
Всем привет!
Меня зовут Денисов Александр. Я работаю в компании Naumen и отвечаю за документирование и локализацию программного продукта Naumen Contact Center (NCC).
В этой статье расскажу о тех проблемах, с которыми мы сталкивались при локализации NCC на английский и немецкий языки и о том, как мы решали эти проблемы. Конечно, на сегодняшний день мы решили далеко не все свои задачи и, скорее всего, этот процесс вообще бесконечен. В статье рассматривается видение всего процесса в целом и те принципы, которым мы стараемся придерживаться или которые начинаем пробовать применять. Материал будет полезен тем, кто только начинает проектировать ПО, планирует его локализацию или уже сталкивается с проблемами, но пока не знает как их решить.

Часто компания задумывается о локализации ПО тогда, когда продукт уже готов и для него написана документация. И так же часто бывает уже поздно что-либо сделать, чтобы в короткие сроки получить хорошую локализацию и не потратить на это огромное количество ресурсов.
Подробно написать обо всех проблемах и трудностях в одной статье невозможно, поэтому я расскажу немного об основных этапах документирования и локализации и затрону несколько, на мой взгляд, наиболее важных вопросов:
Исходя из своего многолетнего опыта работы над документированием и локализацией NCC попробую ответить на эти вопросы.
Naumen Contact Center — это сложное программное обеспечение для организации крупных корпоративных или аутсорсинговых контактных центров.
В чем сложность документирования и локализации этой системы:
Давайте посмотрим на жизненный цикл разработки ПО и выделим только те этапы, которые касаются документирования и локализации:
А теперь давайте представим, что в интерфейсе была допущена одна незначительная ошибка. Она автоматом распространяется на каждый этап, на несколько версий и языков.
Дополнительные ошибки могут появляться на каждом этапе, то есть в результате мы можем получить огромное число ошибок. Незначительные ошибки интерфейса скорее всего не будут исправлены никогда, всегда есть более важные задачи. А если их править, то стоимость этих правок будет очень высокой, так как придется снова пройтись по всей цепочке, всем версиям и языкам. И чем больше версий и языков, тем дороже.
В данном контексте нельзя говорить только о качестве локализации интерфейса или о качестве переведенной документации, так как результат работ каждого этапа является фундаментом для следующего этапа. Именно поэтому очень важно сразу все делать правильно на каждом этапе. И именно поэтому стоит рассматривать разработку ПО, документирование и локализацию как этапы единого неразрывного процесса.
