
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Главные вопросы работы с базой данных связаны с особенностями устройства операционной системы, на которой работает база. Сейчас Linux — основная операционная система для баз данных. Solaris, Microsoft и даже HPUX все еще применяются в энтерпрайзе, но первое место им больше никогда не занять, даже вместе взятым. Linux уверенно завоевывает позиции, потому что open source баз данных все больше. Поэтому вопрос взаимодействия БД с ОС, очевидно, о базах данных в Linux. На это накладывается вечная проблема БД — производительность IO. Хорошо, что в Linux последние годы идет капитальный ремонт IO-стека и есть надежда на просветление.
Илья Космодемьянский (hydrobiont) работает в компании Data Egret, которая занимается консалтингом и поддержкой PostgreSQL, и про взаимодействие ОС и баз данных знает многое. В докладе на HighLoad++ Илья рассказал о взаимодействии IO и БД на примере PostgreSQL, но и показал, как с IO работают другие БД. Рассмотрел стек Linux IO, что нового и хорошего в нем появилось и почему все не так, как было пару лет назад. В качестве полезной памятки — контрольный список настроек PostgreSQL и Linux для максимальной производительности подсистемы IO в новых ядрах.
В видео доклада много английского языка, большую часть которого в статье мы перевели.
Быстрый ввод/вывод — это самая критичная вещь для администраторов баз данных. Все знают, что можно изменить в работе с CPU, что память можно расширить, но ввод/вывод способен все испортить. Если плохо с дисками, и слишком много ввода/вывода, то БД будет стонать. IO станет бутылочным горлышком.
Не только БД или только железо — всё. Даже высокоуровневый Oracle, который сам себе местами операционная система, требует настройки. Читаем инструкции в «Installation guide» от Oracle: поменять такие параметры ядра, поменять другие — настроек много. Не считая того, что в Unbreakable Kernel уже многое по умолчанию зашито на Oracle’овых Linux’ах.
Для PostgreSQL и MySQL изменений требуется еще больше. Все потому, что эти технологии опираются на механизмы ОС. DBA, который работает с PostgreSQL, MySQL или современными NoSQL, должен быть «Linux operation engineer» и крутить разные гайки ОС.
Каждый, кто хочет разобраться с настройками ядра, обращается к LWN. Ресурс гениальный, минималистичный, содержит много полезной информации, но написан разработчиками ядра для разработчиков ядра. Что хорошо пишут разработчики ядра? Ядро, а не статьи, как его использовать. Поэтому я попробую вам все объяснить за разработчиков, а они пусть ядро пишут.
Все многократно усложняется тем, что изначально разработка ядра Linux и переработка его стека отставали, а в последние годы пошли очень быстро. Ни железо, ни разработчики со статьями за ним не поспевают.
Начнем с примеров для PostgreSQL — здесь буферизованный ввод-вывод. У него шаренная память, которая распределяется в User space с точки зрения ОС, и имеет такой же кэша в кэше ядра в Kernel space.

Основная задача современной БД:
В ситуации PostgreSQL это постоянное путешествие туда и обратно: из шаренной памяти, которой управляет PostgreSQL в Page Cache ядра, и дальше на диск через весь стек Linux. Если вы используете БД на файловой системе, она будет работать по этому алгоритму с любой UNIX-подобной системой и с любой БД. Отличия есть, но незначительны.
При использовании Oracle ASM будет по-другому — Oracle сам взаимодействует с диском. Но принцип тот же: с Direct IO или с Page Cache, но задача — как можно быстрее провести странички через весь стек ввода/вывода, каким бы он ни был. И проблемы могут возникнуть на каждом этапе.
Пока все read only, проблем нет. Прочитали и, если достаточно памяти, все данные, которые нужно считать, помещаются в оперативную память. То, что при этом в случае PostgreSQL в Buffer Cache лежит то же самое, нас не очень волнует.
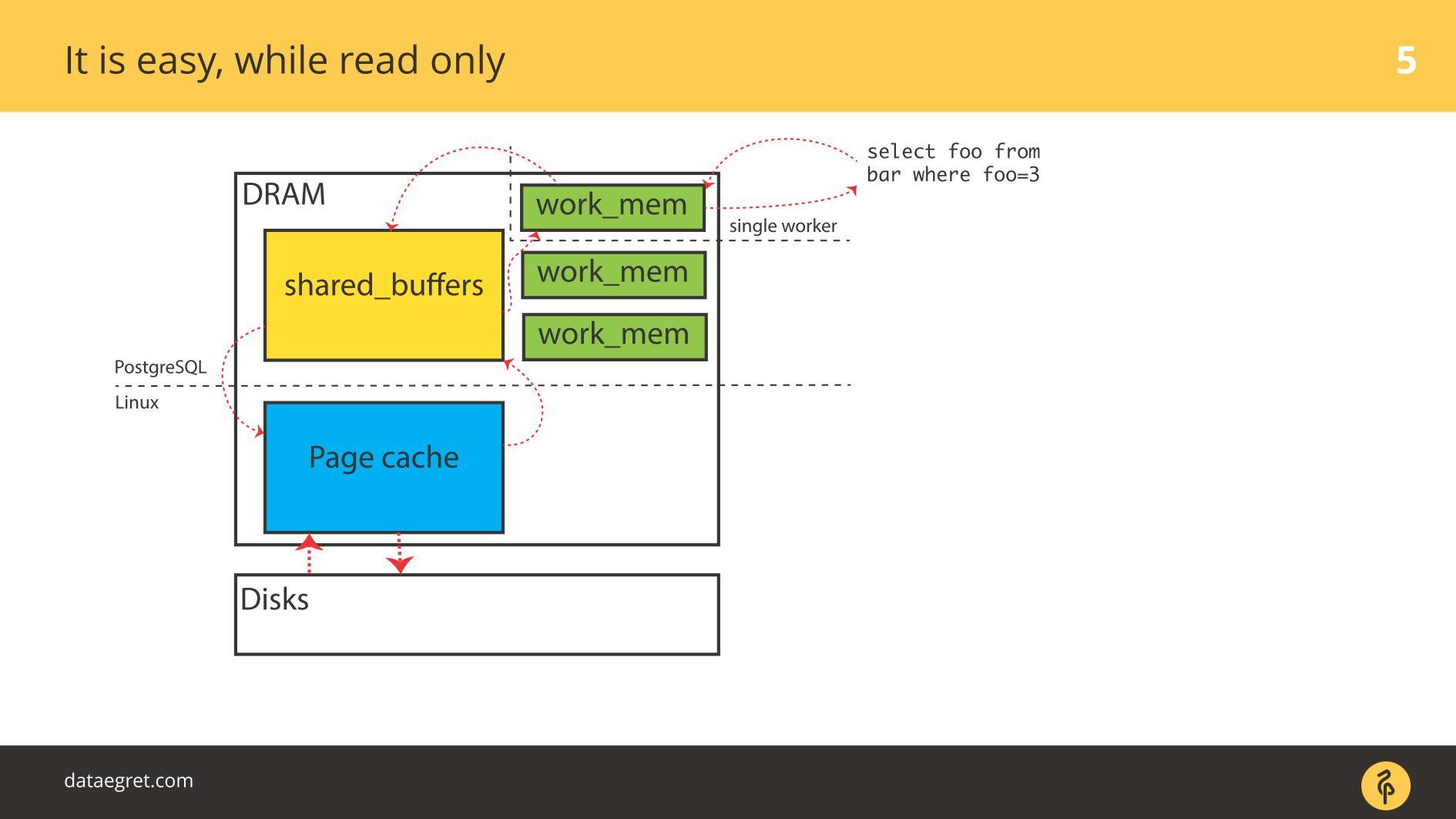
Первая проблема с IO — синхронизация кэша. Возникает, когда требуется запись. В этом случае придется гонять туда и обратно гораздо больше памяти.
Соответственно, необходимо настроить PostgreSQL или MySQL, чтобы из шаренной памяти это все попало на диск. В случае с PostgreSQL — надо еще хорошо настроить фоновое списывание грязных страниц в Linux, чтобы отправить все на диск.
