
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Три года назад Виктор Тарнавский и Алексей Миловидов из Яндекса на сцене HighLoad++ рассказывали, какой ClickHouse хороший, и как он не тормозит. А на соседней сцене был Александр Зайцев с докладом о переезде на ClickHouse с другой аналитической СУБД и с выводом, что ClickHouse, конечно, хороший, но не очень удобный. Когда в 2016 году компания LifeStreet, в которой тогда работал Александр, переводила мультипетабайтовую аналитическую систему на ClickHouse, это была увлекательная «дорога из желтого кирпича», полная неведомых опасностей — ClickHouse тогда напоминал минное поле.
Три года спустя ClickHouse стал гораздо лучше — за это время Александр основал компанию Altinity, которая не только помогает переезжать на ClickHouse десяткам проектов, но и совершенствует сам продукт вместе с коллегами из Яндекса. Сейчас ClickHouse все еще не беззаботная прогулка, но уже и не минное поле.
Александр занимается распределенными системами с 2003 года, разрабатывал крупные проекты на MySQL, Oracle и Vertica. На прошедшей HighLoad++ 2019 Александр, один из пионеров использования ClickHouse, рассказал, что сейчас из себя представляет эта СУБД. Мы узнаем про основные особенности ClickHouse: чем он отличается от других систем и в каких случаях его эффективнее использовать. На примерах рассмотрим свежие и проверенные проектами практики по построению систем на ClickHouse.
Три года назад мы переводили компанию LifeStreet на ClickHouse с другой аналитической базы данных, и миграция аналитики рекламной сети выглядела так:
В процессе миграции росло понимание, что ClickHouse — это хорошая система, с которой приятно работать, но это внутренний проект компании Яндекс. Поэтому есть нюансы: Яндекс сначала будет заниматься собственными внутренними заказчиками и только потом — сообществом и нуждами внешних пользователей, а ClickHouse не дотягивал тогда до уровня энтерпрайза по многим функциональным областям. Поэтому в марте 2017 года мы основали компанию Altinity, чтобы сделать ClickHouse ещё быстрее и удобнее не только для Яндекса, но и для других пользователей. И теперь мы:
И конечно, мы помогаем с переездом на ClickHouse с MySQL, Vertica, Oracle, Greenplum, Redshift и других систем. Мы участвовали в самых разных переездах, и они все были успешными.

Не тормозит! Это главная причина. ClickHouse — очень быстрая база данных для разных сценариев:

Масштабируемость. На какой-то другой БД можно добиться неплохой производительности на одной железке, но ClickHouse можно масштабировать не только вертикально, но и горизонтально, просто добавляя сервера. Все работает не так гладко, как хотелось бы, но работает. Можно наращивать систему вместе с ростом бизнеса. Это важно, что мы не ограничены решением сейчас и всегда есть потенциал для развития.
Портируемость. Нет привязки к чему-то одному. Например, с Amazon Redshift тяжело куда-то переехать. А ClickHouse можно поставить себе на ноутбук, сервер, задеплоить в облако, уйти в Kubernetes — нет ограничений на эксплуатацию инфраструктуры. Это удобно для всех, и это большое преимущество, которым не могут похвастаться многие другие похожие БД.
Гибкость. ClickHouse не останавливается на чем-то одном, например, на Яндекс.Метрике, а развивается и используется во всё большем и большем количестве разных проектов и индустрий. Его можно расширять, добавляя новые возможности для решения новых задач. Например, считается, что хранить логи в БД — моветон, поэтому для этого придумали Elasticsearch. Но, благодаря гибкости ClickHouse, в нём тоже можно хранить логи, и часто это даже лучше, чем в Elasticsearch — в ClickHouse для этого требуется в 10 раз меньше железа.
Бесплатный Open Source. Не нужно ни за что платить. Не нужно договариваться о разрешении поставить систему себе на ноутбук или сервер. Нет скрытых платежей. При этом никакая другая Open Source технология баз данных не может конкурировать по скорости с ClickHouse. MySQL, MariaDB, Greenplum — все они гораздо медленнее.
Сообщество, драйв и fun. У ClickHouse отличное сообщество: митапы, чаты и Алексей Миловидов, который нас всех заряжает своей энергией и оптимизмом.
Чтобы переходить на ClickHouse с чего-то, нужны всего лишь три вещи:
Есть только одно «но»: если переезжаете на ClickHouse с чего-то другого, то обычно что-то идет не так. Мы привыкли к каким-то практикам и вещам, которые работают в любимой БД. Например, любой человек, работающий с SQL-базами данных, считает обязательными такой набор функций:
Набор-то обязательный, но три года назад в ClickHouse не было ни одной из этих функций! Сейчас из нереализованного осталось меньше половины: транзакции, констрейнты, Consistency, миллисекунды и приведение типов.
И главное — то, что в ClickHouse некоторые стандартные практики и подходы не работают или работают не так, как мы привыкли. Всё, что появляется в ClickHouse, соответствует «ClickHouse way», т.е. функции отличаются от других БД. Например:
В 1960 году американский математик венгерского происхождения Wigner E. P. написал статью «The unreasonable effectiveness of mathematics in the natural sciences» («Непостижимая эффективность математики в естественных науках») о том, что окружающий мир почему-то хорошо описывается математическими законами. Математика — абстрактная наука, а физические законы, выраженные в математической форме не тривиальны, и Wigner E. P. подчеркнул, что это очень странно.
С моей точки зрения, ClickHouse — такая же странность. Переформулируя Вигнера, можно сказать так: поразительна непостижимая эффективность ClickHouse в самых разнообразных аналитических приложениях!
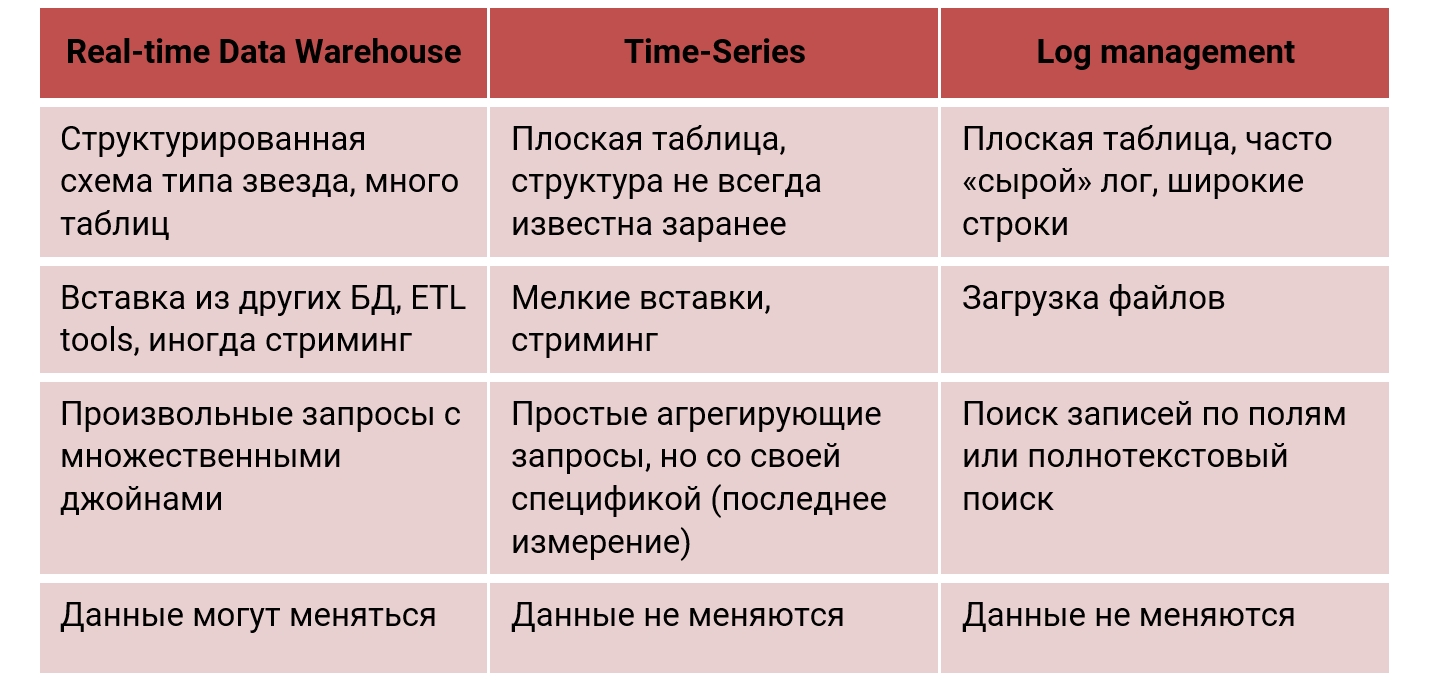
Например, возьмем Real-Time Data Warehouse, в который данные грузятся практически непрерывно. Мы хотим получать от него запросы с секундной задержкой. Пожалуйста — используем ClickHouse, потому что для этого сценария он и был разработан. ClickHouse именно так и используется не только в веб, но и в маркетинговой и финансовой аналитике, AdTech, а также в Fraud detection. В Real-time Data Warehouse используется сложная структурированная схема типа «звезда» или «снежинка», много таблиц с JOIN (иногда множественными), а данные обычно хранятся и меняются в каких-то системах.
