируем создание нужных нам сущностей для функционирования архитектуры, нам также нужно делать это в правильный момент. За управление зависимостями в Dagger отвечает механизм компонентов и сабкомпонентов.
Сабкомпоненты — это компоненты, которые наследуют и расширяют родительский граф зависимостей. Они используются для разбиения графа зависимостей приложения на подграфы, чаще всего для ограничения жизненного цикла объявленных в таких подграфах зависимостей. Поскольку сабкомпонент должен быть явным образом создан в скоупе родительского компонента, его жизненный цикл имеет четко определенные границы. В целом я бы назвал разбиение графа зависимостей приложения на подграфы одним из основных механизмов DI. Не используя этот механизм мы ограничиваем гибкость DI в нашем приложении.
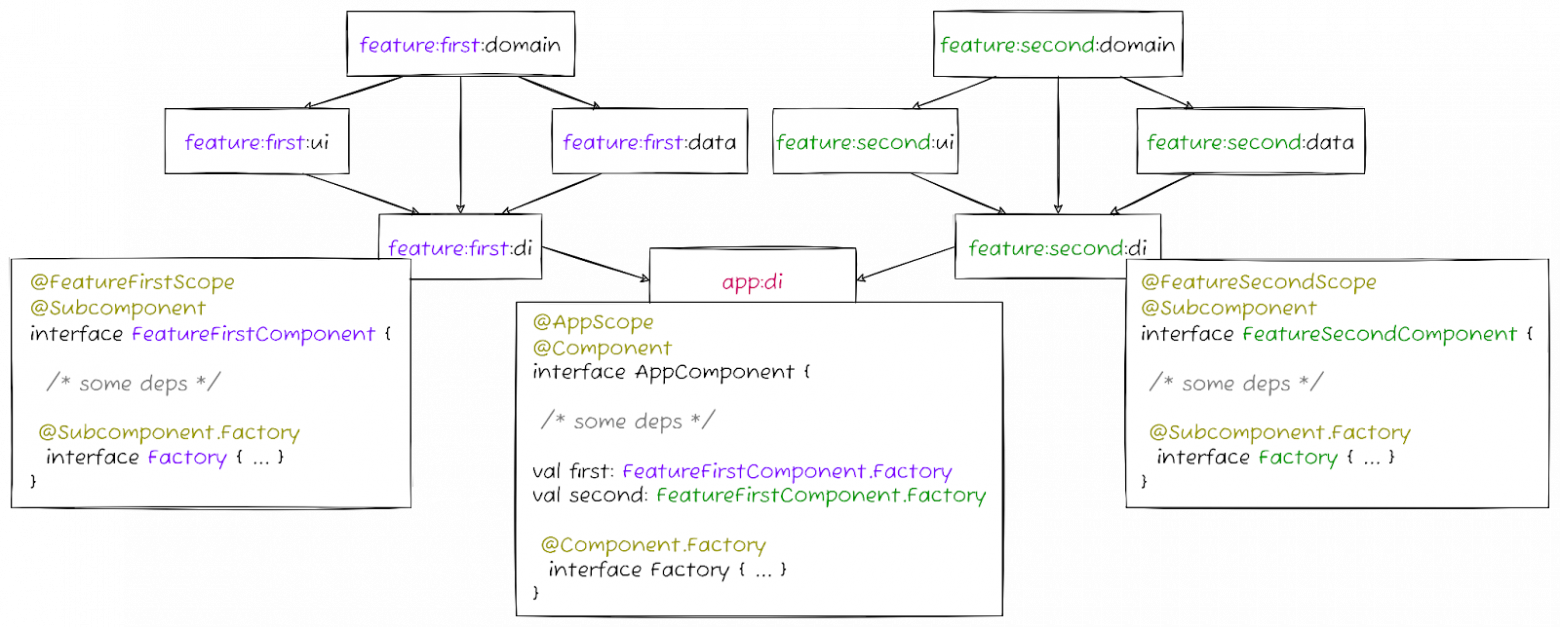
В большинстве реальных проектов такое разбиение работает так: у нас есть фича, разбитая на некоторое количество модулей, например по слоям согласно Clean Architecture, и выделенный DI модуль, который описывает все зависимости этой фичи. Этот DI-модуль с зависимостями фичи как раз и может выступать сабкомпонентом, то есть компонентом Dagger, из которого доступны все зависимости общего для всего приложения компонента (условного app:di модуля), плюс свой собственный скоуп зависимостей, необходимый для работы этой отдельно взятой фичи. Сложность в том, что этот самый компонент фичи нужно в определенный момент создать и в нужный момент позаботиться о том, чтобы после того, как работа с фичей завершена, на этот компонент не осталось ссылок. Другими словами, этот компонент необходимо вручную привязать к жизненному циклу фичи, и для этого никакого специального механизма «из коробки» не предусмотрено.
