
Привет, Хабр! Меня зовут Ефим, я MLOps-инженер в Selectel. В прошлом был автоматизатором, ML-инженером, дата-аналитиком и дата-инженером — и уже несколько лет падаю в пропасть машинного обучения и Data Science. Это буквально необъятная сфера, в которой почти нет ориентиров. Основная проблема в том, что разделов математики довольно много и все они, на первый взгляд, нужны в том же машинном обучении.
В этой статье делюсь полезными материалами, которые помогут найти и заполнить теоретические и практические проблемы и основательно подойти к своему профессиональному развитию. Добро пожаловать под кат!
Используйте навигацию, если не хотите читать текст полностью:
→ Почему машинное обучение — это сложно
→ Нейронные сети
→ Выстраиваем работу с ML
→ Машинное обучение
→ Основы статистики, все части
→ Анализ данных в R, все части
→ Введение в математический анализ
→ Теория вероятностей — наука о случайности, все части
→ Курсы и гайды на Kaggle
→ Платформа DataCamp
→ Платформа Dataquest
→ Платформа Jovian
→ Канал StatQuest with Josh Starmer
→ Блог Machine Learning Mastery
Почему машинное обучение — это сложно
Для начала хотелось бы напомнить, почему одним курсом по машинному обучению и Data Science не обойтись.
Сфер применения машинного обучения много: от рекомендательных движков в музыкальных приложениях, до оценки благонадежности кредитуемого (aka задача кредитного скоринга). Спрос на специалистов, разбирающихся в предметной области и способных грамотно применять методы ML, постоянно растет.
В начале пути кажется, что создать собственный сервис просто: в сети есть открытые высокоуровневые библиотеки вроде PyTorch, TensorFlow, ONNX и других инструментов. Тем не менее, в силу специфики области возникает огромное количество вопросов и даже понимание «основ» машинного обучения не избавляет от подводных камней — а их может быть много. Постараюсь это показать.
Представьте ситуацию. Вы — начинающий специалист. И вам нужно некое портфолио, чтобы продемонстрировать потенциальному работодателю свои навыки и знания. Кроме того, их нужно где-то приобрести и поддерживать в актуальном состоянии.
Вы решили, что будете разрабатывать свой ML-сервис для распознавания лиц. Допустим, он будет построен на базе сверточных нейронных сетей и вы уже разобрались с формальной постановкой задачи (подозреваю, что там некоторым образом всплывут термины вроде Face Recognition и Face Identification). Предположим, что вы даже уже определились с выбором нужных инструментов — например Python, PyTorch и PyTorch Lighting. Какие вопросы могут возникнуть?
- Есть ли примеры кода для выбранных задач или нужно будет имплементировать архитектуру сети с нуля?
