
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Привет, меня зовут Андрей Щукин, я помогаю крупным компаниям мигрировать сервисы и системы в Облако КРОК. Вместе с коллегами из компании Southbridge, которая проводит в учебном центре «Слёрм» курсы по Kubernetes, мы недавно провели вебинар для наших заказчиков.
Я решил взять материалы отличной лекции Павла Селиванова и написать пост для тех, кто ещё только начинает работать с инструментами provisioning’а облаков и не знает, с чего начать. Поэтому я расскажу про стек технологий, которые используются у нас в обучении и продакшене Облака КРОК. Поговорим о современных подходах к управлению инфраструктурой, про связку компонентов Packer, Terraform и Ansible, а также про инструмент Kubeadm, с помощью которого мы будем производить установку.
Под катом будет много текста и конфигов. Материала много, поэтому я добавил навигацию по посту. Также мы подготовили небольшой репозиторий, куда сложили всё необходимое для нашего учебного деплоя.
Не давайте имён курам
Печёные пирожки полезнее жареных
Начинаем печь. Packer
Terraform — инфраструктура как код
Запуск Terraform
Структура кластера Kubernetes
Kubeadm
Репозиторий со всеми файлами
Не давайте имён курам

Существует множество различных концепций управления инфраструктурой. Одна из них называется Pets vs. Cattle, то есть «домашние животные против сельскохозяйственного скота». Данная концепция описывает два противоположных подхода к инфраструктуре.
Представим, что у нас есть любимая собака. Мы заботимся о ней, водим к ветеринару, вычёсываем шёрстку, и вообще она для нас уникальная и неповторимая среди множества других собак.
В другом случае у нас есть курятник. Мы тоже заботимся о курах, кормим, обогреваем и стараемся создать максимально комфортные условия. Тем не менее куры для нас — довольно безликий ресурс, который выполняет свою функцию несения яиц, и мы в лучшем случае обозначаем их как «вон та припорошенная чёрная, которая вечно клюёт цемент». Если курица перестанет нести яйца или сломает лапу, то, скорее всего, просто обеспечит нам вкусный бульон на обед. По сути, мы заботимся не о судьбе отдельной курицы, а о курятнике в целом как о производственной линии.
В ИТ схожий подход стал применяться, как только появились инструменты, снижающие порог входа для инженеров и позволяющие развёртывать и обслуживать сложные кластеры в полностью автоматическом режиме.
Раньше у нас было небольшое число серверов, за которыми следили, тюнинговали вручную и всячески ухаживали. В мониторинге мелькали логи с серверов «Cthulhu», «Aylith» и «Dagon». Традиции.
Потом виртуализация прочно вошла в нашу жизнь, и имена из произведений Лавкрафта и Star Trek уступили более утилитарным «vlg-vlt-vault01.company.ru». Серверов стало много, но мы по-прежнему поднимали сервисы более или менее вручную, устраняя проблемы на каждой машине при необходимости.
Сейчас подход в обслуживании инфраструктуры полностью совпадает с программированием. Мы добавляем ещё один уровень абстракции и перестаём заморачиваться по поводу отдельных узлов. У каждого — безликий индекс вместо имени, и в случае проблемы виртуальная машина просто убивается и поднимается из рабочего снапшота. Есть инструменты, которые позволяют реализовывать такой подход. В нашем случае первый инструмент — Облако КРОК, второй — Terraform.
Печёные пирожки полезнее жареных

В управлении инфраструктурой есть противопоставление двух подходов Fried vs. Baked, то есть «жареное против печёного».
Fried-подход подразумевает, что у вас есть ванильный образ ОС, например, CentOS 7. Потом после деплоя ОС мы используем систему управления конфигурацией для того, чтобы привести систему в целевое состояние. Например, с помощью Ansible, Chef, Puppet или SaltStack.