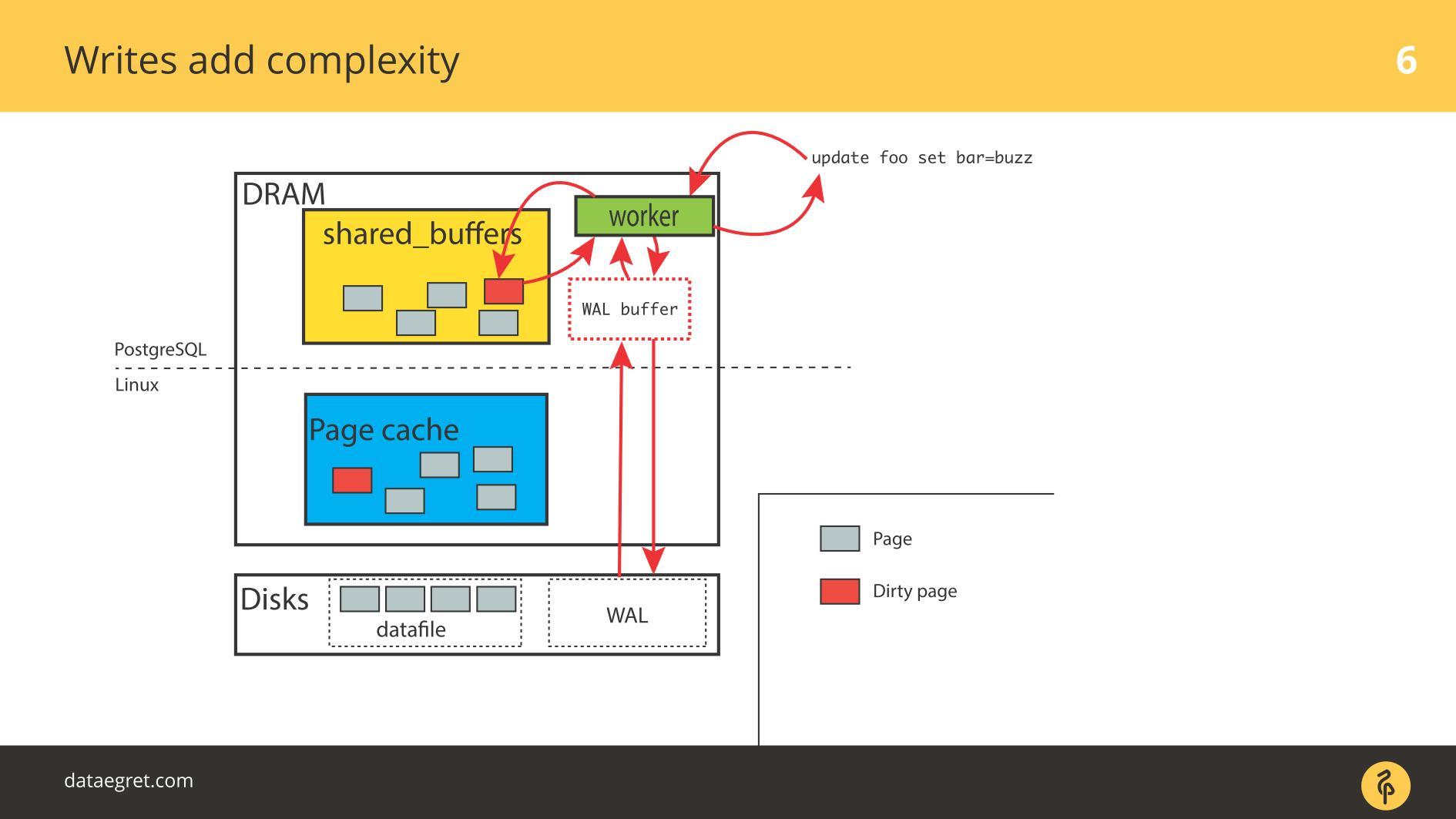
Вторая частая проблема — сбой записи Write-Ahead Log. Проявляется, когда нагрузка настолько мощная, что даже последовательно записываемый журнал упирается в диск. В этой ситуации его тоже надо записать быстро.
Ситуация мало отличается от синхронизации кэша. В PostgreSQL мы работаем с большим количеством шаренных буферов, в базе есть механизмы для эффективной записи Write-Ahead Log, он до предела оптимизирован. Единственное, что можно сделать, чтобы сам лог писался эффективнее — поменять настройки Linux.
Сегмент шаренной памяти может быть очень большим. Я начинал об этом рассказывать на конференциях в 2012 году. Тогда я говорил, что память подешевела, даже встречаются серверы с 32 Гб оперативной памяти. В 2019 уже и в ноутбуках может быть больше, на серверах все чаще стоит 128, 256 и т.д.
Памяти действительно много. Банальная запись занимает время и ресурсы, а технологии, которые мы для этого используем, консервативны. БД старые, их давно разрабатывают, они медленно эволюционируют. Механизмы в базах не то чтобы прямо по последнему слову техники.
Синхронизация страниц в памяти с диском приводит к огромным операциям IO. Когда мы синхронизируем кэши, возникает большой поток IO, и встает еще одна проблема — мы не можем что-то покрутить и посмотреть на эффект. В научном эксперименте исследователи меняют один параметр — получают эффект, второй — получают эффект, третий. У нас так не получится. Мы крутим какие-то параметры в PostgreSQL, настраиваем checkpoints — эффекта не увидели. Дальше опять настраивать весь стек, чтобы поймать хоть какой-то результат. Покрутить один параметр не получится — мы вынуждены настраивать сразу всё.
Большинство IO в PostgreSQL генерирует синхронизация страниц: checkpoints и другие механизмы синхронизации. Если вы работали с PostgreSQL, возможно, видели checkpoints spikes, когда на графиках периодически возникает «пила». Раньше многие сталкивались с такой проблемой, но сейчас есть мануалы, как это чинить, стало проще.
SSD сегодня сильно спасают ситуацию. У PostgreSQL редко что-то упирается непосредственно в запись value. Все упирается в синхронизацию: когда происходит checkpoint, вызывается fsync и происходит как бы «наезд» одного checkpoint на другой. Слишком много IO. Один checkpoint еще не закончился, не выполнил все свои fsyncs, а уже заработал другой checkpoint, и началось!
У PostgreSQL есть уникальная фишка — autovacuum. Это многолетняя история костылей под архитектуру БД. Если autovacuum не справляется, обычно его настраивают, чтобы он работал агрессивно и не мешал остальным: много воркеров autovacuum, частое срабатывание по чуть-чуть, обработка таблиц быстро. Иначе будут проблемы с DDL и с блокировками.
Если работа autovacuum накладывается на checkpoints, то большую часть времени диски утилизованы почти на 100%, и это источник проблем.
Как ни странно, бывает проблема Cache refill. Она обычно меньше известна DBA. Типичный пример: БД стартовала, и какое-то время все печально тормозит. Поэтому даже если у вас много-много оперативки — докупайте хорошие диски, чтобы стек прогревал кэш.
Все это серьезно влияет на производительность. Проблемы начинаются не сразу после рестарта БД, а позже. Например, прошел checkpoint, и много страниц запачкано во всей базе. Они скопированы на диск, потому что нужно их синхронизовать. Потом запросы спрашивают новую версию страниц с диска, и база проседает. На графиках будет видно, как Cache refill после каждого checkpoint вносит определенный процент в нагрузку.
Самая неприятное во вводе/выводе БД — Worker IO. Когда каждый воркер, к которому вы обращаетесь с запросом, начинает генерировать свой IO. В Oracle с ним проще, а в PostgreSQL — проблема.
Причин проблем с Worker IO много: не хватает кэша, чтобы «провести» новые страницы с диска. Например, бывает что все буферы шаренные, они все попачканы, checkpoints еще не было. Чтобы воркер выполнил простейший select, нужно откуда-то взять кэш. Для этого сначала нужно сохранить это все на диск. У вас не специализированный процесс checkpointer, и воркер начинает выполнять fsync, чтобы освободить и заполнить его чем-то новым.
Тут возникает еще большая проблема: воркер — неспециализированная вещь, и весь процесс вообще никак не оптимизирован. Можно на уровне Linux где-то оптимизировать, но в PostgreSQL это аварийная мера.
Какую проблему мы решаем, когда что-то настраиваем? Мы хотим максимизировать путешествие грязных страниц между диском и памятью.
Но часто бывает так, что эти вещи напрямую не касаются диска. Типичный случай — вы видите очень большой load average. Почему так? Потому что кто-то ждет диск, и все остальные процессы тоже ждут. Вроде бы нет явной утилизации дисков по записи, просто что-то там заблокировало диск, а проблема все равно с вводом/выводом.