- Если примеры кода есть, достаточно ли будет Transfer Learning или придется прикручивать Fine Tuning для моделей?
- В случае Fine Tuning какой набор данных нужен для создания проекта?
- Если своих данных нет, откуда их можно взять?
И это лишь часть вопросов, с которыми можно столкнуться на этапе создания, казалось бы, простого сервиса. Могут появиться задачи, связанные вовсе не с данными, а с работой модели.
- Как разработать кастомную функцию потерь или функцию активации?
- Можно ли как-то осознанно выбрать гиперпараметры модели?
- На что вообще эти гиперпараметры влияют, есть ли рамки для каждого из них?
- Что делать, если возникла ошибка с размерностью входного слоя?
- Как имплементировать SOTA-архитектуру?
- Как интерпретировать полученные результаты?
До сих пор это лишь часть проблем, с которыми можно столкнуться из-за незнания математического аппарата. Например, есть параметр momentum. Это один из гиперпараметров, применяемых в обучении нейронной сети с использованием одной из вариаций стохастического градиентного спуска Adam (Adaptive Moment estimation). Чтобы просто понять, зачем этот параметр там нужен, нужно как минимум знать, что такое градиент. Это предполагает знание элементов математического анализа и концепции взвешенной суммы.
Машинное обучение — это о математике
Давайте разберем один из сценариев в прошлом разделе: начинающему ML-инженеру нужно самостоятельно имплементировать SOTA-архитектуру на готовом фреймворке.
В рамках задачи разработчику нужно будет самостоятельно расписать все слои SOTA и понять, как они между собой связаны — а это уже, как минимум, линейная алгебра и, возможно, тензорный анализ. На этом пункте многие скажут: «Очевидно, что ML-инженер должен знать эти дисциплины» — и будут правы.
Теория без практики мертва, но практика без теории слепа. Неважно, как вы изучаете: сверху вниз или снизу вверх, от общего к частному или от частного к общему — важно найти для себя некую точку баланса. Вот, как взаимосвязи в Data Science вижу я:
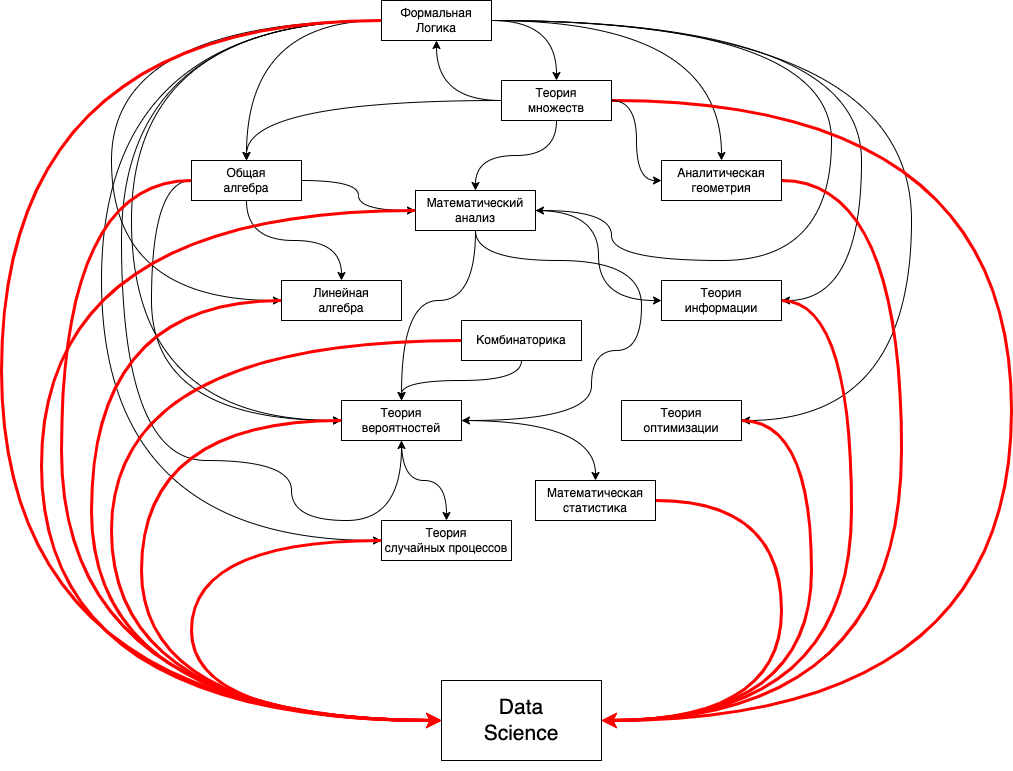
Теперь посмотрим, какие же ресурсы и курсы можно пошерстить, чтобы погрузиться в этот dependency hell.
Введение в Data Science и машинное обучение
Хороший курс для тех, кто только-только начинает вливаться в Data Science и машинное обучение. Простой, без академического снобизма и тонны громоздких терминов.
Лектор Анатолий Карпов рассказывает о наиболее популярных и надежных инструментах, которые применяют в различных компаниях при решении коммерческих задач. При этом в курсе есть достаточный минимум погружения в технические детали. Для меня этот курс был полезен тем, что помог структурировать уже имеющиеся знания и посмотреть на знакомые технологии под другим углом.
Источник → курс доступен по ссылке.

