
Привет, Хабр! Представляю вашему вниманию перевод статьи «Diving Into Delta Lake: Schema Enforcement & Evolution» авторов Burak Yavuz, Brenner Heintz and Denny Lee.

Данные, как и наш опыт, постоянно накапливаются и развиваются. Чтобы не отставать, наши ментальные модели мира должны адаптироваться к новым данным, некоторые из которых содержат новые измерения — новые способы наблюдать вещи, о которых раньше мы не имели представления. Эти ментальные модели мало чем отличаются от схем таблиц, определяющих, как мы классифицируем и обрабатываем новую информацию.
Это подводит нас к вопросу управления схемами. По мере того, как бизнес задачи и требования меняются со временем, меняется и структура ваших данных. Delta Lake позволяет легко внедрять новые измерения при изменении данных. Пользователи имеют доступ к простой семантике для управления схемами своих таблиц. Эти инструменты включают принудительное применение схемы (Schema Enforcement), которое защищает пользователей от непреднамеренного засорения своих таблиц ошибками или ненужными данными, а также эволюцию схемы (Schema Evolution), которая позволяет автоматически добавлять новые столбцы с ценными данными в соответствующие места. В этой статье мы углубимся в использование этих инструментов.
Каждый DataFrame в Apache Spark содержит схему, которая определяет форму данных, такую как типы данных, столбцы и метаданные. С помощью Delta Lake схема таблицы сохраняется в формате JSON внутри журнала транзакций.
Принудительное применение схемы (Schema Enforcement), также известное как проверка схемы (Schema Validation), является защитным механизмом в Delta Lake, который гарантирует качество данных, отклоняя записи, которые не соответствуют схеме таблицы. Как и хостес на стойке регистрации в популярном ресторане, который принимает только по предварительной брони, он проверяет, есть ли каждый столбец данных, вводимых в таблицу, в соответствующем списке ожидаемых столбцов (другими словами, есть ли для каждого из них «бронь»), и отклоняет любые записи со столбцами, которых нет в списке.
Delta Lake использует проверку схемы при записи, что означает, что все новые записи в таблицу проверяются на совместимость со схемой целевой таблицы во время записи. Если схема несовместима, Delta Lake полностью отменяет транзакцию (данные не записываются) и создает исключение, чтобы сообщить пользователю о несоответствии.
Для определения совместимости записи с таблицей Delta Lake использует следующие правила. Записываемый DataFrame:
Чтобы проиллюстрировать это, давайте взглянем на то, что происходит в приведенном ниже коде при попытке добавить некоторые недавно сгенерированные столбцы в таблицу Delta Lake, которая еще не настроена для их принятия.
Вместо автоматического добавления новых столбцов, Delta Lake навязывает схему и останавливает запись. Чтобы помочь определить какой столбец (или их множество) является причиной несоответствия, Spark выводит обе схемы из стек трейса для сравнения.
Поскольку принудительное применение схемы представляет из себя достаточно строгую проверку, оно является отличным инструментом для использования в качестве привратника чистого, полностью преобразованного набора данных, который готов к производству или потреблению. Как правило, применяется к таблицам, которые непосредственно подают данные:
Чтобы подготовить свои данные к этому финальному барьеру, многие пользователи используют простую “multi-hop” архитектуру, которая постепенно вносит структуру в их таблицы. Чтобы узнать об этом больше, вы можете ознакомиться со статьей Машинное обучение производственного уровня с Delta Lake.
Конечно, принудительное применение схемы можно использовать в любом месте вашего пайплайна, но помните, что потоковая запись в таблицу в таком случае может быть фрустрирующей, из-за того что, например, вы забыли, что добавили еще один столбец во входящие данные.
К этому момент вы можете задаться вопросом, из-за чего такой ажиотаж? В конце концов, иногда неожиданная ошибка «несоответствия схемы» может подставить вам подножку в вашем рабочем процессе, особенно если вы новичок в Delta Lake. Почему бы просто не позволить схеме измениться так, как нужно для того, чтобы я мог записать свой DataFrame, несмотря ни на что?
