
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Жизнь продолжается. А мы продолжаем знакомить вас с самыми интересными новостями PostgreSQL.
Пополнение в Core Team
Напоминаем о неписанном правиле сообщества: в Core Team не должно быть большинство из одной компании. После слияния-поглощения EDB 2ndQuadrant 3 из 5 участников Основной Команды оказались коллегами по EDB. К счастью, никого не сократили, а добавили двух достойных: Андреса Фройнда (Andres Freund, Microsoft, Citus) и Джонатана Каца (Jonathan Katz, Crunchy Data).
Любимые области Андреса Фройнда: репликация, производительность и масштабируемость (смотрите три недавние статьи на эту тему, ссылки в нашем разделе Статьи. Производительность), хранение.
Джонатан Кац (Jonathan Katz, Crunchy Data) занимался патчами и ревью, но больше концентрировался на разработке и поддержке сайта, выпуске релизов и прочей сопутствующей, но необходимой деятельности. Он вообще важный человек: председатель совета директоров Ассоциации PostgreSQL в США (United States PostgreSQL Association) и директор Ассоциации PostgreSQL-сообщества Канады (PostgreSQL Community Association of Canada), которая выступает как юридическое лицо сообщества.
Прекрасное, взвешенное решение. Впрочем, не все с этим согласны: Альваро Эрнандес (Álvaro Hernández Tortosa — если полностью) поздравил новоизбранных (непонятно кем и непонятно как — по его мнению) и предложил задуматься над следующими 10 проблемами управления сообществом:
Влияние компаний:
- 40% из Core Team были из одной компании, теперь — 43%, 71% из двух;
- 100% из всего лишь 4 компаний.
Многообразие (diversity):
- 100% это белые мужчины;
- 100% из США или Европы;
- все кроме одного работают в американских компаниях.
Демократия:
- членов Core Team назначают члены Core Team;
- срок неограничен, четверо являются членами уже больше 15 лет.
Прозрачность:
- процессы выбора членов и кандидатов, критерии выбора и пр. — суть большой секрет;
- заседания секретны;
- стратегии (policies) объявляются, а не обсуждаются в сообществе.
Альваро предлагает высказаться. И Ханс-Юрген Шёниг (Hans-Jürgen Schönig) высказывается:
«Никогда не замечал и тени расизма при принятии патчей. Может и дальше будем продолжать как было — думать о компетентности, а не о расе, гендере или о чём там? У нас с этим никогда не было проблем. Так зачем проблему создавать?» Клаус Расмуссен (ClausRasmussen) ещё решительней: «зачем нам этот crap с идентичностями? У нас технологическое сообщество, а не Liberal_arts_college». Желающие могут запастись попкорном и следить за дискуссией. Этот текст обсуждается также здесь.
Я опустил детали в обращении Альваро. Ещё одна из упомянутых им проблем (существующих с точки зрения Альваро): Core Team это «центральный орган» проекта. А юридически проект представляет Postgres Association of Canada, определяя в том числе интеллектуальную собственность: доменные имена, торговые марки и прочее. Как бы чего не вышло.
CF-новость
Анастасия Лубенникова из Postgres Professional стала распорядителем текущего коммитфеста. В этом ей помогает Георгиос Коколатос (Georgios Kokolatos).
Новости PG-этики
А ещё Анастасия входит в Комитет по этике (Code of Conduct Committee) сообщества (а Илья Космодемьянский вышел из комитета).
Кстати, благодаря то ли Альваро, то ли общему настроению, Комитет по этике объявил вакансии: нужны люди из разных стран и разных народов, чтобы отразить многообразие PostgreSQL-сообщества. Пишите на coc@postgresql.org
Документация к PostgreSQL 13.0
The PostgreSQL Global Development Group объявила о доступности русской документации к версии 13. Перевод на русский язык — компания Postgres Professional. Официальная страница русскоязычной документации.
Обучение
DEV2: Разработка серверной части приложений PostgreSQL 12. Расширенный курс.
Новый курс продолжительностью 4 дня. В нём:
- понимание внутренней организации сервера;
- полное использование возможностей, предоставляемых PostgreSQL для реализации логики приложения;
- расширение возможностей СУБД для решения специальных задач.
Основная идея курса – показать не просто базовые функции PostgreSQL, но и его расширяемость: возможность дополнить серверные механизмы собственным кодом, что позволяет использовать PostgreSQL для решения самых разнообразных задач.