Всё отлично работает, особенно когда серверов не очень много. Когда возникает необходимость в массовом деплое, мы сталкиваемся с проблемами производительности. Сотни серверов синхронно начинают пожирать сетевые ресурсы, CPU, RAM и IOPS в процессе накатывания множества новых пакетов. Более того, процесс этот может затягиваться на довольно продолжительное время. Короче, схема абсолютно рабочая, но уже не такая интересная с точки зрения минимизации простоя при авариях.
Baked-подход подразумевает, что у вас есть готовые «запечённые» образы ОС, на которые уже установили все необходимые пакеты, настроили конфигурацию и всё остальное. На выходе у нас есть абстрактный снапшот-шаблон, заточенный под выполнение какой-то функции. Развёртывание инфраструктуры из таких запечённых образов занимает значительно меньше времени и позволяет снизить простой до минимума. Очень похожая идеология используется в многослойных образах Docker, в которые никто не лезет руками без необходимости. Прибили контейнер — подняли новый.
Начинаем печь. Packer

В нашей инфраструктуре мы используем несколько продуктов компании Hashicorp, некоторые из которых получились на редкость удачными. Начнём нашу магию с подготовки и запекания образа с помощью инструмента Packer.
Packer использует JSON Template, т. е. файлы шаблонов, в которых есть описание того, что необходимо получить в качестве «запечённой» виртуальной машины (ВМ). После создания шаблона файл передаётся в Packer, и настраиваются необходимые разрешения для создания сервера в облаке.
Packer позволяет поднять ВМ локально в KVM, VirtualBox, Vagrant, AWS, GCP, Alibaba Cloud, OpenStack и т. д. С Packer удобно работать в Облаке КРОК, так как оно у нас реализует интерфейсы AWS, то есть все инструменты, которые написаны для AWS, работают и с Облаком КРОК.
После задания необходимых шаблонов Packer поднимает в Облаке КРОК ВМ, ожидает её запуска, а далее в работу вступает «поставщик» — provisioner: утилита, которая должна выполнить подготовку образа. В нашем случае это Ansible, хотя Packer может работать и с другими вариантами.
Когда ВМ готова, Packer создаёт её образ и помещает его в Облако КРОК, чтобы другие ВМ можно было запускать из этого же образа.
Структура base.json
В начале файла есть секция, в которой объявляются переменные:
Спойлер
"variables" : {
"source_ami_name": "{{env `SOURCE_AMI_NAME`}}",
"ami_name": "{{env `AMI_NAME`}}",
"instance_type": "{{env `INSTANCE_TYPE`}}",
"kubernetes_version": "{{env `KUBERNETES_VERSION`}}",
"docker_version": "{{env `DOCKER_VERSION`}}",
"subnet_id": "",
"availability_zone": "",
},Основной набор этих переменных будет задаваться из файла settings.json. А те переменные, которые часто меняются, удобнее задавать из консоли при запуске Packer и сборке нового образа.
Далее следует секция Builders:
Спойлер
"builders" : [
{
"type": "amazon-ebs",
"region": "croc",
"skip_region_validation": true,
"custom_endpoint_ec2": "https://api.cloud.croc.ru",
"source_ami": "",
"source_ami_filter": {
"filters": {
"name": "{{user `source_ami_name`}}"
"state": "available",
"virtualization-type": "kvm-virtio"
},
...Здесь описаны целевые облака и метод запуска ВМ. Обратите внимание, что в данном случае объявлен тип amazon-ebs, но для работы Packer с Облаком КРОК задан соответствующий адрес в custom_endpoint_ec2. Наша инфраструктура имеет API, почти полностью совместимое с Amazon Web Services, поэтому, если у вас есть готовые наработки под эту платформу, то вам по большей части нужно будет только указать кастомную точку входа API — api.cloud.croc.ru в нашем примере.
Стоит отдельно отметить секцию source_ami_filter. Здесь задаётся первоначальный образ ВМ, в которую будут внесены необходимые изменения. Однако Packer требует AMI этого образа, т. е. его случайный идентификатор. Поскольку этот идентификатор редко известен заранее и меняется с каждым обновлением, AMI источника задаётся не как конкретная величина, а как переменная source_ami_filter. В данном случае определяющим параметром фильтра является имя образа. Это имя задано в переменных через файл settings.json.
