За рубежом все большую популярность набирает использование искусственного интеллекта в промышленности для предиктивного обслуживания (predictive maintenance) различных систем. Цель этой методики — определение неполадок в работе системы на этапе эксплуатации до выхода её из строя для своевременного реагирования.
Насколько востребован такой подход у нас и на Западе? Вывод можно сделать, например, по статьям на Хабре и в Medium. На Хабре почти не встречается статей по решению задач предиктивного обслуживания. На Medium же есть целый набор. Вот здесь, ещё здесь и здесь хорошо описано, в чем цели и преимущества такого подхода.
Из этой статьи вы узнаете:
 Источник
Источник
Какие возможности даёт предиктивное обслуживание:
В очередной статье на Medium хорошо описаны вопросы, на которые нужно ответить, чтобы понять как в конкретном случае подступиться к этому вопросу.
При сборе данных или при выборе данных для построения модели важно ответить на три группы вопросов:
Важно также заранее понимать, что вы хотите предсказывать, и что предсказать возможно, а что — нет.
В статье на Medium также перечислены вопросы, которые помогут определиться с вашей конкретной целью:
Есть надежда, что ситуация в будущем будет исправляться. Пока в области предиктивного обслуживания есть сложности: мало примеров неправильной работы системы, или моментов времени неправильной работы системы достаточно, но они не размечены; процесс выхода из строя неизвестен.
Основным способом преодоления сложностей в предиктивном обслуживании является использование методов поиска аномалий. Такие алгоритмы не требуют разметки для обучения. Для тестирования и отладки алгоритмов разметка в том или ином виде необходима. Такие методы ограничены тем, что будут предсказывать не конкретную поломку, а лишь сигнализировать о ненормальности показателей.
Но и это уже неплохо.
 Источник
Источник
Теперь хочу рассказать об некоторых особенностях подходов обнаружения аномалий, а потом мы вместе проверим возможности некоторых простых алгоритмов на практике.
Хотя для конкретной ситуации потребуется тестирование нескольких алгоритмов поиска аномалий и выбор лучшего, можно определить некоторые преимущества и недостатки основных методик, используемых в этой области.
В первую очередь важно заранее понимать, каков процент аномалий в данных.
Если речь идет о вариации semi-supervised подхода (обучаемся только на «нормальных» данных, а работаем (тестируемся) потом на данных с аномалиями), то наиболее оптимальным будет выбор метода опорных векторов с одним классом (One-Class SVM). При использовании радиальных базисных функций в качестве ядра этот алгоритм строит нелинейную поверхность вокруг начала координат. Чем чище данные для обучения, тем лучше он работает.
В остальных случаях необходимость знать соотношение аномальных и «нормальных» точек также остается — для определения порога отсечения.
Если число аномалий в данных более 5%, и они достаточно хорошо отделимы от основной выборки, можно использовать стандартные методы поиска аномалий.
В этом случае наиболее стабильным с точки зрения качества является метод изолирующего леса (isolation forest): данные сплитуются случайным образом. У более характерного показания больше вероятность попасть глубже, в то время как необычные показатели будут отделяться от остальной выборки на первых итерациях.
Остальные алгоритмы работают лучше, если «подходят» под специфику данных.
Когда данные имеют нормальное распределение, то подходит метод Elliptic envelope, апроксимирующий данные многомерным нормальным распределением. Чем меньше вероятность, что точка принадлежит распределению, тем больше вероятность, что она аномальная.
Если же данные представлены таким образом, что относительное положение разных точек хорошо отражает их различия, то хорошим выбором представляется метрические методы: например, k ближайших соседей, k-го ближайшего соседа, ABOD (angle-based outlier detection) или LOF (local outlier factor).
Все эти методы предполагают, что «правильные» показатели сконцентрированы в одной области многомерного пространства. Если среди k (или k-ый) ближайших соседей все далеко от целевой, значит точка — аномалия. Для ABOD рассуждения схожие: если все k ближайших точек находятся в одном секторе пространства относительно рассматриваемой, то точка — аномалия. Для LOF: если локальная плотность (заранее определенная для каждой точки по k ближайшим соседям) ниже, чем у k ближайших соседей, то точка — аномалия.
Если данные хорошо кластеризуются — хорошим выбором представляются методы, основанные на кластерном анализе. Если точка равноудалена от центров нескольких кластеров, значит она аномальная.
Если в данных хорошо выделяются направления наибольшего изменения дисперсии, то представляется хорошим выбором — поиск аномалий на основе метода главных компонент. В этом случае в качестве меры аномальности рассматриваются отклонения от среднего значения по n1 (наиболее «главным» компонентам) и по n2 (наименее «главным»).
Для примера предлагается посмотреть на дата-сет от The Prognostics and Health Management Society (PHM Society). Эта нон-профит организация устраивает каждый год соревнования. В 2018 году например требовалось предсказать ошибки в работе и время до выхода из строя установки для ионно-лучевого травления. Мы же возьмем дата-сет за 2015 год. В нем даны показания нескольких датчиков для 30 заводов (обучающая выборка), и требуется предсказать, когда и какая ошибка произойдет.
Ответы по тестовой выборке я в сети не нашел, так что будем играться только с обучающей.
В целом все заводы похожи, но различаются, например, по числу компонент, в числе аномалий и т.д. Поэтому обучаться на первых 20, а тестироваться — на других большого смысла не имеет.
Итак, выберем один из заводов, подгрузим и немного на него посмотрим. Статья будет не про feature engineering, поэтому сильно всматриваться не будем.