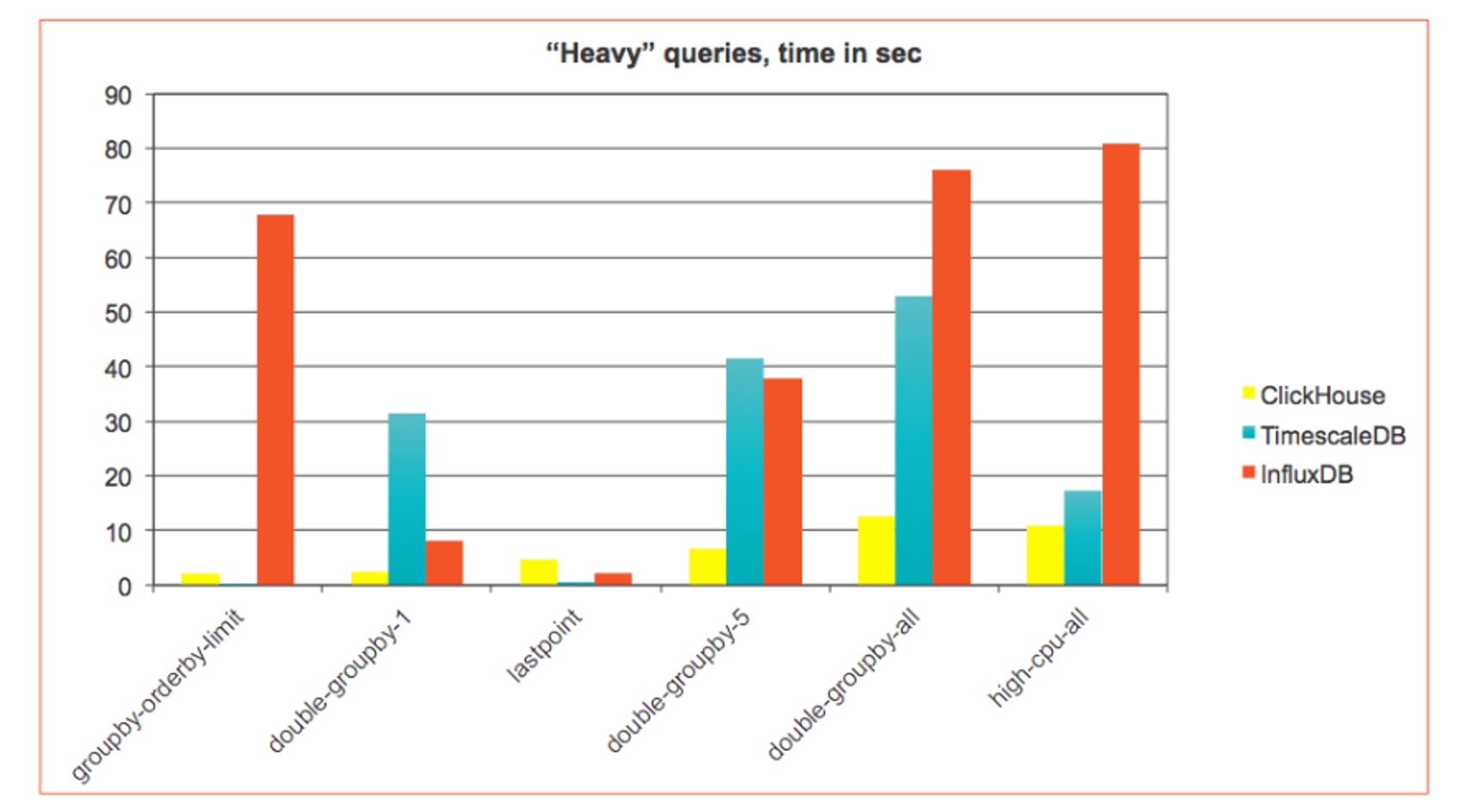
Возьмем другой сценарий — Time Series: мониторинг устройств, сетей, статистика использования, интернет вещей. Здесь мы встречаемся с упорядоченными по времени достаточно простыми событиями. ClickHouse для этого не был изначально разработан, но хорошо себя показал, поэтому крупные компании используют ClickHouse как хранилище для мониторинговой информации. Чтобы изучить, подходит ли ClickHouse для time-series, мы сделали бенчмарк на основе подхода и результатах InfluxDB и TimescaleDB — специализированных time-series баз данных. Оказалось, что ClickHouse, даже без оптимизации под такие задачи, выигрывает и на чужом поле:
В time-series обычно используется узкая таблица — несколько маленьких колонок. С мониторинга может приходить очень много данных, — миллионы записей в секунду, — и обычно они поступают маленькими вставками (real-time стримингом). Поэтому нужен другой сценарий вставки, а сами запросы — со своей некоторой спецификой.
Log Management. Сбор логов в БД — это обычно плохо, но в ClickHouse это можно делать с некоторыми комментариями, как описано выше. Многие компании используют ClickHouse именно для этого. В этом случае используется плоская широкая таблица, где мы храним логи целиком (например, в виде JSON), либо нарезаем на части. Данные загружаются обычно большими батчами (файлами), а ищем по какому-нибудь полю.
Для каждой из этих функций обычно используются специализированные БД. ClickHouse один может делать это всё и настолько хорошо, что обгоняет их по производительности. Давайте теперь подробно рассмотрим time-series сценарий, и как правильно «готовить» ClickHouse под этот сценарий.
В настоящий момент это основной сценарий, для которого ClickHouse считается стандартным решением. Time-series — это набор упорядоченных во времени событий, представляющих изменения какого-то процесса во времени. Например, это может быть частота сердцебиений за день или количество процессов в системе. Всё, что дает временные тики с какими-то измерениями – это time-series:

Больше всего такого рода событий приходит из мониторинга. Это может быть не только мониторинг веба, но и реальных устройств: автомобилей, промышленных систем, IoT, производств или беспилотных такси, в багажник которых Яндекс уже сейчас кладет ClickHouse-сервер.
Например, есть компании, которые собирают данные с судов. Каждые несколько секунд датчики с контейнеровоза отправляют сотни различных измерений. Инженеры их изучают, строят модели и пытаются понять, насколько эффективно используется судно, потому что контейнеровоз не должен простаивать ни секунды. Любой простой — это потеря денег, поэтому важно спрогнозировать маршрут так, чтобы стоянки были минимальными.
Сейчас наблюдается рост специализированных БД, которые измеряют time-series. На сайте DB-Engines каким-то образом ранжируются разные базы данных, и их можно посмотреть по типам:

Самый быстрорастущий тип — time-series. Также растут графовые БД, но time-series растут быстрее последние несколько лет. Типичные представители БД этого семейства — это InfluxDB, Prometheus, KDB, TimescaleDB (построенная на PostgreSQL), решения от Amazon. ClickHouse здесь тоже может быть использован, и он используется. Приведу несколько публичных примеров.
Один из пионеров — компания CloudFlare (CDN-провайдер). Они мониторят свой CDN через ClickHouse (DNS-запросы, HTTP-запросы) с громадной нагрузкой — 6 миллионов событий в секунду. Все идет через Kafka, отправляется в ClickHouse, который предоставляет возможность в реальном времени видеть дашборды событий в системе.
Comcast — один из лидеров телекоммуникаций в США: интернет, цифровое телевидение, телефония. Они создали аналогичную систему управления CDN в рамках Open Source проекта Apache Traffic Control для работы со своими огромными данными. ClickHouse используется как бэкенд для аналитики.
Percona встроили ClickHouse внутрь своего PMM, чтобы хранить мониторинг различных MySQL.
К time-series базам данных есть свои специфические требования.
Давайте посмотрим, как эти требования выполняются в ClickHouse.
В ClickHouse схему для time-series можно сделать разными способами, в зависимости от степени регулярности данных. Можно построить систему на регулярных данных, когда мы знаем все метрики заранее. Например, так сделал CloudFlare с мониторингом CDN — это хорошо оптимизированная система. Можно построить более общую систему, которая мониторит всю инфраструктуру, разные сервисы. В случае нерегулярных данных, мы не знаем заранее, что мониторим — и, наверное, это наболее общий случай.
Регулярные данные. Колонки. Схема простая – колонки с нужными типами:
Это обычная таблица, которая мониторит какую-то активность по загрузке системы (user, system, idle, nice). Просто и удобно, но не гибко. Если хотим более гибкую схему, то можно использовать массивы.