Далее определены настройки ВМ: заданы тип инстанса, процессор, объём памяти, выделяемое место и т. д.:
Спойлер
"instance_type": "{{user `instance_type`}}",
"launch_block_device_mappings": [
{
"device_name": "disk1",
"volume_type": "io1",
"volume_size": "8",
"iops": "1000",
"delete_on_termination": "true"
}
],Следом в base.json определены параметры подключения к данной ВМ:
Спойлер
"availability_zone": "{{user `availability_zone`}}",
"subnet_id": "{{user `subnet_id`}}",
"associate_public_ip_address": true,
"ssh_username": "ec2-user",
"ami_name": "{{user `ami_name`}}"
Здесь важно отметить параметр subnet_id. Его необходимо задать вручную, поскольку без указания подсети ВМ в Облаке КРОК создать нельзя.
Еще один параметр, требующий предварительной подготовки, — associate_public_ip_address. Необходимо выделить белый IP-адрес, поскольку после создания ВМ Packer начнёт применять нужные настройки посредством Ansible. При этом Ansible подключается к ВМ через SSH, что требует наличия белого IP-адреса или VPN.
Последняя секция — это Provisioners:
Спойлер
"provisioners": [
{
"type": "ansible",
"playbook_file": "playbook.yml",
"extra_arguments": [
"--extra-vars",
"kubernetes_version={{user `kubernetes_version`}}",
"--extra-vars",
"docker_version={{user `docker_version`}}"
]
}
]Это поставщики, т. е. утилиты, с помощью которых Packer настраивает сервер. В данном случае используется поставщик типа ansible. Далее следует параметр playbook_file, который определяет роли Ansible и хосты, на которых заданные роли будут применяться. Чуть ниже представлены дополнительные параметры extra_arguments, которые при запуске Ansible передают версии Kubernetes и Docker.
Подготовка Облака КРОК

Помимо наших конфигурационных файлов, нужно сделать несколько вещей со стороны панели управления облаком, чтобы вся магия заработала. Нам нужно выделить белый IP и создать рабочую подсеть, которую мы будем использовать при деплое.
- Нажмите «Выделить адрес». При этом Packer найдёт нужный белый IP-адрес самостоятельно.
- Нажмите «Создать подсеть» и укажите подсеть и маску.
- Скопируйте ID подсети.
- Вставьте это значение в параметр subnet_id в команде запуска Packer.

После этого запустите Packer. Он находит исходный образ ВМ, разворачивает её в Облаке КРОК и выполняет на ней Ansible-роль. Новую ВМ можно увидеть в Облаке КРОК в разделе «Экземпляры».
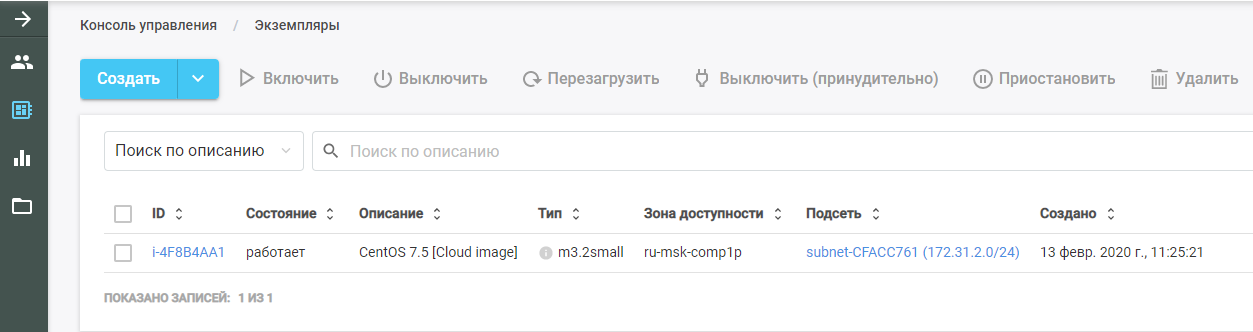

После окончания работы Packer удаляет ВМ из облака и оставляет на её месте готовый образ, который можно найти в разделе «Шаблоны». Из этого образа будет создана вся инфраструктура Kubernetes.
