
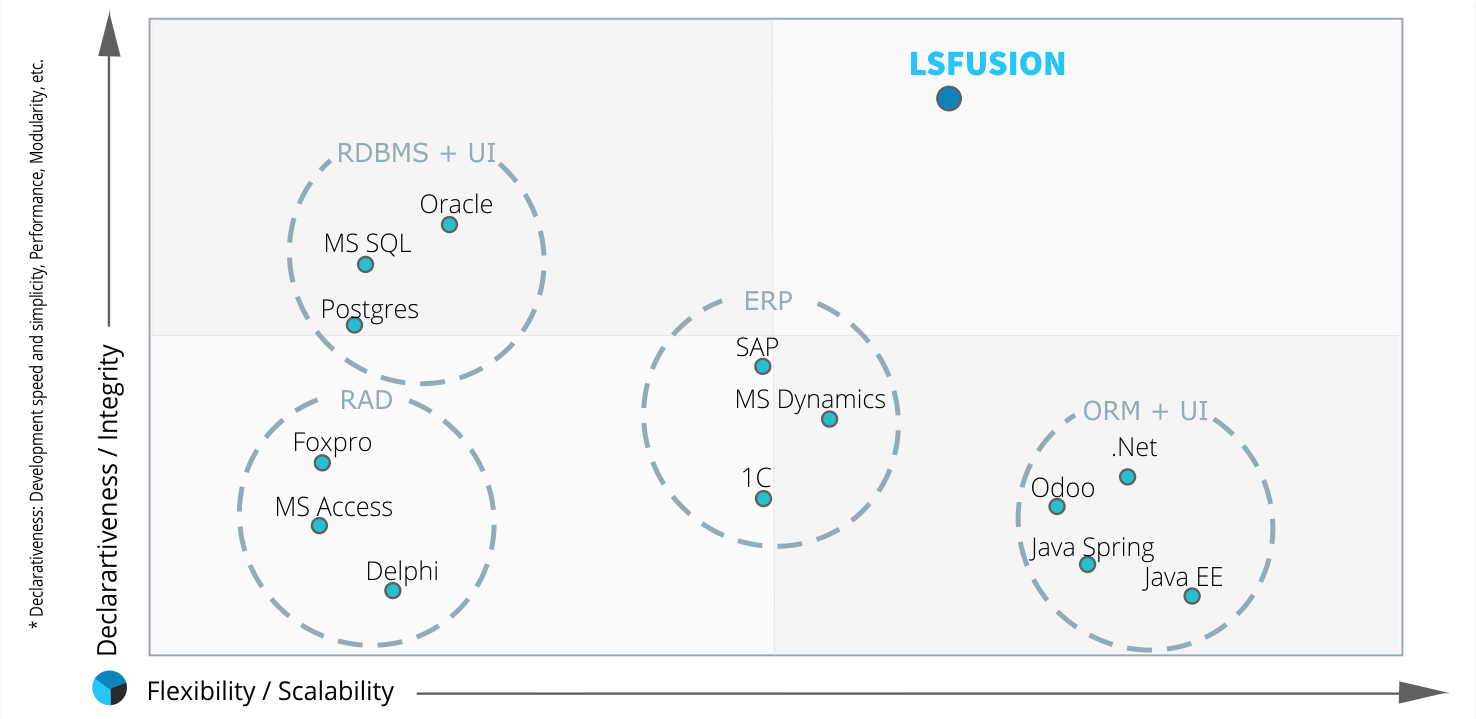
Предыдущая статья “Почему не 1С?” вышла больше года назад и вызвала достаточно живой интерес (совсем немного не дотянула до 100к просмотров и 2к комментариев). Впрочем, как и ожидалось, у многих возник резонный вопрос: “Если не он, то кто?” Безусловно, как многие поняли, та статья писалась не просто так, а чтобы вслед за ней выпустить еще одну, где было бы рассказано, как описанные в первой статье проблемы можно и нужно решать. Однако, по различным причинам, выпуск этой “ответной” статьи был отложен на весьма долгое время. Но, как говорится, лучше поздно, чем никогда.
Как было отмечено в заключении предыдущей статьи, в качестве решения всех описанных проблем предлагается использовать платформу (и одноименный язык) lsFusion. Эта платформа имеет в основе несколько достаточно редких, но при этом наиболее высокодекларативных парадигм программирования: комбинаторное (function-level, не путать с functional), реактивное, событийно-ориентированное, программирование на ограничениях (constraint) и метапрограммирование. Впрочем, для неискушенного читателя это все не более чем набор красивых buzzwords, поэтому не будем уделять много внимания теории, а сразу перейдем на более практический уровень, а именно к решению описанных в предыдущей статье проблем.
Структура этой статьи полностью повторяет структуру статьи «Почему не 1С?» (с теми же названиями разделов и в том же порядке):
- Объекты: Справочники, Документы и т.д.
- Неэффективное получение данных объектов
- Таблицы / Представления: Регистры
- Регистры поддерживаются в очень частных случаях
- Отсутствие ограничений и событий для значений регистров
- В параметрах виртуальных таблиц можно использовать только константы
- Запросы
- Запросы в строках
- Отсутствие оптимизатора запросов
- Отсутствие расширенных SQL возможностей
- Отсутствие запросов на изменение
- Отказ от автоматических блокировок
- Формы
- Отказ от единого потока выполнения: разделение логики на сервер и клиент
- Отказ от синхронности
- Отказ от WYSIWYG: разделение интерфейса на запись и чтение
- Невозможность обращаться в списках к реквизитам форм / текущим значениям других списков
- Избыточные уровни абстракции
- Закрытая физическая модель
- Статичная физическая модель
- Закрытые исходники и лицензии
- Отсутствие наследования и полиморфизма
- Отсутствие явной типизации в коде
- Отсутствие модульности
- Ставка на визуальное программирование
- Фатальный недостаток
- Неуважительные по отношению к разработчикам лицензирование и брендирование
При этом в каждом разделе с названием проблемы в 1С рассказывается, как данная проблема решается в lsFusion.
Объекты: Справочники, Документы и т.д.
