Совсем скоро, 20 ноября, у нас стартует новый поток «Математика и Machine Learning для Data Science», и в преддверии этого мы делимся с вами полезным переводом с подробным, иллюстрированным объяснением дерева решений, разъяснением энтропии дерева решений с формулами и простыми примерами, вводом понятия «информационный выигрыш», которое игнорируется большинством умозрительно-простых туториалов. Статья рассчитана на любящих математику новичков, которые хотят больше разобраться вработе дерева принятия решений. Для полной ясности взят совсем маленький набор данных. В конце статьи — ссылка на код на Github.

Дерево решений — тип контролируемого машинного обучения, который в основном используется в задачах классификации. Дерево решений само по себе — это в основном жадное, нисходящее, рекурсивное разбиение. «Жадное», потому что на каждом шагу выбирается лучшее разбиение. «Сверху вниз» — потому что мы начинаем с корневого узла, который содержит все записи, а затем делается разбиение.

Корневой узел — самый верхний узел в дереве решений называется корневой узел.
Узел принятия решения — подузел, который разделяется на дополнительные подузлы, известен как узел принятия решения.
Лист/терминальный узел — узел, который не разделяется на другие узлы, называется терминальный узел, или лист.
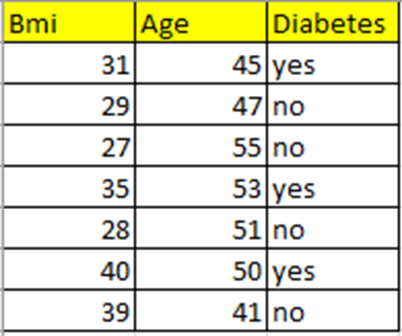
Я взяла совсем маленький набор данных, содержащий индекс массы тела (BMI), возраст (Age) и целевую переменную Diabetes (диабет). Давайте спрогнозируем, будет у человека данного возраста и индекса массы тела диабет или нет.

На графике невозможно провести какую-то прямую, чтобы определить границу принятия решения. Снова и снова мы разделяем данные, чтобы получить границу решения. Так работает алгоритм дерева решений.
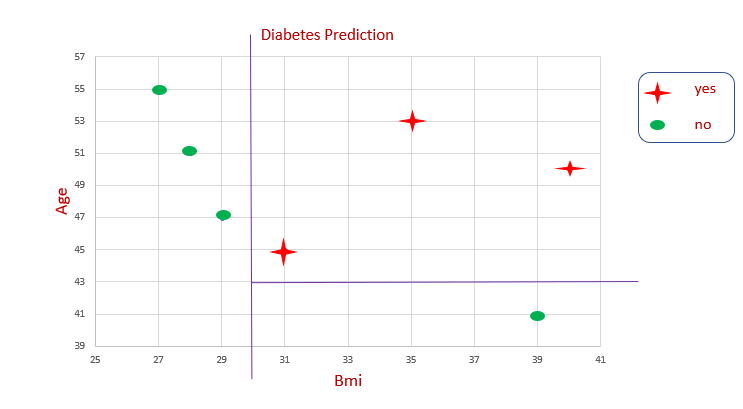
Вот так в дереве решений происходит разбиение.
Энтропия — это мера случайности или неопределенности. Уровень энтропии колеблется от
Энтропия вычисляется так: -(p(0) * log(P(0)) + p(1) * log(P(1)))