Нерегулярные данные. Массивы:
Структура Nested — это два массива: metrics.name и metrics.value. Здесь можно хранить такие произвольные мониторинговые данные, как массив названий и массив измерений при каждом событии. Для дальнейшей оптимизации вместо одной такой структуры можно сделать несколько. Например, одну — для float-значение, другую — для int-значение, потому что int хочется хранить эффективнее.
Но к такой структуре сложнее обращаться. Придется использовать специальную конструкцию, через специальные функции вытаскивать значения сначала индекса, а потом массива:
Но это все равно работает достаточно быстро. Другой способ хранения нерегулярных данных – по строкам.
Нерегулярные данные. Строки. В этом традиционном способе без массивов хранятся сразу названия и значения. Если с одного устройства приходит сразу 5 000 измерений — генерируется 5 000 строк в БД:
ClickHouse с этим справляется — у него есть специальные расширения ClickHouse SQL. Например, maxIf — специальная функция, которая считает максимум по метрике при выполнении какого-то условия. Можно в одном запросе написать несколько таких выражений и сразу посчитать значение для нескольких метрик.
Сравним три подхода:

Детали
Здесь я добавил «Размер данных на диске» для некоторого тестового набора данных. В случае с колонками у нас самый маленький размер данных: максимальное сжатие, максимальная скорость запросов, но мы платим тем, что должны все сразу зафиксировать.
В случае с массивами всё чуть хуже. Данные все равно хорошо сжимаются, и можно хранить нерегулярную схему. Но ClickHouse — колоночная база данных, а когда мы начинаем хранить все в массиве, то она превращается в строковую, и мы платим за гибкость эффективностью. На любую операцию придется прочитать весь массив в память, после этого найти в нем нужный элемент — а если массив растет, то скорость деградирует.
В одной из компаний, которая использует такой подход (например, Uber), массивы нарезаются на кусочки из 128 элементов. Данные нескольких тысяч метрик объемом в 200 ТБ данных/в день хранятся не в одном массиве, а в из 10 или 30 массивах со специальной логикой для хранения.
Максимально простой подход — со строками. Но данные плохо сжимаются, размер таблицы получается большой, да ещё когда запросы идут по нескольким метрикам, то ClickHouse работает неоптимально.
Предположим, что мы выбрали схему с массивом. Но если мы знаем, что большинство наших дашбордов показывают только метрики user и system, мы можем дополнительно из массива на уровне таблицы материализовать эти метрики в колонки таким образом:
При вставке ClickHouse автоматически их посчитает. Так можно совместить приятное с полезным: схема гибкая и общая, но самые часто используемые колонки мы вытащили. Замечу, что это не потребовало менять вставку и ETL, который продолжает вставлять в таблицу массивы. Мы просто сделали ALTER TABLE, добавили пару колонок и получилась гибридная и более быстрая схема, которой можно сразу начинать пользоваться.
Для time-series важно, насколько хорошо вы упаковываете данные, потому что массив информации может быть очень большой. В ClickHouse есть набор средств для достижения эффекта компрессии 1:10, 1:20, а иногда и больше. Это значит, что неупакованные данные объемом 1 ТБ на диске занимают 50-100 ГБ. Меньший размер — это хорошо, данные быстрее можно прочитать и обработать.
Для достижения высокого уровня компрессии, ClickHouse поддерживает следующие кодеки:

Пример таблицы:
Здесь мы определяем кодек DoubleDelta в одном случае, во втором — Gorilla, и обязательно добавляем еще LZ4 компрессию. В результате размер данных на диске сильно уменьшается:
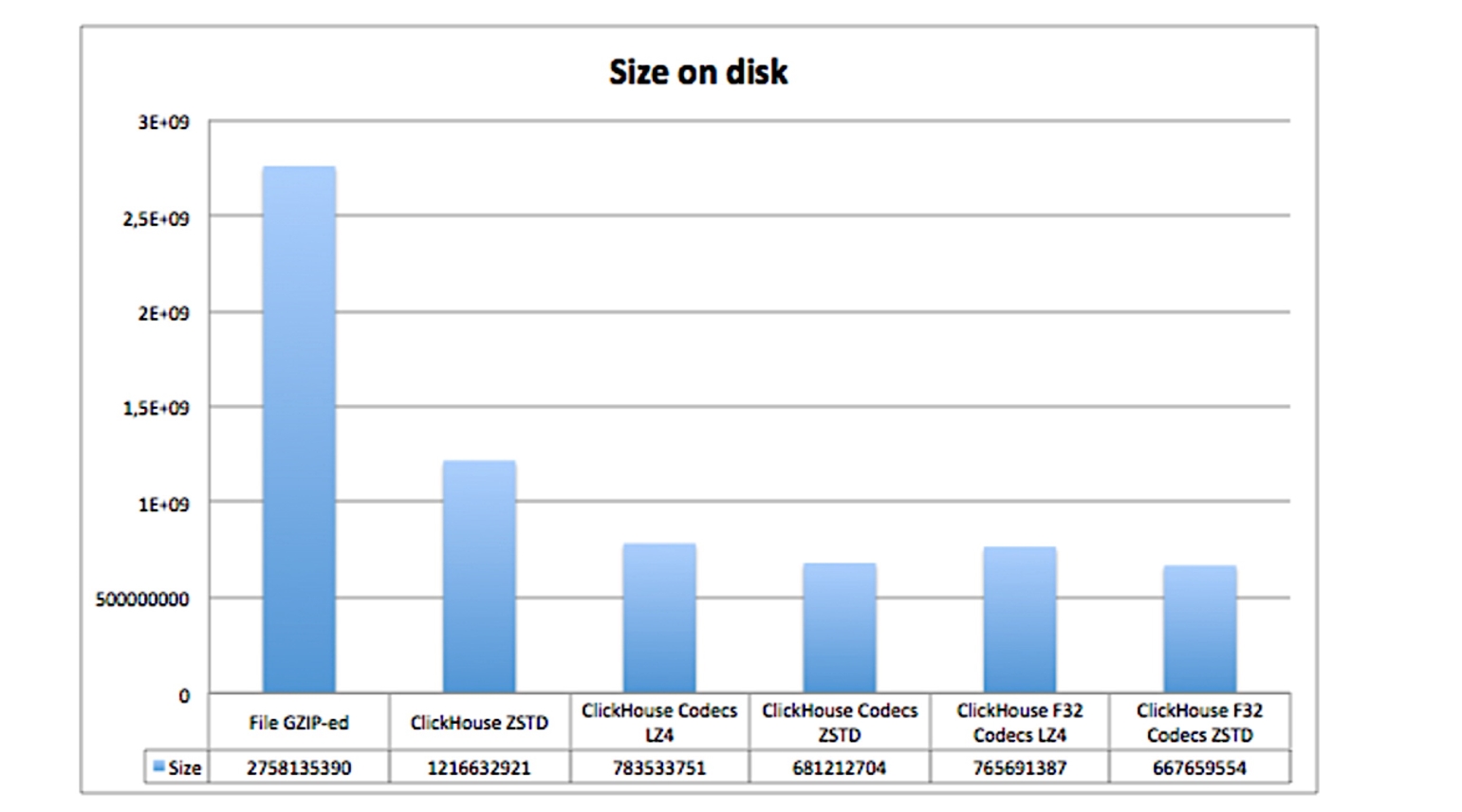
Здесь показано, сколько места занимают одни и те же данные, но при использовании разных кодеков и компрессий:
Видно, что таблицы с кодеками занимают гораздо меньше места.