Ansible
Как упоминалось ранее, в параметрах поставщика Ansible передаётся параметр playbook. Сам файл playbook.yml выглядит так:
- hosts: all
become: true
roles:
| - baseФайл передаёт в Ansible, что на всех хостах необходимо выполнять роль base. При наличии других ролей их можно добавлять в этот же файл списком.
Роль base позволяет получить готовый кластер посредством одной команды. Файл main.yml показывает, что именно делает эта роль:
- Добавляет в шаблон системы репозиторий Docker.
- Добавляет в шаблон системы репозиторий Kubernetes.
- Устанавливает необходимые пакеты.
- Создаёт директорию для конфигурации Docker-демона.
- Конфигурирует машину согласно файлу конфигурации daemon.json.j2.
- Загружает ядро br_netfilter.
- Включает необходимые параметры для br_netfilter.
- Включает компоненты Docker и Kubelet.
- Запускает Docker в ВМ.
- Выполняет команду, которая скачивает образы Docker, необходимые для работы Kubernetes.
При этом устанавливаемые пакеты задаются в файле main.yml из каталога vars. В нашем случае мы устанавливаем пакет docker-ce, а также три пакета, необходимых для работы Kubernetes: kubelet, kubeadm и kubectl.
Terraform — инфраструктура как код

Terraform — это очень функциональный инструмент от HashiCorp для оркестрации облаков. У него свой специфический язык HCL, который часто используется и в других продуктах компании, например, в HashiCorp Vault и Consul.
Основной принцип схож со всеми системами управления конфигурацией. Вы просто указываете целевое состояние в нужном формате, а система рассчитывает алгоритм, как этого достичь. Другое дело, что в отличие от того же Ansible, который на сложных плейбуках работает как чёрный ящик, Terraform может выдать план будущих действий в удобном для анализа виде. Это важно при планировании сложных изменений в инфраструктуре. Спланировав нужные действия, выполните команду terraform apply — и Terraform развернёт инфраструктуру, описанную в файлах.
Как и Packer, этот инструмент поддерживает AWS, GCP, Alibaba Cloud, Azure, OpenStack, VMware и т. д.
Описываем проект
В директории Terraform есть набор файлов с расширением .tf. В этих файлах описаны компоненты инфраструктуры, с которой мы будем работать. Разбивайте проект на функциональные модули. Такая структура позволяет проще управлять версионированием и собирать каждый проект из готовых удобных блоков. Для нашего варианта подойдёт следующая структура:
- main.tf
- network.tf
- security_groups.tf
- master.tf
- master.tpl
Структура файла main.tf
Начнём с файла main.tf, в котором настраивается доступ к облаку. В частности, объявляется несколько параметров, которые настраивают Terraform для работы с Облаком КРОК:
provider "aws" {
endpoints {
ec2 = "https://api.cloud.croc.ru"
}Кроме того, в файле описано, что Terraform должен самостоятельно создать приватный ключ и загрузить его публичную часть на все серверы. Сам приватный ключ выдаётся по окончании работы Terraform:
resource "tls_private_key" "ssh" {
algorithm = "RSA"
}
resource "aws_key_pair" "kube" {
key_name = "terraform"
public_key = "${tls_private_key.ssh.public_key_openssh}"
}
output "ssh" {
value = "${tls_private_key.ssh.private_key_pem}"
}
Структура файла network.tf
В этом файле описываются сетевые компоненты, необходимые для запуска ВМ:
Спойлер
data "aws_availability_zones" "az" {
state = "available"
}
resource "aws_vpc" "kube" {
cidr_block = "${var.vpc_cidr}"
}
resource "aws_eip" "master" {
count = "1"
vpc = true
}
resource "aws_subnet" "private" {
vpc_id = "${aws_vpc.kube.id}"
count = "${length(data.aws_availability_zones.az.names)}"
cidr_block = "${var.private_subnet_cidr_list[count.index]}"
availability_zone = "${data.aws_availability_zones.az.names[count.index]}"
}В Terraform используются два типа компонентов:
- resource — что необходимо создать;
- data — что необходимо получить.
