
Данная работа является пересказом статьи Jingzhou Liu, Wei-Cheng Chang, Yuexin Wu, and Yiming Yang. 2017. Deep Learning for Extreme Multi-label Text Classification. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR '17). Association for Computing Machinery, New York, NY, USA, 115–124. https://doi.org/10.1145/3077136.3080834
Одно из направлений работ в нашей лаборатории Unidata Labs – классификация записей материально-технических ресурсов (МТР) с применением машинного обучения. В этой статье мы бы хотели кратко разобрать нашу постановку задачи как таковую, и после чего предложить разбор одного из методов, которым эта задача могла бы решаться.
Вкратце, продукт Юнидата МТР работает с данными, относящимися к материально-техническим ресурсам клиентов, которые представлены в Юнидата как реестр — т.е., коллекция записей. Записи МТР, как правило, содержат очень большое количество полей, но нас интересует только одно — полное наименование. Оно может выглядеть примерно так:
Петля накладная правая арт.ПН1—130 130*73*2мм St анодирование (Беларусь) |
То есть, это строка, содержащая в себе название и некоторые характеристики ресурса. Данные записи чаще всего необходимо классифицировать узлами классификатора .
Классификатор в данном контексте представляет собой дерево классов сущностей. В России классификаторы определяются как "систематизированный перечень записей с указанием наименований и кодов объектов технико-экономической и социальной информации" и являются официальными документами.
Один из официально утвержденных классификаторов — это ОКПД 2, Общероссийский классификатор продукции по видам экономической деятельности. Запись, приведённая выше может быть классифицирована узлом 25.72.14.120 из него:

До недавнего времени процесс классификации в Юнидата МТР был полностью ручным: пользователь должен был искать в классификаторе подходящий узел с помощью поисковых запросов. Если учесть то, что реестры МТР, как правило, содержат очень большое количество записей — в нашем примере рассматриваются сотни тысяч — легко понять, что времени и ресурсов на такую классификацию требуется очень много. Таким образом, была поставлена задача реализовать некоторую вспомогательную функциональность для классификации на основе машинного обучения. В самом продукте это выглядит как рекомендация пользователю некоторых узлов во время ручной классификации.
Вообще, задача классификации текста в различных постановках является фундаментальной в NLP: для неё существует огромное количество методов, основанных как на классическом машинном обучении, так и на глубинном. Тем не менее, в нашем случае возникают сразу три сложности:
при необходимости, рекомендация должна состоять из нескольких узлов для одной записи — т.к., в Юнидата может быть использована множественная классификация.
исходные данные для обучения, классифицированные вручную, не могут быть сбалансированы по классам по очевидным причинам; тогда как отбрасывание меток, для которых есть всего несколько документов, сильно ухудшает качество модели в контексте задачи и ставит под вопрос её применение
сами классификаторы состоят из нескольких тысяч узлов.
Таким образом, большинство классических методов отпадают — заниматься их подстройкой под начальные условия задачи и “выжиманием” результатов не представляется возможным в индустриальном сеттинге. В дополнение к этому нужно учитывать вопросы производительности.
В процессе исследования мы обнаружили целую область под названием Extreme Multi-Label Classification (сокращается как XML — от eXtreme, без отношения к языку разметки). Multi-label ("многометочная") классификация — это выбор самого релевантного подмножества меток из их полного набора. Такая классификация наиболее релевантна для каталогов продуктов, статей из Википедии или поисковых систем. Extreme указывает на размер пространства меток — так, стандартный бенчмарк-датасет от Amazon содержит 670 тысяч классов. Ниже мы расскажем об особенностях данной постановки задачи, выделяющей эти модели в отдельный класс.
Мы решили пересказать содержание статьи, интересной тем, что это первое применение глубокого обучения (deep learning) для экстремальной классификации, опубликованное в 2017 году. Ниже мы расскажем, какие методы применялись до этого, и изложим результаты их сравнения с новым подходом.
С момента публикации этой статьи прошло довольно много времени и появилось много моделей, также использующих глубокое обучение с более впечатляющими результатами и более интересным внутренним устройством (например, DeepXML/Astec или ECLARE). Тем не менее, применение свёрточных сетей для нестандартной на тот момент для них задачи NLP, а также фокус на масштабируемости и производительности метода для описанных выше особенностей данных делают вклад оригинальным и заслуживающим внимания.
Введение
Статья Deep Learning for Extreme Multi-label Text Classification была предложена на конференции SIGIR’17 группой исследователей из университета Карнеги-Меллона.
Задача XML фундаментально отличается от двух традиционных постановок задачи классификации — бинарной и мульти-классовой (multi-class). В бинарной классификации (выбор из двух альтернатив) метки моделируются как независимые целевые переменные. В мульти-классовой полагаются на предположение о том, что все метки, которыми предлагается классифицировать, взаимоисключающи. Оба подхода как некорректны для задачи сами по себе, так и не представляют адекватной основы для адаптации под XML, т.к. они не моделируют корреляции между метками. На момент написания статьи область multi-label была сфокусирована на явном моделировании таких зависимостей, но все предложенные подходы не масштабируются на большие пространства меток, а также серьёзно страдают от разреженности данных.
Данные для XML чаще всего имеют степенное распределение: т.е. у большого количества классов есть всего несколько экземпляров, что заметно усложняет задачу выделения зависимостей между метками. Другая проблема заключается в том, что вычислительная стоимость обучения независимых классификаторов для каждого класса становится неподъёмной на сотнях тысяч и миллионах меток.
В рассматриваемой же задаче наблюдается существенный прогресс: на момент написания статьи образовались два стабильных класса её решений с подходами, показывающими удовлетворительные результаты.
Конкуренты
В статье предложен краткий обзор классов на тот момент самых современных моделей XML – tree-based ensemble methods и target-embedding methods. С представителями этих классов предложенная модель XML-CNN сравнивается как по результативности, так и по производительности.
Target-embedding методы направлены на снижение размерности пространства меток. Т.е., если рассмотреть обучающую выборку в виде пар векторов  , где
, где  — вектор признаков,
— вектор признаков,  — вектор меток и соответственно,
— вектор меток и соответственно,  и