В этой проблеме задействовано все: диски, память, CPU, IO Schedulers, файловые системы и настройки самой БД. Сейчас пройдемся по стеку, посмотрим, что с этим делать, и что хорошего в Linux изобрели, чтобы все работало лучше.
Долгие годы диски были страшно медленные и никто не занимался latency или оптимизацией стадий перехода. Оптимизация fsyncs не имела смысла. Диск вращался, по нему как по грампластинке ездили головки, и fsyncs был настолько длинный, что проблемы не всплывали.
Без настройки БД топ запросов смотреть бесполезно. Вы настроите достаточное количество шаренной памяти и т.д, и у вас будет новый топ запросов — настраивать придется заново. Здесь та же история. Весь стек Linux был сделан из этого расчета.
Максимизировать производительность IO через максимизацию пропускной способности легко до определенного момента. Придуман вспомогательный процесс PageWriter в PostgreSQL, который разгружал checkpoint. Работа стала параллельной, но задел для добавки параллелизма еще есть. А минимизировать latency — это задача последней мили, для которой нужны супертехнологии.
Этими супертехнологиями стали SSD. Когда они появились, latency резко снизилась. Зато на всех остальных этапах стека проявились проблемы: и со стороны производителей БД, и со стороны производителей Linux. Проблемы требуют решения.
Разработка БД была сосредоточена вокруг максимизации пропускной способности, также как и разработка ядра Linux. Многие методы оптимизации ввода-вывода эпохи вращающихся дисков не так хороши для SSD.
В промежутке мы были вынуждены ставить подпорки для текущей инфраструктуры Linux, но уже с новыми дисками. Смотрели performance-тесты от производителя с большим количеством разных IOPS, а БД лучше не становилось, потому что БД не только и не столько про IOPS. Часто бывает, что мы можем пропустить 50 000 IOPS в секунду, и это хорошо. Но если мы не знаем latency, не знаем ее распределение, то ничего не можем сказать о производительности. В какой-то момент БД начнет делать checkpoint, и latency резко увеличится.
Долгое время, как и сейчас, это было большой проблемой производительности на виртуалках для баз данных. Virtual IO свойственна неравномерность latency, что, конечно, тоже влечет проблемы.
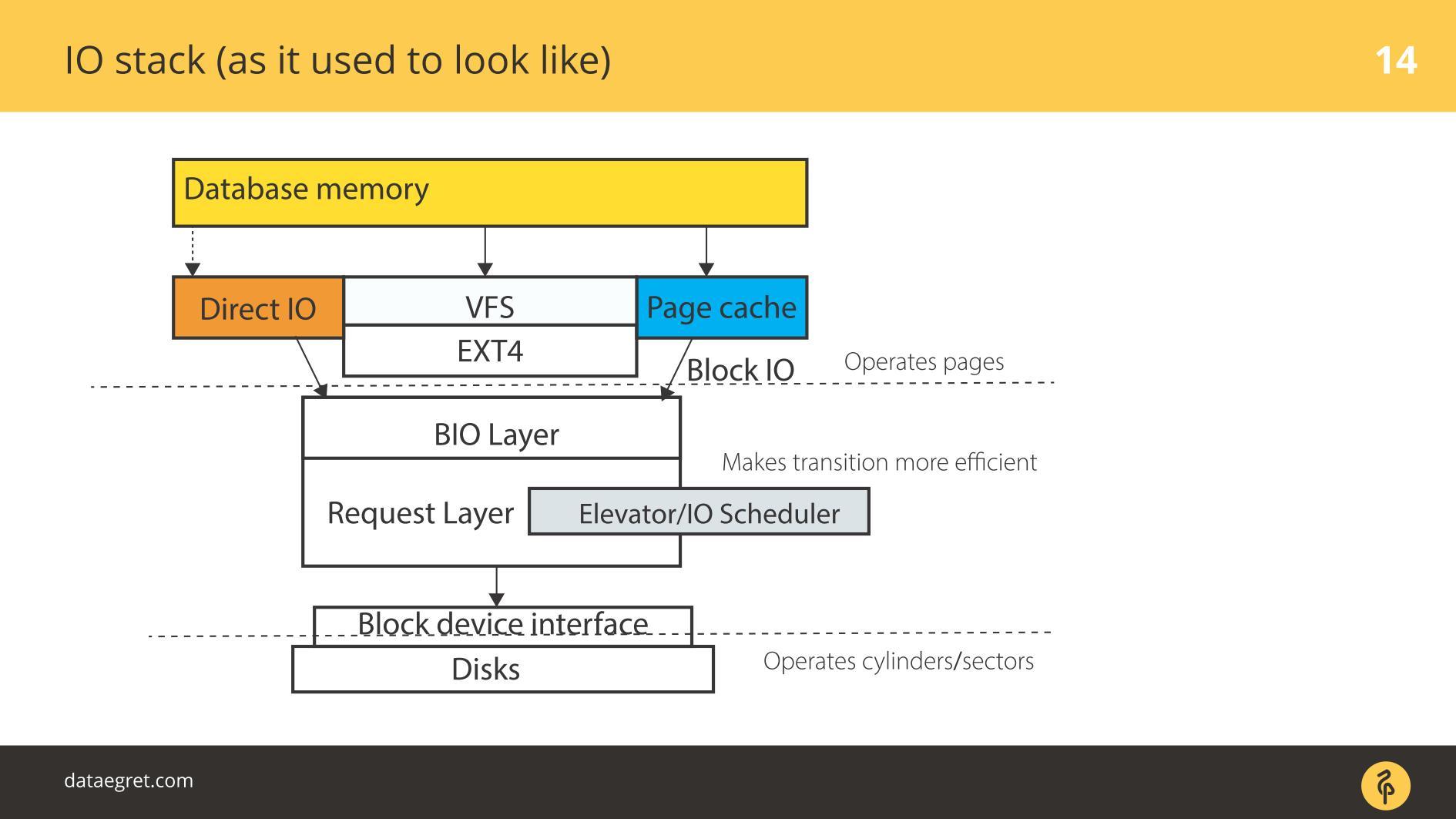
Здесь есть User space — та память, которая управляется самой базой данных. В БД настроили так, чтобы все работало как надо. Об этом можно сделать отдельный доклад, и даже не один. Дальше все неизбежно идет через Page Cache либо через интерфейс Direct IO попадает в Block Input/Output-слой.
Представьте себе интерфейс файловой системы. Через него съезжают странички, которые были в Buffer Cache, как они изначально были в БД, то есть блоками. Block IO-слой занимается следующим. Есть C-структура, которая описывает блок в ядре. Структура берет эти блоки и собирает из них векторы (массивы) запросов на ввод или вывод. Под BIO-слоем находится слой реквестов. На этом слое собираются векторы и отправятся дальше.
Долгое время эти два слоя в Linux были заточены на эффективную запись на магнитные диски. Без перехода было не обойтись. Есть блоки, которыми удобно управлять из базы данных. Нужно эти блоки собрать в векторы, которые удобно записать на диск, чтобы они где-то рядом лежали. Чтобы это эффективно работало, придумали Elevators, или Schedulers IO.
Elevators преимущественно занимались тем, что объединяли и сортировали векторы. Все для того, чтобы в блочный драйвер SD — драйвер квазидиска — блоки для записи приехали в удобном для него порядке. Драйвер производил трансляцию из блоков в свои секторы и писал на диск.
Проблема была в том, что нужно было делать несколько transitions, и на каждом реализовывать свою логику оптимального процесса.
До ядра 2.6 существовал Linus Elevator – самый примитивный IO Scheduler, который написан сами догадаетесь кем. Долгое время он считался абсолютно незыблемым и хорошим, пока не разработали что-то новое.
Linus Elevator имел много проблем. Он объединял и сортировал в зависимости от того, как эффективнее записать. В случае с вращающимися механическими дисками это приводило к тому, что возникал «starvation»: ситуация, когда эффективность записи зависит от поворота диска. Если внезапно нужно одновременно эффективно прочитать, а он уже повернут не так — читается с такого диска плохо.
Постепенно стало понятно, что это неэффективный путь. Поэтому начиная с ядра 2.6 стал появляться целый зоопарк schedulers, который предназначался для разных задач.
