OpenShift 4 предлагает уникальный уровень автоматизации при инсталляции и масштабирования кластеров, обслуживании системы и развертывании обновлений безопасности. Можно сказать, что в плане пользовательского опыта это такой «Kubernetes-кластер как услуга», который обновляется в один клик за счет высокой степени автоматизации, позволяющей масштабировать OpenShift с десятков до сотен кластеров без линейного увеличения численности обслуживающего ИТ-персонала.
Цель этого руководства – помочь администраторам кластеров в планировании обновлений кластерного парка OpenShift и представить лучшие методики автоматизированной эксплуатации OpenShift. Помимо текстовой версии это руководства также доступно в виде вебинара на английском языке на канале OpenShift.tv.
Выпуская новые версии OpenShift, компания Red Hat преследует ту же цель, что и разработчики iOS, Android или браузера Chrome. Все эти программные продукты имеет механизмы постепенного распространения новых версий с целью поддержания качества ПО и работоспособности устройств. В свою очередь, конечные пользователи этих продуктов могут получить ранний доступ за счет бета-версий и выборочно тестировать те или иные новшества, активируя их через флаги.
В каждом релизе OpenShift преследуется следующие цели:
Никаких простоев приложений при выполнении обновления. В приложениях надо использовать все лучшие практики Kubernetes для обеспечения высокой доступности.
Возможность выполнить накат (roll forward) до следующих версий при возникновении любых ошибок. Миграции Kubernetes API не всегда обратимы и варьируются в этом плане от компонента к компоненту. В свою очередь, компоненты OpenShift всегда совместимы вперед и назад в определенном диапазоне версий.
Пауза при любых ошибках блокировки, по возможности, без последствий для кластера. Все компоненты мониторят свою исправность и большинство ошибок не влияют на функциональность, что позволяет администратору устранить причины ошибки или изменить конфигурацию приемлемым образом.
Полный контроль над всем, от ОС до уровня управления кластером (cluster control plane) и кластерных расширений.
Все инсталляции ведут себя одинаково в плане последующей эксплуатации после обновления. И кластеры user-provisioned, и кластеры installer-provisioned обновляются одинаково.
Описывая процессы обновления и релизы OpenShift, мы будем регулярно возвращаться к этим целям в самых разных аспектах. Если вы уяснили эти цели, то дальше, в принципе, можно не читать – у вас все будет отлично с OpenShift при условии, что в своих приложениях вы применяется лучшие практики Kubernetes для приложений высокой доступности. Однако тем, у кого ситуация посложнее и весь бизнес работает на OpenShift, стоит дочитать до конца и получить более глубокое представление.
Каждый релиз OpenShift – это коллекция Операторов
Во-первых, определимся, что мы понимаем под «релизом» (release) OpenShift. OpenShift из коробки включает в себя инструментарий для автоматизации таких процессов, как инициализация (provisioning), управление и масштабирование корпоративных приложений. Этот инструментарий охватывает и написание кода, и сборку ПО, и CI/CD, и логи, и мониторинг, и отладку, и трассировку и многое другое. А вот что он точно не охватывает, так это кластерные сервисы (реестр контейнеров, хранилище, сеть, вход (ingress) и маршрутизация трафика, безопасность и многое другое), которые и делают возможным все то, что перечислено в предыдущем предложении.
Каждый из этих кластерных сервисов реализуется через несколько компонентов, которые должны координировать конфигурации друг с другом, но при этом масштабироваться независимо друг от друга. Обновляться они тоже должны вместе, причем, логика обновления стека мониторинга отличается от логики обновления реестра контейнеров или логики обновления уровня управления Kubernetes.
Для инкапсуляции этих специализированных операционных знаний в OpenShift используется механизм Операторов. Каждый Оператор точно знает, что ему нужно сделать при обновлении, как совместить конфигурацию, которая нужна администратору кластера, с лучшими практиками, и как безопасно активировать новые функции ПО.

Архитектура OpenShift: кластер, платформа и прочие сервисы приложений.
