
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
 ODS'21.")
Мы привыкли, что Machine Learning предоставляет нам большое количество предиктивных методов, которые с каждым годом предсказывают события лучше и лучше. Деревья, леса, бустинги, нейронные сети, обучение с подкреплением и другие алгоритмы машинного обучения позволяют предвидеть будущее все более отчетливо. Казалось бы, что нужно еще? Просто улучшать методы и тогда мы рано или поздно будем жить в будущем так же спокойно, как и в настоящем. Однако не все так просто.
Когда мы рассматриваем бизнес задачи, мы часто сталкиваемся с двумя моментами. Во-первых, мы хотим понять что к чему относится и что с чем связано. Нам важна интерпретация. Чем сложнее модели мы используем, тем более нелинейные они. Тем больше они похожи на черную коробку, в которой очень сложно выявить связи, понятные человеческому разуму. Все же мы привыкли мыслить довольно линейно или близко к тому. Во-вторых, мы хотим понять - если мы подергаем вот эту "ручку", изменится ли результат в будущем и насколько? То есть, мы хотим увидеть причинно-следственную связь между нашим целевым событием и некоторым фактором. Как сказал Рубин - без манипуляции нет причинно следственной связи. Мы часто ошибочно принимаем обыкновенную корреляцию за эту связь. В этой серии статей мы сконцентрируемся на причинах и следствиях.
Но что не так с привычными нам методами ML? Мы строим модель, а значит, предсказывая значение целевого события мы можем менять значение одного из факторов - одной из фич и тогда мы получим соответствующее изменение таргета. Вот нам и предсказание. Все не так просто. По конструкции, большинство ML методов отлично выявляют корреляцию между признаком и таргетом, но ничего не говорят о том, произошло ли изменение целевого события именно из-за изменения значения фичи. То есть, ничего не говорят нам о том - что здесь было причиной, а что следствием.
Чтобы прояснить о чем я, давайте посмотрим на задачу с другой стороны - чуть более формальной. Часто можно встретить следующую запись для модели машинного обучения:

Здесь y - наше целевое событие, a(X) - некоторый ML алгоритм,  - неустранимая ошибка. На самом деле a(X) в уравнении выше мы не знаем и часть просто предполагаем, что он именно такой, исходя из известных нам свойств целевого события и признакового пространства.
- неустранимая ошибка. На самом деле a(X) в уравнении выше мы не знаем и часть просто предполагаем, что он именно такой, исходя из известных нам свойств целевого события и признакового пространства.
После "обучения" модели, мы получаем оценку алгоритма  , с помощью которого получаем предсказания:
, с помощью которого получаем предсказания:

При этом, существует некоторая ошибка нашей оценки  , которую мы можем найти. Наш алгоритм строится с целью минимизации различных функций потерь от предсказания и фактического значения целевой переменной.
, которую мы можем найти. Наш алгоритм строится с целью минимизации различных функций потерь от предсказания и фактического значения целевой переменной.
Вернемся к основному вопросу. Предположим, среди наших X присутствует некоторый признак, через который мы можем влиять на таргет, что мы очень хотим делать. Назовем его T. Оставшееся множество признаков обозначим

Для того, чтобы это вписать в нашу формулу, предлагаю записать множество признаков следующим образом:  . Тогда наше предсказание выглядит:
. Тогда наше предсказание выглядит:

Под "воздействием" мы понимаем следующее: действительно ли, меняя T в реальности, я изменю y? Обозначим

Записывая строго (и предпологая определенный вид распределения ошибки и данных), мы хотим, чтобы следующее утверждение было верно:

То есть, мы хотим, чтобы изменив T мы получили результат и были уверены в нем также, как если бы он был изменен естественным образом. Однако, оказывается, что модели машинного обучения часто так не работают. Они находят корреляции, но это не значит, что изменив наше воздействие мы изменим результат.
Иллюстрацию этого удобно привести с помощью графа причинно-следственных связей. Подробности этого мы оставим за пределами этой статьи, но то, что я покажу будет понятно на интуитивном уровне. Предположим, наши данные описываются следующим образом:

Здесь стандартно: Y - таргет, X - признаки объекта, T - наше воздействие. За C мы принимаем здесь так называемый Confounder - переменную, воздействующую на T и на Y. Если переменная C является не наблюдаемой для нас, то стандартная модель машинного обучения, глядя на корреляцию между изменениями T и Y сможет заметить эту связь. Однако, очевидно что изменяя T мы не изменим Y - для этого должна измениться C! Здесь мы увидели частный случай проблемы эндогенности - проблема упущенной переменной. Видно, что когда мы пытаемся не просто найти корреляции между переменными и прогнозировать изменения в таргете, исходя из наблюдений, а пытаемся влиять на таргет - все становится немного сложнее.
Давайте попробуем также посмотреть на проблемы причинно-следственной связи с точки зрения их отличий от проблем Machine Learning и Statistical Learning. Отличная иллюстрация приводится в книге Elements of Causal Inference: Foundations and Learning Algorithms (Peters et al., 2017):
 с учетом этих связей.")
Ещё одна иллюстрация, которая помогает понять эволюцию мысли от корреляции к причинно-следственной связи (из книги The Book of Why: The New Science of Cause and Effect (Judea Pearl, Dana Mackenzie)):

Но давайте вернемся к эндогенности. Следующий раздел для того, чтобы узнать или вспомнить что же это такое.
Эндогенность
Строго говоря, эндогенность - это корреляция объясняющей переменной (признака) с ошибкой. В математической записи это выглядит следующим образом:

Если говорить о предыдущем примере, то в нем как раз это и происходит, за счет того, что  . Давайте посмотрим - какие еще бывают варианты эндогенности.
. Давайте посмотрим - какие еще бывают варианты эндогенности.
Принято выделять следующие проблемы:
Проблема упущенной переменной (omitted variable)
Обратная причинно-следственная связь (reverse causality)
Ошибка в измерениях (measurement error)
Все эти типы эндогенности отличаются присутствием корреляции ошибки и одного из признаков.
Выглядит очень теоретически. К чему это приводит на практике? Сейчас приготовьтесь испытать дежавю (особенно, если вы смотрели телевизор в последние несколько лет):
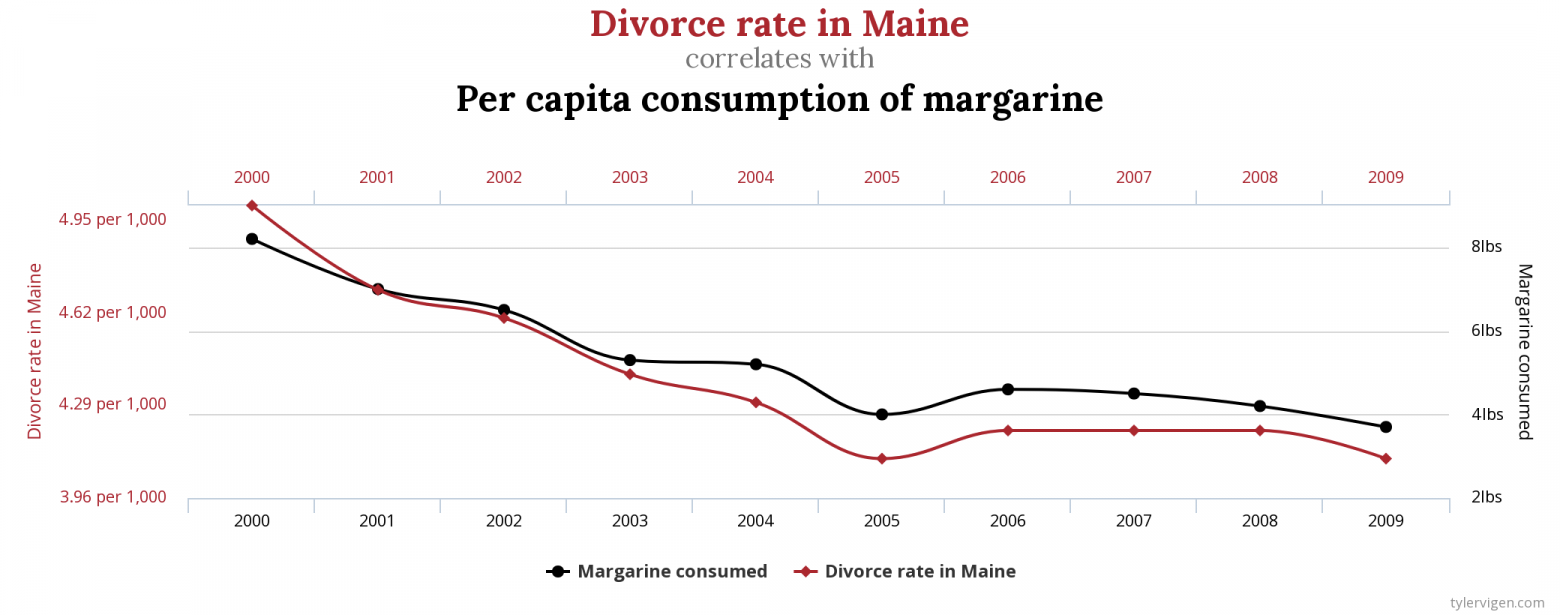

