
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Командам, которые занимаются обработкой данных (поступающих пакетными партиями в рабочих потоках) сложно соответствовать современным требованиям по обработке данных в режиме реального времени. Почему? Потому что пакетный поток данных – от доставки данных до их дальнейшей обработки и анализа – это такая вещь, при работе с которой нужно уметь ждать.
Требуется ждать тех данных, которые пойдут на отправку в ETL-инструмент, дожидаться, пока будет обработана куча данных, ждать, пока информация будет загружена в хранилище данных и даже ждать, пока закончат выполняться сделанные запросы.
Но в опенсорсном пространстве есть решение, разработанное в опенсорсе. В сочетании друг с другом Apache Kafka, Flink и Druid, позволяют создать архитектуру для обработки данных, которая работает в режиме реального времени и позволяет исключить все эти этапы ожидания. В этом посте мы исследуем, как комбинация этих инструментов позволяет создавать широкий спектр приложений для обработки данных в режиме реального времени.
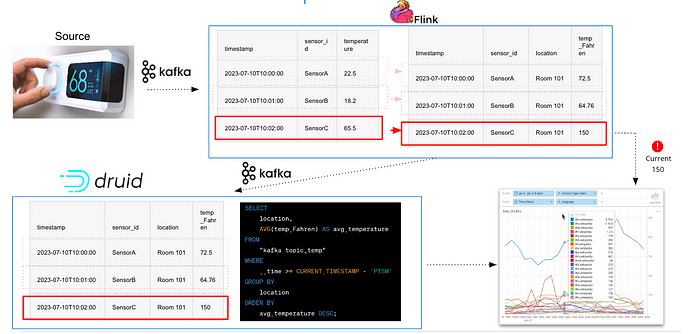
Иллюстрация: поток данных от источника до приложений с применением Kafka-Flink-Druid (источник: imply.io)
❯ Архитектура приложений для обработки данных в режиме реального времени
Для начала вопрос: что представляет собой приложение для обработки данных в режиме реального времени? Просто представьте себе приложение, которое управляется через UI или API, использует свежие данные для извлечения информации и принятия решений в режиме реального времени. В частности, речь об оповещениях, мониторинге, графиках, аналитике и персонализованных рекомендациях.
Чтобы наладить такие рабочие потоки, требуются специализированные встроенные инструменты, которые могли бы обрабатывать целый конвейер от отдельного события до всего приложения. Именно в таких случаях нам пригодится архитектура Kafka-Flink-Druid (KFD).
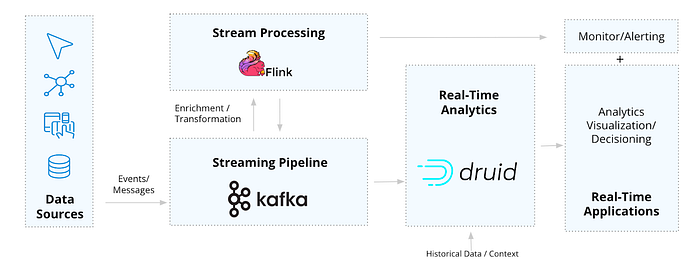
Опенсорсная архитектура для анализа данных в режиме реального времени (image by imply.io)
Крупные компании, которым требуется анализировать данные в режиме реального времени, например, Lyft, Pinterest, Reddit, Paytm, сочетают три эти технологии, так как все они основаны на взаимодополняющих решениях для обработки потоков. Они обеспечивают гладкую обработку данных, в вместе с тем – их свежесть, нужный масштаб и надёжность, соответствующую работе в режиме реального времени.
С такой архитектурой легко и удобно создавать приложения, обеспечивающие наблюдаемость данных, аналитику IoT/телеметрию, диагностику безопасности и выявление её нарушений, сбор информации о пользователе, а также высокую пропускную способность и обслуживание большого количества запросов в секунду.
Давайте подробнее рассмотрим каждую из этих технологий и обсудим, как их можно сочетать друг с другом.