Не менее важно выбрать правильный тип данных:
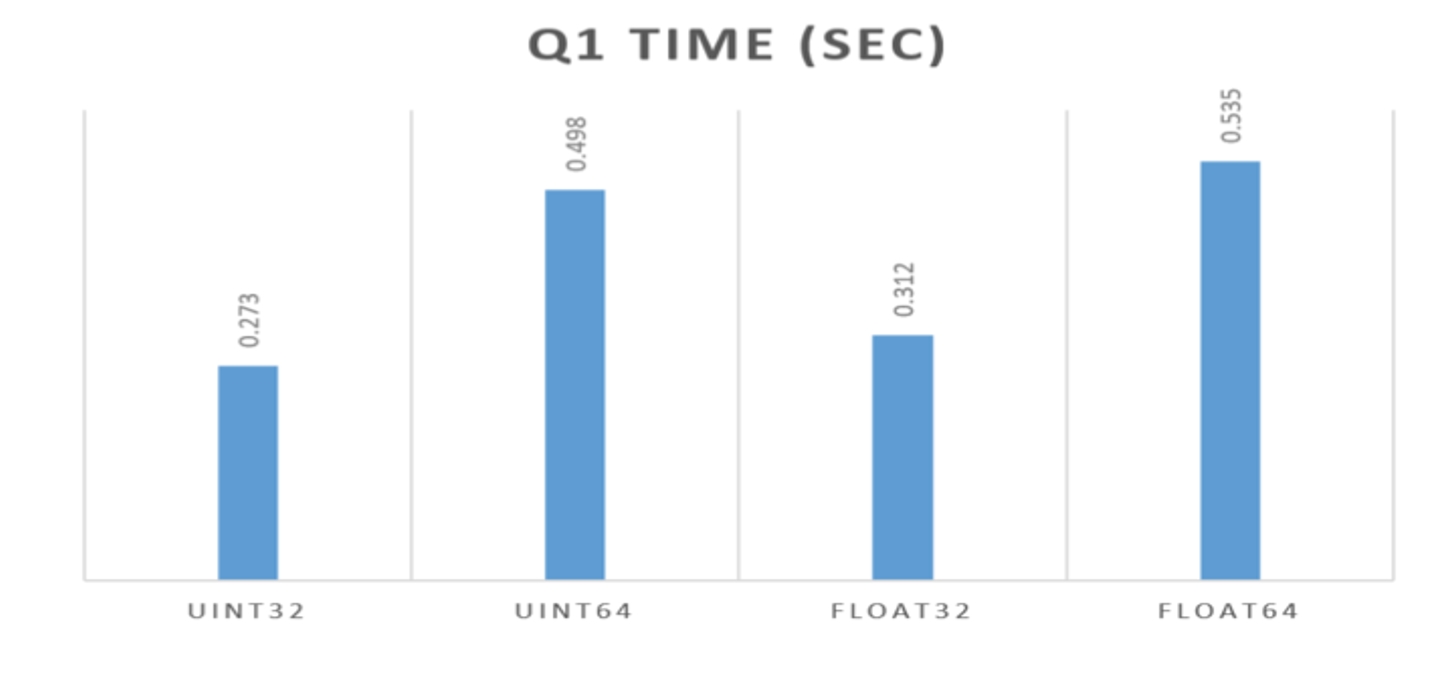
Во всех примерах выше я использовал Float64. Но если бы мы выбрали Float32, то это было бы даже лучше. Это хорошо продемонстрировали ребята из Перконы в статье по ссылке выше. Важно использовать максимально компактный тип, подходящий под задачу: даже в меньшей степени для размера на диске, чем для скорости запросов. ClickHouse очень к этому чувствителен.
Если вы можете использовать int32 вместо int64, то ожидайте почти двукратное увеличение производительности. Данные занимают меньше памяти, и вся «арифметика» работает гораздо быстрее. ClickHouse внутри себя — очень строго типизированная система, он максимально использует все возможности, которые предоставляют современные системы.
Агрегация и материализованные представления позволяют сделать агрегаты на разные случаи жизни:

Например, у вас могут быть не агрегированные исходные данные, и на них можно навесить различные материализованные представления с автоматическим суммированием через специальный движок SummingMergeTree (SMT). SMT — это специальная агрегирующая структура данных, которая считает агрегаты автоматически. В базу данных вставляются сырые данные, они автоматически агрегируются, и сразу по ним можно использовать дашборды.
Как «забывать» данные, которые больше не нужны? ClickHouse умеет это. При создании таблиц можно указать TTL выражения: например, что минутные данные храним один день, дневные — 30 дней, а недельные или месячные не трогаем никогда:
Развивая эту идею, данные можно хранить в ClickHouse в разных местах. Предположим, горячие данные за последнюю неделю хотим хранить на очень быстром локальном SSD, а более исторические данные складываем в другое место. В ClickHouse сейчас это возможно:

Можно сконфигурировать политику хранения (storage policy) так, что ClickHouse будет автоматически перекладывать данные по достижению некоторых условий в другое хранилище.
Но и это еще не все. На уровне конкретной таблицы можно определить правила, когда именно по времени данные переходят на холодное хранение. Например, 7 дней данные лежат на очень быстром диске, а все, что старше, переносится на медленный. Это хорошо тем, что позволяет систему держать на максимальной производительности, при этом контролируя расходы и не тратя средства на холодные данные:
Почти во всём в ClickHouse есть такие «изюминки», но они нивелируются эксклюзивом — тем, чего нет в других БД. Например, вот некоторые из уникальных функций ClickHouse:
В ClickHouse есть много различных способов сделать одно и то же. Например, можно тремя различными способами вернуть последнее значение из таблицы для CPU (есть еще и четвертый, но он ещё экзотичнее).
Первый показывает, как удобно делать в ClickHouse запросы, когда вы хотите проверять, что tuple содержится в подзапросе. Это то, чего мне лично очень не хватало в других БД. Если я хочу что-то сравнить с подзапросом, то в других БД с ним можно сравнивать только скаляр, а для нескольких колонок надо писать JOIN. В ClickHouse можно использовать tuple:
Второй способ делает то же самое, но использует агрегатную функцию argMax:
В ClickHouse есть несколько десятков агрегатных функций, а если использовать комбинаторы, то по законам комбинаторики их получится около тысячи. ArgMax — одна из функций, которая считает максимальное значение: запрос возвращает значение usage_user, на котором достигается максимальное значение created_at:
ASOF JOIN — «склеивание» рядов c разным временем. Это уникальная функция для баз данных, которая есть ещё только в kdb+. Если есть два временных ряда с разным временем, ASOF JOIN позволяет их сместить и склеить в одном запросе. Для каждого значения в одном временном ряду находится ближайшее значение в другом, и они возвращаются на одной строчек:
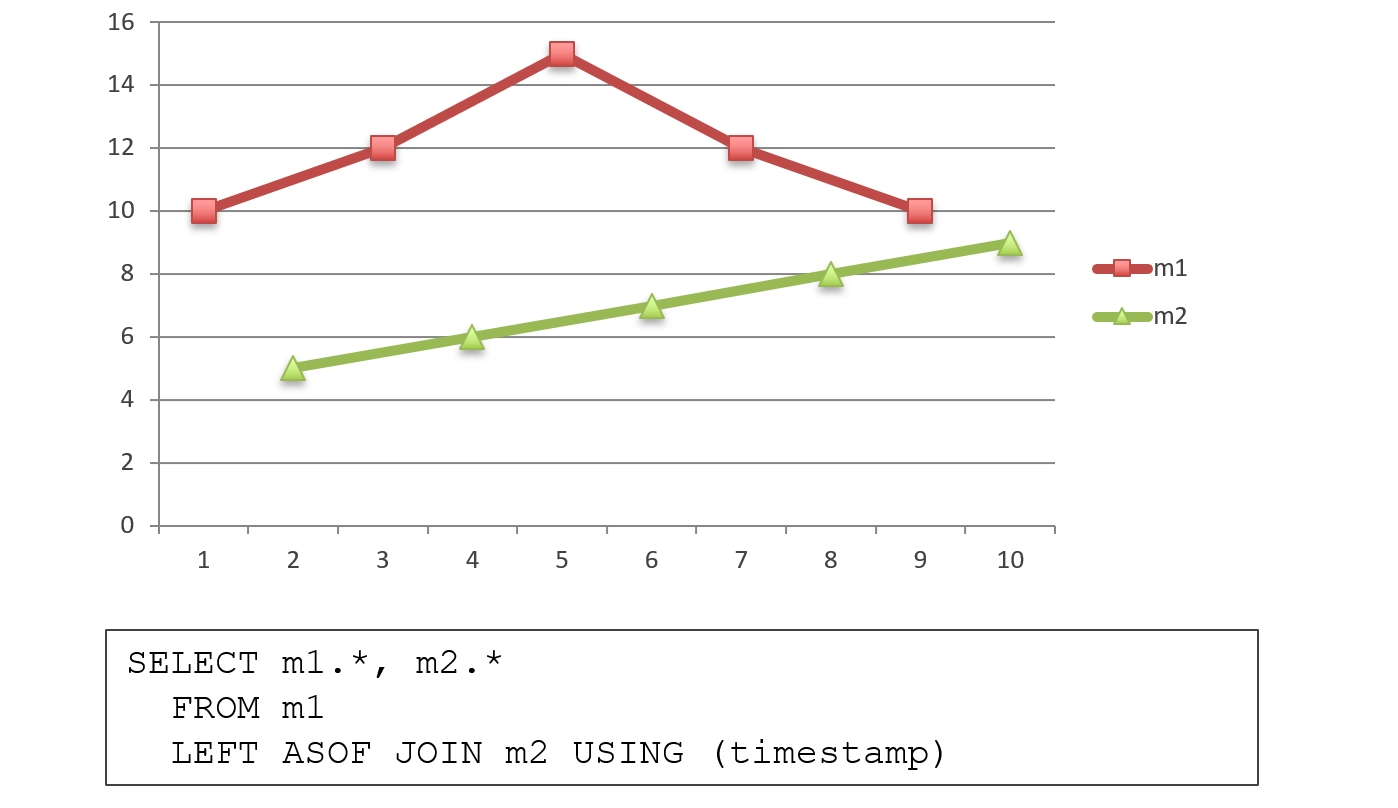
В стандарте SQL-2003 можно писать так:
В ClickHouse так нельзя — он не поддерживает стандарт SQL-2003 и, наверное, никогда не будет это делать. Вместо этого в ClickHouse принято писать так:

Это аналог аналитического запроса в стандарте SQL-2003: он считает разницу между двумя timestamp, duration, порядковый номер — всё, что обычно мы считаем аналитическими функциями. В ClickHouse мы их считаем через массивы: сначала сворачиваем данные в массив, после этого на массиве делаем всё, что хотим, а потом разворачиваем обратно. Это не очень удобно, требует любви к функциональному программированию, как минимум, но это очень гибко.
