Вводная
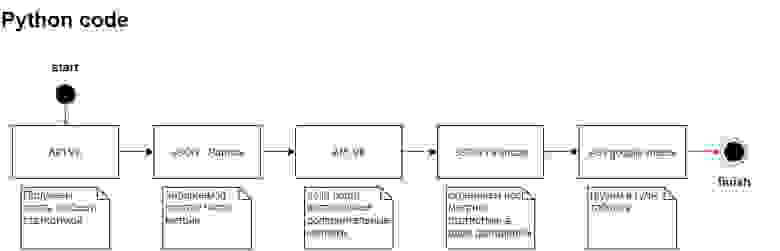
Появилась потребность собирать статистику постов из группы в контакте и затем проанализировать реакции подписчиков на конкретные посты. Если переформулировать на выходе стоит задача с заданной периодичностью снимать показания статистики постов в вк и сохранять их.
Я не профессиональный программист и не претендую, поэтому решил сделать все довольно просто. При помощи api VK забирать посты из группы, собираю нужный мне датафрейм и записываю данные в гугл таблицу, так же через api.
Может быть это и не самое оптимальное решение,
Настраиваем API VK
В этом блоке мы хотим собрать статистику постов из группы vk.
Для начала работы нам нужен user_token из vk. Мне понравилась видеоинструкция здесь, коротко и по делу.
Токен держим в секрете. Переходим в https://dev.vk.com изучаем документацию API.
Нашли подходящий метод wall.get https://dev.vk.com/method/wall.get
Прямо на сайте документации можем попробовать дернуть запрос.
Для этого нам нужно access_token, domain, count, v, filter.
access_token – получили на прошлом шаге. domain – название группы вы увидите в url название группы например https://vk.com/adminsclub. count – количество постов которые можем дернуть. v – версия api. filter – хотим получить только посты от группы устанавливаем owner.

Прописываем логику сбора
Импортируем библиотеку requests. Дергаем тестовый запрос. Поcле анализа структуры решаю, что мне нужен раздел items
# переменные
TOKEN_USER = #ваш токен
VERSION = #версися api vk
DOMAIN = #ваш domain
# через api vk вызываем статистику постов
response = requests.get('https://api.vk.com/method/wall.get',
params={'access_token': TOKEN_USER,
'v': VERSION,
'domain': DOMAIN,
'count': 10,
'filter': str('owner')})
data = response.json()['response']['items']Отдельное поле в статистики количество фотографий для поста, я не нашел.
Через цикл перебираем каждый пост и считаем количество фото, если фотографии нет скрипт ловит ошибку. Обрабатываем ошибку и ставим 0. Собираем новый список с полями id поста и количество фото.
Пишем обработчик. Вызываем pandas
# считаем сколько фото у поста, заводи все в df
id = []
photo = []
for post in data:
id.append(post['id'])
try:
photo.append(len(post['attachments']))
except:
photo.append(0)
df_photo = pd.DataFrame(
{'id': id,
'photo.count': photo,
})Переводим cловарь в df. Импортируем метод from pandas import json_normalize
Оставляем нужные атрибуты и переводим дату в другой формат.
В переменной post_id запихиваем id наших постов.
Я бы хотел обогатить свою статистику более расширенными измерениями
Из документации по api о которой рассказывал выше подобрал метод status.getPostReach
В методе обнаружил новый аргумент owner_id, его можно найти в настройках группы.
Делаем еще один запрос и новые данные сохраняем в датафрейм df_stat_post
# вытаскиваем нужные нам столбцы и переводим формат даты
df = json_normalize(data)
df = df[['id','date','comments.count','likes.count','reposts.count','reposts.wall_count','reposts.mail_count','views.count','text']]
df['date']= [datetime.fromtimestamp(df['date'][i]) for i in range(len(df['date']))]
# для каждого поста вытаскиваем дополнительную статистику
post_id = ','.join(df['id'].astype("str"))
response = requests.get('https://api.vk.com/method/stats.getPostReach',
params={'access_token': TOKEN_USER,
'v': VERSION,
'owner_id': # ваш id_owner,
'post_ids': post_id})
data = response.json()['response']
df_stat_post = json_normalize(data)Теперь приступим к сборке объединяем все наши датафреймы, накидываем дополнительные метрики.
Далее наши данные преобразовываем для загрузки в гугл таблицу.
# объединяем все df cо всеми статистиками и количествам фото
df_final = df.merge(df_stat_post, how='left', left_on='id', right_on="post_id")
df_final = df_final.merge(df_photo, how='left', left_on='id', right_on="id")
df_final.drop(columns='post_id',inplace=True)
# добавляем дополнительные столбцы с временем
df_final['date_time_report'] = datetime.now()
df_final['date_report'] = date.today()
df_final['year'] = df_final['date_time_report'].dt.year
df_final['month'] = df_final['date_time_report'].dt.month
df_final['day'] = df_final['date_time_report'].dt.day
df_final['hour'] = df_final['date_time_report'].dt.hour
df_final['minute'] = df_final['date_time_report'].dt.minute
df_final[['date','date_report','date_time_report']] = df_final[['date','date_report','date_time_report']].astype('str')
# сохраняем все значения
data_list = df_final.values.tolist()Грузим в google sheet через api
Есть готовые библиотеки для работы с google sheet например pygsheets, но мне было важно поработать с API поэтому легких путей не искал.
Прежде чем загрузить надо настроить наш api прекрасная статья, в который пошагово написано и даст возможность поиграться с листами https://habr.com/ru/post/483302/
# подключаемся к гугл таблице
CREDENTIALS_FILE = # Имя файла с закрытым ключом, вы должны подставить свое
# Читаем ключи из файла
credentials = ServiceAccountCredentials.from_json_keyfile_name(CREDENTIALS_FILE, ['https://www.googleapis.com/auth/spreadsheets', 'https://www.googleapis.com/auth/drive'])
httpAuth = credentials.authorize(httplib2.Http()) # Авторизуемся в системе
service = apiclient.discovery.build('sheets', 'v4', http = httpAuth) # Выбираем работу с таблицами и 4 версию API
spreadsheetId = # ваш id листПосле подключения к листу. Находим последнюю заполненную строку.
В моем примере я заполняю последние 10 строк ровно по количеству постов которые я получил из get запроса. Подготавливаем шаблон для запроса, заполняем шаблон данными какие ячейки заполняем и заполняем. Далее выполняем запрос. Готово
# находим последнию строку заполненную
response = service.spreadsheets().values().get(spreadsheetId = spreadsheetId,range="Лист номер один!A1:A").execute()
# последние 10 строк заполняем
number_sheet = "Лист номер один!A" + str(len(response['values'])+1) + ':AA' + str(len(response['values'])+10)
# создаем запрос и вставляем туда данные
data_vk = {
"valueInputOption": "USER_ENTERED", # Данные воспринимаются, как вводимые пользователем (считается значение формул)
"data": [
{"range": "",
"majorDimension": "ROWS", # Сначала заполнять строки, затем столбцы
"values": ''}
]
}
data_vk['data'][0]['range'] = number_sheet
data_vk['data'][0]['values'] = data_list
# выполняем запрос
results = service.spreadsheets().values().batchUpdate(spreadsheetId = spreadsheetId, body = data_vk).execute()Заключение
После написания этого кода мне требовалось запускать его каждый час и принял решение арендовать сервер, установить туда docker и через crontab запускать.
Код на GitHub




