Чем сложнее система, тем больше она обрастает всевозможными алертами. И возникает потребность на эти самые алерты реагировать, агрегировать их и визуализировать. Думаю, ситуация, знакомая многим до нервного тика.
Решение, о котором пойдёт речь, не самое неожиданное, но полноценной статьи по этой теме поиск не выдаёт.
Поэтому я решил поделиться опытом FunCorp и рассказать о том, как выстроен процесс дежурств, кто звонит, почему и как на это всё можно смотреть.

Итак, чтобы решить все эти задачи, мы начали искать удобный инструмент. После недолгих поисков мы остановили свой выбор на PagerDuty. PD показалась нам достаточно полным и лаконичным решением с большим количеством интеграций и настроек. Что она из себя представляет?
Если коротко, PagerDuty — это платформа для обработки инцидентов, которая умеет обрабатывать приходящие инциденты через различные интеграции, настраивать порядок дежурств и далее осуществлять алертинг дежурному инженеру в зависимости от уровня инцидента (при высоком уровне — звонок, при низком — пуш от приложения/смс).
Наверное, это первое, с чего надо начинать настройку PD.
В FunCorp, как и в других компаниях, есть почётная должность дежурного. Она передаётся от инженера к инженеру раз в сутки. Есть так называемая первая и вторая линия реагирования на алерт от PagerDuty. Предположим, приходит алерт высокого приоритета, и если через 10 минут после звонка дежурному из первой линии на него нет реакции (т.е. он не переведён в статус acknowledge или resolved), звонок уходит второму дежурному инженеру. Это настраивается в самом PagerDuty через Escalation Policies.
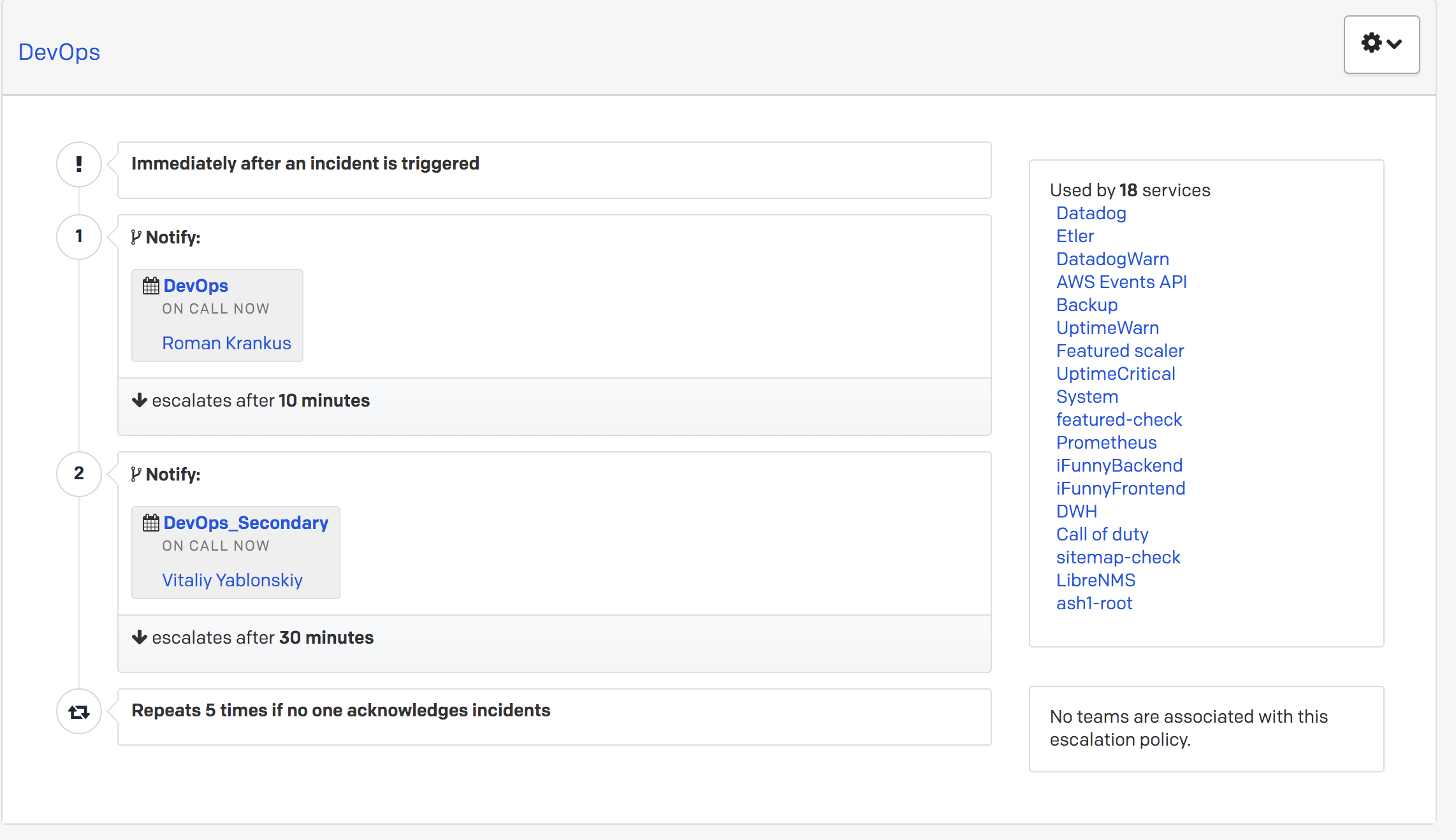
Если и второй дежурный не отвечает, то оповещение возвращается обратно к главному дежурному.
Таким образом, любой приходящий алерт высокого приоритета не может остаться необработанным.