Кроме того, администратор кластера OpenShift может настроить каждый из этих компонентов так, как ему надо, и тогда Оператор объединяет встроенные дефолтные настройки с настройками администратора. Здесь применяется ровно тот же принцип требуемых состояния (desired state), что и везде в Kubernetes. Эта супермощная методология, поскольку кластер постоянно меняется по мере того, как на нем запускаются, останавливаются и масштабируются нагрузки. И все это может спокойно работать во время обновления, поскольку обновление – это всего лишь разновидность конфигурационных изменений.

Список кластерных Операторов и их статусов в консоли OpenShift
На странице настроек в консоли OpenShift можно увидеть полный список Операторов, из которых и состоит каждый релиз OpenShift. Все эти Операторы тестируются и выпускаются одним пакетом, который и образует конкретный релиз OpenShift. Мы еще подробнее остановимся на этом ниже.
Релизы OpenShift выходят каждую неделю и сразу для нескольких версий
Почему расширенная в OpenShift 4 автоматизация так важна? Потому что OpenShift никогда не спит. Потому что он должен парировать сбои в считаные миллисекунды. Потому что при возникновении уязвимости его нужно патчить максимально быстро.
Релизы z-stream
Для каждой поддерживаемой версии OpenShift еженедельно выпускаются текущие обновления безопасности и багфиксы. Мы называем этот канал обновлений «z-stream», отталкиваясь от схемы нумерации версий по шаблону «x.y.z».

Диаграмма типового жизненного цикла OpenShift’овских релизов z-stream
Каждое обновление z-stream конструируется так, чтобы быть максимально безопасным в применении, не менять поведение кластера и не нарушать какие-либо API-контракты. В общем, этот процесс должен быть настолько прозрачным, чтобы автоматические обновления не вызывали никаких возражений ни у кого из наших заказчиков.
Релизы y-stream
Когда вы читаете в нашем блоге или в Твиттере о новых функциях OpenShift, то обычно речь идет о выпуске очередного релиза из разряда y-stream – это так называемый «мажорный релиз», который стоит на уровень выше z-stream. Именно в релизах y-stream появляются такие вещи, как новые версии Kubernetes, новые функции на уровне операционной системы, улучшенная автоматизацию на уровне IaaS-провайдеров и другие расширенные возможности.
Жизненные циклы релизов y-streams строятся с взаимным перекрытием и имеют две фазы. Если какой-то релиз y-stream является последней на текущий момент версией продукта, то именно в его код первым делом вносятся активные разработки и багфиксы (в рамках следующего планового релиза z-stream в этой ветке). Это первая фаза и на диаграмме внизу она обозначена темно-зеленым.
С выпуском нового релиза y-stream, два его непосредственных предшественника переходят в стадию maintenance support, где получают только исправления критических ошибок и обновления безопасности. Это вторая фаза и на диаграмме она светло-зеленая. Программные ошибки, присутствующих сразу в нескольких версиях, как правило, исправляются во всех трех релизах y-stream с активной поддержкой.

Жизненные циклы релизов y-streams строятся с взаимным перекрытием
К чему быть готовым при обновлении OpenShift
Если вам удается достичь обозначенную в начале статьи цель по недопущению простоя приложений и упаковать в Операторы автоматизацию всего что требуется, то процедура обновления сводится к нажатию одной кнопки. И тогда администратору кластер остается только выбрать, когда провести обновление, какую версию OpenShift обновить (если у вас их несколько) и до какой.

Обновление кластера OpenShift из консоли OpenShift
Кластер сам анализирует, до какой версии лучше всего провести обновление и предлагает ее в консоли OpenShift. Это также можно сделать через API на нескольких кластерах или же интегрировать сюда имеющиеся средства автоматизации. Мы в Red Hat осознаем, что это требует довольно высокого доверия со стороны заказчиков, но в целом, наблюдаем, что они охотно и успешно выполняют такие обновления, и они проходят легко и стабильно.