Нейронные сети
Этот курс дает возможность разобраться в устройстве оптимизаторов и даже написать свою версию. В курсе хорошо преподнесены вводные по линейной алгебре и имплементация метода обратного распространения ошибки на NumPy.
Курс особенно полезен для тех, у кого есть «база», новичкам его рекомендовать не могу.
Источник → изучайте нейронные сети по ссылке.
Выстраиваем работу с ML
Недавно мы с коллегами запустили курс «Выстраиваем работу с ML». В нем собрали полезные материалы для компаний, которые внедряют машинное обучение в рабочие процессы. Подробно рассмотрели концепцию MLOps — дисциплину, направленную на унификацию процессов разработки и развертывания ML-систем. Также рассмотрели отдельные инструменты для работы с ML-моделями и подробно осветили понятие платформы обработки данных.
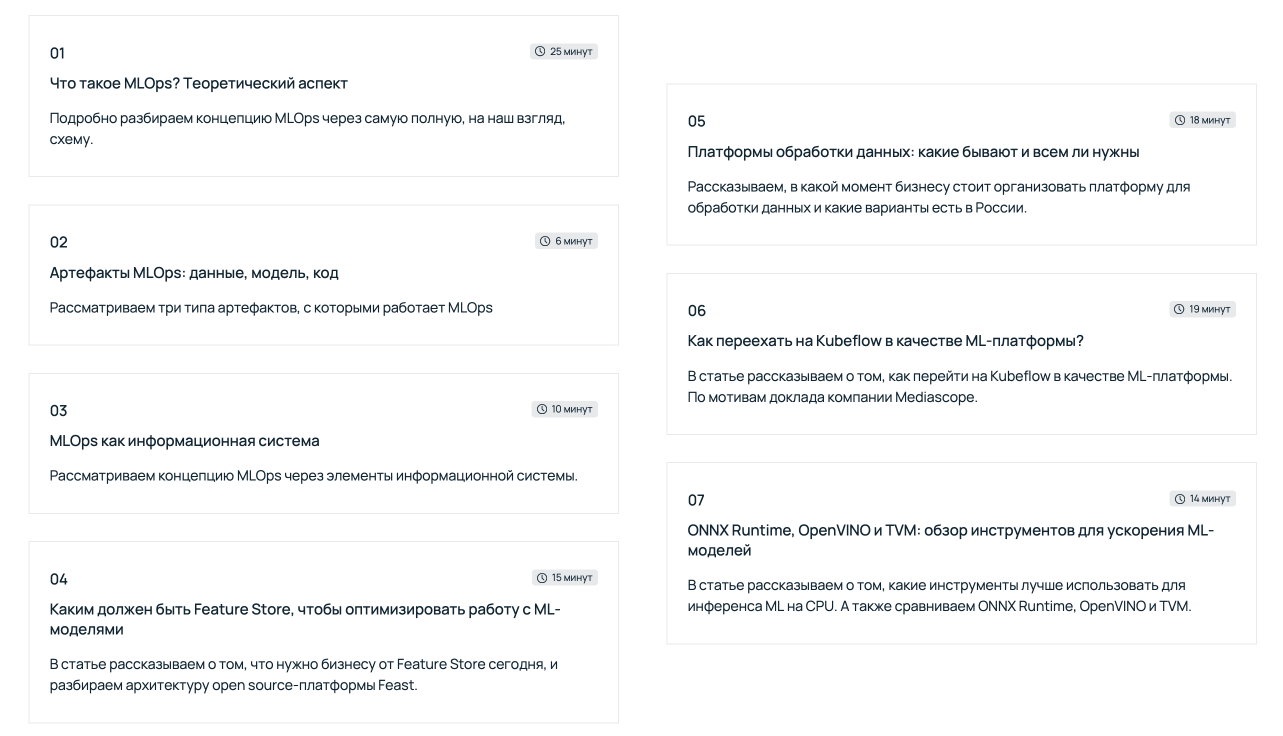
Источник → узнайте больше о ML по ссылке.
Машинное обучение
Это исключительно вводный курс, который скорее заинтересует, чем сделает из вас специалиста. Бережно и аккуратно рассказывает о базовых сущностях, которые лежат в основе математического аппарата машинного обучения. Поэтому курс особенно полезен для специалистов смежных направлений — например, техническим писателям.
Источник → курс доступен по ссылке.
Основы статистики, все части
Один из лучших курсов для «осторожного» погружения в работу статистических критериев, теорию формирования выборок и прочего.
Лектор Анатолий Карпов объясняет, из чего состоит критерий Стьюдента, в чем смысл центральной предельной теоремы, зачем нужно A/B-тестирование и другие вещи. Я бы сказал, этот курс полезен всем, потому что учит трезво оценивать реальность, осмыслять происходящие в ней события и случайные процессы.
Источник → первая часть доступна по ссылке.
Во второй части курса «Основы статистики» уже больше критериев и деталей.
Источник → вторая часть доступна по ссылке.
Третья часть курса еще сильнее погружает в вопросы линейной регрессии. Обсуждаются мультиколлинеарность, гетероскедастичность и другие проблемы, с которыми можно столкнуться в процессе построения регрессионных и классификационных моделей.
Источник → третья часть доступна по ссылке.
Анализ данных в R, все части

