
В последнее время производители FPGA и сторонние компании активно развивают методы разработки для FPGA, отличающиеся от привычных подходов использованием высокоуровневых средств разработки.
Являясь FPGA-разработчиком, в качестве основного инструмента я использую язык описания аппаратуры (HDL) Verilog, но растущая популярность новых методов вызвала у меня большой интерес, поэтому в данной статье я решил сам разобрать что к чему.
Эта статья — не руководство или инструкция к пользованию, это мой обзор и выводы о том, что могут дать различные высокоуровневые средства разработки FPGA-разработчику или программисту, который хочет окунуться в мир FPGA. Для того, чтобы сравнить самые интересные на мой взгляд средства разработки, я написал несколько тестов и проанализировал полученные результаты. Под катом — что из этого вышло.
Сейчас многих манит идея высокоуровневой разработки. Этим заняты как энтузиасты, такие как, например, Quokka и кодогенератор на Python, так и корпорации, такие как Mathworks, и производители FPGA Intel и Xilinx
Каждый для достижения цели использует свои методы и инструменты. Энтузиасты в борьбе за идеальный и прекрасный мир используют свои любимые языки разработки, такие как Python или C#. Корпорации, пытаясь угодить клиенту, предлагают свои или адаптируют существующие инструменты. Mathworks предлагают свой инструмент HDL coder для генерации HDL кода из m-скриптов и моделей Simulink, а Intel и Xilinx — компиляторы для распространенного C/C++.
На данный момент большего успеха достигли обладающие значительными финансовыми и человеческими ресурсами компании, в то время как энтузиасты несколько отстают. Данную статью я посвящу рассмотрению продукта HDL coder от Mathworks и HLS Compiler от Intel.
Начнем сравнения HDL coder от Mathworks и HLS Compiler от Intel, решив несколько задач с использованием разных подходов.
Решение данной задачи не имеет практической ценности, но хорошо подходит в качестве первого теста. Функция принимает 4 параметра, перемножает первый со вторым, третий с четвертым и складывает результаты умножения. Ничего сложного, но посмотрим, как с этим справятся наши испытуемые.
Для решения такой задачи m-скрипт выглядит следующим образом:
Посмотрим, что предлагает нам Mathworks для конвертации кода в HDL.
Я не буду подробно рассматривать работу с HDL-coder, остановлюсь только на тех настройках, которые в дальнейшем буду изменять для получения разных результатов в FPGA, и над изменениями которых придется подумать MATLAB-программисту, которому требуется запустить свой код в FPGA.
Итак, первое, что необходимо сделать, это задать тип и диапазон входных значений. В FPGA нет привычных char, int, float, double. Разрядность числа может быть любой, логично выбирать ее, исходя из диапазона входных значений, который планируется использовать.
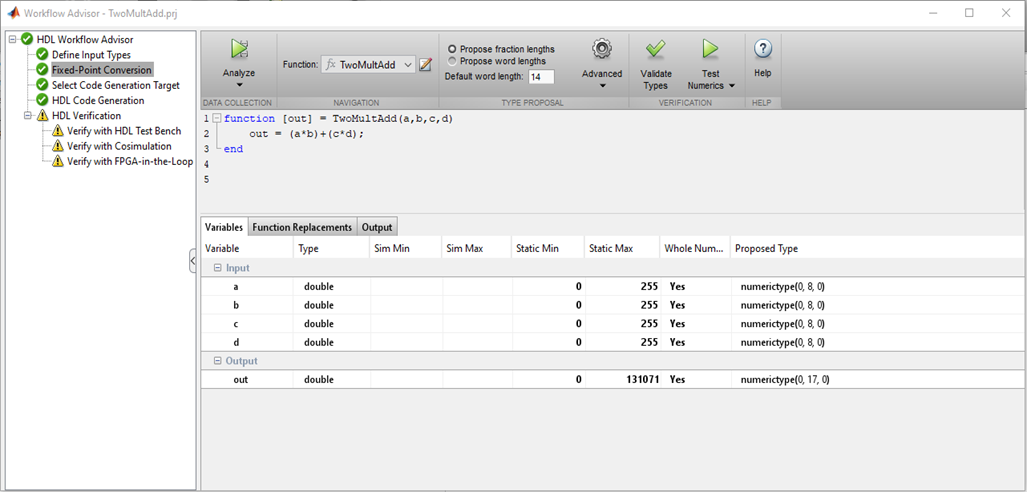
Рисунок 1.
MATLAB проводит проверку типов переменных, их значений и сам подбирает правильные разрядности для шин и регистров, — это действительно удобно. Если проблем с разрядностью и типизацией нет, можно переходить к следующим пунктам.
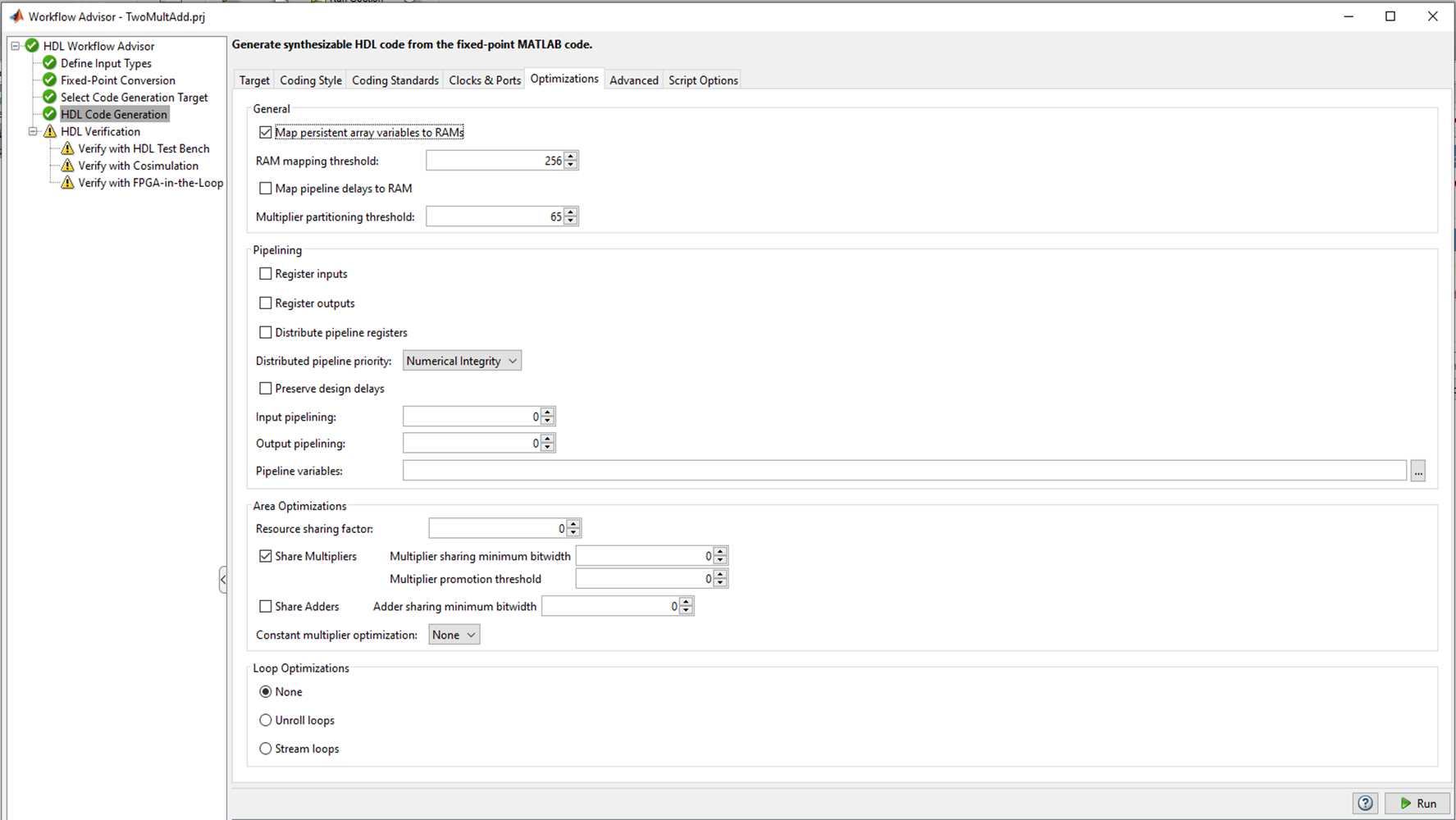
Рисунок 2.
В HDL Code Generation есть несколько вкладок, где можно выбрать язык, в который произойдет конвертация (Verilog или VHDL); стиль кода; названия сигналов. Самая интересная вкладка, на мой взгляд, — это Optimization, — с ней я и буду проводить эксперименты, но позже, а пока оставим все значения по умолчанию и посмотрим, что получится у HDL coder “из коробки”.
Нажимаем кнопку Run и получаем следующий код:
Выглядит код неплохо. MATLAB понимает, что запись всего выражения в одну строку на Verilog — плохая практика. Создает отдельные wire для умножителя и сумматора, придраться особо не к чему. Настораживает, что отсутствует описание регистров. Так получилось потому, что мы и не просили об этом HDL-coder, а все поля в настройках оставили в значениях по умолчанию.
Вот что из такого кода синтезирует Quartus.