В lsFusion основной акцент сделан не на объекты, а на функции и поля (в lsFusion они объединены в одно понятие — свойства). Такой подход позволяет обеспечить прежде всего гораздо более высокую модульность и производительность (об этом в следующих разделах). Впрочем, безусловно, у инкапсуляции тоже есть свои преимущества — например, механизмы копирования и версионирования объектов «из коробки». Правда, при использовании всех такого рода механизмов, существует два нюанса:
- Как правило, все эти механизмы достаточно эвристичны и либо включают лишние данные (например, какую-нибудь сугубо техническую информацию, если она хранится в самом объекте), либо, наоборот, какие-то данные не включают (например, если эти данные хранятся в отдельных таблицах / регистрах, но все равно логически относятся к объекту). Соответственно, эти автоматические механизмы все равно приходится донастраивать вручную, что уничтожает практически все преимущество их «автоматичности».
- Все эти механизмы всегда можно «надстроить» сверху (что в lsFusion уже делается и / или будет сделано в следующих версиях), получив тем самым преимущества обоих подходов.
Неэффективное получение данных объектов
Так как для выполнения логики вычислений lsFusion пытается максимально использовать SQL-сервер, а не сервер приложений (причем делает это максимально группируя запросы, чтобы выполнять их как можно меньше), операции чтения объекта целиком в lsFusion не существует в принципе. Как следствие, и проблема N+1 и проблема избыточного чтения в lsFusion возникают крайне редко. Например следующее действие:
fillSum(Invoice i) { |
fillSum(Invoice i) { |
Таблицы / Представления: Регистры
В lsFusion все те абстракции, которые «намешаны» в регистрах 1С, достаточно четко разделены, что, с одной стороны, дает лучшее понимание того, что происходит «под капотом» (а значит, упрощает оптимизацию производительности), а с другой стороны дает куда большую гибкость. Так, абстракции из регистров отображаются на абстракции lsFusion следующим образом:
- Таблицы — первичные свойства
- Представления — свойства, реализуемые при помощи остальных операторов (впрочем, материализованные свойства можно также рассматривать и как таблицы)
- Работа с моментами / периодами времени — частный случай представлений, свойства, реализуемые при помощи операторов группировки:
- СрезПоследних — GROUP LAST
- Остатки, Обороты — SUM (ОстаткиИОбороты в lsFusion не имеют смысла, так как оптимизатор lsFusion умеет сам объединять подзапросы, если это необходимо)
На тему работы с регистрами в lsFusion была отдельная статья, поэтому подробно останавливаться на этой теме здесь особого смысла нет.
Единственное, что еще хотелось бы отметить. Возможно в lsFusion все же имеет смысл добавить синтаксический сахар по созданию всего этого комбайна из класса регистра, агрегации, а также набора готовых свойств остатков и оборотов. Что-то вроде:
LEDGER Sales GROUP Stock stock, Sku sku SUM NUMERIC quantity, NUMERIC sum; |
Регистры поддерживаются в очень частных случаях
Как уже упоминалось выше, регистры в lsFusion это не один большой комбайн, а несколько разных механизмов, ключевым из которых, пожалуй, является механизм материализаций (запись и автоматическое обновление вычисляемых данных в таблицы).
В отличие от 1С, в lsFusion поддерживается материализация не только суммы и последних по дате значений, но и практически любых вычисляемых данных. Так, в lsFusion можно материализовать:
- Композицию, что, например, позволяет прозрачно денормализовывать данные из разных таблиц (это будет показано в разделе "Статичная физическая модель").
- Максимумы / минимумы / последние значения по любому полю, что позволяет эффективно организовывать нумерацию и ранжирование данных.
- Рекурсию, что, например, позволяет “разворачивать” иерархию в плоские таблицы (с такой же высокой производительностью).
- Выбор (полиморфизм), что позволяет наследовать регистры друг от друга.
- И многие другие
Отсутствие ограничений и событий для значений регистров
lsFusion поддерживает ограничения и события в общем случае, причем, в том числе, для вычисляемых нематериализованных данных. Так, например, для создания ограничения, что остаток (который может вычисляться с использованием любого количества различных данных / операторов) должен быть больше 0, достаточно написать всего одну строку:
CONSTRAINT currentBalance(sku, stock) < 0 MESSAGE 'Остаток не может быть отрицательным'; |
Также, аналогичным образом можно создавать, например, уведомления об изменении любых, в том числе вычисляемых, данных:
WHEN SET(currentBalance(Sku sku, Stock stock) < 0) // когда остаток становится меньше 0 |
В параметрах виртуальных таблиц можно использовать только константы
Опять-таки никаких ограничений на использование параметров в lsFusion нет. Так, если надо обратиться к остатку на дату, можно в качестве даты использовать любые, в том числе вычисляемые, значения. Кроме того, не надо думать, о том чтобы проталкивать условия внешнего контекста внутрь вычисления, lsFusion все это делает автоматически. Так если у нас есть следующее действие:
EXPORT FROM price(Sku sku), balance(date(sku), sku) WHERE name(sku) = 'Колбаса'; |
Запросы
Как уже говорилось выше, lsFusion все вычисления пытается выполнять максимально на SQL сервере (для обеспечения максимальной производительности), таким образом абсолютное большинство абстракций платформы можно скорее отнести к логике запросов, чем к логике процедур. Так, к логике запросов можно отнести всю логику свойств и форм, поэтому проводить аналогии будет правильно именно с этими двумя абстракциями.
Запросы в строках
И логика свойств и логика форм задаются непосредственно на языке lsFusion, соответственно для них:
- в IDE поддерживается полный арсенал разработчика — автоподстановка, подсветка ошибок, синтаксиса, поиск использований и т.п.
- Большинство ошибок обнаруживаются либо на уровне IDE (чаще всего), либо при запуске сервера, что значительно повышает и скорость разработки и надежность разрабатываемых решений.
Тут конечно иногда возникают вопросы с динамическими формируемыми запросами, но как правило они решаются использованием либо соответствующих условных операторов / опций (IF, SHOWIF и т.п.), либо оператора выполнения программного кода (EVAL), позволяющего выполнить любую заданную строку кода на lsFusion.
Отсутствие оптимизатора запросов
В lsFusion внутри очень мощный механизм оптимизации запросов, во многих случаях выполняющий оптимизации, которые не умеют выполнять даже дорогие коммерческие СУБД (не говоря уже о PostgreSQL). Так, все проблемы с производительностью описанные в статье «Почему не SQL», lsFusion умеет решать самостоятельно без каких-либо дополнительных действий со стороны разработчика, который, соответственно, может сконцентрироваться на решении бизнес-задач, а не думать как правильно написать запрос и / или в какую временную таблицу положить его результат.