Кроме того в ClickHouse много специализированных функций. Например, как определить, сколько сессий проходит одновременно? Типичная задача для мониторинга – определить максимальную загрузку одним запросом. В ClickHouse есть специальная функция для этой цели:

Вообще, для многих целей в ClickHouse есть специальные функции:
Это не полный список функций, всего их 500-600. Хинт: все функции в ClickHouse есть в системной таблице (не все документированы, но все интересны):
ClickHouse сам в себе хранит много информации о себе, в том числе log tables, query_log, лог трассировки, лог операции с блоками данных (part_log), лог метрик, и системный лог, который он обычно пишет на диск. Лог метрик – это time-series в ClickHouse на самом ClickHouse: БД сама для себя может играть роль time-series баз данных, таким образом «пожирая» самого себя.

Это тоже уникальная вещь — раз мы хорошо делаем работу для time-series, почему не можем сами в себе хранить всё, что нужно? Нам не нужен Prometheus, мы храним всё в себе. Подключили Grafana и сами себя мониторим. Однако, если ClickHouse упадет, то мы не увидим, — почему, — поэтому обычно так не делают.
Что лучше — один большой кластер или много маленьких ClickHouse? Традиционный подход к DWH — это большой кластер, в котором выделяются схемы под каждое приложение. Мы пришли к администратору БД — дайте нам схему, и нам её выдали:
В ClickHouse можно сделать это по-другому. Можно каждому приложению сделать свой собственный ClickHouse:
Нам больше не нужен большой монструозный DWH и несговорчивые админы. Мы можем каждому приложению выдать свой собственный ClickHouse, и разработчик может это сделать сам, так как ClickHouse очень просто устанавливается и не требует сложного администрирования:

Но если у нас много ClickHouse, и надо часто его ставить, то хочется этот процесс автоматизировать. Для этого можно, например, используем Kubernetes и clickhouse-оператор. В Kubernetes ClickHouse можно поставить «по щелчку»: я могу нажать кнопку, запустить манифест и база готова. Можно сразу же создать схему, начать туда грузить метрики, и через 5 минут у меня уже готов дашборд Grafana. Настолько все просто!
Итак, ClickHouse — это:
Презетацию можно посмотреть здесь.

Три года спустя ClickHouse стал гораздо лучше — за это время Александр основал компанию Altinity, которая не только помогает переезжать на ClickHouse десяткам проектов, но и совершенствует сам продукт вместе с коллегами из Яндекса. Сейчас ClickHouse все еще не беззаботная прогулка, но уже и не минное поле.
Александр занимается распределенными системами с 2003 года, разрабатывал крупные проекты на MySQL, Oracle и Vertica. На прошедшей HighLoad++ 2019 Александр, один из пионеров использования ClickHouse, рассказал, что сейчас из себя представляет эта СУБД. Мы узнаем про основные особенности ClickHouse: чем он отличается от других систем и в каких случаях его эффективнее использовать. На примерах рассмотрим свежие и проверенные проектами практики по построению систем на ClickHouse.
Ретроспектива: что было 3 года назад
Три года назад мы переводили компанию LifeStreet на ClickHouse с другой аналитической базы данных, и миграция аналитики рекламной сети выглядела так:
- Июнь 2016. В OpenSource появился ClickHouse и стартовал наш проект;
- Август. Proof Of Concept: большая рекламная сеть, инфраструктура и 200-300 терабайт данных;
- Октябрь. Первые продакшн-данные;
- Декабрь. Полная продуктовая нагрузка — 10-50 миллиардов событий в день.
- Июнь 2017. Успешный переезд пользователей на ClickHouse, 2,5 петабайт данных на кластере из 60-ти серверов.
В процессе миграции росло понимание, что ClickHouse — это хорошая система, с которой приятно работать, но это внутренний проект компании Яндекс. Поэтому есть нюансы: Яндекс сначала будет заниматься собственными внутренними заказчиками и только потом — сообществом и нуждами внешних пользователей, а ClickHouse не дотягивал тогда до уровня энтерпрайза по многим функциональным областям. Поэтому в марте 2017 года мы основали компанию Altinity, чтобы сделать ClickHouse ещё быстрее и удобнее не только для Яндекса, но и для других пользователей. И теперь мы:
- Обучаем и помогаем строить решения на ClickHouse так, чтобы заказчики не набивали шишки, и чтобы решение в итоге работало;
- Обеспечиваем 24/7 поддержку ClickHouse-инсталляций;
- Разрабатываем собственные экосистемные проекты;
- Активно коммитим в сам ClickHouse, отвечая на запросы пользователей, которые хотят видеть те или иные фичи.
И конечно, мы помогаем с переездом на ClickHouse с MySQL, Vertica, Oracle, Greenplum, Redshift и других систем. Мы участвовали в самых разных переездах, и они все были успешными.
Зачем вообще переезжать на ClickHouse
Не тормозит! Это главная причина. ClickHouse — очень быстрая база данных для разных сценариев:
Случайные цитаты людей, которые долго работают с ClickHouse.
Масштабируемость. На какой-то другой БД можно добиться неплохой производительности на одной железке, но ClickHouse можно масштабировать не только вертикально, но и горизонтально, просто добавляя сервера. Все работает не так гладко, как хотелось бы, но работает. Можно наращивать систему вместе с ростом бизнеса. Это важно, что мы не ограничены решением сейчас и всегда есть потенциал для развития.
Портируемость. Нет привязки к чему-то одному. Например, с Amazon Redshift тяжело куда-то переехать. А ClickHouse можно поставить себе на ноутбук, сервер, задеплоить в облако, уйти в Kubernetes — нет ограничений на эксплуатацию инфраструктуры. Это удобно для всех, и это большое преимущество, которым не могут похвастаться многие другие похожие БД.
Гибкость. ClickHouse не останавливается на чем-то одном, например, на Яндекс.Метрике, а развивается и используется во всё большем и большем количестве разных проектов и индустрий. Его можно расширять, добавляя новые возможности для решения новых задач. Например, считается, что хранить логи в БД — моветон, поэтому для этого придумали Elasticsearch. Но, благодаря гибкости ClickHouse, в нём тоже можно хранить логи, и часто это даже лучше, чем в Elasticsearch — в ClickHouse для этого требуется в 10 раз меньше железа.
Бесплатный Open Source. Не нужно ни за что платить. Не нужно договариваться о разрешении поставить систему себе на ноутбук или сервер. Нет скрытых платежей. При этом никакая другая Open Source технология баз данных не может конкурировать по скорости с ClickHouse. MySQL, MariaDB, Greenplum — все они гораздо медленнее.
Сообщество, драйв и fun. У ClickHouse отличное сообщество: митапы, чаты и Алексей Миловидов, который нас всех заряжает своей энергией и оптимизмом.
Переезд на ClickHouse
Чтобы переходить на ClickHouse с чего-то, нужны всего лишь три вещи:
- Понимать ограничения ClickHouse и для чего он не подходит.
- Использовать преимущества технологии и ее самые сильные стороны.
- Экспериментировать. Даже понимая как работает ClickHouse, не всегда возможно предугадать, когда он будет быстрее, когда медленней, когда лучше, а когда хуже. Поэтому пробуйте.
Проблема переезда
Есть только одно «но»: если переезжаете на ClickHouse с чего-то другого, то обычно что-то идет не так. Мы привыкли к каким-то практикам и вещам, которые работают в любимой БД. Например, любой человек, работающий с SQL-базами данных, считает обязательными такой набор функций:
- транзакции;
- констрейнты;
- consistency;
- индексы;
- UPDATE/DELETE;
- NULLs;
- миллисекунды;
- автоматические приведения типов;
- множественные джойны;
- произвольные партиции;
- средства управления кластером.
Набор-то обязательный, но три года назад в ClickHouse не было ни одной из этих функций! Сейчас из нереализованного осталось меньше половины: транзакции, констрейнты, Consistency, миллисекунды и приведение типов.