Как гласит старая поговорка, «унция профилактики стоит фунта лечения». В какой-то момент, если вы не позаботитесь о применении своей схемы, поднимут свои отвратительные головы проблемы с совместимостью типов данных — на первый взгляд однородные источники необработанных данных могут содержать пограничные случаи, поврежденные столбцы, неправильно сформированные отображения или другие страшные вещи, которые снятся в кошмарах. Лучший подход состоит в том, чтобы останавливать этих врагов у ворот — с помощью принудительного применения схемы — и иметь дело с ними на свету, а не позже, когда они начнут рыскать в темных глубинах вашего рабочего кода.
Принудительное применение схемы дает уверенность в том, что схема вашей таблицы не изменится, если только вы сами не подтвердите вариант изменения. Это предотвращает «разжижение» (dilution) данных, которое может происходить, когда новые столбцы добавляются так часто, что ранее ценные, сжатые таблицы теряют свое значение и полезность из-за наводнения данными. Поощряя вас быть преднамеренным, устанавливать высокие стандарты и ожидать высокого качества, принудительное применение схемы делает именно то, для чего было предназначено — помогать вам оставаться добросовестными, а вашим таблицам — чистыми.
Если при дальнейшем рассмотрении вы решите, что вам на самом деле нужно добавить новый столбец — никаких проблем, ниже приведен однострочный фикс. Решение — эволюция схемы!
Эволюция схемы — это функция, которая позволяет пользователям легко изменять текущую схему таблицы в соответствии с данными, которые меняются с течением времени. Чаще всего она используется при выполнении операции добавления или перезаписи, чтобы автоматически адаптировать схему для включения одного или нескольких новых столбцов.
Следуя примеру из предыдущего раздела, разработчики могут легко использовать эволюцию схемы для добавления новых столбцов, которые ранее были отклонены из-за несоответствия схеме. Эволюция схемы активируется путем добавления
Для просмотра графика выполните следующую Spark SQL запрос
В качестве альтернативы, вы можете установить эту опцию для всей сессии Spark, добавив
Включив в запрос параметр
Дата инженеры и ученые могут использовать эту опцию, чтобы добавить новые столбцы (возможно, недавно отслеживаемую метрику или столбец показателей продаж в этом месяце) в свои существующие производственные таблицы машинного обучения, не нарушая существующие модели, основанные на старых столбцах.
Следующие типы изменений схемы допустимы в рамках эволюцию схемы во время добавления или перезаписи таблицы:
Другие изменения, недопустимые в рамках эволюции схемы, требуют, чтобы схема и данные были перезаписаны путем добавления
Наконец, со следующим релизом Spark 3.0 будет полностью поддерживаться явный DDL (с использованием ALTER TABLE), что позволит пользователям выполнять следующие действия над схемами таблиц:
Эволюцию схемы можно использовать всегда, когда вы намереваетесь изменить схему своей таблицы (в противовес тем случаям, когда вы случайно добавили в свой DataFrame столбцы, которых там быть не должно). Это самый простой способ мигрировать вашу схему, потому что он автоматически добавляет правильные имена столбцов и типы данных без необходимости их явного объявления.
Принудительное применение схемы отклоняет любые новые столбцы или другие изменения схемы, которые не совместимы с вашей таблицей. Устанавливая и поддерживая эти высокие стандарты, аналитики и инженеры могут полагаться на то, что их данные имеют высочайший уровень целостности, рассуждая об этом четко и ясно, что позволяет им принимать более эффективные бизнес-решения.
С другой стороны, эволюция схемы дополняет принудительное применение, упрощая предполагаемые автоматические изменений схемы. В конце концов, это не должно быть сложностью — добавить столбец.
Принудительное применение схемы — это янь, где эволюции схемы — это инь. При совместном использовании эти функции как никогда упрощают подавление шума и настройку сигнала.
Мы также хотели бы поблагодарить Мукула Мурти и Пранава Ананда за их вклад в эту статью.