Когда энтропия равна 0, это означает, что подмножество «чистое», то есть в нем нет энтропии: либо все «да», либо все голоса «нет». Когда она равна 1, то это означает высокую степень случайности. Построим график вероятности P(1) вероятности принадлежности к классу 1 в зависимости от энтропии. Из объяснения выше мы знаем, что:
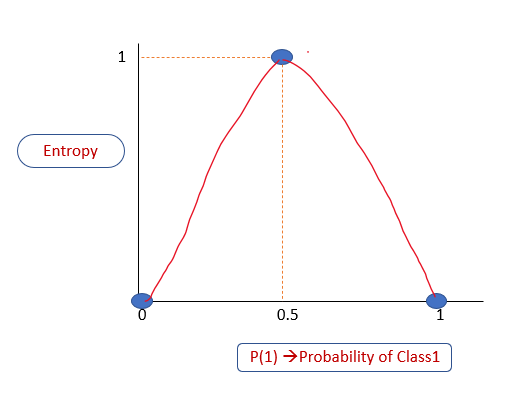
Уровень энтропии всегда находится в диапазоне от 0 до 1.
Информационный выигрыш для разбиения рассчитывается путем вычитания взвешенных энтропий каждой ветви из исходной энтропии. Используем его для принятия решения о порядке расположения атрибутов в узлах дерева решений.
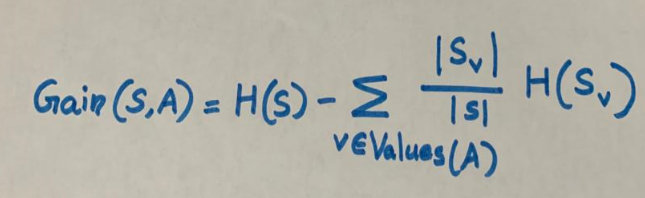
В нашем наборе данных два атрибута, BMI и Age. В базе данных семь записей. Построим дерево решений для нашего набора данных.
В дереве решений начнем с корневого узла. Возьмем все записи (в нашем наборе данных их семь) в качестве обучающих выборок.
Вычисляем энтропию корневого узла:

У нас есть два атрибута — BMI и Age. Как на основе этих атрибутов происходит разбиение? Как проверить эффективность разбиения?
1. При выборе атрибута BMI в качестве переменной разделения и ≤30 в качестве точки разделения мы получим одно чистое подмножество.
Точки разбиения рассматриваются для каждой точки набора данных. Таким образом, если точки данных уникальны, то для n точек данных будет n-1 точек разбиения. То есть в зависимости от выбранных точки и переменной разбиения мы получаем высокий информационный выигрыш и выбираем разделение с этим выигрышем. В большом наборе данных принято считать только точки разделения при определенных процентах распределения значений: 10, 20, 30%. У нас набор данных небольшой, поэтому, видя все точки разделения данных, я выбрала в качестве точки разделения значения ≤30.
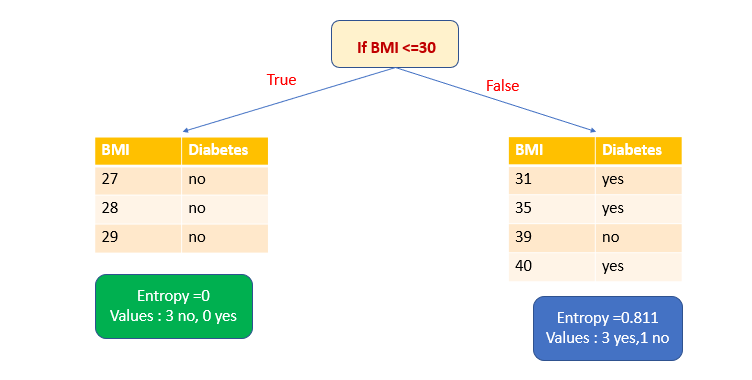
Энтропия чистого подмножества равна нулю. Теперь рассчитаем энтропию другого подмножества. Здесь у нас три голоса за и один против.

Чтобы решить, какой атрибут выбрать для разбиения, нужно вычислить информационный выигрыш.