❯ Потоковый конвейер: Apache Kafka
За несколько последних лет Apache Kafka де-факто превратился в стандарт для обработки потоковых данных. До Kafka также применялись RabbitMQ, ActiveMQ и другие системы для работы с очередями сообщений, использовавшие различные паттерны рассылки сообщений с целью распределять между потребителями данные, поступающие от производителей. Но масштабы работы этих инструментов получались явно ограниченными.
Перенесёмся в сегодняшний день. Kafka повсюду, используется более чем в 80% организаций, входящих в список Fortune 100. Дело в том, что возможности архитектуры Kafka далеко не ограничиваются простой рассылкой сообщений. Благодаря многогранности архитектуры, Kafka отлично подходит для передачи данных «в масштабах целого Интернета», отличается высокой отказоустойчивостью и обеспечивает достаточную согласованность данных для работы с критически важными приложениями. Инструмент Kafka Connect предоставляет разнообразные варианты подключения, позволяющие интегрировать Kafka с любыми источниками данных.
Apache Kafka (иллюстрация imply.io)
❯ Обработка потоков: Apache Flink
По мере того, как Kafka предоставляет данные в режиме реального времени, потребители этих данных должны оставаться в выигрыше от такой скорости и масштаба работы в режиме реального времени. Для этого требуется организовать обработку потоковой передачи данных, и один из наиболее популярных инструментов для этой цели — Apache Flink.
Почему именно Flink? Начнём с того, что Flink крайне хорош в масштабной обработке непрерывных потоков данных – он обладает уникальным движком, приспособленным к обращению как с пакетными, так и с потоковыми данными. Flink естественным образом сочетается с Kafka в качестве обработчика потоков, поскольку между Flink и Kafka обеспечивается бесшовная интеграция, а также во Flink поддерживается семантика строго однократной доставки. Так гарантируется, что каждое событие будет обрабатываться строго один раз, даже в случае отказов системы.
Работать с Flink очень просто: подключаемся к топику Kafka, определяем логику запроса, а затем непрерывно выдаём результаты; то есть, движок работает по принципу «настроил и забыл». Поэтому Flink оказывается весьма многофункциональным в тех юзкейсах, где особенно важно обрабатывать потоки сразу по мере поступления данных и при этом обеспечивать высокую надёжность.
Вот типичные варианты использования Flink:
- Обогащение и преобразование данных
- Непрерывный мониторинг и выдача оповещений
Обогащение и преобразование данных
Если в потоке требуется осуществлять некие операции над данными (например, модифицировать их, улучшать или реструктурировать) и лишь потом использовать, Flink идеально подходит для внесения изменений или улучшений в такие потоки, чтобы при непрерывной обработке данные всегда оставались свежими.
Допустим, к примеру, что нам требуется работать с IoT/телеметрией, чтобы обрабатывать в умном здании информацию, поступающую с температурных датчиков. Каждое событие, поступающее в Kafka, имеет следующую структуру в формате JSON:
{
"sensor_id": "SensorA",
"temperature": 22.5,
"timestamp": "2023–07–10T10:00:00"
}Если ID каждого сенсора необходимо соотнести с местоположением, а температура должна быть выражена в градусах Фаренгейта, то Flink может обновить структуру JSON, чтобы она приняла следующий вид:
{
"sensor_id": "SensorA",
"location": "Room 101",
"temperature_Fahreinheit": 73.4,
"timestamp": "2023–07–10T10:00:00"
}После этого структура будет выдаваться прямо в приложение или отправляться обратно в Kafka.

Здесь наглядно показано, как использовать Flink для обогащения событийно-ориентированных данных (изображение от imply.io)
В данном случае достоинство Flink заключается в скорости при масштабной работе и в том, как легко он обращается с огромными потоками Kafka — обрабатывая до миллионов событий в секунду — и всё это в режиме реального времени. Кроме того, обогащение или преобразование данных – это зачастую процессы без сохранения состояния, где каждую запись данных можно изменить без необходимости поддерживать персистентное состояние. Поэтому и высокая производительность в данном случае даётся минимальными усилиями.
