
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Добрый день, увадаемые читатели.
В прошлом году я работал над одним интересным проектом по оживлению портрета с помощью технологии Realistic Neural Talking Head Models на основе генеративных нейронных сетей. В проекте я использовал разработку центра Samsung AI в Москве под названием Few-Shot Adversarial Learning of Realistic Neural Talking Head Models. В этой статье я расскажу как можно попробовать эту технологию на практике. Кому интересно, прошу под кат.

О разработке Neural Talking Head Models можно прочитать в статье авторов.
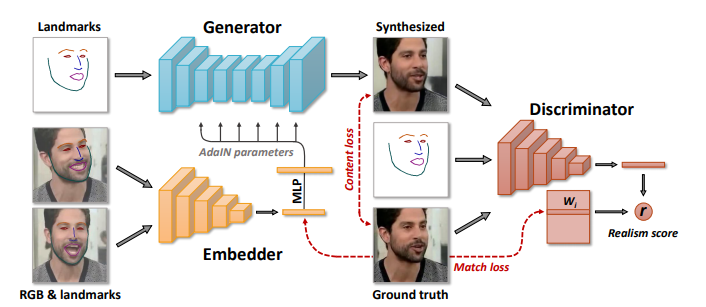
Здесь мы будем использовать реализацию подхода на PyTorch из этого репозитория. Автор реализации Vincent Thévenin — исследователь из французского De Vinci Innovation Center.
Начнем работу с Realistic-Neural-Talking-Head-Models. Лучше использовать Python версии 3 чтобы избежать возможных проблем с пакетами. Клонируем репозиторий и переходим в папку.
Скачаем необходимые файлы отсюда. У нас появятся два файла: Pytorch_VGGFACE_IR.py (PyTorch код) и Pytorch_VGGFACE.pth (Pytorch модель).
Нам не нужно обучать модель, так как автор предоставил нам предобученные веса на Google Drive.
Установим необходимые библиотеки matplotlib, opencv и face_alignment
Нам также нужно установить драйвер NVIDIA, который требуется для запуска embedder_inference.py. Скачать драйвер NVIDIA для вашего конкретного GPU можно отсюда. Например для Tesla K80
Сделаем файл исполняемым и установим драйвер:
В некоторых случаях этот вариант падает с ошибкой «fails due to X server» (подробно описано здесь).
Можно установить драйвер NVIDIA другим способом. Сначала узнаем какой графический драйвер подходит для нашей системы:
Затем установим рекомендуемый драйвер NVIDIA и сделаем ребут:
Наконец нам нужно установить PyTorch согласно установленной версии CUDA. Узнаем какая версия CUDA установлена в системе
Скажем у нас стоит CUDA v10.1
Перейдите на сайт PyTorch и выберите соответствующую инструкцию для вашей ОС по установке PyTorch
Давайте запустим embedder (embedder_inference.py) на видео или изображениях человека и сгенерируем эмбеддинг вектор:
Результат:
Вы получите два файла: e_hat_images.tar и e_hat_video.tar. Давайте запустим finetuning_training.py:
Вывод будет таким:
Введем 1 для изображений
Скрипт выполняет обучение на изображениях.
В результате мы получим примерно такое изображение
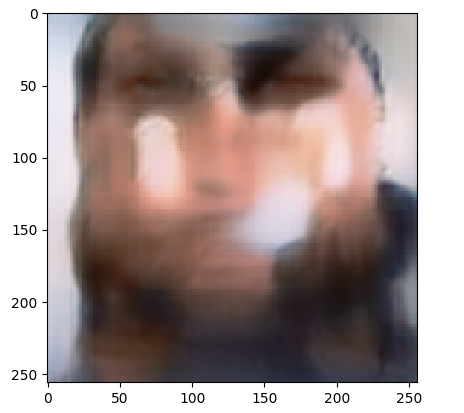
Видно, что качество результата низкое.
Теперь попробуем обучение на видео
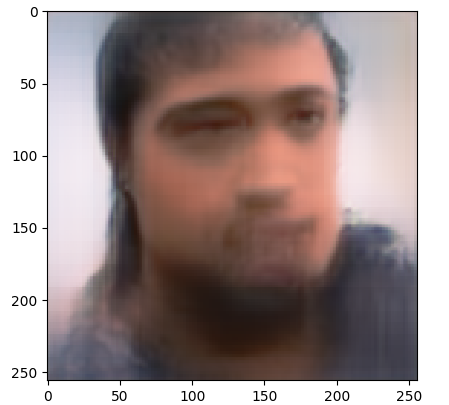
В этот раз значения функции потерь ниже и конечный результат выглядит лучше.