Другие статьи из этой серии:
Погружение в Delta Lake: распаковка журнала транзакций
Машинное обучение производственного уровня с Delta Lake
Что такое озеро данных?
Данные, как и наш опыт, постоянно накапливаются и развиваются. Чтобы не отставать, наши ментальные модели мира должны адаптироваться к новым данным, некоторые из которых содержат новые измерения — новые способы наблюдать вещи, о которых раньше мы не имели представления. Эти ментальные модели мало чем отличаются от схем таблиц, определяющих, как мы классифицируем и обрабатываем новую информацию.
Это подводит нас к вопросу управления схемами. По мере того, как бизнес задачи и требования меняются со временем, меняется и структура ваших данных. Delta Lake позволяет легко внедрять новые измерения при изменении данных. Пользователи имеют доступ к простой семантике для управления схемами своих таблиц. Эти инструменты включают принудительное применение схемы (Schema Enforcement), которое защищает пользователей от непреднамеренного засорения своих таблиц ошибками или ненужными данными, а также эволюцию схемы (Schema Evolution), которая позволяет автоматически добавлять новые столбцы с ценными данными в соответствующие места. В этой статье мы углубимся в использование этих инструментов.
Понимание схем таблиц
Каждый DataFrame в Apache Spark содержит схему, которая определяет форму данных, такую как типы данных, столбцы и метаданные. С помощью Delta Lake схема таблицы сохраняется в формате JSON внутри журнала транзакций.
Что такое принудительное применение схемы?
Принудительное применение схемы (Schema Enforcement), также известное как проверка схемы (Schema Validation), является защитным механизмом в Delta Lake, который гарантирует качество данных, отклоняя записи, которые не соответствуют схеме таблицы. Как и хостес на стойке регистрации в популярном ресторане, который принимает только по предварительной брони, он проверяет, есть ли каждый столбец данных, вводимых в таблицу, в соответствующем списке ожидаемых столбцов (другими словами, есть ли для каждого из них «бронь»), и отклоняет любые записи со столбцами, которых нет в списке.
Как работает принудительное применение схемы?
Delta Lake использует проверку схемы при записи, что означает, что все новые записи в таблицу проверяются на совместимость со схемой целевой таблицы во время записи. Если схема несовместима, Delta Lake полностью отменяет транзакцию (данные не записываются) и создает исключение, чтобы сообщить пользователю о несоответствии.
Для определения совместимости записи с таблицей Delta Lake использует следующие правила. Записываемый DataFrame:
- не может содержать дополнительные столбцы, которых нет в схеме целевой таблицы. И наоборот, все в порядке, если входящие данные не содержат абсолютно все столбцы из таблицы — этим столбцам просто будут присвоены нулевые значения.
- не может иметь типы данных столбцов, которые отличаются от типов данных столбцов в целевой таблице. Если столбец целевой таблицы содержит данные StringType, но соответствующий столбец в DataFrame содержит данные IntegerType, принудительное применение схемы вызовет исключение и предотвратит выполнение операции записи.
- не может содержать имена столбцов, которые отличаются только регистром. Это значит, что вы не можете иметь столбцы с именами 'Foo' и 'foo', определенные в одной таблице. Хотя Spark можно использовать в чувствительном или нечувствительном (по умолчанию) к регистру режиме, Delta Lake сохраняет регистр, но нечувствителен в рамках хранении схемы. Parquet чувствителен к регистру при хранении и возврате информации столбца. Чтобы избежать возможных ошибок, повреждения данных или их потери (с чем мы лично сталкивались в Databricks), мы решили добавить это ограничение.
Чтобы проиллюстрировать это, давайте взглянем на то, что происходит в приведенном ниже коде при попытке добавить некоторые недавно сгенерированные столбцы в таблицу Delta Lake, которая еще не настроена для их принятия.
