
Полгода назад мы представили explain.tensor.ru — публичный сервис для разбора и визуализации планов запросов к PostgreSQL.
За прошедшие месяцы мы сделали про него доклад на PGConf.Russia 2020, подготовили обобщающую статью по ускорению SQL-запросов на основе рекомендаций, которые он выдает… но самое главное — собирали ваши отзывы и смотрели за реальными use case.
И теперь готовы рассказать о новых возможностях, которыми вы можете пользоваться.
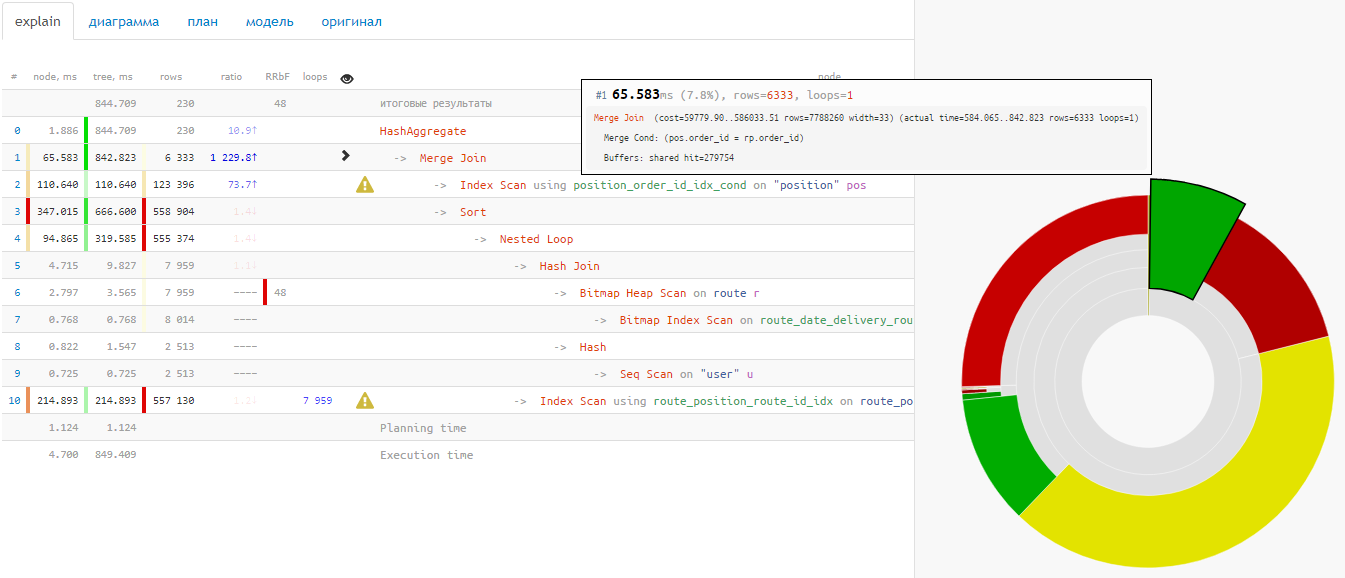
Прямо с консоли выделяем весь блок, начиная со строки с Query Text, со всеми лидирующими пробелами:
… и закидываем все скопированное прямо в поле для плана, ничего не разделяя:

На выходе получаем бонусом к разобранному плану еще и вкладку «контекст», где наш запрос представлен во всей красе:
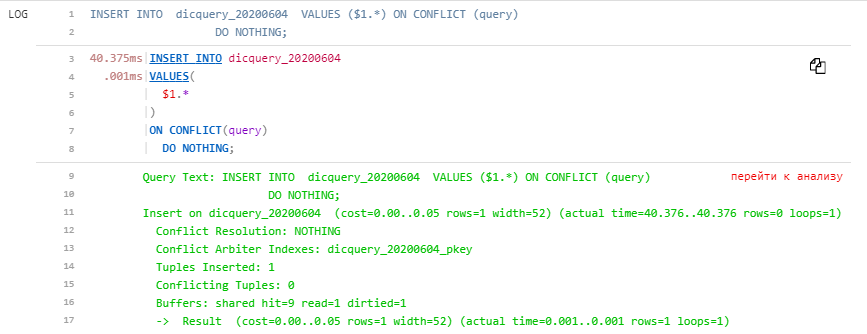
Хоть с внешними кавычками, как копирует pgAdmin, хоть без — кидаем в то же поле, на выходе — красота:

Теперь лучше видно, куда ушло дополнительное время при выполнении запроса:
Иногда приходится сталкиваться с ситуацией, когда в плане вроде и ресурсов читалось-писалось не слишком много, а вроде и время выполнения несообразно большое какое-то.