В данном случае параметр data указывает, что Terraform должен получить зоны доступности заданного облака, которые находятся в состоянии available.
Первый параметр resource описывает создание виртуального частного облака, а следующий параметр описывает создание Elastic IP Address. Для кластера Kubernetes мы заказываем этот IP-адрес через Terraform.
Далее в каждой из зон доступности, а их на данный момент у КРОК Облачные сервисы две, создаётся собственная подсеть. Объявляется создание ресурса типа aws_subnet, и в рамках этого параметра передаётся ID создаваемой aws_vpc. Но, поскольку ID этого ресурса ещё неизвестен, мы указываем параметр aws_vpc.kube.id, который обращается к созданному ресурсу и подставляет значение из поля ID.
Поскольку количество создаваемых подсетей определяется количеством зон доступности облака и это количество может со временем меняться, данный параметр задаётся через переменную length (data.aws_availability_zones.az.names), т. е. длину списка зон доступности, полученного через параметр data.
Последние два параметра — это cidr_block (выделяемая подсеть) и зона доступности, в которой создаётся данная подсеть. Последний параметр также задаётся через переменную, берущую значение из списка data по индексу цикла, объявленного посредством [count.index].
Структура файла security_groups.tf
Security-группы — это своего рода файрвол для облаков, который может быть создан не внутри самих ВМ, а средствами облака. В данном случае в файрволе описаны два правила.
Первое правило создаёт security-группу, которая называется kube. Эта security-группа нужна для того, чтобы разрешить весь исходящий трафик из нод Kubernetes, позволяя нодам свободно выходить в Интернет. Также разрешён входящий трафик к нодам Kubernetes от подсетей самих нод. Таким образом, ноды Kubernetes могут работать между собой без ограничений.
Второе правило создаёт security-группу ssh. Она разрешает подключение по SSH с любых IP-адресов на порт 22 ВМ кластера Kubernetes:
Спойлер
resource "aws_security_group" "kube" {
vpc_id = "${aws_vpc.kube.id}"
name = "kubernetes"
# Allow all outbound
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
# Allow all internal
ingress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["${var.vpc_cidr}"]
}
}
resource "aws_security_group" "ssh" {
vpc_id = "${aws_vpc.kube.id}"
name = "ssh"
# Allow all inbound
ingress {
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
}Мастер-нода. Структура файла master.tf
В файле master.tf описывается создание нескольких шаблонов и инстансов. В частности, создаётся мастер-инстанс Kubernetes.
Переменная ami задаёт AMI исходного образа для ВМ. Далее описаны тип ВМ и подсеть, в которой она создаётся. При задании подсети снова используется цикл, чтобы создавать ВМ в каждой зоне доступности.
Далее объявляются используемые security-группы и ключ, который был указан в файле main.tf. В поле user_data прописано выполнение набора скриптов cloud-init, результаты работы которых будут внедрены в ВМ:
Спойлер
resource "aws_instance" "master" {
count = "1"
ami = "${var.kubernetes_ami}"
instance_type = "c3.large"
disable_api_termination = false
instance_initiated_shutdown_behavior = "terminate"
source_dest_check = false
subnet_id = "${aws_subnet.private.*.id[count.index % length(data.aws_availability_zones.az.names)]}"
associate_public_ip_address = true
vpc_security_group_ids = [
"${aws_security_group.ssh.id}",
"${aws_security_group.kube.id}",
]
key_name = "${aws_key_pair.kube.key_name}"
user_data = "${data.template_cloudinit_config.master.rendered}"
monitoring = "true"
}Мастер-нода. Cloud-init
Cloud-init — инструмент, который разрабатывает Canonical. Он позволяет автоматически выполнить в облачных инфраструктурах определённый набор команд после запуска ВМ. У Terraform есть механизмы интеграции с ним с помощью шаблонов.