2. Выберем атрибут Age в качестве переменной разбиения и ≤45 в качестве точки разбиения.
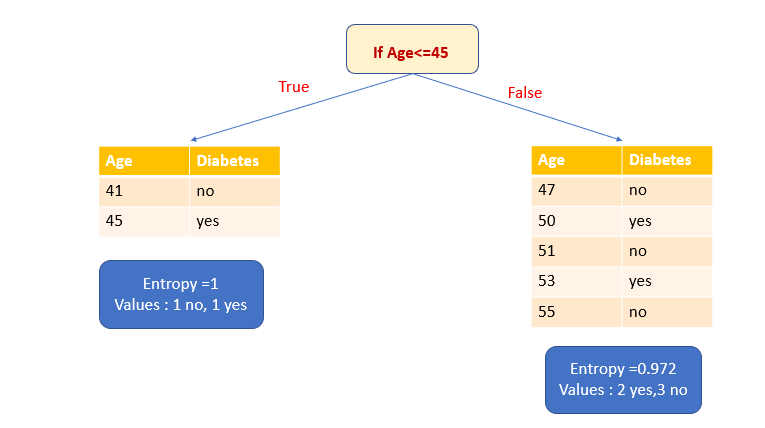
Давайте сначала вычислим энтропию подмножества True. У него есть одно да и одно нет. Это высокий уровень неопределенности. Энтропия равна 1. Теперь рассчитаем энтропию подмножества False. В нем два голоса за и три против.

3. Рассчитаем информационный выигрыш.

Мы должны выбрать атрибут, имеющий высокий информационный выигрыш. В нашем примере такую ценность имеет только атрибут BMI. Таким образом, атрибут BMI выбирается в качестве переменной разбиения. После разбиения по атрибуту BMI мы получаем одно чистое подмножество (листовой узел) и одно нечистое подмножество. Снова разделим это нечистое подмножество на основе атрибута Age. Теперь у нас есть два чистых подмножества (листовой узел).
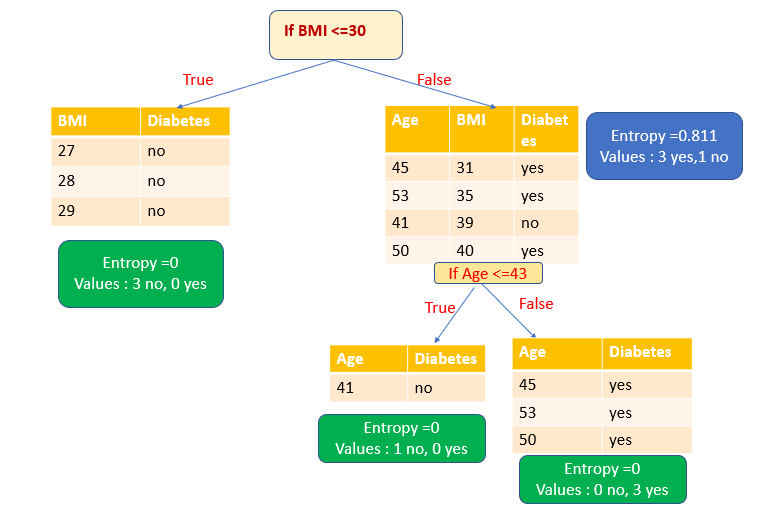
Итак, мы создали дерево решений с чистыми подмножествами.
1. Импортируем библиотеки.
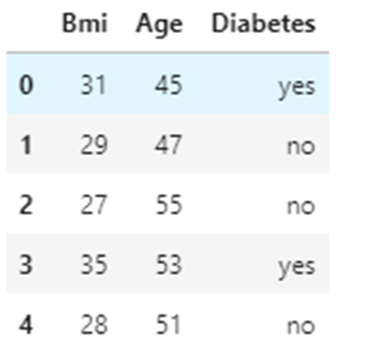
2. Загрузим данные.
3. Разделим переменные на x и y.
Атрибуты BMI и Age принимаются за x.
Атрибут Diabetes (целевая переменная) принимается за y.


4. Построим модель с помощью sklearn
Вывод:
5. Оценка модели
Вывод:
6. Прогнозирование с помощью модели
Давайте предскажем, будет ли диабет у человека 47 лет с ИМТ 29. Напомню, что эти данные есть в нашем наборе данных.
Вывод:
Прогноз — нет, такой же, как и в наборе данных. Теперь спрогнозируем, будет ли диабет у человека 47 лет с индексом массы тела 45. Отмечу, что этих данных в нашем наборе нет.
Вывод:
Прогноз положительный.
7. Визуализация модели:

Код и набор данных из этой статьи доступны на GitHub.
Приходите изумать математику к нам, на курс «Математика и Machine Learning для Data Science» а промокод HABR, добавит 10 % к скидке на баннере.

