
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Всем добрейшего дня! Совсем недавно закончилось ежегодное международное соревнование AI Contest, организатором которого является Сбер вместе с российскими и зарубежными партнёрами в рамках конференции Artificial Intelligence Journey. Задачи этого года: Digital Петр: распознавание рукописей Петра I, NoFloodWithAI: паводки на реке Амур и AI 4 Humanities: ruGPT-3. В этот раз в соревновании участвовало около 1000 человек из 43 государств.
Наша команда приняла участие в решении задачи "Digital Петр: распознавание рукописей Петра I" и заняла первое место. Я бы хотел рассказать о том, что мы наворотили в процессе решения соревнования, кто тут батя, какие трюки и фишки использовали. Информации много, будет много спецэфичных слов, для тех кто не в теме. Это не туториал, очень подробно я описывать не буду, но с удовольствием отвечу на вопросы в комментариях.
Можете посмотреть на команду мечты

План
Описание задачи
Этапы решения
Предобработка данных
Описание нейронной сети
Аугментации
CharMasks
Spell correction using XLMRoberta
Ensemble + Spell Correction Thresholds
Что не сработало
Команда
Заключение
Описание задачи
Формат данных, доступные ресурсы и ограничения

Если без воды, то: Необходимо перевести строку, написанную от руки Петром I, в печатный формат (см. пример ниже). Организаторы совместно с историками подготовили данные, разбив документы построчно, где каждая строка - картинка и ей соответствует текстовый файл с расшифровкой.
Примеры. Текст от руки и печатный аналог


Конечно данные были неидеальны, где-то были опечатки, где-то текст совсем не соответствовал картинке, поэтому дружное коммьюнити все участники сообщали организаторам об опечатках, которые были благополучно исправлены.
Этапы решения
За время проведения соревнования мы протестировали более 500 гипотез, которые включали подбор архитектуры нейронной сети, подбор готовых аугментаций, тестирование своих аугментаций, различные варианты ансамблирования моделей и постобработки.
1. Предобработка данных
Выбросили картинки, на которых очевидно не верна разметка (нашли с помощью OOF), удалили редкие символы. Так как Пётр писал не только горизонтально (как на картинках выше), но и на полях (как на картинке ниже), то в данных присутствовали картинки с вертикальными надписями, которые нужно было перевернуть либо на +90, либо на -90 градусов. Для поворота картинок мы обучили сеть (Resnet34 с изменённой головой) которая предсказывала есть ли необходимость поворачивать картинку и в какую сторону. Это необходимо для того, чтобы поворачивать картинки на скрытых данных.
Пример вертикальной картинки

Также реализовали кастомное разбиение данных со стратификацией по буквам, т.е. с равномерным распределением букв по фолдам. Получилась достаточно хорошая и стабильная корреляция с лидербордом.
2. Описание нейронной сети
Мы рассматривали два варианта архитектур нейронных сетей, одну под CTCLoss и другую на классическом Attention. Отдельно про CTCLoss можно посмотреть тут, а про Attention почитать тут. Начали с CTCLoss, но на нём и остались, так как на подход с Attention не хватило времени. Сразу покажу картинку.
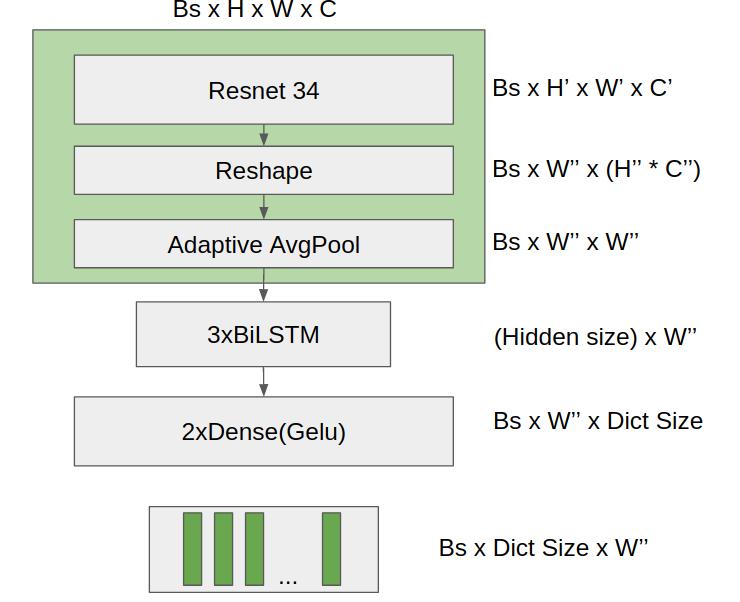
Где Bs - размер батча, (w, h, c) - параметры изображения (ширина, высота, каналы). Штрихи указывают на производные параметры от исходных. Hidden size - размер скрытого слоя в LSTM слое. Dict Size - количество буковок, которые будет знать наша нейронка. Dense - слой полносвязной сети в Keras, аналог Linear в PyTorch.
3. Аугментации
Что такое аугментации, как их применять можно посмотреть тут и тут. Мы использовали стандартные аугментации: ToGray, CLAHE, Rotate, CutOut.
Однако CutOut мы в середине соревнования заменили на другую аугментацию. Мы написали её сами, назвали HandWrittenBlots, суть в том, что это имитация человеческой почеркушки с различным размером, наклоном и прозрачностью. Сделано это для того, чтобы улучшить (кто бы мог подумать) распознавание перечёркнутых букв. CutOut накидывал, HandWrittenBlots накинул еще больше. Аугментацию можно найти в репозитории Augmixations. Пример использования тут.

