Нейросети — это та тема, которая вызывает огромный интерес и желание разобраться в ней. Но, к сожалению, поддаётся она далеко не каждому. Когда видишь тома непонятной литературы, теряешь желание изучить, но всё равно хочется быть в курсе происходящего.
В конечном итоге, как мне показалось, нет лучше способа разобраться, чем просто взять и создать свой маленький проект.
Можно прочитать лирическую предысторию, разворачивая текст, а можно это пропустить и перейти непосредственно к описанию нейросети.
Характеристики:
Основным преимуществом моей библиотеки является создание сети одной строчкой кода.
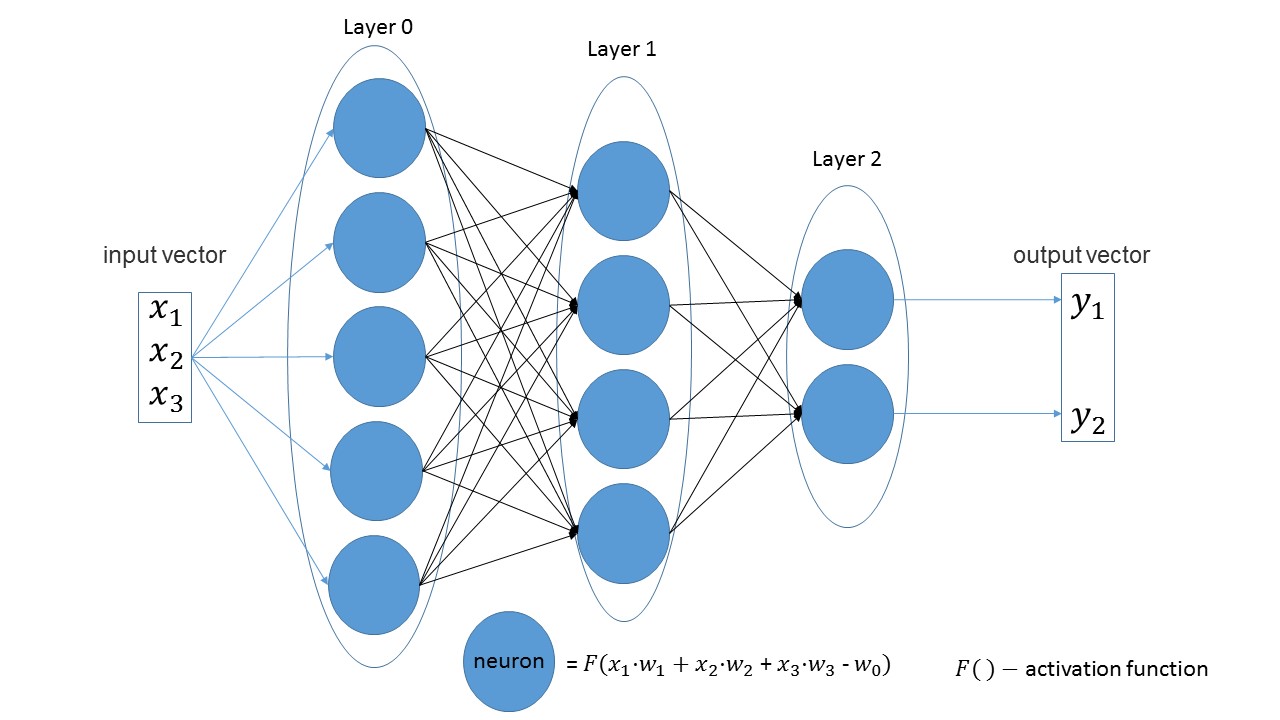
Легко заметить, что в линейных слоях количество нейронов в одном слое равняется количеству входных параметров в следующем слое. Ещё одно очевидное утверждение — число нейронов в последнем слое равняется количеству выходных значений сети.
Давайте создадим сеть, получающую на вход три параметра, имеющую три слоя с 5-ью, 4-мя и 2-мя нейронами.
Если взглянуть на рисунок, то можно как раз увидеть: сначала 3 входных параметра, затем слой с 5-ью нейронами, затем слой с 4-мя нейронами и, наконец, последний слой с 2-мя нейронами.
По умолчанию все функции активации являются сигмоидами (мне они больше нравятся).