.")
Поставим себя на место парламентария - законотворца, который к нашему всеобщему сожалению не освоил отличие корреляций от причинно-следственных связей. Дабы укрепить семейные связи в первом случае наш герой может принять решение запретить маргарин к примеру. Это будет логично. Во втором случае, для спасения жизней своих сограждан он, пожалуй, предложит наложить эмбарго на продажу японских автомобилей, что вызовет политическую напряженность, но главное, что благое дело сделано. И, наконец, он избавит граждан США от заразы науки и технологий, тем самым пытаясь значительно снизить смертность. Что ж, может быть и не стоит изучать причинно-следственные связи, в конце концов срок депутата ограничен.
Задача
Что ж, надеюсь, что вы как минимум порадовались, посмотрев на красивые картинки, теперь перейдем к задаче, которую мы излагали в докладе. Перед нами стояла проблема улучшения системы ценообразования для товаров (мобильной техники и аксессуаров) с целью повышения прибыли бизнеса с партии этих товаров. Давайте разберем эту формулировку по словам, чтобы понять - что же от нас хотят. Начнем с конца:
Партия товаров
Я предлагаю рассматривать некоторый аксессуар. Например, некоторое универсальное зарядное устройство для смартфонов. Для простоты, пусть его технология не будет подвержена старению, хотя бы на горизонте года. Пусть его продажи несильно зависят от выхода новых моделей смартфонов. Партия (stock) это заранее известный объем закупки. Мы можем воспринимать её как набор зарядных устройств, который мы купили, скажем, в январе и следующая поставка будет через год.
Повышение прибыли
Прибыль давайте также понимать довольно просто. Это наша выручка (цена, умноженная на количество проданного товара) минус наши издержки (стоимость закупки). Цену хранения единицы товара будем считать пренебрежимо малой. В конце концов, для зарядных устройств это очень близко к правде. Записывая формально:

Здесь
 - прибыль,
- прибыль,  - розничная цена,
- розничная цена,  - количество проданного товара,
- количество проданного товара,  -оптовая цена закупки товара.
-оптовая цена закупки товара.
Улучшение системы ценообразования Из предыдущего упрощенного уравнения не понятно - причем здесь цена? Максимум для
 здесь достигается за счет увеличения цены до бесконечности. Но на то она и упрощенная. Давайте сделаем её чуть реалистичней:
здесь достигается за счет увеличения цены до бесконечности. Но на то она и упрощенная. Давайте сделаем её чуть реалистичней:
Здесь мы отразили немного больше зависимостей. Очевидно, объем проданного товара зависит от цены. При этом, чем выше цена, тем меньше объем продаж. При этом, закупка у нас фиксирована и мы имеем закупленную партию как факт, так что цена закупки - константа.
Казалось бы, давайте просто решим простейшую задачу оптимизации и выставим оптимальную цену. Но, все не так просто. Во-первых у нас целый год. Все, что не будет продано за год будет продаваться с большим дисконтом и приносить убыток, хранить это станет также дорого. Мы можем считать, что все, что не продано за год - выброшено.
Во-вторых, есть конкуренты и, повышая цену, мы теряем в продажах гораздо больше, чем было бы, будь мы монополистами. В-третьих, у нас может быть очень мало истории колебания цен, чтобы выявить зависимость q(p) при больших изменениях цены.