Когда наши программисты взялись за локализацию системы, она была абсолютно к этому не готова. Текст интерфейса хранился в коде, а желание руководства было: «все сделать быстро». Программисты написали скрипт, который выдернул весь текст из кода и закинул в файлы ресурсов, а на следующий день отдали файлы ресурсов первому попавшемуся сотруднику со знанием английского языка, который все быстренько перевел в блокноте. Что из этого получилось, можно увидеть ниже.
На изображении приведена простая кнопка, она открывает какую-то форму с параметрами, где эти параметры можно изменить. Таких кнопок в системе десятки. На русском языке для такой кнопки обнаружилось 3 варианта, локализация на английский содержала уже 7 вариантов.
В этой ситуации сразу возникает большое желание навести порядок в строках интерфейса. Для этого предлагаю применять следующие правила:
К сожалению, применить подобные правила ко всем существующим 30 000 строкам сразу, очень трудоемко. Здесь мы находимся на начальном этапе и постепенно приводим в порядок наиболее часто повторяющиеся строки и разрабатываем правила для новых строк. Но согласитесь, было бы супер, если бы все правила были прописаны и выполнялись сразу!
Давайте взглянем на процесс документирования и локализации с привязкой ко времени. Если начать документирование и локализацию раньше, чем закончилась разработка фичи, то придется все переделать (возможно, несколько раз).
То же самое с переводом документации.
А если отдать пользователям документацию раньше, чем закончились все правки, можно рассчитывать на кучу замечаний. Скорее всего часть из этих замечаний и так будет поправлена на последних этапах разработки, но придется потратить лишнее время, чтобы их обработать.
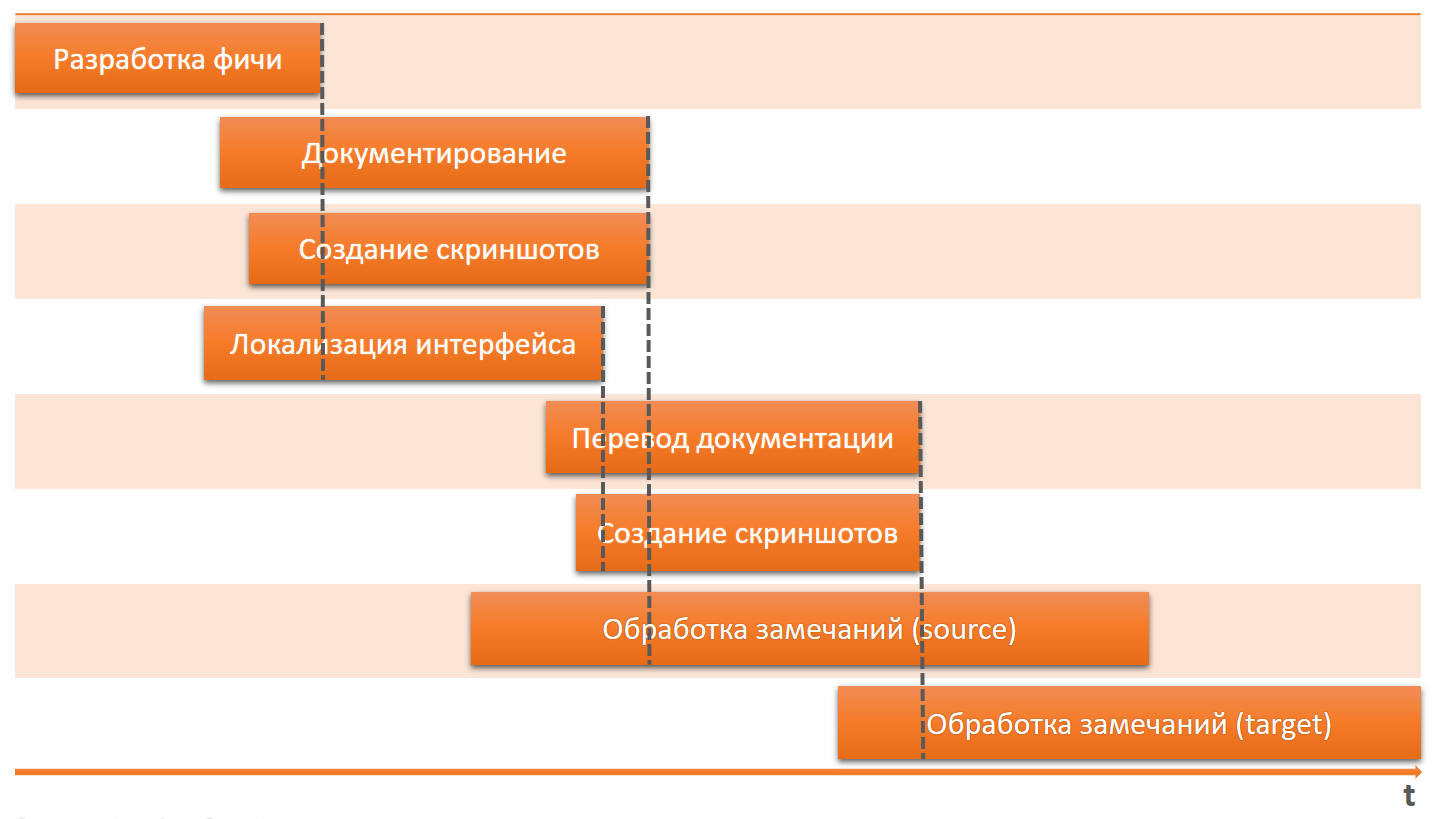
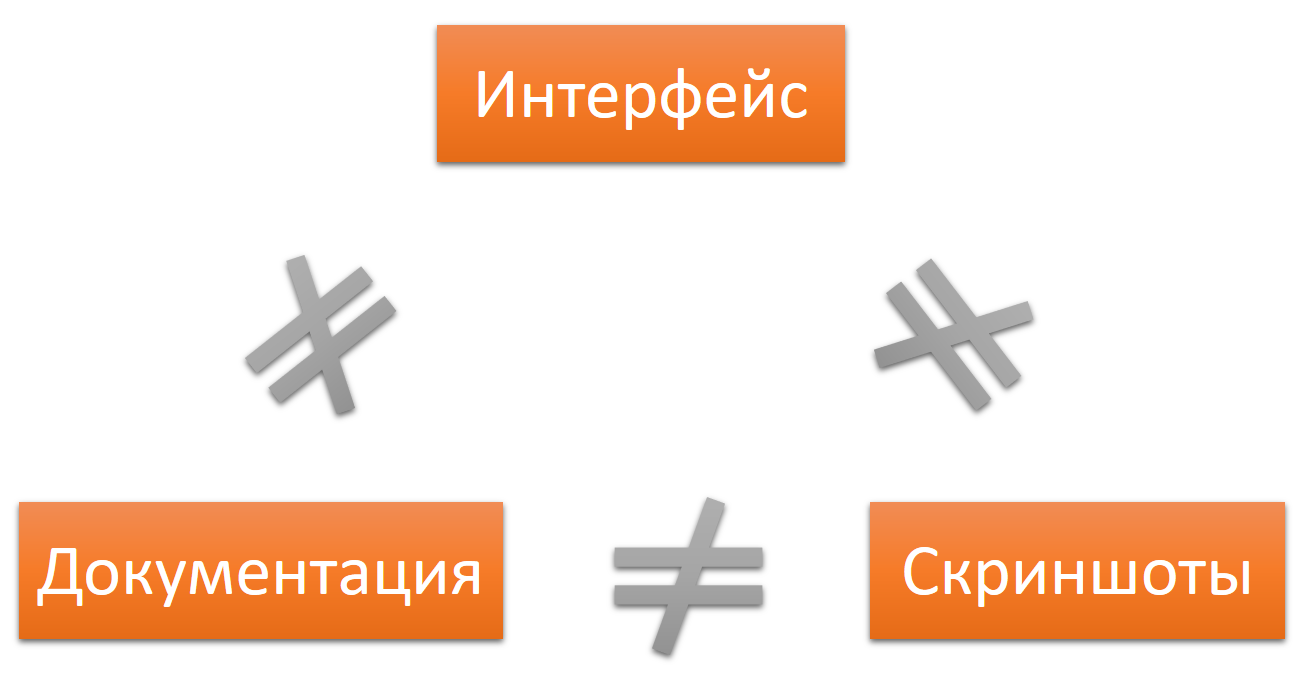
Если же процессы не согласованы, и мы вовремя не отслеживаем все изменения, то «ничего-ничему-нигде» не будет соответствовать.
Документация не будет соответствовать интерфейсу. Скриншоты не будут соответствовать интерфейсу и тексту документации.
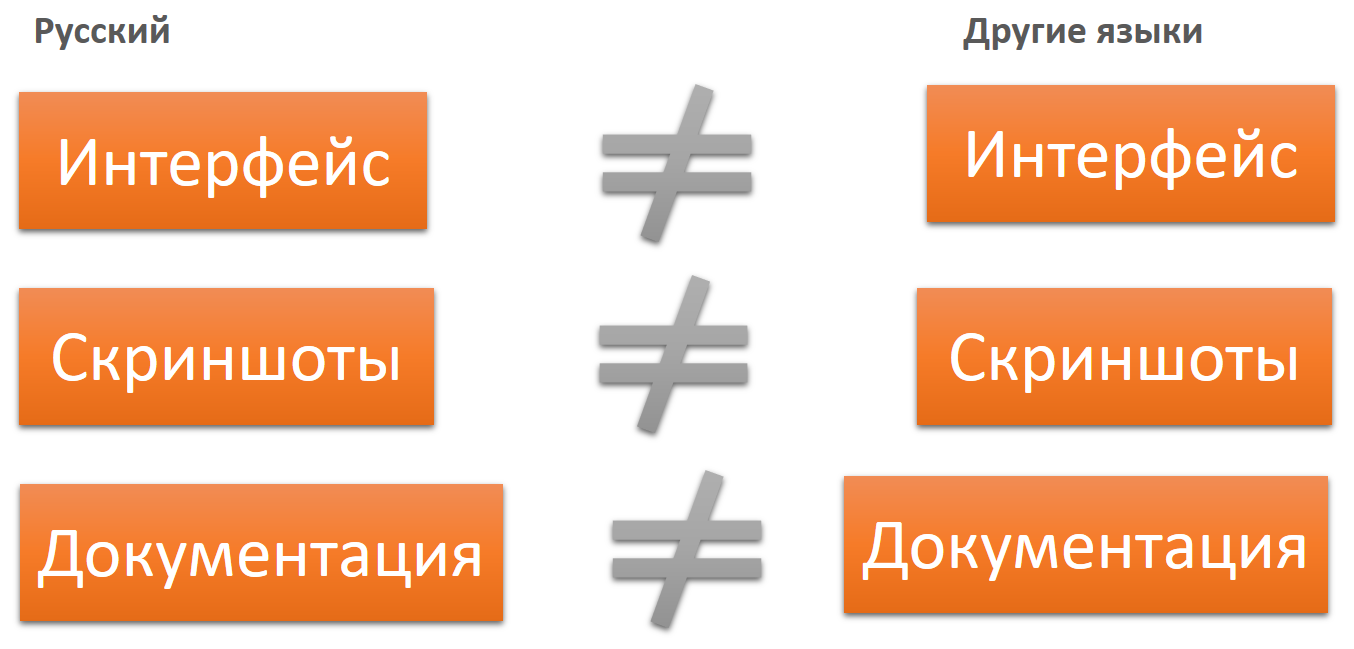
То же самое с локализацией. Текст интерфейса и документации на исходном языке не будет соответствовать тексту интерфейса и документации на других языках.
Мы решили, что на текущий момент можем себе позволить начинать каждый новый этап только после того, как закончили предыдущий.
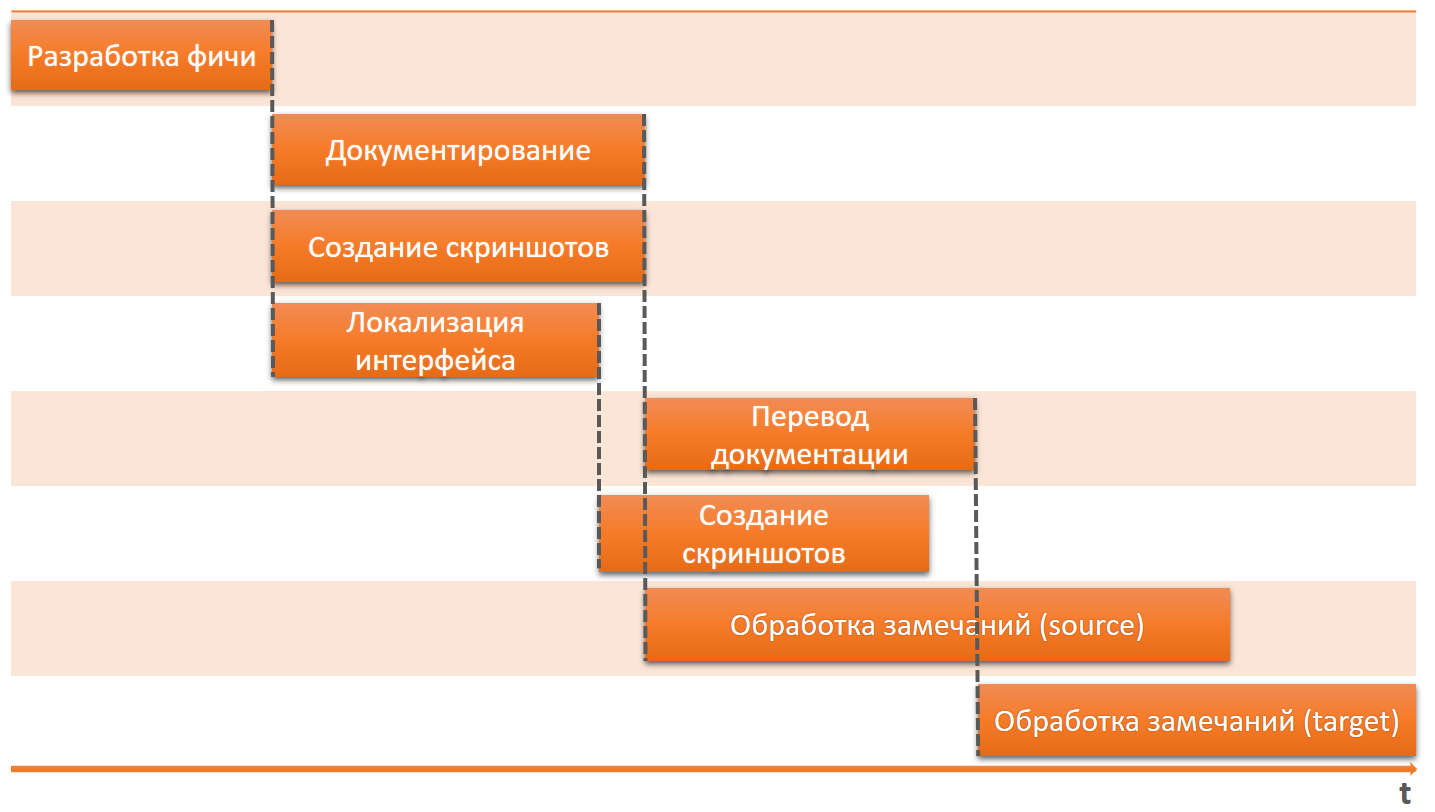
Да, документация и локализация у нас выходят с опозданием уже после релиза. И если говорить о локализации, мы уже обеспечили себе возможность непрерывной локализации, но мы этой возможностью не пользуемся и делаем всю локализацию одним этапом в конце релиза. Пара дней в рамках полугодового релиза — это совсем небольшой этап.