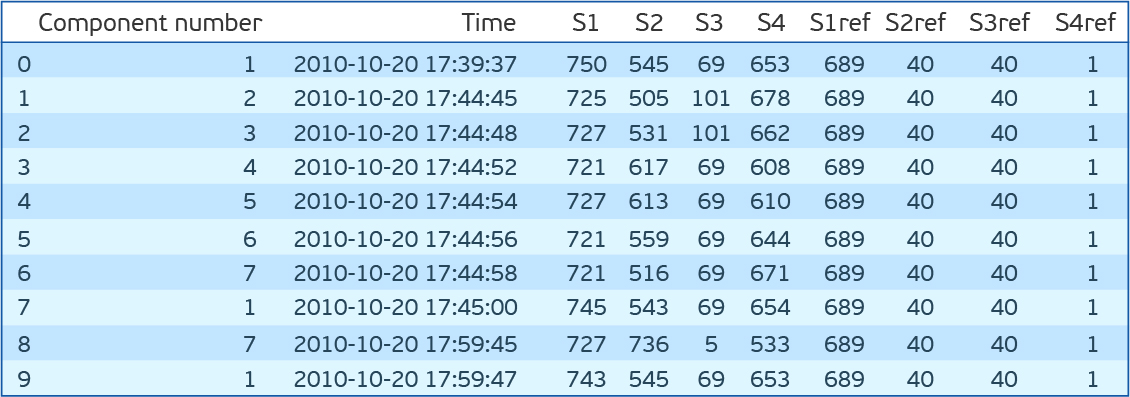
Как видим есть семь компонент для каждой из которых есть показания четырёх датчиков, которые снимаются каждые 15 минут. S1ref-S4ref в описании соревнования значатся как референсные значения, но по значениям сильно отличаются от показаний датчиков. Чтобы не тратить время на раздумья о том, что они означают, убираем их. Если посмотреть на распределение значения для каждого признака (S1-S4), то окажется, что у S1, S2 и S4 распределения непрерывны, а у S3 дискретны. Кроме того, если посмотреть на совместное распределение S2 и S4, окажется, что они обратно пропорциональны.
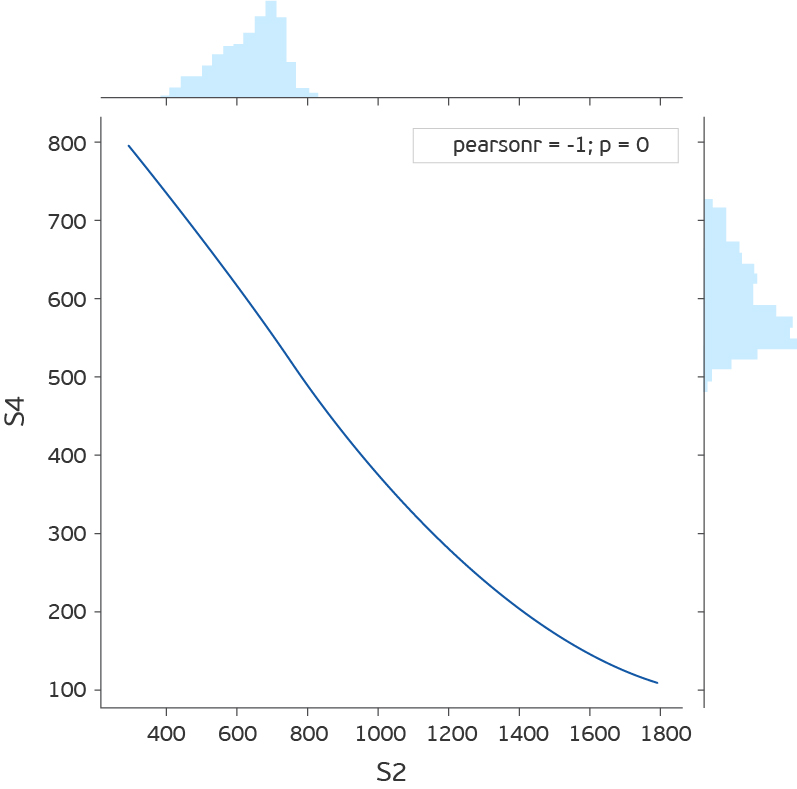
Хотя отклонение от прямой зависимости и может говорить об ошибке, не станем это проверять, а просто уберем S4.
Ещё раз обработаем дата-сет. Оставляем S1, S2 и S3. S1 и S2 шкалируем StandardScaler’ом (вычитаем среднее и делим на стандартное отклонение), S3 переводим в OHE (One Hot Encoding). Сшиваем показания от всех компонент завода в одну строку. Итого 89 фичей. 2*7 = 14 — показания S1 и S2 для 7 компонент и 75 уникальных значений R3. Всего 56 тыс. таких строк.
Подгрузим файл с ошибками.
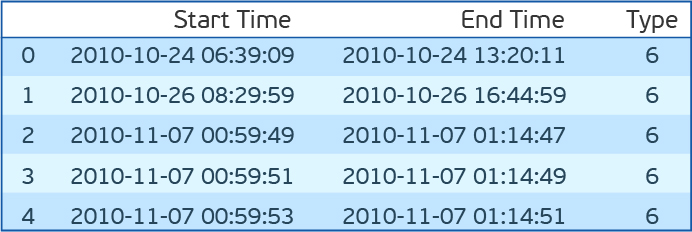
Перед тем, как попробовать перечисленные алгоритмы на нашем дата-сете, позволю себе ещё одно небольшое отступление. Нужно ведь тестироваться. Для этого предлагается взять время начала ошибки и время конца. И все показания внутри этого промежутка считать аномальными, а вне — нормальными. У этого подхода есть много недостатков. Но особенно один — аномальное поведение скорее всего возникает до того, как ошибка фиксируется. Сдвинем для верности окно аномальности на полчаса назад во времени. Оценивать будем F1-меру, точность (precision) и полноту (recall).
