
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Привет! А вот и вторая часть поста про принципы юнит-тестирования. Если в первой мы обсудили влияние тестов на разрабатываемые продукты и познакомились с теорией юнит-тестирования, то в этой обсудим некоторые практические моменты. Внутри поста — структура юнит-тестов, стили юнит-тестов, принципы рефакторинга, полезные советы для того, чтобы ваши юнит-тесты были эффективными и читаемыми, а также некоторые антипаттерны при написании тестов.
Ну и, конечно же, список источников, где можно получить дополнительную полезную информацию. В общем, начнём.
Структура юнит-тестов
В нашей команде при написании юнит-тестов мы стараемся использовать подход AAA — Arrange, Act, Assert (Подготовка, Действие, Проверка).
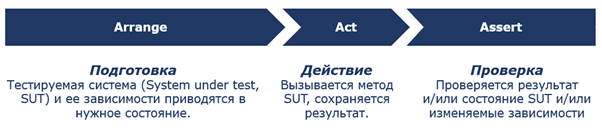
Кратко расскажу о нем. Тест делится на три блока, которые идут друг за другом. Ширина блоков на рисунке выше образно отражает объём кода, который должен занимать каждый из блоков.
Первый — Arrange, подготовка. В этом блоке готовятся тестовые данные, определяется поведение замокированных зависимостей и выполняются другие подготовительные действия. Таким образом тестируемая система приводится в нужное для теста состояние. Этот блок чаще всего самый объемный.
Второй блок — Act, действие. Вызывается метод тестируемой системы и сохраняется результат, который этот метод возвращает (если таковой есть). Самый маленький блок по объему, чаще всего одна строка кода – вызов метода.
Третий блок — Assert, проверка. В этом блоке выполняется серия проверок – например, сравнивается результат, который вернул вызов метода тестируемой системы с ожидаемым. Или проверяется, какие зависимости вызывались, в какой последовательности и какими параметрами. Этот блок отвечает на вопрос, правильно ли работает тестируемая система и фактически заключает в себе ценность теста. По объему сравним с блоком Arrange, объем зависит от того, как много нужно проверок, чтобы убедиться в правильности работы тестируемой системы.
Говоря про эффективность, стоит упомянуть про хорошие практики. Я приведу простые, на первый взгляд очевидные, но как мне кажется, полезные советы:
Избегайте множественных блоков Arrange, Act и Assert в одном тесте
Встречались такие юнит-тесты – подготовка тестовых данных, вызов метода тестируемой системы, проверка, дополнительная подготовка тестовых данных, вызов другого метода тестируемой системы, проверка. Такой подход усложняет как написание теста, так и диагностику проблем в случае его падения.
Такой тест стоит разделить на несколько, чтобы каждый тест имел по одному блоку каждого типа, и проверял всего один вариант поведения тестируемой системы.
Избегайте условных операторов в тестах
Тесты должны быть простые и линейные, потому что на тесты мы не пишем тесты. Ветвление в тестах усложняет их, что может приводить с тяжело диагностируемым ошибкам. Каждую ветвь условного оператора стоит представить отдельным тестом.
Избегайте секций Act больше, чем из одного вызова
Если для теста требуется вызвать сначала один метод тестируемой системы, потом другой, высока вероятность того, что API тестируемой системы спроектировано неправильно. Использующий такую систему клиент должен в этом случае помнить, в каком порядке и сколько методов необходимо вызвать для получения нужного результата. API должно быть продумано так, чтобы одно действие выполнялось за вызов одного метода. Если это не так, то стоит подумать над рефакторингом кода тестируемой системы.
Избегайте больших секций проверки
При проверке объектов с большим количеством полей, блок Arrange может довольно сильно разрастаться, если каждое из полей объекта, возвращенного вызовом тестируемой системы в блоке Act, сравнивается с каждым полем объекта - ожидаемого результата, отдельно. В этом случае стоит подумать о возможности добавить в тестовый класс дополнительный метод сравнения таких объектов, который будет проверять равенство по всем нужным полям. Это сильно упростит тест и с точки зрения читаемости, и с точки зрения написания.