Пока наш продукт не массовый, у нас нет острой необходимости чтобы документация и локализация появлялись в один день. У нас длинные релизы, крупные корпоративные клиенты, которых не очень много по сравнению с небольшими и более массовыми продуктами, и устанавливать новую версию продукта или обновляться на нее они начинают далеко не сразу. Затраты на постоянное переделывание при этом заметно сокращаются.
На этапе документирования и локализации мы постоянно сталкивались с проблемами терминологии:
Процесс же разработки у нас какое-то время выглядел так:
А при попытках вклиниться в этот процесс с терминологией, мы получали такие отговорки:
Но «потом» выяснялось, что поправить мы можем далеко не все. Например, были ситуации, когда из-за неверно понятой терминологии объекты системы размещались не на тех уровнях иерархии или объединялись в неверные группы.
Сейчас мы проверяем термины и текст интерфейса параллельно тестированию постановки. То есть пока тестировщики пишут свои замечания, мы пишем свои.

Что мы делаем во время тестирования постановки:
При выявлении новых терминов мы добавляем их в глоссарий, при этом:
Можно сказать, что благодаря согласованию терминологии и текстов интерфейса на этапе согласования постановки, мы стали экономить кучу времени на многократных исправлениях на последующих этапах.
Принципы, которым мы придерживаемся при документировании:
Теперь расскажу про некоторые, особо важные моменты процесса документирования.
В большинстве систем работы с единым источником можно использовать переменные. Поэтому мы разработали сценарии, которые автоматически преобразуют файлы ресурсов интерфейса в файлы с переменными. В процессе разработки документации мы не набираем тексты элементов интерфейса, а вставляем в текст переменные. Таким образом в русскую версию автоматически подтягиваются русские строки, в английскую версию английские, в немецкую немецкие.

Какие это дает преимущества:
Еще в документации есть много повторяющихся предложений. Например, такое предложение, как — «Нажмите на кнопку Сохранить.». В системах работы с единым источником такое предложение можно поместить в сниппет. Сниппет — это такой небольшой файл, который можно вставлять на другие страницы документации.

Как вы можете заметить, текст кнопки Сохранить в сниппет также подставляется из переменной.
Это дает следующие преимущества:
В своей документации мы часто используем скриншоты и другие изображения, которые могут содержать текст.
Чтобы делать скриншоты на разных языках своими силами, под каждым скриншотом мы пишем текст, который на нем используется. Этот текст тегируется и не попадает в готовую документацию. Перед тем, как делать перевод документации, мы переводим тексты для скриншотов. А во время перевода документации делаем скриншоты силами технических писателей без знания языка.
С использованием скриншотов бывают и другие трудности. Например, как отследить все изменения, если в интерфейсе меняется одна строка текста, которая используется в 50 местах?
Как потом найти все скриншоты этих 50 мест, чтобы заменить их в документации?
Для решения этой проблемы мы используем инструмент QVisual, который разработали в компании Tinkoff. Процесс работы с ним выглядит так:
Таким образом мы сокращаем затраты на многочисленные проверки скриншотов вручную. Тем более, что вручную не всегда удается выявить все ошибки, что-то можно просто проглядеть.
Правда, не все окна можно открыть при помощи ссылок и это работает только для Web-интерфейса, но часть проблем с обновлением скриншотов это все равно снимает.
Перед локализацией интерфейса, если это еще не сделано, нужно перевести все термины глоссария.
Когда глоссарий переведен, можно начинать локализацию. В этом процессе мы придерживаемся следующих принципов:
Отмечу, что контекст может иметь больший приоритет для принятия решения о переводе, чем наличие такой же, уже переведенной строки в памяти переводов. Также на основе контекста могут применяться те или иные правила перевода, которые указаны в руководстве по стилю.
Может быть несколько способов предоставления контекста:
Принципы, которым мы стараемся придерживаться при переводе документации:
Скажу несколько слов об организационной структуре компании. У всех она разная, но представим такой случай, когда за каждый этап отвечает свой отдел.
Обратная связь от одного отдела к предыдущему в таком варианте будет затруднена, взаимодействие между сотрудниками разных отделов налаживается сложно. Решение всех вопросов через руководителя тоже «узкое горлышко». У каждого руководителя свое видение, цели и приоритеты. Много времени может тратиться на дополнительные согласования.
На мой взгляд за все тексты на всех языках должен отвечать один отдел.
При таком распределении ответственности, каждая версия продукта — это отдельный проект из нескольких этапов, и за качество выполнения этого проекта нужно отвечать в целом. Так проще наладить обратную связь, оперативно разобраться в любой проблеме, сделать ретроспективу и найти первопричину проблемы.
Приведу пример.
Благодаря тому, что наши технические писатели сами проверяют переводы с помощью QA, мы увидели десятки, а то и сотни ошибок неконсистентности.
Оказалось, что переводчик видит одинаковые по смыслу, но по разному написанные предложения и делает для них один и тот же перевод. Мы инициировали задачу и технический писатель заменил все разные варианты одного и того же по смыслу текста на один сниппет. Теперь таких повторяющихся ошибок больше не будет. Специалистам не придется тратить время на их анализ, а перевод на новые языки в будущем будет проще.
В общем случае, если у переводчика во время перевода возникают вопросы, то для нас это уже «звоночек» о том, что что-то не так на ранних этапах и надо делать задачу на исправление.
Перед тем как пытаться сделать идеальную документацию на всех языках, стоит задуматься, а какое качество нужно? Ответить на этот вопрос помогут дополнительные вопросы:
Если принято решение вычитывать документацию:
Web-документацию с уже описанными фичами мы делаем доступной для внутреннего использования еще до выхода релиза. Вычитку документации на русском языке делает весь департамент и в особенности аналитики, так как именно они ставят задачи на разработку и на этом этапе лучше всех понимают, что должно быть в документации.
Новые сотрудники также очень ценные пользователи документации. У новичков свежий взгляд, а еще цель разобраться с системой во время испытательного срока.
Переведенную документацию могут вычитывать и партнеры. Можно заключать с ними такие соглашения. Партнер присылает вам все замечания, а заодно сам разбирается в системе.