Непрерывный мониторинг и оповещение
Благодаря характерной для Flink комбинации отказоустойчивости и непрерывной обработки в режиме реального времени, такое решение идеально подходит для оперативного обнаружения и отслеживания в критически важных прикладных контекстах.
Когда чувствительность при обнаружении очень высока – на уровне долей секунд – а выборка при этом также ведётся очень быстро, Flink здесь нам как раз пригодится в качестве уровня предоставления данных благодаря применяемой в нём непрерывной обработке. Flink очень удобен для отслеживания условий и инициирования оповещений, а также для действий по ситуации.
По части уведомлений Flink выигрывает в том, что поддерживает их как с сохранением, так и без сохранения состояния. Пороговые значения и даже триггеры вида «уведомить пожарную часть, когда температура достигнет X градусов» просты, но не всегда достаточно интеллектуальны. Поэтому найдутся практические случаи, в которых оповещение должно будет выдаваться в соответствии со сложными паттернами, при которых требуется запоминать состояние или даже агрегировать метрики (например, сумму, среднее, минимум, максимум, счёт, т. д.) – в рамках непрерывного потока данных. Flink может мониторить и обновлять состояние, чтобы выявлять отклонения и аномалии.
Здесь необходимо учитывать, что при использовании Flink для мониторинга и оповещения создаётся постоянная нагрузка на ЦП – и, соответственно, постоянно тратятся ресурсы. Это требуется для постоянной сверки возникающих условий с порогами и паттернами, и такой подход, конечно, отличает Flink от базы данных, которая нагружает ЦП только во время выполнения запроса. Поэтому очень важно разобраться, в самом ли деле вам требуется непрерывная работа.
❯ Аналитика в режиме реального времени: Apache Druid
Apache Druid закругляет представленную архитектуру данных, присоединяясь к Kafka и Flink в качестве потребителя потоков данных. обеспечивая их анализ в режиме реального времени. Притом, что это база данных с аналитическим уклоном, она спроектирована и используется во многом иначе, чем другие базы и хранилища данных.
Начнём с того, что Druid можно считать братом Kafka и Flink. Он также нативно настроен на работу с потоками. На самом деле, ему даже не нужен коннектор с Kafka, поскольку он подключается прямо к топикам Kafka и поддерживает семантику «строго однократной доставки». Кроме того, Druid рассчитан на стремительное и при этом масштабное поглощение потоковых данных и на незамедлительное запрашивание событий сразу после их поступления, в оперативной памяти.
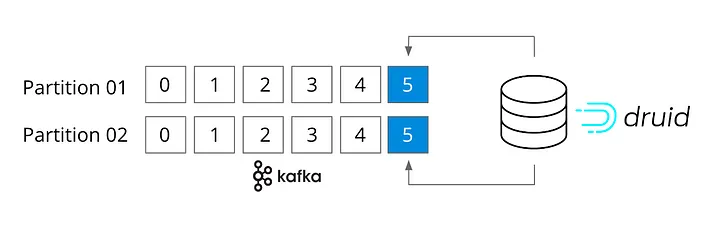
Процесс поглощения в Druid нативно спроектирован в расчёте на работу с каждым отдельным событием (image by imply.io)
Если рассмотреть ситуацию со стороны запросов, то Druid – это высокопроизводительная база данных для аналитики в режиме реального времени, обрабатывающая запросы в большом масштабе и в доли секунды, причём, под нагрузкой. Если мы говорим о таком варианте использования, где важна производительность и требуется обрабатывать от терабайт до петабайт данных (например, происходит агрегация, фильтрация, группирование, объединение данных) в больших объёмах, то Druid в качестве базы данных подходит идеально. Он неизменно молниеносно обрабатывает запросы и легко масштабируется с единственного ноутбука до кластера из 1000 узлов.
Вот почему Druid известен как база данных для аналитики в реальном времени: именно здесь данные, получаемые в реальном времени, сочетаются с запросами в реальном времени.