Поскольку невозможно «запечь» в ВМ всё необходимое, после запуска в зависимости от своего типа она должна либо присоединиться к кластеру Kubernetes, либо инициализировать кластер Kubernetes. В шаблоне файла cloud-init под названием master.tpl выполняется несколько действий.
1. Записываются конфигурационные файлы для Kubeadm:
#cloud-config
write_files:
- path: etc/kubernetes/kubeadm.conf
owner: root:root
content:
...2. Выполняется набор команд:
- в генерируемый файл конфигурации записывается IP-адрес мастера;
- инициализируется мастер в кластере Kubernetes командой kubeadm init;
- в кластере Kubernetes устанавливается оверлейная сеть Calico командой kubectl apply.
runcmd:
- sed -i "s/CONTROL_PLANE_IP/$(curl http://169.254.169.254/latest/meta-data-local-ipv4)/g" /etc/kubernetes/kubeadm.conf
- kubeadm init --config /etc/kubernetes/kubeadm.conf
- mkdir -p $HOME/.kube
- sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
- sudo chown $(id -u):$(id -g) $HOME/.kube/config
- kubectl apply -f https://docs.projectcalico.org/v3.8/manifests/calico.yamlПосле выполнения команд при запуске ВМ получается рабочий кластер Kubernetes из одной мастер-ноды. Остальные ноды будут присоединяться к этой мастер-ноде.
Рядовые ноды. node.tf
Файл node.tf похож на файл master.tf. Здесь также создаются ресурсы, которые в данном случае называются node. Единственное отличие в том, что мастер-нода создаётся в единственном экземпляре, а количество создаваемых рабочих нод задано через переменную nodes_count:
resource "aws_instance" "node" {
count = "${var.nodes_count}"
ami = "${var.kubernetes_ami}"
instance_type = "c3.large"Файл cloud-init для рабочих нод выполняет всего одну команду — kubeadm join. Эта команда присоединяет готовую машину к кластеру Kubernetes, используя передаваемый нами токен авторизации.
Запуск Terraform
При запуске Terraform использует несколько модулей:
- модуль AWS;
- модуль шаблонов;
- модуль TLS, отвечающий за генерацию ключей.
Эти модули необходимо установить на локальную машину:
terraform init terraform/Вместе с этой командой указывается директория, в которой расположены все необходимые файлы. При инициализации Terraform скачивает все указанные модули, после чего необходимо выполнить команду terraform plan:
terraform plan -var-file terraform/vars/dev.tfvars terraform/Обратите внимание, что, помимо директории с файлами Terraform, указывается файл var-file, в котором содержатся значения переменных, использующихся в файлах Terraform. Директория vars может содержать несколько файлов .tfvars, что позволяет управлять различными типами инфраструктур с помощью одного набора файлов Terraform.
В самом файле dev.tfvars содержатся следующие важные переменные:
- Kubernetes_version ( устанавливаемая версия Kubernetes);
- Kubernetes_ami (AMI образа, который создал Packer).
Задав необходимые значения переменных, выполните команду terraform plan, после чего Terraform представит список действий, необходимых для достижения состояния, описанного в файлах Terraform.
Проверив этот список, примените предлагаемые изменения:
terraform apply -auto-approve -var-file terraform/vars/dev.tfvars terraform/От команды terraform plan её отличает наличие ключа — auto-approve, который избавляет от необходимости подтверждать вносимые изменения. Можно опустить этот ключ, но тогда каждое действие нужно будет подтверждать вручную.
Структура кластера Kubernetes

Кластер Kubernetes состоит из мастер-ноды, которая выполняет функции управления, и рабочих нод, которые запускают приложения, устанавливаемые в кластере.
