 Недавно завершился «Диалог 2020», международная научная конференция по компьютерной лингвистике и интеллектуальным технологиям. Традиционно одно из ключевых событий конференции – это Dialogue Evaluation, соревнования между разработчиками автоматических систем лингвистического анализа текстов. Мы уже рассказывали на Хабре о задачах, которые участники состязаний решали в прошлом году, например, о генерации заголовков и поиске пропущенных слов в тексте. Сегодня мы поговорили с победителями двух дорожек Dialogue Evaluation этого года — Владиславом Корзуном и Даниилом Анастасьевым — о том, почему они решили участвовать в технологических соревнованиях, какие задачи и какими способами решали, чем ребята интересуются, где учились и чем планируют заниматься в будущем. Добро пожаловать под кат!
Недавно завершился «Диалог 2020», международная научная конференция по компьютерной лингвистике и интеллектуальным технологиям. Традиционно одно из ключевых событий конференции – это Dialogue Evaluation, соревнования между разработчиками автоматических систем лингвистического анализа текстов. Мы уже рассказывали на Хабре о задачах, которые участники состязаний решали в прошлом году, например, о генерации заголовков и поиске пропущенных слов в тексте. Сегодня мы поговорили с победителями двух дорожек Dialogue Evaluation этого года — Владиславом Корзуном и Даниилом Анастасьевым — о том, почему они решили участвовать в технологических соревнованиях, какие задачи и какими способами решали, чем ребята интересуются, где учились и чем планируют заниматься в будущем. Добро пожаловать под кат!Владислав Корзун, победитель дорожки Dialogue Evaluation RuREBus-2020

Чем ты занимаешься?
Я разработчик в NLP Advanced Research Group в ABBYY. В данный момент мы решаем задачу one shot learning для извлечения сущностей. Т. е. имея небольшую обучающую выборку (5-10 документов), надо научиться извлекать специфические сущности из похожих документов. Для этого мы собираемся использовать выходы обученной на стандартных типах сущностей (Персоны, Локации, Организации) NER-модели в качестве признаков для решения этой задачи. Также мы планируем использовать специальную языковую модель, которая обучалась на документах, схожих по тематике с нашей задачей.
Какие задачи ты решал на Dialogue Evaluation?
На «Диалоге» я участвовал в соревновании RuREBus, посвященном извлечению сущностей и отношений из специфических документов корпуса Минэкономразвития. Данный корпус сильно отличался от корпусов, используемых, например, в соревновании Conll. Во-первых, сами типы сущностей были не стандартные (Персоны, Локации, Организации), среди них были даже неименованные и субстантивы действий. Во-вторых, сами тексты представляли собой не наборы выверенных предложений, а реальные документы, из-за чего в них попадались различные списки, заголовки и даже таблицы. В итоге основные трудности возникали именно с обработкой данных, а не с решением задачи, т.к. по сути это классические задачи Named Entity Recognition и Relation Extraction.
В самом соревновании было 3 дорожки: NER, RE с заданными сущностями и end-to-end RE. Я пытался решить первые две. В первой задаче я использовал классические подходы. Сперва я попробовал в качестве модели использовать рекуррентную сеть, а в качестве признаков – словные эмбеддинги fasttext, шаблоны капитализации, символьные эмбеддинги и POS-тэги[1]. Затем я уже использовал различные предобученные BERT-ы [2], которые довольно сильно превзошли предыдущий мой подход. Однако этого не хватило, чтобы занять первое место в этой дорожке.
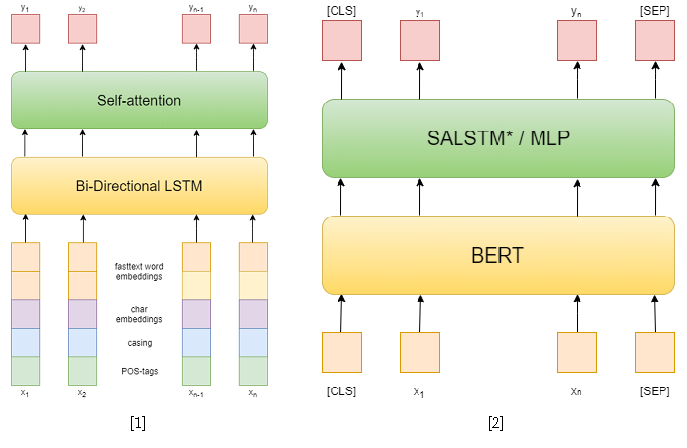
А вот во второй дорожке мне это удалось. Для решения задачи извлечения отношений я свел её к задаче классификации отношений, схожей с SemEval 2010 Task 8. В данной задаче для каждого предложения дана одна пара сущностей, для которой нужно классифицировать отношение. А в дорожке в каждом предложении может быть сколько угодно сущностей, однако она просто сводится к предыдущей путем сэмплирования предложения для каждой пары сущностей. Также при обучении я брал отрицательные примеры случайно для каждого предложения в размере, не большем удвоенного числа положительных, чтобы сократить обучающую выборку.