Что заставляет пользователей отправлять обратную связь:
Отмечу, что замечания мы исправляем только в текущей версии документации, то есть той, что еще находится в разработке. Считаем, что лучше уделять как можно больше внимания новым версиям и делать в ней как можно меньше ошибок, чем тратить кучу времени на поддержку старых версий.
Каждая компания находится на своем этапе развития, и часто не нужно вкладывать огромное число человеко-ресурсов, чтобы достичь приемлемого на сегодняшний день результата.
Сначала разберитесь, что именно необходимо на текущий момент и сделайте только это, а затраты увеличивайте по мере возрастания потребностей.
Это была достаточно общая статья о процессах документирования и локализации в целом. В будущем попробую написать о более узких темах.
Спасибо, если дочитали до конца! Желаю вам успехов в работе и отладке своих процессов документирования и локализации!
Буду рад ответить на вопросы, обсудить ваши мысли и идеи!
Меня зовут Денисов Александр. Я работаю в компании Naumen и отвечаю за документирование и локализацию программного продукта Naumen Contact Center (NCC).
В этой статье расскажу о тех проблемах, с которыми мы сталкивались при локализации NCC на английский и немецкий языки и о том, как мы решали эти проблемы. Конечно, на сегодняшний день мы решили далеко не все свои задачи и, скорее всего, этот процесс вообще бесконечен. В статье рассматривается видение всего процесса в целом и те принципы, которым мы стараемся придерживаться или которые начинаем пробовать применять. Материал будет полезен тем, кто только начинает проектировать ПО, планирует его локализацию или уже сталкивается с проблемами, но пока не знает как их решить.
Введение
Часто компания задумывается о локализации ПО тогда, когда продукт уже готов и для него написана документация. И так же часто бывает уже поздно что-либо сделать, чтобы в короткие сроки получить хорошую локализацию и не потратить на это огромное количество ресурсов.
Подробно написать обо всех проблемах и трудностях в одной статье невозможно, поэтому я расскажу немного об основных этапах документирования и локализации и затрону несколько, на мой взгляд, наиболее важных вопросов:
- Какие этапы жизненного цикла разработки программного обеспечения влияют на качество документирования и локализации?
- Что и когда нужно делать на каждом этапе?
- Какие подходы, возможности инструментов можно применять для решения задач и проблем каждого этапа?
- Как орг. структура влияет на процессы документирования и локализации?
- Как организовать получение обратной связи от пользователей документации?
- Как экономить временные и финансовые затраты на каждом этапе?
Исходя из своего многолетнего опыта работы над документированием и локализацией NCC попробую ответить на эти вопросы.
Особенности NCC и процесса разработки
Naumen Contact Center — это сложное программное обеспечение для организации крупных корпоративных или аутсорсинговых контактных центров.
В чем сложность документирования и локализации этой системы:
- Система не облачная.
- Сложная настройка, много интеграций с различными системами.
- Поддержка нескольких версий.
- Как следствие п. 1-3 мы имеем сложные внедрения и обновления. У каждого клиента своя версия, своя конфигурация и интеграции с различными системами.
- Система не массовая, ее использует только крупный бизнес. Поэтому число клиентов не очень большое по сравнению с небольшими массовыми продуктами.
- Большое число специфических терминов.
- Многоролевая модель. А это значит, что документация и интерфейс должны подстраиваться под особенности каждой роли (уровень знаний и особенности задач).
- Интерфейсы системы содержат около 30 000 строк текста и написано около 3000 страниц сложной технической документации.
- Релизы выходят 2-3 раза в год.
- После каждого релиза обновляется и дополняется примерно 10% текста интерфейса и документации.
- 3 языка: русский (исходный), английский и немецкий.
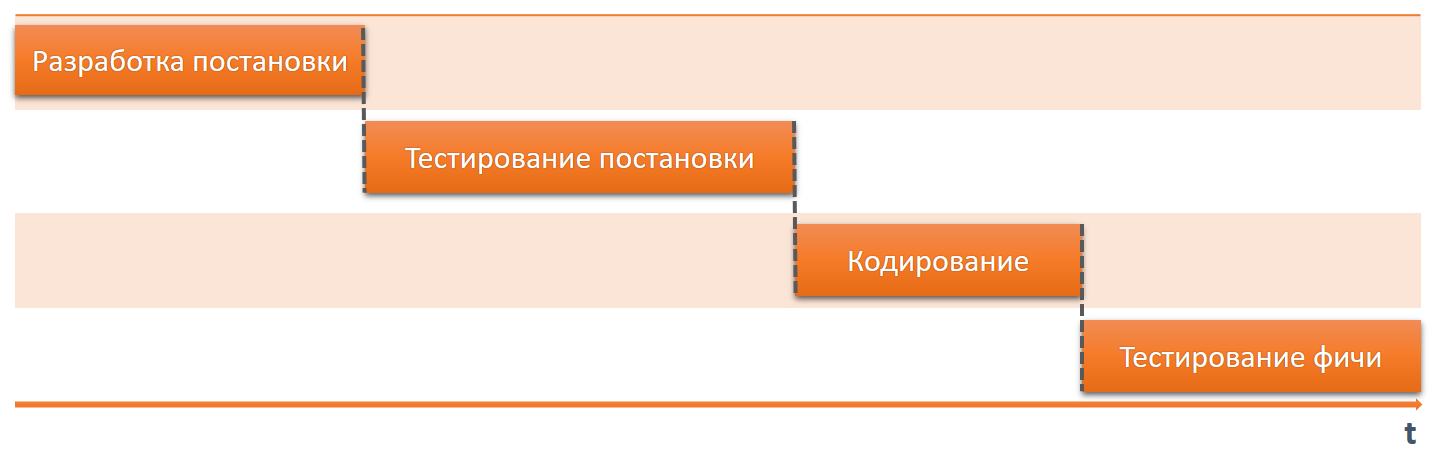
Жизненный цикл разработки
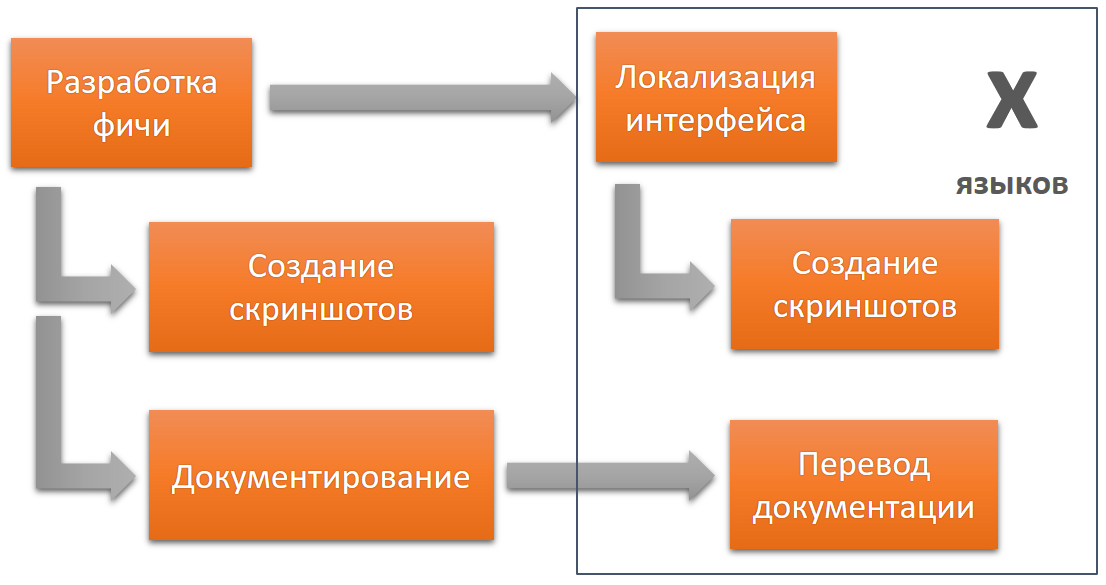
Давайте посмотрим на жизненный цикл разработки ПО и выделим только те этапы, которые касаются документирования и локализации:
- Разработка фичи. В рамках этого этапа разрабатываются тексты для интерфейса.
- Документирование. В рамках этого этапа разрабатывается документация, включая создание скриншотов и других изображений.