Выше мы говорили, что Операторы, управляющие мониторингом, журналам, реестром и другими функциями системы, работают через механизм требуемых состояний, что позволяет администратору кластера настраивать и управлять этими функциями. Обновление всего кластера тоже работает по принципу требуемых состояний. Когда вы изменяете требуемую версию в консоли, вы просто меняете значение одного поля в объекте Kubernetes. Это выглядит вот так:
$ oc get clusterversion
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS
version 4.6.1 True False 2d21h Cluster version is 4.6.1
$ oc get clusterversion version -o yaml
apiVersion: config.openshift.io/v1
kind: ClusterVersion
metadata:
name: version
spec:
channel: fast-4.6
clusterID: abc-123-abc-123
desiredUpdate:
force: false
image: quay.io/openshift-release-dev/ocp-release@sha256:d78292...c2b9
version: 4.6.1
upstream: https://api.openshift.com/api/upgrades_info/v1/graphОбновление уровня управления (cluster control plane)
Теперь подробнее разберем, что при этом происходит. Первое, OpenShift'овский Оператор CVO (Cluster Version Operator) страхует вас, предлагая для обновления только те версии OpenShift, которые проверены на текущий момент и гарантировано имеют высокое качество. Когда вы решите начать обновление, загружаются новые версии всех Операторов кластера и проверяются их электронные подписи.
Второе, CVO оркестирует необходимые для достижения требуемого состояния изменения для всех Операторов и делает это в определенном порядке, постоянно контролируя исправность. Сначала обновляются уровень управления и etcd, затем ОС и конфигурация узлов, на которых работает сам уровень управления, и, наконец, все оставшиеся Операторы кластера. Обновление уровня управления с тремя узлами (3 Node Control Plane) обычно занимает около часа, с учетом скачивания необходимых контейнеров, реконфигурации компонентов и перезагрузки узлов. Процесс обновления можно в реальном времени отслеживать в консоли OpenShift, а его продолжительность прямо пропорциональна количеству узлов.
Важно отметить, что в течение всего периода обновления сохраняется работоспособность Kubernetes API, базы данных etcd, механизмов кластерной маршрутизации трафика и ingress, поскольку все эти компоненты работают в режиме высокой доступности. После того, как обновления уровня управления будет закончено, соответствующий процесс в консоли помечается как выполненный.
Обновление Worker Node из пула узлов
Узлы Worker Node обновляются только после того, как обновится уровень управления. Это никак не блокирует процесс обновления кластера, поскольку узлы могут приходить и уходить в ходе автомасштабирования, кроме того, есть неподконтрольные кластеру факторы, способные замедлять или даже блокировать развертывание узлов Worker Node.
Но есть, безусловно, и хорошие вещи: PodDisruptionBudgets, правила affinity и anti-affinity, лимиты ресурсов, зонды Readiness и Liveness и другие лучшие практики Kubernetes помогают обеспечить высокую доступность и устойчивость ваших приложений во время обновления кластера.

Операторы кластера обновляются в определенном порядке и в ходе обновления в консоли могут присутствовать сразу несколько версий.
В любом сконфигурированном пуле узлов есть ограничение по максимальному количеству одновременно недоступных машин. Отталкиваясь от этого ограничения, Оператор MCO (Machine Configuration Operator) старается максимально быстро обновить и перезагрузить все узлы Worker Node, используя сигналы от рабочих нагрузок. В этот период pod’ы по мере необходимости переназначаются на другие узлы. Пулы узлов помогают не только настроить определенное железо (например, GPU), но и замедлить или ускорить обновление тех или и иных классов приложений.
Сам процесс сконструирован так, чтобы быстро обновлять узлы по месту, а не уничтожать и создавать их заново, на что уходит больше времени. В результате, удается сократить время простоя, сведя его к тому, насколько быстро машина отработает POST, а не зависеть от медленной загрузки PXE или по сети, или ждать, пока облачный API загрузит новую виртуальную машину. Кроме того, благодаря такому подходу обновление везде работает одинаково, неважно, на какой платформе или облачной IaaS развернут кластер. Как результат, снижается общая сложность системы, а отладка становится проще.
Подключенные кластеры: чем старше, тем умнее
Подключенным мы называем любой кластер OpenShift, который собирает и передает телеметрию в Red Hat. С помощью этой информации мы нарабатываем знания о работе и обновлении огромного парка кластеров OpenShift не только для мониторинга качества и производительности обновления ПО, но и для того, чтобы защитить своих заказчиков от ошибок и неудачных обновлений. Подробнее см. Удаленный мониторинг исправности и Какие сведения Red Hat Insight собирает о ваших кластерах.