И главное — то, что в ClickHouse некоторые стандартные практики и подходы не работают или работают не так, как мы привыкли. Всё, что появляется в ClickHouse, соответствует «ClickHouse way», т.е. функции отличаются от других БД. Например:
- Индексы не выбирают, а пропускают.
- UPDATE/DELETE не синхронные, а асинхронные.
- Множественные джойны есть, но планировщика запросов нет. Как они тогда выполняются, вообще не очень понятно людям из мира БД.
Сценарии ClickHouse
В 1960 году американский математик венгерского происхождения Wigner E. P. написал статью «The unreasonable effectiveness of mathematics in the natural sciences» («Непостижимая эффективность математики в естественных науках») о том, что окружающий мир почему-то хорошо описывается математическими законами. Математика — абстрактная наука, а физические законы, выраженные в математической форме не тривиальны, и Wigner E. P. подчеркнул, что это очень странно.
С моей точки зрения, ClickHouse — такая же странность. Переформулируя Вигнера, можно сказать так: поразительна непостижимая эффективность ClickHouse в самых разнообразных аналитических приложениях!
Например, возьмем Real-Time Data Warehouse, в который данные грузятся практически непрерывно. Мы хотим получать от него запросы с секундной задержкой. Пожалуйста — используем ClickHouse, потому что для этого сценария он и был разработан. ClickHouse именно так и используется не только в веб, но и в маркетинговой и финансовой аналитике, AdTech, а также в Fraud detection. В Real-time Data Warehouse используется сложная структурированная схема типа «звезда» или «снежинка», много таблиц с JOIN (иногда множественными), а данные обычно хранятся и меняются в каких-то системах.
Возьмем другой сценарий — Time Series: мониторинг устройств, сетей, статистика использования, интернет вещей. Здесь мы встречаемся с упорядоченными по времени достаточно простыми событиями. ClickHouse для этого не был изначально разработан, но хорошо себя показал, поэтому крупные компании используют ClickHouse как хранилище для мониторинговой информации. Чтобы изучить, подходит ли ClickHouse для time-series, мы сделали бенчмарк на основе подхода и результатах InfluxDB и TimescaleDB — специализированных time-series баз данных. Оказалось, что ClickHouse, даже без оптимизации под такие задачи, выигрывает и на чужом поле:
В time-series обычно используется узкая таблица — несколько маленьких колонок. С мониторинга может приходить очень много данных, — миллионы записей в секунду, — и обычно они поступают маленькими вставками (real-time стримингом). Поэтому нужен другой сценарий вставки, а сами запросы — со своей некоторой спецификой.
Log Management. Сбор логов в БД — это обычно плохо, но в ClickHouse это можно делать с некоторыми комментариями, как описано выше. Многие компании используют ClickHouse именно для этого. В этом случае используется плоская широкая таблица, где мы храним логи целиком (например, в виде JSON), либо нарезаем на части. Данные загружаются обычно большими батчами (файлами), а ищем по какому-нибудь полю.
Для каждой из этих функций обычно используются специализированные БД. ClickHouse один может делать это всё и настолько хорошо, что обгоняет их по производительности. Давайте теперь подробно рассмотрим time-series сценарий, и как правильно «готовить» ClickHouse под этот сценарий.
Time-Series
В настоящий момент это основной сценарий, для которого ClickHouse считается стандартным решением. Time-series — это набор упорядоченных во времени событий, представляющих изменения какого-то процесса во времени. Например, это может быть частота сердцебиений за день или количество процессов в системе. Всё, что дает временные тики с какими-то измерениями – это time-series:
Больше всего такого рода событий приходит из мониторинга. Это может быть не только мониторинг веба, но и реальных устройств: автомобилей, промышленных систем, IoT, производств или беспилотных такси, в багажник которых Яндекс уже сейчас кладет ClickHouse-сервер.
Например, есть компании, которые собирают данные с судов. Каждые несколько секунд датчики с контейнеровоза отправляют сотни различных измерений. Инженеры их изучают, строят модели и пытаются понять, насколько эффективно используется судно, потому что контейнеровоз не должен простаивать ни секунды. Любой простой — это потеря денег, поэтому важно спрогнозировать маршрут так, чтобы стоянки были минимальными.
Сейчас наблюдается рост специализированных БД, которые измеряют time-series. На сайте DB-Engines каким-то образом ранжируются разные базы данных, и их можно посмотреть по типам:
Самый быстрорастущий тип — time-series. Также растут графовые БД, но time-series растут быстрее последние несколько лет. Типичные представители БД этого семейства — это InfluxDB, Prometheus, KDB, TimescaleDB (построенная на PostgreSQL), решения от Amazon. ClickHouse здесь тоже может быть использован, и он используется. Приведу несколько публичных примеров.
Один из пионеров — компания CloudFlare (CDN-провайдер). Они мониторят свой CDN через ClickHouse (DNS-запросы, HTTP-запросы) с громадной нагрузкой — 6 миллионов событий в секунду. Все идет через Kafka, отправляется в ClickHouse, который предоставляет возможность в реальном времени видеть дашборды событий в системе.
Comcast — один из лидеров телекоммуникаций в США: интернет, цифровое телевидение, телефония. Они создали аналогичную систему управления CDN в рамках Open Source проекта Apache Traffic Control для работы со своими огромными данными. ClickHouse используется как бэкенд для аналитики.
Percona встроили ClickHouse внутрь своего PMM, чтобы хранить мониторинг различных MySQL.
Специфические требования
К time-series базам данных есть свои специфические требования.
- Быстрая вставка со многих агентов. Мы должны очень быстро вставить данные со многих потоков. ClickHouse хорошо это делает, потому что у него все вставки не блокирующие. Любой insert — это новый файл на диске, а маленькие вставки можно буферизовать тем или иным способом. В ClickHouse лучше вставлять данные большими пакетами, а не по одной строчке.
- Гибкая схема. В time-series мы обычно не знаем структуру данных до конца. Можно построить систему мониторинга для конкретного приложения, но тогда ее трудно использовать для другого приложения. Для этого нужна более гибкая схема. ClickHouse, позволяет это сделать, даже несмотря на то, что это строго типизированная база.
- Эффективное хранение и «забывание» данных. Обычно в time-series гигантский объем данных, поэтому их надо хранить максимально эффективно. Например, у InfluxDB хорошая компрессия — это его основная фишка. Но кроме хранения, нужно еще уметь и «забывать» старые данные и делать какой-нибудь downsampling — автоматический подсчет агрегатов.
- Быстрые запросы агрегированных данных. Иногда интересно посмотреть последние 5 минут с точностью до миллисекунд, но на месячных данных минутная или секундная гранулярность может быть не нужна — достаточно общей статистики. Поддержка такого рода необходима, иначе запрос за 3 месяца будет выполняться очень долго даже в ClickHouse.
- Запросы типа «last point, as of». Это типичные для time-series запросы: смотрим последнее измерение или состояние системы в момент времени t. Для БД это не очень приятные запросы, но их тоже надо уметь выполнять.
- «Склеивание» временных рядов. Time-series — это временной ряд. Если есть два временных ряда, то их часто нужно соединять и коррелировать. Не на всех БД это удобно делать, особенно, с невыравненными временными рядами: здесь — одни временные засечки, там — другие. Можно считать средние, но вдруг там все равно будет дырка, поэтому непонятно.
Давайте посмотрим, как эти требования выполняются в ClickHouse.
Схема
В ClickHouse схему для time-series можно сделать разными способами, в зависимости от степени регулярности данных. Можно построить систему на регулярных данных, когда мы знаем все метрики заранее. Например, так сделал CloudFlare с мониторингом CDN — это хорошо оптимизированная система. Можно построить более общую систему, которая мониторит всю инфраструктуру, разные сервисы. В случае нерегулярных данных, мы не знаем заранее, что мониторим — и, наверное, это наболее общий случай.
Регулярные данные. Колонки. Схема простая – колонки с нужными типами:
CREATE TABLE cpu (
created_date Date DEFAULT today(),
created_at DateTime DEFAULT now(),
time String,
tags_id UInt32, /* join to dim_tag */
usage_user Float64,
usage_system Float64,
usage_idle Float64,
usage_nice Float64,
usage_iowait Float64,
usage_irq Float64,
usage_softirq Float64,
usage_steal Float64,
usage_guest Float64,
usage_guest_nice Float64
) ENGINE = MergeTree(created_date, (tags_id, created_at), 8192);Это обычная таблица, которая мониторит какую-то активность по загрузке системы (user, system, idle, nice). Просто и удобно, но не гибко. Если хотим более гибкую схему, то можно использовать массивы.