Говоря о курсах по основам статистики, имеет смысл упомянуть и курс по анализу данных в R. Поскольку все примеры, иллюстрирующие идеи и концепции из статистики, демонстрируются именно на этом языке.
Первая часть курса не распыляется и покрывает только часть тем — знакомство с синтаксисом, работу с датасетами и их визуализацию. Но этого вполне достаточно, чтобы влиться в язык и погрузиться в более сложные темы вроде RSpark.
Источник → первая часть доступна по ссылке.
Вторая часть логически развивает материал первой. В ней более пристально расписаны способы, как шерудить данные (преимущественно табличные), отрисовывать их и строить отчеты с помощью R Markdown.
Трудно сказать, насколько вам пригодится материал из этой части. Но если вы решили, что тематика языка R вам близка, то с помощью курса можете закрепить полученные знания.
Источник → вторая часть доступна по ссылке.
Введение в математический анализ

Не проходил курс полностью, но есть одна вещь, из-за которой готов его рекомендовать — это задачи. Почти в самом начале наткнулся на пример, который вогнал меня в ступор.

Решил задачу только со 117 попытки.
Поделиться ссылкой:
Интересные статьи
Интересные статьи

В 1977 году на рынке ПК безраздельно властвовала «большая тройка»: Apple II, Commodore PET и TRS-80. Стоимости их были $1298, $795 и $600 соответственно. И общедоступными для того времени они вовс...

С Bash связано одно распространённое заблуждение, которое заключается в том, что имена bash-функций должны быть составлены по тем же правилам, что и имена переменных. В руководстве по...

Научные теории — это краеугольный камень успеха и дальнейшего развития во всех сферах общества. Будь то теория относительность, изменившая облик современной физики, или т...

Благодаря которым вы станете лучше как программист
Привычки, относящиеся к написанию кода, есть у каждого разработчика — и вредные, и полезные. Но если завести правильные привычки, это помож...

Оригинал поста в моём личном блоге
Мне посчастливилось лично познакомиться со Стивеном Вольфрамом на Первой Российской конференции «Wolfram технологии», которая проходила в 2013 г. в СПбГУ. ...