Рисунок 3.
Никаких проблем, все как и было задумано.
В FPGA мы реализуем синхронные схемы, и все-таки хотелось бы видеть регистры. HDL-coder предлагает механизм для размещения регистров, но где их разместить — решать разработчику. Мы можем разместить регистры на входе умножителей, на выходе умножителей перед сумматором или на выходе сумматора.
Для синтезирования примеров я выбрал семейство FPGA Cyclone V, где для реализации арифметических действий используются специальные DSP блоки со встроенными сумматорами и умножителями. Выглядит DSP блок следующим образом:
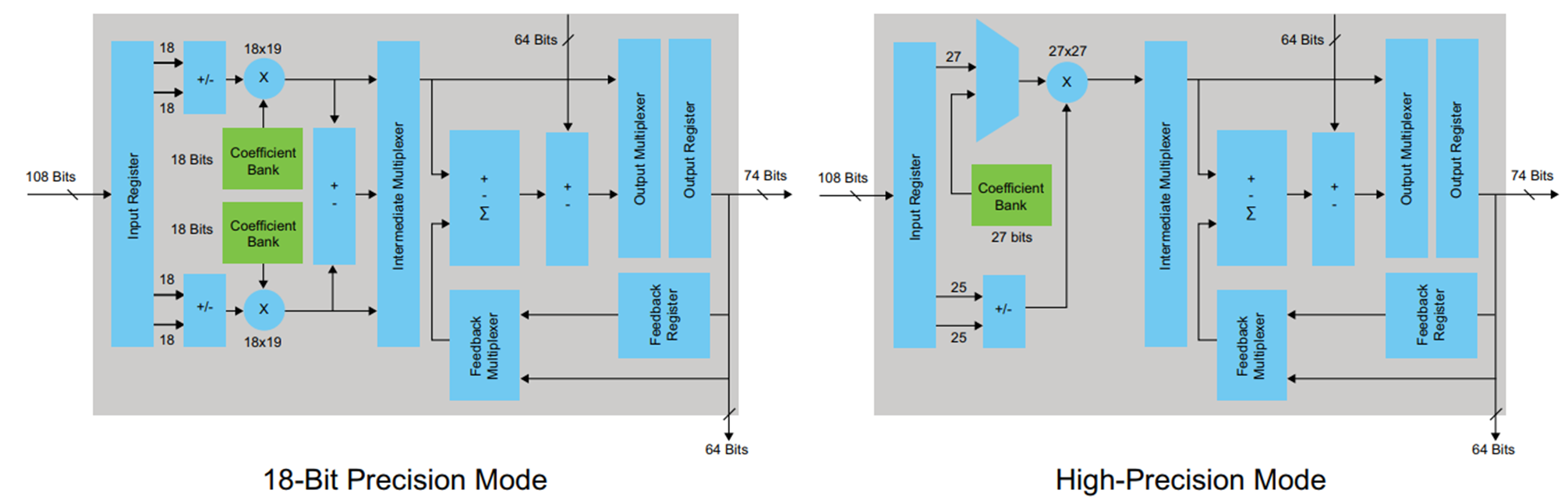
Рисунок 4.
DSP блок имеет входные и выходные регистры. Нет необходимости пытаться защелкнуть результаты умножения в регистре до сложения, это только нарушит архитектуру (в определенных случаях такой вариант возможен и даже нужен). Как поступать с входным и выходным регистром решать разработчику, исходя из требований к задержке (latency) и необходимой максимальной частоте. Я принял решение использовать только выходной регистр. Для того, чтобы этот регистр был описан в коде, генерируемом HDL-coder’ом, во вкладке Options в HDL coder необходимо поставить галочку напротив Register output и повторно запустить конвертацию.
Получается следующий код:
Как видно, в коде есть принципиальные отличия по сравнению с предыдущим вариантом. Появился always-блок, который и является описанием регистра (как раз то, что мы хотели). Для работы always-блока появились также входы модуля clk (тактовая частота) и reset (сброс). Видно, что выход сумматора защелкивается в триггере, описанном в always. Также есть пара сигналов разрешения ena, но они нам не очень интересны.
Посмотрим на схему, которую теперь синтезирует Quartus.

Рисунок 5.
И снова результаты хорошие и ожидаемые.
На рисунке ниже представлена таблица использованных ресурсов — держим ее в уме.

Рисунок 6.
За это первое задание Mathworks получает зачет. Все не сложно, предсказуемо и с желаемым результатом.
Я довольно подробно описал простой пример, привел схему DSP-блока и описал возможности применения настройки использования регистров в HDL-coder, отличных от настроек “по умолчанию”. Это сделано не просто так. Этим я хотел подчеркнуть, что даже в таком простом примере при использования HDL-coder знания архитектуры FPGA и основ цифровой схемотехники необходимы, а настройки необходимо изменять осознанно.
Давайте попробуем собрать код с той же функциональностью, написанный на С++, и посмотрим, что в итоге синтезируется в FPGA с помощью HLS compiler.
Итак, код на С++
Типы данных я выбрал так, чтобы избежать переполнения переменных.
Есть продвинутые методы задания разрядностей, но наша цель — проверить возможность собрать под FPGA написанные в стиле С/С++ функции без внесения изменений, все из коробки.
Так как HLS compiler — родной инструмент Intel, собираем код специальным компилятором и проверяем результат сразу в Quartus.
Посмотрим на схему, которую синтезирует Quartus.

Рисунок 7.
Компилятор создал регистры на входе и выходе, но самая суть скрыта в модуле обертке. Начинаем разворачивать обертку и… видим еще, еще и еще вложенные модули.
Структура проекта выглядит так.