Код выделения признаков и определения качества модели:
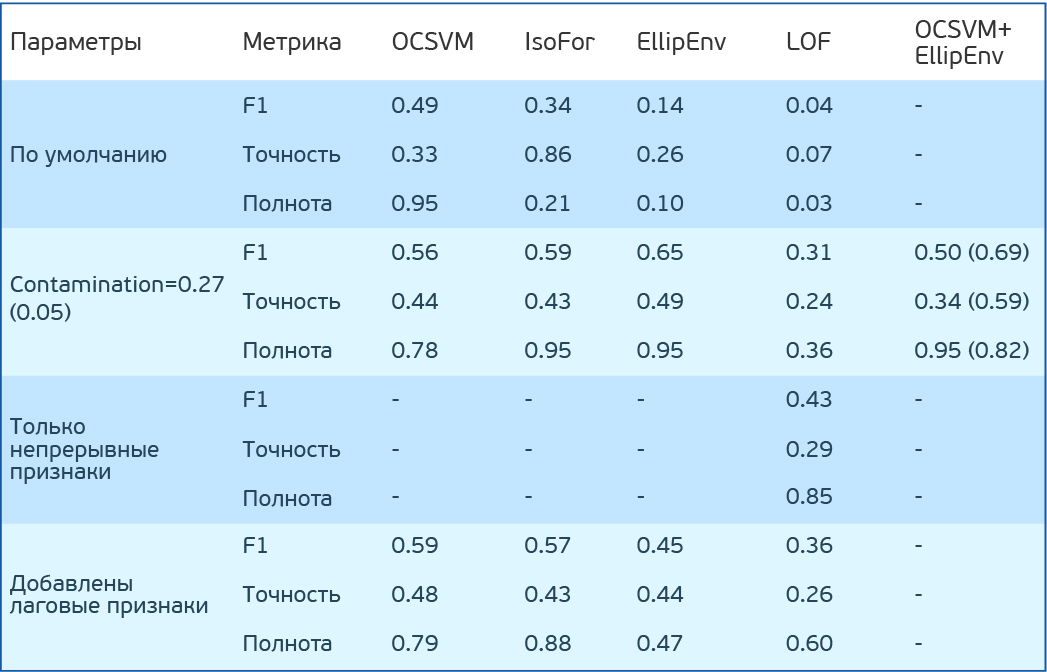 Результаты тестирования простых алгоритмов поиска аномалий на датасете PHM 2015 Data Challenge
Результаты тестирования простых алгоритмов поиска аномалий на датасете PHM 2015 Data Challenge
Вернёмся к алгоритмам. Попробуем One Class SVM (OCSVM), IsolationForest (IF), EllipticEnvelope (EE) и LocalOutlierFactor (LOF) на наших данных. Для начала никакие параметры задавать не будем. Отмечу, что LOF может работать в двух режимах. Если novelty=False умеет искать аномалии только в обучающей выборке (есть только fit_predict), если True, то нацелен на поиск аномалий вне обучающей выборки (умеет отдельно fit и predict). У IF есть режим (behaviour) old и new. Используем new. Он дает результаты получше.
OCSVM определяет аномалии хорошо, но слишком много ложно-положительных результатов. У остальных методов результат еще хуже.
Но предположим, что мы знаем процент аномалий в данных. В нашем случае 27%. У OCSVM есть nu — верхняя оценка на процент ошибок и нижняя на процент опорных векторов. У остальных методов contamination — процент ошибок в данных. В методах IF и LOF он определяется автоматически, а у OCSVM и EE задан по умолчанию равным 0.1. Попробуем задать contamination (nu) равным 0.27. Теперь топовый результат у EE.
Код для проверки моделей:
Интересно посмотреть на распределения показателей аномальности для разных методов. Видно, что LOF действительно работает плохо для этих данных. У ЕЕ есть точки, которые алгоритм считает крайне аномальными. Тем не менее, туда попадают и нормальные точки. У IsoFor и OCSVM видно, что важен выбор порога отсечения (contamination/nu), который будет менять trade-off между точностью и полнотой.

Логично, что показания датчиков имеют близкое к нормальному распределение, вблизи стационарных значений. Если у нас действительно есть размеченная тестовая выборка, а лучше еще и валидационная, то можно значение contamination оттюнить. Дальше уже вопрос, на какие ошибки ориентироваться больше: ложноположительные или ложноотрицательные?
Результат LOF совсем низкие. Не очень впечатляет. Но вспомним, что на вход у нас идут OHE переменные наравне с переменными преобразованными StandardScaler’ом. А расстояния по умолчанию евклидовы. А вот если посчитать только по S1 и S2 переменным, то ситуация выправляется и результат получается сравним с другими методами. Важно, тем не менее, понимать, что один из ключевых параметров перечисленных метрических классификаторов — число соседей. Оно значительно влияет на качество, и его необходимо тюнить. Саму метрику расстояния тоже хорошо бы подбирать.
Теперь попробуем совместить две модели. В начале одной уберем аномалии из обучающей выборки. А потом на более «чистой» обучающей выборке обучим OCSVM. По предыдущем результатам наибольшую полноту мы наблюдали у EE. Очищаем обучающую выборку через EE, тренируем OCSVM на ней и получаем F1 = 0.50, Точность = 0.34, полнота = 0.95. Не впечатляет. Вот только мы же задались nu = 0.27. А данные у нас более или менее «чистые». Если предположить, что на обучающей выборке полнота у EE будет такой же, то ошибок останется 5%. Зададимся таким nu и получим F1 = 0.69, Точность = 0.59, полнота = 0.82. Отлично. Важно отметить, что в других методах такое совмещение не прокатит, поскольку они подразумевают, что в обучающей выборке и тестовой число аномалий одинаково. При обучении этих методов на чистом тренировочном дата-сете придется задавать contamination меньше, чем в реальных данных, и не близкий к нулю, но лучше его подбирать на кросс-валидации.
Интересно посмотреть на результат поиска на последовательности показаний:

На рисунке показан отрезок показаний первого и второго датчиков для 7 компонент. В легенде цвет соответствующих ошибок (начало и конец показаны вертикальными линиями одного цвета). Точками обозначены предсказания: зеленым — верные предсказания, красным — ложноположительные, фиолетовым — ложноотрицательные. Из рисунка видно, что визуально определить время ошибок сложно, а алгоритм справляется с этой задачей достаточно хорошо. Хотя важно понимать, что показания третьего датчика тут не приведены. Кроме того, есть ложноположительные показания после окончания ошибки. Т.е. алгоритм видит, что там тоже ошибочные значения, а мы разметили эту область как безошибочную. Справа на рисунке видна область перед ошибкой, которую мы разметили как ошибочную (за полчаса до ошибки), которая распознана как безошибочная, что приводит к ложноотрицательным ошибкам модели. В центре рисунка виден связный кусок, распознанный как ошибка. Вывод можно сделать следующий: при решении задачи поиска аномалий нужно плотно взаимодействовать с инженерами, понимающими суть работы систем, выход их строя которых нужно предсказывать, поскольку проверка используемых алгоритмов на разметке не до конца отражает реальность и не моделирует условий, в которых такие алгоритмы могли бы использоваться.
