Всем привет! В этом посте я расскажу, какие подходы мы в Поиске Mail.ru используем для сравнения текстов. Для чего это нужно? Как только мы научимся хорошо сравнивать разные тексты друг с другом, поисковая система сможет лучше понимать запросы пользователя.
Что нам для этого нужно? Для начала строго поставить задачу. Нужно определить для себя, какие тексты мы считаем похожими, а какие не считаем и затем сформулировать стратегию автоматического определения схожести. В нашем случае будут сравниваться тексты пользовательских запросов с текстами документов.
Задача определения текстовой релевантности состоит из трёх этапов. Первый, самый простой: искать совпадающие слова в двух текстах и на основании результатов делать выводы о схожести. Следующая, более сложная задача, — поиск связи между разными словами, понимание синонимов. И наконец, третий этап: анализ предложения/текста целиком, вычленение смысла и сравнение предложений/текстов по смыслам.

Один из способов решения этой задачи заключается в нахождении некоторого отображения из пространства текстов в какое-то более простое. Например, можно перевести тексты в векторное пространство и сравнивать векторы.
Давайте вернемся к началу и рассмотрим самый простой подход: поиск совпадающих слов в запросах и документах. Такая задача сама по себе уже достаточно сложна: чтобы сделать это хорошо, нам нужно научиться получать нормальную форму слов, что само по себе нетривиально.
| Запрос |
Заголовок документа |
|---|---|
| Сказочный герой |
Азбука сказочных героев |
| Сказочный герой |
Литература для дошкольного возраста |
Модель прямого сопоставления можно сильно улучшать. Одно из решений — сопоставлять условные синонимы. Например, можно вводить вероятностные предположения на распределение слов в текстах. Можно работать с векторными представлениями и неявно вычленять связи между несовпадающими словами, причём делать это автоматически.
Так как мы занимаемся поиском, у нас есть много данных о поведении пользователей при получении тех или иных документов в ответ на какие-то запросы. На основе этих данных мы можем делать выводы про связь между разными словами.
Возьмём два предложения:

Присвоим каждой паре слов из запроса и из заголовка некоторый вес, который будет означать, насколько первое слово связано со вторым. Будем предсказывать клик как сигмоидальное преобразование от суммы этих весов. То есть поставим задачу логистической регрессии, в которой признаки представляются набором пар вида (слово из запроса, слово из заголовка/текста документа). Если мы сможем обучить такую модель, то поймём, какие слова являются синонимами, аккуратнее говоря, могут быть связаны, а какие скорее не могут.
Теперь нужно создать хороший датасет. Оказывается, достаточно взять историю кликов пользователей, добавить негативные примеры. Как подмешивать негативные примеры? Лучше всего добавлять их в датасет в пропорции 1:1. Причём сами примеры на первом этапе обучения можно делать случайно: к паре запрос-документ находим еще один случайный документ, и считаем такую пару негативом. На более поздних этапах обучения выгодно подавать более сложные примеры: у которых есть пересечения, а также случайные примеры, которые модель считает похожими (hard negative mining).
Пример: синонимы для слова «треугольник».
| Оригинальное слово |
Синоним |
Вес |
|---|---|---|
| ТРЕУГОЛЬНИК |
ГЕОМЕТРИЯ |
0,55878 |
| ТРЕУГОЛЬНИК |
РЕШИТЬ |
0,66079 |
| ТРЕУГОЛЬНИК |
РАВНОСТОРОННИЙ |
0,37966 |
| ТРЕУГОЛЬНИК |
ОГЭ |
0,51284 |
| ТРЕУГОЛЬНИК |
БЕРМУДСКИЙ |
0,52195 |
На данном этапе уже можно выделить неплохую функцию, сопоставляющую слова, но это еще не то, к чему мы стремимся.Такая функция позволяет делать непрямое сопоставление слов, а мы хотим сопоставлять целые предложения.