Рисунок 8.
Очевиден намек от Intel: “руками не лезть!”. Но мы попробуем, тем более функционал не сложный.
В недрах дерева проекта |quartus_compile|TwoMultAdd:TwoMultAdd_inst|TwoMultAdd_internal:twomultadd_internal_inst|TwoMultAdd_fu
nction_wrapper:TwoMultAdd_internal|TwoMultAdd_function:theTwoMultAdd_function|bb_TwoMultAdd_B1_start:
thebb_TwoMultAdd_B1_start|bb_TwoMultAdd_B1_start_stall_region:thebb_TwoMultAdd_B1_start_stall_region|i
_sfc_c1_wt_entry_twomultadd_c1_enter_twomultadd:thei_sfc_c1_wt_entry_twomultadd_c1_enter_twomultad
d_aunroll_x|i_sfc_logic_c1_wt_entry_twomultadd_c1_enter_twomultadd13:thei_sfc_logic_c1_wt_entry_twom
ultadd_c1_enter_twomultadd13_aunroll_x|Mult1 находится искомый модуль.
Можем посмотреть на схему искомого модуля, синтезированную Quartus’ом.
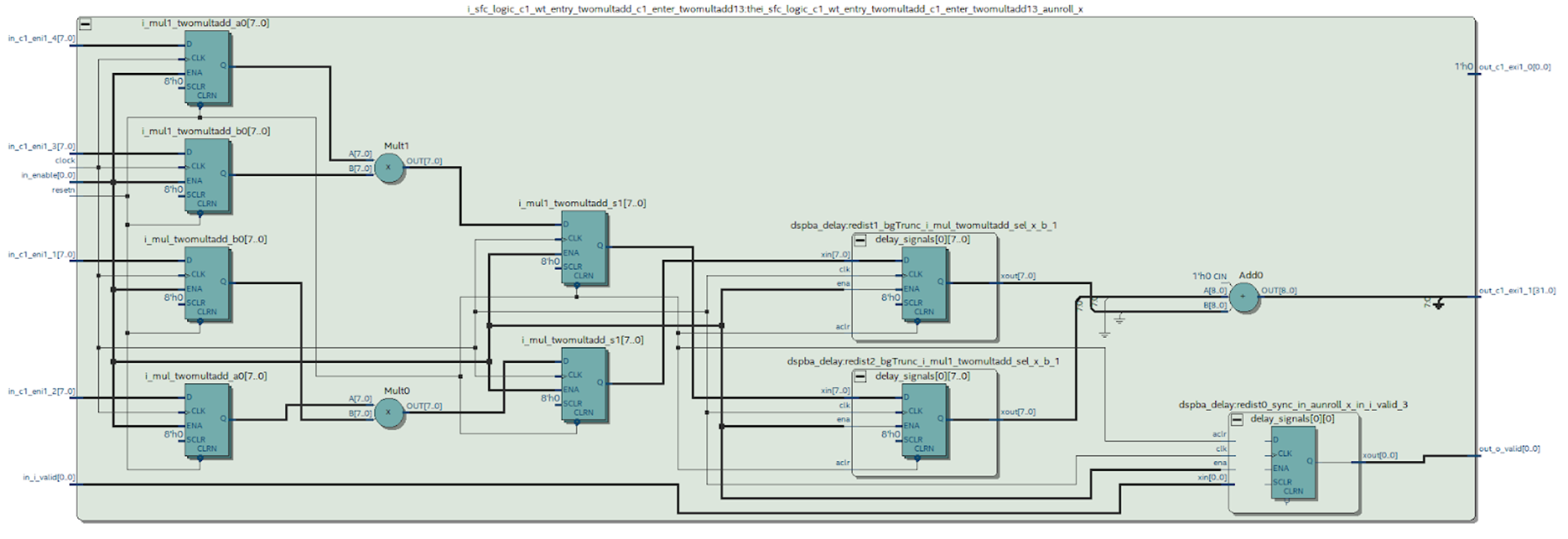
Рисунок 9.
Какие выводы можно сделать из этой схемы.
Видно, что произошло то, чего мы пытались избежать при работе в MATLAB: синтезирован регистр на выходе умножителя — это не очень хорошо. Из схемы DSP блока (Рисунок 4) видно, что есть только один регистр на его выходе, а значит каждое умножение придется производить в отдельном блоке.
В таблице использованных ресурсов показано, к чему это приводит.

Рисунок 10.
Сравним результаты с таблицей HDL coder (Рисунок 6).
Если с использованием большего числа регистров можно мириться, то расходовать драгоценные DSP блоки на таком простом функционале очень неприятно.
Но есть огромный плюс в Intel HLS по сравнению с HDL coder. При настройках “по умолчанию” HLS compiler развел в FPGA синхронный дизайн, хоть и израсходовал больше ресурсов. Такая архитектура возможна, видно, что Intel HLS настроен на достижение максимальной производительности, а не на экономию ресурсов.
Посмотрим как наши испытуемые поведут себя с более сложными проектами.
Данная функция широко используется в обработке изображений: так называемый, “матричный фильтр”. Реализуем его с использованием высокоуровневых средств.
Работа сразу начинается с ограничения. HDL Сoder не может принимать на вход функций 2-D матрицы. С учетом того, что MATLAB — это инструмент работы именно с матрицами, — то это серьезный удар по всему наследованному коду, что может стать серьезной проблемой. Если код пишется с нуля, это неприятная особенность, которую надо учитывать. Так что приходится разворачивать все матрицы в вектор и реализовывать функции с учетом векторов на входе.
Код для функции в MATLAB выглядит следующим образом
Сгенерированный HDL код получился очень раздутым и содержит сотни строк, поэтому приводить его здесь я не буду. Сразу посмотрим какую схему синтезирует Quartus из этого кода.

Рисунок 11.
Выглядит данная схема неудачно. Формально она рабочая, но я предполагаю, что работать она будет на очень низкой частоте, и вряд ли ее можно использовать в реальном железе. Но любое предположение должно быть проверено. Для этого разместим регистры на входе и выходе данной схемы и при помощи Timing Analyzer оценим реальное положение дел. Для проведения анализа необходимо указать желаемую рабочую частоту схемы, чтобы Quartus знал, к чему стремиться при разводке, и в случае неудачи предоставил отчеты о нарушениях.
Задаем частоту 100МГц, посмотрим, что у Quartus получится выжать из предложенной схемы.

Рисунок 12.
Видно, что получилось немногое: 33 МГц выглядят несерьезно. Задержка в цепочке из умножителей и сумматоров около 30 нс. Чтобы избавиться от этого “бутылочного горлышка”, необходимо использовать конвейер: вставляем регистры после арифметических операций, уменьшая тем самым критический путь.
HDL coder дает нам такую возможность. Во вкладке Options можно задать Pipeline variables. Так как рассматриваемый код написан в MATLAB стиле, нет возможности конвейеризировать переменные (кроме переменных mult и summ), что нас не устраивает. Необходимо вставить регистры в промежуточные цепи, скрытые в нашем HDL коде.
Причем ситуация с оптимизацией могла быть и хуже. Например, ничего не мешает нам написать код
он вполне адекватен для MATLAB, но полностью лишает нас возможности оптимизации HDL.
Выход следующий — править код руками. Это очень важный момент, так как мы отказываемся от наследования и начинаем переписывать m-скрипт, причем НЕ в MATLAB стиле.
Новый код выглядит следующим образом
В Quartus собираем сгенерированный HDL Coder’ом код. Видно, что количество слоев с примитивами (комбинаторной логикой) уменьшилось, и схема выглядит гораздо лучше.
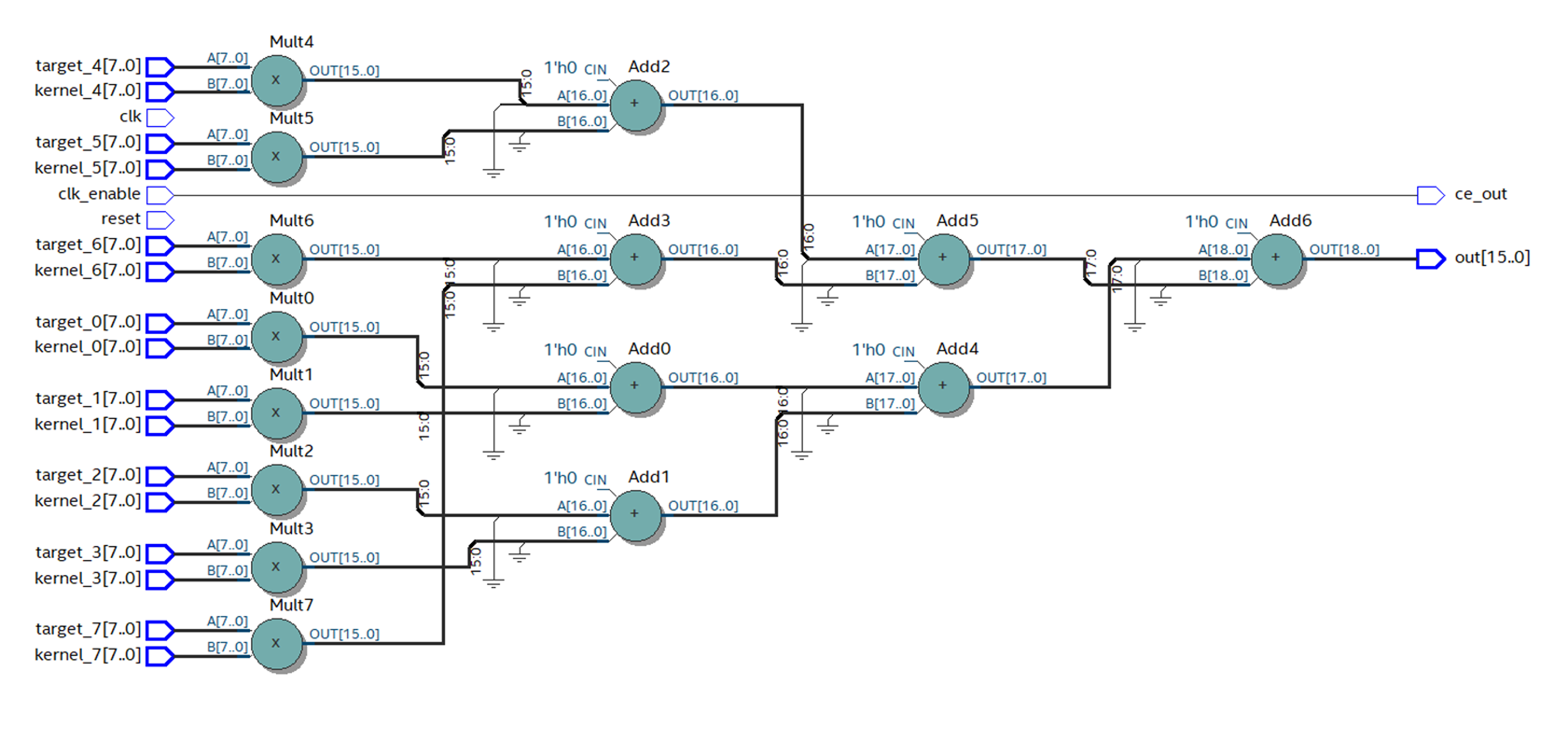
Рисунок 12.
При правильной компоновке примитивов частота вырастает почти в 3 раза, до 88 МГц.