В качестве подходов к решению задачи классификации отношений я использовал две модели, основанные на BERT-e. В первой я просто конкатенировал выходы BERT с NER-эмбеддингами и затем усреднял признаки по каждому токену с помощью Self-attention[3]. В качестве второй модели была взята одна из лучших для решения SemEval 2010 Task 8 – R-BERT[4]. Суть данного подхода в следующем: вставить специальные токены до и после каждой сущности, усреднить выходы BERT для токенов каждой сущности, объединить полученные вектора с выходом, соответствующим CLS-токену и классифицировать полученный вектор признаков. В итоге данная модель заняла первое место в дорожке. Результаты соревнования доступны здесь.
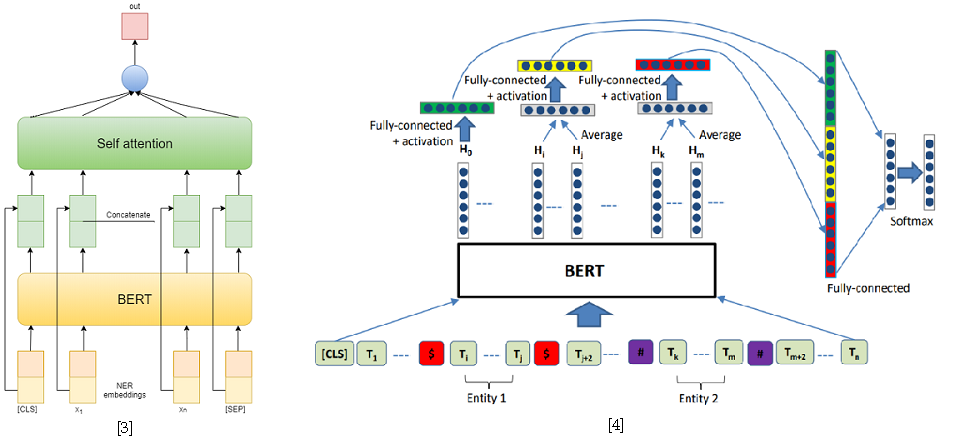
[4] Wu, S., He, Y. (2019, November). Enriching pre-trained language model with entity information for relation classification. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management (pp. 2361-2364).
Что показалось тебе наиболее сложным в этих задачах?
Самым проблемным оказалась обработка корпуса. Сами задачи максимально классические, для их решения уже есть готовые фреймворки, например AllenNLP. Но ответ нужно выдавать с сохранением спанов токенов, поэтому я не мог просто использовать готовый пайплайн, не написав множество дополнительного кода. Поэтому я решил писать весь пайплайн на чистом PyTorch, чтобы ничего не упустить. Хотя некоторые модули из AllenNLP я все-таки использовал.
Еще в корпусе было много довольно длинных предложений, которые доставляли неудобства при обучении больших трансформеров, например BERT-а, т.к. они становятся требовательны к видеопамяти с увеличением длины предложений. Однако большинство таких предложений – перечисления, разделенные точкой с запятой, и их можно было разделить по этому символу. Оставшиеся предложения я просто делил по максимальному числу токенов.
Ты раньше участвовал в «Диалоге» и дорожках?
В прошлом году выступал со своим магистерским дипломом на студенческой сессии.
А почему в этом году решил участвовать в соревнованиях?
В это время я как раз решал задачу извлечения отношений, но для другого корпуса. Я пытался использовать другой подход, основанный на деревьях синтаксического разбора. В качестве входных данных использовался путь в дереве от одной сущности к другой. Но такой подход, к сожалению, не показал сильных результатов, хоть и был на уровне с подходом, основанном на рекуррентных сетях, использующих в качестве признаков эмбеддинги токенов и другие признаки, такие как длина пути от токена к руту или одной из сущностей в дереве синтаксического разбора, а также относительное положение от сущностей.