Многие путают эти schedulers с schedulers операционной системы, потому что у них похожие названия. CFQ — Completely Fair Queuing — это не то же самое, что schedulers ОС. Просто названия похожи. Он был придуман как универсальный scheduler.
Что такое универсальный scheduler? Как вы считаете, у вас усредненная нагрузка или, наоборот, уникальная? У баз данных очень плохо с универсальностью. Универсальную нагрузку можно представить себе как работу обычного ноутбука. Там происходит все подряд: мы слушаем музыку, играем, набираем текст. Для этого как раз универсальные schedulers и писались.
Основная задача универсального scheduler: в случае Linux для каждого виртуального терминала и процесса создать свою очередь запросов. Когда мы хотим послушать музыку в аудиопроигрывателе, IO для проигрывателя занимает очередь. Если мы хотим забэкапить что-нибудь с помощью команды cp, этим занимается что-то еще.
В случае с базами данных возникает проблема. Как правило, БД — это процесс, который стартовал, и во время работы возникли параллельные процессы, которые всегда заканчиваются в одной и той же очереди ввода/вывода. Причина в том, что это одно и то же приложение, один и тот же родительский процесс. Для очень небольших нагрузок такой scheduling подходил, для остальных не имел смысла. Его было проще выключить и не использовать, если это возможно.
Постепенно появился deadline scheduler — работает хитрее, но базово это merge и сортировка для вращающихся дисков. С учетом устройства конкретной дисковой подсистемы мы собираем векторы блоков, чтобы записать их оптимальным способом. У него было меньше проблем со «starvation», но они там были.
Поэтому ближе к третьим ядрам Linux появился noop или none, который гораздо лучше работал с распространившимися SSD. Включая scheduler noop, мы фактически отключаем scheduling: нет сортировок, мерджинга и подобных вещей, которыми занимались CFQ и deadline.
Это лучше работает с SSD, потому что SSD от природы параллельный: у него есть ячейки памяти. Чем больше этих элементов напихать на одной PCIe плате, тем эффективнее все будет работать.
Scheduler из каких-то своих потусторонних, с точки зрения SSD, соображений, собирает какие-то векторы и куда-то их отправляет. Это все заканчивается воронкой. Так мы убиваем параллелизм SSD, не используем их на полную катушку. Поэтому простое отключение, когда векторы едут как попало без всякой сортировки, срабатывало лучше с точки зрения производительности. Из-за этого считается, что на SSD лучше идут random read, random write.
Начиная с ядра 3.13 появился blk-mq. Немного раньше был прототип, но в 3.13 впервые появилась рабочая версия.
Начинался blk-mq как scheduler, но scheduler’ом его назвать сложно — архитектурно он стоит отдельно. Это замена request layer в ядре. Потихоньку разработка blk-mq привела к серьезной переработке всего стека ввода/вывода Linux.
Идея такая: давайте для ввода/вывода использовать нативную возможность SSD делать эффективный параллелизм. В зависимости от того, сколько параллельных потоков ввода/вывода можно использовать, есть честные очереди, через которые мы просто пишем as is на SSD. Для каждой CPU есть своя очередь для записи.
В настоящий момент blk-mq активно развивается и работает. Нет причин его не использовать. В современных ядрах, от 4 и выше, от blk-mq выигрыш ощутим — не 5-10%, а существенно больше.
В нынешнем виде blk-mq напрямую завязан на NVMe driver Linux. Есть не только драйвер для Linux, но и драйвер для Microsoft. Но именно идея сделать blk-mq и NVMe driver — это та самая переработка стека Linux, от которой базы данных здорово выиграли.
Консорциум из нескольких компаний решил сделать спецификацию, этот самый протокол. Сейчас он уже в продакшн-версии отлично работает для локальных PCIe SSD. Практически готово решение для дисковых массивов, которые подключаются по оптике.
Давайте в нее погрузимся, чтобы понять, что это такое. Спецификация NVMe большая, поэтому все подробности не рассмотрим, а только пробежимся по ним.

Простейший случай: есть CPU, есть его очередь, и мы как-то идем на диск.
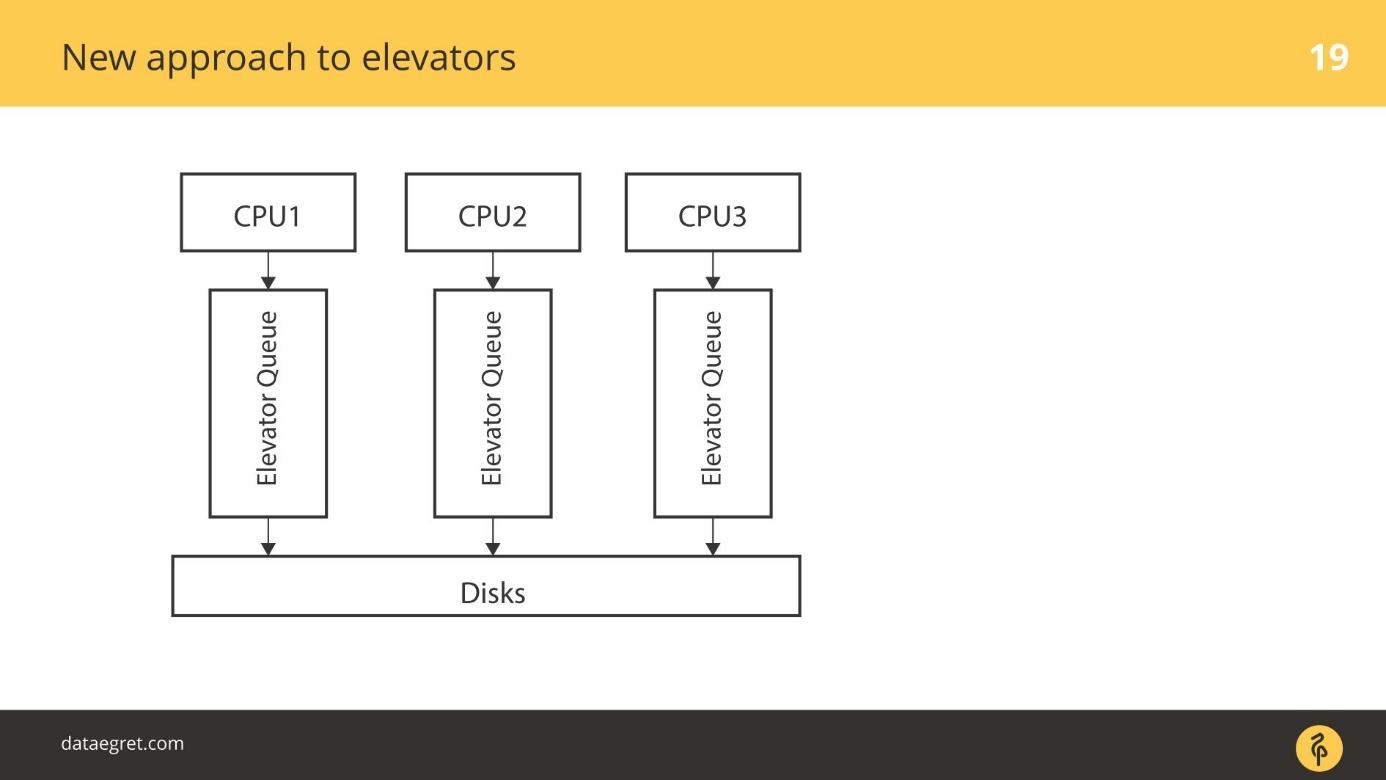
Более продвинутые Elevators работали по-другому. Есть несколько CPU и несколько очередей. Каким-то образом, например, в зависимости от того, от какого родительского процесса отпочковались воркеры БД, IO попадает в очередь и на диски.
blk-mq — это абсолютно новый подход. Каждый CPU, каждая NUMA-зона добавляет свой ввод/вывод в свою очередь. Дальше данные попадают на диски, не важно, как подключенными, потому что драйвер новый. Там нет SD драйвера, который оперирует понятиями цилиндров, блоков.
Был переходный период. В какой-то момент все вендоры RAID-массивов стали продавать аддоны, которые позволяли обходить кэш RAID. Если подключены SSD — напрямую писать туда. Они отключали применение SD-драйвера для своих продуктов, как blq-mq.
Так выглядит стек в новом виде.