Теперь посмотрим, откуда могут приходить инциденты.
В PD сыпется много разнообразных инцидентов от различных сервисов. У нас сейчас таких сервисов около 25, и для их обработки мы используем некоторые готовые интеграции.
Основной системой сбора метрик является Prometheus. Про неё уже много написано на Хабре, я только скажу, что у нас их несколько под разные среды: одна собирает метрики с виртуалок и докеров, другая — из сервисов амазона, третья —с «железных машин». В основном как экспортёр метрик используется Telegraf.
Тут тоже, думаю, всё понятно из названия. Эта интеграция используется для отправки уведомлений от некоторый скриптов, выполняемых по крону. PD выдаёт вам некий адрес, на который вы отправляете письма. При создании сервиса cтакой интеграцией вы можете настроить приоритеты, в каком порядке будут обрабатываться входящие инциденты, как именно создавать алерт (на каждое приходящее письмо, на приходящее письмо + некое правило и т.д.).

На мой взгляд, весьма интересная интеграция. Бывают случаи, когда происходит что-то, но не покрывается инцидентами. Поэтому мы добавили интеграцию из Slack для создания инцидента. Т. е. в корпоративный Slack можно написать /callofduty все тормозит и скоро сломается и PD обработает это и отправит инцидент дежурному инженеру.
Делаем:

Видим:

Интеграция по HTTP. Тут, на самом деле, нет особо ничего интересного, просто POST-запрос с телом в JSON-формате. Например, из интересного: мы используем её для внешнего мониторинга при помощи https://www.statuscake.com/. Этот сервис проверяет доступность наших сайтов из разных точек мира. В случае, когда мы получаем неприемлемый код ответа (например, 502) создаётся инцидент и дальше всё идёт по цепочке, описанной выше. В самом StatusCake есть возможность мониторинга внутренних урлов, истечения срока SSL-сертификата или домена.