Из аргументов против использования сабкомпонентов как явления, иногда называют то, что на больших проектах их наличие увеличивает время сборки. Если говорить о структуре модулей в проекте, то я бы начал с того, что если мы в этой схеме заменим Dagger на любой другой DI — Koin, Kodein, Toothpick или ещё какой-то, то модули будут пересобираться ровно так же, как они пересобираются с Dagger. Когда мы меняем что-то в одном из фичевых модулей — пересоберется он сам, DI модуль этой фичи, и общий app:di который от него зависит. Отличие может быть разве что в механизме кодогенерации, используемом Dagger, чтобы гарантировать нам те самые compile-time гарантии, ради которых мы и добавляем его в проект.
Работает эта кодогенерация на kapt. Если у вас в проекте kapt ни для чего другого не используется, то, конечно, разница в скорости сборки действительно будет иметь место. Замечу только, что лично не встречался с проектами, на которых это было бы драматическое количество времени, или хотя бы настолько серьезное, чтобы поднять вопрос о том стоят ли compile-time гарантии потери в скорости сборок. Кроме того, Dagger уже некоторое время обещают переписать на ksp, так что можно надеяться, что он ближайшее время ускорится.
Резюмируя ответ на изначальный вопрос — использовать ли в проекте с Dagger сабкомпоненты — важно понимать зачем вообще они используются. Их основное назначение — делить общий граф зависимостей приложения на подграфы, которые могут в нужный момент создаваться и уничтожаться. Без этого механизма у нас все зависимости будут создаваться и существовать в общем компоненте, что в определённых обстоятельствах приводит к увеличению потребления памяти, потенциально к ее утечкам и связанными с этим багам.
Какой подход использовать для навигации в Android-приложениях
На собеседованиях я часто встречаю и сам задаю вопрос: как вы готовите навигацию? По моему опыту, это болезненный вопрос для Android-разработчиков.
Для навигации существует известный набор популярных библиотек, например Navigation Component, Cicerone, Voyager. У меня создалось впечатление, что Navigation Component сегодня лидирует с большим отрывом, Cicerone понемногу теряет популярность, а Voyager появился недавно, но уже набирает обороты (прошу случайного читателя не принимать мои субъективные ощущения со слов других людей за сколь угодно объективную статистику).
Если взять стартовавший за последний год «средний по больнице» проект, то мы увидим в нем Navigation Component + MVVM с навигацией между экранами — composable функциями или фрагментами — прямо в composable функции экрана, фрагменте, или в лучшем случае во ViewModel. Дальше логика навигации как правило никак не абстрагирована, всё происходит около view, то есть на ui слое, если говорить терминами условной Clean Architecture.
По правде говоря, более важным вопросом в контексте обсуждения навигации я считаю не выбор библиотеки, то есть движка навигации, а скорее проектирование вокруг него удобной абстракции. Так что, отвечая на вопрос как мы готовим навигацию, я бы хотел сосредоточиться именно на том, какие абстракции удобно выделить и как в целом мы подходим к проектированию.
Для примера рассмотрим некоторую фичу в нашем приложении. Для начала стоит договориться о том, что мы считаем фичей. В контексте нашей архитектуры фичей принято называть некоторый сценарий, то есть последовательность экранов, объединенных общей идеей. В банковском приложении это может быть последовательность экранов, которая приводит к выпуску карты клиентом. У фичи есть свои зависимости: есть ui, который состоит из одного или нескольких экранов, есть слой данных со своими репозиториями, доменная логика, и есть некий общий модуль, в который всё сводится.
