
Привет, Хабр. Меня зовут Дмитрий Гусаков. Я тимлид команды QA в компании Arenadata. Наша команда занимается тестированием компонентов Arenadata Enterprise Data Platform, в том числе тестированием оркестратора гибридного data-ландшафта Arenadata Cluster Manager. Каждый день мы пишем и актуализируем большое количество тестов для API. Поэтому сегодня я хочу обсудить тему автоматической генерации таких тестов и поделиться с сообществом нашими решениями и опытом.
Для начала давайте подумаем, что приходит вам в голову, когда вы слышите слово «автотесты».

Согласно терминологии ISTQB:
«автоматизация тестирования (test automation): использование программного обеспечения для осуществления или помощи в проведении определённых тестовых процессов, например, управление тестированием, проектирование тестов, выполнение тестов и проверка результатов».
Лично для меня автотесты — это классный способ избавиться от ручного регресса и не делать одно и то же по сто раз. Но у всего есть своя цена, даже у классных способов. Для автотестов это их разработка и поддержка. Как минимизировать время разработки и не писать тысячу раз похожие тесты для соседних endpoints в API? И как сделать этот процесс удобным для использования в будущем? Давайте разбираться!
Базовые требования к тестам
Допустим, перед нами новый проект. Нужно написать автотесты для REST API. Условия, в которых придётся работать, следующие:
в первую очередь тестируем базовые свойства REST API, а именно:
допустимость методов для конкретного endpoint;
корректность принимаемых и возвращаемых типов и структур данных;
корректность работы сортировки и фильтрации;
бизнес-логика работы приложения вынесена за рамки REST API и не оказывает значительного влияния на тестирование его базовых свойств;
тесты нужны ASAP;
спецификация методов может и будет меняться;
тесты должны соответствовать концепции Black Box;
количество QA Engineers ограничено.
Теперь надо решить, какими мы хотим видеть автотесты на новом проекте.
Что действительно важно для автотестов?
Мы с командой выделили для себя 3 наиболее важных аспекта хороших автоматизированных тестов.

Автоматизация подготовки тестовых данных
Данный аспект особенно важен в ситуации частых изменений в приложении.
Автоматизация подготовки данных помогает сделать тесты автономными. Не нужно заботиться о том, в каком состоянии находятся данные на тестовом стенде или в тестируемом приложении.
Из минусов: такой подход может потребовать дополнительных усилий со стороны разработки, например для создания инструментов получения этих тестовых данных и для поддержки таких инструментов.
Минимизация дублирований кода автотестов и логики проверок
По мере роста приложения вопрос дублирования в тестовом фреймворке может стать большой проблемой. Актуализация тестов с большим количеством дублирования, скорее всего, будет отнимать значительное время.
Прозрачность как самих проверок, так и их результатов
Пока тесты зелёные, вопрос детальности описания шагов в отчёте и результатов тестов почти никого не волнует, но как только тесты перестают проходить успешно, мы моментально оказываемся в ситуации, когда подробный отчёт критически необходим для разбора проблемы.
В идеальной ситуации из отчёта по тестам мы должны иметь возможность однозначно определить источник проблемы и получить все необходимые для её воспроизведения данные.
Классические подходы
Обратимся для начала к нашему прошлому опыту или к мнению опытных коллег. Что у нас там есть?
Хардкод или предзаполнение БД
Как правило, в автотестах данные для проверок хранятся в статичном виде в теле теста или в виде констант:
def test_cluster_post_positive(api_client):
body = {"name": "test_cluster"}
expected_code = 200
...А для заполнения приложения данными может использоваться предзаполнение БД или иной скрипт создания данных и объектов в приложении перед началом тестов.
INSERT INTO CLUSTERS ...Проблема такого подхода заключается в том, что при любом изменении схемы данных нам с вами придётся шерстить код тестов в поисках затронутых данных и обновлять их.
Такие манипуляции, безусловно, будут отнимать значительное время на поддержку тестов.
Дамп базы данных с «прода»
Альтернативой ручному созданию скриптов заполнения БД может выступать использование обезличенных данных с production-среды.

