
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Дмитрий Калугин-Балашов большую часть своей жизни писал поиск: с 2011 года в компании Mail.ru был поиск по почте, затем был небольшой перерыв из-за работы в США, а сейчас это — работа над поиском в Couchbase. Одна из первых вещей, которую Дмитрий понял, работая в США — не всегда покупают самое эффективное решение. Иногда покупают то, где клиент будет иметь меньше проблем.
Поэтому ещё в 2013 году Дмитрий написал движок поиска для почтовых ящиков Mail.ru и рассказал об этом в том же году на конференции HighLoad и в статье на Хабре. А на HighLoad 2019 показал, как устроен полнотекстовый поиск в Couchbase Server, и сегодня мы предлагаем расшифровку его доклада.

На самом деле в Couchbase используется внешний опенсорсный движок Bleve:
Этот движок изначально был создан внутри Couchbase как проект для реализации полнотекстового поиска в виде библиотеки, написанной на Go. Сначала он был простым монолитным индексом — если есть хранилище «ключ-значение», то слева берём слова в виде ключей, а в виде значений ставим документы — и всё, у нас есть полнотекстовый поиск! Но в работе он становился очень большим, а обычное хранилище k-value под поиск не оптимизировано. Нагрузка под поиск очень специфичная, а если ещё и апдейты есть, то движок неизбежно начинает тупить.
Поэтому Couchbase решили создать сегментированный индекс — специальное хранилище под поисковые данные, в котором используются Immutable-сегменты, оптимизированные под поиск.
Что такое обратный индекс? Если есть книга, в которой я хочу что-то найти по слову — как это сделать? На последней странице обычно есть указатель на слово и страницу, где этот термин встречается. Обратный индекс сопоставляет слова со списком. В книге это страницы, у нас — документы в базе (у нас документно-ориентированная БД, в которой хранятся «джейсонки»).
Map[string]uint. Самое простое. Кто владеет Гошкой, знает, что это хэш-таблица. Но это не очень хорошо, потому что у нас используются слова, и иногда надо по ним итерироваться. Если у нас неточный поиск, мы начинаем считать расстояние Левенштейна, нужно итерироваться местами, а это по hashmap нельзя. Но можно сделать дерево.
Tree. Но дерево — оно здоровое, поэтому тоже не годится, потому что мы делаем хранилище под поиск, а это одновременно и общее хранилище для БД.
Trie. Префиксное дерево — это уже лучше, оно довольно компактное, его можно через два массива построить. Но можно ли сделать лучше?
Finite State Transducer. Это автомат под названием Vellum, который Couchbase для себя же и написали. Есть реализация FST на Go и других языках. В нем есть всего лишь три процедуры:
Чтобы построить, нужен список слов в алфавитном порядке (например, возьмём «are, ate, see»). Так как у нас индексы сегментированные (сегменты неизменяемые), то нам это отлично подходит — мы его построили один раз и забыли.
Давайте теперь построим. Мы должны хранить пары: слово – число (потом это будет указатель). Состояния автомата просто нумеруются числами, и на каждом ребре есть буква и число. По сумме этих чисел мы считаем конечное число:

Таким образом слово are дает 4. Добавляем второе слово:

Добавляем третье слово:

Теперь мы делаем еще одну операцию и компактим:
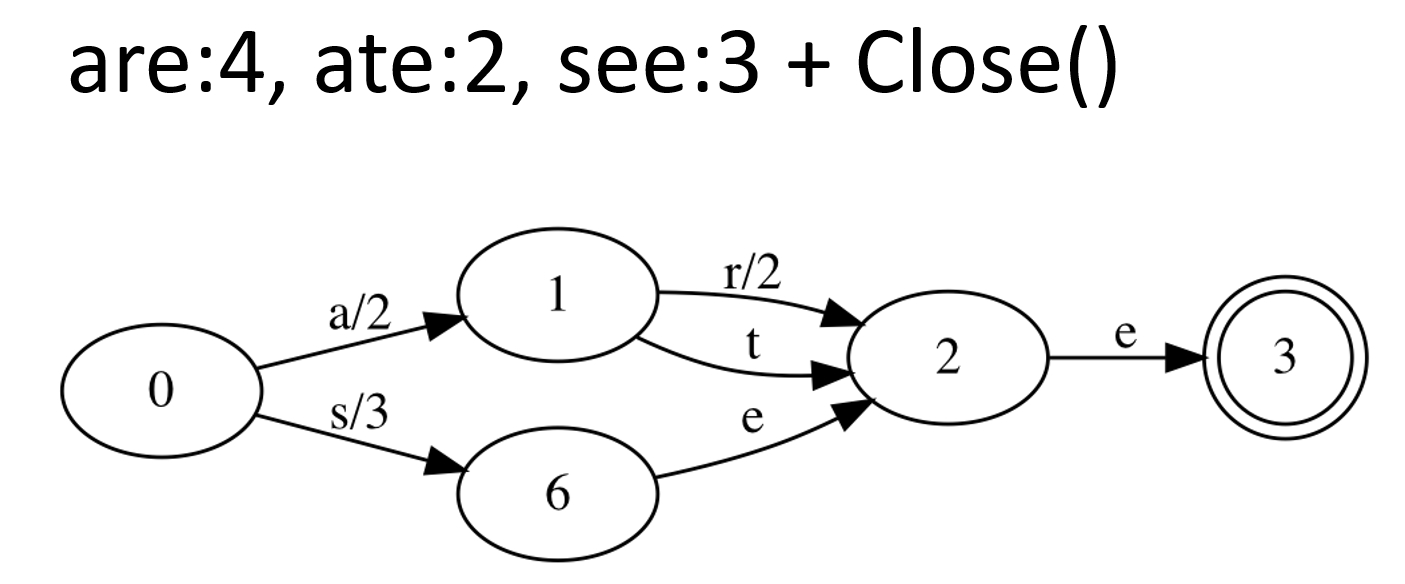
Получается автомат, в котором всего два объекта:
Открыть его мы можем либо из файла через mmap (если он поддерживается в системе):
либо из массива Bytes (это нам будет очень нужно дальше), и можем загрузить прямо из буфера:
Дальше запускаем поиск в FST:
К списку слов есть список страниц в книге, а в БД PostingsList — список документов. Как его можно хранить?
Как сделать лучше? Есть RoaringBitmap, с библиотеками почти для всех языков. Работает он так: берем последовательность наших чисел и разбиваем на куски (чанки). Каждый чанк кодируем одним из трех способов:
Выбираем тот, который лучше сожмет — так мы получаем минимизацию. Там есть ряд проблем, например, не очень понятно, как делать бинарные операции (AND, OR и прочие). Но именно для хранение это получается более эффективным, чем какой-нибудь способ в отдельности. Создано это было, кстати, именно для полнотекстового поиска.
Теперь попробуем сделать полнотекстовый поиск Memory-Only. У нас есть Snapshot — это наш индекс на какую-то единицу времени. В нём есть несколько сегментов с данными. Внутри сегментов ищем обратные индексы, которые все read-only. Также есть какое-то приложение, которое работает с нашим поиском:

Давайте пытаемся что-нибудь туда добавить. Понятно, что если мы что-то добавляем, возможно, будет удаление – какие-то данные в предыдущих сегментах инвалидируются:

Но сами сегменты нам не нужны – мы копируем их под read mutex и добавляем новый сегмент. Маленькие фрагменты — это просто битовые массивы. Если что-то удаляется, мы просто выставляем там биты:

То есть сам сегмент – read only (immutable), но удалить что-то можно, выставив эти биты, если в новом сегменте пришла эта информация. Это называется Segment Introduction: есть новый сегмент (битовый массив) и горутина (Introducer). Ее задача — добавить сегмент в наш Snapshot, который мы присылаем по каналу:

Горутина еще раз, уже под эксклюзивной блокировкой, выставляет эти биты, потому что за время, пока мы передавали, что-то могло измениться:

И все — мы переходим к четвертому Snapshot и получаем Memory-Only решение:

Для того, чтобы сохранить на диск, есть еще одна горутина — Persister. У нас есть номера эпох, также пронумеруем сегменты (a, b, c, d):

В Persister есть цикл FOR, время от времени он пробуждается и смотрит – «О! Появился новый сегмент, давайте его сохраним»:

Для этого сегмента у нас две базы данных: маленькая БД, куда он сохраняется, и корневая БД, которая просто описывает всю эту конструкцию. Таким образом мы сохраняем на диск и меняем номер эпохи после записи:

Сегменты будут расти (они все неизменяемые), когда-то мы захотим их склеить — и для этого у нас есть merger. Создаем Merge plane третьей горутиной:

Также есть номер эпохи, когда мы мерджим. Далее мы делаем какие-то операции. Merge Introduction, как и обычный сегмент Introduction, попадает обратно в него и создает новый сегмент, а два склеивает, удаляя оттуда данные:

Таким образом мы удаляем часть сегментов.
Важное примечание. После того, как мы записали zap-файл на диск, мы сегмент закрываем и тут же обратно открываем, но не как in-memory сегмент, а как сегмент на диске. Хотя у них одинаковый интерфейс, устроены они по-разному: сегмент на диске проецируется в память через mmap.
Изначально это был BoltDB. Потом создатель сказал: «Ну вас всех на фиг, я устал, я ухожу», и BoltDB закрылся. Хотя позже его форкнули в BBoltDB, работал он всё равно плохо, потому что вернулись к той же проблеме: база данных в общем не очень подходит для хранения поисковых индексов. И мы тогда заменили BBoltDB на самописный формат .zap. Корневая база осталась BBoltDB, но там ничего особо критичного хранить не надо:

Формат ZAP — это просто сегмент на диске. Мы его не читаем READ’ами, он читается mmap’ом, при этом данные внутри максимально удобны для in-memory работы. Сам формат ZAP с индексами выглядит так:

В футере описано, где что искать, и мы по указателю находим индекс полей. Что у нас есть? Есть сколько-то (от 0 до F#) проиндексированных полей в документах, они пронумерованы и проиндексированы. Стрелками показаны указатели, сколько полей, и мы знаем заранее, сколько их. Мы находим в Fields Index указатель, а в Fields — место, и понимаем по названию поля, что это такое:

Есть еще один указатель:

Он указывает место, где будут храниться наши словари (dictionaries), при этом, под каждое поле будет свой словарь:

Этот указатель показывает VELLUM данные:

А мы помним, что VELLUM может читать данные прямо из памяти. Мы спроецировали память, нашли нужный указатель, взяли кусок данных и начали с помощью VELLUM в нём искать. Нам даже не нужны READ, мы просто к списку слов делаем список OFFSET, который ведёт к RoaringBitmap. Таким образом мы получаем номера документов, которые найдутся по этому слову в этом поле:

Также есть позиции вхождения, если мы хотим сделать подсветку. Если у нас длинная строка, то мы узнаем, в каком месте находится нужное нам слово. Еще мы можем получить определенную статистику частоты встречаемости и другую инфу, нужную для ранжирования:

DocValues – это вспомогательный и необязательный список полей, в нём хранятся значения полей:

Значения полей нужны для ранжирования, мы дублируем по номеру поля значения для каждого документа:

Для каждого документа мы знаем список полей и их значение. И, что самое важное, тут есть искусственное поле — ID. Дело в том, что внутри ZAP-файла все документы нумеруются с 0 и до бесконечности, а в самой базе данных текстовые имена. Так что в ID происходит сопоставление между номером внутри ZAP-файла и внешним номером (внешним именем):

