Тысячи менеджеров из офисов продаж по всей стране фиксируют в нашей CRM-системе ежедневно десятки тысяч контактов — фактов общения с потенциальными или уже работающими с нами клиентами. А для этого клиента надо сначала найти, и желательно очень быстро. И происходит это чаще всего по названию.
Поэтому неудивительно, что, разбирая в очередной раз «тяжелые» запросы на одной из самых нагруженных баз — нашего собственного корпоративного аккаунта СБИС, я обнаружил «в топе» запрос для «быстрого» поиска по названию для карточек организаций.
Причем дальнейшее расследование выявило интересный пример сначала оптимизации, а затем деградации производительности запроса при последовательной его доработке силами нескольких команд, каждая из которых действовала исключительно из лучших побуждений.
 [КДПВ отсюда]
[КДПВ отсюда]
Что вообще обычно подразумевает пользователь, когда говорит про «быстрый» поиск по названию? Почти никогда это не оказывается «честный» поиск по подстроке типа
Пользователь же подразумевает на бытовом уровне, что вы ему обеспечите поиск по началу слова в названии и покажете более релевантным то, что начинается на введенное. И сделаете это практически мгновенно — при подстрочном вводе.
И уж тем более не будет человек специально вводить
Вообще, правильно сформулировать требования к задаче — больше половины решения. Иногда внимательный анализ use case может существенно влиять на результат.
Что же делает абстрактный разработчик?
Ой, поиск это сложно, что-то вообще им заниматься не хочется — давайте отдадим это devops! Пусть они нам развернут внешнюю относительно БД поисковую систему: Sphinx, ElasticSearch,…
Рабочий, хоть и трудоемкий в плане синхронизации и оперативности изменений вариант. Но не в нашем случае, поскольку поиск осуществляется для каждого клиента только в рамках данных его аккаунта. А данные имеют достаточно высокую изменчивость — и если сейчас менеджер внес карточку
Поэтому — давайте искать «прямо по базе». К счастью, PostgreSQL позволяет нам это делать, и не одним вариантом — их и рассмотрим.
Цепляемся за слово «подстрока». А ведь ровно для индексного поиска по подстроке (и даже по регулярным выражениям!) есть отличный модуль pg_trgm! Только потом надо будет правильно посортировать.
Давайте попробуем взять для простоты модели такую табличку:
Заливаем туда 7.8 миллионов записей реальных организаций и индексируем:
Поищем для подстрочного поиска первые 10 записей:
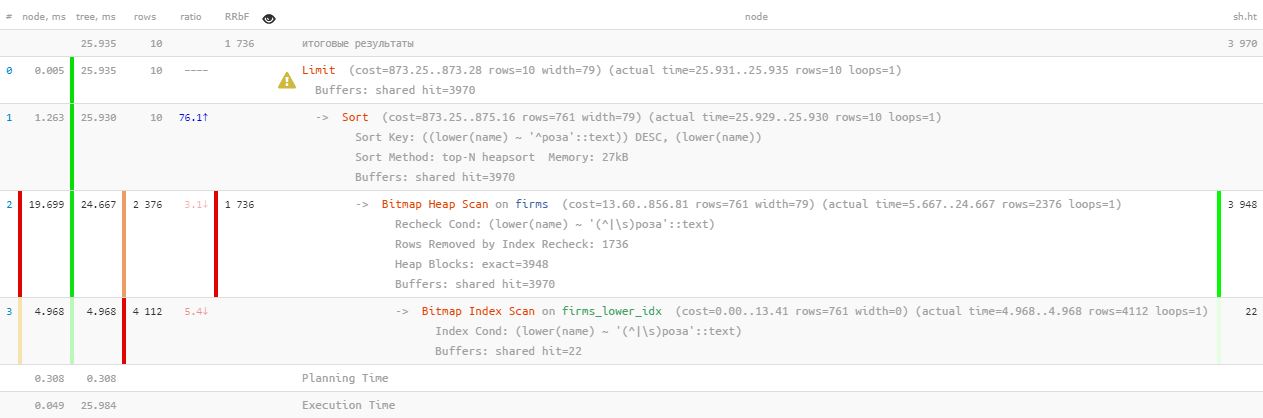
[посмотреть на explain.tensor.ru]
Ну, такое… 26мс, 31MB прочитанных данных и больше 1.7K отфильтрованных записей — для 10 искомых. Накладные расходы слишком велики, нельзя ли как-то поэффективнее?