Подключенные кластеры OpenShift со временем становятся всё умнее и умнее, и на это есть несколько причин:
Более беспроблемное обновление. Подключенные кластеры могут запросить и получить последний на момент такого запроса, а значит и наиболее оптимальный для себя граф обновления. Время от времени определенные пути обновления (последовательность обновления версий ПО) блокируются на период расследования возникающих инцидентов или исправления найденных ошибок, и тогда подключенные кластеры направляются в обход. Благодаря телеметрии, количество таких заблокированных путей удалось сократить примерно на 50%: в версии 4.2 их было 21, а в версиях 4.4 и 4.5 – уже менее десятка. Понятно, что всё это работает только при наличии подключения к интернету, поэтому ниже мы отдельно остановимся на ситуации, когда кластеры изолированы или ограниченно подключены к интернету.
Более качественные релизы ПО. Red Hat оперативно выявляет проблемы в парке подключенных кластеров (так же, как, например, это делают разработчики iOS или Chrome), и телеметрия ваших кластеров означает, что конкретно ваша комбинация кластерной конфигурации, версий ПО, а также плагинов storage и network может положительно сказаться на качестве ПО в целом и, в конечном счете, сделать процесс обновления более стабильным и безопасным конкретно для вас. Например, при переходе от версии 4.3 к 4.4 и затем к 4.5, количество ошибок, исправленных перед продвижением релиза в stable-канал, сократилось на 75%.
Ускоренная обработка обращений в поддержку. Достигается за счет того, что ваш тикет может автоматически дополняться недостающей информацией, которая подтягивается из вашего подключенного кластера.
Непосредственная проактивная поддержка. Если Red Hat обнаруживает проблему, которая возникает только в очень специфических сочетаниях конфигураций и версий ПО, наша техподдержки может проактивно связаться с вами, чтобы предотвратить катастрофу. В дополнение к таким специфическим проблемам Red Hat также отслеживает такие неполадки, как низкая производительность etcd при записи на диск, проблемы с SDN, деградация стека мониторинга и логов, использование устаревших API, сбои при работе с сертификатами, дрейф времени узлов и многое другое.
Управление подписками. Для кластеров, размер которых меняется динамически, можно автоматизировать управление подписками через OpenShift Cluster Manager, чтобы всегда иметь необходимое количество подписок без лишних телодвижений.
Самый свежий каталог контента. Операторы, диаграммы Helm и другой сертифицированный контент регулярно получает программные исправления и обновления безопасности. Подключенные кластеры могут использовать этот обновленный контент сразу после его выпуска.

Подключенные кластеры получают новейшую версию безопасных путей обновления непосредственно от Red Hat
OpenShift предлагает больше контроля при выборе каналов обновления
При установке или обновлении OpenShift до какой-то версии y-stream надо выбрать, к какому из трех каналов обновления подключается кластер: candidate, fast или stable.
Имя канала | Общедоступные версии (GA) | Описание |
candidate-4.y | Нет | • Лучший вариант для тестирования на совместимость с самыми последними версиями OpenShift. • Может содержать версии без рекомендованных путей обновления. |
fast-4.y | Да | • Самый быстро обновляемый канал. • Рекомендуется использовать хотя бы один продакшн-кластер для отлова проблем, которые могут возникнуть только в вашей конкретной среде. |
stable-4.y | Да | • Самый медленно обновляемый канал. • Версии выпускаются только после достижения хорошей стабильности в канале fast. • Может заметно отставать от канала fast в первые недели после выпуска релиза y-stream. |
Дополнительные сведения по обновления OpenShift и выбору канала приводятся в документации.
Как видно по этой таблице, и канал fast, и канал stable предлагают общедоступные (general availability, GA) и полностью поддерживаемые версии программного продукта, разница лишь в частоте выхода версий. Данные, собираемые со всех каналов (candidate, fast и stable), повышают качество автоматического тестирования Red Hat и помогают выявить и устранить ошибки по мере продвижения релиза по этапам жизненного цикла.