- Локализация интерфейса на несколько языков.
- Перевод документации на другие языки, включая локализацию скриншотов и других изображений.
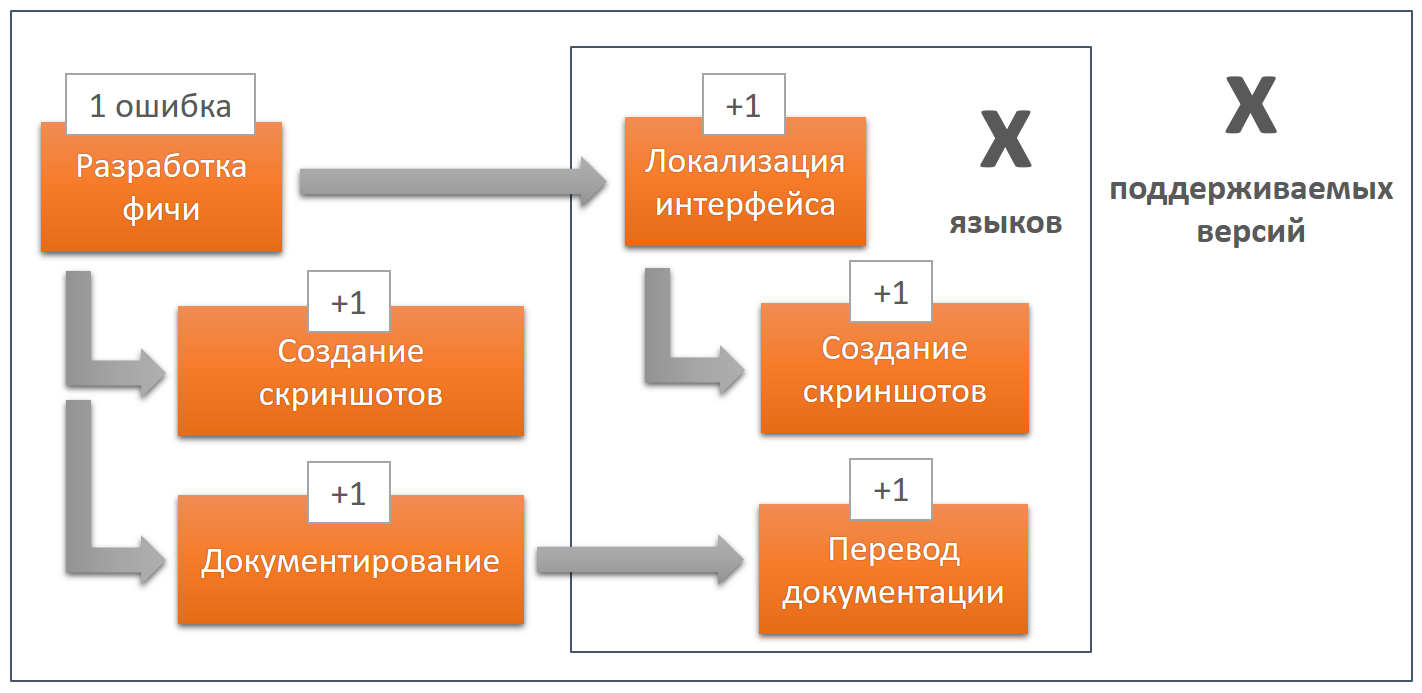
А теперь давайте представим, что в интерфейсе была допущена одна незначительная ошибка. Она автоматом распространяется на каждый этап, на несколько версий и языков.
Дополнительные ошибки могут появляться на каждом этапе, то есть в результате мы можем получить огромное число ошибок. Незначительные ошибки интерфейса скорее всего не будут исправлены никогда, всегда есть более важные задачи. А если их править, то стоимость этих правок будет очень высокой, так как придется снова пройтись по всей цепочке, всем версиям и языкам. И чем больше версий и языков, тем дороже.
В данном контексте нельзя говорить только о качестве локализации интерфейса или о качестве переведенной документации, так как результат работ каждого этапа является фундаментом для следующего этапа. Именно поэтому очень важно сразу все делать правильно на каждом этапе. И именно поэтому стоит рассматривать разработку ПО, документирование и локализацию как этапы единого неразрывного процесса.
Организация текста в интерфейсе
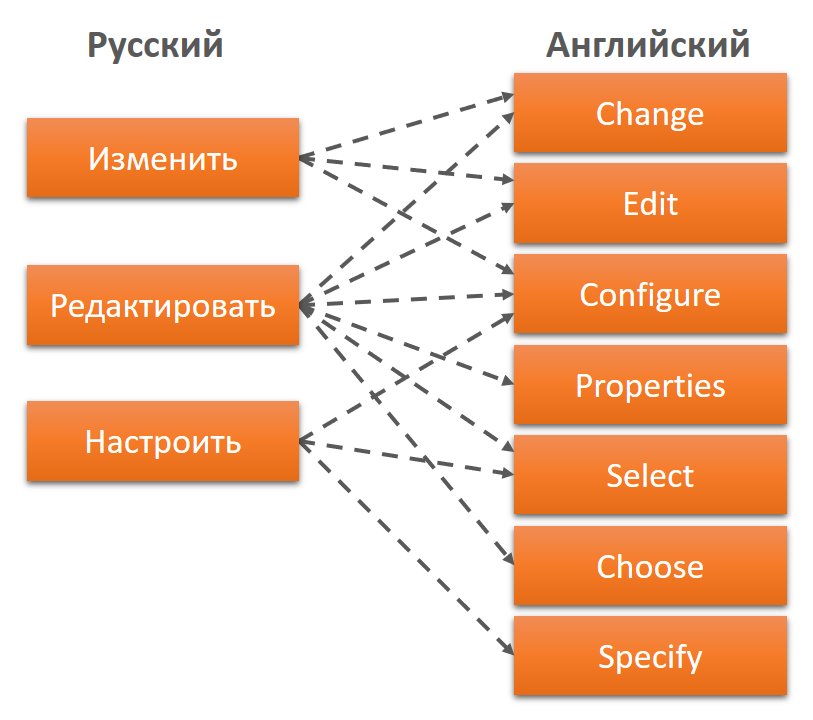
Когда наши программисты взялись за локализацию системы, она была абсолютно к этому не готова. Текст интерфейса хранился в коде, а желание руководства было: «все сделать быстро». Программисты написали скрипт, который выдернул весь текст из кода и закинул в файлы ресурсов, а на следующий день отдали файлы ресурсов первому попавшемуся сотруднику со знанием английского языка, который все быстренько перевел в блокноте. Что из этого получилось, можно увидеть ниже.
На изображении приведена простая кнопка, она открывает какую-то форму с параметрами, где эти параметры можно изменить. Таких кнопок в системе десятки. На русском языке для такой кнопки обнаружилось 3 варианта, локализация на английский содержала уже 7 вариантов.
В этой ситуации сразу возникает большое желание навести порядок в строках интерфейса. Для этого предлагаю применять следующие правила:
- Деление всех строк на группы.
Все строки следует делить на группы в соответствии с типом элементов интерфейса. Даже если строки имеют один и тот же текст, для разных групп могут применяться разные правила перевода. Например, правило капитализации первой буквы каждого слова в английском языке. Для одних типов элементов интерфейса оно применяется, для других нет. - Удаление дублей.