Код для отрисовки графика:
Если процент аномалий ниже 5% и/или они плохо отделяемы от «нормальных» показателей, вышеперечисленные методы работают плохо и стоит использовать алгоритмы на основе нейронных сетей. В самом простом случае это будут:
Отдельно стоит отметить специфику работы с временными рядами. Важно понимать, что большинство вышеперечисленных алгоритмов (кроме автоэнкодеров и изолирующего леса) скорее всего будут давать худшее качество при добавлении лаговых признаков (показаний за предыдущие моменты времени).
Попробуем добавить лаговые признаки в нашем примере. В описании соревнования говорится, что значения за 3 часа до ошибки уже с ошибкой никак не связаны. Тогда добавим признаки за 3 часа. Итого 259 признаков.
В итоге у OCSVM и IsolationForest результаты почти не изменились, а у Elliptic Envelope и LOF упали.
Для использования информации о динамике системы, следует использовать автоэнкодеры с рекуррентными или со сверточными нейронными сетями. Или же, например, сочетание автоэкодеров, сжимающих информацию, и обычных подходов поиска аномалий на основе сжатой информации. Перспективным представляется и обратный подход. Первичный отсев наиболее нехарактерных точек стандартными алгоритмами, а затем обучение автоэнкодера уже на более чистых данных.
 Источник
Источник
Существует набор методик для работы с одномерными временными рядами. Все они нацелены на предсказания будущих показаний, а аномалиями считаются точки, расходящиеся с предсказанием.
Тройное экспоненциальное сглаживание, раскладывает ряд на 3 компоненты: уровень, тренд и сезонность. Соответственно, если ряд представим в таком виде, метод работает хорошо. Facebook Prophet действует по похожему принципу, но сами компоненты оценивает по-другому. Подробнее можно почитать, например, здесь.
В этом методе предсказательная модель строится на авторегрессии и скользящем среднем. Если речь идет о расширении S(ARIMA), то позволяет и оценивать сезонность. Подробнее о подходе можно прочитать здесь, здесь и здесь.
Когда речь идет о временных рядах и присутствует информация о временах возникновения ошибок, можно применять методы обучения с учителем. Помимо необходимости размеченных данных в этом случае важно понимать, что предсказание ошибки будет зависеть от природы ошибки. Если ошибок много и разной природы, скорее всего нужно будет предсказывать каждую по отдельности, что потребует еще больше размеченных данных, но и перспективы будут привлекательнее.
Есть и альтернативные способы использования машинного обучения в предиктивном обслуживании. Например, предсказание выхода системы из строя в ближайшие N дней (задача классификации). Важно понимать, что такой подход требует, чтобы возникновению ошибки в работе системы предшествовал период деградации (необязательно постепенной). При этом наиболее удачным подходом представляется использование нейросетей со сверточными и/или рекуррентными слоями. Отдельно стоит отметить методы по аргументации временных рядов. Мне наиболее интересными и одновременно простыми представляются два подхода:
Ещё есть вариант с предсказанием оставшегося времени жизни системы (задача регрессии). Здесь можно выделить отдельный подход: предсказание не времени жизни, а параметров распределения Вейбулла.
Про само распределение можно почитать здесь, а здесь про использование его в связке с рекуррентными сетками. У этого распределения два параметра α и β. α говорит о том, когда произойдет событие, а β — о том, насколько алгоритм в этом уверен. Хотя применение такого подхода перспективно, возникают трудности при обучении нейронной сети в этом случае, поскольку алгоритму вначале легче быть неуверенным, чем предсказывать адекватное время жизни.
Отдельно стоит отметить регрессию Кокса. Она позволяет предсказывать отказоустойчивость системы для каждого момента времени после диагностики, представляя его в виде произведения двух функций. Одна функция представляет собой деградацию системы, не зависимую от ее параметров, т.е. общую для любых таким систем. А вторая — экспоненциальную зависимость от параметров конкретной системы. Так для человека есть общая функция, связанная со старением, более менее одинаковым для всех. Но ухудшение здоровья связано и с состоянием внутренних органов, которое у всех разное.
Надеюсь, теперь вы знаете о предиктивном обслуживании чуть больше. Уверен, у вас появятся вопросы, касательно методов машинного обучения, которые чаще всего используются для этой технологии. Я буду рад ответить на каждый из них в комментариях. Если вам интересно не просто спросить о написанном, а хочется заниматься чем-то подобным, наша команда в CleverDATA всегда рада талантливым и увлеченным профессионалам.
Насколько востребован такой подход у нас и на Западе? Вывод можно сделать, например, по статьям на Хабре и в Medium. На Хабре почти не встречается статей по решению задач предиктивного обслуживания. На Medium же есть целый набор. Вот здесь, ещё здесь и здесь хорошо описано, в чем цели и преимущества такого подхода.
Из этой статьи вы узнаете:
- зачем нужна эта методика,
- какие подходы машинного обучения чаще используются для предиктивного обслуживания,
- как я опробовал один из приёмов на простом примере.
Какие возможности даёт предиктивное обслуживание:
- контролируемый процесс ремонтных работ, которые выполняются по мере необходимости, сохраняя таким образом деньги, и без спешки, что улучшает качество этих работ;
- определение конкретной неполадки в работе оборудования (возможность приобрести определенную деталь для замены при работающем оборудовании дает огромные преимущества);
- оптимизация работы оборудования, нагрузок и т.п.;
- уменьшение затрат на регулярное отключение оборудования.
В очередной статье на Medium хорошо описаны вопросы, на которые нужно ответить, чтобы понять как в конкретном случае подступиться к этому вопросу.