Действительно, PostgreSQL предоставляет очень мощный механизм полнотекстового поиска (Full Text Search), в том числе с возможностью префиксного поиска. Отличный вариант, даже расширений устанавливать не нужно! Давайте попробуем:

[посмотреть на explain.tensor.ru]
Тут нам немного помогла параллелизация исполнения запроса, сократив время вдвое до 11мс. Да и прочитать нам пришлось в 1.5 раза меньше — всего 20MB. А тут чем меньше — тем лучше, ведь чем больший объем мы вычитываем, тем выше шансы получить cache miss, и каждая лишняя прочитанная с диска страница данных — потенциальные «тормоза» для запроса.
Всем предыдущий запрос хорош, да только если его дернуть сотню тысяч раз за сутки, то набежит уже 2TB прочитанных данных. В лучшем случае — из памяти, но если не повезет, то и с диска. Так что давайте попробуем сделать его поменьше.
Вспомним, что пользователь хочет видеть сначала «которые начинаются на ...». Так ведь это же в чистом виде префиксный поиск с помощью
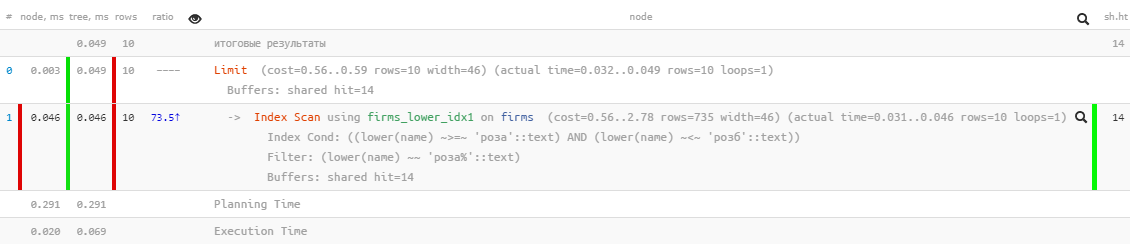
[посмотреть на explain.tensor.ru]
Отличные показатели — всего 0.05мс и чуть больше 100KB прочитано! Только мы же забыли сортировку по названию, чтобы пользователь не заблудился в результатах:
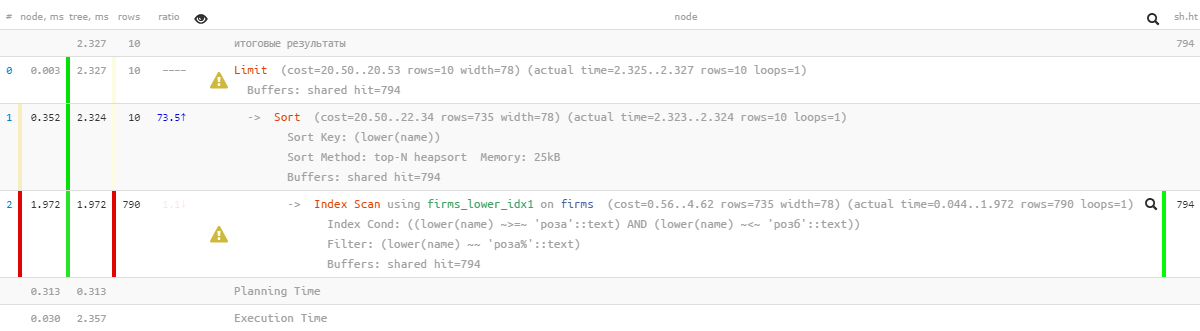
[посмотреть на explain.tensor.ru]
Ой, что-то уже не так красиво — вроде и индекс есть, но сортировка летит мимо него… Оно, конечно, уже в разы эффективнее, чем предыдущий вариант, но…
Но есть же индекс, который позволяет и по диапазону искать, и сортировку при этом нормально использовать — обычный btree!
Только запрос под него придется «собирать вручную»:

[посмотреть на explain.tensor.ru]
Отлично — и сортировка работает, и потребление ресурсов осталось «микроскопическим», в тысячи раз эффективнее «чистого» FTS! Осталось собрать в единый запрос:
Замечу, что второй подзапрос выполняется только если первый вернул меньше ожидаемого последним
Таки да, мы теперь имеем на таблице одновременно btree и gin, зато статистически получилось, что меньше 10% запросов доходят до выполнения второго блока. То есть при таких известных заранее типичных ограничениях для задачи мы смогли уменьшить суммарное потребление ресурсов сервера практически в тысячи раз!
Теперь оставляем наш запрос «настояться» полгода-год, и с удивлением снова обнаруживаем его «в топе» с показателями суммарного суточного «прокачивания» памяти (buffers shared hit) в 5.5TB — то есть еще больше, чем было исходно.