Так пример из статьи про 1С в lsFusion будет выглядеть следующим образом:
ВЫБРАТЬ
РасходнаяНакладнаяСостав.Номенклатура,
УчетНоменклатурыОстатки.КоличествоОстаток
ИЗ
Документ.РасходнаяНакладная.Состав КАК РасходнаяНакладнаяСостав
ЛЕВОЕ СОЕДИНЕНИЕ РегистрНакопления.УчетНоменклатуры.Остатки(,
Номенклатура В (
ВЫБРАТЬ Номенклатура
ИЗ Документ.РасходнаяНакладная.Состав
ГДЕ Ссылка = &Документ)) КАК УчетНоменклатурыОстатки
ПО УчетНоменклатурыОстатки.Номенклатура = РасходнаяНакладнаяСостав.Номенклатура
ГДЕ
РасходнаяНакладнаяСостав.Ссылка = &Документ И
(УчетНоменклатурыОстатки.КоличествоОстаток < РасходнаяНакладнаяСостав.Количество ИЛИ
УчетНоменклатурыОстатки.КоличествоОстаток ЕСТЬ NULL)currentBalance(InvoiceDetail id) = currentBalance(sku(id)); |
Отсутствие расширенных SQL возможностей
Кроме классического набора операций в SQL-92, состоящего из группировок и композиций (аналог в SQL — соединения), в lsFusion также поддерживаются операции:
- Разбиение / упорядочивание (аналог в SQL — оконные функции)
- Рекурсия (аналог в SQL — рекурсивные CTE)
- Полиморфизм (косвенный аналог в SQL — наследование таблиц)
Причем те же рекурсии в lsFusion поддерживаются в общем случае без каких-либо дополнительных ограничений (вроде невозможности использования GROUP BY в запросе шага).
Отсутствие запросов на изменение
Большинство ERP-платформ хотя формально и поддерживают ORM механизмы, но на практике, из-за плохой производительности, решения на ERP-платформах все равно в абсолютном большинстве случаев используют запросы на SQL-подобных языках.
Впрочем, в том же 1С запросы поддерживаются только для операций чтения данных, для записи все-таки приходится использовать ORM механизмы, производительность которых оставляет желать лучшего. В lsFusion такой проблемы нет, и все операции, в том числе создание объектов, могут выполняться на сервере БД, причем одним запросом. Например:
generateCards() { |
В конечном итоге скомпилируется в один запрос (или несколько, но их количество не будет зависеть от количества данных) и выполнится очень быстро, причем все события / ограничения / агрегации также будут выполнены / проверены / пересчитаны ограниченным числом запросов (опять-таки, не зависящим от количества данных).
Тоже самое касается и механизма изменения / удаления большого количества данных / объектов:
FOR sum(DiscountCard d) > 10000 DO |
sum(DiscountCard d) ← TRUE WHERE sum(d) > 10000; |
Отказ от автоматических блокировок
Проблема блокировок (и вообще целостности данных) была достаточно подробно описана в статье про 1С, поэтому повторяться здесь особого смысла я не вижу. Там же был описан и один из самых простых и эффективных методов ее решения:
- Использовать версионные СУБД (или версионный режим в том же MS SQL).
- Повысить уровень изоляции базы до Repeatable Read или еще лучше до Serializable.
- Материализовать данные, для которых важна целостность.
- Все транзакции с конфликтами записей или дедлоками откатывать и повторять заново.
Именно этот способ решения проблемы используется в lsFusion. Правда, в отличие от того же 1С (как и остальных платформ) в lsFusion:
- поддерживается динамическая физическая модель и прозрачные материализации, что значительно упрощает выполнение третьего пункта (и за него может отвечать даже не разработчик, а администратор),
- обеспечивается транзакционность данных на сервере приложений, что позволяет безболезненно откатывать транзакции в любой момент, что в свою очередь позволяет получить поддержку четвертого пункта «из коробки».
Формы
В lsFusion формы — универсальный механизм, отвечающий за объединение данных вместе и вывод их пользователю / ИС в том или ином виде.
Отказ от единого потока выполнения: разделение логики на сервер и клиент
В отличие от 1С в lsFusion поток выполнения един и для сервера, и для клиента. Такое единство значительно упрощает взаимодействие с пользователем / клиентским устройством с точки зрения процесса разработки. Так, пример в статье про 1С написан именно на языке lsFusion, и, соответственно, выглядит следующим образом:
f() <- someData(); // читаем данные из базы необходимые для myForm |
Тут может возникнуть впечатление, что в lsFusion вообще не существует возможности выполнять заданный код на клиенте (в смысле кроме уже встроенных в платформу операторов/действий). Но это не так, в lsFusion существует специальная опция CLIENT в операторе INTERNAL, которая позволяет выполнить заданный именно на клиенте код. Для десктоп клиента этот код задается на Java, а для веб-клиента — на JavaScript. Правда обычно такая “тонкая настройка” нужна очень редко, поэтому подробно останавливаться на ней здесь особого смысла нет.
Отказ от синхронности
Синхронность в бизнес-приложении важна прежде всего для организации диалоговых процессов (когда от пользователя нужно получить ответ) и для обеспечения “транзакционности” процессов (когда необходимо гарантировать полное, от начала и до конца, выполнение некоторой операции). Проблема синхронности на клиенте прежде всего в однопоточности клиентской среды (например, браузера), и, как мы выяснили в предыдущей статье, в 1С эту проблему просто решили переложить на разработчика (справедливости ради, в последних версиях в платформу вроде начали добавлять async / await, но это лишь частичное решение проблемы).
В lsFusion управление клиентским потоком полностью осуществляется платформой, соответственно платформа сама эмулирует синхронность взаимодействия сервера с клиентом таким образом, чтобы не блокировать поток обработки событий на клиенте, тем самым избегая и блокировки интерфейса, и необходимости открывать еще одно окно браузера.
Отказ от WYSIWYG: разделение интерфейса на запись и чтение
Как было подробно описано в предыдущей статье, у подхода 1С в построении интерфейсов, которые одновременно содержат и первичные и вычисляемые данные (для этого напомню используются динамические списки), есть как минимум 2 проблемы:
- Из-за отсутствия оптимизатора, в динамических списках крайне противопоказано использовать подзапросы / виртуальные таблицы (представления).
- Динамические списки нельзя редактировать.