При желании, на любом слое можно поменять на другую функцию.
Легко создать обучающую выборку. Первый вектор — входные данные, второй вектор — целевые данные.
Обучение сети:
Включение оптимизации:
И метод, чтобы просто получить значение сети:
Уже вошло в негласную традицию тестировать любую сеть на базе MNIST. И я не стал исключением. Весь код с комментариями можно посмотреть тут.
Что получилось:
Примерно за 10 минут (только CPU ускорение), можно получить точность 75%. С оптимизацией Адама за 5 минут можно получить точность 88% процентов. В конечном итоге мне удалось достичь точности в 97%.
Для маленькой завершённости проекта не хватало как раз этой статьи. Если хотя бы десять человек заинтересуются и поиграются, то уже будет победа. Добро пожаловать на мой GitHub.
P.S.: Если вам для того, чтобы разобраться, нужно создать что-то своё, не бойтесь и творите.
В конечном итоге, как мне показалось, нет лучше способа разобраться, чем просто взять и создать свой маленький проект.
Можно прочитать лирическую предысторию, разворачивая текст, а можно это пропустить и перейти непосредственно к описанию нейросети.
В чём смысл делать свой проект.
Плюсы:
Минусы:
- Лучше понимаешь, как устроены нейронки
- Лучше понимаешь, как работать с уже с существующими библиотеками
- Параллельно изучаешь что-то новое
- Щекочешь своё Эго, создавая что-то своё
Минусы:
- Создаёшь велосипед, притом скорее всего хуже существующих
- Всем плевать на твой проект
Выбор языка.
На момент выбора языка я более-менее знал С++, и был знаком с основами Python. Работать с нейронками проще на Python, но С++ знал лучше и нет проще распараллеливания вычислений, чем OpenMP. Поэтому я выбрал С++, а API под Python, чтобы не заморачиваться, будет создавать swig, который работает на Windows и Linux. (Пример, как сделать из кода С++ библиотеку для Python)
OpenMP и GPU ускорение.
На данный момент в Visual Studio установлена OpenMP версии 2.0., в которой есть только CPU ускорение. Однако начиная с версии 3.0 OpenMP поддерживает и GPU ускорение, при этом синтаксис директив не усложнился. Осталось лишь дождаться, когда OpenMP 3.0 будет поддерживаться всеми компиляторами. А пока, для простоты, только CPU.
Мои первые грабли.
В вычислении значения нейрона есть следующий момент: перед тем, как мы вычисляем функцию активации, нам надо сложить перемножение весов на входные данные. Как учат это делать в университете: прежде чем суммировать большой вектор маленьких чисел, его надо отсортировать по возрастанию. Так вот. В нейросетях кроме как замедление работы программы в N раз ничего это не даёт. Но понял я это лишь тогда, когда уже тестировал свою сеть на MNIST.
Выкладывание проекта на GitHub.
Я не первый, кто выкладывает своё творение на GitHub. Но в большинстве случаев, перейдя по ссылке, видишь лишь кучу кода с надписью в README.md «Это моя нейросеть, смотрите и изучайте». Чтобы быть лучше других хотя бы в этом, более-менее описал README.md и заполнил Wiki. Посыл же простой — заполняйте Wiki. Интересное наблюдение: если заголовок в Wiki на GitHub написан на русском языке, то якорь на этот заголовок не работает.
Лицензия.
Когда создаёшь свой маленький проект, лицензия — это опять же способ пощекотать своё Эго. Вот интересная статья на тему, для чего нужна лицензия. Я же остановил свой выбор на APACHE 2.0.
Описание сети.
Характеристики:
| Название | FoxNN (Fox-Neural-Network) |
| Операционная система | Windows, Linux |
| Языки | C++, Python |
| Ускорение | CPU (GPU в планах) |
| Внешние зависимости | Нет (чистый С++, STL, OpenMP) |
| Флаги компиляции | -std=c++14 -fopenmp |
| Слои | линейные (сверточные в планах) |
| Оптимизации | Адам, Нестеров |
| Случайное изменение весов | Есть |
| Википедия (инструкция) | Есть |
Основным преимуществом моей библиотеки является создание сети одной строчкой кода.
Легко заметить, что в линейных слоях количество нейронов в одном слое равняется количеству входных параметров в следующем слое. Ещё одно очевидное утверждение — число нейронов в последнем слое равняется количеству выходных значений сети.