# Сгенерируем DataFrame ссуд, который мы добавим в нашу таблицу Delta Lake
loans = sql("""
SELECT addr_state, CAST(rand(10)*count as bigint) AS count,
CAST(rand(10) * 10000 * count AS double) AS amount
FROM loan_by_state_delta
""")
# Вывести исходную схему DataFrame
original_loans.printSchema()
root
|-- addr_state: string (nullable = true)
|-- count: integer (nullable = true)
# Вывести новую схему DataFrame
loans.printSchema()
root
|-- addr_state: string (nullable = true)
|-- count: integer (nullable = true)
|-- amount: double (nullable = true) # new column
# Попытка добавить новый DataFrame (с новым столбцом) в существующую таблицу
loans.write.format("delta") \
.mode("append") \
.save(DELTALAKE_PATH)
Returns:
A schema mismatch detected when writing to the Delta table.
To enable schema migration, please set:
'.option("mergeSchema", "true")\'
Table schema:
root
-- addr_state: string (nullable = true)
-- count: long (nullable = true)
Data schema:
root
-- addr_state: string (nullable = true)
-- count: long (nullable = true)
-- amount: double (nullable = true)
If Table ACLs are enabled, these options will be ignored. Please use the ALTER TABLE command for changing the schema.Вместо автоматического добавления новых столбцов, Delta Lake навязывает схему и останавливает запись. Чтобы помочь определить какой столбец (или их множество) является причиной несоответствия, Spark выводит обе схемы из стек трейса для сравнения.
В чем польза принудительного применения схемы?
Поскольку принудительное применение схемы представляет из себя достаточно строгую проверку, оно является отличным инструментом для использования в качестве привратника чистого, полностью преобразованного набора данных, который готов к производству или потреблению. Как правило, применяется к таблицам, которые непосредственно подают данные:
- Алгоритмам машинного обучения
- BI дашбордам
- Аналитике данных и инструментам визуализации
- Любой производственной системе, требующей строго структурированных, строго типизированных семантических схем.
Чтобы подготовить свои данные к этому финальному барьеру, многие пользователи используют простую “multi-hop” архитектуру, которая постепенно вносит структуру в их таблицы. Чтобы узнать об этом больше, вы можете ознакомиться со статьей Машинное обучение производственного уровня с Delta Lake.
Конечно, принудительное применение схемы можно использовать в любом месте вашего пайплайна, но помните, что потоковая запись в таблицу в таком случае может быть фрустрирующей, из-за того что, например, вы забыли, что добавили еще один столбец во входящие данные.
Предотвращение разжижения данных
К этому момент вы можете задаться вопросом, из-за чего такой ажиотаж? В конце концов, иногда неожиданная ошибка «несоответствия схемы» может подставить вам подножку в вашем рабочем процессе, особенно если вы новичок в Delta Lake. Почему бы просто не позволить схеме измениться так, как нужно для того, чтобы я мог записать свой DataFrame, несмотря ни на что?
Как гласит старая поговорка, «унция профилактики стоит фунта лечения». В какой-то момент, если вы не позаботитесь о применении своей схемы, поднимут свои отвратительные головы проблемы с совместимостью типов данных — на первый взгляд однородные источники необработанных данных могут содержать пограничные случаи, поврежденные столбцы, неправильно сформированные отображения или другие страшные вещи, которые снятся в кошмарах. Лучший подход состоит в том, чтобы останавливать этих врагов у ворот — с помощью принудительного применения схемы — и иметь дело с ними на свету, а не позже, когда они начнут рыскать в темных глубинах вашего рабочего кода.
Принудительное применение схемы дает уверенность в том, что схема вашей таблицы не изменится, если только вы сами не подтвердите вариант изменения. Это предотвращает «разжижение» (dilution) данных, которое может происходить, когда новые столбцы добавляются так часто, что ранее ценные, сжатые таблицы теряют свое значение и полезность из-за наводнения данными. Поощряя вас быть преднамеренным, устанавливать высокие стандарты и ожидать высокого качества, принудительное применение схемы делает именно то, для чего было предназначено — помогать вам оставаться добросовестными, а вашим таблицам — чистыми.
Если при дальнейшем рассмотрении вы решите, что вам на самом деле нужно добавить новый столбец — никаких проблем, ниже приведен однострочный фикс. Решение — эволюция схемы!