Как следствие в 1С все интерфейсы по сути строго разделены на интерфейсы чтения и интерфейсы ввода. В lsFusion описанных двух проблем нет, и, как следствие, можно абсолютно декларативно строить максимально эргономичные и привычные пользователю «Excel-style» интерфейсы, вытаскивая на форму одновременно и данные, которые необходимо ввести, и данные, необходимые для принятия решения того, что именно надо вводить. Причем все построенные интерфейсы (как впрочем и остальные абстракции в lsFusion) реактивны «из коробки» — автоматически обновляются при вводе / изменении данных пользователем. Впрочем на эту тему была отдельная статья, поэтому подробно останавливаться на этой теме здесь также не имеет особого смысла.
Невозможность обращаться в списках к реквизитам форм / текущим значениям других списков
В lsFusion при задании свойств, фильтров и других элементов на форме можно обращаться сразу ко всем объектам, даже если они отображаются в разных списках (или других представлениях). При этом платформа сама следит за изменениями объектов (также как и за изменениями данных) и автоматически обновляет данные формы использующие эти объекты. Например, если создать следующую форму:
FORM balance |
Избыточные уровни абстракции
Основным принципом при создании lsFusion был и остается принцип — чистота и завершенность всех создаваемых абстракций. Так:
- За один и тот же функционал в lsFusion отвечает ровно одна абстракция. Если для реализации некоторого функционала можно использовать уже существующие абстракции — их нужно использовать. Такой подход значительно упрощает как изучение платформы разработчиками, так и разработку самой платформой.
- Все абстракции выстроены в уровни (верхние используют нижние) таким образом, что если какая то абстракция разработчика не устраивает, он всегда может спуститься на уровень ниже, тем самым получить большую гибкость (правда при этом выполнив больше работы). Графически такая иерархия выглядит следующим образом:
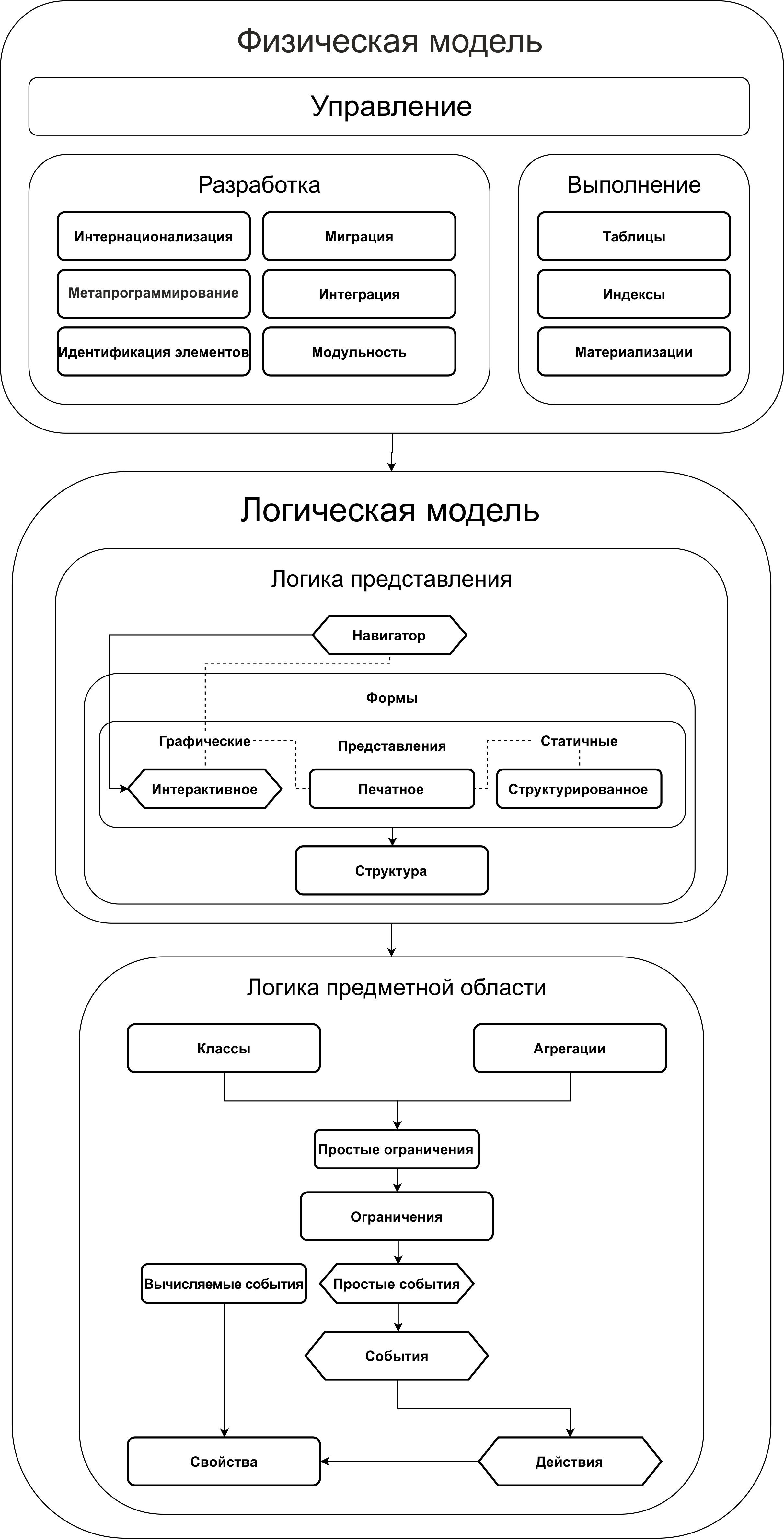
Как следствие, количество абстракций в lsFusion значительно меньше чем в 1С. Соответственно взглянем на абстракции 1С из предыдущей статьи глазами lsFusion:
- Объекты / записи
В lsFusion абстракция таблицы (а значит и записи) есть только на уровне администрирования. Соответственно, так как за группировку различных запросов в один (впрочем как и их написание, оптимизацию и т.п.) отвечает сама платформа, с точки зрения разработчика абстракции «запись» не существует вообще (так как она попросту не нужна).
- Объекты / ссылки на объекты
Тут как я уже упоминал в предыдущей статье, 1С что-то сильно перемудрили на мой взгляд и естественно никаких различий между объектами и ссылками на них в lsFusion нет (и я даже не могу представить, зачем это различие может понадобиться).
- Данные формы / Данные объектов
В lsFusion поддерживается практически абсолютная реактивность на всех уровнях, в том числе на уровне форм. Соответственно необходимости в каких-то дополнительных абстракциях вроде «данных формы» в lsFusion попросту нет. Есть просто данные, и соответственно при любом их изменение платформа автоматически обновляет все представления их использующие. Если же форме нужны какие-то свои локальные данные, разработчик просто создает необходимые локальные первичные свойства, и работает с ними также как и со всеми остальными свойствами (например хранящимися в базе). То есть никаких крышесносящих РеквизитФормыВЗначение в lsFusion нет.