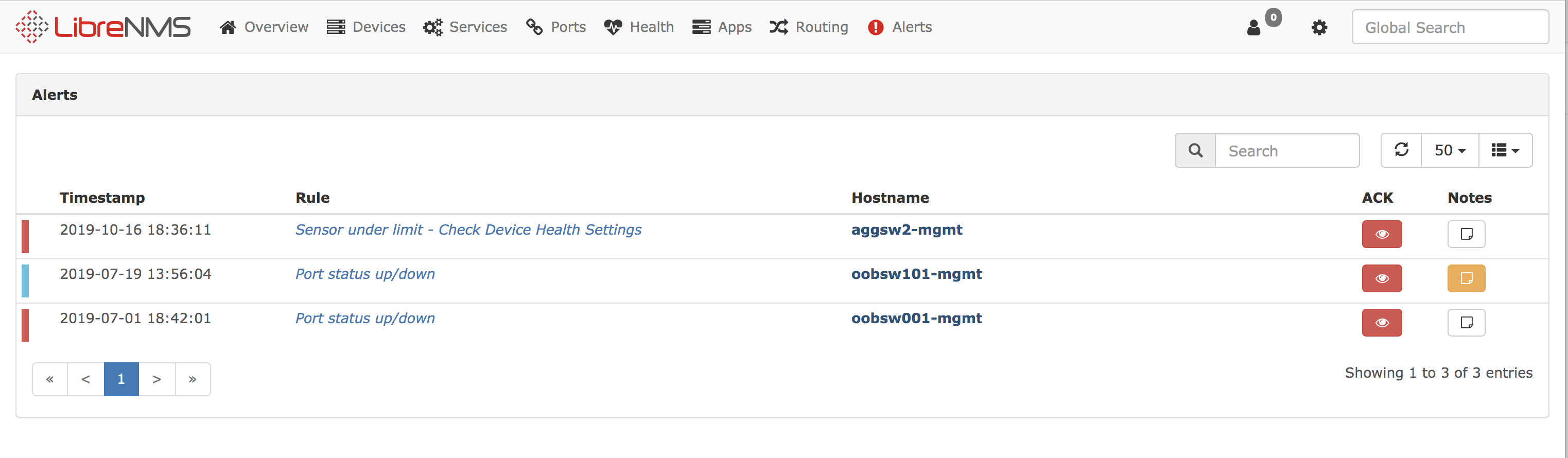
Это ещё одна система мониторинга, подробнее о ней можно почитать на их сайте https://www.librenms.org/. С её помощью мы осуществляем мониторинг сетевых интерфейсов и iDRAC с серверов.
Были ещё такие интеграции, как Datadog, CloudWatch. Подробнее о том, что с ними стало, можно посмотреть вот тут.
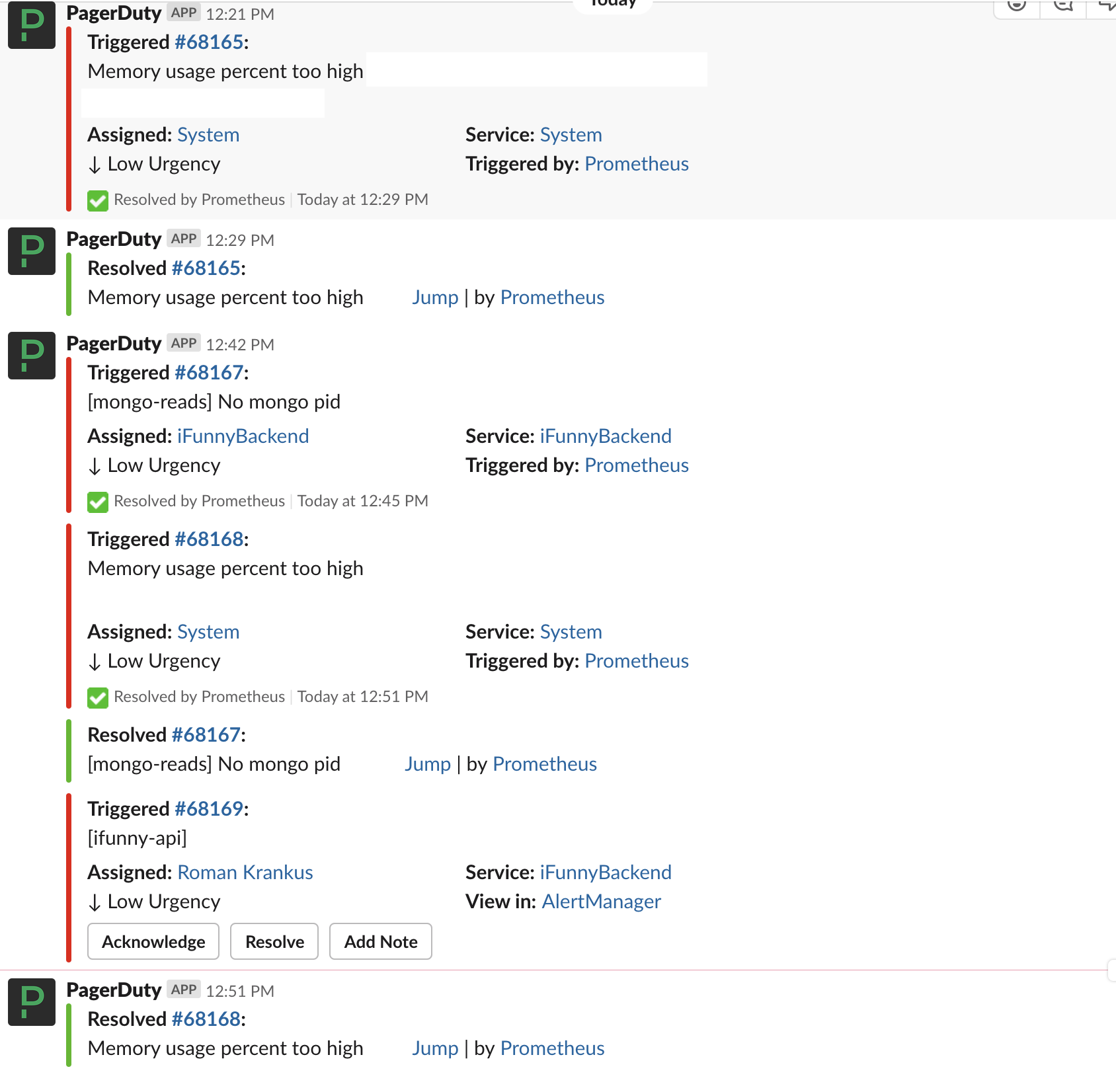
Основной системой информирования об инциденте является Slack. В специальный чат пишутся все приходящие в PD инциденты, и если меняется их статус, это также отображается в чате.
Когда появилась возможность вывести полезные данные на экраны висящих под потолком мониторов, мы внезапно поняли, что нам (в devops-отделе) нечего на них выводить. Есть замечательная Grafana, но ей всего не охватить, да и сотрудники реагируют на алерты, а не на графики.