Давайте создадим сеть, получающую на вход три параметра, имеющую три слоя с 5-ью, 4-мя и 2-мя нейронами.
import foxnn
nn = foxnn.neural_network([3, 5, 4, 2])
Если взглянуть на рисунок, то можно как раз увидеть: сначала 3 входных параметра, затем слой с 5-ью нейронами, затем слой с 4-мя нейронами и, наконец, последний слой с 2-мя нейронами.
По умолчанию все функции активации являются сигмоидами (мне они больше нравятся).
При желании, на любом слое можно поменять на другую функцию.
В наличии самые популярные функции активации.
- sigmoid — сигмоида
- sinusoid — синус
- gaussian — Гаус
- relu — линейный выпрямитель
- identity_x — тождественная
- tan_h — th
- arctan — арктангенс
- elu — экспоненциальная линейная функция
nn.get_layer(0).set_activation_function("gaussian")
Легко создать обучающую выборку. Первый вектор — входные данные, второй вектор — целевые данные.
data = foxnn.train_data()
data.add_data([1, 2, 3], [1, 0]) #на вход три параметра, на выход два параметра
Обучение сети:
nn.train(data_for_train=data, speed=0.01, max_iteration=100, size_train_batch=98)
Включение оптимизации:
nn.settings.set_mode("Adam")
И метод, чтобы просто получить значение сети:
nn.get_out([0, 1, 0.1])
Немного о названии метода.
Отдельно get переводится как получить, а out — выход. Хотел получить название "дай выходное значение", и получил это. Лишь позже заметил, что получилось выметайся. Но так забавнее, и решил оставить.
Тестирование
Уже вошло в негласную традицию тестировать любую сеть на базе MNIST. И я не стал исключением. Весь код с комментариями можно посмотреть тут.
Создаёт тренировочную выборку:
from mnist import MNIST
import foxnn
mndata = MNIST('C:download/')
mndata.gz = True
imagesTrain, labelsTrain = mndata.load_training()
def get_data(images, labels):
train_data = foxnn.train_data()
for im, lb in zip(images, labels):
data_y = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0] # len(data_y) == 10
data_y[lb] = 1
data_x = im
for j in range(len(data_x)):
# приводим пиксель в диапазон (-1, 1)
data_x[j] = ((float(data_x[j]) / 255.0) - 0.5) * 2.0
train_data.add_data(data_x, data_y) # добавляем в обучающую выборку
return train_data
train_data = get_data(imagesTrain, labelsTrain)
Создаём сеть: три слоя, на вход 784 параметра, и 10 на выход:
nn = foxnn.neural_network([784, 512, 512, 10])
nn.settings.n_threads = 7 # распараллеливаем процесс обучения на 7 процессов
nn.settings.set_mode("Adam") # используем оптимизацию Адама
Обучаем:
nn.train(data_for_train=train_data, speed=0.001, max_iteration=10000, size_train_batch=98)
Что получилось:
Примерно за 10 минут (только CPU ускорение), можно получить точность 75%. С оптимизацией Адама за 5 минут можно получить точность 88% процентов. В конечном итоге мне удалось достичь точности в 97%.
Основные недостатки (уже есть в планах на доработку):
- В Python ещё не протянуты ошибки, т.е. в python ошибка не будет перехвачена и программа просто завершится с ошибкой.
- Пока обучение указывается в итерациях, а не в эпохах, как это принято в других сетях.
- Нет GPU ускорения
- Пока нет других видов слоёв.
- Надо залить проект на PyPi.
Для маленькой завершённости проекта не хватало как раз этой статьи. Если хотя бы десять человек заинтересуются и поиграются, то уже будет победа. Добро пожаловать на мой GitHub.
P.S.: Если вам для того, чтобы разобраться, нужно создать что-то своё, не бойтесь и творите.
![«За и против»: апскейлинг исторических видеороликов — почему он нравится не всем [«1000 и 1» мнение по теме]](/upload/resize_cache/iblock/73e/105_70_0/73e31d43c4d3824eb858dcbed8462495.jpeg "«За и против»: апскейлинг исторических видеороликов — почему он нравится не всем [«1000 и 1» мнение по теме]")