Тут приходится говорить: "Ой, наверное, в тот момент диск на сервере был слишком перегружен, поэтому читалось так долго!" Но как-то это не слишком точно…
Но можно это определить абсолютно достоверно. Дело в том, что среди опций конфигурации PG-сервера есть
Ну, а теперь самое приятное — мы научились понимать и отображать эти данные с учетом всех трансформаций дерева исполнения:
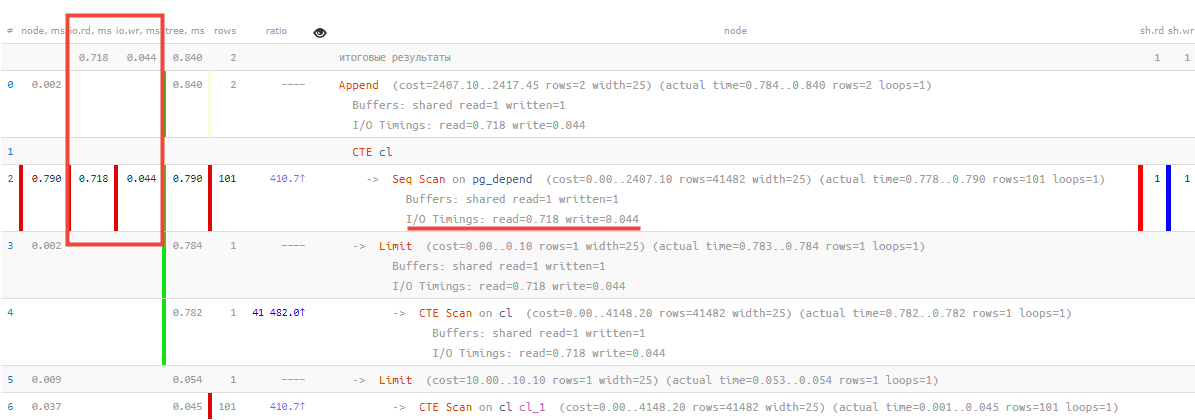
Тут можно заметить, что из 0.790ms всего времени исполнения 0.718ms заняло чтение одной страницы данных, 0.044ms — запись ее же, а на всю остальную полезную активность было потрачено всего 0.028ms!
Ознакомиться с полным обзором нововведений можно в подробной статье, а мы конкретно про изменения в планах.


Теперь на каждой вкладке появилась возможность быстро взять скриншот вкладки в буфер обмена на всю ширину и глубину вкладки — «прицел» справа-сверху:
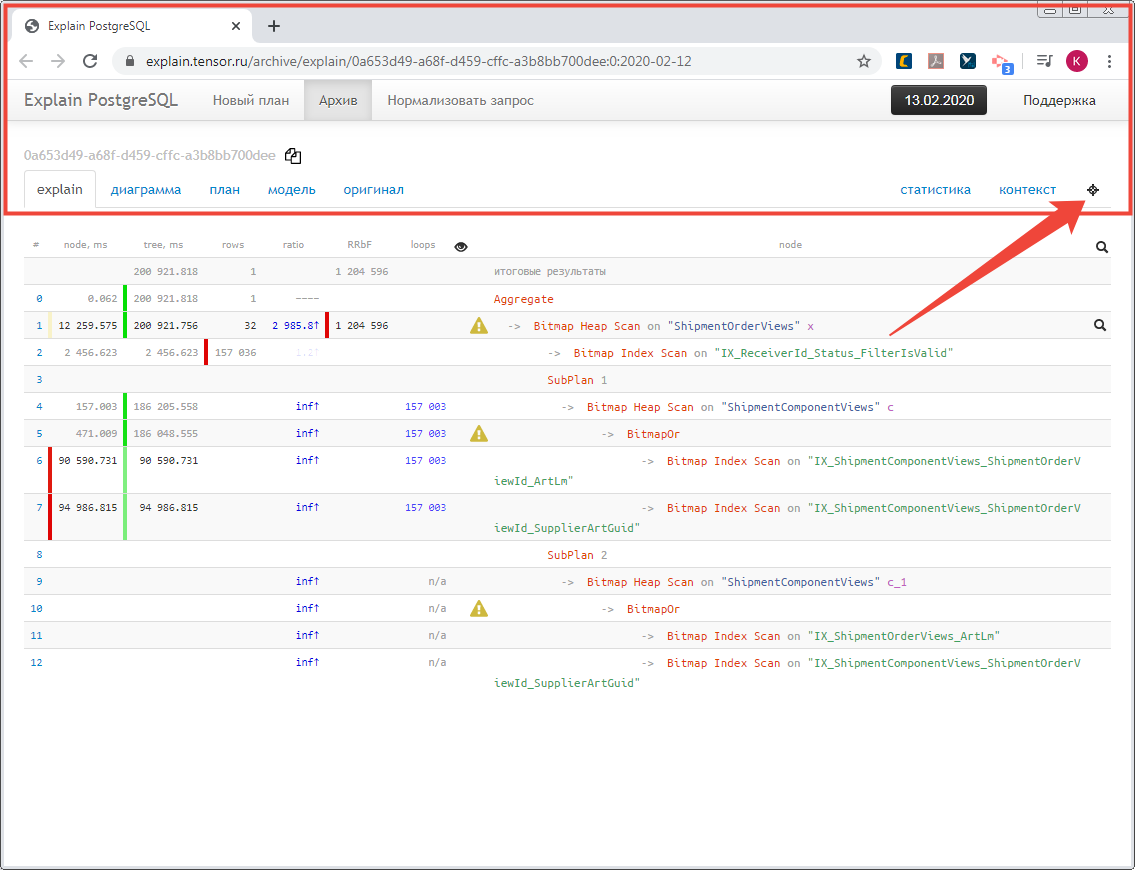
Собственно, большинство картинок для этой публикации получено именно так.
Их не только стало больше, но и про каждую можно подробно прочитать в статье, перейдя по ссылке:

Некоторые очень просили добавить возможность удалять «совсем» даже непубликуемые в архиве планы — пожалуйста, достаточно нажать соответствующую иконку:
Ну, и не забываем, что у нас есть группа поддержки, куда можно писать свои замечания и предложения.
За прошедшие месяцы мы сделали про него доклад на PGConf.Russia 2020, подготовили обобщающую статью по ускорению SQL-запросов на основе рекомендаций, которые он выдает… но самое главное — собирали ваши отзывы и смотрели за реальными use case.
И теперь готовы рассказать о новых возможностях, которыми вы можете пользоваться.
Поддержка разных форматов планов
План из лога, вместе с запросом
Прямо с консоли выделяем весь блок, начиная со строки с Query Text, со всеми лидирующими пробелами:
Query Text: INSERT INTO dicquery_20200604 VALUES ($1.*) ON CONFLICT (query)
DO NOTHING;
Insert on dicquery_20200604 (cost=0.00..0.05 rows=1 width=52) (actual time=40.376..40.376 rows=0 loops=1)
Conflict Resolution: NOTHING
Conflict Arbiter Indexes: dicquery_20200604_pkey
Tuples Inserted: 1
Conflicting Tuples: 0
Buffers: shared hit=9 read=1 dirtied=1
-> Result (cost=0.00..0.05 rows=1 width=52) (actual time=0.001..0.001 rows=1 loops=1)
… и закидываем все скопированное прямо в поле для плана, ничего не разделяя:
На выходе получаем бонусом к разобранному плану еще и вкладку «контекст», где наш запрос представлен во всей красе:
JSON и YAML
EXPLAIN (ANALYZE, BUFFERS, FORMAT JSON)
SELECT * FROM pg_class;"[
{
"Plan": {
"Node Type": "Seq Scan",
"Parallel Aware": false,
"Relation Name": "pg_class",
"Alias": "pg_class",
"Startup Cost": 0.00,
"Total Cost": 1336.20,
"Plan Rows": 13804,
"Plan Width": 539,
"Actual Startup Time": 0.006,
"Actual Total Time": 1.838,
"Actual Rows": 10266,
"Actual Loops": 1,
"Shared Hit Blocks": 646,
"Shared Read Blocks": 0,
"Shared Dirtied Blocks": 0,
"Shared Written Blocks": 0,
"Local Hit Blocks": 0,
"Local Read Blocks": 0,
"Local Dirtied Blocks": 0,
"Local Written Blocks": 0,
"Temp Read Blocks": 0,
"Temp Written Blocks": 0
},
"Planning Time": 5.135,
"Triggers": [
],
"Execution Time": 2.389
}
]"Хоть с внешними кавычками, как копирует pgAdmin, хоть без — кидаем в то же поле, на выходе — красота:
Расширенная визуализация
Planning Time / Execution Time
Теперь лучше видно, куда ушло дополнительное время при выполнении запроса:
I/O Timing
Иногда приходится сталкиваться с ситуацией, когда в плане вроде и ресурсов читалось-писалось не слишком много, а вроде и время выполнения несообразно большое какое-то.