На мастер-ноде установлено четыре компонента, обеспечивающих работу данной системы:
- ETCD, т. е. база данных Kubernetes;
- API Server, через который мы сохраняем информацию в Kubernetes и получаем из него информацию;
- Controller Manager;
- Scheduler.
На рабочих нодах установлено два дополнительных компонента:
- Kube-proxy (отвечает за генерацию сетевых правил в кластере Kubernetes);
- Kubelet (отвечает за передачу команды Docker-демону для запуска приложений в кластере Kubernetes).
Между нодами работает сетевой плагин Calico.
Диаграмма рабочего процесса кластера
Предположим, что пользователь создаёт в кластере Kubernetes объект под названием replicaset.
Обратите внимание, что в кластере Kubernetes нет компонента, который раздавал бы команды другим компонентам. Такое большое количество компонентов нужно для того, чтобы каждый из них приводил свою небольшую часть инфраструктуры к состоянию, которое пользователь указал в YAML-файлах. Обмен информацией, необходимой для этого, производится исключительно через API-сервер. Напрямую компоненты друг с другом не общаются.
Предположим, что пользователь создаёт в кластере Kubernetes объект под названием replicaset.
- Информация от пользователя передаётся на API-сервер, который содержит базу данных ETCD. В базе данных сохраняется информация о запуске объекта.
- API-сервер возвращает пользователю информацию о создании объекта.
- Controller-manager записывает на API-сервер информацию о том, что необходимо создать «поды», то есть инстансы приложения.
- Scheduler назначает созданным подам конкретные ноды из кластера. Информация об этом снова сохраняется в ETCD на API-сервере.
- Kubelet передаёт API-запрос в Docker по запуску необходимого образа.
- Docker выполняет установку подов.
- Kubelet передаёт на API-сервер информацию о том, что контейнеры запущены и работают.
Обратите внимание, что в кластере Kubernetes нет компонента, который раздавал бы команды другим компонентам. Такое большое количество компонентов нужно для того, чтобы каждый из них приводил свою небольшую часть инфраструктуры к состоянию, которое пользователь указал в YAML-файлах. Обмен информацией, необходимой для этого, производится исключительно через API-сервер. Напрямую компоненты друг с другом не общаются.
Kubeadm

Последний элемент, про который стоит упомянуть, — это Kubeadm. Развёртывание нового Kubernetes-кластера — всегда довольно кропотливый процесс. На каждом этапе есть риски ошибок из-за человеческого фактора, и многие задачи просто очень рутинные и долгие. Например, разливка сертификатов для TLS-шифрования между нодами и поддержание их в актуальном состоянии. Вот тут как раз на помощь приходят утилиты для базовой шаблонной автоматизации. Фишка Kubeadm в том, что он официально сертифицирован для работы с Kubernetes.
Он позволяет:
- установить, сконфигурировать и запустить все основные компоненты кластера;
- управлять сертификатами, в т. ч. ротировать их и выписывать новые;
- управлять версиями компонентов кластера (производить апгрейд и даунгрейд).
При этом Kubeadm не является полноценной системой управления кластером Kubernetes, а представляет собой своего рода строительный блок, который позволяет настроить Kubernetes на той ноде, на которой утилита Kubeadm запущена. Это означает, что необходима система оркестрации, которая будет запускать все необходимые ВМ, настраивать их и запускать Kubeadm на всех нодах. Именно для этих целей используется Terraform.
Репозиторий со всеми файлами
Вот тут мы положили все файлы и конфиги в одном месте, чтобы вам было удобнее. Если у вас нет под рукой частного облака, но есть желание пройти все эти шаги самостоятельно и протестировать деплой на практике, напишите нам на cloud@croc.ru.
Мы дадим вам демо-вариант для тестов и проконсультируем по всем вопросам.
А ещё скоро будет новый Слёрм, где можно будет создать свой кластер. По промо-коду КРОК скидка 10%.
Для тех, кто уже работает с Kubernetes, есть продвинутый курс. Скидка та же.