и  — их количества, то эти методы заключаются в проекции (линейной или нелинейной) из пространства
— их количества, то эти методы заключаются в проекции (линейной или нелинейной) из пространства  в пространство
в пространство  меньшей размерности, предполагая, что матрица меток низкого ранга. После чего становится возможным применение стандартных методов классификации (таких как SVM или kNN). В основном, методы этой группы различаются способом “сжатия” и “расжатия” векторов. В разных работах применялись фильтры Блума, сингулярное разложение, и т.д.
меньшей размерности, предполагая, что матрица меток низкого ранга. После чего становится возможным применение стандартных методов классификации (таких как SVM или kNN). В основном, методы этой группы различаются способом “сжатия” и “расжатия” векторов. В разных работах применялись фильтры Блума, сингулярное разложение, и т.д.
Представителем этого класса выбрана модель SLEEC [2], которая строит  -размерные эмбеддинги
-размерные эмбеддинги  для исходных векторов меток
для исходных векторов меток  . Эти эмбеддинги построены таким образом, что они сохраняют попарные расстояния для близких по какой-либо метрике расстояния векторов, т.е.
. Эти эмбеддинги построены таким образом, что они сохраняют попарные расстояния для близких по какой-либо метрике расстояния векторов, т.е.  только если
только если  находится среди
находится среди  ближайших соседей
ближайших соседей  . Она выучивает набор матриц-регрессоров
. Она выучивает набор матриц-регрессоров  таких что
таких что  . После чего используется линейная регрессия для отображения документов в вектора меток в пространстве уменьшенной размерности.
. После чего используется линейная регрессия для отображения документов в вектора меток в пространстве уменьшенной размерности.
Tree-based ensemble ("наборы деревьев") методы же основаны на деревьях решений: они также рекурсивно разбивают пространство меток в каждом не-листовом узле, а в каждом их листе находится классификатор, который обучен на небольшом под-наборе меток. Их отличие заключается в том, что эти методы выучивают гиперплоскость (эквивалент взвешенной линейной комбинации всех признаков) вместо выбора одного признака. Ensemble здесь означает то, что используется лес, а не одно дерево. Представителем этого класса был выбран FastXML [3] как метод с наилучшими результатами.
В дополнение к описанным методам, авторы адаптируют несколько неспециализированных методов классификации под задачу XML. В их число входят две свёрточные нейронные сети, предназначенные для многоклассовой постановки задачи: Bow-CNN [4] и CNN-Kim [5]. На архитектуре CNN-Kim основан собственно предлагаемый метод, и в сущности он отличается только наличием дополнительного слоя и пулинг-слоем с другим способом. Тогда как Bow-CNN работает на bag-of-words векторах: текст разбивается на сегменты, и для каждого сегмента конструируется one-hot вектор размерности  , равный размеру всего словаря.
, равный размеру всего словаря.
Далее, авторы также рассматривают fastText [6] — минималистичный метод классификации текста, предложенный в 2014 году. Его авторы предлагают усреднять эмбеддинги слов документа для получения его репрезентации. Классификация производится с использованием линейного softmax классификатора.
Наконец, последний метод — это PD-Sparse [7]. Это max-margin классификатор (родственный SVM), который не попадает в описанные выше категории.
Метод
Как и все прочие CNN подходы, данная модель выучивает большое количество признаков пропуская документ через набор свёрточных фильтров (convolutional filters).
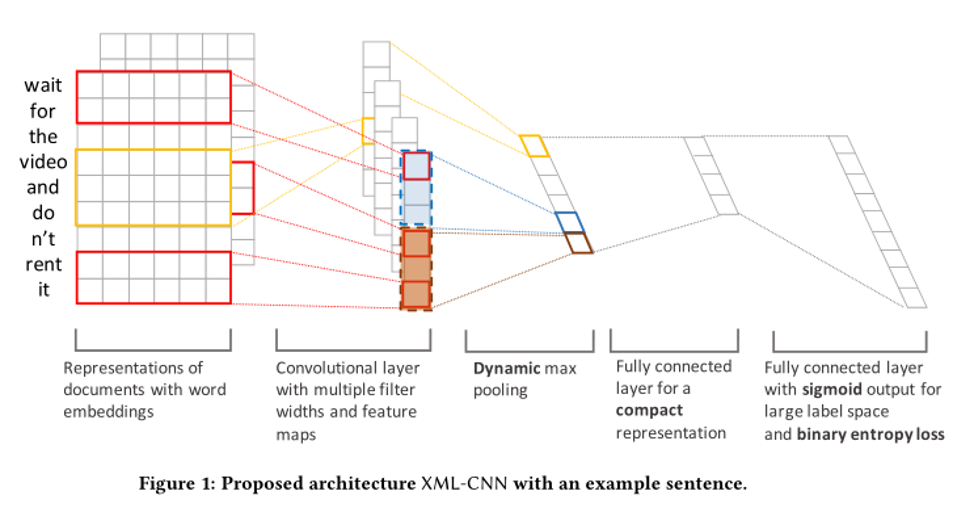
Архитектура алгоритма может быть описана следующим образом:
Входной слой получает репрезентации документов, составленные из предобученных 300-размерных эмбеддингов Glove
Свёрточный слой с несколькими фильтрами разных размеров
Динамический макс-пулинг слой для захвата/улавливания детальных признаков из различных регионов документа
Полносвязный слой-"узкое место" (bottleneck; его размерность ниже чем размерность пространства меток) для построения компактного представления документа. Это необходимо для уменьшения размера модели и увеличения производительности.
Полносвязный слой с сигмоидой как активацией и binary cross-entropy функцией потерь
На первом шаге происходит следующее. Пусть  это
это  -мерное представление
-мерное представление  -го (
-го ( ) слова в виде эмбеддингов. Соответственно, весь документ — это конкатенация эмбеддингов слов:
) слова в виде эмбеддингов. Соответственно, весь документ — это конкатенация эмбеддингов слов: ![e_{1:m} = [e_1, \ldots, e_m] \in \mathbb{R}^{km}](https://habrastorage.org/getpro/habr/upload_files/6e6/37f/013/6e637f0135bcb89c33a7c32f2a39f6fd.svg) . Сегмент от
. Сегмент от  -го до
-го до  -го слова обозначается
-го слова обозначается ![e_{i:j} = [e_i, \ldots, e_j] \in \mathbb{R}^{k * (j-i+1)}](https://habrastorage.org/getpro/habr/upload_files/198/b20/517/198b20517b67d31e1937cc446988ecfd.svg) .
.
Сверточный фильтр  применяется к сегменту из h слов
применяется к сегменту из h слов  для получения нового признака
для получения нового признака  :
:

Здесь  это нелинейная функция активации, такая как sigmoid или ReLU. (Для простоты записи авторы опускают смещение). Фильтр применяется к каждому возможному сегменту для того, чтобы получить набор
это нелинейная функция активации, такая как sigmoid или ReLU. (Для простоты записи авторы опускают смещение). Фильтр применяется к каждому возможному сегменту для того, чтобы получить набор  -ых. Этот набор — карта признаков
-ых. Этот набор — карта признаков ![c = [c_1, \ldots, c_m] \in \mathbb{R}^m](https://habrastorage.org/getpro/habr/upload_files/2d5/25d/279/2d525d2792884c68419a52aa76de120d.svg) , произведённая фильтром v. Документ дополняется (padded) так, чтобы получалось m признаков, если он слишком короткий.
, произведённая фильтром v. Документ дополняется (padded) так, чтобы получалось m признаков, если он слишком короткий.
Несколько сверточных фильтров с различными размерами окон используются внутри сверточного слоя чтобы “выхватить” семантическую информацию из текста. Предположим, что используется  сверточных фильтров, и, соответственно, получено
сверточных фильтров, и, соответственно, получено  карт признаков
карт признаков  . Затем операция пулинга
. Затем операция пулинга  применяется к каждой карте и в результате получается
применяется к каждой карте и в результате получается 
 -мерных векторов вида
-мерных векторов вида  . Выбор
. Выбор  будет обсуждаться в следующем разделе.
будет обсуждаться в следующем разделе.
Результаты слоя подвыборки подаются на вход полносвязному bottleneck-слою с  юнитами. В свою очередь, его результаты подаются в выходной слой с
юнитами. В свою очередь, его результаты подаются в выходной слой с  юнитами, где каждое число на выходе соответствует предсказываемой метке (
юнитами, где каждое число на выходе соответствует предсказываемой метке ( ). Формально это выглядит так:
). Формально это выглядит так:
![f = W_o g_h(W_h[P(c^{(1)}), \ldots, P(c^{(t)})])](https://habrastorage.org/getpro/habr/upload_files/47d/fd6/c39/47dfd6c394f57d6a83e9888da1c15c87.svg) ,
,
где  ,
,  это матрицы весов bottleneck и выходного слоя соответственно, а
это матрицы весов bottleneck и выходного слоя соответственно, а  – это функция активации bottleneck слоя.
– это функция активации bottleneck слоя.
Авторы утверждают что три вышеуказанных компонента – операция пулинга, функция потери и bottleneck-слой (поставленный между слоем пулинга и выходным) позволяют их модели показывать хорошие результаты на задаче XML. Мы разберём устройство каждого из этих компонентов, и кратко опишем проведённый ablation study, которое показывает уместность всех трех.
Dynamic max pooling
Прошлые модели для классификации текстов использовали max-over-time пулинг. Его идея заключается в том, что мы просто берем максимум из feature map:  . Мотивация следующая мы пытаемся “захватить” самый важный признак в каждой feature map. При использовании max-over-time пулинга каждый фильтр генерирует один признак, то есть выдача слоя пулинга будет описываться как
. Мотивация следующая мы пытаемся “захватить” самый важный признак в каждой feature map. При использовании max-over-time пулинга каждый фильтр генерирует один признак, то есть выдача слоя пулинга будет описываться как ![[P(c^{(1)}, \ldots, c^{(t)})] = [\hat{c}^{(1)}, \ldots, \hat{c}^{(t)}] \in \mathbb{R}^t](https://habrastorage.org/getpro/habr/upload_files/1c6/875/47d/1c687547dfe5807baac0a897469e6624.svg) .
.
Авторы считают что недостатком max-over-time пулинга является то, что для каждого фильтра только одно значение признака (и, соответственно, информация связанная с ним) переходит на последующие уровни. Это может негативно сказаться в случае длинных документов и кроме того, этот вариант пулинга не "захватывает" информацию о позиции этого признака.
Поэтому авторы решили использовать dynamic max pooling подход, в котором каждым фильтром генерируются  признаков. То есть, для документа с
признаков. То есть, для документа с  словами авторы поровну делят его карту признаков на
словами авторы поровну делят его карту признаков на  фрагментов, а каждый фрагмент пулится в один признак (также беря максимальное значение во фрагменте). Таким образом, информация про различные части документа может дойти до верхних слоев сети. Формально, с помощью этой схемы пулинга каждый фильтр производит
фрагментов, а каждый фрагмент пулится в один признак (также беря максимальное значение во фрагменте). Таким образом, информация про различные части документа может дойти до верхних слоев сети. Формально, с помощью этой схемы пулинга каждый фильтр производит  -мерный признак (считаем что
-мерный признак (считаем что  делится на
делится на  без остатка):
без остатка):
![P(c) = [max(c_{1:\frac{1}{p}}), \ldots, max(c_{m-\frac{m}{p}+1:m}) ] \in \mathbb{R}^{p}](https://habrastorage.org/getpro/habr/upload_files/ef3/9b1/401/ef39b140163ba82683121adcd5b76e2d.svg)
Функция потерь
Самый очевидный способ адаптировать методы для multi-class к multi-label - это расширить стандартную cross-entropy функцию потерь, сделав её "многомерной":