Вначале всё делается в канале fast, и только потом идет в канал stable. Именно поэтому после выпуска очередной мажорной версии OpenShift (иначе говоря, релиза y-stream) в stable-канале может довольно долго не появляться никаких обновлений, поскольку наши инженеры собирают данные и оценивают другие факторы, включая обращения в техподдержку и опыт консультантов Red Hat, работающих с заказчиками.
На рисунке ниже показано, что автоматизированное тестирование применяется на всех стадиях выпуска релизов OpenShift, а также как меняются фидбек-механизмы обратной связи по мере продвижения от предрелизной к пост-релизной стадии.

Процесс выпуска новых версий OpenShift и циклы обратной связи (feedback).
Исправление ошибок и проактивная поддержка на всех этапах
Красные прямоугольники на рисунке выше обозначают три ключевых момента при обнаружении проблем и принятия решений о том, что делать дальше. Главный вопрос, который при этом задают себе инженеры OpenShift звучит так: насколько серьезна обнаруженная проблема и надо ли из-за нее блокировать релиз, или можно исправить ее позже, в следующих релизах z-stream. А теперь разберем это подробно.
Отзыв релиза на этапе финального тестирования. Еще до того, как релиз попадет в какой-либо канал, финальное тестирование может выявить ошибки, критичные настолько, что их обязательно надо исправить, прежде чем давать релизу хоть какой-то шанс попасть в кластеры заказчиков. Это происходит на поздней стадии цикла разработки и блокировка релиза обычно выполняется с помощью внутренних инструментов, связанных с подписанием контейнеров или другими подобными вещами. Именно из-за этого появляются разрывы в номерах версий OpenShift, например, так и не выпущенная версия 4.6.0, поскольку после покидания системы сборки, номер версии не может использоваться повторно.
Блокировка перехода на релиз в канале candidate. В этом канале основной упор делается на выявлении ошибок, возникающих в реальных клиентских средах, поскольку автоматизированное тестирование OpenShift просто не в состоянии покрыть все возможные варианты IaaS-сред и дата-центров, которые могут быть у заказчиков. Поэтому если на этом этапе обнаруживается, что релиз негативно влияет на значительную часть контролируемого парка, то для кластеров блокируется возможность перехода на эту версию.
Блокировка в каналах fast или stable. На пост-релизном этапе (general availability) могут выявляться определенные ошибки или возникать условия, из-за которых переход на определенные версии в одном или обоих указанных каналах может быть заблокирован. Такая блокировка возникает после того, как ошибка была подтверждена или имела место во время расследования.
После попадания релиза в канал fast особое внимание уделяется проблемам, связанным с обновлением OpenShift и общей стабильностью платформы. На этой стадии обновление кластеров впервые выходит на широкий охват контролируемого парка, особенно когда это первый релиз y-stream. Для ошибок, выявляемых на этой стадии, максимально быстро пишутся исправления, которые затем выпускаются в составе последующих релизов z-stream. А граф обновления оперативно обновляется для того, чтобы направить кластеры в обход найденной проблемы.
В свою очередь, при попадании релиза в канал stable фокус смещается на стабильность рабочих нагрузок, поскольку именно stable-версиям предстоит столкнуться с наиболее широким кругом приложений, а почти все часто возникающие проблемы к этому моменту уже отсеяны на предыдущих этапах. Подключенные кластеры здесь особенно полезны для заказчика, поскольку именно они позволяют обнаружить и быстро исправить ошибки, которые возникают на очень небольшом подмножестве кластеров, а то и у вас одного.
Переключение канала обновления как способ перехода на новый релиз y-stream
Чтобы перейти на новый релиз y-stream, достаточно переключить канал обновления. Последующие версии вашего текущего релиза y-stream будут автоматически использовать в вашем кластере выбранный канал.
Естественно, вы можете остаться на том же канале обновления, либо переключиться на другой. Как только вы сделаете выбор, кластер проверит, есть ли путь обновления с вашей текущей версии до одной из версий на новом канале, и активирует кнопку обновления.

Обновление путем переключения канала в консоли OpenShift.
Выше мы уже несколько раз упоминали безопасные пути обновления и возможность запретить кластерам обновляться до определенных релизов. Ниже поговорим об этом подробнее.