Вот как Druid дополняет Flink:
- Запросы высокой степени интерактивности
- Сочетание исторических данных с данными, получаемыми в реальном времени
Запросы высокой степени интерактивности
Программисты используют Druid в качестве основы для аналитических приложений. Высоконагруженные приложения, для которых предусматриваются разные варианты использования – как внутренние (операционные), так и внешние (ориентированные на пользователя) охватывают функционал, связанный с наблюдаемостью, безопасностью, аналитикой продукта, IoT/телеметрией, производственными операциями, т.д. Как правило, приложениям, основанным на работе с Druid, присущи такие характеристики:
- Высокая производительность в больших масштабах: у приложений, в которых нужна производительность при считывании с укладыванием в доли секунды, либо выполнение насыщенных аналитических запросов на материале крупных датасетов без предвычисления данных. Druid демонстрирует высокую производительность, даже если пользователи приложения произвольно группируют, фильтруют и нарезают множество случайных запросов а масштабе от терабайт до петабайт данных.
- Большой объём запросов: есть приложения, в которых требуется обрабатывать большое количество аналитических запросов в секунду. В качестве примера здесь произойдёт любое приложение с фасадом – напр., продукт для работы с данными – для которого задан высокий целевой уровень обслуживания: за доли секунды нужно обрабатывать нагрузки, содержащие от сотен до тысяч (разных) конкурентных запросов.
- Данные временных рядов: приложения, позволяющие судить о данных в их временном срезе (в Druid работа с временными рядами – как раз сильная, а не слабая сторона). Druid может очень быстро обрабатывать данные временных рядов в большом масштабе, поскольку сегментирует время и поддерживает подходящий для этого формат. Именно поэтому основанные на времени фильтры WHERE работают невероятно быстро.
Для таких приложений характерна или очень высокая визуализация данных/UI с синтезируемыми наборами результатов, а также большая гибкость при изменении запросов на лету (поэтому-то Druid настолько быстр), или масштабная потоковая работа по принятию решений, обеспечиваемая через API Druid.
Вот пример аналитического приложения, работающего на основе Apache Druid:
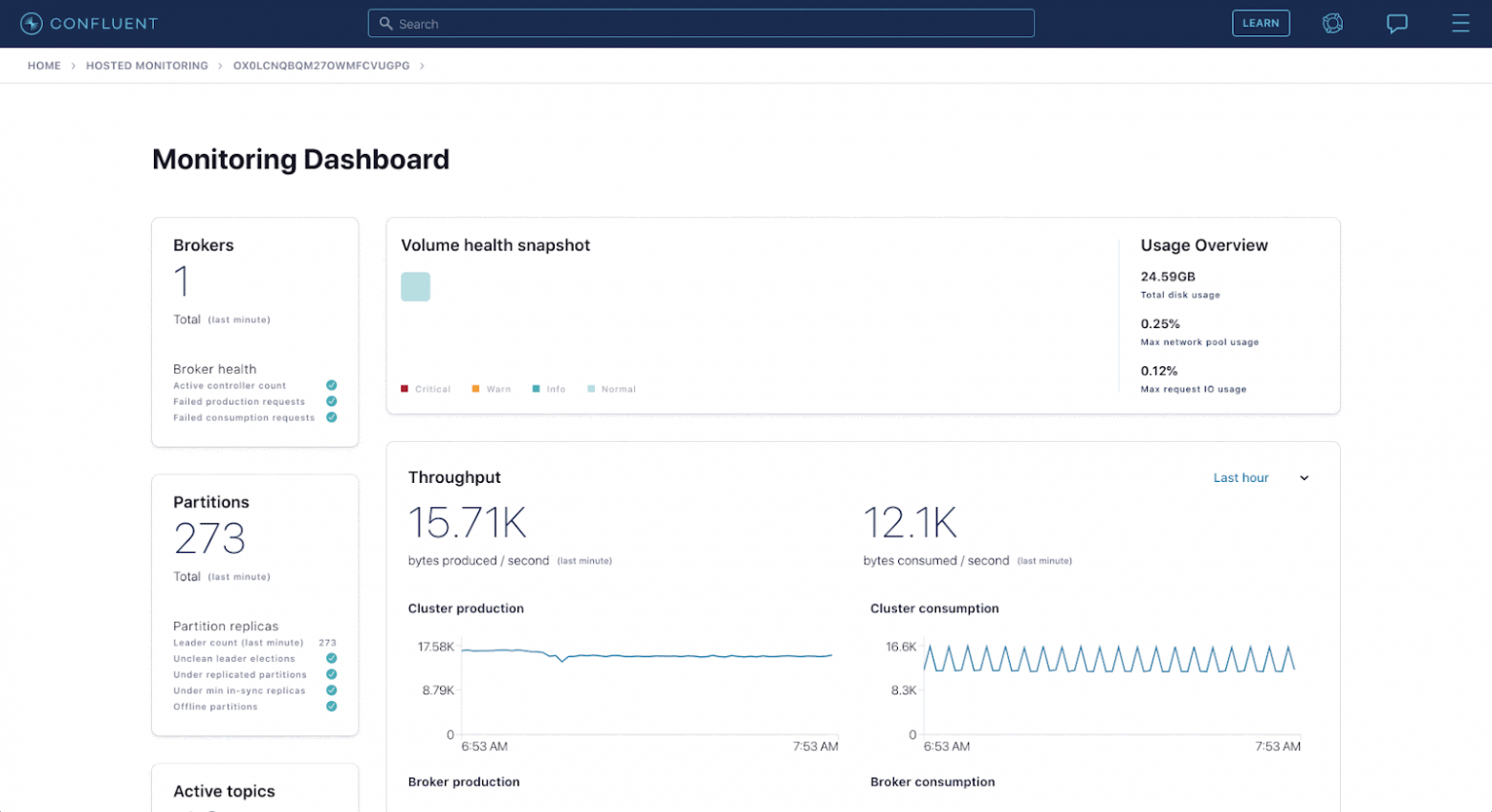