Здесь  обозначает параметры модели,
обозначает параметры модели,  является множеством релевантных меток для
является множеством релевантных меток для  -го классифицируемого объекта а
-го классифицируемого объекта а  – предсказание модели на
– предсказание модели на  -м объекте для метки
-м объекте для метки  полученное посредством softmax:
полученное посредством softmax:

Другим вариантом могла бы быть ranking loss, которая минимизирует количество неправильно упорядоченных пар меток в выдаче модели, но, как было показано другими исследователями, она проигрывает binary cross-entropy loss при использовании с сигмоидой на multi-label датасетах. Поэтому авторы решили остановиться на BCE:
![\min_{\Theta} -\frac{1}{n} \sum_{i=1}^n \sum_{j=1}^L [y_{ij} \log (\sigma({f}_{ij})) + (1 - {y}_{ij})log(1-\sigma({f}_{ij}))]](https://habrastorage.org/getpro/habr/upload_files/883/c00/46f/883c0046fa483afe899d651b7b117eee.svg)
где  - это сигмоида.
- это сигмоида.
Эксперименты
Датасеты

В данной таблице представлены статистики открытых бенчмарк-датасетов, используемых в экспериментах. RCV1 — это Reuters Corpus Volume I, EUR-Lex — набор классифицированных legal документов Евросоюза, Wiki - набор статей из англоязычной википедии с категориями, и Amazon — наименования товаров Amazon с категориями.
Подпись:  — мощность обучающего множества,
— мощность обучающего множества,  — тестового множества,
— тестового множества,  — количество признаков,
— количество признаков,  - количество уникальных меток,
- количество уникальных меток,  — среднее количество меток на документ,
— среднее количество меток на документ,  — среднее количество документов на метку,
— среднее количество документов на метку,  — среднее количество слов на документ и
— среднее количество слов на документ и  — среднее количество слов на документ в тестовом множестве.
— среднее количество слов на документ в тестовом множестве.
Метрики
Авторы используют две указанные ниже метрики качества ранжирования в оценке представленных алгоритмов. Они являются стандартным выбором для задачи XML, т.к. сама постановка отсылает к ранжированию – для каждого документа требуется выбрать из огромного пространства меток лишь небольшой набор подходящих и ранжировать их. Качество этого списка оценивается по релевантности его верхних позиций.
В следующих формулах  — это one-hot вектор меток документа, а
— это one-hot вектор меток документа, а  — это вектор оценок релевантности меток этого же документа, предсказанный моделью.
— это вектор оценок релевантности меток этого же документа, предсказанный моделью.
 - это количество релевантных меток в векторе
- это количество релевантных меток в векторе  . Наконец,
. Наконец,  — это множество ранговых индексов действительно релевантных меток среди верхних k предсказаний.
— это множество ранговых индексов действительно релевантных меток среди верхних k предсказаний.
 (точность на
(точность на  элементах — доля релевантных среди
элементах — доля релевантных среди  ранжированных элементов, предсказанных моделью), вычисляемая как:
ранжированных элементов, предсказанных моделью), вычисляемая как:

Normalized Discounted Cumulative Gain:

, где

при  = 1, 3, 5.
= 1, 3, 5.
 и
и  вычисляются для каждого документа в отдельности, а потом усредняются по набору.
вычисляются для каждого документа в отдельности, а потом усредняются по набору.
Полные результаты экспериментов представлены в таблицах ниже. Жирным шрифтом выделен лучший метод.