Граф обновления обеспечивает надежное и безопасное обновление
Почему вся эта автоматизация отрабатывает безопасно и почему кластеров OpenShift разумно выбирает надежные пути обновления? Потому что все это опирается на БД графов, которая выдает пути обновления через различные версии. И, конечно же, иногда она направляет вас одному пути, а не по другому по вполне определенным причинам.
На рисунке ниже показано, как выглядит граф обновления, но имейте в виду, что он постоянно меняется по мере обнаружения новых ошибок, их исправления или выработки обходных путей.
Взгляните на рисунок ниже: в верхней части собраны версии, с которых можно обновиться, в нижней части – версии, до которых можно обновиться.

Граф обновления, простое представление.
На самом деле, всё устроено несколько сложнее. Как видно на рисунок ниже, от многих версий стрелки идут сразу к нескольким следующим версиям, обозначая пути обновления, которые признаны безопасными по результатам нашего автоматизированного тестирования и с учетом текущей ситуации с ошибками, а также данных по результатам реальных обращений в техподдержку. Но пугаться не стоит – ваш кластер автоматически разберется со всем этим без вас.
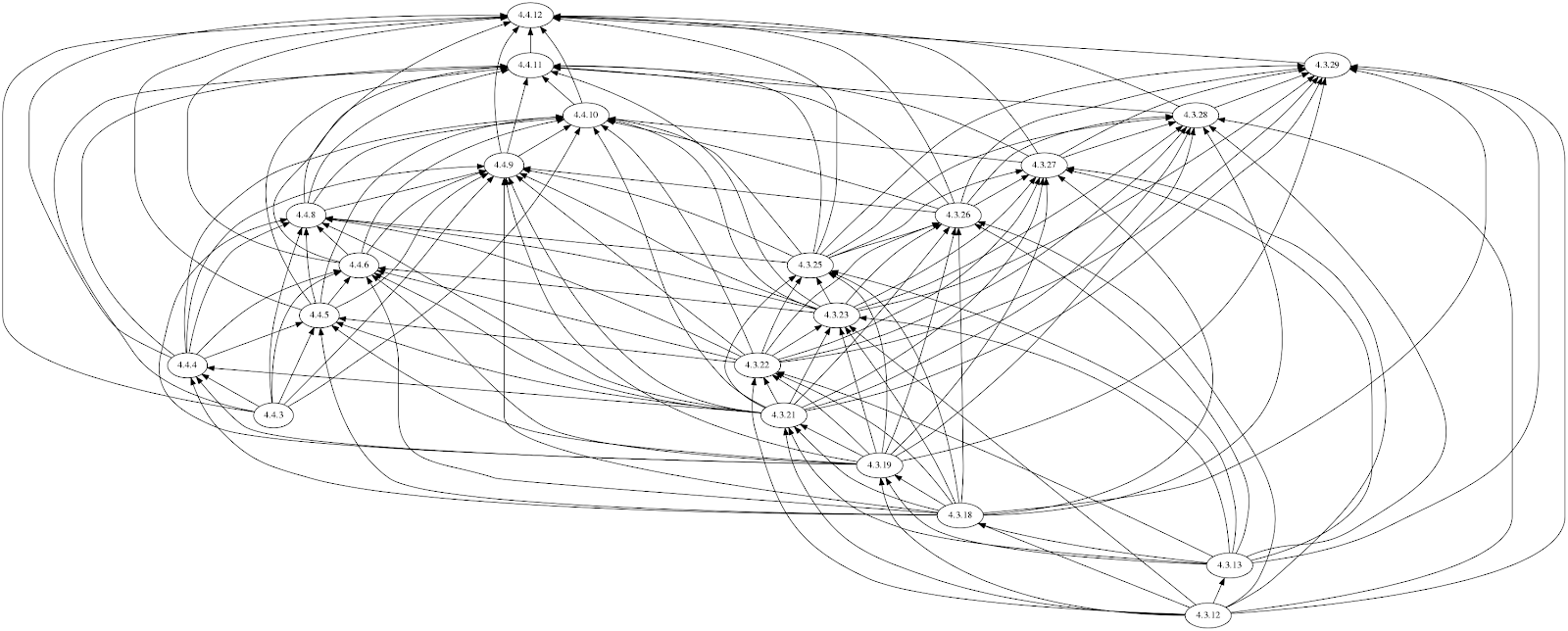
Граф обновления OpenShift с версии 4.3 до версии 4.4, полное представление
Блокировка перехода как проактивный элемент безопасного обновления
Еще один ключевой момент графа обновления – это то, когда и как Red Hat решает изменить его, вводя так называемые «блокировки перехода» (blocking an edge) от одной версии к другой.