Нет, конечно, и бизнес у нас вырос, и нагрузка увеличилась, но не настолько же! Значит, что-то тут нечисто — давайте разбираться.
В какой-то момент другой команде разработчиков захотелось сделать возможность из быстрого подстрочного поиска «прыгнуть» в реестр с теми же, но расширенными результатами. А какой реестр без постраничной навигации? Давайте прикрутим!
Теперь можно было без напрягов для разработчика показывать реестр результатов поиска с «типа-постраничной» подгрузкой.
Конечно, на самом-то деле, для каждой следующей страницы данных читается все больше и больше (все из предыдущего раза, которые отбросим, плюс нужный «хвостик») — то есть это однозначный антипаттерн. А правильнее было бы — запускать поиск на следующей итерации от запомненного в интерфейсе ключа, но про это — в другой раз.
В какой-то момент разработчику захотелось разнообразить результирующую выборку данными из другой таблицы, для чего весь предыдущий запрос был отправлен в CTE:
И даже так — неплохо, поскольку вложенный запрос вычисляется только для 10 возвращаемых записей, если бы не…
Где-то в процессе такой эволюции из 2-го подзапроса потерялось
Что делает разработчик вместо поиска причины?.. Не вопрос!
То есть понятно, что результат, в итоге, ровно тот же, но шанс «пролететь» во 2-й подзапрос CTE стал сильно выше, да и без этого, читается явно больше.
Но это не самая печаль. Поскольку разработчик попросил отобрать
Вот так вот, разработчики жили — не тужили, потому что в реестре «докрутить» до существенных значений N при хроническом замедлении получения каждой следующей «страницы» у пользователя явно не хватало терпения.
Пока к ним не пришли разработчики из другого отдела, и не захотели воспользоваться таким удобным методом для итеративного поиска — то есть берем из какой-то выборки кусочек, фильтруем по дополнительным условиям, рисуем результат, потом следующий кусочек (что в нашем случае достигается за счет увеличения N), и так пока не заполним экран.
В общем, в пойманном экземпляре N достигло значений почти в 17K, а всего за сутки было выполнено «по цепочке» не меньше 4K таких запросов. Последние из них смело сканировали уже по 1GB памяти на каждой итерации…

Поэтому неудивительно, что, разбирая в очередной раз «тяжелые» запросы на одной из самых нагруженных баз — нашего собственного корпоративного аккаунта СБИС, я обнаружил «в топе» запрос для «быстрого» поиска по названию для карточек организаций.
Причем дальнейшее расследование выявило интересный пример сначала оптимизации, а затем деградации производительности запроса при последовательной его доработке силами нескольких команд, каждая из которых действовала исключительно из лучших побуждений.
0: чего же хотел пользователь
Что вообще обычно подразумевает пользователь, когда говорит про «быстрый» поиск по названию? Почти никогда это не оказывается «честный» поиск по подстроке типа
... LIKE '%роза%' — ведь тогда в результат попадают не только 'Розалия' и 'Магазин Роза', но и 'Гроза' и даже 'Дом Деда Мороза'.Пользователь же подразумевает на бытовом уровне, что вы ему обеспечите поиск по началу слова в названии и покажете более релевантным то, что начинается на введенное. И сделаете это практически мгновенно — при подстрочном вводе.
1: ограничиваем задачу
И уж тем более не будет человек специально вводить
'роз магаз', чтобы каждое слово вам приходилось искать префиксно. Нет, пользователю отреагировать на быструю подсказку для последнего слова гораздо проще, чем целенаправленно «недовводить» предыдущие — посмотрите, как это отрабатывает любой поисковик.Вообще, правильно сформулировать требования к задаче — больше половины решения. Иногда внимательный анализ use case может существенно влиять на результат.
Что же делает абстрактный разработчик?
1.0: внешний поисковый движок
Ой, поиск это сложно, что-то вообще им заниматься не хочется — давайте отдадим это devops! Пусть они нам развернут внешнюю относительно БД поисковую систему: Sphinx, ElasticSearch,…
Рабочий, хоть и трудоемкий в плане синхронизации и оперативности изменений вариант. Но не в нашем случае, поскольку поиск осуществляется для каждого клиента только в рамках данных его аккаунта. А данные имеют достаточно высокую изменчивость — и если сейчас менеджер внес карточку
'Магазин Роза', то через 5-10 секунд он уже может вспомнить, что забыл указать там email и захотеть ее найти и поправить.Поэтому — давайте искать «прямо по базе». К счастью, PostgreSQL позволяет нам это делать, и не одним вариантом — их и рассмотрим.