Статьи
Масштабируемость и производительность
Measuring the Memory Overhead of a Postgres Connection
Андрес Фройнд (тот самый, кто только что обосновался в PostgreSQL Core Team) опубликовал серию из 3 статей о производительности PostgreSQL при большом числе соединений. Они дублируются в блоге Citus и в блоге Microsoft (пока 20 лайков, 2 подписчика).
В статье об издержках памяти начинается с популярного мотива — а если бы треды, а не процессы? Спойлер Андреса: если аккуратно померить, то издержки меньше 2 мебибайта. А неаккуратно — это при помощи top и ps.
Для более тонких замеров памяти Андрес использует системные
/proc/$pid/status и /proc/$pid/smaps_rollup. Так можно увидеть значения VmRSS, VmRSS, RssAnon, RssFile, RssShmem — если вы не знали, что это, то из статьи узнаете и поймёте, почему они важны. Чтобы не обмануться с причиной перерасхода памяти, он замеряет с включенным и отключенным huge_pages. Ещё: надо помнить о copy-on-write при форке процесса.Analyzing the Limits of Connection Scalability in Postgres
Андрес исследует узкие места с тем, чтобы далее предложить путь их решения, и аргументирует не только из общих соображений, а с примерами и листингами. Раздувание кеша (cache bloat) тоже (как и оверхед при форке) не критично. Управление
work_mem тоже удовлетворительно. А собака зарыта в куче снэпшотов: функция GetSnapshotData() дорогая и вызывается часто. Вывод: надо менять саму модель соединений (connection model), а может и модель исполнения запросов (query execution model). А от себя добавим: эта тема более, чем активно обсуждалась в рассылке hackers. Более того: в Postgres Professional давно ведутся разработки в этом направлении. В Postgre Pro Enterprise Edition есть встроенный пул соединений. Это не совсем то, что сделал Андрес, но это тоже в тему масштабируемости клиентских соединений.За диагностической 2-й статьёй следует 3-я — конструктивная: предложения Андреса уже в форме патчей, которые должны войти в версию PostgreSQL 14:
Improving Postgres Connection Scalability: Snapshots
Пересказывать эту статью в паре абзацев, кажется, бессмысленно. Даём ссылки на серию патчей Андреса (все они начинаются с «snapshot scalability: » — здесь опускаем):
Don’t compute global horizons while building snapshots
Move PGXACT->xmin back to PGPROC
Introduce dense array of in-progress xids
Move PGXACT->vacuumFlags to ProcGlobal->vacuumFlags
Move subxact info to ProcGlobal, remove PGXACT.
cache snapshots using a xact completion counter
(Об этом также здесь)
Другую серию — из 3 статей в жанре от 8.3 и до 13 — опубликовал Томаш Вондра (Tomas Vondra, 2ndQuadrant — то есть EDB).
OLTP performance since PostgreSQL 8.3
В этой статье Томаш сначала объясняет замысел серии: почему начал с 8.3, почему именно эти тесты, зачем ему тестировать полнотекстовый поиск, на какой машине тестировать. Он не ставит цели сверхкорректного сравнения, это скорее упражнение для лучшего понимания PostgreSQL. До 8.3 он уж слишком отличался от нынешнего, охват и так недурен: 12 лет. А машина — обычный офисный компьютер.
В 1-й статье серии Томаш исследует производительность OLTP на bgbench, взятой из 13-й версии,
scale 100 (1.6 ГБ), 1 000 (16 ГБ) и 10 000 (160 ГБ). Клиенты от 1 до 256. Хранение — NVMe SSD / SATA RAID; режимы: read-only (pgbench -S) / read-write (pgbench -N)Графики с NVMe SSD ведут себя прилично: производительность в основном монотонно растёт с номером версии. А вот с SATA творятся чудеса: c SATA RAID в режиме чтения некоторые флюктуации и, похоже, регресс в версии 9.6. А вот на записи-чтении грандиозное ускорение с версии 9.1 — в 6 раз!
Томаш уверен, что постгрессистам придут в голову блестящие идеи, как эффективней использовать ресурсы железа. Патчи по улучшению масштабированию соединений или патч по неволатильным буферам WAL тому пример. Можно ждать радикальных улучшений в хранении (более эффективный формат файлов на диске, использование прямого ввода-вывода, например), более эффективные индексы.