Остаются мелочи. Это Chunk Factor(на какие кусочки бьем, когда делаем чанки данных), версия, контрольная сумма и число документов (D#):
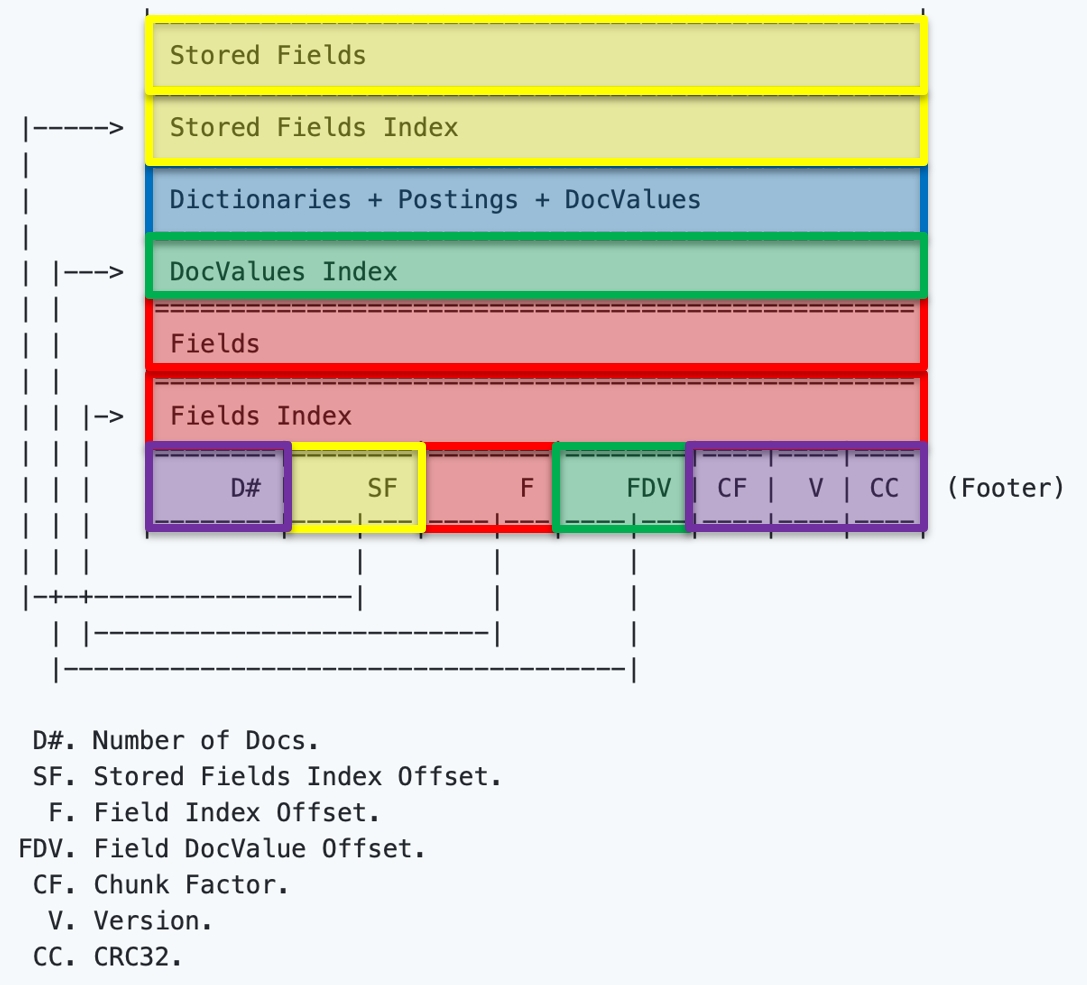
Это весь ZAP-файл. Как искать, думаю, уже понятно: мы отражаем в память и находим, по какому полю ищем. После этого находим слово, идем по длинной цепочке и находим результаты.
Есть интересная операция Rollback. Базе данных Rollback нужен всегда — мы можем нагородить огород, и нам нужна возможность откатиться. В нашем случае откат делается очень просто. У нас есть эпохи. Мы храним в корневой базе текущую конфигурацию и предыдущие (1-2), куда хотим откатиться. Если мы хотим откатиться на предыдущую эпоху, мы достаем конфигурацию из индекса, и получаем откат на предыдущую эпоху. В сегмент мы добавляем, когда происходит какая-то операция или группа операций (мы обычно их вставляем большой группой):