1.1: «честная» подстрока
Цепляемся за слово «подстрока». А ведь ровно для индексного поиска по подстроке (и даже по регулярным выражениям!) есть отличный модуль pg_trgm! Только потом надо будет правильно посортировать.
Давайте попробуем взять для простоты модели такую табличку:
CREATE TABLE firms(
id
serial
PRIMARY KEY
, name
text
);Заливаем туда 7.8 миллионов записей реальных организаций и индексируем:
CREATE EXTENSION pg_trgm;
CREATE INDEX ON firms USING gin(lower(name) gin_trgm_ops);Поищем для подстрочного поиска первые 10 записей:
SELECT
*
FROM
firms
WHERE
lower(name) ~ ('(^|\s)' || 'роза')
ORDER BY
lower(name) ~ ('^' || 'роза') DESC -- сначала "начинающиеся на"
, lower(name) -- остальное по алфавиту
LIMIT 10;
[посмотреть на explain.tensor.ru]
Ну, такое… 26мс, 31MB прочитанных данных и больше 1.7K отфильтрованных записей — для 10 искомых. Накладные расходы слишком велики, нельзя ли как-то поэффективнее?
1.2: поиск по тексту? это же FTS!
Действительно, PostgreSQL предоставляет очень мощный механизм полнотекстового поиска (Full Text Search), в том числе с возможностью префиксного поиска. Отличный вариант, даже расширений устанавливать не нужно! Давайте попробуем:
CREATE INDEX ON firms USING gin(to_tsvector('simple'::regconfig, lower(name)));SELECT
*
FROM
firms
WHERE
to_tsvector('simple'::regconfig, lower(name)) @@ to_tsquery('simple', 'роза:*')
ORDER BY
lower(name) ~ ('^' || 'роза') DESC
, lower(name)
LIMIT 10;[посмотреть на explain.tensor.ru]
Тут нам немного помогла параллелизация исполнения запроса, сократив время вдвое до 11мс. Да и прочитать нам пришлось в 1.5 раза меньше — всего 20MB. А тут чем меньше — тем лучше, ведь чем больший объем мы вычитываем, тем выше шансы получить cache miss, и каждая лишняя прочитанная с диска страница данных — потенциальные «тормоза» для запроса.
1.3: все-таки LIKE?
Всем предыдущий запрос хорош, да только если его дернуть сотню тысяч раз за сутки, то набежит уже 2TB прочитанных данных. В лучшем случае — из памяти, но если не повезет, то и с диска. Так что давайте попробуем сделать его поменьше.
Вспомним, что пользователь хочет видеть сначала «которые начинаются на ...». Так ведь это же в чистом виде префиксный поиск с помощью
text_pattern_ops! И только если нам «не хватит» до 10 искомых записей, то дочитывать их придется с помощью FTS-поиска:CREATE INDEX ON firms(lower(name) text_pattern_ops);SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('роза' || '%')
LIMIT 10;[посмотреть на explain.tensor.ru]
Отличные показатели — всего 0.05мс и чуть больше 100KB прочитано! Только мы же забыли сортировку по названию, чтобы пользователь не заблудился в результатах:
SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('роза' || '%')
ORDER BY
lower(name)
LIMIT 10;[посмотреть на explain.tensor.ru]
Ой, что-то уже не так красиво — вроде и индекс есть, но сортировка летит мимо него… Оно, конечно, уже в разы эффективнее, чем предыдущий вариант, но…
1.4: «доработать напильником»
Но есть же индекс, который позволяет и по диапазону искать, и сортировку при этом нормально использовать — обычный btree!
CREATE INDEX ON firms(lower(name));Только запрос под него придется «собирать вручную»:
SELECT
*
FROM
firms
WHERE
lower(name) >= 'роза' AND
lower(name) <= ('роза' || chr(65535)) -- для UTF8, для однобайтовых - chr(255)
ORDER BY
lower(name)
LIMIT 10;[посмотреть на explain.tensor.ru]
Отлично — и сортировка работает, и потребление ресурсов осталось «микроскопическим», в тысячи раз эффективнее «чистого» FTS! Осталось собрать в единый запрос:
(
SELECT
*
FROM
firms
WHERE
lower(name) >= 'роза' AND
lower(name) <= ('роза' || chr(65535)) -- для UTF8, для однобайтовых кодировок - chr(255)
ORDER BY
lower(name)
LIMIT 10
)
UNION ALL
(
SELECT
*
FROM
firms
WHERE
to_tsvector('simple'::regconfig, lower(name)) @@ to_tsquery('simple', 'роза:*') AND
lower(name) NOT LIKE ('роза' || '%') -- "начинающиеся на" мы уже нашли выше
ORDER BY
lower(name) ~ ('^' || 'роза') DESC -- используем ту же сортировку, чтобы НЕ пойти по btree-индексу
, lower(name)
LIMIT 10
)
LIMIT 10;Замечу, что второй подзапрос выполняется только если первый вернул меньше ожидаемого последним
LIMIT количества строк. Про такой способ оптимизации запросов я уже писал раньше.Таки да, мы теперь имеем на таблице одновременно btree и gin, зато статистически получилось, что меньше 10% запросов доходят до выполнения второго блока. То есть при таких известных заранее типичных ограничениях для задачи мы смогли уменьшить суммарное потребление ресурсов сервера практически в тысячи раз!