Что такое эволюция схемы?
Эволюция схемы — это функция, которая позволяет пользователям легко изменять текущую схему таблицы в соответствии с данными, которые меняются с течением времени. Чаще всего она используется при выполнении операции добавления или перезаписи, чтобы автоматически адаптировать схему для включения одного или нескольких новых столбцов.
Как работает эволюция схемы?
Следуя примеру из предыдущего раздела, разработчики могут легко использовать эволюцию схемы для добавления новых столбцов, которые ранее были отклонены из-за несоответствия схеме. Эволюция схемы активируется путем добавления
.option('mergeSchema', 'true') к вашей Spark команде .write или .writeStream.# Добавьте параметр mergeSchema
loans.write.format("delta") \
.option("mergeSchema", "true") \
.mode("append") \
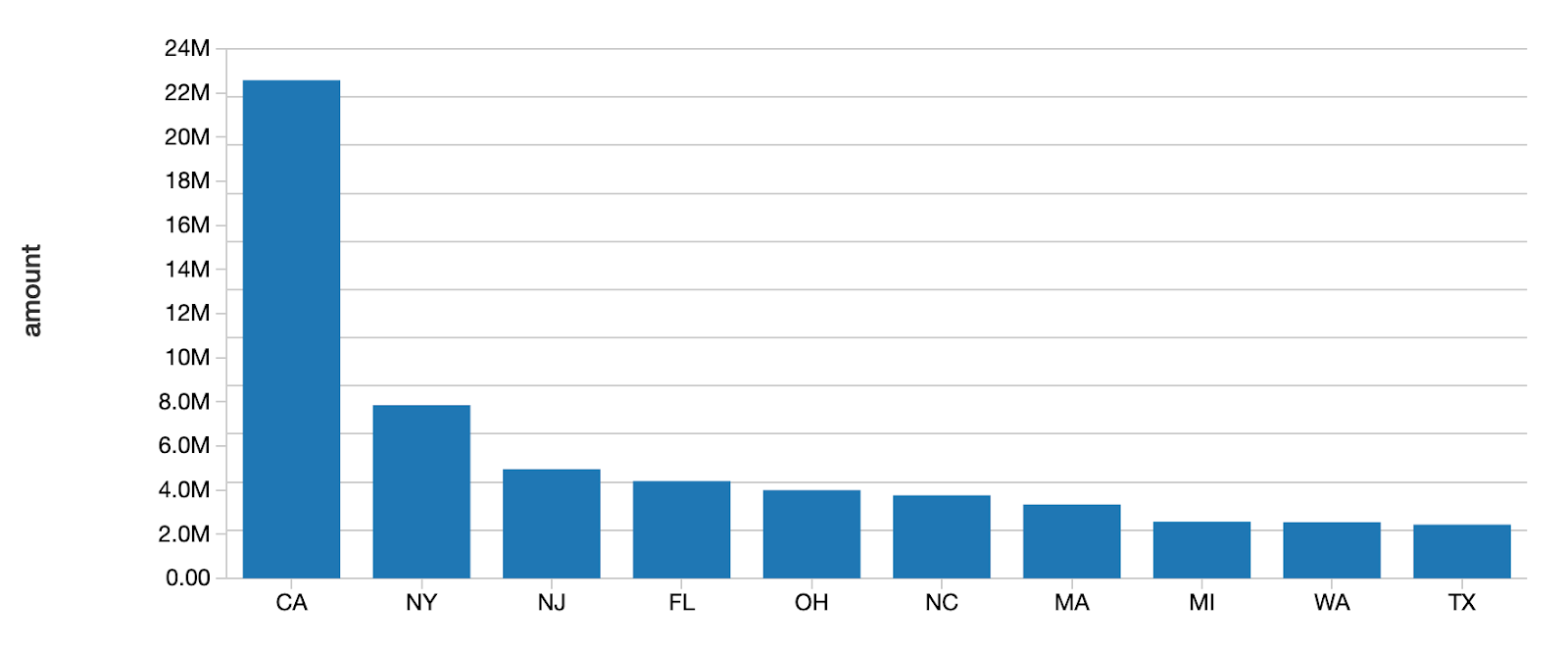
.save(DELTALAKE_SILVER_PATH)Для просмотра графика выполните следующую Spark SQL запрос
# Создайте график с новым столбцом, чтобы подтвердить, что запись прошла успешно
%sql
SELECT addr_state, sum(`amount`) AS amount
FROM loan_by_state_delta
GROUP BY addr_state
ORDER BY sum(`amount`)
DESC LIMIT 10В качестве альтернативы, вы можете установить эту опцию для всей сессии Spark, добавив
spark.databricks.delta.schema.autoMerge = True в конфигурацию Spark. Но пользуйтесь этим с осторожностью, поскольку принудительное применение схемы больше не будет предупреждать вас о непреднамеренных несоответствиях схеме.Включив в запрос параметр
mergeSchema, все столбцы, которые присутствуют в DataFrame, но отсутствуют в целевой таблице, автоматически добавляются в конец схемы в рамках транзакции записи. Также могут быть добавлены вложенные поля, и они также будут добавлены в конец соответствующих столбцов структуры.Дата инженеры и ученые могут использовать эту опцию, чтобы добавить новые столбцы (возможно, недавно отслеживаемую метрику или столбец показателей продаж в этом месяце) в свои существующие производственные таблицы машинного обучения, не нарушая существующие модели, основанные на старых столбцах.
Следующие типы изменений схемы допустимы в рамках эволюцию схемы во время добавления или перезаписи таблицы:
- Добавление новых столбцов (это наиболее распространенный сценарий)
- Изменение типов данных из NullType -> любой другой тип или повышение из ByteType -> ShortType -> IntegerType