TPC-H performance since PostgreSQL 8.3
Для измерения производительности на аналитических нагрузках Томаш запускал бенчмарк TPC-H (его ещё называют бенчмарком принятия решений — decision support), получал результаты, которые можно анализировать ещё очень долго, нарисовал красивые графики, и сделал свои выводы — в меру отпущенного на это времени.
В TPC-H 22 запроса на 3 наборах данных: малом, среднем и большом. Томаш гоняет их на версиях от 8.3 до 13, да ещё и то включает, то отключает параллелизм. Коэффициенты масштабирования (scale factor) он выбирает такие: 1 (цель — поместиться в shared-buffers), 10 (в память) и 75 (не поместиться в память). Комбинаций — море, для анализа — простор. Иногда автор действительно «опускается» до отдельных запросов и анализирует причины странного поведения. Кривая производительности немонотонно меняется с версией, а по отдельным запросам скачет совсем неожиданно. Причина простая: планировщик и оптимизатор умнеют с новыми версиями за счёт новых планов и/или за счет новых способов использования статистики, но оборотная сторона — промахи: неверный выбор плана из-за плохой статистики, оценок стоимостей или других ошибок. Примерно то же и с параллелизмом: появляются новые планы, но если стоимости и оценки расходятся с реальностью, выбираются планы, хуже старых, последовательных.

Диаграмма из статьи TPC-H performance since PostgreSQL 8.3. Можно было поместить в наш раздел Прекрасное.
Full-text search since PostgreSQL 8.3
В преамбуле Томаш рассказывает историю FTS в PostgreSQL, которая началась с Олега Бартунова и Фёдора Сигаева лет за 20 до основания Postgres Professional. Далее Томаш сетует на отсутствие индустриальных стандартов тестирования полнотекстового поиска и обращается к собственным ресурсам ПО: в незапамятные времена он сочинил утилиту archie – парочку питоновых скриптов, которые загружают архивы переписки PostgreSQL, превращая их в базу, которую можно индексировать, в которой можно искать тексты. Сейчас в таких архивах около миллиона строк — 9.5 ГБ не считая индексов. В качестве тестовых запросов он взял 33 тыс. реальных поисковых запросов к архиву на сайте PostgreSQL.org.

Фёдор Сигаев и Олег Бартунов. Фотография из статьи Full-text search since PostgreSQL 8.3
Запросы были разного типа, но для статьи взял вот такие — с
tsvector, придуманным ещё Бартуновым и Сигаевым: SELECT id, subject FROM messages WHERE body_tsvector @@ $1
SELECT id, subject FROM messages WHERE body_tsvector @@ $1
ORDER BY ts_rank(body_tsvector, $1) DESC LIMIT 100Кроме того Томаш тестировал влияние индексов GIN и GiST. Оба запроса с использованием GIN дают огромный скачок в производительности — в 4 с лишним раза! Томаш благодарит за это Александра Короткова и Хейкки Линнакангас (Heikki Linnakangas), придумавших патч Improve speed of multi-key GIN lookups. А вот если использовать GiST, то ничего хорошего вообще не будет. А будет плавная деградация. Почему ж никто не жаловался? — вопрошает автор и предполагает, что вместе с апгрейдом версий многие апгрейдили и железо, и это маскировало эффект. Или просто не использовали GiST для текстового поиска.
Олег, Теодор [Фёдор] и их коллеги — напоминает Томаш — работали над более мощными вариантами GIN-индексов — VODKA и RUM [примечание редакции: об индексах RUM, о том, чем они лучше GIN, о расширении rum можно почитать здесь. Про водку не будем :)]. Это как минимум поможет некоторым типам запросов. Особенно автор надеется на улучшение поддержки новых типов полнотекстовых запросов, так как новые типы индексов спроектированы для того, чтобы ускорить фразовый поиск (см. там же).
Книжечки
Кстати, о текстовых файлах и поиске в них. Вот 196640 книг (файлов) в текстовом формате. Их, скорее всего, будут использовать для обучения больших сетей, но можно их, скажем, использовать и в каких-нибудь тестах производительности текстового поиска или ещё каких-то манипуляций текстом. Собирали тексты энтузиасты с the-eye.eu (почему-то недоступного честному пользователю из РФ).