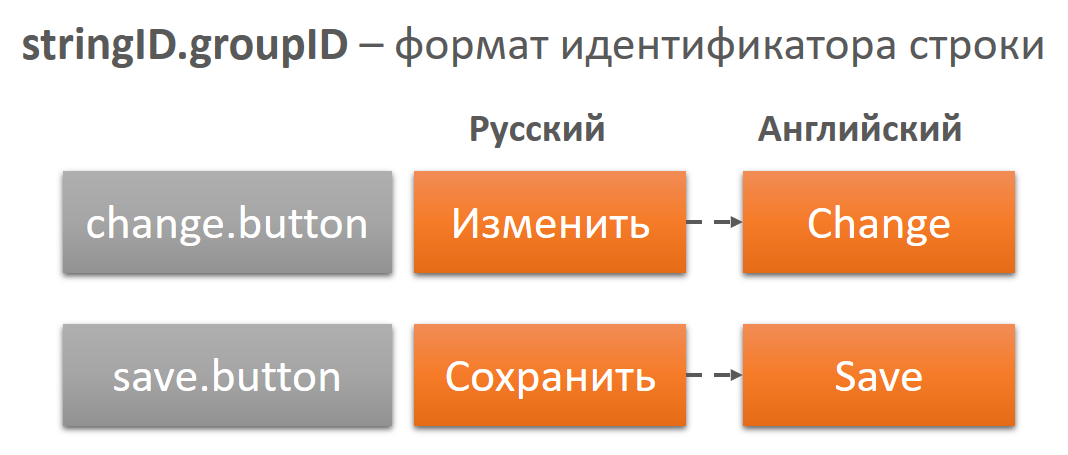
В каждой группе имеет смысл удалить все дублирующиеся строки, то есть строки с одинаковым текстом. Тогда останется единственный вариант как на русском языке, так и на других языках. Это экономит затраты на перевод. Отмечу, что скорее всего повторяющиеся строки все же останутся, так как в некоторых случаях контекст у них может быть разный. Более того, такие строки, с одинаковым исходным текстом могут переводиться по-разному. Например, слово Имя, в контексте имени человека может переводиться как First name, а в контексте имени файла просто Name. - Добавление контекста в идентификаторы строк.
Идентификатор строки может состоять из идентификатора самой строки и группы, к которой строка относится. Это нужно, чтобы переводчик мог использовать идентификатор для выбора правила локализации. Если мы имеем такие правильные идентификаторы, то процесс проверки и исправления тех же ошибок капитализации можно легко автоматизировать.
К сожалению, применить подобные правила ко всем существующим 30 000 строкам сразу, очень трудоемко. Здесь мы находимся на начальном этапе и постепенно приводим в порядок наиболее часто повторяющиеся строки и разрабатываем правила для новых строк. Но согласитесь, было бы супер, если бы все правила были прописаны и выполнялись сразу!
Процесс документирования и локализации
Давайте взглянем на процесс документирования и локализации с привязкой ко времени. Если начать документирование и локализацию раньше, чем закончилась разработка фичи, то придется все переделать (возможно, несколько раз).
То же самое с переводом документации.
А если отдать пользователям документацию раньше, чем закончились все правки, можно рассчитывать на кучу замечаний. Скорее всего часть из этих замечаний и так будет поправлена на последних этапах разработки, но придется потратить лишнее время, чтобы их обработать.
Если же процессы не согласованы, и мы вовремя не отслеживаем все изменения, то «ничего-ничему-нигде» не будет соответствовать.
Документация не будет соответствовать интерфейсу. Скриншоты не будут соответствовать интерфейсу и тексту документации.
То же самое с локализацией. Текст интерфейса и документации на исходном языке не будет соответствовать тексту интерфейса и документации на других языках.
Мы решили, что на текущий момент можем себе позволить начинать каждый новый этап только после того, как закончили предыдущий.
Да, документация и локализация у нас выходят с опозданием уже после релиза. И если говорить о локализации, мы уже обеспечили себе возможность непрерывной локализации, но мы этой возможностью не пользуемся и делаем всю локализацию одним этапом в конце релиза. Пара дней в рамках полугодового релиза — это совсем небольшой этап.
Пока наш продукт не массовый, у нас нет острой необходимости чтобы документация и локализация появлялись в один день. У нас длинные релизы, крупные корпоративные клиенты, которых не очень много по сравнению с небольшими и более массовыми продуктами, и устанавливать новую версию продукта или обновляться на нее они начинают далеко не сразу. Затраты на постоянное переделывание при этом заметно сокращаются.
Проблемы терминологии
На этапе документирования и локализации мы постоянно сталкивались с проблемами терминологии:
- Одни и те же сущности назывались по-разному, а разные сущности назвались одинаково.
- Одни и те же термины переводились по-разному, а разные термины переводились одинаково.
- Какая-либо сущность могла приравниваться к ее дочерним сущностям, из которых она состоит, или родительским сущностям.
- Выбирались неудачные или неверные термины для обозначения сущности.
Процесс же разработки у нас какое-то время выглядел так:
- Аналитики пишут постановку.
- Постановку тестируют тестировщики.
- Разработчики кодируют.
- Тестировщики тестируют результат.
А при попытках вклиниться в этот процесс с терминологией, мы получали такие отговорки:
- Вы затормозите весь процесс.
- Это вообще все не так важно.
- У вас есть инструменты, вы все можете поправить потом.
Но «потом» выяснялось, что поправить мы можем далеко не все. Например, были ситуации, когда из-за неверно понятой терминологии объекты системы размещались не на тех уровнях иерархии или объединялись в неверные группы.
Сейчас мы проверяем термины и текст интерфейса параллельно тестированию постановки. То есть пока тестировщики пишут свои замечания, мы пишем свои.
Что мы делаем во время тестирования постановки:
- Выявляем новые термины.
- Проверяем текст интерфейса: на корректность употребления терминов, соответствие руководству по стилю и соответствие ролям.
- Выявляем уже существующие строки, чтобы не делать дубли.
- Согласуем необходимость локализации, т. к. некоторые части интерфейса могут использоваться только в одной стране.
При выявлении новых терминов мы добавляем их в глоссарий, при этом:
- Добавляем определение или контекст.
- Указываем на взаимосвязь с другими терминами (указываем родительские и дочерние термины).
- Пытаемся сразу указать английское значение, так как после выбора английского названия иногда становится понятно, что русское выбрано не очень верно.
Можно сказать, что благодаря согласованию терминологии и текстов интерфейса на этапе согласования постановки, мы стали экономить кучу времени на многократных исправлениях на последующих этапах.
Документирование
Принципы, которым мы придерживаемся при документировании:
- Использование системы с единым источником.
- Использование глоссария.
- Использование руководства по стилю.
- Деление документации на небольшие и легко отчуждаемые документы.
Это стоит делать, даже если основной формат – это Web. Если понадобится, можно переводить не всю документацию, а только самые важные документы, или делать это поэтапно.
Теперь расскажу про некоторые, особо важные моменты процесса документирования.
Переиспользование текста
В большинстве систем работы с единым источником можно использовать переменные. Поэтому мы разработали сценарии, которые автоматически преобразуют файлы ресурсов интерфейса в файлы с переменными. В процессе разработки документации мы не набираем тексты элементов интерфейса, а вставляем в текст переменные. Таким образом в русскую версию автоматически подтягиваются русские строки, в английскую версию английские, в немецкую немецкие.
Какие это дает преимущества:
- Исключаются ошибки в текстах элементов интерфейса, если они упоминаются в документации. Тексты элементов интерфейса в документации всегда идентичны текстам в интерфейсе.
- Если строки текста поменялись в интерфейсе, они автоматически меняются в документации.
- Исключаются ошибки при переводе текстов элементов интерфейса в документации.
- Переводчик тратит меньше времени на работу.
Еще в документации есть много повторяющихся предложений. Например, такое предложение, как — «Нажмите на кнопку Сохранить.». В системах работы с единым источником такое предложение можно поместить в сниппет. Сниппет — это такой небольшой файл, который можно вставлять на другие страницы документации.
Как вы можете заметить, текст кнопки Сохранить в сниппет также подставляется из переменной.
Это дает следующие преимущества:
- Одинаковые по смыслу предложения везде идентичны, а значит повышается единообразие текста.
- Сокращаются затраты на разработку документации за счет переиспользования.
- Переводятся такие предложения только 1 раз. Это сокращает затраты переводчика.
Скриншоты и другие изображения
В своей документации мы часто используем скриншоты и другие изображения, которые могут содержать текст.
Чтобы делать скриншоты на разных языках своими силами, под каждым скриншотом мы пишем текст, который на нем используется. Этот текст тегируется и не попадает в готовую документацию. Перед тем, как делать перевод документации, мы переводим тексты для скриншотов. А во время перевода документации делаем скриншоты силами технических писателей без знания языка.
С использованием скриншотов бывают и другие трудности. Например, как отследить все изменения, если в интерфейсе меняется одна строка текста, которая используется в 50 местах?