Нерегулярные данные. Массивы:
CREATE TABLE cpu_alc (
created_date Date,
created_at DateTime,
time String,
tags_id UInt32,
metrics Nested(
name LowCardinality(String),
value Float64
)
) ENGINE = MergeTree(created_date, (tags_id, created_at), 8192);
SELECT max(metrics.value[indexOf(metrics.name,'usage_user')]) FROM ...
Структура Nested — это два массива: metrics.name и metrics.value. Здесь можно хранить такие произвольные мониторинговые данные, как массив названий и массив измерений при каждом событии. Для дальнейшей оптимизации вместо одной такой структуры можно сделать несколько. Например, одну — для float-значение, другую — для int-значение, потому что int хочется хранить эффективнее.
Но к такой структуре сложнее обращаться. Придется использовать специальную конструкцию, через специальные функции вытаскивать значения сначала индекса, а потом массива:
SELECT max(metrics.value[indexOf(metrics.name,'usage_user')]) FROM ...Но это все равно работает достаточно быстро. Другой способ хранения нерегулярных данных – по строкам.
Нерегулярные данные. Строки. В этом традиционном способе без массивов хранятся сразу названия и значения. Если с одного устройства приходит сразу 5 000 измерений — генерируется 5 000 строк в БД:
CREATE TABLE cpu_rlc (
created_date Date,
created_at DateTime,
time String,
tags_id UInt32,
metric_name LowCardinality(String),
metric_value Float64
) ENGINE = MergeTree(created_date, (metric_name, tags_id, created_at), 8192);
SELECT
maxIf(metric_value, metric_name = 'usage_user'),
...
FROM cpu_r
WHERE metric_name IN ('usage_user', ...)
ClickHouse с этим справляется — у него есть специальные расширения ClickHouse SQL. Например, maxIf — специальная функция, которая считает максимум по метрике при выполнении какого-то условия. Можно в одном запросе написать несколько таких выражений и сразу посчитать значение для нескольких метрик.
Сравним три подхода:
Детали
Здесь я добавил «Размер данных на диске» для некоторого тестового набора данных. В случае с колонками у нас самый маленький размер данных: максимальное сжатие, максимальная скорость запросов, но мы платим тем, что должны все сразу зафиксировать.
В случае с массивами всё чуть хуже. Данные все равно хорошо сжимаются, и можно хранить нерегулярную схему. Но ClickHouse — колоночная база данных, а когда мы начинаем хранить все в массиве, то она превращается в строковую, и мы платим за гибкость эффективностью. На любую операцию придется прочитать весь массив в память, после этого найти в нем нужный элемент — а если массив растет, то скорость деградирует.
В одной из компаний, которая использует такой подход (например, Uber), массивы нарезаются на кусочки из 128 элементов. Данные нескольких тысяч метрик объемом в 200 ТБ данных/в день хранятся не в одном массиве, а в из 10 или 30 массивах со специальной логикой для хранения.
Максимально простой подход — со строками. Но данные плохо сжимаются, размер таблицы получается большой, да ещё когда запросы идут по нескольким метрикам, то ClickHouse работает неоптимально.
Гибридная схема
Предположим, что мы выбрали схему с массивом. Но если мы знаем, что большинство наших дашбордов показывают только метрики user и system, мы можем дополнительно из массива на уровне таблицы материализовать эти метрики в колонки таким образом:
CREATE TABLE cpu_alc (
created_date Date,
created_at DateTime,
time String,
tags_id UInt32,
metrics Nested(
name LowCardinality(String),
value Float64
),
usage_user Float64
MATERIALIZED metrics.value[indexOf(metrics.name,'usage_user')],
usage_system Float64
MATERIALIZED metrics.value[indexOf(metrics.name,'usage_system')]
) ENGINE = MergeTree(created_date, (tags_id, created_at), 8192);
При вставке ClickHouse автоматически их посчитает. Так можно совместить приятное с полезным: схема гибкая и общая, но самые часто используемые колонки мы вытащили. Замечу, что это не потребовало менять вставку и ETL, который продолжает вставлять в таблицу массивы. Мы просто сделали ALTER TABLE, добавили пару колонок и получилась гибридная и более быстрая схема, которой можно сразу начинать пользоваться.
Кодеки и компрессия
Для time-series важно, насколько хорошо вы упаковываете данные, потому что массив информации может быть очень большой. В ClickHouse есть набор средств для достижения эффекта компрессии 1:10, 1:20, а иногда и больше. Это значит, что неупакованные данные объемом 1 ТБ на диске занимают 50-100 ГБ. Меньший размер — это хорошо, данные быстрее можно прочитать и обработать.
Для достижения высокого уровня компрессии, ClickHouse поддерживает следующие кодеки:
Пример таблицы:
CREATE TABLE benchmark.cpu_codecs_lz4 (
created_date Date DEFAULT today(),
created_at DateTime DEFAULT now() Codec(DoubleDelta, LZ4),
tags_id UInt32,
usage_user Float64 Codec(Gorilla, LZ4),
usage_system Float64 Codec(Gorilla, LZ4),
usage_idle Float64 Codec(Gorilla, LZ4),
usage_nice Float64 Codec(Gorilla, LZ4),
usage_iowait Float64 Codec(Gorilla, LZ4),
usage_irq Float64 Codec(Gorilla, LZ4),
usage_softirq Float64 Codec(Gorilla, LZ4),
usage_steal Float64 Codec(Gorilla, LZ4),
usage_guest Float64 Codec(Gorilla, LZ4),
usage_guest_nice Float64 Codec(Gorilla, LZ4),
additional_tags String DEFAULT ''
)
ENGINE = MergeTree(created_date, (tags_id, created_at), 8192);Здесь мы определяем кодек DoubleDelta в одном случае, во втором — Gorilla, и обязательно добавляем еще LZ4 компрессию. В результате размер данных на диске сильно уменьшается:
Здесь показано, сколько места занимают одни и те же данные, но при использовании разных кодеков и компрессий:
- в GZIP’ованном файле на диске;
- в ClickHouse без кодеков, но с ZSTD-компрессией;
- в ClickHouse c кодеками и компрессией LZ4 и ZSTD.
Видно, что таблицы с кодеками занимают гораздо меньше места.
Размер имеет значение
Не менее важно выбрать правильный тип данных:
Во всех примерах выше я использовал Float64. Но если бы мы выбрали Float32, то это было бы даже лучше. Это хорошо продемонстрировали ребята из Перконы в статье по ссылке выше. Важно использовать максимально компактный тип, подходящий под задачу: даже в меньшей степени для размера на диске, чем для скорости запросов. ClickHouse очень к этому чувствителен.
Если вы можете использовать int32 вместо int64, то ожидайте почти двукратное увеличение производительности. Данные занимают меньше памяти, и вся «арифметика» работает гораздо быстрее. ClickHouse внутри себя — очень строго типизированная система, он максимально использует все возможности, которые предоставляют современные системы.
Агрегация и Materialized Views
Агрегация и материализованные представления позволяют сделать агрегаты на разные случаи жизни:
Например, у вас могут быть не агрегированные исходные данные, и на них можно навесить различные материализованные представления с автоматическим суммированием через специальный движок SummingMergeTree (SMT). SMT — это специальная агрегирующая структура данных, которая считает агрегаты автоматически. В базу данных вставляются сырые данные, они автоматически агрегируются, и сразу по ним можно использовать дашборды.
TTL — «забываем» старые данные
Как «забывать» данные, которые больше не нужны? ClickHouse умеет это. При создании таблиц можно указать TTL выражения: например, что минутные данные храним один день, дневные — 30 дней, а недельные или месячные не трогаем никогда:
CREATE TABLE aggr_by_minute
…
TTL time + interval 1 day
CREATE TABLE aggr_by_day
…
TTL time + interval 30 day
CREATE TABLE aggr_by_week
…
/* no TTL */
Multi-tier — разделяем данные по дискам
Развивая эту идею, данные можно хранить в ClickHouse в разных местах. Предположим, горячие данные за последнюю неделю хотим хранить на очень быстром локальном SSD, а более исторические данные складываем в другое место. В ClickHouse сейчас это возможно:
Можно сконфигурировать политику хранения (storage policy) так, что ClickHouse будет автоматически перекладывать данные по достижению некоторых условий в другое хранилище.
Но и это еще не все. На уровне конкретной таблицы можно определить правила, когда именно по времени данные переходят на холодное хранение. Например, 7 дней данные лежат на очень быстром диске, а все, что старше, переносится на медленный. Это хорошо тем, что позволяет систему держать на максимальной производительности, при этом контролируя расходы и не тратя средства на холодные данные:
CREATE TABLE
...
TTL date + INTERVAL 7 DAY TO VOLUME 'cold_volume',
date + INTERVAL 180 DAY DELETE
Уникальные возможности ClickHouse
Почти во всём в ClickHouse есть такие «изюминки», но они нивелируются эксклюзивом — тем, чего нет в других БД. Например, вот некоторые из уникальных функций ClickHouse:
- Массивы. В ClickHouse очень хорошая поддержка для массивов, а также возможность выполнять на них сложные вычисления.