Сверху все осталось также. Например, БД сильно отстают. Ввод/вывод от БД точно также, как раньше, попадает в Block IO-слой. Там есть тот самый blk-mq, который заменяет слой запросов, а не scheduler.
В ядре 3.13 примерно на этом заканчивалась вся оптимизация, но в современных ядрах используются новые технологии. Стали появляться специальные schedulers для blk-mq, которые рассчитаны на более сильный параллелизм. В современных четвертых ядрах Linux зрелыми считаются два schedulers IO — это Kyber и BFQ. Они рассчитаны на работу с параллелизмом и с blk-mq.
BFQ — Budget Fair Queueing — это аналог СFQ. Они абсолютно непохожи, хотя один вырос из другого. BFQ — это scheduler со сложной математикой. Каждое приложение и процесс имеет некоторую квоту на IO. Квота зависит от объема IO, который процесс/приложение генерирует. Согласно этому бюджету у нас есть полоса, в которую пишем. Насколько хорошо это работает — вопрос сложный. Если интересуетесь BFQ, есть масса статей, которые разбирают математику процесса.
Kyber — это альтернатива. Это как BFQ, но без математики. У Kyber небольшой scheduler по количеству кода. Его основная задача — принимать от CPU и отправлять. Kyber легковеснее и работает лучше.
Важный момент для всего стека — blk-mq не смотрит в SD-драйвер. У него нет очередного слоя конверсии, на который я жаловался, когда показывал, как раньше выглядел IO-стек. Из blk-mq в NVMe driver все приходит сразу в готовом виде. Блоки в цилиндры не пересчитываются.
В новом подходе возникло несколько интересных моментов — резко упала latency, и этого слоя в том числе. Сначала появились SSD, которые хорошо работают — появилась возможность перерабатывать этот слой. Как только мы перестали конвертировать туда-сюда, выяснилось, что и в NVMe-слое, и в blk-mq есть свои узкие места, которые тоже надо оптимизировать. Сейчас о них поговорим.
У Томаса Кренна есть постоянно обновляемая и актуальная диаграмма стека ввода/вывода Linux.
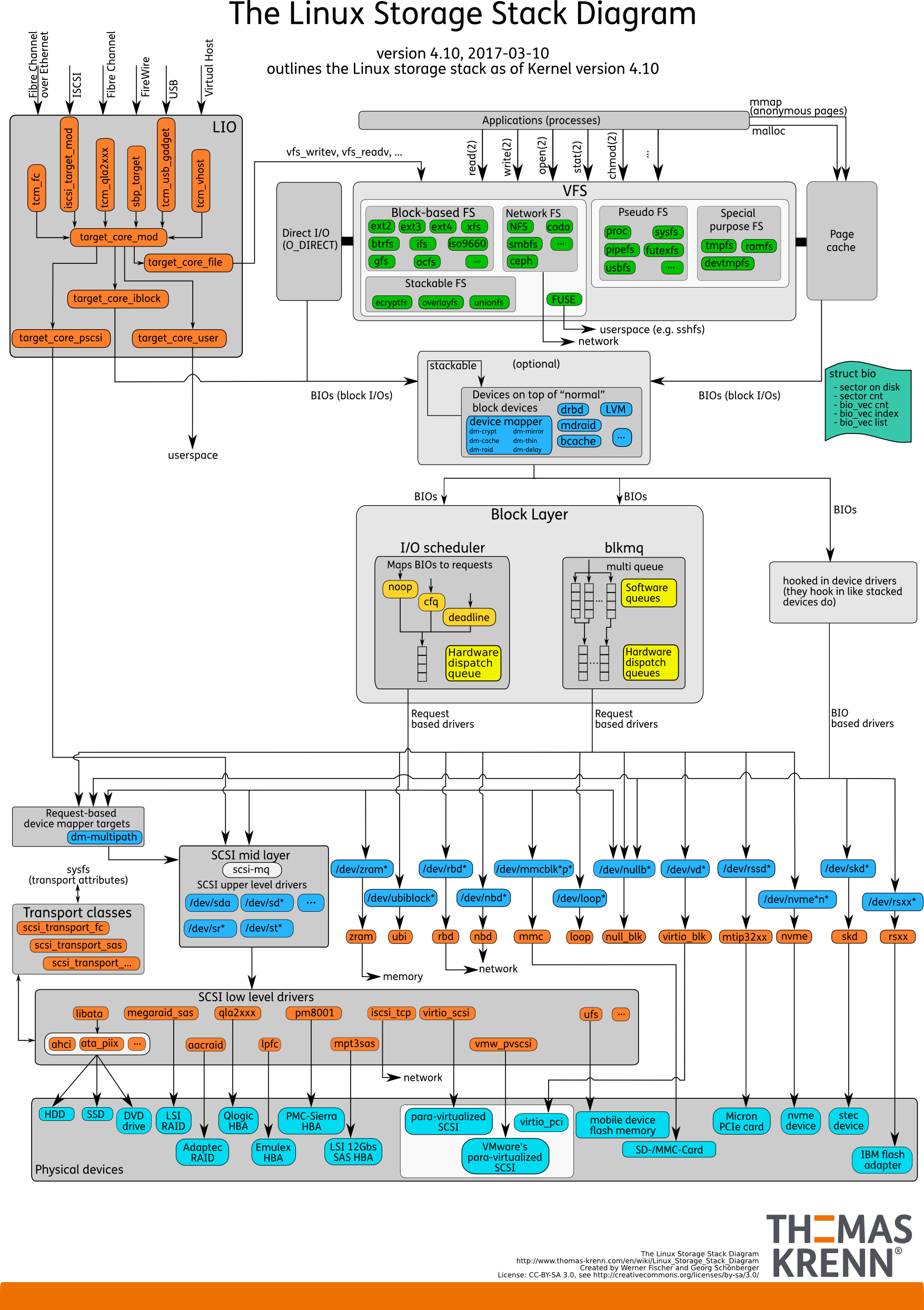
На диаграмме видно, кто над кем стоял, взаимоотношения между драйверами, какие Elevators, часть какого слоя.
Диаграмма регулярно обновляется, что помогает следить за эволюцией ядра администраторам БД и другим специалистам, которые работают с базами.
NVM Express или NVMe — это спецификация, набор стандартов, которые помогают эффективнее использовать SSD. Спецификация хорошо реализована в Linux. Linux — одна из движущих сил стандарта.
Сейчас в продакшне третья версия. Драйвер этой версии по спецификации может пропускать в районе 20 ГБ/с на один SSD блок, а NVMe пятой версии, которой еще нет, — до 32 ГБ/с. У SD драйвера нет ни интерфейсов, ни механизмов внутри, чтобы обеспечить такую пропускную способность.
Когда-то БД писались под вращающиеся диски и ориентированы на них — у них есть индексы в виде B-дерева, например. Возникает вопрос: готовы ли к NVMe базы данных? Способны ли БД прожевать такую нагрузку?
Пока нет, но они адаптируются. Недавно в рассылке PostgreSQL была пара коммитов про
За последние полтора года в NVMe добавили IO polling.
Сначала были вращающиеся диски с высокой latency. Потом появились SSD, которые гораздо быстрее. Но возник косяк: идет fsync, начинается запись, и на очень низком уровне — глубоко в драйвере, отправляется запрос непосредственно в железку — запиши.
Механизм был простой — отправили и ждем, пока обработается прерывание. Подождать обработку прерывания — не проблема, по сравнению с записью на вращающийся диск. Настолько долго надо было ждать, что как только запись закончилась, прерывание сработало.
Поскольку SSD записывает очень быстро, вынужденно появился механизм опроса железки о записи. В первых версиях возрастание скорости ввода/вывода достигло 50% из-за того, что не ждем прерывания, а активно спрашиваем железку о записи. Этот механизм и называется IO polling.
Он был представлен в последних версиях. В версии 4.12 появились IO schedulers, специально заточенные для работы с blk-mq и NVMe, про которые я сказал — Kyber и BFQ. Они уже официально в ядре, их можно использовать.
Сейчас уже в пригодном для использования виде есть так называемый IO tagging. В основном производители облаков и виртуалок контрибьютят в эту разработку. Грубо говоря, ввод от определенного приложения можно затэгать и дать ему приоритет. К этому пока не готовы БД, но следите за обновлениями. Думаю, скоро это будет мейнстримом.