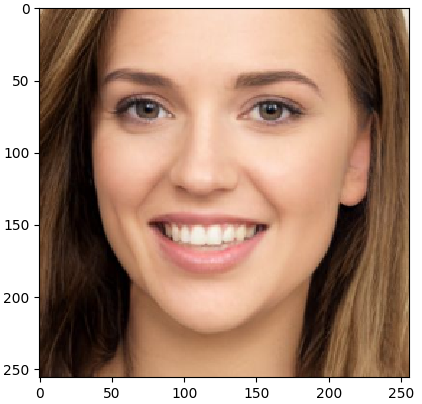
Результат обучения finetuning_training на нашем собственном изображении
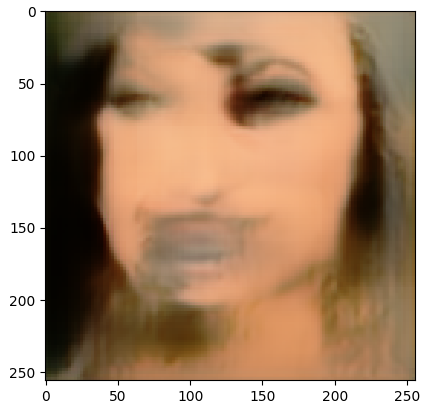
и оригинал
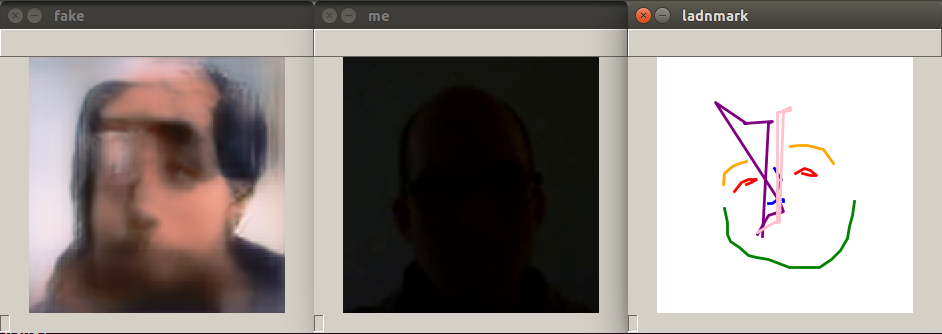
Здесь также есть скрипт webcam_inference.py для тестирования генерации изображений по видео с камеры. Запустим the webcam_inference.py
Этот скрипт запускает модель на основе персоны из вектора эмбеддинга и потока с камеры, выполняет только инференс. Скрипт генерирует три изображения: facial landmark, оригинал (фото с камеры) и фейк. В этот раз инференс выполняется на модели дообученной на видео


Сейчас попробуем модель дообученную на изображениях
Инференс выполняется очень медленно. У меня запуск занял несколько минут на виртуалке на Google Cloud с NVIDIA GPU.
Мы можем переобучить генератор на видео чтобы получить лучше результат. Автор проекта утверждает, что генератор был обучен на 5 эпохах что не является оптимальным.
Для обучения мы можем использовать датасет VoxCeleb2. Чтобы скачать датасет вы должны запросить доступ к нему заполнив специальную форму.
Датасет разбит на 9 частей. Для скачивания всего датасета вы можете воспользоваться моим bash скриптом, доступным на github. Запустим скрипт для загрузки датасета
Внимание: каждая часть датасета весит 30GB (весь датасет 270GB).
Как только все части датасета загружены их нужно смерджить в один архив:
Изменим путь до папки mp4 с видео для обучения в файле train.py (строка 21):
Сейчас запустим скрипт train.py
Он выведет в терминал следующее
На этом все. Можно оживить любые фото, в том числе фото исторических личностей и картины (н-р, Мону Лизу). Успехов вам в оживлении фото!
В прошлом году я работал над одним интересным проектом по оживлению портрета с помощью технологии Realistic Neural Talking Head Models на основе генеративных нейронных сетей. В проекте я использовал разработку центра Samsung AI в Москве под названием Few-Shot Adversarial Learning of Realistic Neural Talking Head Models. В этой статье я расскажу как можно попробовать эту технологию на практике. Кому интересно, прошу под кат.
О разработке Neural Talking Head Models можно прочитать в статье авторов.
Здесь мы будем использовать реализацию подхода на PyTorch из этого репозитория. Автор реализации Vincent Thévenin — исследователь из французского De Vinci Innovation Center.
Начнем работу с Realistic-Neural-Talking-Head-Models. Лучше использовать Python версии 3 чтобы избежать возможных проблем с пакетами. Клонируем репозиторий и переходим в папку.
git clone https://github.com/vincent-thevenin/Realistic-Neural-Talking-Head-Models.git
cd Realistic-Neural-Talking-Head-Models
Скачаем необходимые файлы отсюда. У нас появятся два файла: Pytorch_VGGFACE_IR.py (PyTorch код) и Pytorch_VGGFACE.pth (Pytorch модель).