Используйте одинаковое имя для тестируемой системы во всех тестах
Мы у себя используем имя sut (System Under Test) для переменной, которой присвоена ссылка на тестируемую систему. Видя в тесте переменную sut, сразу понимаешь, что это тот класс, который тестируется. Это начинает приносить свои плоды достаточно быстро, снижая вероятность ошибок и упрощая понимание тестов.
Используйте фабричные методы для подготовки схожих данных для тестов
Часто для большинства тестов одного класса требуется практически одинаковая подготовка тестовых данных с минимальными отличиями. Когда объем подготовки тестовых данных достаточно большой, его можно вынести в отдельные фабричные методы, куда в параметры можно передавать необходимые изменения, а на выходе получать подготовленные данные. Это помогает не дублировать большие объемы кода в каждом тестовом методе.
Договоритесь об именовании тестовых методов в команде
Про именование тестов есть множество материалов и различных подходов в сети. Споры как именовать тесты правильно ведутся и сейчас, у всех этих подходов есть плюсы и минусы. Я не буду их рассматривать в этом посте, мне хочется лишь донести, что важно иметь один взгляд на именование тестов в команде, с которым согласны все участники. Это сильно упростит чтение тестов, написанных другим участником команды.
Используйте библиотеки ассертов для повышения читаемости тестов
Рекомендую использовать библиотеки ассертов, которые позволяют писать проверки в виде DSL, например, AsserJ (для Java) или AssertK(для Kotlin). Такие библиотеки есть для большинства языков, и их использование сильно повышает читаемость кода тестов. Нужно помнить, что читаем код мы чаще, чем пишем.
Стили юнит-тестирования
Под стилями юнит-тестирования понимается то, как производится оценка правильность работы тестируемого кода.
Первый из них — проверка выходных данных

Тест проверяет результат, генерируемый тестируемой системой. Такой стиль предполагает отсутствие побочных эффектов, а единственным результатом работы тестируемой системы является возвращаемое значение.
Как это происходит: производится вызов метода тестируемой системы, этот метод возвращает результат после своей работы, производится сравнение возвращенного методом результата с ожидаемым. Если значение, которое нам вернула тестируемая система и значение, которое мы ожидали, совпадают, значит, она работает корректно. Это очень простой стиль, но в то же время очень мощный. Увы, но этот стиль не всегда применим.
Он может быть применён к так называемым чистым функциям, для которых он будет лучшим стилем. Чистая функция - терминология из области функционального программирования. Такая функция детерминирована – зависит только от входных данных, и каждый раз возвращает одинаковое значение при вызове с одинаковыми параметрами (если не было иных изменений), а также не имеет побочных эффектов (например, не изменяет внутреннее состояние класса, не выбрасывает исключения, которые фактически являются еще одним результатом работы функции и прочее). Более подробно можно почитать по ссылке в конце поста.
Второй стиль — проверка состояния
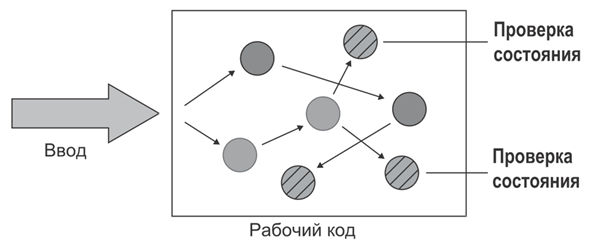
Тест проверяет итоговое состояние тестируемой системы после выполнения операции, либо его изменяемых зависимостей.
Как это происходит: вызывается метод тестируемой системы, после чего проверяется состояние тестируемой системы или состояние ее изменяемых зависимостей, что позволяет понять, правильно ли отработала тестируемая система, сравнивая ожидаемое состояние и то состояние, в которое они перешли.
Такой стиль используется классической школой. В отличии от проверки состояния, этот стиль более подвержен ложным срабатываниям из-за высокой вероятности завязывания на детали имплементации. Обычно тесты, написанные в этом стиле больше по объему, чем в стиле проверки выходных данных из-за более объемного блока проверок.
Третий стиль — проверка взаимодействия

Такой стиль используется лондонской школой. Тест использует моки для проверки взаимодействий между тестируемой системой и ее изменяемыми зависимостями.
Как это происходит: вызывается метод тестовой системы, после чего проверяется взаимодействие с моками (например, с какими параметрами и в какой последовательности они вызывались).