В PostgreSQL не поддерживается Direct IO и есть ряд проблем, которые мешают включить поддержку. Сейчас это поддерживается только для value, и только если не включена репликация. Требуется написать очень много ОС-специфичного кода, и пока что все воздерживаются от этого.
Несмотря на то, что Linux сильно ругается на идею Direct IO и на то, как он реализован, все БД туда идут. В Oracle и MySQL Direct IO активно используется. PostgreSQL — единственная БД, которая Direct IO не переносит.
Как защититься в PostgreSQL от сюрпризов fsync:
Илья Космодемьянский (hydrobiont) работает в компании Data Egret, которая занимается консалтингом и поддержкой PostgreSQL, и про взаимодействие ОС и баз данных знает многое. В докладе на HighLoad++ Илья рассказал о взаимодействии IO и БД на примере PostgreSQL, но и показал, как с IO работают другие БД. Рассмотрел стек Linux IO, что нового и хорошего в нем появилось и почему все не так, как было пару лет назад. В качестве полезной памятки — контрольный список настроек PostgreSQL и Linux для максимальной производительности подсистемы IO в новых ядрах.
В видео доклада много английского языка, большую часть которого в статье мы перевели.
Зачем говорить про IO?
Быстрый ввод/вывод — это самая критичная вещь для администраторов баз данных. Все знают, что можно изменить в работе с CPU, что память можно расширить, но ввод/вывод способен все испортить. Если плохо с дисками, и слишком много ввода/вывода, то БД будет стонать. IO станет бутылочным горлышком.
Чтобы все хорошо заработало, настроить нужно всё.
Не только БД или только железо — всё. Даже высокоуровневый Oracle, который сам себе местами операционная система, требует настройки. Читаем инструкции в «Installation guide» от Oracle: поменять такие параметры ядра, поменять другие — настроек много. Не считая того, что в Unbreakable Kernel уже многое по умолчанию зашито на Oracle’овых Linux’ах.
Для PostgreSQL и MySQL изменений требуется еще больше. Все потому, что эти технологии опираются на механизмы ОС. DBA, который работает с PostgreSQL, MySQL или современными NoSQL, должен быть «Linux operation engineer» и крутить разные гайки ОС.
Каждый, кто хочет разобраться с настройками ядра, обращается к LWN. Ресурс гениальный, минималистичный, содержит много полезной информации, но написан разработчиками ядра для разработчиков ядра. Что хорошо пишут разработчики ядра? Ядро, а не статьи, как его использовать. Поэтому я попробую вам все объяснить за разработчиков, а они пусть ядро пишут.
Все многократно усложняется тем, что изначально разработка ядра Linux и переработка его стека отставали, а в последние годы пошли очень быстро. Ни железо, ни разработчики со статьями за ним не поспевают.
Типичная база данных
Начнем с примеров для PostgreSQL — здесь буферизованный ввод-вывод. У него шаренная память, которая распределяется в User space с точки зрения ОС, и имеет такой же кэша в кэше ядра в Kernel space.
Основная задача современной БД:
- поднимать в память странички с диска;
- когда происходит какое-то изменение, помечать странички, как грязные;
- записывать в Write-Ahead Log;
- после этого синхронизировать память, чтобы она была консистентна диску.
В ситуации PostgreSQL это постоянное путешествие туда и обратно: из шаренной памяти, которой управляет PostgreSQL в Page Cache ядра, и дальше на диск через весь стек Linux. Если вы используете БД на файловой системе, она будет работать по этому алгоритму с любой UNIX-подобной системой и с любой БД. Отличия есть, но незначительны.
При использовании Oracle ASM будет по-другому — Oracle сам взаимодействует с диском. Но принцип тот же: с Direct IO или с Page Cache, но задача — как можно быстрее провести странички через весь стек ввода/вывода, каким бы он ни был. И проблемы могут возникнуть на каждом этапе.
Две проблемы IO
Пока все read only, проблем нет. Прочитали и, если достаточно памяти, все данные, которые нужно считать, помещаются в оперативную память. То, что при этом в случае PostgreSQL в Buffer Cache лежит то же самое, нас не очень волнует.
Первая проблема с IO — синхронизация кэша. Возникает, когда требуется запись. В этом случае придется гонять туда и обратно гораздо больше памяти.
Соответственно, необходимо настроить PostgreSQL или MySQL, чтобы из шаренной памяти это все попало на диск. В случае с PostgreSQL — надо еще хорошо настроить фоновое списывание грязных страниц в Linux, чтобы отправить все на диск.
Вторая частая проблема — сбой записи Write-Ahead Log. Проявляется, когда нагрузка настолько мощная, что даже последовательно записываемый журнал упирается в диск. В этой ситуации его тоже надо записать быстро.
Ситуация мало отличается от синхронизации кэша. В PostgreSQL мы работаем с большим количеством шаренных буферов, в базе есть механизмы для эффективной записи Write-Ahead Log, он до предела оптимизирован. Единственное, что можно сделать, чтобы сам лог писался эффективнее — поменять настройки Linux.
Основные проблемы работы с БД
Сегмент шаренной памяти может быть очень большим. Я начинал об этом рассказывать на конференциях в 2012 году. Тогда я говорил, что память подешевела, даже встречаются серверы с 32 Гб оперативной памяти. В 2019 уже и в ноутбуках может быть больше, на серверах все чаще стоит 128, 256 и т.д.
Памяти действительно много. Банальная запись занимает время и ресурсы, а технологии, которые мы для этого используем, консервативны. БД старые, их давно разрабатывают, они медленно эволюционируют. Механизмы в базах не то чтобы прямо по последнему слову техники.
Синхронизация страниц в памяти с диском приводит к огромным операциям IO. Когда мы синхронизируем кэши, возникает большой поток IO, и встает еще одна проблема — мы не можем что-то покрутить и посмотреть на эффект. В научном эксперименте исследователи меняют один параметр — получают эффект, второй — получают эффект, третий. У нас так не получится. Мы крутим какие-то параметры в PostgreSQL, настраиваем checkpoints — эффекта не увидели. Дальше опять настраивать весь стек, чтобы поймать хоть какой-то результат. Покрутить один параметр не получится — мы вынуждены настраивать сразу всё.
Большинство IO в PostgreSQL генерирует синхронизация страниц: checkpoints и другие механизмы синхронизации. Если вы работали с PostgreSQL, возможно, видели checkpoints spikes, когда на графиках периодически возникает «пила». Раньше многие сталкивались с такой проблемой, но сейчас есть мануалы, как это чинить, стало проще.
SSD сегодня сильно спасают ситуацию. У PostgreSQL редко что-то упирается непосредственно в запись value. Все упирается в синхронизацию: когда происходит checkpoint, вызывается fsync и происходит как бы «наезд» одного checkpoint на другой. Слишком много IO. Один checkpoint еще не закончился, не выполнил все свои fsyncs, а уже заработал другой checkpoint, и началось!
У PostgreSQL есть уникальная фишка — autovacuum. Это многолетняя история костылей под архитектуру БД. Если autovacuum не справляется, обычно его настраивают, чтобы он работал агрессивно и не мешал остальным: много воркеров autovacuum, частое срабатывание по чуть-чуть, обработка таблиц быстро. Иначе будут проблемы с DDL и с блокировками.
Но когда Autovacuum настроен агрессивно, он начинает «жевать» IO.
Если работа autovacuum накладывается на checkpoints, то большую часть времени диски утилизованы почти на 100%, и это источник проблем.
Как ни странно, бывает проблема Cache refill. Она обычно меньше известна DBA. Типичный пример: БД стартовала, и какое-то время все печально тормозит. Поэтому даже если у вас много-много оперативки — докупайте хорошие диски, чтобы стек прогревал кэш.
Все это серьезно влияет на производительность. Проблемы начинаются не сразу после рестарта БД, а позже. Например, прошел checkpoint, и много страниц запачкано во всей базе. Они скопированы на диск, потому что нужно их синхронизовать. Потом запросы спрашивают новую версию страниц с диска, и база проседает. На графиках будет видно, как Cache refill после каждого checkpoint вносит определенный процент в нагрузку.
Самая неприятное во вводе/выводе БД — Worker IO. Когда каждый воркер, к которому вы обращаетесь с запросом, начинает генерировать свой IO. В Oracle с ним проще, а в PostgreSQL — проблема.