Если же за это время у нас ничего такого не добавится, мы сделаем Rollback под эксклюзивом — это нормально.
Так работает само ядро. Как работает поиск — уже очевидно. Если поиск идет по точному совпадению, то прочитали, прошли по цепочке и нашли. Если поиск неточный, то добавляется автомат Левенштейна и начинаются итерации по vellum, но процесс проходит примерно так же.
Поэтому ещё в 2013 году Дмитрий написал движок поиска для почтовых ящиков Mail.ru и рассказал об этом в том же году на конференции HighLoad и в статье на Хабре. А на HighLoad 2019 показал, как устроен полнотекстовый поиск в Couchbase Server, и сегодня мы предлагаем расшифровку его доклада.
На самом деле в Couchbase используется внешний опенсорсный движок Bleve:
- blevesearch.com
- github.com/blevesearch/bleve
Этот движок изначально был создан внутри Couchbase как проект для реализации полнотекстового поиска в виде библиотеки, написанной на Go. Сначала он был простым монолитным индексом — если есть хранилище «ключ-значение», то слева берём слова в виде ключей, а в виде значений ставим документы — и всё, у нас есть полнотекстовый поиск! Но в работе он становился очень большим, а обычное хранилище k-value под поиск не оптимизировано. Нагрузка под поиск очень специфичная, а если ещё и апдейты есть, то движок неизбежно начинает тупить.
Поэтому Couchbase решили создать сегментированный индекс — специальное хранилище под поисковые данные, в котором используются Immutable-сегменты, оптимизированные под поиск.
Что такое обратный индекс? Если есть книга, в которой я хочу что-то найти по слову — как это сделать? На последней странице обычно есть указатель на слово и страницу, где этот термин встречается. Обратный индекс сопоставляет слова со списком. В книге это страницы, у нас — документы в базе (у нас документно-ориентированная БД, в которой хранятся «джейсонки»).
ОК, а как хранить список слов?
Map[string]uint. Самое простое. Кто владеет Гошкой, знает, что это хэш-таблица. Но это не очень хорошо, потому что у нас используются слова, и иногда надо по ним итерироваться. Если у нас неточный поиск, мы начинаем считать расстояние Левенштейна, нужно итерироваться местами, а это по hashmap нельзя. Но можно сделать дерево.
Tree. Но дерево — оно здоровое, поэтому тоже не годится, потому что мы делаем хранилище под поиск, а это одновременно и общее хранилище для БД.
Trie. Префиксное дерево — это уже лучше, оно довольно компактное, его можно через два массива построить. Но можно ли сделать лучше?
Finite State Transducer. Это автомат под названием Vellum, который Couchbase для себя же и написали. Есть реализация FST на Go и других языках. В нем есть всего лишь три процедуры:
- Построение FST (один раз);
- Поиск;
- Итерирование.
Чтобы построить, нужен список слов в алфавитном порядке (например, возьмём «are, ate, see»). Так как у нас индексы сегментированные (сегменты неизменяемые), то нам это отлично подходит — мы его построили один раз и забыли.
Давайте теперь построим. Мы должны хранить пары: слово – число (потом это будет указатель). Состояния автомата просто нумеруются числами, и на каждом ребре есть буква и число. По сумме этих чисел мы считаем конечное число:
Таким образом слово are дает 4. Добавляем второе слово:
Добавляем третье слово:
Теперь мы делаем еще одну операцию и компактим:
Получается автомат, в котором всего два объекта:
- Builder — мы строим, операцию делаем;
- Reader — мы читаем и делаем либо поиск, либо итерацию.
Открыть его мы можем либо из файла через mmap (если он поддерживается в системе):
fst, err := vellum.Open("/tmp/vellum.fst")либо из массива Bytes (это нам будет очень нужно дальше), и можем загрузить прямо из буфера:
fst, err := vellum.Load(buf.Bytes())Дальше запускаем поиск в FST:
val, exists, err = fst.Get([]byte("dog"))
Как хранить PostingsList?
К списку слов есть список страниц в книге, а в БД PostingsList — список документов. Как его можно хранить?