Дерево решений — тип контролируемого машинного обучения, который в основном используется в задачах классификации. Дерево решений само по себе — это в основном жадное, нисходящее, рекурсивное разбиение. «Жадное», потому что на каждом шагу выбирается лучшее разбиение. «Сверху вниз» — потому что мы начинаем с корневого узла, который содержит все записи, а затем делается разбиение.
Корневой узел — самый верхний узел в дереве решений называется корневой узел.
Узел принятия решения — подузел, который разделяется на дополнительные подузлы, известен как узел принятия решения.
Лист/терминальный узел — узел, который не разделяется на другие узлы, называется терминальный узел, или лист.
Набор данных
Я взяла совсем маленький набор данных, содержащий индекс массы тела (BMI), возраст (Age) и целевую переменную Diabetes (диабет). Давайте спрогнозируем, будет у человека данного возраста и индекса массы тела диабет или нет.
Представление набора данных
На графике невозможно провести какую-то прямую, чтобы определить границу принятия решения. Снова и снова мы разделяем данные, чтобы получить границу решения. Так работает алгоритм дерева решений.
Вот так в дереве решений происходит разбиение.
Важные теоретические определения
Энтропия
Энтропия — это мера случайности или неопределенности. Уровень энтропии колеблется от
0 до 1. Когда энтропия равна 0, это означает, что подмножество чистое, то есть в нем нет случайных элементов. Когда энтропия равна 1, это означает высокую степень случайности. Энтропия обозначается символами H(S).Формула энтропии
Энтропия вычисляется так: -(p(0) * log(P(0)) + p(1) * log(P(1)))
P(0) → Вероятность принадлежности к класу0
P(1) → Вероятность принадлежности к классу1
Связь между энтропией и вероятностью
Когда энтропия равна 0, это означает, что подмножество «чистое», то есть в нем нет энтропии: либо все «да», либо все голоса «нет». Когда она равна 1, то это означает высокую степень случайности. Построим график вероятности P(1) вероятности принадлежности к классу 1 в зависимости от энтропии. Из объяснения выше мы знаем, что:
Если P(1) равно 0, то энтропия равна 0
Если P(1) равно 1, то энтропия равна 0
Если P(1) равно 0,5, то энтропия равна 1
Уровень энтропии всегда находится в диапазоне от 0 до 1.
Информационный выигрыш
Информационный выигрыш для разбиения рассчитывается путем вычитания взвешенных энтропий каждой ветви из исходной энтропии. Используем его для принятия решения о порядке расположения атрибутов в узлах дерева решений.
H(S) → Энтропия
A → Атрибут
S → Множество примеров {x}
V → Возможные значения A
Sv → Подмножество
Как работает дерево решений
В нашем наборе данных два атрибута, BMI и Age. В базе данных семь записей. Построим дерево решений для нашего набора данных.
1. Корневой узел
В дереве решений начнем с корневого узла. Возьмем все записи (в нашем наборе данных их семь) в качестве обучающих выборок.
В корневом узле наблюдаем три голоса за и четыре против.
Вероятность принадлежности к классу 0 равна 4/7. Четыре из семи записей принадлежат к классу 0.
P(0) = 4/7
Вероятность принадлежности к классу 1 равна 3/7. То есть три из семи записей принадлежат классу 1.
P(1) = 3/7.
Вычисляем энтропию корневого узла:
2. Как происходит разбиение?
У нас есть два атрибута — BMI и Age. Как на основе этих атрибутов происходит разбиение? Как проверить эффективность разбиения?
1. При выборе атрибута BMI в качестве переменной разделения и ≤30 в качестве точки разделения мы получим одно чистое подмножество.