- Запросы / СКД / Аналитика (BI)
Тут все немного сложнее. Запросов, как уже упоминалось в разделе объекты / записи в lsFusion нет (за их формирование и выполнение отвечает сама платформа). Остальной функционал выбора, объединения и отображения данных (не только из этого пункта, а вообще) в lsFusion соответствует следующим механизмам:
- Печатные формы — печатное представление формы, дизайн которого задается при помощи JasperReports, одной из самых распространенных систем отчетности под Java. Позволяет строить pixel-perfect формы, и вообще обладает огромным количеством различных возможностей.
- Встроенная аналитика — одно из представлений списка объектов формы, поддерживает графики, диаграммы, сводные таблицы и многое другое.
- Сложные интерактивные формы с вычисляемыми данными — «обычное» интерактивное представление формы позволяет отображать как первичные, так и вычисляемые данные, а также создавать сразу много списков объектов и связывать их друг с другом «одной строкой кода» (в разделе выше был пример).
- Программный интерфейс работы с данными — структурированное представление формы, позволяет экспортировать (и наоборот импортировать) любую форму в JSON, XML, XLSX, DBF и другие распространенные форматы.
Фактически вся работа с множествами данных в lsFusion сводится к одной единственной абстракции — форме. Соответственно, эту форму можно отображать в различных представлениях, в зависимости от того в каком виде нужно отобразить результат обработки данных. Такое единообразие, не только значительно упрощает изучение платформы разработчиком, но и дает дополнительную гибкость при разработке / поддержке создаваемых решений.
Закрытая физическая модель
В lsFusion отсутствует классическая инкапсуляция, и во многом благодаря этому отображение логики lsFusion на классическую реляционную БД куда более прозрачно и очевидно, чем в остальных платформах / фреймворках (в том числе 1С). Так в lsFusion любое материализованное свойство — это поле таблицы, в которой ключами являются параметры этого свойства. Плюс, для каждого набора классов можно задать таблицу, в которую по умолчанию будут попадать все свойства, классы параметров которых наследуются от данного набора классов (или совпадают). В общем-то все.
Открытая и прозрачная физическая модель дает массу преимуществ:
- Простая и очень производительная интеграция со сторонними инструментами (например BI).
- Возможность использования стандартных средств администрирования БД (например, профайлеров)
- Читабельные запросы в журналах и логах.
Статичная физическая модель
PS: Так как большая часть статьи писалась «на сутках» (есть сейчас такое национальное развлечение в Беларуси) и самой статьи «Почему не 1С?» перед глазами у автора не было, многое писалось по памяти, и, как оказалось, этого и следующего недостатка в предыдущей статье не было вообще. Но, так как эти разделы уже были написаны, мы решили их все же включить в эту статью.
Как уже упоминалось в предыдущем разделе, отображение логики данных в lsFusion на реляционную базу данных прозрачно и может полностью контролироваться разработчиком. Вместе с материализациями в общем случае и индексами разработчик (и даже администратор) может добиться практически любой производительности даже на огромных объемах данных. Причем, так как платформа сама следит за изменениями физической модели и обновляет структуру БД без каких-либо дополнительных миграций, процесс оптимизации производительности может (и должен) выполняться на работающей базе, когда известна статистика и варианты использования этой базы. Так предположим, у нас есть простой пример:
date = DATA DATE (DocumentDetail) |
- JOIN с таблицей товаров, штрихкод в таблице SKU совпадает с заданным;
- подсчет количества строк документов по всем датам больше заданной.
При этом у SQL сервера будет два варианта: либо бежать по индексу по датам в таблице строк, либо бежать по индексу по штрихкодам в таблице товаров, находить товары, после чего бежать по индексу по Sku в таблице строк. В обоих случаях производительность будет оставлять желать лучшего (если движений одного товара очень много и товаров очень много). В lsFusion для решения этой проблемы достаточно изменить / добавить следующие строки:
barcode(DocumentDetail dd) = barcode(sku(d)) MATERIALIZED; // помечает, что |
Закрытые исходники и лицензии
Открытые исходники и лицензия в последнее время стали де-факто стандартом в отрасли средств разработки. Даже Microsoft, известная ранее консервативностью в этом вопросе, открыла исходники .Net, сделала его бесплатным и выпустила версию под Linux.
Наверное, единственная область, которая осталась в стороне от этого тренда — это ERP-платформы, что на мой взгляд, во многом обусловлено как раз фатальным недостатком: разработка всей инфраструктуры с нуля — это очень затратное мероприятие. Соответственно, делать такую платформу открытой и бесплатной может быть экономически необоснованно.
lsFusion выпускается под LGPL v3 лицензией, которая подразумевает свободное использование, распространение и модификацию (за исключением выпуска коммерческой версии платформы), в общем практически все что угодно. Исходники доступны на GitHub. Это обычный Maven-проект, соответственно поддерживаются все стандартные циклы сборки Maven: compile, install, package и т.п. Также открыты исходники сервера сборки, плагина, управление проектами ведётся в GitHub Projects. То есть вся инфраструктура открыта настолько, насколько это возможно.
Отсутствие наследования и полиморфизма
Тут все просто. Наследование и полиморфизм в lsFusion есть. Причем поддерживаются оба этих механизма в общем случае, то есть поддерживается как множественное наследование (когда один класс может наследовать несколько классов), так и множественный полиморфизм (когда реализация выбирается в зависимости от сразу нескольких параметров).
Наследование и полиморфизм очень важны для обеспечения максимально высокой модульности (о которой чуть позже), да и вообще являются одними из самых эффективных инструментов декомпозиции сложных задач, что и обеспечило им такую распространенность (как ключевых частей ООП).
Про то в каком именно виде в lsFusion поддерживаются наследование и полиморфизм уже неоднократно рассказывалось на хабре, как в формате tutorial, так и на конкретных примерах, поэтому повторяться тут не будем.
Отсутствие явной типизации в коде
В lsFusion поддерживаются одновременно и явная и неявная типизация. То есть разработчик может задавать классы параметров (если ему так удобнее), а может не задавать. Впрочем, с учетом количества преимуществ обеспечиваемых явной типизацией в реальных (особенно сложных) проектах неявная типизация на практике используется крайне редко.