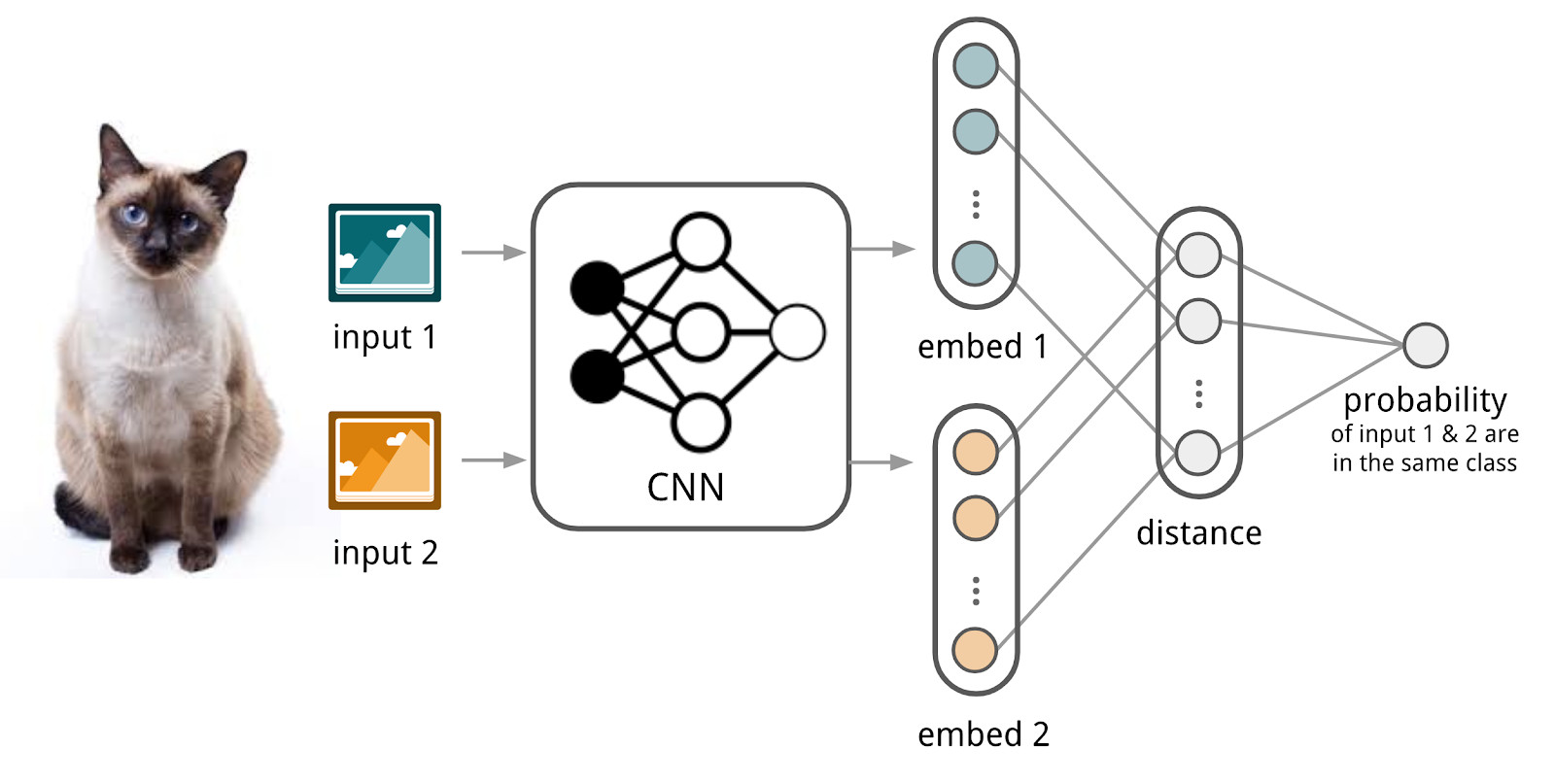
Здесь нам помогут нейронные сети. Давайте сделаем encoder, который принимает текст (запрос или документ) и выдаёт векторное представление, такое, что у похожих текстов векторы будут близкими, а у непохожих — далекими. Например, в качестве меры похожести можно использовать косинусное расстояние.