Этот стиль наиболее подвержен ложным срабатываниям, потому что наиболее сильно привязан к деталям реализации изменяемых зависимостей. Также тесты в этом стиле самые объемные, потому что требуется настройка поведения моков (особенно цепочки моков – когда один мок при вызове его метода возвращает другой мок) и проверка взаимодействий с ними.
Рассмотренные стили можно свести в таблицу для сравнения по устойчивости к рефакторингу и затраты на сопровождение.

Можно увидеть, что проверка выходных данных выигрывает по всем фронтам. И ее рекомендуется использовать везде, где она применима.
Рефакторинг для эффективных юнит-тестов
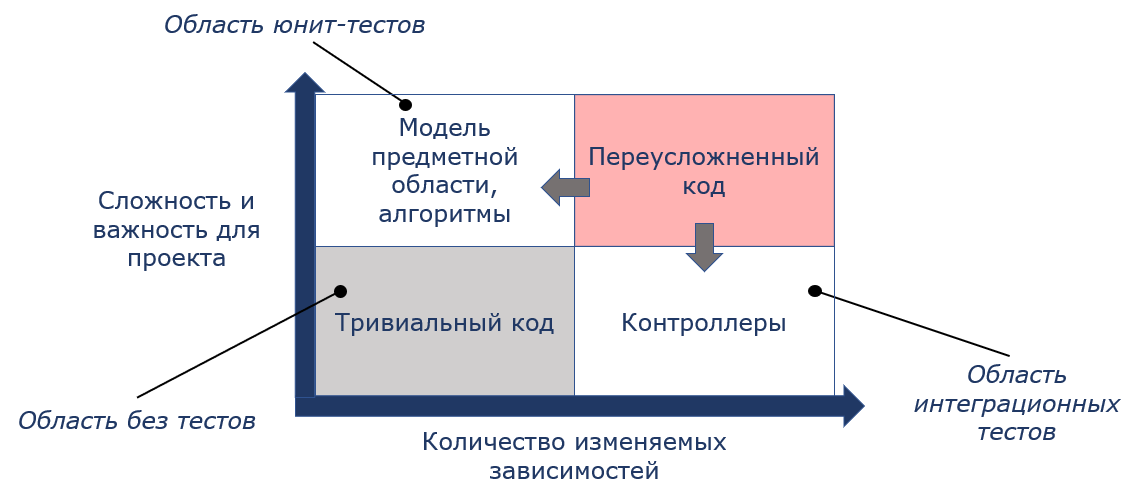
Улучшить качество тестов иногда возможно только при рефакторинге тестируемого кода. Код можно оценить по двум его характеристикам:

Вертикальная ось отражает важность и сложность кода. Чем важнее код, тем больше он делает полезного для проекта с точки зрения бизнес-ценности. Сложность кода можно воспринимать как цикломатическую сложность - количество возможных ветвлений в программе либо в методе.
Горизонтальная ось отражает количество изменяемых зависимостей. Тестирование кода с большим количеством изменяемых зависимостей требует значительных затрат.
Таким образом, код можно разделить на четыре квадранта.
Модель предметной области, алгоритмы. Этот код, который приносит основную ценность продукту. Содержит основную логику программы и имеет минимальное количество изменяемых зависимостей.
Тривиальный код. Конструкторы, геттеры, простые однострочные методы, то есть то, что очень имеет низкую сложность и важность, малое количество или вообще отсутствие зависимостей.
Контроллеры. Имеют низкую сложность, но большое количество зависимостей. Контроллеры — это координаторы работы компонентов нашей логики.
Переусложнённый код. У такого кода высокая сложность и большое количество зависимостей. В качестве примера можно привести «толстый контроллер».
Для каждого из квадрантов есть рекомендации, как тестировать такой код:
То, что имеет высокую сложность и важность для проекта, но имеет небольшое количество изменяемых зависимостей, в основном это предметная область, покрывается юнит-тестами, которые будут наиболее эффективными.
Тривиальный код можно оставлять без покрытия тестами. Затраты на тестирование такого кода зачастую не окупаются.
Тестирование контроллеров юнит-тестами зачастую не лучшее решение из-за большого количества зависимостей и простой логике работы. Для тестирования такого кода рекомендуется использовать интеграционные тесты.