При сборе данных или при выборе данных для построения модели важно ответить на три группы вопросов:
- Все ли неполадки в системе можно предсказать? Какие предсказать особенно важно?
- Что представляет собой процесс выхода из строя? Прекращается ли работа системы целиком или только меняется режим работы? Быстрый ли это процесс, мгновенный или постепенная деградация?
- В достаточной ли степени показатели системы отражают ее работоспособность? Относятся ли они к отдельным частям системы или к системе в целом?
Важно также заранее понимать, что вы хотите предсказывать, и что предсказать возможно, а что — нет.
В статье на Medium также перечислены вопросы, которые помогут определиться с вашей конкретной целью:
- Что нужно предсказывать? Оставшееся время жизни, аномальное поведение или нет, вероятность выйти из строя за следующие N часов/дней/недель?
- Достаточно ли накопленных исторических данных?
- Известно ли, когда система выдавала аномальные показания, а когда — нет. Возможна ли разметка таковых показаний?
- Насколько вперед должна видеть модель? Насколько независимы показания, отражающие работу системы, в промежутке часа/дня/недели
- Что нужно оптимизировать? Должна ли модель отлавливать как можно больше нарушений, при этом выдавая ложную тревогу, или достаточно отлавливать несколько событий, без ложных срабатываний.
Есть надежда, что ситуация в будущем будет исправляться. Пока в области предиктивного обслуживания есть сложности: мало примеров неправильной работы системы, или моментов времени неправильной работы системы достаточно, но они не размечены; процесс выхода из строя неизвестен.
Основным способом преодоления сложностей в предиктивном обслуживании является использование методов поиска аномалий. Такие алгоритмы не требуют разметки для обучения. Для тестирования и отладки алгоритмов разметка в том или ином виде необходима. Такие методы ограничены тем, что будут предсказывать не конкретную поломку, а лишь сигнализировать о ненормальности показателей.
Но и это уже неплохо.
Методы
Теперь хочу рассказать об некоторых особенностях подходов обнаружения аномалий, а потом мы вместе проверим возможности некоторых простых алгоритмов на практике.
Хотя для конкретной ситуации потребуется тестирование нескольких алгоритмов поиска аномалий и выбор лучшего, можно определить некоторые преимущества и недостатки основных методик, используемых в этой области.
В первую очередь важно заранее понимать, каков процент аномалий в данных.
Если речь идет о вариации semi-supervised подхода (обучаемся только на «нормальных» данных, а работаем (тестируемся) потом на данных с аномалиями), то наиболее оптимальным будет выбор метода опорных векторов с одним классом (One-Class SVM). При использовании радиальных базисных функций в качестве ядра этот алгоритм строит нелинейную поверхность вокруг начала координат. Чем чище данные для обучения, тем лучше он работает.
В остальных случаях необходимость знать соотношение аномальных и «нормальных» точек также остается — для определения порога отсечения.
Если число аномалий в данных более 5%, и они достаточно хорошо отделимы от основной выборки, можно использовать стандартные методы поиска аномалий.
В этом случае наиболее стабильным с точки зрения качества является метод изолирующего леса (isolation forest): данные сплитуются случайным образом. У более характерного показания больше вероятность попасть глубже, в то время как необычные показатели будут отделяться от остальной выборки на первых итерациях.
Остальные алгоритмы работают лучше, если «подходят» под специфику данных.
Когда данные имеют нормальное распределение, то подходит метод Elliptic envelope, апроксимирующий данные многомерным нормальным распределением. Чем меньше вероятность, что точка принадлежит распределению, тем больше вероятность, что она аномальная.
Если же данные представлены таким образом, что относительное положение разных точек хорошо отражает их различия, то хорошим выбором представляется метрические методы: например, k ближайших соседей, k-го ближайшего соседа, ABOD (angle-based outlier detection) или LOF (local outlier factor).
Все эти методы предполагают, что «правильные» показатели сконцентрированы в одной области многомерного пространства. Если среди k (или k-ый) ближайших соседей все далеко от целевой, значит точка — аномалия. Для ABOD рассуждения схожие: если все k ближайших точек находятся в одном секторе пространства относительно рассматриваемой, то точка — аномалия. Для LOF: если локальная плотность (заранее определенная для каждой точки по k ближайшим соседям) ниже, чем у k ближайших соседей, то точка — аномалия.
Если данные хорошо кластеризуются — хорошим выбором представляются методы, основанные на кластерном анализе. Если точка равноудалена от центров нескольких кластеров, значит она аномальная.
Если в данных хорошо выделяются направления наибольшего изменения дисперсии, то представляется хорошим выбором — поиск аномалий на основе метода главных компонент. В этом случае в качестве меры аномальности рассматриваются отклонения от среднего значения по n1 (наиболее «главным» компонентам) и по n2 (наименее «главным»).
Для примера предлагается посмотреть на дата-сет от The Prognostics and Health Management Society (PHM Society). Эта нон-профит организация устраивает каждый год соревнования. В 2018 году например требовалось предсказать ошибки в работе и время до выхода из строя установки для ионно-лучевого травления. Мы же возьмем дата-сет за 2015 год. В нем даны показания нескольких датчиков для 30 заводов (обучающая выборка), и требуется предсказать, когда и какая ошибка произойдет.
Ответы по тестовой выборке я в сети не нашел, так что будем играться только с обучающей.
В целом все заводы похожи, но различаются, например, по числу компонент, в числе аномалий и т.д. Поэтому обучаться на первых 20, а тестироваться — на других большого смысла не имеет.
Итак, выберем один из заводов, подгрузим и немного на него посмотрим. Статья будет не про feature engineering, поэтому сильно всматриваться не будем.