Как потом найти все скриншоты этих 50 мест, чтобы заменить их в документации?
Для решения этой проблемы мы используем инструмент QVisual, который разработали в компании Tinkoff. Процесс работы с ним выглядит так:
- Во время разработки документации под каждым скриншотом мы делаем ссылку на стенд, где этот скриншот сделан.
- В определенный момент готовим список всех ссылок.
- Загружаем полученный список в QVisual.
- QVisual пробегает по одной версии продукта и делает набор скриншотов.
- Далее берем новую версию продукта и QVisual пробегает по ней, используя те же ссылки.
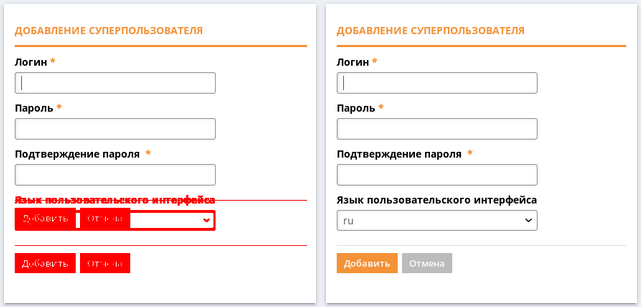
- Затем QVisual сравнивает 2 набора скриншотов и генерирует отчет. В отчете, в графическом виде можно увидеть различия между двумя версиями. Пример ниже. Сразу видно, что в новой версии скриншота появилось дополнительное поле Язык пользовательского интерфейса.
- Далее повторяем процедуру сравнения (п. 1-6) для каждого языка.
- Берем отчеты, и проходимся по скриншотам в документации.
Таким образом мы сокращаем затраты на многочисленные проверки скриншотов вручную. Тем более, что вручную не всегда удается выявить все ошибки, что-то можно просто проглядеть.
Правда, не все окна можно открыть при помощи ссылок и это работает только для Web-интерфейса, но часть проблем с обновлением скриншотов это все равно снимает.
Локализация интерфейса
Перед локализацией интерфейса, если это еще не сделано, нужно перевести все термины глоссария.
Когда глоссарий переведен, можно начинать локализацию. В этом процессе мы придерживаемся следующих принципов:
- Используем глоссарий.
- Используем память переводов.
- Используем руководство по стилю.
- Используем контекст.
- Используем автоматическую проверку качества (Quality Assurance или QA).
Отмечу, что контекст может иметь больший приоритет для принятия решения о переводе, чем наличие такой же, уже переведенной строки в памяти переводов. Также на основе контекста могут применяться те или иные правила перевода, которые указаны в руководстве по стилю.
Может быть несколько способов предоставления контекста:
- Как я уже писал выше, контекст может быть заложен в самом идентификаторе строки или в дополнительных полях файлов ресурсов (если позволяет формат).
- Могут быть добавлены скриншоты. На данный момент мы имеем возможность к особо сложным строкам вручную добавлять скриншоты.
- Предоставление стендов и документации на исходном языке. Как показывает практика, этот способ не работает. Переводчики обычно не пользуются предоставленными им материалами и стендами. Возможно потому, что время на перевод одной строки увеличивается многократно.
Перевод документации
Принципы, которым мы стараемся придерживаться при переводе документации:
- Сначала выполняем перевод текстов для скриншотов и других изображений. Как я писал выше, скриншоты делаются параллельно с переводом документации. Делается это на стенде с использованием переведенных текстов для скриншотов.
- Переводим только изменившиеся и новые строки. Переведенные ранее строки со 100% совпадением просто не смотрим. Да, можно каждый релиз заново вычитывать всю документацию, но с учетом того, что каждый релиз обновляется примерно 10% текста, вычитывать оставшиеся 90% текста – это неоправданные затраты.
- Используем глоссарий. Глоссарий должен быть переведен ранее, на этапе локализации интерфейса.
- Используем память переводов документации.
- Используем память переводов интерфейса.
- Используем руководство по стилю.
- Используем автоматическую проверку качества (QA).
Организационная структура и обратная связь
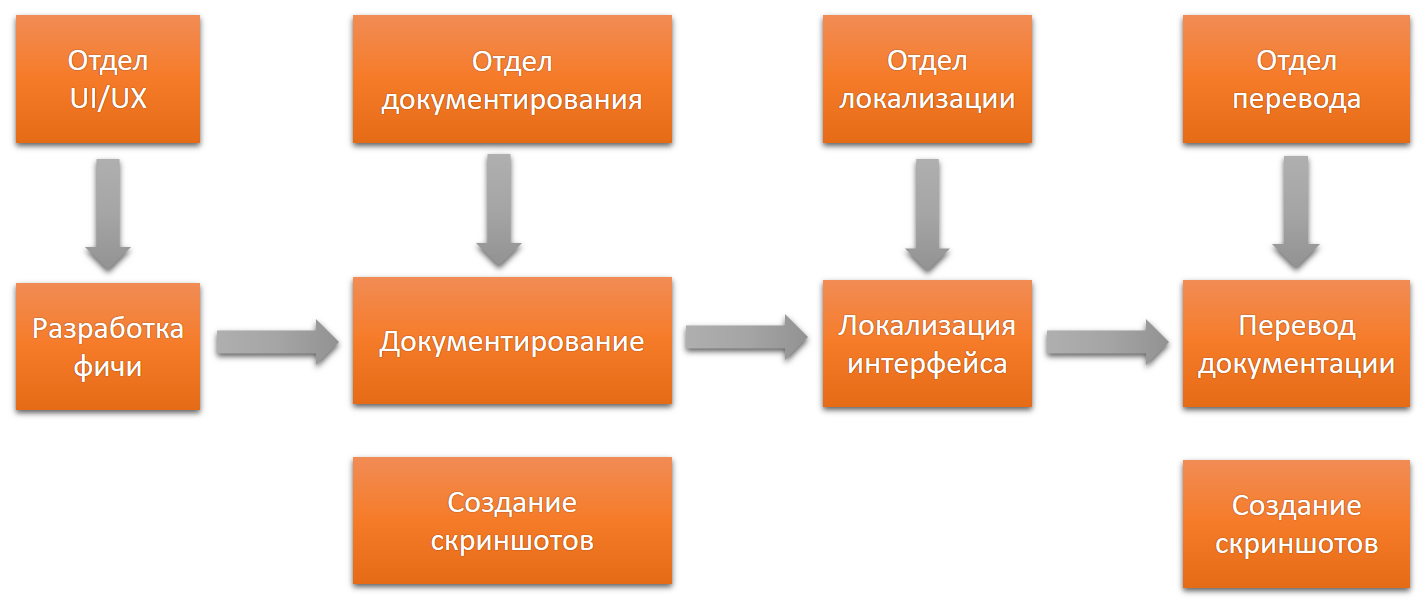
Скажу несколько слов об организационной структуре компании. У всех она разная, но представим такой случай, когда за каждый этап отвечает свой отдел.
Обратная связь от одного отдела к предыдущему в таком варианте будет затруднена, взаимодействие между сотрудниками разных отделов налаживается сложно. Решение всех вопросов через руководителя тоже «узкое горлышко». У каждого руководителя свое видение, цели и приоритеты. Много времени может тратиться на дополнительные согласования.