Такой подход позволяет работать с реальными данными. Однако он не гарантирует наличия всех данных, необходимых для тестов, и сильно завязан на наличие production-среды, которая может использоваться в качестве источника таких данных.
Стоит отметить, что такой подход далеко не всегда возможен. Препятствием могут стать как политики работы с персональными данными, так и невозможность получения доступа к «проду» или его отсутствие (для клиентских приложений).
Про данные понятно. Что насчёт кодовой базы?
Создание отдельных тестов для каждого endpoint

Одним из наиболее часто применяемых подходов к написанию автотестов для API является создание отдельных тестов для каждого endpoint.
Данный подход удобен с точки зрения учёта индивидуальных особенностей конкретного endpoint, но неизбежно влечёт за собой дублирование кода и логики проверок. Также при большом количестве таких наборов на выходе получается весьма тяжёлый фреймворк.
И вот мы с вами плавно приходим к мысли о том, что рассмотренные выше варианты не так уж и хороши, особенно в разрезе озвученных в самом начале тезисов о хороших автотестах. Давайте думать дальше.
Генерация тестов по SWAGGER-описанию
Во многих проектах можно встретить использование такого инструмента, как SWAGGER, для описания REST API.

Если коротко, то SWAGGER и подобные ему решения нацелены на автоматическую генерацию документации к API на основе кода приложения. При правильном использовании разработчику не приходится задумываться о ведении отдельной документации к API, что и делает такие системы крайне популярными.
Кажется, что решение становится очевидным: генерируем тесты и данные для них по SWAGGER-описанию! Если SWAGGER так популярен, то для него должен быть готовый инструмент.
Однако после часов гугления и поисков выясняется ряд обстоятельств.
Первое — инструментов для генерации тестов по SWAGGER-описанию великое множество. Вот несколько наиболее ярких примеров:
meqaio/swagger_meqa
noahdietz/oatts
earldouglas/swagger-test
Второе — далеко не все из них генерируют именно код автотестов. Некоторые используют свой собственный формат, при котором генерация и выполнение тестов происходят в рамках одного инструмента. Некоторые генерируют скрипты для последующего выполнения. Ряд фреймворков предназначен для автогенерации юнит-тестов для конкретного языка и фреймворка разработки.
Ну и третье, но, пожалуй, самое важное: ни один из таких инструментов не решает вопрос подготовки тестовых данных…
Именно 3-й пункт является основным препятствием для использования готовых инструментов.
А значит, разумно будет создать своё кастомное решение. Именно о таком решении, разработанном в стенах компании Arenadata, я бы и хотел сегодня вам рассказать.
Автоматизируем по максимуму!
Но перед тем как приступить к рассказу о нашем решении для автоматического создания тестов, вспомним основные требования к автотестам, которые мы сформулировали ранее:
автоматическая генерация тестовых данных;
минимальное количество дублирования кода и логики в самих тестах;
детальный и понятный отчёт с результатами тестов.
Автоматическая генерация тестовых данных
Даже если мы располагаем слепком данных с прода, это не даёт нам гарантии наличия в приложении всех необходимых для конкретного теста данных.
Инструментов для решения данной проблемы может быть много. Некоторые из них мы уже описали ранее в обзоре классических подходов.
Посовещавшись с командой, мы выбрали подход, при котором данные для каждого теста генерируются индивидуально. Для задач тестирования базового поведения API этот подход нам показался оптимальным.