Причин проблем с Worker IO много: не хватает кэша, чтобы «провести» новые страницы с диска. Например, бывает что все буферы шаренные, они все попачканы, checkpoints еще не было. Чтобы воркер выполнил простейший select, нужно откуда-то взять кэш. Для этого сначала нужно сохранить это все на диск. У вас не специализированный процесс checkpointer, и воркер начинает выполнять fsync, чтобы освободить и заполнить его чем-то новым.
Тут возникает еще большая проблема: воркер — неспециализированная вещь, и весь процесс вообще никак не оптимизирован. Можно на уровне Linux где-то оптимизировать, но в PostgreSQL это аварийная мера.
Основная проблема IO для БД
Какую проблему мы решаем, когда что-то настраиваем? Мы хотим максимизировать путешествие грязных страниц между диском и памятью.
Но часто бывает так, что эти вещи напрямую не касаются диска. Типичный случай — вы видите очень большой load average. Почему так? Потому что кто-то ждет диск, и все остальные процессы тоже ждут. Вроде бы нет явной утилизации дисков по записи, просто что-то там заблокировало диск, а проблема все равно с вводом/выводом.
Проблемы ввода-вывода для баз данных не всегда касаются только дисков.
В этой проблеме задействовано все: диски, память, CPU, IO Schedulers, файловые системы и настройки самой БД. Сейчас пройдемся по стеку, посмотрим, что с этим делать, и что хорошего в Linux изобрели, чтобы все работало лучше.
Диски
Долгие годы диски были страшно медленные и никто не занимался latency или оптимизацией стадий перехода. Оптимизация fsyncs не имела смысла. Диск вращался, по нему как по грампластинке ездили головки, и fsyncs был настолько длинный, что проблемы не всплывали.
Память
Без настройки БД топ запросов смотреть бесполезно. Вы настроите достаточное количество шаренной памяти и т.д, и у вас будет новый топ запросов — настраивать придется заново. Здесь та же история. Весь стек Linux был сделан из этого расчета.
Пропускная способность и latency
Максимизировать производительность IO через максимизацию пропускной способности легко до определенного момента. Придуман вспомогательный процесс PageWriter в PostgreSQL, который разгружал checkpoint. Работа стала параллельной, но задел для добавки параллелизма еще есть. А минимизировать latency — это задача последней мили, для которой нужны супертехнологии.
Этими супертехнологиями стали SSD. Когда они появились, latency резко снизилась. Зато на всех остальных этапах стека проявились проблемы: и со стороны производителей БД, и со стороны производителей Linux. Проблемы требуют решения.
Разработка БД была сосредоточена вокруг максимизации пропускной способности, также как и разработка ядра Linux. Многие методы оптимизации ввода-вывода эпохи вращающихся дисков не так хороши для SSD.
В промежутке мы были вынуждены ставить подпорки для текущей инфраструктуры Linux, но уже с новыми дисками. Смотрели performance-тесты от производителя с большим количеством разных IOPS, а БД лучше не становилось, потому что БД не только и не столько про IOPS. Часто бывает, что мы можем пропустить 50 000 IOPS в секунду, и это хорошо. Но если мы не знаем latency, не знаем ее распределение, то ничего не можем сказать о производительности. В какой-то момент БД начнет делать checkpoint, и latency резко увеличится.
Долгое время, как и сейчас, это было большой проблемой производительности на виртуалках для баз данных. Virtual IO свойственна неравномерность latency, что, конечно, тоже влечет проблемы.
Стек IO. Как это было раньше
Здесь есть User space — та память, которая управляется самой базой данных. В БД настроили так, чтобы все работало как надо. Об этом можно сделать отдельный доклад, и даже не один. Дальше все неизбежно идет через Page Cache либо через интерфейс Direct IO попадает в Block Input/Output-слой.
Представьте себе интерфейс файловой системы. Через него съезжают странички, которые были в Buffer Cache, как они изначально были в БД, то есть блоками. Block IO-слой занимается следующим. Есть C-структура, которая описывает блок в ядре. Структура берет эти блоки и собирает из них векторы (массивы) запросов на ввод или вывод. Под BIO-слоем находится слой реквестов. На этом слое собираются векторы и отправятся дальше.
Долгое время эти два слоя в Linux были заточены на эффективную запись на магнитные диски. Без перехода было не обойтись. Есть блоки, которыми удобно управлять из базы данных. Нужно эти блоки собрать в векторы, которые удобно записать на диск, чтобы они где-то рядом лежали. Чтобы это эффективно работало, придумали Elevators, или Schedulers IO.
Elevators
Elevators преимущественно занимались тем, что объединяли и сортировали векторы. Все для того, чтобы в блочный драйвер SD — драйвер квазидиска — блоки для записи приехали в удобном для него порядке. Драйвер производил трансляцию из блоков в свои секторы и писал на диск.
Проблема была в том, что нужно было делать несколько transitions, и на каждом реализовывать свою логику оптимального процесса.
Elevators: до ядра 2.6
До ядра 2.6 существовал Linus Elevator – самый примитивный IO Scheduler, который написан сами догадаетесь кем. Долгое время он считался абсолютно незыблемым и хорошим, пока не разработали что-то новое.
Linus Elevator имел много проблем. Он объединял и сортировал в зависимости от того, как эффективнее записать. В случае с вращающимися механическими дисками это приводило к тому, что возникал «starvation»: ситуация, когда эффективность записи зависит от поворота диска. Если внезапно нужно одновременно эффективно прочитать, а он уже повернут не так — читается с такого диска плохо.
Постепенно стало понятно, что это неэффективный путь. Поэтому начиная с ядра 2.6 стал появляться целый зоопарк schedulers, который предназначался для разных задач.
Elevators: между 2.6 и 3
Многие путают эти schedulers с schedulers операционной системы, потому что у них похожие названия. CFQ — Completely Fair Queuing — это не то же самое, что schedulers ОС. Просто названия похожи. Он был придуман как универсальный scheduler.
Что такое универсальный scheduler? Как вы считаете, у вас усредненная нагрузка или, наоборот, уникальная? У баз данных очень плохо с универсальностью. Универсальную нагрузку можно представить себе как работу обычного ноутбука. Там происходит все подряд: мы слушаем музыку, играем, набираем текст. Для этого как раз универсальные schedulers и писались.
Основная задача универсального scheduler: в случае Linux для каждого виртуального терминала и процесса создать свою очередь запросов. Когда мы хотим послушать музыку в аудиопроигрывателе, IO для проигрывателя занимает очередь. Если мы хотим забэкапить что-нибудь с помощью команды cp, этим занимается что-то еще.
В случае с базами данных возникает проблема. Как правило, БД — это процесс, который стартовал, и во время работы возникли параллельные процессы, которые всегда заканчиваются в одной и той же очереди ввода/вывода. Причина в том, что это одно и то же приложение, один и тот же родительский процесс. Для очень небольших нагрузок такой scheduling подходил, для остальных не имел смысла. Его было проще выключить и не использовать, если это возможно.
Постепенно появился deadline scheduler — работает хитрее, но базово это merge и сортировка для вращающихся дисков. С учетом устройства конкретной дисковой подсистемы мы собираем векторы блоков, чтобы записать их оптимальным способом. У него было меньше проблем со «starvation», но они там были.
Поэтому ближе к третьим ядрам Linux появился noop или none, который гораздо лучше работал с распространившимися SSD. Включая scheduler noop, мы фактически отключаем scheduling: нет сортировок, мерджинга и подобных вещей, которыми занимались CFQ и deadline.
Это лучше работает с SSD, потому что SSD от природы параллельный: у него есть ячейки памяти. Чем больше этих элементов напихать на одной PCIe плате, тем эффективнее все будет работать.
Scheduler из каких-то своих потусторонних, с точки зрения SSD, соображений, собирает какие-то векторы и куда-то их отправляет. Это все заканчивается воронкой. Так мы убиваем параллелизм SSD, не используем их на полную катушку. Поэтому простое отключение, когда векторы едут как попало без всякой сортировки, срабатывало лучше с точки зрения производительности. Из-за этого считается, что на SSD лучше идут random read, random write.
Elevators: 3.13 и далее
Начиная с ядра 3.13 появился blk-mq. Немного раньше был прототип, но в 3.13 впервые появилась рабочая версия.