Когда Red Hat обнаруживает какую-то проблему с обновлением, то наша первая цель состоит в том, чтобы предотвратить переходы на версию, в которой она возникает, чтобы уберечь остальных. Вторая же цель заключается в том, чтобы устранить эту проблему на кластерах, которые уже успели обновиться до этой злосчастной версии.
Если вам «повезло» обновиться до версии, которую впоследствии заблокировали, то обычно в этом нет никакой опасности. В большинстве случаев, вы даже не будете знать, что такая блокировка возникла, и не столкнетесь ни с какими негативными последствиями, поскольку, скорее всего, причина блокировки пока что просто является предметом расследования и возникает далеко не во всех комбинациях «кластер-платформа-рабочая нагрузка-конфигурация».
Ошибки, ставшие причиной блокировки, обычно исправляются, после чего граф получает новые пути обновления. Кроме того, администратор кластера может принудительно выполнить обновление до заблокированной версии, даже если кластер советует этого не делать. Свяжитесь с технической поддержкой Red Hat или своим TAM-менеджером, чтобы понять, чем такое принудительно обновление может грозить конкретно вашему кластеру.

Как меняется граф обновления при обнаружении проблемы в версии 4.4.11 и ее последующем устранении в версии 4.4.12.
Критерии блокировки переходов
Иногда блокировка может затрагивать только одну версию, а иногда и целый диапазон. Для определения масштабов блокировки используются следующие критерии:
Область поражения – надо ли блокировать переходы и с каких версий на какие?
1. Пример: Заказчик выполняет обновление с версии 4.y.Z до 4.y+1.z, использует Google Cloud Platform, имеет несколько тысяч пространств имен – затронуто примерно 5% от подписного парка.
2. Пример: все заказчики, выполняющие обновление с версии 4.y.z до 4.y+1.z, сталкиваются с проблемой примерно в 10% случаевТяжесть последствий – насколько они серьезны, чтобы блокировать переход.
1. Пример: нарушения в работе edge-маршрутизации на срок до 2 минут.
2. Пример: недоступность API в течение 1,5 минут.
3. Пример: потеря кворума etcd, устраняется только восстановлением из резервной копии.Сложность устранения (даже умеренно серьезные последствия могут быть признаны приемлемыми, если легко устраняются)
1. Пример: проблема исчезла сама собой через 5 минут.
2. Пример: админ может исправить всё с помощью команды oc.
3. Пример: админу придется подключаться к хостам по SSH, восстанавливаться из резервной копии или выполнять другие экстренные действия.Насколько далеко назад простирается проблема (если она была во всех предыдущих версиях, то ее наличие в новой версии ничего не меняет)
1. Пример: Да, это всегда было так, просто мы раньше не замечали.
2. Пример: Да, в версиях 4.y.z – 4.y+1.z или 4.y.z – 4.y.z+1
Неподключенные кластеры: всё то же самое, только под трудоемким контролем администратора
Итак, мы добрались до неподключенных кластеров, то есть кластеров, которые изолированы или ограниченно подключены к интернету. Посмотрим, насколько они отличаются от подключенных кластеров в плане пользовательского опыта.
Для автоматизации перевода кластера OpenShift в требуемое состояние используется модель Операторов, поэтому если загрузить все необходимые контейнеры и метаданные в закрытый контур корпоративной сети, то в плане пользовательского опыта неподключенный кластер ничем не будет отличаться от подключенного.
Поскольку все контейнеры оказываются в закрытом контуре, то здесь уже администратор кластера решает, с каких версий выполнять обновления и до каких. Этот процесс состоит из разбора текущего графа обновления на момент начала зеркалирования, и выяснения того, какие из ошибок, присутствующих в том или ином релизе, релевантны для вашей системы, а какие нет. Так что если у вас есть время на многодневные согласования, инструменты сканирования контейнеров и другие необходимые средства безопасности, то можно подобрать свой, более оптимальный путь обновления.