Рисунок 13.
Теперь последний штрих: в настройках Optimization указываем summ_1, summ_2 и summ_3 как элементы конвейера. Собираем получившийся код в Quartus. Схема меняется следующим образом:

Рисунок 14.
Максимальная частота снова увеличивается и теперь ее значение около 195 МГц.

Рисунок 15.
Столько же ресурсов на кристалле займет такой дизайн? На рисунке 16 показана таблица использованных ресурсов для описанного случая.
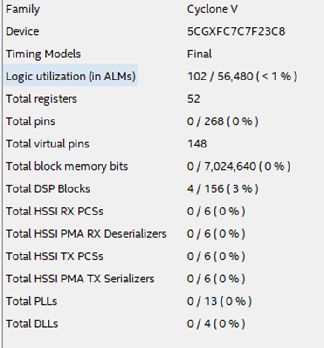
Рисунок 16.
Какие выводы можно сделать после рассмотрения этого примера?
Главный недостаток HDL coder — использовать MATLAB код в чистом виде вряд ли получится.
Отсутствует поддержка матриц как входов функции, разводка кода в MATLAB стиле посредственная.
Главная опасность в отсутствии регистров в сгенерированном без дополнительных настроек коде. Без этих регистров, даже получив формально работающий HDL код без синтаксических ошибок, использование такого кода в современных реалиях и разработках нежелательно.
Желательно сразу писать код, заточенный под конвертацию в HDL. В таком случае можно получать вполне приемлемые по скорости и ресурсоемкости результаты.
Если вы MATLAB разработчик, не спешите нажимать кнопку Run и собирать ваш код под FPGA, помните, что ваш код будет синтезирован в реальную схему. =)
Для того-же функционала я написал следующий код на С/С++
Первое, что бросается в глаза, это количество использованных ресурсов.

Рисунок 17.
Из таблицы видно, что использован всего 1 DSP блок, значит что-то пошло не так, и умножения не выполняются параллельно. Также удивляет количество использованных регистров, и задействована даже память, но это оставим на совести HLS compiler.
Хочется отметить, что HLS compiler развел неоптимальную, использующую огромное количество лишних ресурсов, но все же рабочую схему, которая, по отчетам Quartus, заработает на приемлемой частоте, и такого провала как у HDL coder не будет.

Рисунок 18.
Попробуем улучшить ситуацию. Что для этого нужно? Правильно, закрыть глаза на наследование и залезть в код, но пока что совсем немного.
HLS есть специальные директивы для оптимизации кода под FPGA. Вставляем директиву unroll, которая должна развернуть наш цикл в параллель:
Посмотрим как на это отреагировал Quartus

Рисунок 19.
Первым делом обращаем внимание на количество DSP блоков — их 16, а значит умножения выполняются параллельно.
Ура! unroll работает! Но с тем, как сильно выросла утилизация других ресурсов, уже тяжело мириться. Схема стала абсолютно нечитаемой.

Рисунок 20.
Я полагаю, это произошло из-за того, что никто не указал компилятору на то, что нам вполне подходят вычисления в числах с фиксированной точкой, и он честно на логике и регистрах реализовал всю математику с плавающей точкой. Нужно объяснить компилятору что от него требуется, и для этого мы снова погружаемся в код.
Для целей использования fixed-point реализованы шаблонные классы.

Рисунок 21.
Если говорить своими словами, мы можем использовать переменные, разрядность которых задаем вручную с точностью до бита. Для тех, кто пишет на HDL, к этому не привыкать, но программисты С/С++, наверное, схватятся за голову. Разрядности, как в MATLAB, в данном случае никто не подскажет, и считать количество бит должен сам разработчик.
Посмотрим как это выглядит на практике.
Редактируем код следующим образом:
И вместо жутких макарон из рисунка 20 получаем вот такую красоту:

Рисунок 22.
К сожалению, нечто странное продолжает происходить с использованными ресурсами.

Рисунок 23.
Но при подробном рассмотрении отчетов видно, что непосредственно интересующий нас модуль выглядит более чем адекватно:

Рисунок 24.
Огромное потребление регистров и блочной памяти связано с большим количеством периферийных модулей. Глубокий смысл их существования мне пока до конца не понятен, и с этим нужно будет разобраться, но проблема решаема. В крайнем случае можно аккуратно вырезать из общей структуры проекта один интересующий нас модуль, что избавит нас от периферийных модулей, пожирающих ресурсы.
Начиная писать эту статью, я не ожидал, что она окажется такой объемной. Но я не могу отказаться от третьего, и последнего в рамках данной статьи, примера.
Во-первых, это реальный пример из моей практики, и именно из-за него я начал смотреть в сторону высокоуровневых средств разработки.
Во-вторых, из первых двух примеров мы могли бы сделать предположение, что чем сложнее дизайн, тем хуже высокоуровневые средства справляются с задачей.
Я же хочу продемонстрировать, что это суждение ошибочно, и на самом деле чем сложнее задача, тем больше проявляются достоинства высокоуровневых средств разработки.
В прошлом году в работе над одним из проектов меня не устраивала приобретенная на Aliexpress камера, а именно — цвета были недостаточно насыщенными. Один из популярных способов варьировать насыщенность цветов — это перейти из цветового пространства RGB в пространство HSV, где один из параметров и есть насыщенность. Помню, как я открыл формулу перехода и глубоко вздохнул… Реализация подобных вычислений в FPGA не является чем-то экстраординарным, но на написание кода потратить время, конечно придется. Итак, формула перехода из RGB в HSV выглядит следующим образом:

Рисунок 25.
Реализация такого алгоритма в FPGA займет не дни, но часы, причем все это нужно делать очень аккуратно ввиду специфики HDL, а реализация на C++ или в MATLAB займет, я думаю, минуты.
На C++ можно написать код прямо в лоб и все равно получить рабочий результат.
Я написал следующий вариант на С++
И Quartus успешно имплементировал полученный результат, что видно из таблицы использованных ресурсов.