В зависимости от того, какой endpoint предстоит проверить в том или ином тест-кейсе, фреймворк определяет, какие именно объекты нужно создать перед началом теста, какие данные необходимо отправить в запросе и какой ответ ожидать.
Но откуда алгоритм узнает, какие именно данные нужны тесту и, более того, как их создать?
Модели данных
Ответ на этот вопрос, как ни странно, лежит в попытке минимизации дублирования кода и логики. Давайте представим себе типичный набор тестов API. Они все будут очень похожи. Разница будет именно в данных. А значит, при классическом подходе мы будем множество раз описывать похожие методы подготовки данных для разных методов.
Чтобы этого не происходило, алгоритм подготовки данных должен быть универсальным и абстрактным.
В нашем случае мы создали описания моделей данных и их зависимостей для каждого endpoint.
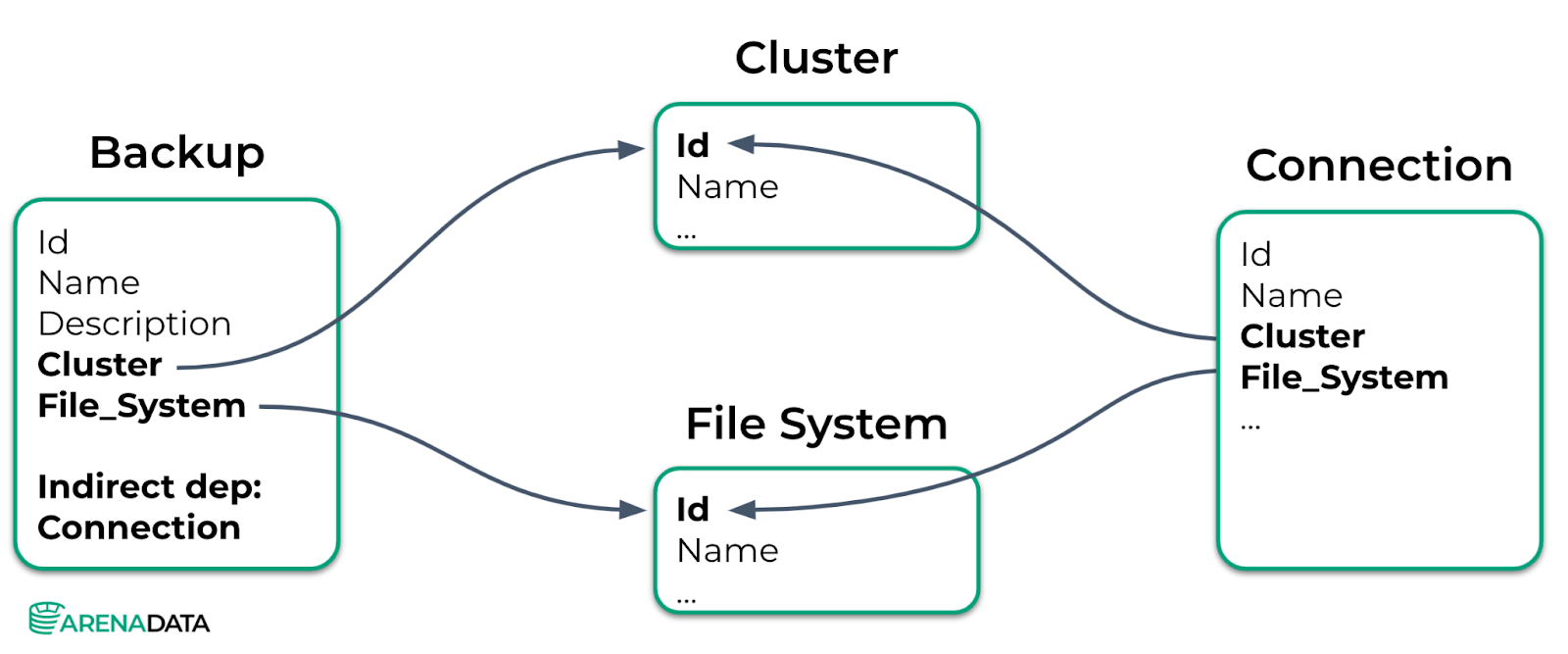
Например, для создания данных для endpoint Backup нам необходимо, чтобы в приложении уже были созданы данные для endpoints Cluster и File System — это пример явной или прямой зависимости. Также для выбранных кластера и файловой системы должен существовать Connection — и это так называемая неявная зависимость.

Рассмотрим на данном примере алгоритм генерации данных.
Итак, мы с вами хотим создать данные для endpoint Backup.
В его модели описана неявная зависимость от endpoint Connection.
Значит, перед созданием данных для endpoint Backup алгоритм должен будет создать данные для endpoint Connection. Для их создания выполняется рекурсивный вызов метода генерации данных для endpoint Connection.
У connection нет неявных зависимостей, но есть явные. Значит, далее следуют рекурсивные вызовы методов генерации данных для endpoint Cluster и File System.
У endpoint Cluster и File System нет зависимостей, значит, они могут быть созданы без дальнейших действий. Создаём их.
Далее происходит сворачивание цепочки рекурсивных вызовов, и на выходе мы имеем возможность создать данные для endpoint Backup, потому что все его зависимости были созданы.
Отдельно стоит отметить, что наличие явных и неявных рекурсивных зависимостей, которые могли бы привести к зацикливанию работы алгоритма, недопустимо и считается ошибкой приложения.
Вот так вкратце и работает автоматическое создание тестовых данных.
Помимо связей и типов данных в модели Endpoint описываются всевозможные характеристики полей, например:
является ли поле обязательным,
можно ли после создания объекта изменить значение этого поля и т. д.
Также важно не забыть про Url данного endpoint и про список допустимых для него методов.
Модели тест кейсов
Описанные модели позволяют решить вопрос генерации данных, но не решают вопроса генерации самих тестов. Для решения этого вопроса нам нужны обобщённые описания тест-кейсов, построенные по следующей логике.
Указывается метод, для которого будет применим данный кейс. Далее ставится опциональная пометка о типе теста (позитивный или негативный). В теле теста описывается действие или последовательность действий. И в завершение перечисляются правила формирования данных для проверок.