Другие изменения, недопустимые в рамках эволюции схемы, требуют, чтобы схема и данные были перезаписаны путем добавления
.option("overwriteSchema", "true"). Например, в случае, когда столбец «Foo» изначально был integer, а новая схема была бы строкового типа данных, тогда все файлы Parquet (data) необходимо было бы перезаписать. К таким изменениям относятся:- удаление столбца
- изменение типа данных существующего столбца (на месте)
- переименование столбцов, которые отличаются только регистром (например, «Foo» и «foo»)
Наконец, со следующим релизом Spark 3.0 будет полностью поддерживаться явный DDL (с использованием ALTER TABLE), что позволит пользователям выполнять следующие действия над схемами таблиц:
- добавление столбцов
- изменение комментариев к столбцам
- настройка свойств таблицы, определяющих поведение таблицы, например, установка продолжительности хранения журнала транзакций.
В чем польза эволюция схемы?
Эволюцию схемы можно использовать всегда, когда вы намереваетесь изменить схему своей таблицы (в противовес тем случаям, когда вы случайно добавили в свой DataFrame столбцы, которых там быть не должно). Это самый простой способ мигрировать вашу схему, потому что он автоматически добавляет правильные имена столбцов и типы данных без необходимости их явного объявления.
Заключение
Принудительное применение схемы отклоняет любые новые столбцы или другие изменения схемы, которые не совместимы с вашей таблицей. Устанавливая и поддерживая эти высокие стандарты, аналитики и инженеры могут полагаться на то, что их данные имеют высочайший уровень целостности, рассуждая об этом четко и ясно, что позволяет им принимать более эффективные бизнес-решения.
С другой стороны, эволюция схемы дополняет принудительное применение, упрощая предполагаемые автоматические изменений схемы. В конце концов, это не должно быть сложностью — добавить столбец.
Принудительное применение схемы — это янь, где эволюции схемы — это инь. При совместном использовании эти функции как никогда упрощают подавление шума и настройку сигнала.
Мы также хотели бы поблагодарить Мукула Мурти и Пранава Ананда за их вклад в эту статью.
Другие статьи из этой серии:
Погружение в Delta Lake: распаковка журнала транзакций
Статьи по теме
Машинное обучение производственного уровня с Delta Lake
Что такое озеро данных?