Рисунок 26.
Частота очень неплохая

Рисунок 27.
С HDL coder все немного сложнее.
Чтобы не раздувать статью, я не буду приводить m-скрипт для этой задачи, он не должен вызывать сложности. Написанный в лоб m-скрипт вряд ли можно успешно использовать, но если отредактировать код и правильно указать места для конвейеризации, получим рабочий результат. Это, конечно, займет несколько десятков минут, но не часы.
В C++ тоже желательно расставить директивы и перевести вычисления в фиксированную точку, что также займет не очень много времени.
А значит, используя высокоуровневые средства разработки, мы экономим время, и чем сложнее алгоритм, тем больше времени экономится — так будет продолжаться, пока мы не упремся в ограничения объема ресурсов FPGA или жесткие ограничения по скорости вычислений, где придется браться за HDL.
Что можно сказать в заключении.
Очевидно, золотой молоток еще не изобретен, но есть дополнительные инструменты, которые вполне можно использовать при разработке.
Главным достоинством высокоуровневых средств, по моему мнению, является скорость разработки. Получить достаточное качество за сроки, порой на порядок меньшие, чем при разработке с использованием HDL, это реальность.
К таким достоинствам, как использование для FPGA наследованного кода и подключение к разработке для FPGA программистов без предварительной подготовки я отношусь настороженно. Для получения удовлетворительных результатов придется отказаться от многих привычных приемов программирования.
Еще раз хочу отметить, что данная статья — это лишь поверхностный взгляд на высокоуровневые средства разработки для FPGA.
В HLS compiler есть большие возможности для оптимизаций: прагмы, специальные библиотеки с оптимизированными функциями, описания интерфейсов, в интернете много статей про “best practices” и т.д. Фишка MATLAB, которая не была рассмотрена, это возможность прямо из GUI сгенерировать, например, фильтр, не написав ни одной строчки кода, просто указав желаемые характеристики, что еще ускоряет время разработки.
Кто победил в сегодняшнем исследовании? Мое мнение — это Intel HLS compiler. Он генерирует рабочий дизайн даже из не оптимизированного кода. HDL coder без вдумчивого анализа и переработки кода я бы использовать побоялся. Также хочу отметить, что HDL coder достаточно старый инструмент, но как мне известно, он так и не приобрел широкого признания. А вот HLS, хоть и молод, но видно, что производители FPGA делают на него большую ставку, думаю мы увидим его дальнейшее развитие и рост популярности.
Представители фирмы Xilinx уверяют, что развитие и внедрение высокоуровневых средств — это единственная возможность в будущем вести разработку для все бОльших и бОльших чипов FPGA. Традиционные средства просто не будут справляться с этим, и вероятно, Verilog/VHDL уготована судьба ассемблера, но это в будущем. А сейчас у нас в руках есть инструменты разработки (со своими плюсами и минусами), выбирать которые мы должны исходя из задачи.
Буду ли я использовать высокоуровневые средства разработки в своей работе? Скорее да, сейчас их развитие идет семимильными шагами, поэтому надо как минимум не отставать, но объективных причин немедленно бросать HDL я не вижу.
В конце еще раз хочу отметить, что на данном этапе развития высокоуровневых средств проектирования пользователю ни на минуту нельзя забывать, что он пишет не исполняемую в процессоре программу, а создает схему с реальными проводами, триггерами и логическими элементами.
Являясь FPGA-разработчиком, в качестве основного инструмента я использую язык описания аппаратуры (HDL) Verilog, но растущая популярность новых методов вызвала у меня большой интерес, поэтому в данной статье я решил сам разобрать что к чему.
Эта статья — не руководство или инструкция к пользованию, это мой обзор и выводы о том, что могут дать различные высокоуровневые средства разработки FPGA-разработчику или программисту, который хочет окунуться в мир FPGA. Для того, чтобы сравнить самые интересные на мой взгляд средства разработки, я написал несколько тестов и проанализировал полученные результаты. Под катом — что из этого вышло.
Зачем нужны высокоуровневые средства разработки для FPGA
- Ускорить разработку проекта
— за счет переиспользования уже написанного на языках высокого уровня кода;
— за счет использования всех достоинств языков высокого уровня, при написании кода с нуля;
— за счет уменьшения времени компиляции и верификации кода.
- Возможность создавать универсальный код, который будет работать на любом семействе FPGA.
- Снизить порог вхождения в разработку для FPGA, например уход от понятий “тактовая частота” и других низкоуровневых сущностей. Возможность писать код для FPGA разработчику, не знакомому с HDL.
Откуда берутся средства высокоуровневой разработки
Сейчас многих манит идея высокоуровневой разработки. Этим заняты как энтузиасты, такие как, например, Quokka и кодогенератор на Python, так и корпорации, такие как Mathworks, и производители FPGA Intel и Xilinx
Каждый для достижения цели использует свои методы и инструменты. Энтузиасты в борьбе за идеальный и прекрасный мир используют свои любимые языки разработки, такие как Python или C#. Корпорации, пытаясь угодить клиенту, предлагают свои или адаптируют существующие инструменты. Mathworks предлагают свой инструмент HDL coder для генерации HDL кода из m-скриптов и моделей Simulink, а Intel и Xilinx — компиляторы для распространенного C/C++.
На данный момент большего успеха достигли обладающие значительными финансовыми и человеческими ресурсами компании, в то время как энтузиасты несколько отстают. Данную статью я посвящу рассмотрению продукта HDL coder от Mathworks и HLS Compiler от Intel.
А как же Xilinx
В данной статье я не рассматриваю HLS от Xilinx, по причине разных архитектур и САПР Intel и Xilinx, что делает невозможным провести однозначное сравнение результатов. Но хочу отметить, что Xilinx HLS, как и Intel HLS, предоставляет компилятор C/C++ и концептуально они схожи.
Начнем сравнения HDL coder от Mathworks и HLS Compiler от Intel, решив несколько задач с использованием разных подходов.
Сравнение средств высокоуровневой разработки
Тест первый. “Два умножителя и сумматор”
Решение данной задачи не имеет практической ценности, но хорошо подходит в качестве первого теста. Функция принимает 4 параметра, перемножает первый со вторым, третий с четвертым и складывает результаты умножения. Ничего сложного, но посмотрим, как с этим справятся наши испытуемые.
HDL coder от Mathworks
Для решения такой задачи m-скрипт выглядит следующим образом:
function [out] = TwoMultAdd(a,b,c,d)
out = (a*b)+(c*d);
end
Посмотрим, что предлагает нам Mathworks для конвертации кода в HDL.
Я не буду подробно рассматривать работу с HDL-coder, остановлюсь только на тех настройках, которые в дальнейшем буду изменять для получения разных результатов в FPGA, и над изменениями которых придется подумать MATLAB-программисту, которому требуется запустить свой код в FPGA.
Итак, первое, что необходимо сделать, это задать тип и диапазон входных значений. В FPGA нет привычных char, int, float, double. Разрядность числа может быть любой, логично выбирать ее, исходя из диапазона входных значений, который планируется использовать.
Рисунок 1.
MATLAB проводит проверку типов переменных, их значений и сам подбирает правильные разрядности для шин и регистров, — это действительно удобно. Если проблем с разрядностью и типизацией нет, можно переходить к следующим пунктам.