Здесь мы будем использовать аппарат сиамских сетей, потому что их куда проще обучать. Сиамская сеть состоит из encoder’а, который применяется к примерам данных из двух и более семейств и операции сравнения (например, косинусного расстояния). При применении encoder’а к элементам из разных семейств используются те же самые веса; это само по себе дает хорошую регуляризацию и сильно уменьшает количество коэффициентов, нужных для обучения.
Encoder производит из текстов векторные представления и обучается так, чтобы косинус между представлениями похожих текстов был максимален, а между представлениями непохожих — минимален.
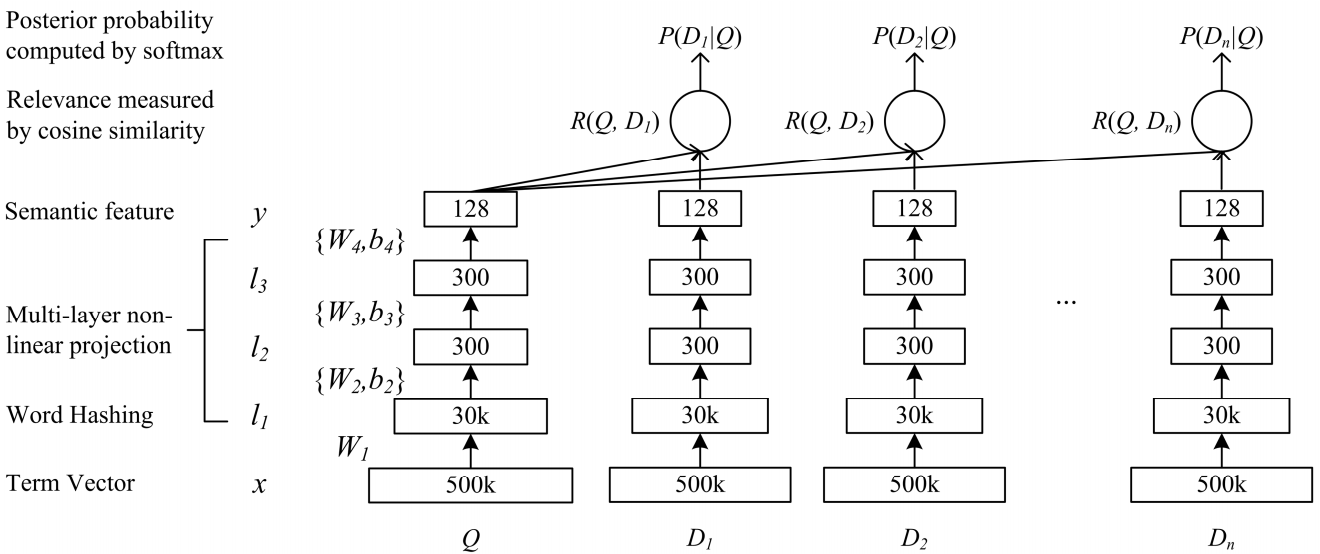
Для нашей задачи подходит сеть глубокой семантической сложности DSSM. Мы используем её с небольшими изменениями, о которых я скажу ниже.
Как устроена классическая DSSM: запросы и документы представляются в виде мешка триграмм, из которого получается стандартное векторное представление. Оно пропускается через несколько полносвязных слоёв, и сеть обучается так, чтобы максимизировать условную вероятность документа при условии запроса, что эквивалентно максимизации косинусного расстояния между векторными представлениями, полученными полным проходом по сети.