PostgreSQL 14: Часть 2 или «в тени тринадцатой» (Коммитфест 2020-09)
Эта статья Павла Лузанова из отдела образования Postgres Professional и о производительности тоже: постольку, поскольку патчи, принятые на этом коммитфесте, имели отношение к производительности (о патчах Андреса, которые он упоминал, там тоже есть). Это, как и Часть 1 (Коммитфест 2020-07), MUST READ для тех, кто следит за технологическими новшествами PostgreSQL — без IMHO.
Жизнь в PostgreSQL
памяти Джона Хортона Конвея, погибшего от COVID-19
Открывает эту мемориальную подборку ссылок недавняя статья Егора Рогова: «Жизнь» на PostgreSQL
Некто Сергей aka ildarovich делает это на языке запросов 1С, а точнее одним запросом: Игра «Жизнь» в одном запросе
А вот на C#: Как ускорить игру «Жизнь» в сто раз, в комментариях есть SQL-код.
На JS, огромная статья, очень красивая визуализация: Эволюционирующие клеточные автоматы
Кстати, о Конвее: Джо (Joe), однофамилец классика клеточных автоматов (в прошлом выпуске мы ссылались на статью 2007-го года про то, как использовать PL/R для GIS) теперь, в начале ноября 2020, пишет на тему сверх-актуальную:
Election Night Prediction Modeling using PL/R in Postgres
Он использует пакеты mvtnorm (3 алгоритма нормального распределения), politicaldata (специальные тулзы для сбора и анализа политических данных) и tidyverse (разные средства анализа данных). Для развлечения Джо предлагает разобраться в немалом количестве строк кода, создаёт свой тип данных и ещё предлагает придумать SQL-запросы в качестве упражнения.
Релизы
PostgreSQL 13.1
А также 12.5, 11.10, 10.15, 9.6.20 и 9.5.24. В новых версиях исправлены обнаруженные баги, в том числе связанные с безопасностью. Сейчас мы не будем на них останавливаться. Они описаны на этой странице.
OpenGauss 1.0.1
Сотрудник Huawei Вадим Гусев сообщает на хабре о появлении openGauss: новая СУБД от Huawei для нагруженных enterprise-проектов прибавила в функциональности
Это форк PostgreSQL, опенсорсный вариант проприетарной GaussDB, который работает на x86 и китайских процессорах Kunpeng 920, у которых архитектура ARM64 (к слову: напоминаем, что ARM ltd куплена Nvidia), то есть мы можем предположить курс на китайское импортозамещение (в нише ARM у нас не «Эльбрусы», а «Байкалы»).
Как утверждают создатели, у OpenGauss гибридная ориентация в духе HTAP, и она многое умеет :
- колоночное хранение;
- in-memory engine;
- развертывается решение как в контейнерах, так и на физических серверах;
- ИИ (глубокое обучение с подкреплением в сочетании с эвристическими алгоритмами) рекомендует параметры.;
- инкрементальное резервное копирование;
- Standby на удаленной площадке в синхронном или асинхронном режиме (до четырех реплик на физическом уровне).
В статье с длинным интернациональным списком авторов (фамилии от индийских до русских, китайцы в меньшинстве) оценивается производительность на TPC-C.
Database Lab 2.0
Николай Самохвалов и Артём Картасов из Postgres.ai (Артём делал бОльшую часть кода) на Постгрес-вторнике 3 ноября рассказали (за полтора часа) о Database Lab 2.0 — новой, сильно отличающейся версии своей среды для тестирования и разработки с «тонкими клонами» (при клонировании копируются только измененные блоки).
Новое:
- поддержка RDS и других облачных Postgres-сервисов;
- физическое развертывание с нативной поддержкой WAL-G;
- декларативное развертывание;
- управление снэпшотами, политики снэпшотов;
- предобработка данных (анонимизация);
- time travel для диагностики, контроля изменений, быстрого точечного восстановления;
- оптимизация SQL на новом уровне: serverless EXPLAIN и бот-помощник для оптимизации;
- 100% покрытие миграций БД (изменение схемы) автоматическими тестами на полноразмерных копиях БД;
- регрессивные тесты;
- поддержка docker-имиджей для Postgres 9.6, 10, 11, 12 и 13; по умолчанию в них расширения Timescale, Citus, PoWA и много других, а также большинство расширений, поддерживаемых Amazon RDS;
- документация сильно расширена.