Рисунок 2.
В HDL Code Generation есть несколько вкладок, где можно выбрать язык, в который произойдет конвертация (Verilog или VHDL); стиль кода; названия сигналов. Самая интересная вкладка, на мой взгляд, — это Optimization, — с ней я и буду проводить эксперименты, но позже, а пока оставим все значения по умолчанию и посмотрим, что получится у HDL coder “из коробки”.
Нажимаем кнопку Run и получаем следующий код:
`timescale 1 ns / 1 ns
module TwoMultAdd_fixpt
(a,
b,
c,
d,
out);
input [7:0] a; // ufix8
input [7:0] b; // ufix8
input [7:0] c; // ufix8
input [7:0] d; // ufix8
output [16:0] out; // ufix17
wire [15:0] TwoMultAdd_fixpt_mul_temp; // ufix16
wire [16:0] TwoMultAdd_fixpt_2; // ufix17
wire [15:0] TwoMultAdd_fixpt_mul_temp_1; // ufix16
wire [16:0] TwoMultAdd_fixpt_3; // ufix17
//HDL code generation from MATLAB function: TwoMultAdd_fixpt
//%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
// %
// Generated by MATLAB 9.2 and Fixed-Point Designer 5.4 %
// %
//%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
assign TwoMultAdd_fixpt_mul_temp = a * b;
assign TwoMultAdd_fixpt_2 = {1'b0, TwoMultAdd_fixpt_mul_temp};
assign TwoMultAdd_fixpt_mul_temp_1 = c * d;
assign TwoMultAdd_fixpt_3 = {1'b0, TwoMultAdd_fixpt_mul_temp_1};
assign out = TwoMultAdd_fixpt_2 + TwoMultAdd_fixpt_3;
endmodule // TwoMultAdd_fixpt
Выглядит код неплохо. MATLAB понимает, что запись всего выражения в одну строку на Verilog — плохая практика. Создает отдельные wire для умножителя и сумматора, придраться особо не к чему. Настораживает, что отсутствует описание регистров. Так получилось потому, что мы и не просили об этом HDL-coder, а все поля в настройках оставили в значениях по умолчанию.
Вот что из такого кода синтезирует Quartus.
Рисунок 3.
Никаких проблем, все как и было задумано.
В FPGA мы реализуем синхронные схемы, и все-таки хотелось бы видеть регистры. HDL-coder предлагает механизм для размещения регистров, но где их разместить — решать разработчику. Мы можем разместить регистры на входе умножителей, на выходе умножителей перед сумматором или на выходе сумматора.
Для синтезирования примеров я выбрал семейство FPGA Cyclone V, где для реализации арифметических действий используются специальные DSP блоки со встроенными сумматорами и умножителями. Выглядит DSP блок следующим образом:
Рисунок 4.
DSP блок имеет входные и выходные регистры. Нет необходимости пытаться защелкнуть результаты умножения в регистре до сложения, это только нарушит архитектуру (в определенных случаях такой вариант возможен и даже нужен). Как поступать с входным и выходным регистром решать разработчику, исходя из требований к задержке (latency) и необходимой максимальной частоте. Я принял решение использовать только выходной регистр. Для того, чтобы этот регистр был описан в коде, генерируемом HDL-coder’ом, во вкладке Options в HDL coder необходимо поставить галочку напротив Register output и повторно запустить конвертацию.
Получается следующий код:
`timescale 1 ns / 1 ns
module TwoMultAdd_fixpt
(clk,
reset,
clke_ena_i,
a,
b,
c,
d,
clke_ena_o,
out);
input clk;
input reset;
input clke_ena_i;
input [7:0] a; // ufix8
input [7:0] b; // ufix8
input [7:0] c; // ufix8
input [7:0] d; // ufix8
output clke_ena_o;
output [16:0] out; // ufix17
wire enb;
wire [16:0] out_1; // ufix17
wire [15:0] TwoMultAdd_fixpt_mul_temp; // ufix16
wire [16:0] TwoMultAdd_fixpt_2; // ufix17
wire [15:0] TwoMultAdd_fixpt_mul_temp_1; // ufix16
wire [16:0] TwoMultAdd_fixpt_3; // ufix17
reg [16:0] out_2; // ufix17
//HDL code generation from MATLAB function: TwoMultAdd_fixpt
//%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
// %
// Generated by MATLAB 9.2 and Fixed-Point Designer 5.4 %
// %
//%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
assign TwoMultAdd_fixpt_mul_temp = a * b;
assign TwoMultAdd_fixpt_2 = {1'b0, TwoMultAdd_fixpt_mul_temp};
assign TwoMultAdd_fixpt_mul_temp_1 = c * d;
assign TwoMultAdd_fixpt_3 = {1'b0, TwoMultAdd_fixpt_mul_temp_1};
assign out_1 = TwoMultAdd_fixpt_2 + TwoMultAdd_fixpt_3;
assign enb = clke_ena_i;
always @(posedge clk or posedge reset)
begin : out_reg_process
if (reset == 1'b1) begin
out_2 <= 17'b00000000000000000;
end
else begin
if (enb) begin
out_2 <= out_1;
end
end
end
assign clke_ena_o = clke_ena_i;
assign out = out_2;
endmodule // TwoMultAdd_fixpt
Как видно, в коде есть принципиальные отличия по сравнению с предыдущим вариантом. Появился always-блок, который и является описанием регистра (как раз то, что мы хотели). Для работы always-блока появились также входы модуля clk (тактовая частота) и reset (сброс). Видно, что выход сумматора защелкивается в триггере, описанном в always. Также есть пара сигналов разрешения ena, но они нам не очень интересны.
Посмотрим на схему, которую теперь синтезирует Quartus.
Рисунок 5.
И снова результаты хорошие и ожидаемые.
На рисунке ниже представлена таблица использованных ресурсов — держим ее в уме.
Рисунок 6.
За это первое задание Mathworks получает зачет. Все не сложно, предсказуемо и с желаемым результатом.
Я довольно подробно описал простой пример, привел схему DSP-блока и описал возможности применения настройки использования регистров в HDL-coder, отличных от настроек “по умолчанию”. Это сделано не просто так. Этим я хотел подчеркнуть, что даже в таком простом примере при использования HDL-coder знания архитектуры FPGA и основ цифровой схемотехники необходимы, а настройки необходимо изменять осознанно.
HLS Compiler от Intel
Давайте попробуем собрать код с той же функциональностью, написанный на С++, и посмотрим, что в итоге синтезируется в FPGA с помощью HLS compiler.
Итак, код на С++
component unsigned int TwoMultAdd(unsigned char a, unsigned char b, unsigned char c, unsigned char d)
{
return (a*b)+(c*d);
}
Типы данных я выбрал так, чтобы избежать переполнения переменных.
Есть продвинутые методы задания разрядностей, но наша цель — проверить возможность собрать под FPGA написанные в стиле С/С++ функции без внесения изменений, все из коробки.
Так как HLS compiler — родной инструмент Intel, собираем код специальным компилятором и проверяем результат сразу в Quartus.
Посмотрим на схему, которую синтезирует Quartus.
Рисунок 7.
Компилятор создал регистры на входе и выходе, но самая суть скрыта в модуле обертке. Начинаем разворачивать обертку и… видим еще, еще и еще вложенные модули.
Структура проекта выглядит так.
Рисунок 8.
Очевиден намек от Intel: “руками не лезть!”. Но мы попробуем, тем более функционал не сложный.
В недрах дерева проекта |quartus_compile|TwoMultAdd:TwoMultAdd_inst|TwoMultAdd_internal:twomultadd_internal_inst|TwoMultAdd_fu
nction_wrapper:TwoMultAdd_internal|TwoMultAdd_function:theTwoMultAdd_function|bb_TwoMultAdd_B1_start:
thebb_TwoMultAdd_B1_start|bb_TwoMultAdd_B1_start_stall_region:thebb_TwoMultAdd_B1_start_stall_region|i
_sfc_c1_wt_entry_twomultadd_c1_enter_twomultadd:thei_sfc_c1_wt_entry_twomultadd_c1_enter_twomultad
d_aunroll_x|i_sfc_logic_c1_wt_entry_twomultadd_c1_enter_twomultadd13:thei_sfc_logic_c1_wt_entry_twom
ultadd_c1_enter_twomultadd13_aunroll_x|Mult1 находится искомый модуль.
Можем посмотреть на схему искомого модуля, синтезированную Quartus’ом.
Рисунок 9.
Какие выводы можно сделать из этой схемы.
Видно, что произошло то, чего мы пытались избежать при работе в MATLAB: синтезирован регистр на выходе умножителя — это не очень хорошо. Из схемы DSP блока (Рисунок 4) видно, что есть только один регистр на его выходе, а значит каждое умножение придется производить в отдельном блоке.