- Агрегирующие структуры данных. Это одна из «киллер-фич» ClickHouse. Несмотря на то, что ребята из Яндекса говорят, что мы не хотим агрегировать данные, все агрегируют в ClickHouse, потому что это быстро и удобно.
- Материализованные представления. Вместе с агрегирующими структурами данных материализованные представления позволяют делать удобную real-time агрегацию.
- ClickHouse SQL. Это расширение языка SQL с некоторыми дополнительными и эксклюзивными фичами, которые есть только в ClickHouse. Раньше это было как бы с одной стороны расширение, а с другой стороны — недостаток. Сейчас почти все недостатки по сравнению с SQL 92 мы убрали, теперь это только расширение.
- Lambda–выражения. Есть ли они ещё в какой-нибудь базе данных?
- ML-поддержка. Это есть в разных БД, в каких-то лучше, в каких-то хуже.
- Открытый код. Мы можем расширять ClickHouse вместе. Сейчас в ClickHouse около 500 контрибьюторов, и это число постоянно растет.
Хитрые запросы
В ClickHouse есть много различных способов сделать одно и то же. Например, можно тремя различными способами вернуть последнее значение из таблицы для CPU (есть еще и четвертый, но он ещё экзотичнее).
Первый показывает, как удобно делать в ClickHouse запросы, когда вы хотите проверять, что tuple содержится в подзапросе. Это то, чего мне лично очень не хватало в других БД. Если я хочу что-то сравнить с подзапросом, то в других БД с ним можно сравнивать только скаляр, а для нескольких колонок надо писать JOIN. В ClickHouse можно использовать tuple:
SELECT *
FROM cpu
WHERE (tags_id, created_at) IN
(SELECT tags_id, max(created_at)
FROM cpu
GROUP BY tags_id)Второй способ делает то же самое, но использует агрегатную функцию argMax:
SELECT
argMax(usage_user), created_at),
argMax(usage_system), created_at),
...
FROM cpu В ClickHouse есть несколько десятков агрегатных функций, а если использовать комбинаторы, то по законам комбинаторики их получится около тысячи. ArgMax — одна из функций, которая считает максимальное значение: запрос возвращает значение usage_user, на котором достигается максимальное значение created_at:
SELECT now() as created_at,
cpu.*
FROM (SELECT DISTINCT tags_id from cpu) base
ASOF LEFT JOIN cpu USING (tags_id, created_at)
ASOF JOIN — «склеивание» рядов c разным временем. Это уникальная функция для баз данных, которая есть ещё только в kdb+. Если есть два временных ряда с разным временем, ASOF JOIN позволяет их сместить и склеить в одном запросе. Для каждого значения в одном временном ряду находится ближайшее значение в другом, и они возвращаются на одной строчек:
Аналитические функции
В стандарте SQL-2003 можно писать так:
SELECT origin,
timestamp,
timestamp -LAG(timestamp, 1) OVER (PARTITION BY origin ORDER BY timestamp) AS duration,
timestamp -MIN(timestamp) OVER (PARTITION BY origin ORDER BY timestamp) AS startseq_duration,
ROW_NUMBER() OVER (PARTITION BY origin ORDER BY timestamp) AS sequence,
COUNT() OVER (PARTITION BY origin ORDER BY timestamp) AS nb
FROM mytable
ORDER BY origin, timestamp;
В ClickHouse так нельзя — он не поддерживает стандарт SQL-2003 и, наверное, никогда не будет это делать. Вместо этого в ClickHouse принято писать так:
Я обещал лямбды – вот они!
Это аналог аналитического запроса в стандарте SQL-2003: он считает разницу между двумя timestamp, duration, порядковый номер — всё, что обычно мы считаем аналитическими функциями. В ClickHouse мы их считаем через массивы: сначала сворачиваем данные в массив, после этого на массиве делаем всё, что хотим, а потом разворачиваем обратно. Это не очень удобно, требует любви к функциональному программированию, как минимум, но это очень гибко.
Специальные функции
Кроме того в ClickHouse много специализированных функций. Например, как определить, сколько сессий проходит одновременно? Типичная задача для мониторинга – определить максимальную загрузку одним запросом. В ClickHouse есть специальная функция для этой цели:
Вообще, для многих целей в ClickHouse есть специальные функции:
- runningDifference, runningAccumulate, neighbor;
- sumMap(key, value);
- timeSeriesGroupSum(uid, timestamp, value);
- timeSeriesGroupRateSum(uid, timestamp, value);
- skewPop, skewSamp, kurtPop, kurtSamp;
- WITH FILL / WITH TIES;
- simpleLinearRegression, stochasticLinearRegression.
Это не полный список функций, всего их 500-600. Хинт: все функции в ClickHouse есть в системной таблице (не все документированы, но все интересны):
select * from system.functions order by nameClickHouse сам в себе хранит много информации о себе, в том числе log tables, query_log, лог трассировки, лог операции с блоками данных (part_log), лог метрик, и системный лог, который он обычно пишет на диск. Лог метрик – это time-series в ClickHouse на самом ClickHouse: БД сама для себя может играть роль time-series баз данных, таким образом «пожирая» самого себя.
Это тоже уникальная вещь — раз мы хорошо делаем работу для time-series, почему не можем сами в себе хранить всё, что нужно? Нам не нужен Prometheus, мы храним всё в себе. Подключили Grafana и сами себя мониторим. Однако, если ClickHouse упадет, то мы не увидим, — почему, — поэтому обычно так не делают.
Большой кластер или много маленьких ClickHouse
Что лучше — один большой кластер или много маленьких ClickHouse? Традиционный подход к DWH — это большой кластер, в котором выделяются схемы под каждое приложение. Мы пришли к администратору БД — дайте нам схему, и нам её выдали:
В ClickHouse можно сделать это по-другому. Можно каждому приложению сделать свой собственный ClickHouse:
Нам больше не нужен большой монструозный DWH и несговорчивые админы. Мы можем каждому приложению выдать свой собственный ClickHouse, и разработчик может это сделать сам, так как ClickHouse очень просто устанавливается и не требует сложного администрирования:
Но если у нас много ClickHouse, и надо часто его ставить, то хочется этот процесс автоматизировать. Для этого можно, например, используем Kubernetes и clickhouse-оператор. В Kubernetes ClickHouse можно поставить «по щелчку»: я могу нажать кнопку, запустить манифест и база готова. Можно сразу же создать схему, начать туда грузить метрики, и через 5 минут у меня уже готов дашборд Grafana. Настолько все просто!
Что в итоге?
Итак, ClickHouse — это:
- Быстро. Это всем известно.
- Просто. Немного спорно, но я считаю, что тяжело в учении, легко в бою. Если понять, как ClickHouse работает, дальше все очень просто.
- Универсально. Он подходит для разных сценариев: DWH, Time Series, Log Storage. Но это не OLTP база данных, поэтому не пытайтесь сделать там короткие вставки и чтения.
- Интересно. Наверное, тот, кто работает с ClickHouse, пережил много интересных минут в хорошем и плохом смысле. Например, вышел новый релиз, все перестало работать. Или когда вы бились над задачей два дня, но после вопроса в Телеграм-чате задача решилась за две минуты. Или как на конференции на докладе Леши Миловидова скриншот из ClickHouse сломал трансляцию HighLoad++. Такого рода вещи происходят постоянно и делают нашу жизнь с ClickHouse яркой и интересной!
Презетацию можно посмотреть здесь.
Долгожданная встреча разработчиков высоконагруженных систем на HighLoad++ состоится 9 и 10 ноября в Сколково. Наконец это будет офлайн-конференция (хоть и с соблюдением всех мер предосторожности), так как энергию HighLoad++ невозможно упаковать в онлайн.
Для конференции мы находим и показываем вам кейсы о максимальных возможностях технологий: HighLoad++ был, есть и будет единственным местом, где можно за два дня узнать, как устроены Facebook, Яндекс, ВКонтакте, Google и Amazon.
Проводя наши встречи без перерыва с 2007 года, в этом году мы встретимся в 14-й раз. За это время конференция выросла в 10 раз, в прошлом году ключевое событие отрасли собрало 3339 участника, 165 спикеров докладов и митапов, а одновременно шло 16 треков.
В прошлом году для вас было 20 автобусов, 5280 литров чая и кофе, 1650 литров морсов и 10200 бутылочек воды. А ещё 2640 килограммов еды, 16 000 тарелок и 25 000 стаканчиков. Кстати, на деньги, вырученные от переработанной бумаги, мы посадили 100 саженцев дуба :)
Билеты купить можно здесь, получить новости о конференции — здесь, а поговорить — во всех соцсетях: Telegram, Facebook, Vkontakte и Twitter.