Начнем с казалось бы более простых задач и попробуем решить все проблемы, которые описали выше и некоторые другие.
Оптимальная цена
Начнем с выставления оптимальной в моменте цены. Как выставить эту цену?

На помощь здесь конечно придет простейшая теория оптимизации и основы микроэкономики. Решим задачу оптимизации, дабы найти оптимальную цену. Из FOC:

$$ $$
И что мы видим? Нам позарез нужно понять зависимость q(p) для решения уравнения. Для начала мы решили оценить её с помощью простой модели линейной регрессии:

Здесь X - набор признаков, и, соответственно, коэффициентов при нем тоже несколько, надеюсь, никого не запутает такая нотация.  предполагаем i.i.d (это очень сильное предположение, особенно учитывая автокорреляцию ошибок, если мы смотрим во времени, но, чтобы не размывать целей примера, здесь я не буду углубляться в решение этой задачи).
предполагаем i.i.d (это очень сильное предположение, особенно учитывая автокорреляцию ошибок, если мы смотрим во времени, но, чтобы не размывать целей примера, здесь я не буду углубляться в решение этой задачи).
В результате решения этой задачи мы можем получить некую оценку  , которая показывает нам каким образом количество продаж товара зависит от цены. Звучит это просто, но на деле конечно нас ждут не дождутся проблемы:
, которая показывает нам каким образом количество продаж товара зависит от цены. Звучит это просто, но на деле конечно нас ждут не дождутся проблемы:
На каждый товар не так много наблюдений, потому есть большой риск не увидеть статистической значимости в нашем коэффициенте
Есть товары, цена которых исторически не менялась, а значит наша модель не сработает для них в целом (нарушены базовые предположения OLS)
Есть товары, для которых мы видим положительную оценку
 (как бы вы интерпретировали её?)
(как бы вы интерпретировали её?)
Так как мы являемся последователями стоической философии, то мы представляли даже худшие варианты развития событий - такие как столкновение с метеоритом или чума, так что то, что мы увидели нас даже обрадовало. Какие идеи у нас возникли для решения этих задач?
Число наблюдений