В данном соревновании я решил участвовать, т. к. у меня уже были некоторые наработки для решения подобных задач. И почему их не применить в соревновании и не получить публикацию? Получилось не так просто, как я думал, но это, скорее, из-за проблем с взаимодействием с корпусами. В итоге для меня это, скорее, была инженерная задача, чем исследовательская.
А в других соревнованиях ты участвовал?
В это же время наша команда участвовала в SemEval. В основном задачей занимался Илья Димов, я лишь предложил пару идей. Там была задача классификации пропаганды: выделен спан текста и нужно его классифицировать. Я предложил использовать подход R-BERT, то есть выделять в токенах эту сущность, перед ней и после нее вставлять специальный токен и усреднять выходы. В итоге это дало небольшой прирост. Вот и научная ценность: для решения задачи мы использовали модель, предназначенную совсем для другого.
Еще участвовал в ABBYY-шном хакатоне, в ACM icpc – соревнованиях по спортивному программированию на первых курсах. Мы тогда особо далеко не прошли, но было весело. Подобные соревнования сильно отличаются от представленных на «Диалоге», где есть достаточно много времени, чтобы спокойно реализовать и проверить несколько подходов. В хакатонах же нужно все делать быстро, времени расслабиться, попить чай нет. Но в этом и вся прелесть подобных мероприятий – в них царит специфическая атмосфера.
Какие самые интересные задачи ты решал на соревнованиях либо на работе?
Скоро будет соревнование по генерации жестов GENEA, и я собираюсь туда пойти. Мне кажется, это будет интересно. Это воркшоп на ACM – International Conference on Intelligent Virtual Agents. В данном соревновании предлагается генерировать жесты для 3D-модели человека на основе голоса. Я выступал в этом году на «Диалоге» с похожей темой, делал небольшой обзор подходов для задачи автоматической генерации мимики и жестов по голосу. Нужно набираться опыта, ведь мне еще диссертацию защищать по схожей теме. Я хочу попробовать создать читающего виртуального агента, с мимикой, жестами, и конечно, голосом. Текущие подходы синтеза речи позволяют генерировать довольно реалистичную речь по тексту, а подходы генерации жестов – жесты по голосу. Так почему бы не объединить эти подходы.
Кстати, где ты сейчас учишься?
Я учусь в аспирантуре кафедры компьютерной лингвистики ABBYY в МФТИ. Через два года буду защищать диссертацию.
Какие знания и навыки, полученные в вузе, тебе помогают сейчас?
Как ни странно, математика. Пусть я и не интегрирую каждый день и не перемножаю матрицы в уме, но математика учит аналитическому мышлению и умению разобраться в чем угодно. Ведь любой экзамен включает в себя доказательство теорем, и пытаться их выучить – бесполезно, а понять и доказать самому, помня только идею, возможно. Также у нас были неплохие курсы по программированию, где мы с низкого уровня учились понимать, как все устроено, разбирали различные алгоритмы и структуры данных. И теперь разобраться с новым фреймворком или даже языком программирования не составит проблем. Да, конечно, у нас были курсы и по машинному обучению, и по NLP, в частности, но все-таки, как мне кажется, базовые навыки важнее.
Даниил Анастасьев, победитель дорожки Dialogue Evaluation GramEval-2020

Чем ты занимаешься?
Я занимаюсь разработкой голосового помощника «Алиса», работаю в группе поиска смысла. Мы анализируем запросы, которые приходят в «Алису». Стандартный пример запроса – «Какая завтра погода в Москве?». Нужно понять, что это запрос про погоду, что в запросе спрашивается про локацию (Москва) и есть указание времени (завтра).
Расскажи про задачу, которую ты решал в этом году на одном из треков Dialogue Evaluation.
Я занимался задачей, очень близкой тому, чем занимаются в ABBYY. Нужно было построить модель, которая проанализирует предложение, сделает морфологический и синтаксический разбор, определит леммы. Это очень похоже на то, что делают в школе. Построение модели заняло примерно 5 моих выходных дней.

Модель училась на нормальном русском языке, но, как видите, она работает и на таком языке, который был в задаче.
А похоже ли это на то, чем ты занимаешься на работе?