Тут приходится говорить: "Ой, наверное, в тот момент диск на сервере был слишком перегружен, поэтому читалось так долго!" Но как-то это не слишком точно…
Но можно это определить абсолютно достоверно. Дело в том, что среди опций конфигурации PG-сервера есть
track_io_timing:Включает замер времени операций ввода/вывода. Этот параметр по умолчанию отключён, так как для этого требуется постоянно запрашивать текущее время у операционной системы, что может значительно замедлить работу на некоторых платформах. Для оценивания издержек замера времени на вашей платформе можно воспользоваться утилитой pg_test_timing. Статистику ввода/вывода можно получить через представление pg_stat_database, в выводе EXPLAIN (когда используется параметр BUFFERS) и через представление pg_stat_statements.Этот параметр можно включить и в рамках локальной сессии:
SET track_io_timing = TRUE;Ну, а теперь самое приятное — мы научились понимать и отображать эти данные с учетом всех трансформаций дерева исполнения:
Тут можно заметить, что из 0.790ms всего времени исполнения 0.718ms заняло чтение одной страницы данных, 0.044ms — запись ее же, а на всю остальную полезную активность было потрачено всего 0.028ms!
Будущее с PostgreSQL 13
Ознакомиться с полным обзором нововведений можно в подробной статье, а мы конкретно про изменения в планах.
Planning buffers
Учет ресурсов, выделенных планировщику, нашел свое отражение еще в одном патче, не относящемуся к pg_stat_statements. EXPLAIN с опцией BUFFERS будет сообщать количество буферов, использованных на этапе планирования:
Seq Scan on pg_class (actual rows=386 loops=1) Buffers: shared hit=9 read=4 Planning Time: 0.782 ms Buffers: shared hit=103 read=11 Execution Time: 0.219 ms
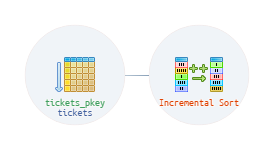
Инкрементальная сортировка
В случаях, когда необходима сортировка по многим ключам (k1, k2, k3…), планировщик теперь может воспользоваться знанием о том, что данные уже отсортированы по нескольким из первых ключей (например, k1 и k2). В этом случае можно не пересортировывать все данные заново, а разделить их на последовательные группы с одинаковыми значениями k1 и k2, и “досортировать” по ключу k3.
Таким образом вся сортировка распадается на несколько последовательных сортировок меньшего размера. Это снижает объем необходимой памяти, а еще позволяет выдавать первые данные раньше, чем вся сортировка будет выполнена полностью.
Incremental Sort (actual rows=2949857 loops=1) Sort Key: ticket_no, passenger_id Presorted Key: ticket_no Full-sort Groups: 92184 Sort Method: quicksort Memory: avg=31kB peak=31kB -> Index Scan using tickets_pkey on tickets (actual rows=2949857 loops=1) Planning Time: 2.137 ms Execution Time: 2230.019 ms
Улучшения UI/UX
Скриншоты, они везде!
Теперь на каждой вкладке появилась возможность быстро взять скриншот вкладки в буфер обмена на всю ширину и глубину вкладки — «прицел» справа-сверху:
Собственно, большинство картинок для этой публикации получено именно так.
Рекомендации на узлах
Их не только стало больше, но и про каждую можно подробно прочитать в статье, перейдя по ссылке:
Удаление из архива
Некоторые очень просили добавить возможность удалять «совсем» даже непубликуемые в архиве планы — пожалуйста, достаточно нажать соответствующую иконку:
Ну, и не забываем, что у нас есть группа поддержки, куда можно писать свои замечания и предложения.