Начинался blk-mq как scheduler, но scheduler’ом его назвать сложно — архитектурно он стоит отдельно. Это замена request layer в ядре. Потихоньку разработка blk-mq привела к серьезной переработке всего стека ввода/вывода Linux.
Идея такая: давайте для ввода/вывода использовать нативную возможность SSD делать эффективный параллелизм. В зависимости от того, сколько параллельных потоков ввода/вывода можно использовать, есть честные очереди, через которые мы просто пишем as is на SSD. Для каждой CPU есть своя очередь для записи.
В настоящий момент blk-mq активно развивается и работает. Нет причин его не использовать. В современных ядрах, от 4 и выше, от blk-mq выигрыш ощутим — не 5-10%, а существенно больше.
blk-mq — наверное, лучшая опция для работы с SSD.
В нынешнем виде blk-mq напрямую завязан на NVMe driver Linux. Есть не только драйвер для Linux, но и драйвер для Microsoft. Но именно идея сделать blk-mq и NVMe driver — это та самая переработка стека Linux, от которой базы данных здорово выиграли.
Консорциум из нескольких компаний решил сделать спецификацию, этот самый протокол. Сейчас он уже в продакшн-версии отлично работает для локальных PCIe SSD. Практически готово решение для дисковых массивов, которые подключаются по оптике.
Драйвер blk-mq и NVMe больше, чем планировщик. Система нацелена на замену всего уровня запросов.
Давайте в нее погрузимся, чтобы понять, что это такое. Спецификация NVMe большая, поэтому все подробности не рассмотрим, а только пробежимся по ним.
Старый подход к elevators
Простейший случай: есть CPU, есть его очередь, и мы как-то идем на диск.
Более продвинутые Elevators работали по-другому. Есть несколько CPU и несколько очередей. Каким-то образом, например, в зависимости от того, от какого родительского процесса отпочковались воркеры БД, IO попадает в очередь и на диски.
Новый подход к elevators
blk-mq — это абсолютно новый подход. Каждый CPU, каждая NUMA-зона добавляет свой ввод/вывод в свою очередь. Дальше данные попадают на диски, не важно, как подключенными, потому что драйвер новый. Там нет SD драйвера, который оперирует понятиями цилиндров, блоков.
Был переходный период. В какой-то момент все вендоры RAID-массивов стали продавать аддоны, которые позволяли обходить кэш RAID. Если подключены SSD — напрямую писать туда. Они отключали применение SD-драйвера для своих продуктов, как blq-mq.
Новый стек с blk-mq
Так выглядит стек в новом виде.
Сверху все осталось также. Например, БД сильно отстают. Ввод/вывод от БД точно также, как раньше, попадает в Block IO-слой. Там есть тот самый blk-mq, который заменяет слой запросов, а не scheduler.
В ядре 3.13 примерно на этом заканчивалась вся оптимизация, но в современных ядрах используются новые технологии. Стали появляться специальные schedulers для blk-mq, которые рассчитаны на более сильный параллелизм. В современных четвертых ядрах Linux зрелыми считаются два schedulers IO — это Kyber и BFQ. Они рассчитаны на работу с параллелизмом и с blk-mq.
BFQ — Budget Fair Queueing — это аналог СFQ. Они абсолютно непохожи, хотя один вырос из другого. BFQ — это scheduler со сложной математикой. Каждое приложение и процесс имеет некоторую квоту на IO. Квота зависит от объема IO, который процесс/приложение генерирует. Согласно этому бюджету у нас есть полоса, в которую пишем. Насколько хорошо это работает — вопрос сложный. Если интересуетесь BFQ, есть масса статей, которые разбирают математику процесса.
Kyber — это альтернатива. Это как BFQ, но без математики. У Kyber небольшой scheduler по количеству кода. Его основная задача — принимать от CPU и отправлять. Kyber легковеснее и работает лучше.
Важный момент для всего стека — blk-mq не смотрит в SD-драйвер. У него нет очередного слоя конверсии, на который я жаловался, когда показывал, как раньше выглядел IO-стек. Из blk-mq в NVMe driver все приходит сразу в готовом виде. Блоки в цилиндры не пересчитываются.
В новом подходе возникло несколько интересных моментов — резко упала latency, и этого слоя в том числе. Сначала появились SSD, которые хорошо работают — появилась возможность перерабатывать этот слой. Как только мы перестали конвертировать туда-сюда, выяснилось, что и в NVMe-слое, и в blk-mq есть свои узкие места, которые тоже надо оптимизировать. Сейчас о них поговорим.
Диаграмма стека Linux IO
У Томаса Кренна есть постоянно обновляемая и актуальная диаграмма стека ввода/вывода Linux.
На диаграмме видно, кто над кем стоял, взаимоотношения между драйверами, какие Elevators, часть какого слоя.
Диаграмма регулярно обновляется, что помогает следить за эволюцией ядра администраторам БД и другим специалистам, которые работают с базами.
Спецификация NVM Express
NVM Express или NVMe — это спецификация, набор стандартов, которые помогают эффективнее использовать SSD. Спецификация хорошо реализована в Linux. Linux — одна из движущих сил стандарта.
Сейчас в продакшне третья версия. Драйвер этой версии по спецификации может пропускать в районе 20 ГБ/с на один SSD блок, а NVMe пятой версии, которой еще нет, — до 32 ГБ/с. У SD драйвера нет ни интерфейсов, ни механизмов внутри, чтобы обеспечить такую пропускную способность.
Эта спецификация существенно быстрее, чем все, что было раньше.
Когда-то БД писались под вращающиеся диски и ориентированы на них — у них есть индексы в виде B-дерева, например. Возникает вопрос: готовы ли к NVMe базы данных? Способны ли БД прожевать такую нагрузку?
Пока нет, но они адаптируются. Недавно в рассылке PostgreSQL была пара коммитов про
pwrite() и подобные вещи. Разработчики PostgreSQL и MySQL взаимодействуют с разработчиками ядра. Конечно, хотелось бы, чтобы взаимодействия было больше.Последние разработки
За последние полтора года в NVMe добавили IO polling.
Сначала были вращающиеся диски с высокой latency. Потом появились SSD, которые гораздо быстрее. Но возник косяк: идет fsync, начинается запись, и на очень низком уровне — глубоко в драйвере, отправляется запрос непосредственно в железку — запиши.
Механизм был простой — отправили и ждем, пока обработается прерывание. Подождать обработку прерывания — не проблема, по сравнению с записью на вращающийся диск. Настолько долго надо было ждать, что как только запись закончилась, прерывание сработало.
Поскольку SSD записывает очень быстро, вынужденно появился механизм опроса железки о записи. В первых версиях возрастание скорости ввода/вывода достигло 50% из-за того, что не ждем прерывания, а активно спрашиваем железку о записи. Этот механизм и называется IO polling.
Он был представлен в последних версиях. В версии 4.12 появились IO schedulers, специально заточенные для работы с blk-mq и NVMe, про которые я сказал — Kyber и BFQ. Они уже официально в ядре, их можно использовать.
Сейчас уже в пригодном для использования виде есть так называемый IO tagging. В основном производители облаков и виртуалок контрибьютят в эту разработку. Грубо говоря, ввод от определенного приложения можно затэгать и дать ему приоритет. К этому пока не готовы БД, но следите за обновлениями. Думаю, скоро это будет мейнстримом.
Примечания по Direct IO
В PostgreSQL не поддерживается Direct IO и есть ряд проблем, которые мешают включить поддержку. Сейчас это поддерживается только для value, и только если не включена репликация. Требуется написать очень много ОС-специфичного кода, и пока что все воздерживаются от этого.
Несмотря на то, что Linux сильно ругается на идею Direct IO и на то, как он реализован, все БД туда идут. В Oracle и MySQL Direct IO активно используется. PostgreSQL — единственная БД, которая Direct IO не переносит.
Чек-лист
Как защититься в PostgreSQL от сюрпризов fsync:
- Настроить checkpoint, чтобы они были реже и больше.
- Настроить background writer, чтобы они помогал checkpoint.
- Оттюнить Autovacuum, чтобы не было лишнего паразитного ввода/вывода.
Согласно традиции в ноябре ждем профессиональных разработчиков высоконагруженных сервисов в Сколково на HighLoad++. Еще есть месяц, чтобы подать заявку на доклад, но первые доклады в программу мы уже приняли. Подпишитесь на рассылку и будете узнавать о новых темах из первых рук.