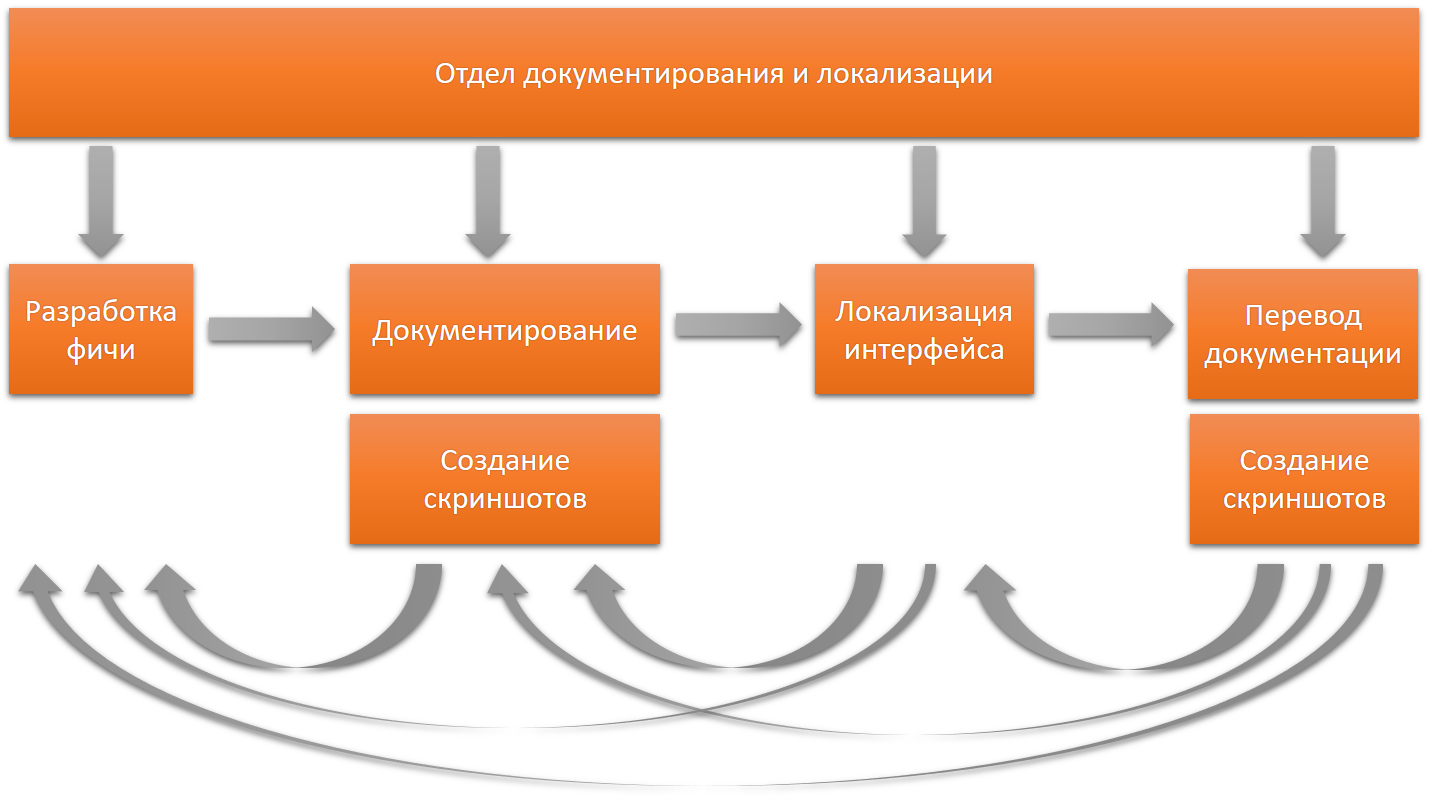
На мой взгляд за все тексты на всех языках должен отвечать один отдел.
При таком распределении ответственности, каждая версия продукта — это отдельный проект из нескольких этапов, и за качество выполнения этого проекта нужно отвечать в целом. Так проще наладить обратную связь, оперативно разобраться в любой проблеме, сделать ретроспективу и найти первопричину проблемы.
Приведу пример.
Благодаря тому, что наши технические писатели сами проверяют переводы с помощью QA, мы увидели десятки, а то и сотни ошибок неконсистентности.
Оказалось, что переводчик видит одинаковые по смыслу, но по разному написанные предложения и делает для них один и тот же перевод. Мы инициировали задачу и технический писатель заменил все разные варианты одного и того же по смыслу текста на один сниппет. Теперь таких повторяющихся ошибок больше не будет. Специалистам не придется тратить время на их анализ, а перевод на новые языки в будущем будет проще.
В общем случае, если у переводчика во время перевода возникают вопросы, то для нас это уже «звоночек» о том, что что-то не так на ранних этапах и надо делать задачу на исправление.
Какое качество документации нужно
Перед тем как пытаться сделать идеальную документацию на всех языках, стоит задуматься, а какое качество нужно? Ответить на этот вопрос помогут дополнительные вопросы:
- Кто пользователи документации?
Если документация во внешнем доступе и клиенты на основе нее принимают решение о покупке продукта, то качество должно быть близко к идеальному. Если документацией чаще всего начинают пользоваться уже после внедрения системы и читают ее преимущественно инженеры (у нас именно так), качество документации уже не повлияет на решение о покупке. Главное, чтобы инструкции помогали решать задачи. В этой связи важно, чтобы все было правильно именно в технической части: форматы команд, функции, примеры и так далее. На грамматические или стилистические ошибки инженеры вряд ли обратят особое внимание. - Каково число пользователей?
Если документацию никто не читает, то и об ошибках никто не скажет, никто их не увидит. Все вычитки будут зря. На сколько уместно в этом случае вкладываться в качество документации или вычитывать переводы? Возможно, лучше сначала потратить часть ресурсов на то, чтобы привлечь пользователей.
Вычитка документации и обратная связь пользователей
Если принято решение вычитывать документацию:
- Вычитывать можно далеко не все.
Постройте статистику по использованию документации и отдайте на вычитку, например, топ-50 страниц, которые читают сотни и тысячи пользователей. Если какие-то страницы читают 1-2 раза в год, то ими можно пренебречь. - Лучше вычитывать готовую документацию.
Не все проблемы можно увидеть в CAT-системе. Например, соответствие картинок тексту или состыковка разных частей текста в общем документе (сниппеты, переменные), единый подход к переводу заголовков и тому подобное. - Никто кроме пользователей, которые реально решают задачи с помощью документации, не скажет, качественная у вас документация или нет.
- Никто кроме носителя языка не скажет, на сколько качественно переведена документация.
Web-документацию с уже описанными фичами мы делаем доступной для внутреннего использования еще до выхода релиза. Вычитку документации на русском языке делает весь департамент и в особенности аналитики, так как именно они ставят задачи на разработку и на этом этапе лучше всех понимают, что должно быть в документации.
Новые сотрудники также очень ценные пользователи документации. У новичков свежий взгляд, а еще цель разобраться с системой во время испытательного срока.
Переведенную документацию могут вычитывать и партнеры. Можно заключать с ними такие соглашения. Партнер присылает вам все замечания, а заодно сам разбирается в системе.
Что заставляет пользователей отправлять обратную связь:
- Все любят критиковать.
И чтобы критика не оставалась где-то в курилке, можно сделать простой способ попадания ее к нам. Мы сделали очень простую форму. Можно выделить текст с ошибкой, нажать Ctrl+Enter и нажать кнопку Отправить. Иногда комментарии писать даже не обязательно. Это занимает очень мало времени и не вызывает особых трудностей. - Замечания должны обрабатываться.
Оставляя замечание пользователь попадает в копию задачи и видит, когда и в какой версии она закрылась. Если же замечания оставлять без внимания, пользователи быстро поймут, что они зря тратят время и больше писать не будут. - Пользователи делают это для себя.
То есть, помогают улучшить документацию для себя и для других пользователей, получают от этого удовлетворение. В следующий раз, когда им повторно потребуется информация (в которой была ошибка или которой недоставало), они ее найдут в документации и им не придется самим писать ответ клиенту. Они просто отправят ссылку клиенту, который обратился в техподдержку. Таким образом они сокращают себе и своим коллегам затраты.
Отмечу, что замечания мы исправляем только в текущей версии документации, то есть той, что еще находится в разработке. Считаем, что лучше уделять как можно больше внимания новым версиям и делать в ней как можно меньше ошибок, чем тратить кучу времени на поддержку старых версий.
Выводы
Каждая компания находится на своем этапе развития, и часто не нужно вкладывать огромное число человеко-ресурсов, чтобы достичь приемлемого на сегодняшний день результата.
Сначала разберитесь, что именно необходимо на текущий момент и сделайте только это, а затраты увеличивайте по мере возрастания потребностей.
Это была достаточно общая статья о процессах документирования и локализации в целом. В будущем попробую написать о более узких темах.
Спасибо, если дочитали до конца! Желаю вам успехов в работе и отладке своих процессов документирования и локализации!
Буду рад ответить на вопросы, обсудить ваши мысли и идеи!