После тщательного, но безуспешного поиска на GitHub лаконичной и информативной «борды» для PD, мы решили написать свою — только с тем, что нужно нам. Хотя сначала была идея вывести на экран сам интерфейс PD, но это выглядело ещё более неудобным.
Чтобы написать её, хватает только получения ключа от PD с read-only правами.
И вот что у нас получилось:
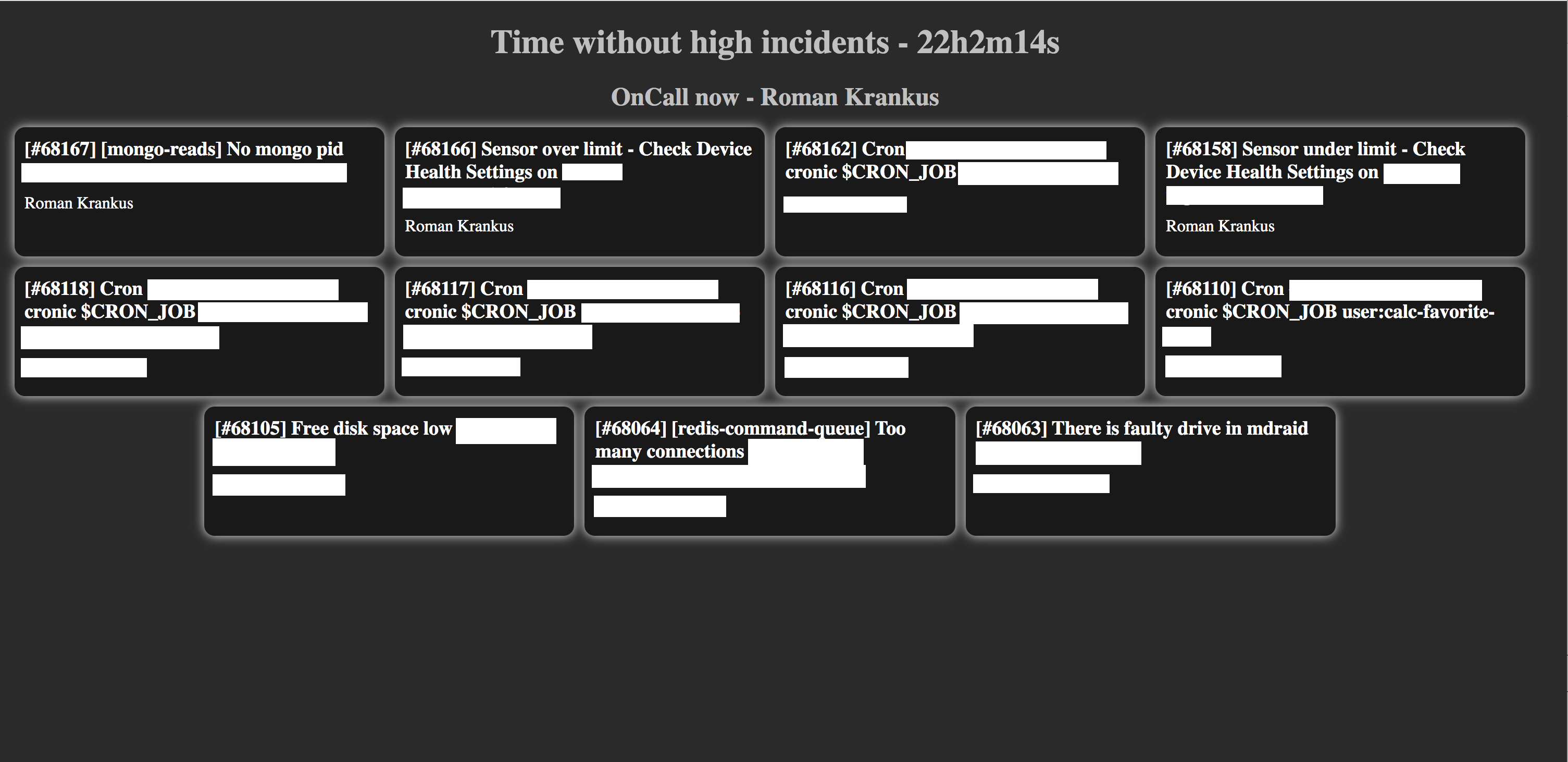
На экран выводятся актуальные открытые инциденты, имя текущего дежурного инженера из выбранного расписания и время без инцидента высокого приоритета (панель с инцидентом высокого приоритета будет выделена красным цветом).
Исходники этой реализации посмотреть здесь.
В итоге мы получили удобный дашборд для просмотра всех наших инцидентов. Буду рад, если кому-то из вас пригодится наш опыт.
Решение, о котором пойдёт речь, не самое неожиданное, но полноценной статьи по этой теме поиск не выдаёт.
Поэтому я решил поделиться опытом FunCorp и рассказать о том, как выстроен процесс дежурств, кто звонит, почему и как на это всё можно смотреть.
Что такое PagerDuty?
Итак, чтобы решить все эти задачи, мы начали искать удобный инструмент. После недолгих поисков мы остановили свой выбор на PagerDuty. PD показалась нам достаточно полным и лаконичным решением с большим количеством интеграций и настроек. Что она из себя представляет?
Если коротко, PagerDuty — это платформа для обработки инцидентов, которая умеет обрабатывать приходящие инциденты через различные интеграции, настраивать порядок дежурств и далее осуществлять алертинг дежурному инженеру в зависимости от уровня инцидента (при высоком уровне — звонок, при низком — пуш от приложения/смс).
Кто такой дежурный?
Наверное, это первое, с чего надо начинать настройку PD.