(иллюстрация Confluent)
Компания Confluent, в которой был создан инструмент Apache Kafka, предоставляет своим клиентам аналитику через приложение Confluent Health+. Это приложение, показанное выше, отличается высокой интерактивностью и даёт пользователям массу ценной информации из экосистемы Confluent. Под капотом события текут в Kafka и Druid по 5 миллионов событий в секунду.
Сочетание данных реального времени и исторических данных
В вышеприведённом примере показано, как Druid кладётся в основу аналитического приложения, отличающегося высокой интерактивностью, и логичен вопрос: “а как это всё связано с потоковой передачей данных?” Вопрос хороший, поскольку Druid может работать не только с потоковыми данными. Он также очень хорош в случаях, когда требуется поглощать большие пакетные данные.
Но Druid особенно важен в архитектурах для работы с данными реального времени, так как обеспечивает интерактивное взаимодействие с данными, как получаемыми в реальном времени, так и с данными, собранными исторически и дающими ещё более насыщенный контекст.
Тогда как Flink отлично помогает ответить на вопрос «что сейчас происходит» (т. е. выдаёт тот статус, в котором в настоящий момент находится задание Flink), Druid технически не очень приспособлен для ответов на вопросы: «что сейчас происходит, как это соотносится с событиями, происходившими ранее, какие факторы/условия привели к такому результату». В совокупности у этих вопросов большой потенциал, поскольку они позволяют, например, исключить ложноположительные результаты, выявить новые тренды, принимать в режиме реального времени более проницательные решения.
Для ответа на вопрос «как это соотносится с событиями, происходившими ранее» требуется исторический контекст – нужно знать день, неделю, год или другой временной горизонт, чтобы произвести корреляцию. Вопрос «какие факторы/условия привели к такому результату» требуют интеллектуального анализа всего датасета. Поскольку Druid – это база данных для аналитики в режиме реального времени, она поглощает информацию в режиме реального времени, но попутно и долговременно сохраняет её. Так эти данные превращаются в исторические, и впоследствии их также можно запрашивать, чтобы взглянуть на них под другим углом или провести какое-нибудь импровизрованное исследование.