pg_statement_rollback 1.0
pg_statement_rollback — это расширение Жиля Дароля (Gilles Darold), Жульена Руо (Julien Rouhaud) и Дэйва Шарпа (Dave Sharpe), которое реализует в PostgreSQL откат транзакции на уровне оператора (server side rollback at statement level for PostgreSQL) как в Oracle или DB2. Это значит, что при ошибке в выполнении оператора его результаты не видны — как будто оператора и не было. При этом результаты операторов, выполненных в транзакции до этого, не теряются. В PostgreSQL это можно было сделать только на клиенте, в psql, например:
\set ON_ERROR_ROLLBACK onТеперь всё будет работать на сервере таким образом, как будто для каждого оператора серверу посылаются
SAVEPOINT autosave
и
RELEASE SAVEPOINT autosave— а такая роскошь раньше могла сказаться на производительности. Авторы дают результаты тестов TPS-B и честно рассказывают о проблемах.
pgbitmap 0.9.3
Бета-релиз расширения pgbitmap, доступно на pgxn и github.
Это расширение Марка Манро (Marc Munro) создаёт тип
pgbitmap с полным набором функций, операторов и агрегатов. Он отличается от стандартных типов Postgres bit и bit varying тем, что строка не начинается с нулевого бита и тем, что набор операций намного богаче. Этот тип разрабатывался под Virtual Private Database для управления привилегиями. В этом релизе исправлены ошибки, он считается релизом-кандидатом. Сейчас открытых багов не осталось — присылайте, если найдёте.Документация здесь.
pgpool-II 4.2 beta1
В новой версии:
- улучшено и упрощено конфигурирование логирования;
- добавлен новый режим кластера: snapshot_isolation_mode, который гарантирует не только модификацию данных нескольким инстансам, но и согласованность по чтению;
- поддержка LDAP-аутентификации между клиентом и Pgpool-II;
- импорт SQL-парсера PostgreSQL 13.
и прочее, о чём можно прочитать в Release notes.
Загрузить можно отсюда.
pg_activity 1.6.2
pg_activity это интерфейс в стиле top для мониторинга бэкендов PostgreSQL в реальном времени. Поддерживается Бенуа Лабро (Benoit Lobréau, Dalibo Labs). В нём можно:
- настраивать частоту обновления;
- переключаться между тремя представлениями запросов: исполняющиеся/ждущие/блокирующие;
- сортировать по PostgreSQL-метрикам: READ/s, WRITE/s
Зависимостей теперь мало. Работает на Python 2.6+. Исходники здесь.
pgcenter 0.6.6
На гитхабе Алексея Лесовского (Data Egret) появилась новая версия. В ней:
- рейтинги запросов адаптированы к версии PostgreSQL 13;
- тайминги операторов адаптированы к версии 13;
- надо проапдейтить конфигурацию
travic-ci: отключитьskip_cleanup; проапгерйдить Go до версии 1.14.
pglogical 2.3.3
Появилась поддержка PostgreSQL 13. Загружать отсюда. Чейнджлог недоступен, за информацией велено обращаться к info@2ndQuadrant.com.
repmgr 5.2.0
Добавлена поддержка PostgreSQL 13. Из изменений:
- новая опция
--verify-backupзапускает утилиту pg_verifybackup после сканирования реплики, чтобы убедиться в консистентности скопированных данных (только для PostgreSQL 13 и позже); - у
failover_validation_commandпоявились новые параметры и конфигурационная опцияalways_promoteдля управления промоутированием ноды в случае, когда метаданные repmgr уже неактуальны; - поддержка PostgreSQL 9.3 прекращена.
Есть и другие изменения, о которых можно узнать здесь. Сорсы находятся здесь, а инструкции по инсталляции здесь.