- Просто список чисел – это массив (кстати, можно использовать дельта-кодирование);
- Битовый массив. Это удобно, если, что список чисел, как страницы в книге, начинается просто от 0 и числа идут подряд. Но только если в нем не будет повторяемых элементов.
- RLE-сжатие. Битовый массив можно еще иногда сжать.
Как сделать лучше? Есть RoaringBitmap, с библиотеками почти для всех языков. Работает он так: берем последовательность наших чисел и разбиваем на куски (чанки). Каждый чанк кодируем одним из трех способов:
- Просто список чисел
- Битовый массив
- RLE-сжатие
Выбираем тот, который лучше сожмет — так мы получаем минимизацию. Там есть ряд проблем, например, не очень понятно, как делать бинарные операции (AND, OR и прочие). Но именно для хранение это получается более эффективным, чем какой-нибудь способ в отдельности. Создано это было, кстати, именно для полнотекстового поиска.
Поиск Memory-Only?
Теперь попробуем сделать полнотекстовый поиск Memory-Only. У нас есть Snapshot — это наш индекс на какую-то единицу времени. В нём есть несколько сегментов с данными. Внутри сегментов ищем обратные индексы, которые все read-only. Также есть какое-то приложение, которое работает с нашим поиском:
Давайте пытаемся что-нибудь туда добавить. Понятно, что если мы что-то добавляем, возможно, будет удаление – какие-то данные в предыдущих сегментах инвалидируются:
Но сами сегменты нам не нужны – мы копируем их под read mutex и добавляем новый сегмент. Маленькие фрагменты — это просто битовые массивы. Если что-то удаляется, мы просто выставляем там биты:
То есть сам сегмент – read only (immutable), но удалить что-то можно, выставив эти биты, если в новом сегменте пришла эта информация. Это называется Segment Introduction: есть новый сегмент (битовый массив) и горутина (Introducer). Ее задача — добавить сегмент в наш Snapshot, который мы присылаем по каналу:
Горутина еще раз, уже под эксклюзивной блокировкой, выставляет эти биты, потому что за время, пока мы передавали, что-то могло измениться:
И все — мы переходим к четвертому Snapshot и получаем Memory-Only решение:
Для того, чтобы сохранить на диск, есть еще одна горутина — Persister. У нас есть номера эпох, также пронумеруем сегменты (a, b, c, d):
В Persister есть цикл FOR, время от времени он пробуждается и смотрит – «О! Появился новый сегмент, давайте его сохраним»:
Для этого сегмента у нас две базы данных: маленькая БД, куда он сохраняется, и корневая БД, которая просто описывает всю эту конструкцию. Таким образом мы сохраняем на диск и меняем номер эпохи после записи:
Сегменты будут расти (они все неизменяемые), когда-то мы захотим их склеить — и для этого у нас есть merger. Создаем Merge plane третьей горутиной:
Также есть номер эпохи, когда мы мерджим. Далее мы делаем какие-то операции. Merge Introduction, как и обычный сегмент Introduction, попадает обратно в него и создает новый сегмент, а два склеивает, удаляя оттуда данные:
Таким образом мы удаляем часть сегментов.
Важное примечание. После того, как мы записали zap-файл на диск, мы сегмент закрываем и тут же обратно открываем, но не как in-memory сегмент, а как сегмент на диске. Хотя у них одинаковый интерфейс, устроены они по-разному: сегмент на диске проецируется в память через mmap.
Формат ZAP
Изначально это был BoltDB. Потом создатель сказал: «Ну вас всех на фиг, я устал, я ухожу», и BoltDB закрылся. Хотя позже его форкнули в BBoltDB, работал он всё равно плохо, потому что вернулись к той же проблеме: база данных в общем не очень подходит для хранения поисковых индексов. И мы тогда заменили BBoltDB на самописный формат .zap. Корневая база осталась BBoltDB, но там ничего особо критичного хранить не надо:
Формат ZAP — это просто сегмент на диске. Мы его не читаем READ’ами, он читается mmap’ом, при этом данные внутри максимально удобны для in-memory работы. Сам формат ZAP с индексами выглядит так:
В футере описано, где что искать, и мы по указателю находим индекс полей. Что у нас есть? Есть сколько-то (от 0 до F#) проиндексированных полей в документах, они пронумерованы и проиндексированы. Стрелками показаны указатели, сколько полей, и мы знаем заранее, сколько их. Мы находим в Fields Index указатель, а в Fields — место, и понимаем по названию поля, что это такое:
Есть еще один указатель:
Он указывает место, где будут храниться наши словари (dictionaries), при этом, под каждое поле будет свой словарь:
Этот указатель показывает VELLUM данные:
А мы помним, что VELLUM может читать данные прямо из памяти. Мы спроецировали память, нашли нужный указатель, взяли кусок данных и начали с помощью VELLUM в нём искать. Нам даже не нужны READ, мы просто к списку слов делаем список OFFSET, который ведёт к RoaringBitmap. Таким образом мы получаем номера документов, которые найдутся по этому слову в этом поле:
Также есть позиции вхождения, если мы хотим сделать подсветку. Если у нас длинная строка, то мы узнаем, в каком месте находится нужное нам слово. Еще мы можем получить определенную статистику частоты встречаемости и другую инфу, нужную для ранжирования:
DocValues – это вспомогательный и необязательный список полей, в нём хранятся значения полей:
Значения полей нужны для ранжирования, мы дублируем по номеру поля значения для каждого документа:
Для каждого документа мы знаем список полей и их значение. И, что самое важное, тут есть искусственное поле — ID. Дело в том, что внутри ZAP-файла все документы нумеруются с 0 и до бесконечности, а в самой базе данных текстовые имена. Так что в ID происходит сопоставление между номером внутри ZAP-файла и внешним номером (внешним именем):
Остаются мелочи. Это Chunk Factor(на какие кусочки бьем, когда делаем чанки данных), версия, контрольная сумма и число документов (D#):
Это весь ZAP-файл. Как искать, думаю, уже понятно: мы отражаем в память и находим, по какому полю ищем. После этого находим слово, идем по длинной цепочке и находим результаты.
Rollback
Есть интересная операция Rollback. Базе данных Rollback нужен всегда — мы можем нагородить огород, и нам нужна возможность откатиться. В нашем случае откат делается очень просто. У нас есть эпохи. Мы храним в корневой базе текущую конфигурацию и предыдущие (1-2), куда хотим откатиться. Если мы хотим откатиться на предыдущую эпоху, мы достаем конфигурацию из индекса, и получаем откат на предыдущую эпоху. В сегмент мы добавляем, когда происходит какая-то операция или группа операций (мы обычно их вставляем большой группой):
Если же за это время у нас ничего такого не добавится, мы сделаем Rollback под эксклюзивом — это нормально.
Так работает само ядро. Как работает поиск — уже очевидно. Если поиск идет по точному совпадению, то прочитали, прошли по цепочке и нашли. Если поиск неточный, то добавляется автомат Левенштейна и начинаются итерации по vellum, но процесс проходит примерно так же.
Пока пандемия идет к финишу, мы продолжаем проводить встречи онлайн. В понедельник 30 ноября будем обсуждать банковскую архитектуру на встрече «Эволюция через боль. Как устроен СберБанк Онлайн изнутри?». Рассмотрим с нуля, как создается и развивается архитектура в банке и узнаем, что под капотом у крупнейшего банка страны. Узнаем, почему банку недостаточно простого приложения из одного сервиса и одной базы данных и увидим на примерах монолит и микросервис. Начало в 18 часов.
А 3 декабря будет митап «Безопасность и надёжность в финтехе». Спикеров будет несколько, и они поднимут несколько тем. Сначала будет разговор о закулисье финтеха, затем — как и какими инструментами сделать финтех надежным сервисом, и на закуску — как снизить риски ИБ в разработке финансовых систем. Начнем в 17.
Следите за новостями — Telegram, Twitter, VK и FB и присоединяйтесь к обсуждениям.


")