В таблице использованных ресурсов показано, к чему это приводит.
Рисунок 10.
Сравним результаты с таблицей HDL coder (Рисунок 6).
Если с использованием большего числа регистров можно мириться, то расходовать драгоценные DSP блоки на таком простом функционале очень неприятно.
Но есть огромный плюс в Intel HLS по сравнению с HDL coder. При настройках “по умолчанию” HLS compiler развел в FPGA синхронный дизайн, хоть и израсходовал больше ресурсов. Такая архитектура возможна, видно, что Intel HLS настроен на достижение максимальной производительности, а не на экономию ресурсов.
Посмотрим как наши испытуемые поведут себя с более сложными проектами.
Тест второй. “Поэлементное перемножение матриц с суммированием результата”
Данная функция широко используется в обработке изображений: так называемый, “матричный фильтр”. Реализуем его с использованием высокоуровневых средств.
HDL coder от Mathwork
Работа сразу начинается с ограничения. HDL Сoder не может принимать на вход функций 2-D матрицы. С учетом того, что MATLAB — это инструмент работы именно с матрицами, — то это серьезный удар по всему наследованному коду, что может стать серьезной проблемой. Если код пишется с нуля, это неприятная особенность, которую надо учитывать. Так что приходится разворачивать все матрицы в вектор и реализовывать функции с учетом векторов на входе.
Код для функции в MATLAB выглядит следующим образом
function [out] = mhls_conv2_manually(target,kernel)
len = length(kernel);
mult = target.*kernel;
summ = sum(mult);
out = summ/len;
end
Сгенерированный HDL код получился очень раздутым и содержит сотни строк, поэтому приводить его здесь я не буду. Сразу посмотрим какую схему синтезирует Quartus из этого кода.
Рисунок 11.
Выглядит данная схема неудачно. Формально она рабочая, но я предполагаю, что работать она будет на очень низкой частоте, и вряд ли ее можно использовать в реальном железе. Но любое предположение должно быть проверено. Для этого разместим регистры на входе и выходе данной схемы и при помощи Timing Analyzer оценим реальное положение дел. Для проведения анализа необходимо указать желаемую рабочую частоту схемы, чтобы Quartus знал, к чему стремиться при разводке, и в случае неудачи предоставил отчеты о нарушениях.
Задаем частоту 100МГц, посмотрим, что у Quartus получится выжать из предложенной схемы.
Рисунок 12.
Видно, что получилось немногое: 33 МГц выглядят несерьезно. Задержка в цепочке из умножителей и сумматоров около 30 нс. Чтобы избавиться от этого “бутылочного горлышка”, необходимо использовать конвейер: вставляем регистры после арифметических операций, уменьшая тем самым критический путь.
HDL coder дает нам такую возможность. Во вкладке Options можно задать Pipeline variables. Так как рассматриваемый код написан в MATLAB стиле, нет возможности конвейеризировать переменные (кроме переменных mult и summ), что нас не устраивает. Необходимо вставить регистры в промежуточные цепи, скрытые в нашем HDL коде.
Причем ситуация с оптимизацией могла быть и хуже. Например, ничего не мешает нам написать код
out = (sum(target.*kernel))/len;он вполне адекватен для MATLAB, но полностью лишает нас возможности оптимизации HDL.
Выход следующий — править код руками. Это очень важный момент, так как мы отказываемся от наследования и начинаем переписывать m-скрипт, причем НЕ в MATLAB стиле.
Новый код выглядит следующим образом
function [out] = mhls_conv2_manually(target,kernel)
len = length(kernel);
mult = target.*kernel;
summ_1 = zeros([1,(len/2)]);
summ_2 = zeros([1,(len/4)]);
summ_3 = zeros([1,(len/8)]);
for i=0:1:(len/2)-1
summ_1(i+1) = (mult(i*2+1)+mult(i*2+2));
end
for i=0:1:(len/4)-1
summ_2(i+1) = (summ_1(i*2+1)+summ_1(i*2+2));
end
for i=0:1:(len/8)-1
summ_3(i+1) = (summ_2(i*2+1)+summ_2(i*2+2));
end
out = summ_3/len;
end
В Quartus собираем сгенерированный HDL Coder’ом код. Видно, что количество слоев с примитивами (комбинаторной логикой) уменьшилось, и схема выглядит гораздо лучше.
Рисунок 12.
При правильной компоновке примитивов частота вырастает почти в 3 раза, до 88 МГц.
Рисунок 13.
Теперь последний штрих: в настройках Optimization указываем summ_1, summ_2 и summ_3 как элементы конвейера. Собираем получившийся код в Quartus. Схема меняется следующим образом:
Рисунок 14.
Максимальная частота снова увеличивается и теперь ее значение около 195 МГц.
Рисунок 15.
Столько же ресурсов на кристалле займет такой дизайн? На рисунке 16 показана таблица использованных ресурсов для описанного случая.
Рисунок 16.
Какие выводы можно сделать после рассмотрения этого примера?
Главный недостаток HDL coder — использовать MATLAB код в чистом виде вряд ли получится.
Отсутствует поддержка матриц как входов функции, разводка кода в MATLAB стиле посредственная.
Главная опасность в отсутствии регистров в сгенерированном без дополнительных настроек коде. Без этих регистров, даже получив формально работающий HDL код без синтаксических ошибок, использование такого кода в современных реалиях и разработках нежелательно.
Желательно сразу писать код, заточенный под конвертацию в HDL. В таком случае можно получать вполне приемлемые по скорости и ресурсоемкости результаты.
Если вы MATLAB разработчик, не спешите нажимать кнопку Run и собирать ваш код под FPGA, помните, что ваш код будет синтезирован в реальную схему. =)
HLS Compiler от Intel
Для того-же функционала я написал следующий код на С/С++
component unsigned int conv(unsigned char *data, unsigned char *kernel)
{
unsigned int mult_res[16];
unsigned int summl;
summl = 0;
for (int i = 0; i < 16; i++)
{
mult_res[i] = data[i] * kernel[i];
summl = summl+mult_res[i];
}
return summl/16;
}
Первое, что бросается в глаза, это количество использованных ресурсов.
Рисунок 17.
Из таблицы видно, что использован всего 1 DSP блок, значит что-то пошло не так, и умножения не выполняются параллельно. Также удивляет количество использованных регистров, и задействована даже память, но это оставим на совести HLS compiler.
Хочется отметить, что HLS compiler развел неоптимальную, использующую огромное количество лишних ресурсов, но все же рабочую схему, которая, по отчетам Quartus, заработает на приемлемой частоте, и такого провала как у HDL coder не будет.
Рисунок 18.
Попробуем улучшить ситуацию. Что для этого нужно? Правильно, закрыть глаза на наследование и залезть в код, но пока что совсем немного.
HLS есть специальные директивы для оптимизации кода под FPGA. Вставляем директиву unroll, которая должна развернуть наш цикл в параллель:
#pragma unroll
for (int i = 0; i < 16; i++)
{
mult_res[i] = data[i] * kernel[i];
}
Посмотрим как на это отреагировал Quartus
Рисунок 19.
Первым делом обращаем внимание на количество DSP блоков — их 16, а значит умножения выполняются параллельно.
Ура! unroll работает! Но с тем, как сильно выросла утилизация других ресурсов, уже тяжело мириться. Схема стала абсолютно нечитаемой.
Рисунок 20.
Я полагаю, это произошло из-за того, что никто не указал компилятору на то, что нам вполне подходят вычисления в числах с фиксированной точкой, и он честно на логике и регистрах реализовал всю математику с плавающей точкой. Нужно объяснить компилятору что от него требуется, и для этого мы снова погружаемся в код.
Для целей использования fixed-point реализованы шаблонные классы.
Рисунок 21.