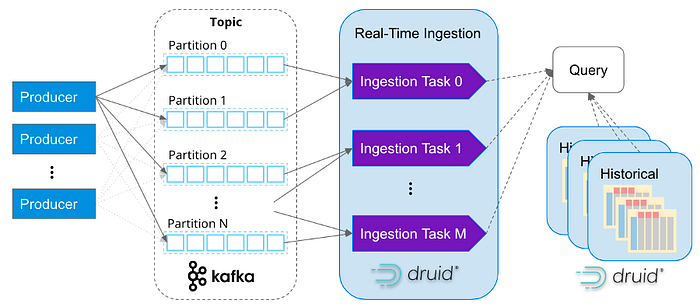
Как в Apache Druid в реальном времени масштабируется поглощение данных и топики соотносятся с задачами, решаемыми на поглощаемых данных (иллюстрация imply.io)
Например, допустим, что мы создаём приложение, отслеживающее безопасные входы в систему и выискивающее в них признаки подозрительного поведения. В качестве порогового значения можно установить окно в 5 минут: то есть, обновлять и выдавать информацию о попытках входа в систему. Для Flink это легко. Но в Druid актуальные попытки входа в систему также будут соотноситься с историческими данными по таким попыткам, чтобы выявить в прошлом такие всплески попыток входа в систему, которые не привели к нарушению безопасности. Таким образом, исторический контекст в данном случае позволяет определить, свидетельствует ли данный всплеск о возникшей проблеме или вполне нормален.
Соответственно, если у вас есть приложение, в котором требуется представлять много аналитики – например, текущий статус, различные агрегации, варианты группирования, временные окна, сложные объединения и т. д. – по стремительно меняющимся событиям, но также важен исторический контекст и исследование имеющихся данных через максимально гибкий API, то лучше Druid вам ничего не найти.
❯ Лист самопроверки по Flink и Druid
Как Flink, так и Druid созданы для работы с потоковыми данными. На базовом уровне у них действительно есть общие черты: оба работают в оперативной памяти, оба могут масштабироваться, распараллеливаться, при этом их архитектуры выстраивались в расчёте на совершенно разные варианты использования, как и было рассмотрено выше.
Вот простой список вопросов для самопроверки, на которые нужно ответить, понимая, о какой рабочей нагрузке идёт речь:
- Требуется ли нам преобразовывать или объединять данные в режиме реального времени или отправлять данные в виде потока?
Присмотритесь к Flink, поскольку это его «конёк» — инструмент проектировался именно для обработки данных в режиме реального времени. - Требуется ли конкурентно поддерживать сразу множество разных запросов?
Присмотритесь к Druid, так как он поддерживает аналитику с большим количеством запросов в секунду и не требует управлять ни запросами, ни заданиями. - Требуется ли непрерывно обновлять или агрегировать метрики?
Присмотритесь к Flink, так как он поддерживает сложную обработку событий с сохранением состояния. - Предполагается ли аналитика повышенной сложности и сравнение актуальных данных с историческими?
Присмотритесь к Druid, так как он может легко и быстро запрашивать данные реального времени в сочетании с историческими данными. - Требуется ли поддерживать клиентский интерфейс приложения или визуализацию данных?
Попробуйте обогатить данные во Flink, а затем отправьте их в Druid, который станет для вас уровнем обслуживания данных.
Как правило, на выходе имеем не Druid или Flink, а скорее Druid и Flink. Технические характеристики обоих очень располагают к сочетанию этих инструментов друг с другом и для поддержки широкого спектра приложений реального времени.
❯ Заключение
Бизнес все активнее требует от аналитиков данных именно данные, получаемые в режиме реального времени. Это означает, что работу с потоком данных нужно переосмыслить от начала и до конца. Вот почему многие компании обращаются к триаде Kafka-Flink-Druid как к де-факто стандартной опенсорсной архитектуре для приложений, работающих с данными в реальном времени. Эта триада просто идеальная.
Если хотите попробовать архитектуру Kafka-Flink-Druid, то эти опенсорсные проекты можно скачать здесь: Kafka, Flink, Druid.