Прекрасное
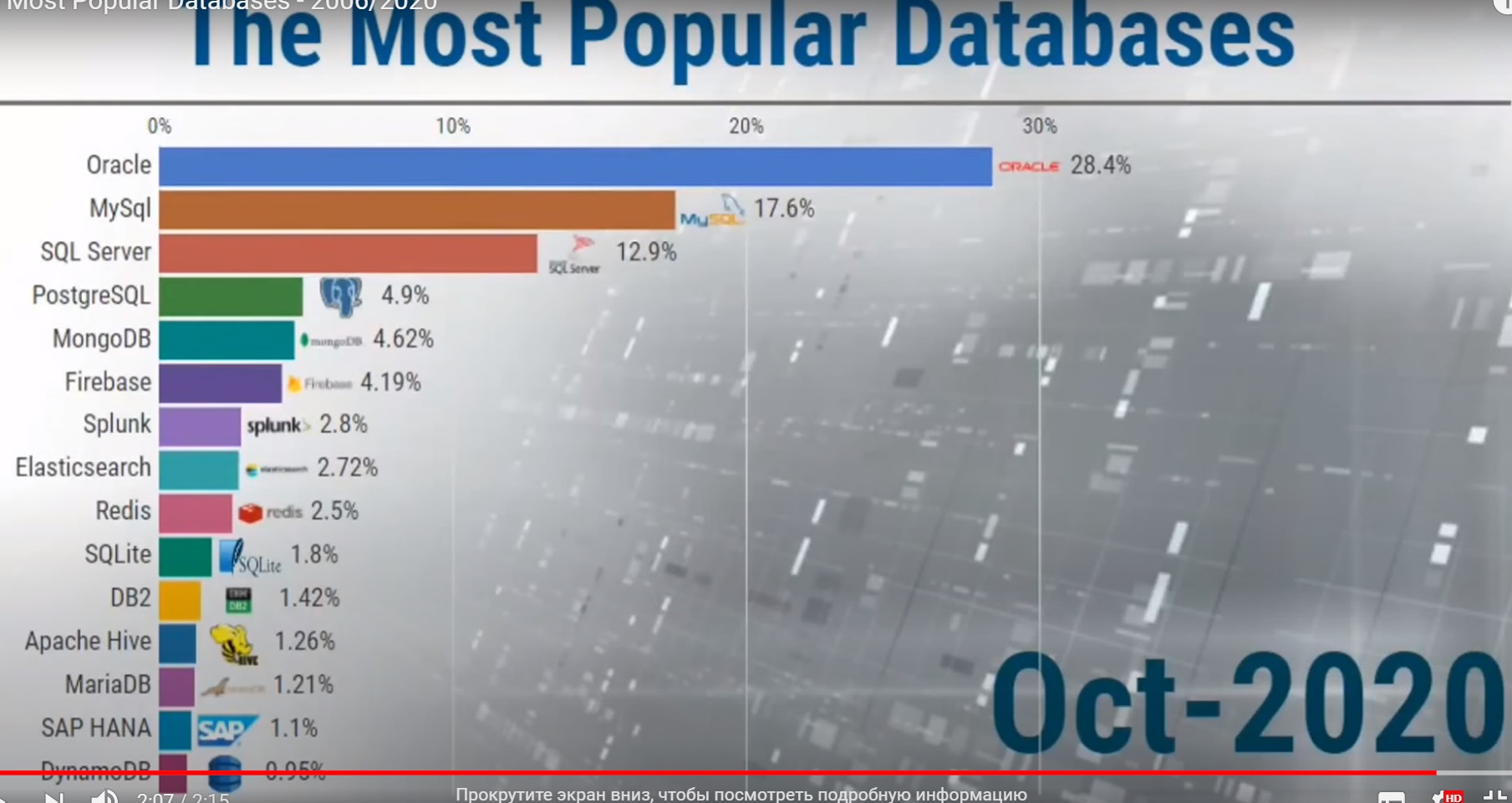
Популярность баз 2006 — 2020
Скриншоты не передадут гипнотической мощи этой динамической инфографики от DB weekly. Это кино увлекательно, познавательно воодушевляюще и даже чуть-чуть отрезвляюще в то же время.

а через 14 лет популярность PostgreSQL выросла более, чем в 2 раза:
Postgres Observability
Интерактивный шедевр наглядности & информативности (этот скриншот в подмётки не годится). Автор Алексей Лесовский из DataEgret.

Конференции
Highload++
Внимание: переносится! Новые даты конференции 17 и 18 февраля 2021 года!
Ибица 2020 — зачеркнуто — 2021
Одна из самых любимых PG-народом конференций — Postgres Ibiza 2020 — должна состояться в 2021 году 23-25-го июня (дата предварительная). Следите за новостями на pgibz.io или на сайте FUNDACIÓN POSTGRESQL — сообщества с испаноязычным уклоном. Про Бали пока не слышно.
Postgres Build 2020
Виртуальная европейская конференция по PostgreSQL, посещение бесплатное. Фокус на кейсы реальных клиентов. Пройдёт 8-9 декабря 2020 он-лайн. Twitter и LinkedIn: #postgresbuild.