Скорее, нет. Тут надо понимать, что эта задача сама по себе особого смысла не несет – её решают как подзадачу в рамках решения некоторой важной для бизнеса задачи. Так, например, в компании ABBYY, где я работал когда-то, морфо-синтаксический разбор – это начальный этап в рамках решения задачи извлечения информации. В рамках моих текущих задач у меня не возникает необходимости в таких разборах. Однако сам по себе дополнительный опыт работы с предобученными языковыми моделями типа BERT, по ощущениям, безусловно полезен для моей работы. В целом, это и было основной мотивацией для участия – я хотел не выиграть, а попрактиковаться и получить какие-то полезные навыки. К тому же, мой диплом был частично связан с темой задачи.
Участвовал ли ты в Dialogue Evaluation до этого?
Участвовал в дорожке MorphoRuEval-2017 на 5 курсе и тоже тогда занял 1 место. Тогда нужно было определить только морфологию и леммы, без синтаксических отношений.
Реально ли применять твою модель для других задач уже сейчас?
Да, мою модель можно использовать для других задач – я выложил весь исходный код. Планирую выложить код с применением более легковесной и быстрой, но менее точной модели. Теоретически, если кому-то захочется, можно использовать текущую модель. Проблема в том, что она будет слишком большая и медленная для большинства. В соревновании никого не волнует скорость, интересно добиться как можно более высокого качества, а вот в практическом применении всё обычно наоборот. Поэтому основная польза от таких вот больших моделей – это знание, какое качество максимально достижимо, чтобы понимать, чем жертвуешь.
А для чего ты участвуешь в Dialogue Evaluation и других подобных соревнованиях?
Хакатоны и такие соревнования напрямую не связаны с моей деятельностью, но это все равно полезный опыт. Например, когда я участвовал в хакатоне AI Journey в прошлом году, я научился каким-то вещам, которые потом использовал в работе. Задача была научиться проходить ЕГЭ по русскому языку, то есть решать тесты и писать сочинение. Понятно, что это всё слабо связано с работой. А вот умение быстро придумать и обучить модель, которая решает какую-то задачу – очень даже полезно. Мы тогда с командой, кстати, заняли первое место.
Расскажи, какое образование ты получил и чем занимался после университета?
Окончил бакалавриат и магистратуру кафедры компьютерной лингвистики ABBYY в МФТИ, выпустился в 2018 году. Также учился в Школе анализа данных (ШАД). Когда пришло время выбирать базовую кафедру на 2 курсе, у нас большая часть группы пошла на кафедры ABBYY – компьютерной лингвистики или распознавания изображений и обработки текста. В бакалавриате нас хорошо учили программировать – были очень полезные курсы. Я с 4 курса работал в ABBYY на протяжении 2,5 лет. Сначала в группе морфологии, затем занимался задачами, связанными с языковыми моделями для улучшения распознавания текста в ABBYY FineReader. Я писал код, обучал модели, сейчас я занимаюсь тем же, но для совсем другого продукта.
А как проводишь свободное время?
Люблю читать книги. В завиcимости от времени года стараюсь бегать или ходить на лыжах. Увлекаюсь фотографией во время путешествий.
Есть ли у тебя планы или цели на ближайшие, допустим, 5 лет?
5 лет – слишком далекий горизонт планирования. У меня ведь даже нет 5-летнего опыта работы. За последние 5 лет многое поменялось, сейчас явно другое ощущение от жизни. С трудом представляю, что еще может измениться, но есть мысли получить PhD за границей.
Что можешь посоветовать молодым разработчикам, которые занимаются компьютерной лингвистикой и находятся в начале пути?
Лучше всего практиковаться, пробовать и участвовать в соревнованиях. Совсем начинающие могут пройти один из множества курсов: например, от ШАДа, DeepPavlov или даже мой собственный, который я когда-то провел в ABBYY.
Кстати, мы продолжаем набор в магистратуру на кафедры ABBYY в МФТИ: распознавания изображений и обработки текста (РИОТ) и компьютерной лингвистики (КЛ). До 15 июля включительно присылайте на brains@abbyy.com мотивационное письмо с указанием кафедры, на которую хотели бы поступить, и резюме с указанием среднего балла GPA по 5- или 10-балльной шкале.
Подробности о магистратуре можно посмотреть на видео, а о кафедрах ABBYY – прочитать здесь.