Представленный на картинке пример описания тест-кейса может быть применён для любого endpoint, для которого допустим метод POST.
Итоговый алгоритм
В итоге алгоритм тестового фреймворка по очереди выбирает endpoint, определяет по его модели, какие методы для него разрешены, и на выходе получает полный набор тестов для этого endpoint.
Таким образом, единожды описав все необходимые тест-кейсы и модели данных для всех endpoint, мы получаем полноценный набор автотестов.

Если у вас есть желание подробнее погрузиться в тонкости работы описанных сегодня алгоритмов, то добро пожаловать в наш семпл-проект на github, в котором мы с командой разместили для вас пример реализации автотестов в описанной парадигме.
Также вы найдёте там пулл-реквест с описанием изменений в приложении и соответствующими изменениями в тестах. Главной целью этого пулл-реквеста является наглядная иллюстрация объёма изменений в тестах при изменениях в приложении.
Детальный отчет
В качестве отчёта мы с командой использовали Allure Report в связке с продуктом Allure TestOps, позволяющим нам хранить все отчёты в одном месте.
Основной упор был сделан на отображение всех шагов подготовки данных, выполнения теста и сбор логов для упавших тестов.
Достичь такого результата получилось достаточно просто путём упаковки всех основных операций в allure.step и использования allure.attach для прикрепления дополнительной информации, в том числе логов.
Пример отчёта также есть в нашем демонстрационном проекте.

Сложности и подводные камни
Как и в любом деле, мы не смогли избежать сложностей и неожиданностей при написании автотестов.
Первое, с чем пришлось столкнуться, — это неявные зависимости между сущностями и объектами в приложении. В примере, рассмотренном ранее, мы уже говорили об этом аспекте. Помните, что для создания бекапа нам нужно было сначала создать connection между кластером и файловой системой? Это, наверное, самый простой пример неявной зависимости, с которой пришлось работать.

Решение в данном случае — это модификация моделей и алгоритма создания данных.
Вторым значительным препятствием стала валидация создаваемых данных на стороне приложения.
Если с числами, строками и внешними ключами всё достаточно очевидно, то, когда дело доходит до полей, значения которых проверяются по референсам из других полей других объектов, всё становится интереснее.

Конкретно в нашем случае мы столкнулись с генерацией конфигураций в формате Json для одного объекта (Connection) по JsonSchema из другого объекта (Connection Type).
Как и в прошлом кейсе, решение состояло в модификации моделей и алгоритма генерации значений для полей типа Json.
Последней трудностью, на которой стоит заострить внимание, является оценка степени покрытия отдельных endpoint тестами.

Основной проблемой здесь являются возможные дефекты самого тестового фреймворка. Возможно, модель описана неточно, или в описании тест-кейса допущена ошибка, которая проявляется только для некоторых endpoint.
Тут ничего не остаётся, кроме ручного анализа результатов прогона после внесения изменений в алгоритм или добавления новых моделей. Но даже при учёте трудозатрат на единоразовую ручную проверку подобных ситуаций общая эффективность подхода и экономия времени остаются значительными по сравнению с классическими подходами, описанными во вводной части.
Границы применимости
На данный момент подход отлично зарекомендовал себя как способ организации детального покрытия автотестами API-методов с простой бизнес-логикой. Есть планы по расширению области его применения на методы с более сложной бизнес-логикой и CRUD-сценарии.
Возможности применения такого подхода для UI-тестов маловероятны, однако попробовать можно. Особенно если UI содержит в себе похожие структуры (однотипные формы, оборачивающие API-методы, страницы с отображением данных из БД или логов)
Также неизученным, но перспективным кажется применение описанного подхода при тестировании схем и структур данных непосредственно в БД. Например, при проектировании сложной системы со связями, процедурами преобразования данных и триггерами.
Чуть менее глобальным, но от того не менее важным является применение описанных алгоритмов для тестирования на безопасность. В таком случае разработчик автотестов делает акцент на генерации невалидных данных с целью «сломать» логику работы сервиса именно в контексте безопасности.
Итоги
Применение описанного подхода при разработке тестов API позволяет:
в разы снизить затраты на обновление тестов и тестовых данных в случае частых изменений в требованиях;
справиться с разработкой автотестов силами 1 QA Automation engineer для команды разработки из 3–5 backend-разработчиков;
ограничить затраты на правку/доработку автотестов при добавлении или изменении endpoint не более чем 20 % от времени на разработку такого изменения.
Надеюсь, что представленные в статье материалы и идеи помогут вам в оптимизации ваших автотестов и в упрощении процесса их поддержки!
Хочу выразить огромную благодарность всей команде Arenadata QA за помощь в подготовке данной статьи!