Po-Sen Huang Xiaodong He Jianfeng Gao Li Deng Alex Acero Larry Heck. 2013 Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
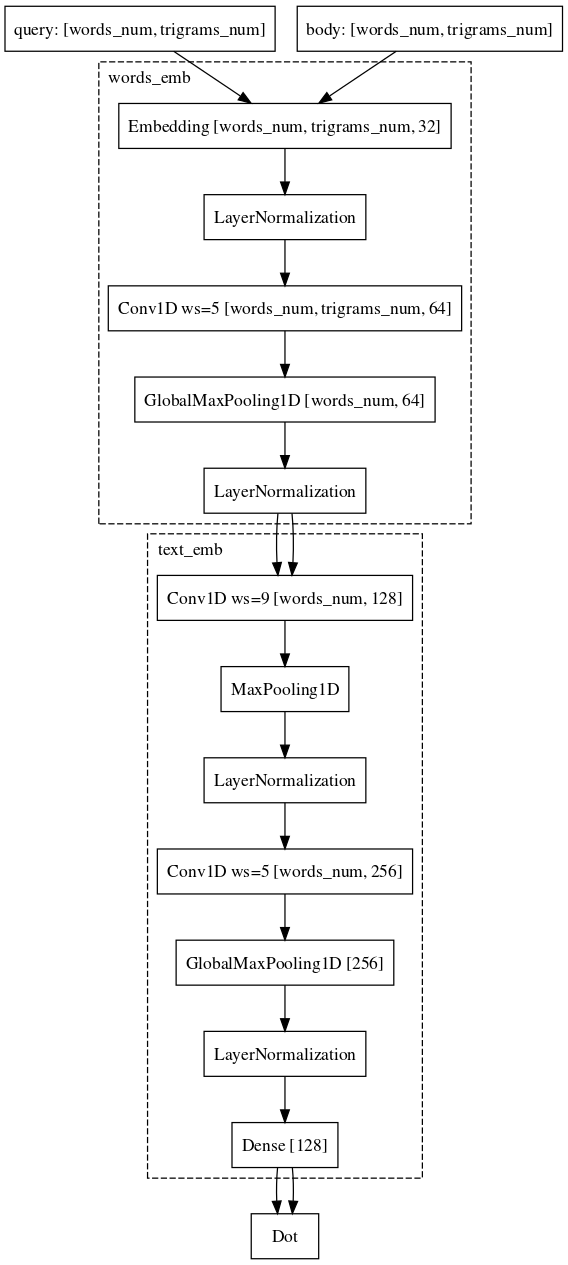
Мы пошли почти таким же путем. А именно, каждое слово в запросе представляем в виде вектора триграмм, а текст в виде вектора слов, таким образом оставляя информацию о том, какое слово где стояло. Дальше применяем одномерные свёртки внутри слов, сглаживая представление оных, и операцию глобального максимального пуллинга для агрегации информации о предложении в простом векторном представлении.

Датасет, который мы использовали для обучения, почти полностью совпадает по своей сути с тем, который используется для линейной модели.
На этом мы не остановились. Во-первых, придумали режим предобучения. Берём для документа список запросов, вводя которые пользователи взаимодействуют с этим документом, и предобучаем нейронную сеть делать эмбеддинги таких пары близкими. Так как эти пары из одного семейства, такая сеть обучается проще. Плюс её потом легче дообучать на боевых примерах, когда мы сравниваем запросы и документы.
Пример: на сайт e.mail.ru/login пользователи переходят с запросами: электронная почта, электронная почта вход, электронный адрес, …
| Запрос |
Документ |
ВМ25 |
Нейроранк |
|---|---|---|---|
| астана тойота |
Официальный сайт Toyota в Казахстане |
0 |
0,839 |
| поэзия |
Стихи.ру |
0 |
0,823 |
| ворлд дрим паттайя |
Бангкок Dream World |
0 |
0,818 |
| спб картошка |
Купить картофель в Санкт-Петербурге |
0 |
0,811 |
Наконец, последняя сложная часть, с которой мы до сих пор боремся и в которой почти достигли успеха, это задача сравнения запроса с каким-нибудь длинным документом. Почему эта задача сложнее? Здесь уже хуже подходит машинерия сиамских сетей, потому что запрос и длинный документ относятся к разным семействам объектов. Тем не менее, мы можем себе позволить почти не менять архитектуру. Нужно лишь добавить свертки еще и по словам, что позволит сохранить больше информации о контексте каждого слова для финального векторного представления текста.
В данный момент мы продолжаем улучшать качество наших моделей модифицируя архитектуры и экспериментируя с источникам данных и механизмами сэмплирования.
 с CRM Битрикс24")