Если говорить своими словами, мы можем использовать переменные, разрядность которых задаем вручную с точностью до бита. Для тех, кто пишет на HDL, к этому не привыкать, но программисты С/С++, наверное, схватятся за голову. Разрядности, как в MATLAB, в данном случае никто не подскажет, и считать количество бит должен сам разработчик.
Посмотрим как это выглядит на практике.
Редактируем код следующим образом:
component ac_fixed<16,16,false> conv(ac_fixed<8,8,false> *data, ac_fixed<8,8,false> *kernel)
{
ac_fixed<16,16,false>mult_res[16];
ac_fixed<32,32,false>summl;
#pragma unroll
for (int i = 0; i < 16; i++)
{
mult_res[i] = data[i] * kernel[i];
}
for (int i = 0; i < 16; i++)
{
summl = summl+mult_res[i];
}
return summl/16;
}
И вместо жутких макарон из рисунка 20 получаем вот такую красоту:
Рисунок 22.
К сожалению, нечто странное продолжает происходить с использованными ресурсами.
Рисунок 23.
Но при подробном рассмотрении отчетов видно, что непосредственно интересующий нас модуль выглядит более чем адекватно:
Рисунок 24.
Огромное потребление регистров и блочной памяти связано с большим количеством периферийных модулей. Глубокий смысл их существования мне пока до конца не понятен, и с этим нужно будет разобраться, но проблема решаема. В крайнем случае можно аккуратно вырезать из общей структуры проекта один интересующий нас модуль, что избавит нас от периферийных модулей, пожирающих ресурсы.
Тест третий. “Переход из цветового пространства RGB в цветовое пространство HSV”
Начиная писать эту статью, я не ожидал, что она окажется такой объемной. Но я не могу отказаться от третьего, и последнего в рамках данной статьи, примера.
Во-первых, это реальный пример из моей практики, и именно из-за него я начал смотреть в сторону высокоуровневых средств разработки.
Во-вторых, из первых двух примеров мы могли бы сделать предположение, что чем сложнее дизайн, тем хуже высокоуровневые средства справляются с задачей.
Я же хочу продемонстрировать, что это суждение ошибочно, и на самом деле чем сложнее задача, тем больше проявляются достоинства высокоуровневых средств разработки.
В прошлом году в работе над одним из проектов меня не устраивала приобретенная на Aliexpress камера, а именно — цвета были недостаточно насыщенными. Один из популярных способов варьировать насыщенность цветов — это перейти из цветового пространства RGB в пространство HSV, где один из параметров и есть насыщенность. Помню, как я открыл формулу перехода и глубоко вздохнул… Реализация подобных вычислений в FPGA не является чем-то экстраординарным, но на написание кода потратить время, конечно придется. Итак, формула перехода из RGB в HSV выглядит следующим образом:
Рисунок 25.
Реализация такого алгоритма в FPGA займет не дни, но часы, причем все это нужно делать очень аккуратно ввиду специфики HDL, а реализация на C++ или в MATLAB займет, я думаю, минуты.
На C++ можно написать код прямо в лоб и все равно получить рабочий результат.
Я написал следующий вариант на С++
struct color_space{
unsigned char rh;
unsigned char gs;
unsigned char bv;
};
component color_space rgb2hsv(color_space rgb_0)
{
color_space hsv;
float h,s,v,r,g,b;
float max_col, min_col;
r = static_cast<float>(rgb_0.rh)/255;
g = static_cast<float>(rgb_0.gs)/255;
b = static_cast<float>(rgb_0.bv)/255;
max_col = std::max(std::max(r,g),b);
min_col = std::min(std::min(r,g),b);
//расчет H
if (max_col == min_col)
h = 0;
else if (max_col==r && g>=b)
h = 60*((g-b)/(max_col-min_col));
else if (max_col==r && g<b)
h = 60*((g-b)/(max_col-min_col))+360;
else if (max_col==g)
h = 60*((b-r)/(max_col-min_col))+120;
else if (max_col==b)
h = 60*((r-g)/(max_col-min_col))+240;
//расчет S
if (max_col == 0)
s = 0;
else
{
s = (1-(min_col/max_col))*100;
}
//расчет V
v = max_col*100;
hsv.rh = static_cast<char>(h);
hsv.gs = static_cast<char>(s);
hsv.bv = static_cast<char>(v);
return hsv;
}
И Quartus успешно имплементировал полученный результат, что видно из таблицы использованных ресурсов.
Рисунок 26.
Частота очень неплохая
Рисунок 27.
С HDL coder все немного сложнее.
Чтобы не раздувать статью, я не буду приводить m-скрипт для этой задачи, он не должен вызывать сложности. Написанный в лоб m-скрипт вряд ли можно успешно использовать, но если отредактировать код и правильно указать места для конвейеризации, получим рабочий результат. Это, конечно, займет несколько десятков минут, но не часы.
В C++ тоже желательно расставить директивы и перевести вычисления в фиксированную точку, что также займет не очень много времени.
А значит, используя высокоуровневые средства разработки, мы экономим время, и чем сложнее алгоритм, тем больше времени экономится — так будет продолжаться, пока мы не упремся в ограничения объема ресурсов FPGA или жесткие ограничения по скорости вычислений, где придется браться за HDL.
Заключение
Что можно сказать в заключении.
Очевидно, золотой молоток еще не изобретен, но есть дополнительные инструменты, которые вполне можно использовать при разработке.
Главным достоинством высокоуровневых средств, по моему мнению, является скорость разработки. Получить достаточное качество за сроки, порой на порядок меньшие, чем при разработке с использованием HDL, это реальность.
К таким достоинствам, как использование для FPGA наследованного кода и подключение к разработке для FPGA программистов без предварительной подготовки я отношусь настороженно. Для получения удовлетворительных результатов придется отказаться от многих привычных приемов программирования.
Еще раз хочу отметить, что данная статья — это лишь поверхностный взгляд на высокоуровневые средства разработки для FPGA.
В HLS compiler есть большие возможности для оптимизаций: прагмы, специальные библиотеки с оптимизированными функциями, описания интерфейсов, в интернете много статей про “best practices” и т.д. Фишка MATLAB, которая не была рассмотрена, это возможность прямо из GUI сгенерировать, например, фильтр, не написав ни одной строчки кода, просто указав желаемые характеристики, что еще ускоряет время разработки.
Кто победил в сегодняшнем исследовании? Мое мнение — это Intel HLS compiler. Он генерирует рабочий дизайн даже из не оптимизированного кода. HDL coder без вдумчивого анализа и переработки кода я бы использовать побоялся. Также хочу отметить, что HDL coder достаточно старый инструмент, но как мне известно, он так и не приобрел широкого признания. А вот HLS, хоть и молод, но видно, что производители FPGA делают на него большую ставку, думаю мы увидим его дальнейшее развитие и рост популярности.
Представители фирмы Xilinx уверяют, что развитие и внедрение высокоуровневых средств — это единственная возможность в будущем вести разработку для все бОльших и бОльших чипов FPGA. Традиционные средства просто не будут справляться с этим, и вероятно, Verilog/VHDL уготована судьба ассемблера, но это в будущем. А сейчас у нас в руках есть инструменты разработки (со своими плюсами и минусами), выбирать которые мы должны исходя из задачи.
Буду ли я использовать высокоуровневые средства разработки в своей работе? Скорее да, сейчас их развитие идет семимильными шагами, поэтому надо как минимум не отставать, но объективных причин немедленно бросать HDL я не вижу.
В конце еще раз хочу отметить, что на данном этапе развития высокоуровневых средств проектирования пользователю ни на минуту нельзя забывать, что он пишет не исполняемую в процессоре программу, а создает схему с реальными проводами, триггерами и логическими элементами.