Очевидным способом борьбы с этой бедой кажется объединение товаров в одну выборку. Но каким образом различать их? Предположим, что зависимости не универсальны и не отличаются от товара к товару. Первой попыткой может быть добавить dummy переменные (или fixed effects) на различные товары. Но тогда мы добавим огромное число переменных и выигрыш от объединения будет крайне невелик.
Есть другой вариант - в рамках одного класса товаров, давайте опишем их некоторыми признаками, присутствие которых обусловленно классом товара, а их значения могут отличаться от одного товара к другому. Например, если это зарядные устройства, то они могут различаться типом, производителем, мощностью. Таким образом мы, вводя некоторые вполне валидные предположения, выиграем от роста количества наблюдений.
Отсутствие изменения цены
Здесь мы можем пойти двумя путями. Первый уже произошел автоматически. В результате перехода от индивидуальных товаров к их группе, мы уже добавили вариацию в цену (предполагая единую зависимость от цены для всей группы). Второй путь - рандомизация. Для тех товаров, которые не имели исторических изменений в цене, мы можем волевым усилием устроить случайные изменения цены в разумных пределах.
Положительная корреляция цены и продаж
Эта проблема интересна, особенно в контексте нашей прошлой дискуссии о причинно-следственной связи и проблеме эндогенности. Давайте подумаем - может ли быть такое, что повышая цену мы начинаем продавать больше товара? Вполне возможно, но рост продаж вряд ли будет объясняться ростом цены, особенно в контексте наших товаров. Переводя на графический язык, положительный коэффициент говорит нам о следующей зависимости между ценой и продажами:
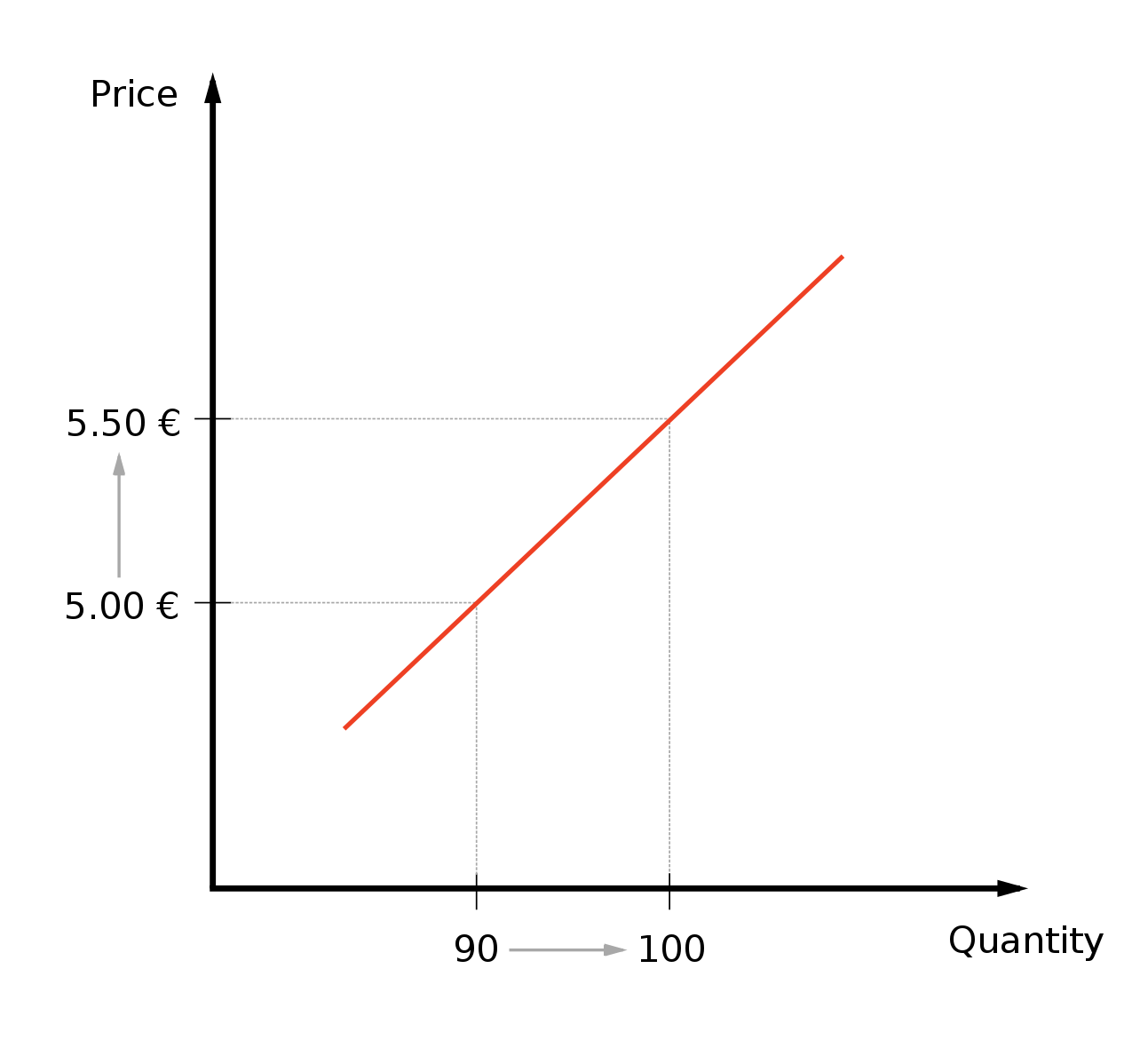
Думаю этот график довольно наглядно показывает, что как бы нам ни хотелось ничего не делать с этим коэффициентом - не выйдет. Маловероятно, что повышая цену мы добьемся этим увеличения продаж. В противном случае, нам стоило бы поставить цену на данное зарядное устройство равной бесконечности и перепрофилировать бизнес.
И снова эндогенность
Мы задумались. То ли половина наших товаров “неправильные”, то ли здесь где-то зарыта какая-то другая собака
Интересные статьи
Интересные статьи