2: как «прокисают» запросы
Теперь оставляем наш запрос «настояться» полгода-год, и с удивлением снова обнаруживаем его «в топе» с показателями суммарного суточного «прокачивания» памяти (buffers shared hit) в 5.5TB — то есть еще больше, чем было исходно.
Нет, конечно, и бизнес у нас вырос, и нагрузка увеличилась, но не настолько же! Значит, что-то тут нечисто — давайте разбираться.
2.1: рождение пейджинга
В какой-то момент другой команде разработчиков захотелось сделать возможность из быстрого подстрочного поиска «прыгнуть» в реестр с теми же, но расширенными результатами. А какой реестр без постраничной навигации? Давайте прикрутим!
( ... LIMIT <N> + 10)
UNION ALL
( ... LIMIT <N> + 10)
LIMIT 10 OFFSET <N>;Теперь можно было без напрягов для разработчика показывать реестр результатов поиска с «типа-постраничной» подгрузкой.
Конечно, на самом-то деле, для каждой следующей страницы данных читается все больше и больше (все из предыдущего раза, которые отбросим, плюс нужный «хвостик») — то есть это однозначный антипаттерн. А правильнее было бы — запускать поиск на следующей итерации от запомненного в интерфейсе ключа, но про это — в другой раз.
2.2: хочется экзотики
В какой-то момент разработчику захотелось разнообразить результирующую выборку данными из другой таблицы, для чего весь предыдущий запрос был отправлен в CTE:
WITH q AS (
...
LIMIT <N> + 10
)
SELECT
*
, (SELECT ...) sub_query -- какой-то запрос к связанной таблице
FROM
q
LIMIT 10 OFFSET <N>;И даже так — неплохо, поскольку вложенный запрос вычисляется только для 10 возвращаемых записей, если бы не…
2.3: DISTINCT бессмысленный и беспощадный
Где-то в процессе такой эволюции из 2-го подзапроса потерялось
NOT LIKE условие. Понятно, что после этого UNION ALL начал возвращать некоторые записи дважды — сначала найденные по началу строки, а потом еще раз — по началу первого слова этой строки. В пределе, все записи 2го подзапроса могли совпасть с записями первого.Что делает разработчик вместо поиска причины?.. Не вопрос!
- расширим вдвое размер исходных выборок
- наложим DISTINCT, чтобы получились только одинарные экземпляры каждой строки
WITH q AS (
( ... LIMIT <2 * N> + 10)
UNION ALL
( ... LIMIT <2 * N> + 10)
LIMIT <2 * N> + 10
)
SELECT DISTINCT
*
, (SELECT ...) sub_query
FROM
q
LIMIT 10 OFFSET <N>;То есть понятно, что результат, в итоге, ровно тот же, но шанс «пролететь» во 2-й подзапрос CTE стал сильно выше, да и без этого, читается явно больше.
Но это не самая печаль. Поскольку разработчик попросил отобрать
DISTINCT не по конкретным, а сразу по всем полям записи, то туда автоматом попало и поле sub_query — результат подзапроса. Теперь, для выполнения DISTINCT, базе пришлось выполнить уже не 10 подзапросов, а все <2 * N> + 10!2.4: кооперация превыше всего!
Вот так вот, разработчики жили — не тужили, потому что в реестре «докрутить» до существенных значений N при хроническом замедлении получения каждой следующей «страницы» у пользователя явно не хватало терпения.
Пока к ним не пришли разработчики из другого отдела, и не захотели воспользоваться таким удобным методом для итеративного поиска — то есть берем из какой-то выборки кусочек, фильтруем по дополнительным условиям, рисуем результат, потом следующий кусочек (что в нашем случае достигается за счет увеличения N), и так пока не заполним экран.
В общем, в пойманном экземпляре N достигло значений почти в 17K, а всего за сутки было выполнено «по цепочке» не меньше 4K таких запросов. Последние из них смело сканировали уже по 1GB памяти на каждой итерации…
Итого