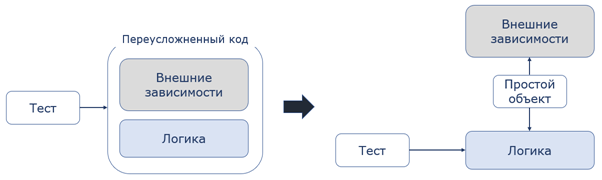
Переусложнённый код, как и тривиальный, тестировать также не стоит. Сам код скорее всего нарушает принцип единственной ответственности, а тесты на такой код будут большие и сложные в разработке и поддержке. Такой код стоит отрефакторить, чтобы перевести функциональность в те области, которые хорошо тестируются.
Один из вариантов – использовать паттерн «Скромный объект» (Humble Object), который позволяет отделить сложную логику от большого количества зависимостей и протестировать сложную логику отдельно. Более подробно про этот паттерн можно узнать по ссылке в конце поста.
Антипаттерны юнит-тестирования
Как и при написании основного кода, в юнит-тестировании существуют антипаттерны, которые стоит избегать. Список антипаттернов не ограничивается рассматриваемыми далее. Я привожу их для того, чтобы можно было понимать, какие риски несет их использование.
Раскрытие приватного поведения и состояния
Не стоит делать публичными методы или свойства, которые иначе остались бы приватными, только для облегчения юнит-тестирования. Часто бывает, что публичный метод внутри себя вызывает набор приватных методов и манипулируют приватными свойствами. И есть соблазн эти приватные методы и свойства сделать публичными для того, чтобы можно было их протестировать отдельно, а не через публичный метод. И это плохая практика.
В чем проблема? Проблема в том, что такой подход ведет к раскрытию деталей имплементации. Тесты становятся хрупкими. При рефакторинге без изменения публичного поведения такие тесты начнут падать, хотя тесты, использующие публичные методы класса будут корректно отрабатывать.
Для тестирования такого кода стоит использовать публичные методы класса. Юнит-тест – это такой же клиент основного кода, как и остальные, для него не должно быть привилегий дополнительного доступа к тестируемой системе по сравнению с обычным клиентским кодом.
Конечно, есть исключения. Например, ORM фреймворкам зачастую не требуется публичного конструктора класса, они могут создать объект через приватный конструктор с использованием рефлексии. В тестах создать объект класса с приватным конструктором простым путем не получится. В таком случае допустимо сделать конструктор публичным, но в конструкторе обязательно нужно не забывать соблюдать все необходимые предусловия, то есть все необходимые проверки для того, чтобы не было возможности сконструировать объект некорректно.
Утечка доменных знаний в тесты
Иногда в тестах, для получения ожидаемого результата, дублируется логика тестируемого кода. Такое встречается достаточно часто. Это приводит к привязке к деталям имплементации и к ложноотрицательным срабатываниям — когда функциональность работает неправильно, но тесты проходят, потому что ожидаемый результат также рассчитывается неправильно.
Как тестировать в этом случае? Основной совет – необходимо предварительно рассчитать результат альтернативным путем, без использования тестируемой системы. Например, сходить за расчетам к экспертам предметной области или бизнес-аналитикам, посчитать вручную или получить его каким-то другим путем. И вот с ним уже сравнивать то, что нам вернула тестируемая система.
Загрязнение кода
Иногда в рабочий код для тестов вставляются дополнительные логические ветви. Например, флаги настроек логирования в зависимости от того, выполняется код при тестировании или в продуктивной среде. В этом случае тестовый код смешивается с рабочим и его приходится поддерживать. А еще он вносит вероятность возникновения багов в продуктивной эксплуатации.
Как в этом случае тестировать? Если мы видим, что в коде нужна изменяемое поведение, и для тестов оно должно отличаться от продуктивной среды, в этом случае для получения различного поведения зависимости, она должна быть представлена интерфейсом, реализация которого будет отличаться для тестов и для продуктивной среды
Полезные ссылки
● Книге Владимира Хорикова. «Принципы юнит-тестирования». Также у автора есть свой и профиль на Хабре.
● Интересная статья по функциональному программированию.
● http://xunitpatterns.com/Humble Object.html
● Подробная статья с примерами про антипаттерны в юнит-тестах.
На этом вторая часть закончена. Всех заинтересовавшихся жду в комментариях для обсуждения.