Процесс обновления в неподключенном кластере.
Кроме того, вам, возможно захочется проанализировать такой фактор, как долгосрочная дорожная карта конфигураций вычислительных ресурсов, сети и хранилищ, используемых в OpenShift, чтобы отложить обновление до тех пор, пока не появится релиз, где будут устранены критичные для вас ошибки или появится новый, важный для работы ваших приложений функционал.
В ближайшем будущем мы предоставим заказчикам возможность полноценно использовать OpenShift Update Service внутри закрытого контура с возможностью настройки графа, что значительно снизит трудоемкость обновления десятков или сотен неподключенных кластеров.
Точки сужения и пропуск релизов
Теперь, когда мы изучили процесс выпуска обновлений OpenShift во всех аспектах, посмотрим, как некоторые из этих аспектов комбинируются и проявляются на практике. Если мониторить обновление кластеров OpenShift, отчетливо видно, что несмотря на еженедельный выпуск релизов z-stream и багфиксов, граф обновления ведет себя между выходами мажорных версий (релизов y-stream) одним и тем же образом и имеет характерные точки сужения.
В начале жизненного цикла первые несколько релизов z-stream идут последовательно, а затем начинают расширяться, создавая всё больше ветвей и расползаясь по кластерам по мере того, как народ в течение нескольких недель обновляет свои кластеры. На рисунке ниже этому этапу соответствует та часть ромба, где он начинает расширяться.
К середине жизненного цикла, который примерно приходится на момент появления следующего мажорного релиза (y-stream), пути обновления начинают сжиматься, поскольку ошибки мало-помалу исправляются и граф становится все более проработанным за счет фидбека от подключенных кластеров. На рисунке ниже этому этапу соответствует середина ромба.
Затем, по мере приближения к следующему мажорному релизу, пути обновления становятся все уже и уже, вплоть до того, что остаются только две конкретные версии, чтобы обеспечить тщательно протестированный и безопасный путь обновления с одного релиза y-stream на другой. По мере обработки фидбека от таких обновлений и перехода релизов из канала fast в канал stable количество путей начнет увеличиваться.

Характерная картина периодического изменения графа обновления.
Как уже говорилось выше, это упрощенная версия, а на самом деле логика обновления кластера обрабатывает очень сложный граф. На рисунке ниже видно, что переход непосредственно на 28-й релиз OpenShift 4.3 можно выполнить с большинства предыдущих релизов, что делает его идеальной отправной точкой для обновления до следующей мажорной версии, OpenShift 4.4.
Граф обновления сходится к единственной версии z-stream при переходе к следующей мажорной версии OpenShift.
Пропуск мажорной версии
У большинства читателей это руководства, вероятно, остается последний вопрос: «А можно полностью пропустить мажорную версию (релиз y-stream)?"
Прямо сейчас ответ будет «нет». Да, граф обновления в принципе может заоркестрировать такой вариант, и мы надеемся, что в будущем его удастся реализовать. Но на сегодняшний день в upstream-версиях Kubernetes для этого слишком много системных изменений.
В частности, речь идет о переводе многих API из стадии beta в разряд stable для соответствия обновленному руководству по маркировке API, о миграции дисков хранилища из внутреннего облака (in-tree) во внешнее (out-of-tree), а также о целом ряде более мелких и специфических изменений, которые Red Hat отслеживает в upstream-версии как член special interest group. OpenShift безусловно будет оркестрировать эти миграции, но для того, чтобы реализовать их с сохранением полной работоспособности клиентских кластеров и приложений требуются чрезвычайно инвазивные изменения. Попытка добавить сюда пропуск мажорного релиза Kubernetes – это пока что перебор.
Автоматизированное обновление OpenShift – попробуйте сами
Отправьте коллегам ссылку на это руководство или его видеоверсию на канале OpenShift.tv. И поскольку лучше всего знания приобретаются на практике, заходите на https://openshift.com/try, загружайте предыдущую версию OpenShift, развертывайте ее в облаке любого провайдера IaaS или в своем дата-центре и пробуйте обновить OpenShift своими руками!