Нам не нужно обучать модель, так как автор предоставил нам предобученные веса на Google Drive.
Установим необходимые библиотеки matplotlib, opencv и face_alignment
pip install matplotlib opencv-python face_alignment
sudo apt-get install python-tk
Нам также нужно установить драйвер NVIDIA, который требуется для запуска embedder_inference.py. Скачать драйвер NVIDIA для вашего конкретного GPU можно отсюда. Например для Tesla K80
wget http://us.download.nvidia.com/tesla/440.33.01/NVIDIA-Linux-x86_64-440.33.01.runСделаем файл исполняемым и установим драйвер:
chmod +x NVIDIA-Linux-x86_64-440.33.01.run
sudo ./NVIDIA-Linux-x86_64-440.33.01.run
В некоторых случаях этот вариант падает с ошибкой «fails due to X server» (подробно описано здесь).
Можно установить драйвер NVIDIA другим способом. Сначала узнаем какой графический драйвер подходит для нашей системы:
ubuntu-drivers devicesЗатем установим рекомендуемый драйвер NVIDIA и сделаем ребут:
sudo apt-get install nvidia-384Наконец нам нужно установить PyTorch согласно установленной версии CUDA. Узнаем какая версия CUDA установлена в системе
nvcc --versionСкажем у нас стоит CUDA v10.1
Cuda compilation tools, release 10.1, V10.1.243Перейдите на сайт PyTorch и выберите соответствующую инструкцию для вашей ОС по установке PyTorch
pip install torch torchvisionДавайте запустим embedder (embedder_inference.py) на видео или изображениях человека и сгенерируем эмбеддинг вектор:
python embedder_inference.pyРезультат:
Saving e_hat...
...Done saving
Вы получите два файла: e_hat_images.tar и e_hat_video.tar. Давайте запустим finetuning_training.py:
python finetuning_training.pyВывод будет таким:
What source to finetune on?
0: Video
1: Images
Введем 1 для изображений
Downloading: "https://download.pytorch.org/models/vgg19-dcbb9e9d.pth" to /home/vladimir/.cache/torch/checkpoints/vgg19-dcbb9e9d.pth
...
avg batch time for batch size of 1 : 0:00:12.463398
[0/40][0/1] Loss_D: 2.0553 Loss_G: 5.2649 D(x): 1.0553 D(G(y)): 1.0553Скрипт выполняет обучение на изображениях.
В результате мы получим примерно такое изображение
Видно, что качество результата низкое.
Теперь попробуем обучение на видео
avg batch time for batch size of 1 : 0:00:13.738919
[0/40][0/1] Loss_D: 2.0539 Loss_G: 3.3976 D(x): 1.0539 D(G(y)): 1.0539В этот раз значения функции потерь ниже и конечный результат выглядит лучше.
Результат обучения finetuning_training на нашем собственном изображении
и оригинал
Здесь также есть скрипт webcam_inference.py для тестирования генерации изображений по видео с камеры. Запустим the webcam_inference.py
python webcam_inference.py
Этот скрипт запускает модель на основе персоны из вектора эмбеддинга и потока с камеры, выполняет только инференс. Скрипт генерирует три изображения: facial landmark, оригинал (фото с камеры) и фейк. В этот раз инференс выполняется на модели дообученной на видео
Сейчас попробуем модель дообученную на изображениях
Инференс выполняется очень медленно. У меня запуск занял несколько минут на виртуалке на Google Cloud с NVIDIA GPU.
Мы можем переобучить генератор на видео чтобы получить лучше результат. Автор проекта утверждает, что генератор был обучен на 5 эпохах что не является оптимальным.
Для обучения мы можем использовать датасет VoxCeleb2. Чтобы скачать датасет вы должны запросить доступ к нему заполнив специальную форму.
Датасет разбит на 9 частей. Для скачивания всего датасета вы можете воспользоваться моим bash скриптом, доступным на github. Запустим скрипт для загрузки датасета
sh download.sh
Внимание: каждая часть датасета весит 30GB (весь датасет 270GB).
Как только все части датасета загружены их нужно смерджить в один архив:
cat vox2_dev* > vox2_mp4.zip
Изменим путь до папки mp4 с видео для обучения в файле train.py (строка 21):
path_to_mp4 = '../../Data/vox2_mp4/dev/mp4'
dataset = VidDataSet(K=8, path_to_mp4 = path_to_mp4, device=device)Сейчас запустим скрипт train.py
python train.pyОн выведет в терминал следующее
Initiating new checkpoint...
...Done
Downloading the face detection CNN. Please wait...
Downloading the Face Alignment Network(FAN). Please wait...
На этом все. Можно оживить любые фото, в том числе фото исторических личностей и картины (н-р, Мону Лизу). Успехов вам в оживлении фото!