В FunCorp, как и в других компаниях, есть почётная должность дежурного. Она передаётся от инженера к инженеру раз в сутки. Есть так называемая первая и вторая линия реагирования на алерт от PagerDuty. Предположим, приходит алерт высокого приоритета, и если через 10 минут после звонка дежурному из первой линии на него нет реакции (т.е. он не переведён в статус acknowledge или resolved), звонок уходит второму дежурному инженеру. Это настраивается в самом PagerDuty через Escalation Policies.
Если и второй дежурный не отвечает, то оповещение возвращается обратно к главному дежурному.
Таким образом, любой приходящий алерт высокого приоритета не может остаться необработанным.
Теперь посмотрим, откуда могут приходить инциденты.
Какие интеграции используем?
В PD сыпется много разнообразных инцидентов от различных сервисов. У нас сейчас таких сервисов около 25, и для их обработки мы используем некоторые готовые интеграции.
- Prometheus
Основной системой сбора метрик является Prometheus. Про неё уже много написано на Хабре, я только скажу, что у нас их несколько под разные среды: одна собирает метрики с виртуалок и докеров, другая — из сервисов амазона, третья —с «железных машин». В основном как экспортёр метрик используется Telegraf.
- Email
Тут тоже, думаю, всё понятно из названия. Эта интеграция используется для отправки уведомлений от некоторый скриптов, выполняемых по крону. PD выдаёт вам некий адрес, на который вы отправляете письма. При создании сервиса cтакой интеграцией вы можете настроить приоритеты, в каком порядке будут обрабатываться входящие инциденты, как именно создавать алерт (на каждое приходящее письмо, на приходящее письмо + некое правило и т.д.).
- Slack
На мой взгляд, весьма интересная интеграция. Бывают случаи, когда происходит что-то, но не покрывается инцидентами. Поэтому мы добавили интеграцию из Slack для создания инцидента. Т. е. в корпоративный Slack можно написать /callofduty все тормозит и скоро сломается и PD обработает это и отправит инцидент дежурному инженеру.
Делаем:
Видим:
- API
Интеграция по HTTP. Тут, на самом деле, нет особо ничего интересного, просто POST-запрос с телом в JSON-формате. Например, из интересного: мы используем её для внешнего мониторинга при помощи https://www.statuscake.com/. Этот сервис проверяет доступность наших сайтов из разных точек мира. В случае, когда мы получаем неприемлемый код ответа (например, 502) создаётся инцидент и дальше всё идёт по цепочке, описанной выше. В самом StatusCake есть возможность мониторинга внутренних урлов, истечения срока SSL-сертификата или домена.
- LibreNMS
Это ещё одна система мониторинга, подробнее о ней можно почитать на их сайте https://www.librenms.org/. С её помощью мы осуществляем мониторинг сетевых интерфейсов и iDRAC с серверов.
Были ещё такие интеграции, как Datadog, CloudWatch. Подробнее о том, что с ними стало, можно посмотреть вот тут.
Визуализация
Основной системой информирования об инциденте является Slack. В специальный чат пишутся все приходящие в PD инциденты, и если меняется их статус, это также отображается в чате.
Когда появилась возможность вывести полезные данные на экраны висящих под потолком мониторов, мы внезапно поняли, что нам (в devops-отделе) нечего на них выводить. Есть замечательная Grafana, но ей всего не охватить, да и сотрудники реагируют на алерты, а не на графики.
После тщательного, но безуспешного поиска на GitHub лаконичной и информативной «борды» для PD, мы решили написать свою — только с тем, что нужно нам. Хотя сначала была идея вывести на экран сам интерфейс PD, но это выглядело ещё более неудобным.
Чтобы написать её, хватает только получения ключа от PD с read-only правами.
И вот что у нас получилось:
На экран выводятся актуальные открытые инциденты, имя текущего дежурного инженера из выбранного расписания и время без инцидента высокого приоритета (панель с инцидентом высокого приоритета будет выделена красным цветом).
Исходники этой реализации посмотреть здесь.
В итоге мы получили удобный дашборд для просмотра всех наших инцидентов. Буду рад, если кому-то из вас пригодится наш опыт.



")