Также стоит отметить, что в некоторых правилах класс параметра может не задаваться явно, но при этом он автоматически выводится из семантики правила, и дальше все работает, точно также, как если бы этот класс параметра задавался явно. Например:
invoice (InvoiceDetail id) = DATA Invoice; |
Отсутствие модульности
Несмотря на то, что это вроде всего один маленький пункт, модульность в мире бизнес-приложений является чуть ли не краеугольным камнем любого как типового, так и custom-made решения. Дело в том, что какой крутой не была бы платформа, писать необходимое решение полностью с нуля часто бывает не оправдано чисто экономически. С другой стороны поставлять огромный монолит клиенту целиком несет в себе не меньшие проблемы, как с точки зрения производительности и простоты обучения / использования такого «космолета», так и с точки зрения его дальнейшего сопровождения и доработок под постоянно меняющиеся требования.
В lsFusion модульность выведена на качественно новый уровень. Сделано это прежде всего благодаря следующим механизмам:
- События предметной области (и все то, что на них построено — ограничения и агрегации) — позволяют разбить всю бизнес-логику на множество небольших напрямую независимых друг от друга правил. Эти правила, в свою очередь, автоматически выстраиваются платформой в один большой поток выполнения, в зависимости от того, какие данные эти правила изменяют / используют.
- Расширения — позволяют расширять практически все существующие в платформе абстракции. Такая возможность опять-таки позволяет максимально декомпозировать любую сложную бизнес-логику (например, сложные формы).
- Множественные наследование и полиморфизм — дают все преимущества ООП, основным из которых является все та же декомпозиция (а значит и модульность). Отметим, что полиморфизм в какой-то степени являются частным случаям расширений (то есть они «расширяют» существующее абстрактное свойство / действие, добавлением к нему новых реализаций).
- Отказ от инкапсуляции и акцент на данных, а не объектах (это уже упоминалось в самом первом разделе). Впрочем, тут конечно важно не отсутствие синтаксического сахара в виде this, а то, что классы в lsFusion получаются по сути открытыми, то есть опять-таки «расширяемыми».
- Метапрограммирование — позволяет осуществлять шаблонизацию кода, тем самым значительно уменьшая его дублирование, а значит опять-таки (пусть и косвенно) повышая модульность создаваемых решений
Вообще, если обобщить все вышесказанное, получается, что модульность в lsFusion обеспечивается максимальной ее декларативностью (а точнее антиимперативностью), так как практически вся логика приложения на lsFusion задается в виде отдельных очень компактных не связанных друг с другом правил / элементов, которые платформа при запуске этого приложения сама собирает в единый большой механизм.
Соответственно, большинство «коробочных» решений на lsFusion — это набор из сотен (или даже тысяч) микромодулей, из которых можно выбирать любые подмножества, которые необходимы в конкретном проекте. Причем разрезы можно делать как вертикально (скажем включать в проект модуль Продаж, и не включать модуль Розничной торговли), так и горизонтально (то есть взять только базовую логику из каждого модуля и не включать в проект сложный узкоспециализированный функционал).
Ставка на визуальное программирование
В предыдущей статье были подробно расписаны все недостатки ВП, и скорее всего, именно поэтому подход Everything as code стал золотым стандартом в мире современной разработки. Именно такой подход используется и в lsFusion.
Впрочем, это не означает, что никаких средств визуализации разработки в lsFusion нет вообще. Так, естественно, при проектировании форм есть возможность предварительного просмотра получающегося дизайна формы в текущем модуле (так как этот дизайн зависит от модуля). Кроме того для lsFusion в IDEA поддерживаются все стандартные механизмы визуальной работы с кодом: структура класса, иерархия класса, граф модулей, граф использований свойств и т.п. Но опять-таки, код первичен, а все визуальные средства являются всего лишь альтернативным представлением этого кода.
Фатальный недостаток
Вообще, проблема переписывания всего, что только можно, — это проблема не только 1С, но и многих других ERP-платформ. Обусловлено это, видимо, историческим наследием, и имеет как минимум две проблемы:
- Невозможность использования уже существующей базы знаний.
- Это очень трудозатратно, и получившиеся в итоге компоненты платформы все равно будут значительно уступать компонентам, созданным компаниями, которые специализируются на разработке именно этих компонент.
В lsFusion используется другой подход: если можно использовать что-то готовое, лучше использовать что-то готовое. В крайнем случае использовать что-то с максимально высоким уровнем абстрагирования и сверху достроить то, чего не хватает.
Язык. Тут мы получаем больше всего вопросов в стиле “почему мы не используем какой-нибудь уже существующий язык”. На самом деле мы изначально и пытались использовать Java для задания логики приложения. Но со временем стало очевидно, что в отличие от того же 1С, язык lsFusion фундаментально отличается от всех существующих языков. Он гораздо более декларативный и высокоуровневый, сочетает в себе и логику запросов, и логику процедур, и даже логику представлений. Соответственно преимущества от поддержки своего языка явно начали перевешивать риски того, что на начальном этапе многие разработчики негативно относятся к любым новым языкам. В итоге мы все же решились на свой язык. И на мой взгляд, приняли правильное решение.
Но естественно, поддержка языка lsFusion делалась не с нуля — для создания серверных парсера и лексера в lsFusion используется ANTLR, для того же самого в IDEA используется Grammar-Kit (парсер), JFlex (лексер).
UI. Для реализации десктоп-клиента используется Java SE (Swing, Web Start), что позволило получить поддержку сразу всех ОС, а также обновление и установку клиентского приложения прямо из коробки. Впрочем, как уже говорилось в одной из предыдущих статей, основным клиентом в текущей и следующих версиях будет веб-клиент, поэтому подробно на особенностях реализации десктоп-клиента останавливаться не будем.
Для реализации веб-клиента в lsFusion используется:
GWT — позволяет использовать Java и на сервере(ах), и на клиенте. Плюс, что, наверное, все же более важно, GWT позволяет разрабатывать клиента на типизированном языке с полиморфизмом и наследованием, без чего разработка столь функционального и одновременно быстрого клиента была бы гораздо сложнее. Кроме того GWT имеет достаточно бесшовную интеграцию с JavaScript, и соответственно позволил нам использовать огромное количество существующих JavaScript библиотек
Тут многие могут заметить, что GWT уже полумертв, и сейчас использование того же TypeScript было бы логично. Но:
а) при начале разработки веб-клиента TypeScript ещё только-только появился;
б) разработчик на lsFusion напрямую с GWT не сталкивается, поэтому его наличие в структуре ни на что не влияет, и при необходимости клиентскую часть всегда можно перевести на любую другую технологию.