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
from sklearn.covariance import EllipticEnvelope
from sklearn.neighbors import LocalOutlierFactor
from sklearn.ensemble import IsolationForest
from sklearn.svm import OneClassSVM
dfa=pd.read_csv('plant_12a.csv',names=['Component number','Time','S1','S2','S3','S4','S1ref','S2ref','S3ref','S4ref'])
dfa.head(10)Как видим есть семь компонент для каждой из которых есть показания четырёх датчиков, которые снимаются каждые 15 минут. S1ref-S4ref в описании соревнования значатся как референсные значения, но по значениям сильно отличаются от показаний датчиков. Чтобы не тратить время на раздумья о том, что они означают, убираем их. Если посмотреть на распределение значения для каждого признака (S1-S4), то окажется, что у S1, S2 и S4 распределения непрерывны, а у S3 дискретны. Кроме того, если посмотреть на совместное распределение S2 и S4, окажется, что они обратно пропорциональны.
Хотя отклонение от прямой зависимости и может говорить об ошибке, не станем это проверять, а просто уберем S4.
Ещё раз обработаем дата-сет. Оставляем S1, S2 и S3. S1 и S2 шкалируем StandardScaler’ом (вычитаем среднее и делим на стандартное отклонение), S3 переводим в OHE (One Hot Encoding). Сшиваем показания от всех компонент завода в одну строку. Итого 89 фичей. 2*7 = 14 — показания S1 и S2 для 7 компонент и 75 уникальных значений R3. Всего 56 тыс. таких строк.
Подгрузим файл с ошибками.
dfc=pd.read_csv('plant_12c.csv',names=['Start Time', 'End Time','Type'])
dfc.head()Перед тем, как попробовать перечисленные алгоритмы на нашем дата-сете, позволю себе ещё одно небольшое отступление. Нужно ведь тестироваться. Для этого предлагается взять время начала ошибки и время конца. И все показания внутри этого промежутка считать аномальными, а вне — нормальными. У этого подхода есть много недостатков. Но особенно один — аномальное поведение скорее всего возникает до того, как ошибка фиксируется. Сдвинем для верности окно аномальности на полчаса назад во времени. Оценивать будем F1-меру, точность (precision) и полноту (recall).
Код выделения признаков и определения качества модели:
def load_and_preprocess(plant_num):
#загружаем в память показания датчиков и времена, когда были зафиксированы ошибки
dfa=pd.read_csv('plant_{}a.csv'.format(plant_num),names=['Component number','Time','S1','S2','S3','S4','S1ref','S2ref','S3ref','S4ref'])
dfc=pd.read_csv('plant_{}c.csv'.format(plant_num),names=['Start Time','End Time','Type']).drop(0,axis=0)
N_comp=len(dfa['Component number'].unique())
#округляем до 15 минут
dfa['Time']=pd.to_datetime(dfa['Time']).dt.round('15min')
#ошибка номер 6 нас не интересует (в соревновании говорилась, что ее не рассматривать)
dfc=dfc[dfc['Type']!=6]
dfc['Start Time']=pd.to_datetime(dfc['Start Time'])
dfc['End Time']=pd.to_datetime(dfc['End Time'])
#сливаем строки от разных модулей в одну, а затем еще и переводим в OHE показания 3-го датчика
dfa=pd.concat([dfa.groupby('Time').nth(i)[['S1','S2','S3']].rename(columns={"S1":"S1_{}".format(i),"S2":"S2_{}".format(i),"S3":"S3_{}".format(i)}) for i in range(N_comp)],axis=1).dropna().reset_index()
for k in range(N_comp):
dfa=pd.concat([dfa.drop('S3_'+str(k),axis=1),pd.get_dummies(dfa['S3_'+str(k)],prefix='S3_'+str(k))],axis=1).reset_index(drop=True)
#делим на обучающую и тестовую выборки и шкалируем
df_train,df_test=train_test_split(dfa,test_size=0.25,shuffle=False)
cols_to_scale=df_train.filter(regex='S[1,2]').columns
scaler=preprocessing.StandardScaler().fit(df_train[cols_to_scale])
df_train[cols_to_scale]=scaler.transform(df_train[cols_to_scale])
df_test[cols_to_scale]=scaler.transform(df_test[cols_to_scale])
return df_train,df_test,dfc
#код для получения разметки в тестовых данных
def get_true_labels(measure_times,dfc,shift_delta):
idxSet=set()
dfc['Start Time']-=pd.Timedelta(minutes=shift_delta)
dfc['End Time']-=pd.Timedelta(minutes=shift_delta)
for idx,mes_time in tqdm_notebook(enumerate(measure_times),total=measure_times.shape[0]):
intersect=np.array(dfc['Start Time']<mes_time).astype(int)*np.array(dfc['End Time']>mes_time).astype(int)
idxs=np.where(intersect)[0]
if idxs.shape[0]:
idxSet.add(idx)
dfc['Start Time']+=pd.Timedelta(minutes=shift_delta)
dfc['End Time']+=pd.Timedelta(minutes=shift_delta)
true_labels=pd.Series(index=measure_times.index)
true_labels.iloc[list(idxSet)]=1
true_labels.fillna(0,inplace=True)
return true_labels
#код для проверки качества модели и распечатки распределения показателей аномальности
def check_model(model,df_train,df_test,filt='S[123]'):
model.fit(df_train.drop('Time',axis=1).filter(regex=(filt)))
y_preds = pd.Series(model.predict(df_test.drop(['Time','Label'],axis=1).filter(regex=(filt)))).map({-1:1,1:0})
print('F1 score: {:.3f}'.format(f1_score(df_test['Label'],y_preds)))
print('Precision score: {:.3f}'.format(precision_score(df_test['Label'],y_preds)))
print('Recall score: {:.3f}'.format(recall_score(df_test['Label'],y_preds)))
score = model.decision_function(df_test.drop(['Time','Label'],axis=1).filter(regex=(filt)))
sns.distplot(score[df_test['Label']==0])
sns.distplot(score[df_test['Label']==1])
df_train,df_test,anomaly_times=load_and_preprocess(12)
df_test['Label']=get_true_labels(df_test['Time'],dfc,30)Вернёмся к алгоритмам. Попробуем One Class SVM (OCSVM), IsolationForest (IF), EllipticEnvelope (EE) и LocalOutlierFactor (LOF) на наших данных. Для начала никакие параметры задавать не будем. Отмечу, что LOF может работать в двух режимах. Если novelty=False умеет искать аномалии только в обучающей выборке (есть только fit_predict), если True, то нацелен на поиск аномалий вне обучающей выборки (умеет отдельно fit и predict). У IF есть режим (behaviour) old и new. Используем new. Он дает результаты получше.