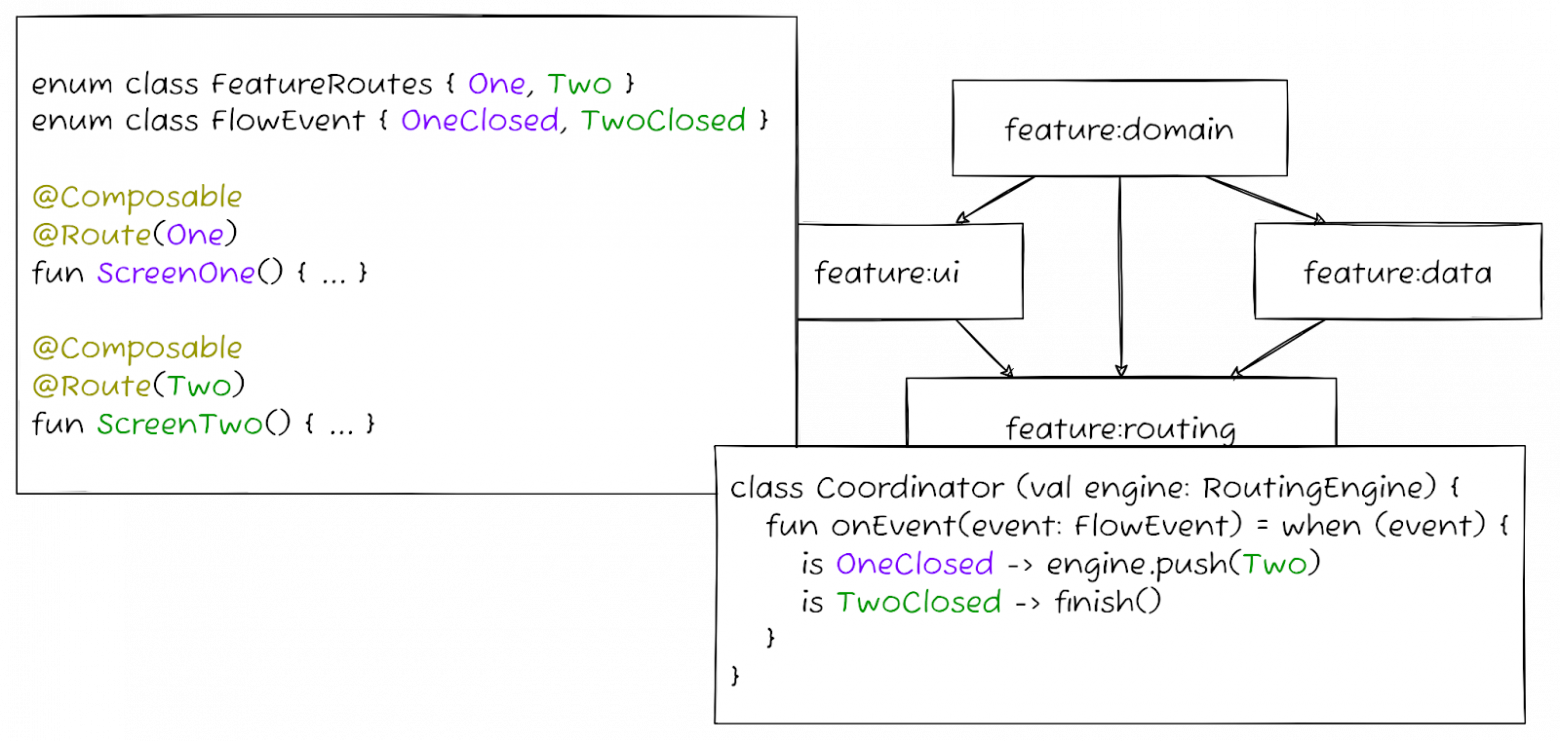
В нашей архитектуре этот общий модуль объединяет собой навигацию и di. Такое решение в частности было принято в связи с тем, что нам нужна точка в приложении, где можно получить информацию о том, когда следует инициализировать зависимости фичи-сценария и когда эти зависимости следует потерять. Практика показывает, что такую информацию проще всего получить именно в том месте, где происходит управление сценарием, то есть в той части логики, которая непосредственно управляет переключением экранов — именно в ней мы можем понять, когда сценарий как последовательность экранов запустился и когда он закончился. Именно поэтому точкой входа для графа зависимостей сценария-фичи выбрана навигация: в наш модуль навигации инкапсулирована абстракция для логики переключения экранов, а также абстракция для инициализации зависимостей сценария.
Для реализации такой логики ui модуль поставляет в модуль навигации информацию о зарегистрированных в сценарии экранах (Routes) и абстрактных событиях навигации (Event). И то, и другое не зависит от конкретной реализации в ui модуле — информация о зарегистрированных экранах в простом случае — строка без каких-либо знаний о том, composable это, fragment, controller, activity или что-либо другое, в целом идеология этого подхода примерно та же, что и у подхода к построению графа навигации в Navigation Component. События навигации (Event) в свою очередь — просто условное событие, по которому логика, управляющая переключением экранов в сценарии, принимает решение на какой экран пойти.
Именно эта концепция представляется мне наиболее интересной и заслуживающей обсуждения. Движок навигации, который обозначен как RoutingEngine, это уже конкретная реализация механизма переключения экранов, которая может быть как раз сделана на любой из озвученных библиотек или любой другой — это представляется мне вопросом второстепенной важности. В своих проектах мы используем простую анимированную смену Composable-функций, поставляемых через фабрики экранов.

Это решение может показаться излишним усложнением, в особенности для небольших проектов, насчитывающих не более дюжины экранов. Однако я считаю важным подчеркнуть основные аргументы в пользу необходимости такой или подобной абстракции в более крупных проектах:
Возможность переиспользовать экраны в разных сценариях. Если все экраны будут жестко связаны друг с другом условиями переходов, переиспользовать их в другом контексте не получится: если в коде экрана А написано, что с него мы идем на экран Б, то единственный способ пойти на экран В — это поставить в код экрана А явное условие.
Логика (а навигация это тоже логика), которая протекает во view, как известно, достаточно плохо влияет на качество и поддержку кода. Условия из предыдущего пункта копятся со временем и их становится не то чтобы сложно поддерживать, а даже просто читать.