Но когда-нибудь миграция на TypeScript, я думаю, все же случится.
- Full Calendar, Leaflet — используются для поддержки “нестандартных” представлений списков (календаря и карты).
- Spring Security, MVC, DI — используются для задач аутентификации, управления сессиями, а также инициализации серверов (веб, приложений).
BI — для задач “внутренней” аналитики в lsFusion используется представление “сводная таблица”. Для реализации этого представления используются:
- pivot-table, subtotal — для пользовательской настройки BI, отрисовки таблиц (в том числе с подитогами),
- plotly — для отрисовки графиков и диаграмм,
- tableToExcel — для выгрузки сводных таблиц в Excel (с сохранением форматирования, collapsible рядов и т.п.).
Тут стоит отметить, что первая и третья библиотеки достаточно серьезно доработаны (во всяком случае, первая), но в этом и заключается сила open-source, если что-то в технологии не устраивает — разработчик всегда может сам изменить технологию под свои нужды.
Печатные формы. Для работы с печатными формами в lsFusion используется одна из самых популярных технологий в этой области — JasperReports.
Тут стоит отметить вот какую особенность. В 1С по непонятным причинам технология работы с печатными формами объединена с инструментами аналитики, что, на мой взгляд, достаточно странно, так как:
а) если группировки и колонки постоянно изменяются, дизайн по определению является динамичным и, скажем, уместить его в А4 или просто сделать красивым весьма непросто;
б) аналитические инструменты требуют определенную “ячеистость”, что с другой стороны усложняет построение pixel-perfect печатных форм.
В lsFusion используется другой подход: инструменты аналитики объединены с обычными таблицами (используют те же renderer’ы, стили, события и т. п.), а печатные формы являются отдельным механизмом. Соответственно BI обладает интерактивностью обычных таблиц (переход по ссылке, детализация и т. п.), а печатные формы используются в основном для печати документов и периодичной отчетности (с минимальной кастомизацией).
- IDE. Когда мы начинали разработку плагина для IDE, IDEA ещё не была настолько популярна (Eclipse был существенно популярнее), поэтому выбирая IDEA мы изрядно рисковали. Ирония, но несмотря на меньшее сообщество, найти материал по разработке своего языка под IDEA оказалось проще, да и ее архитектура выглядела существенно более продуманно. Сейчас IDEA (а точнее IntelliJ Platform) практически без сомнения лидер на рынке IDE, обладает огромным количеством возможностей, практически все из которых поддерживаются при работе с lsFusion (либо из коробки, либо благодаря реализации необходимых доработок в lsFusion плагине). Плюс stub index’ы, chameleon element'ы и многое другое позволяет обеспечить высокую производительность практически на любых объемах lsFusion кода (скажем, у меня в агрегированном проекте десятки проектов достаточно высокой сложности с сотнями тысяч строк кода, и все работает очень быстро).
- Система контроля версий. Everything as code позволяет использовать любую из существующих систем контроля версий, самой популярной из которых, безусловно, является Git. Впрочем, на некоторых проектах с непрерывной поставкой без крупных функциональных веток можно спокойно использовать тот же Subversion (что, например, мы и делаем на некоторых проектах).
Система управления зависимости / сборки. Опять таки EaC позволяет использовать существующие системы управления зависимости / сборки в Java, наиболее распространенной из которых является Maven (так центральный репозиторий для lsFusion поддерживается на repo.lsfusion.org).
Чтобы подключить сервер в Maven-проект достаточно в pom.xml добавить следующие строки:
<repositories> <repository> <id>lsfusion</id> <name>lsFusion Public Repository</name> <url>http://repo.lsfusion.org</url> </repository> </repositories>
Что еще важнее, через Maven очень легко подключать сторонние серверные Java библиотеки. Например, если нам надо решить СЛАУ, просто находим соответствующую библиотеку в центральном Maven репозитории, добавляем в pom.xml.
<dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-math3</artifactId> <version>3.2</version> </dependency>
И эту зависимость автоматически подключат и IDE, и сервера сборки.
Сервера приложений и БД. Для работы с серверами БД используется JDBC, при этом все проблемы с производительностью / соответствием спецификации решаются именно родными средствами СУБД. То есть никаких пропатченных версий Postgres не требуется (которых может не быть в центральных репозиториях Docker, yum и т.п.)
Также сервер приложений использует несколько компонент Java Spring, что значительно упростило реализацию процессов инициализации и настройки сервера приложений и сделало эти процессы более стандартизированными.
Неуважительные по отношению к разработчикам лицензирование и брендирование
Как уже упоминалось выше, lsFusion распространяется под лицензией LGPL v3.0, которая позволяет все что угодно, кроме, разве что, создания коммерческой версии lsFusion и ее дальнейшей продажи. Соответственно, для разработчика платформа lsFusion не более чем инструмент для решения его задач, а не манна небесная, на которую он должен молиться и с которой его должны ассоциировать. Как следствие, основной ценностью в экосистеме lsFusion является не платформа как таковая, а решения на этой платформе, и что, возможно даже более важно, компетенции людей / компаний их дорабатывающих, внедряющих и поддерживающих. Почему именно такие акценты актуальны в современном ИТ-мире? Дело в том, что большинство бизнесов сейчас уже «как-то» автоматизировано, и, соответственно, основной вопрос заключается как раз в качестве этой автоматизации — ее глубине, гибкости и соответствии существующим бизнес-процессам. А обеспечение всех этих требований требует как хорошо спроектированных модульных специализированных решений, так и умение быстро и качественно дорабатывать эти решения прямо на лету (так как, как правило, в крупных проектах внедрение сначала идет «as is», а только потом «to be»). Соответственно грести все компании, использующие платформу, под одну гребенку, превращая их во «франчей», в конечном итоге, не выгодно никому:
- ни самим компаниям — так как все компании обезличиваются, а значит нет смысла работать над качеством и маржинальностью, главное чтобы было дешевле. Соответственно все франчи превращаются в «продажников», которым все равно что продавать — запчасти или софт.
- ни их заказчикам — так как в большинстве случаев им приходится работать с пузырем, соломинкой и лаптем
Другое дело, что некий общий каталог решений на lsFusion все равно может быть полезен (опять-таки и людям / компаниям использующим lsFusion, и их заказчикам), и такой каталог безусловно появится (хотя, наверное, все же в среднесрочной перспективе).