XML-CNN показал наилучший результат по  в 11 из 18 случаев, SLEEC в 4, Bow-CNN в 2 и FastXML в 1. Похожая ситуация наблюдается и по
в 11 из 18 случаев, SLEEC в 4, Bow-CNN в 2 и FastXML в 1. Похожая ситуация наблюдается и по  , где XML-CNN побеждает в 12 случаях. Стоит отметить, что в случаях, когда результат XML-CNN не лучший, он всегда занимает второе место.
, где XML-CNN побеждает в 12 случаях. Стоит отметить, что в случаях, когда результат XML-CNN не лучший, он всегда занимает второе место.
Интерпретация результатов и ablation study
XML-CNN показывает наилучшие результаты на датасетах с самым большим количеством документов на метку. Это соответствует интуиции относительно глубокого обучения: ему, как правило, требуется больше данных для успеха. Тем не менее, неспециализированные методы DL показывают результаты намного хуже.
Одно из интересных наблюдений — это тот факт, что FastText и CNN-Kim показали значительно более плохие результаты на самых больших пространствах меток. Авторы предполагают, что именно высокая разреженность таких данных "ломает" эти методы. А именно, они не моделируют зависимости между метками, и поэтому не могут показать адекватный результат.
Переходя к ablation study, нужно сказать, что XML-CNN сравнивался с CNN-Kim, т.к. он на нём и основан. На графике v1 обозначает новую функцию потерь, v2 — +дополнительные скрытые слои, v3 — +динамический макс-пулинг (т.е., полную версию XML-CNN).

Приведённый график убедительно показывает, что XML-CNN сильнее CNN-Kim для данной задачи, и каждый дополнительный элемент её архитектуры вносит свой вклад в результат.
Масштабируемость и эффективность

Технические подробности обучения изложены в самой статье. На графике представлены полученные результаты при тестировании всех методов на различных объёмах от пространства меток датасета Wiki-500K. Как видно из графика, 4 из предложенных методов смогли обучиться на полном датасете, а у остальных возникли проблемы с памятью. Методы, у которых проблем не возникло, тем не менее показывают результаты в целом намного хуже, чем результаты XML-CNN.
В статье также приведена подробная таблица со временем, затраченным на обучение и тестирование всех методов на всех упомянутых датасетах.
Заключение
В данной статье был приведён новый на тот момент подход для решения задачи multi-label классификации с использованием глубокого обучения и свёрточных нейронных сетей. Взяв за основу метод, использовавшийся для multi-class классификации, авторы предложили три дополнения, успешно адаптировавших метод к новой постановке — новая функция потерь, дополнительный слой-"узкое место", и динамический макс-пулинг.
За этим подходом вскоре последовали и другие, с которыми можно ознакомиться в репозитории. Данный алгоритм, например, реализован и может быть использован для извлечения признаков в алгоритме DeepXML [8].
1. Jingzhou Liu, Wei-Cheng Chang, Yuexin Wu, and Yiming Yang. 2017. Deep Learning for Extreme Multi-label Text Classification. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR '17). Association for Computing Machinery, New York, NY, USA, 115–124. DOI:https://doi.org/10.1145/3077136.3080834
2. Kush Bhatia, Himanshu Jain, Purushotam Kar, Manik Varma, and Prateek Jain. 2015. Sparse local embeddings for extreme multi-label classification. In Advances in Neural Information Processing Systems. 730–738.
3. Yashoteja Prabhu and Manik Varma. 2014. Fastxml: A fast, accurate and stable tree-classifer for extreme multi-label learning. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 263–272.
4. Rie Johnson and Tong Zhang. 2015. Effective use of word order for text categorization with convolutional neural networks. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 103–112.
5. Yoon Kim. 2014. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). 1746–1751.
6. Armand Joulin, Edouard Grave, Piotr Bojanowski, and Tomas Mikolov. 2016. Bag of tricks for efficient text classification. arXiv preprint arXiv:1607.01759 (2016).
7. Ian EH Yen, Xiangru Huang, Kai Zhong, Pradeep Ravikumar, and Inderjit S Dhillon. 2016. PD-Sparse: A Primal and Dual Sparse Approach to Extreme Multiclass and Multi Label Classification. (2016)
8. Dahiya, Kunal, et al. "Deepxml: A deep extreme multi-label learning framework applied to short text documents." In Proceedings of the 14th ACM International Conference on Web Search and Data Mining. 2021.
Подготовили: Анна Смирнова, Георгий Чернышев