Точки разбиения рассматриваются для каждой точки набора данных. Таким образом, если точки данных уникальны, то для n точек данных будет n-1 точек разбиения. То есть в зависимости от выбранных точки и переменной разбиения мы получаем высокий информационный выигрыш и выбираем разделение с этим выигрышем. В большом наборе данных принято считать только точки разделения при определенных процентах распределения значений: 10, 20, 30%. У нас набор данных небольшой, поэтому, видя все точки разделения данных, я выбрала в качестве точки разделения значения ≤30.
Энтропия чистого подмножества равна нулю. Теперь рассчитаем энтропию другого подмножества. Здесь у нас три голоса за и один против.
P(0)=1/4 [одна из четырех записей)
P(1)=3/4 [три из четырех записей)
Чтобы решить, какой атрибут выбрать для разбиения, нужно вычислить информационный выигрыш.
2. Выберем атрибут Age в качестве переменной разбиения и ≤45 в качестве точки разбиения.
Давайте сначала вычислим энтропию подмножества True. У него есть одно да и одно нет. Это высокий уровень неопределенности. Энтропия равна 1. Теперь рассчитаем энтропию подмножества False. В нем два голоса за и три против.
3. Рассчитаем информационный выигрыш.
Мы должны выбрать атрибут, имеющий высокий информационный выигрыш. В нашем примере такую ценность имеет только атрибут BMI. Таким образом, атрибут BMI выбирается в качестве переменной разбиения. После разбиения по атрибуту BMI мы получаем одно чистое подмножество (листовой узел) и одно нечистое подмножество. Снова разделим это нечистое подмножество на основе атрибута Age. Теперь у нас есть два чистых подмножества (листовой узел).
Итак, мы создали дерево решений с чистыми подмножествами.
Напишем это на Python с помощью sklearn
1. Импортируем библиотеки.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
2. Загрузим данные.
df=pd.read_csv("Diabetes1.csv")
df.head()
3. Разделим переменные на x и y.
Атрибуты BMI и Age принимаются за x.
Атрибут Diabetes (целевая переменная) принимается за y.
x=df.iloc[:,:2]
y=df.iloc[:,2:]x.head(3)
y.head(3)
4. Построим модель с помощью sklearn
from sklearn import tree
model=tree.DecisionTreeClassifier(criterion="entropy")
model.fit(x,y)
Вывод:
DecisionTreeClassifier (criterion=«entropy»)5. Оценка модели
model.score(x,y)
Вывод:
1.0. Мы взяли очень маленький набор данных, поэтому оценка равна 1.6. Прогнозирование с помощью модели
Давайте предскажем, будет ли диабет у человека 47 лет с ИМТ 29. Напомню, что эти данные есть в нашем наборе данных.
model.predict([[29,47]])
Вывод:
array([‘no’], dtype=object)Прогноз — нет, такой же, как и в наборе данных. Теперь спрогнозируем, будет ли диабет у человека 47 лет с индексом массы тела 45. Отмечу, что этих данных в нашем наборе нет.
model.predict([[45,47]])
Вывод:
array([‘yes’], dtype=object)Прогноз положительный.
7. Визуализация модели:
tree.plot_tree(model)
Код и набор данных из этой статьи доступны на GitHub.
Приходите изумать математику к нам, на курс «Математика и Machine Learning для Data Science» а промокод HABR, добавит 10 % к скидке на баннере.
- «Математика и Machine Learning для Data Science»
- Продвинутый курс «Machine Learning Pro + Deep Learning»
- Курс «Python для веб-разработки»
- Обучение профессии Data Science
- Обучение профессии Data Analyst
- Онлайн-буткемп по Data Analytics
Eще курсы
- Курс по Machine Learning
- Курс по JavaScript
- Профессия Веб-разработчик
- Профессия Java-разработчик
- C++ разработчик
- Курс по аналитике данных
- Курс по DevOps
- Разработчик игр на Unity
- Профессия iOS-разработчик с нуля
- Профессия Android-разработчик с нуля
Рекомендуемые статьи
- Как стать Data Scientist без онлайн-курсов
- 450 бесплатных курсов от Лиги Плюща
- Как изучать Machine Learning 5 дней в неделю 9 месяцев подряд
- Сколько зарабатывает аналитик данных: обзор зарплат и вакансий в России и за рубежом в 2020
- Machine Learning и Computer Vision в добывающей промышленности