OCSVM определяет аномалии хорошо, но слишком много ложно-положительных результатов. У остальных методов результат еще хуже.
Но предположим, что мы знаем процент аномалий в данных. В нашем случае 27%. У OCSVM есть nu — верхняя оценка на процент ошибок и нижняя на процент опорных векторов. У остальных методов contamination — процент ошибок в данных. В методах IF и LOF он определяется автоматически, а у OCSVM и EE задан по умолчанию равным 0.1. Попробуем задать contamination (nu) равным 0.27. Теперь топовый результат у EE.
Код для проверки моделей:
def check_model(model,df_train,df_test,filt='S[123]'):
model_type,model = model
model.fit(df_train.drop('Time',axis=1).filter(regex=(filt)))
y_preds = pd.Series(model.predict(df_test.drop(['Time','Label'],axis=1).filter(regex=(filt)))).map({-1:1,1:0})
print('F1 score for {}: {:.3f}'.format(model_type,f1_score(df_test['Label'],y_preds)))
print('Precision score for {}: {:.3f}'.format(model_type,precision_score(df_test['Label'],y_preds)))
print('Recall score for {}: {:.3f}'.format(model_type,recall_score(df_test['Label'],y_preds)))
score = model.decision_function(df_test.drop(['Time','Label'],axis=1).filter(regex=(filt)))
sns.distplot(score[df_test['Label']==0])
sns.distplot(score[df_test['Label']==1])
plt.title('Decision score distribution for {}'.format(model_type))
plt.show()Интересно посмотреть на распределения показателей аномальности для разных методов. Видно, что LOF действительно работает плохо для этих данных. У ЕЕ есть точки, которые алгоритм считает крайне аномальными. Тем не менее, туда попадают и нормальные точки. У IsoFor и OCSVM видно, что важен выбор порога отсечения (contamination/nu), который будет менять trade-off между точностью и полнотой.
Логично, что показания датчиков имеют близкое к нормальному распределение, вблизи стационарных значений. Если у нас действительно есть размеченная тестовая выборка, а лучше еще и валидационная, то можно значение contamination оттюнить. Дальше уже вопрос, на какие ошибки ориентироваться больше: ложноположительные или ложноотрицательные?
Результат LOF совсем низкие. Не очень впечатляет. Но вспомним, что на вход у нас идут OHE переменные наравне с переменными преобразованными StandardScaler’ом. А расстояния по умолчанию евклидовы. А вот если посчитать только по S1 и S2 переменным, то ситуация выправляется и результат получается сравним с другими методами. Важно, тем не менее, понимать, что один из ключевых параметров перечисленных метрических классификаторов — число соседей. Оно значительно влияет на качество, и его необходимо тюнить. Саму метрику расстояния тоже хорошо бы подбирать.
Теперь попробуем совместить две модели. В начале одной уберем аномалии из обучающей выборки. А потом на более «чистой» обучающей выборке обучим OCSVM. По предыдущем результатам наибольшую полноту мы наблюдали у EE. Очищаем обучающую выборку через EE, тренируем OCSVM на ней и получаем F1 = 0.50, Точность = 0.34, полнота = 0.95. Не впечатляет. Вот только мы же задались nu = 0.27. А данные у нас более или менее «чистые». Если предположить, что на обучающей выборке полнота у EE будет такой же, то ошибок останется 5%. Зададимся таким nu и получим F1 = 0.69, Точность = 0.59, полнота = 0.82. Отлично. Важно отметить, что в других методах такое совмещение не прокатит, поскольку они подразумевают, что в обучающей выборке и тестовой число аномалий одинаково. При обучении этих методов на чистом тренировочном дата-сете придется задавать contamination меньше, чем в реальных данных, и не близкий к нулю, но лучше его подбирать на кросс-валидации.
Интересно посмотреть на результат поиска на последовательности показаний:
На рисунке показан отрезок показаний первого и второго датчиков для 7 компонент. В легенде цвет соответствующих ошибок (начало и конец показаны вертикальными линиями одного цвета). Точками обозначены предсказания: зеленым — верные предсказания, красным — ложноположительные, фиолетовым — ложноотрицательные. Из рисунка видно, что визуально определить время ошибок сложно, а алгоритм справляется с этой задачей достаточно хорошо. Хотя важно понимать, что показания третьего датчика тут не приведены. Кроме того, есть ложноположительные показания после окончания ошибки. Т.е. алгоритм видит, что там тоже ошибочные значения, а мы разметили эту область как безошибочную. Справа на рисунке видна область перед ошибкой, которую мы разметили как ошибочную (за полчаса до ошибки), которая распознана как безошибочная, что приводит к ложноотрицательным ошибкам модели. В центре рисунка виден связный кусок, распознанный как ошибка. Вывод можно сделать следующий: при решении задачи поиска аномалий нужно плотно взаимодействовать с инженерами, понимающими суть работы систем, выход их строя которых нужно предсказывать, поскольку проверка используемых алгоритмов на разметке не до конца отражает реальность и не моделирует условий, в которых такие алгоритмы могли бы использоваться.
