

Пришлось мне недавно решать задачку по оптимизации поиска дубликатов изображений.
Существующее решение работает на довольно известной библиотеке, написанной на Python, — Image Match, основанной на работе «AN IMAGE SIGNATURE FOR ANY KIND OF IMAGE» за авторством H. Chi Wong, Marshall Bern и David Goldberg.
По ряду причин было принято решение переписать всё на Kotlin, заодно отказавшись от хранения и поиска в ElasticSearch, который требует заметно больше ресурсов, как железных, так и человеческих на поддержку и администрирование, в пользу поиска в локальном in-memory кэше.
Для понимания того, как оно работает, пришлось с головой погружаться в «эталонный» код на Python, так как оригинальная работа порой не совсем очевидна, а в паре мест заставляет вспомнить мем «как нарисовать сову». Собственно, результатами этого изучения я и хочу поделиться, заодно рассказав про некоторые оптимизации, как по объёму данных, так и по скорости поиска. Может, кому пригодится.
Disclaimer: Существует вероятность, что я где-то напортачил, сделал неправильно или не оптимально. Ну что уж, буду рад любой критике и комментариям. :)
Как оно работает:
- Изображение преобразуется к 8-битному чёрно-белому формату (одна точка — это один байт в значении 0-255)
- Изображение обрезается таким образом, чтобы отбросить 5% накопленной разницы (подробнее ниже) с каждой из четырёх сторон. Например, чёрную рамку вокруг изображения.
- Выбирается рабочая сетка (по умолчанию 9x9), узлы которой буду служить опорными точками сигнатуры изображения.
- Для каждой опорной точки на основании некоторой области вокруг неё рассчитывается её яркость.
- Для каждой опорной точки рассчитывается насколько она ярче/темнее своих восьми соседей. Используется пять градаций, от -2 (сильно темнее) до 2 (сильно ярче).
- Вся эта «радость» разворачивается в одномерный массив (вектор) и обзывается сигнатурой изображения.
Схожесть двух изображений проверяется следующим образом:
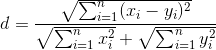
Чем меньше d — тем лучше. По факту, d<0.3 — это практически гарантия идентичности.
Теперь более подробно.
Шаг первый
Думаю, что про преобразование в grayscale рассказывать особого смысла нет.
Шаг второй
Допустим, у нас есть такая картинка:

Видно, что тут присутствует чёрная рамка по 3 пикселя справа и слева и по 2 пикселя сверху и снизу, которая нам в сравнении совсем не нужна
Граница обрезания определяется по такому алгоритму:
- Для каждого столбца рассчитываем сумму абсолютных разностей соседних элементов.
- Обрезаем слева и справа такое количество пикселей, вклад которых в общее накопленное различие менее 5%.

Аналогичным же образом поступаем и для столбцов.
Важное уточнение: если размеры получившегося изображения недостаточны для осуществления шага 4, то обрезания не делаем!
Шаг третий
Ну тут совсем всё просто, делим картинку на равные части и выбираем узловые точки.

Шаг четвёртый
Яркость опорной точки рассчитывается как средняя яркость всех точек в квадратной области вокруг неё. В оригинальной работе используется следующая формула для расчёта стороны этого квадрата:

Шаг пятый
Для каждой опорной точки вычисляется разность её яркости с яркостью её восьми соседей. Для тех точек, у которых не достаёт соседей (верхний и нижний ряды, левая и правая колонка), разница принимается за 0.
Далее эти разницы приводятся к пяти градациям:
| x-y | Значение | Описание |
|---|---|---|
| -2..2 | 0 | Идентичны |
| -50..-3 | -1 | Темнее |
| < -50 | -2 | Сильно темнее |
| 3..50 | 1 | Ярче |
| >50 | 2 | Сильно ярче |
Получается примерно вот такая матрица:
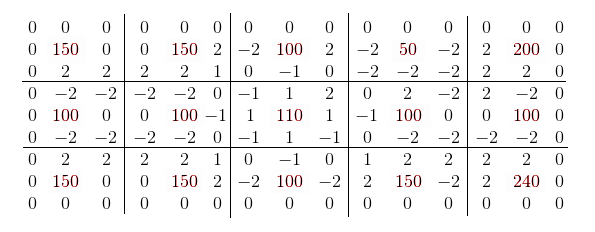
Шаг шестой
Думаю в пояснениях не нуждается.
А теперь про оптимизации
В оригинальной работе справедливо указывается, что из получившейся сигнатуры можно совершенно спокойно выкинуть нулевые значения по краям матрицы, так как они будут идентичны для всех изображений.
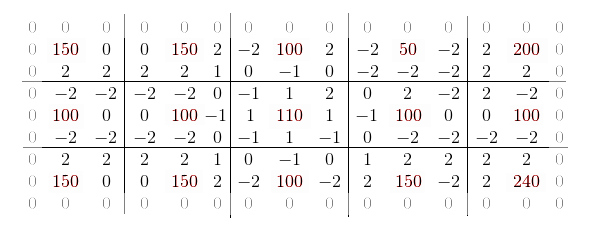
Однако если внимательно посмотреть, то видно, что для любых двух соседей их взаимные градации будут равны по модулю. Следовательно, на самом то деле, можно смело выкинуть по четыре дублирующихся значений для каждой опорной точки, сократив размер сигнатуры в два раза (без учёта боковых нулей).
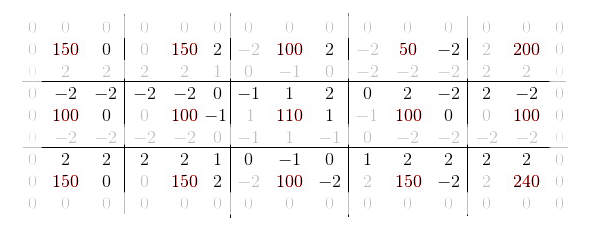
Очевидно, что при расчете суммы квадратов, для каждого x обязательно будет присутствовать равный по модулю x' и формулу расчета нормы можно записать примерно так (не углубляясь в переиндексацию):
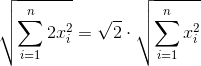
Это справедливо как для числителя, так и для обоих слагаемых знаменателя.
Далее в оригинальной работе замечается, что для хранение каждой градации достаточно трёх бит. То есть, например, в Unsigned Long влезет 21 градация. Это довольно большая экономия на размере, но, с другой стороны, добавляет сложности при расчёте суммы квадратов разницы двух сигнатур. Надо сказать, что идея эта меня чем-то очень зацепила и не отпускала пару дней, пока однажды вечером не озарило, как можно и
Используем для хранения такую схему, по 4 бита на градацию:
| Градация | Храним как |
|---|---|
| -2 | 0b1100 |
| -1 | 0b0100 |
| 0 | 0b0000 |
| 1 | 0b0010 |
| 2 | 0b0011 |
Да, в один Unsigned Long влезет всего 16 градаций, против 21, но зато массив разницы двух сигнатур будет вычисляться одним xor'ом и 15 сдвигами вправо с вычислением количества выставленных бит на каждой итерации сдвига. Т.е.
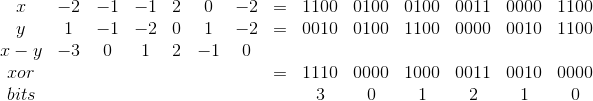
Знак нам безразличен, так как все значения будут возводиться в квадрат.
Кроме того, если заранее определить пороговое значение дистанции, значения больше которой нам не интересны, то, немного поплясав вокруг формулы расчёта, можно вывести довольно легковесное фильтрующее условие по простому количеству выставленных бит.
Более подробно про оптимизацию этого алгоритма, с примерами кода, можно прочитать в предыдущей статье. Отдельно рекомендую почитать комментарии к ней — хабровчанин masyaman предложил несколько довольно интересных способов по расчету, в том числе и с упаковкой градаций в трёх битах, с использованием битовой магии.
Собственно, всё. Спасибо за внимание. :)


![Программа для поиска единомышленников ВКонтакте [Open source]](/upload/resize_cache/iblock/4df/105_70_0/4df96e711f49b5310e1074a3c4a30b2f.png "Программа для поиска единомышленников ВКонтакте [Open source]")