Также стоит отметить, что возможности распространять платформу под бесплатной лицензией во многом удалось достичь, благодаря отсутствию фатального недостатка. Как показала практика, затраты на разработку платформы значительно снижаются, когда не надо переписывать огромное количество готовых технологий / библиотек, над которыми, в свою очередь, уже трудятся тысячи и тысячи высококлассных разработчиков.
Ну и еще один важный момент. Как отмечалось выше, качество платформы критично прежде всего либо в крупных проектах (где бизнес-процессы как правило более сложные и уникальные), либо в узкоспециализированных решениях (где сам бизнес достаточно уникальный / редкий). В типовых решениях для малого и среднего бизнеса (особенно не сильно притязательных в плане IT) ценность платформы, как впрочем и самого решения, зачастую не очень высоки, поэтому сама логика рынка подсказывала сделать такие решения такими же бесплатными и открытыми (как сама платформа). Что мы собственно и сделали с решением MyCompany. Более того это решение выпускается даже под более свободной лицензией, чем сама платформа, что дает возможность сторонним разработчикам создавать на его основе свои специализированные решения, и, что еще более важно, дает возможность их продавать, тем самым зарабатывая на лицензиях.
Заключение
Конечно, многие могут сказать, что в бизнес-приложениях платформа — это не главное. Куда важнее уже существующие на этой платформе решения и компании, их внедряющие. Доля правды в этом, безусловно, есть, но все же есть два важных момента:
- В современном мире бизнес-приложений реальный экономический эффект могут дать только очень гибкие решения (быстро меняющиеся вместе с компанией), плюс, обладающие очень высокой глубиной автоматизации / кастомизации. И тут уже платформа выходит на первый план.
- Глобальная цифровизация всех каналов общения привела к тому, что многие, даже очень сложные, проекты разрабатываются и внедряются практически полностью онлайн (с буквально единичными очными встречами с заказчиком, более того, часто у самого заказчика все коммуникации внутри осуществляются исключительно онлайн). Как следствие, необходимость иметь физическое присутствие во всех регионах, где представлен заказчик, если не отпала, то стала гораздо менее острой. Соответственно, уже нет такой большой разницы между существованием 30 или 3000 поставщиков решения, на первый план опять-таки выходят уже другие факторы.
Ну и наконец, хотелось отметить, что это ещё не все. В процессе подготовки и обсуждения первой статьи выяснилось ещё как минимум несколько важных пунктов, где lsFusion если не лучше, то уж точно сильно отличается от 1С и других существующих на рынке ERP-платформ.
Существенный оверхед при работе с «большими» объектами (например документами)
Большие документы (скажем больше, чем на тысячу строк) читаются в память целиком, даже если в них необходимо просмотреть / изменить одну строку.
Ограниченность пользовательских настроек
Пользователь по факту может вытягивать данные только по ссылкам на объекты (то есть из справочников), достать данные из регистров, табличных частей, выполнить какие-то базовые группировки и т. п. пользователь не может. То есть настройка пользователем очень примитивная.
Невозможность одновременной работы с объектами (по аналогии например с Google docs)
Например, когда один документ необходимо редактировать сразу нескольким пользователям (ну или просто не ограничивать пользователей в таком редактировании, если, например, они изменяют абсолютно разные данные).
Неудобная работа с динамическим количеством колонок
А именно в том случае, когда отображение колонок зависит от данных формы (и соответственно количество колонок может изменяться). Еще более непонятно, как это все увязывать с динамическими списками.
Отсутствие мгновенного контроля ссылочной целостности при удалении
В 1С, есть либо мгновенное удаление без контроля ссылочной целостности, либо удаление через пометку удаления с контролем ссылочной целостности. Проблема первого подхода понятна (собственно само отсутствие контроля), а проблема второго подхода заключается в том, что чаще всего именно пользователь, который удаляет объект, ответственен за то, что делать со ссылками на этот объект (то есть заменить ссылку на другой объект или удалить связанные объекты). Соответственно разнося процесс удаления во времени, возникает сразу много вопросов:
- Пользователь может просто забыть, почему удалял тот или иной объект.
- Администратор, который по идее должен выполнять процесс удаления, может быть вообще не в курсе, что делать с возникающими «битыми ссылками» (по сути ему придется искать пользователей, которые удаляли эти объекты и спрашивать у них).
Неочевидные / неэргономичные интерфейсы для выполнения многих базовых действий
Например:
- Настройка группировок — настройка через списки, вместо интуитивных drag-drop интерфейсов.
- Групповое изменение данных — вообще не WYSIWYG операция, а находится где-то в администрировании (часть БСП как я понял).
- Фильтрация — если скажем необходимо отфильтровать все записи с текущим полем > заданного значения (закопана в Еще -> Настроить список, где необходимо найти нужную колонку и сделать еще несколько нажатий).
- Подсчет количества записей, суммы по колонке — честно говоря так и не нашел где это делается (но может просто плохо искал)
Впрочем, этот пункт весьма субъективен и возможно зависит от привычек пользователя (все вышесказанное это мой личный опыт на основе работы с множеством других различных бизнес-приложений).
Невозможность прозрачной подмены представлений списков / свойств
Прозрачно заменить представление в 1С не может:
- ни пользователь — например, просто нажав соответствующую кнопку (как, например, в Odoo или lsFusion)
- ни даже разработчик — декларативно выбрав для отображения данных другой renderer, отличный от таблицы / поля, например, карту, «спидометр» или вообще любую js-функцию (причем так, чтобы обновлением данных продолжала заниматься сама платформа).
Ограниченность ряда абстракций (которые являются частными случаями)
Например, если необходимо:
- организовать табличные части в табличных частях
- реализовать классификатор на дату
- реализовать несколько классификаторов (с выбором их пользователем)
- организовать цепочку статусов документов (а не просто проведен / не проведен)
- и т.п.
Конечно все эти задачи в 1С «как-то» можно решить, но при этом придется отказаться от предлагаемых 1С абстракций / паттернов проектирования, которые в описанных случаях будут не то что помогать, а даже немного мешать.
Соответственно, в ближайшем будущем скорее всего выйдет вторая часть статьи «Почему не 1С», но она с большой вероятностью сразу будет в формате сравнения — как что-то делается в 1С и как это же делается в lsFusion (то есть это будет скорее вторая часть этой статьи, а не предыдущей). Благо, так как у нас в команде появились бывшие 1С-разработчики с большим опытом, писать эту статью будет существенно проще.