Код для отрисовки графика:
def plot_time_course(df_test,dfc,y_preds,start,end,vert_shift=4):
plt.figure(figsize=(15,10))
cols=df_train.filter(regex=('S[12]')).columns
add=0
preds_idx=y_preds.iloc[start:end][y_preds[0]==1].index
true_idx=df_test.iloc[start:end,:][df_test['Label']==1].index
tp_idx=set(true_idx.values).intersection(set(preds_idx.values))
fn_idx=set(true_idx.values).difference(set(preds_idx.values))
fp_idx=set(preds_idx.values).difference(set(true_idx.values))
xtime=df_test['Time'].iloc[start:end]
for col in cols:
plt.plot(xtime,df_test[col].iloc[start:end]+add)
plt.scatter(xtime.loc[tp_idx].values,df_test.loc[tp_idx,col]+add,color='green')
plt.scatter(xtime.loc[fn_idx].values,df_test.loc[fn_idx,col]+add,color='violet')
plt.scatter(xtime.loc[fp_idx].values,df_test.loc[fp_idx,col]+add,color='red')
add+=vert_shift
failures=dfc[(dfc['Start Time']>xtime.iloc[0])&(dfc['Start Time']<xtime.iloc[-1])]
unique_fails=np.sort(failures['Type'].unique())
colors=np.array([np.random.rand(3) for fail in unique_fails])
for fail_idx in failures.index:
c=colors[np.where(unique_fails==failures.loc[fail_idx,'Type'])[0]][0]
plt.axvline(failures.loc[fail_idx,'Start Time'],color=c)
plt.axvline(failures.loc[fail_idx,'End Time'],color=c)
leg=plt.legend(unique_fails)
for i in range(len(unique_fails)):
leg.legendHandles[i].set_color(colors[i])Если процент аномалий ниже 5% и/или они плохо отделяемы от «нормальных» показателей, вышеперечисленные методы работают плохо и стоит использовать алгоритмы на основе нейронных сетей. В самом простом случае это будут:
- автоэнкодеры (высокая ошибка обученного автоэнкодера будет сигнализировать об аномальности показания);
- рекуррентные сети (учится по последовательности предсказывать последнее показание. Если отличие большое — точка аномальная).
Отдельно стоит отметить специфику работы с временными рядами. Важно понимать, что большинство вышеперечисленных алгоритмов (кроме автоэнкодеров и изолирующего леса) скорее всего будут давать худшее качество при добавлении лаговых признаков (показаний за предыдущие моменты времени).
Попробуем добавить лаговые признаки в нашем примере. В описании соревнования говорится, что значения за 3 часа до ошибки уже с ошибкой никак не связаны. Тогда добавим признаки за 3 часа. Итого 259 признаков.
В итоге у OCSVM и IsolationForest результаты почти не изменились, а у Elliptic Envelope и LOF упали.
Для использования информации о динамике системы, следует использовать автоэнкодеры с рекуррентными или со сверточными нейронными сетями. Или же, например, сочетание автоэкодеров, сжимающих информацию, и обычных подходов поиска аномалий на основе сжатой информации. Перспективным представляется и обратный подход. Первичный отсев наиболее нехарактерных точек стандартными алгоритмами, а затем обучение автоэнкодера уже на более чистых данных.
Существует набор методик для работы с одномерными временными рядами. Все они нацелены на предсказания будущих показаний, а аномалиями считаются точки, расходящиеся с предсказанием.
Модель Хольта-Уинтерса
Тройное экспоненциальное сглаживание, раскладывает ряд на 3 компоненты: уровень, тренд и сезонность. Соответственно, если ряд представим в таком виде, метод работает хорошо. Facebook Prophet действует по похожему принципу, но сами компоненты оценивает по-другому. Подробнее можно почитать, например, здесь.
S(ARIMA)
В этом методе предсказательная модель строится на авторегрессии и скользящем среднем. Если речь идет о расширении S(ARIMA), то позволяет и оценивать сезонность. Подробнее о подходе можно прочитать здесь, здесь и здесь.
Другие подходы в предиктивном обслуживании
Когда речь идет о временных рядах и присутствует информация о временах возникновения ошибок, можно применять методы обучения с учителем. Помимо необходимости размеченных данных в этом случае важно понимать, что предсказание ошибки будет зависеть от природы ошибки. Если ошибок много и разной природы, скорее всего нужно будет предсказывать каждую по отдельности, что потребует еще больше размеченных данных, но и перспективы будут привлекательнее.
Есть и альтернативные способы использования машинного обучения в предиктивном обслуживании. Например, предсказание выхода системы из строя в ближайшие N дней (задача классификации). Важно понимать, что такой подход требует, чтобы возникновению ошибки в работе системы предшествовал период деградации (необязательно постепенной). При этом наиболее удачным подходом представляется использование нейросетей со сверточными и/или рекуррентными слоями. Отдельно стоит отметить методы по аргументации временных рядов. Мне наиболее интересными и одновременно простыми представляются два подхода:
- выбирается непрерывная часть ряда (например, 70%, а остальное убирается) и растягивается до изначального размера
- выбирается непрерывная часть ряда (например, 20%) и растягивается или сжимается. После этого весь ряд соответственно сжимается или растягивается до изначального размера.
Ещё есть вариант с предсказанием оставшегося времени жизни системы (задача регрессии). Здесь можно выделить отдельный подход: предсказание не времени жизни, а параметров распределения Вейбулла.
Про само распределение можно почитать здесь, а здесь про использование его в связке с рекуррентными сетками. У этого распределения два параметра α и β. α говорит о том, когда произойдет событие, а β — о том, насколько алгоритм в этом уверен. Хотя применение такого подхода перспективно, возникают трудности при обучении нейронной сети в этом случае, поскольку алгоритму вначале легче быть неуверенным, чем предсказывать адекватное время жизни.
Отдельно стоит отметить регрессию Кокса. Она позволяет предсказывать отказоустойчивость системы для каждого момента времени после диагностики, представляя его в виде произведения двух функций. Одна функция представляет собой деградацию системы, не зависимую от ее параметров, т.е. общую для любых таким систем. А вторая — экспоненциальную зависимость от параметров конкретной системы. Так для человека есть общая функция, связанная со старением, более менее одинаковым для всех. Но ухудшение здоровья связано и с состоянием внутренних органов, которое у всех разное.
Надеюсь, теперь вы знаете о предиктивном обслуживании чуть больше. Уверен, у вас появятся вопросы, касательно методов машинного обучения, которые чаще всего используются для этой технологии. Я буду рад ответить на каждый из них в комментариях. Если вам интересно не просто спросить о написанном, а хочется заниматься чем-то подобным, наша команда в CleverDATA всегда рада талантливым и увлеченным профессионалам.
Есть ли вакансии? Конечно!
- Разработчик Java (Big Data)