P.S. Форма вырезанных прямоугольников в CutOut тут такая потому, что параметры были подобраны эмпирически и вертикальные тонкие прямоугольники докидывали больше всего.
4. CharMasks
Это крутая штука, которая возможна, когда используешь CTC Loss. Дело в том, после предсказания моделью последовательности символов, есть возможность разбить входную картинку по этим символам, пропорционально размеру выходной последовательности (руками разбивать картинки конечно тоже можно, но это совсем прохладная история). Для этого нужно использовать координаты стыков различных букв (Именно так делали ребята для Action Labeling тут).

Таким образом мы получаем координаты начала и конца каждого символа. А затем, имея координаты всех символов во всех строках датасета, мы можем сами генерировать любую фразу почерком Петра. Вопрос остаётся в том, что нам пока негде брать древнерусские фразочки. Поэтому мы идём в гугл и нагугливаем книжки с текстами XVII-XVIII веков (Да, их тоже надо почистить и обработать). И уже теперь, с чистой совестью, достаём любую фразу из нашего корпуса текстов и составляем по ней картинку.

Да, она будет не идеальна, и если генерировать изображения, используя однобуквенные символы, то скор это не улучшит. Но тут в дело вступают токенизаторы. Обучаем мы их на предложениях из имеющегося датасета, в котором у нас есть соответствующие картинки. Таким образом для каждого токена мы теперь можем получить картинку. Далее с помощью токенизаторов (Multi Word Expression) мы можем составлять фразы из токенов (состоящих из нескольких символов и пробелов) различной длины и генерировать соответствующую картинку.

Далее еще поработали с цветом бумаги, для того чтобы сделать его более однородным и естественным, т.к. сами понимаете, что цвет бумаги в датасете от картинки к картинке совершенно разный. В результате получилось как-то так:

5. Spell correction using XLMRoberta
Сразу скажу, что в этом пункте много текста.
Естественно, наша супермегапаверфьюженстелскрутая модель не предсказывает идеальные предложения и всё же делает некоторые ошибки (особенно пробелы, ненавижу пробелы). И совершенно случайно в наши ряды затисались эксперты NLP. Ну они и обучили буквенную языковую модель XLMRoberta на корпусе XVII-XVIII в.в., а затем реализовали модель исправления опечаток в стиле Петра I. Делали следующее:
1. из сырого выхода OCR модели (перед тем как схлопнуть повторяющиеся символы и паддинги) склеивали повторяющиеся символы (включая паддинг) и пересчитывали их вероятности (среднее + softmax), брали 3 наиболее вероятные символа (буквы/цифры/blank в т.ч.) для каждой позиции в тексте;
2. каждую локальную позицию проверяли и исправляли так: давали 3-4 варианта модели, а она выбирала наиболее правильный - т.к. символы были буквы/цифры/blank, то таким образом мы боролись как с расстановкой пробелов, так и с другими видами опечаток с учетом контекста. Также с помощью данного подхода легко реализовать zero-shot learning, где предсказываются символы, которых не было в исходном датасете. Так мы накинули варианты похожих с точки зрения OCR латинских и кириллических букв ('р': 'p', 'о': 'o', 'е': 'e', 'с': 'c', 'а': 'a', 'х': 'x', 'и': 'u', 'к': ‘k’);
3. сортировали все локальные позиции по уверенности OCR модели и исправляли по одной step by step (!), что позволило улучшить и главное не испортить следующие предикты на более уверенных позициях;
4. обучали модель так: маскировали буквы (рандомно от 0 до 12), 50% масок превращали в padding (борьба с наличием лишних символов), 10% оставшихся букв заменяли на рандомный символ в тч и. паддинг (для стабилизации предикта). пытались предсказать маскированные буквы на фичах XLMRoberta из outputhiddenstates - почти как NER, но классификация на все заданные символы;
5. на GPU данная модель учится довольно долго, поэтому мы юзали TPU на Colab
P.S.
После завершения соревнования мы узнали (один из участников опубликовал своё решение), что в этой задаче можно было применить BeamSearch. Реализация которого есть тут.
6. Ensemble + Spell Correction Thresholds
Думаю, что многие в соревновании столкнулись с тем, что модели, обученные с помощью CTCLoss, нельзя так просто заблендить. А ансамбль это крутая штука и хотелось бы его использовать. Поэтому немного покурив бамбук подумав, мы пришли к своеобразному ансамблю.Представим что у нас есть N моделей и у всех мы сделали предикт и нам остаётся только "схлопнуть" повторяющиеся буквы для того чтобы получилось чистое предложение. Мы проделываем данную операцию, но не только с символами но и с их вероятностями, усредняя их. Таким образом получаем среднюю вероятность каждого символа. И теперь, итерируясь по всем моделям, бёрем только те предикты, средняя вероятность которых наиболее высокая.Надеюсь, что +- понятно описал.
Что не сработало
Other Backbones. Мы ставили эксперименты с кучей других бекбонов и доп блоками (EfficientNet, [SE, ECA]ResNet[xt], Mobilenet и др), но на удивление лучше всего заходит классический Resnet34.
Augmentations. Перепробовали практически весь набор аугментаций из всеми нами любимого Albumentations (Brightness, Gamma, Blur и др), остались только те, что я указал выше.
TTA (Test-Time Augmentations). Интересно то, что на нашей holdout выборке ТТА давал прирост, а на public test - нет. Мы решили верить паблик тесту, так как там выборка заметно больше нашей на holdout.
Classic Blending. Как было сказано выше, по причине того, что каждая модель может выдавать текста, длины которых будут отличаться, и на самом деле еще по ряду причин, связанных с рекуррентностью выходного текста.
Команда
Все четверо из команды работаем в компании ОЦРВ в лаборатории искусственного интеллекта и нейронных сетей в городе Сириус (Сочи). Спасибо ребятам, что продержались до конца и показали отличный результат! :)
Информация каждом члене команды
Карачёв Денис (github, linkedin, kaggle)
Шоненков Алексей (github, linkedin, kaggle)
Смолин Илья (github, linkedin, kaggle)
Новопольцев Максим (linkedin, kaggle)
Заключение
Подытоживая, хотелось бы поблагодарить организаторов за столь интересное мероприятие, в ходе которого было приобретено большое количество знаний и опыта в области распознавания текста по картинке и не только. Мы работали в выходные и все свободные вечера, потому что задача нам показалась действительно интересной.
P.S.Наше самое быстрое решение (одна модель, public):
| CER: 2.531 | WER: 13.5 | ACC: 62.107 | TIME: 32s |
Код submission и веса опубликованы здесь.
P.P.S. Бонус
Особо пытливым предлагаю разгадать ребус, что же здесь написано? :)

")
")
")
