Проект «Стикольщик», или сказ о том, как я пробовал ML.Net, отказался от него в пользу простого самописного алгоритма, собрал коллекцию из 18000+ наборов стикеров и создал чат-бота для Telegram, использующего их в общении
Введение
Да, длинный и сумбурный заголовок, далее постараюсь быть более лаконичен. История берет начало с выпуска бета версии ML.Net, желания попробовать машинное обучение и большие данные в деле на знакомой платформе. Мысль о точке приложения новоиспечённого инструмента анализа витала в воздухе, а если точнее, то переходила из одной головы в другую в форме чат-ботов говорилок в телеграме.
Хотелось сделать не просто ещё одну реализацию, а что-то иное. В результате выбор пал на стикеры. С одной стороны, более примитивный и первобытный способ общения, с другой – меньшая вероятность бредогенерации, т.к. картинка оставляет больше простора для додумывания смыслов.
Все те говорилки, как позже выяснилось, использовали цепи Маркова. И как бы это ни было удивительно, моя последняя реализация частично совпала с алгоритмом. Но об этом потом.
В начале был ML.Net. И он позволял с помощью удобных визуальных инструментов обучать модели данных и использовать в проектах на C#. Из предложенных в инструментарии типовых задач была выбрана задача классификации. На вход передаём массив слов, на выходе получаем стикер. То есть разбиваем группы слов на классы. Каждый стикер порождает отдельный класс.
Проблема курицы и яйца
С решаемой задачей определились. Теперь нужно собрать побольше данных. По-хорошему, бот может сам их собирать. Но чтобы сделать бота нужны данные. Замкнутый круг.
Чтобы выйти из бесконечного цикла, открываем Telegram и видим кучу чатов и публичных групп, участники которых используют стикеры. Отлично! Парсим эти данные.
Чтобы распарсить собственные чаты, нужно использовать Telegram API. Я использовал TLSharp. С тех пор много воды утекло и сейчас проект не поддерживается, так что приводить пример кода нет смысла. Единственное, авторы теперь рекомендуют использовать WTelegramClient.
Долго ли, коротко ли, спустя несколько десятков часов получаем текстовый файл с структурой данных в виде диалогов: вопрос/утверждение - ответный стикер.

где prevMsgText – текст сообщения, на которое ответили стикером,
prevMediaUniqueId – уникальный идентификатор стикера, на который ответили стикером,
prevMediaId – идентификатор стикера, на который ответили стикером,
stickerUniqueId - уникальный идентификатор ответного стикера,
stickerId - идентификатор ответного стикера,
emoji – емоджи ответного стикера,
isAnimated – анимированный ли ответный стикер,
setName – название набора стикеров.
Обучение модели ML.Net
Отлично, данные у нас теперь есть. В файле data.csv 9000 диалогов. Выбираем подходящую модель и обучаем.
Документация Microsoft подсказывает, что для наших нужд подходит задача многоклассовой классификации. Для обучения сейчас доступны следующие алгоритмы:
LightGbmMulticlassTrainer
SdcaMaximumEntropyMulticlassTrainer
SdcaNonCalibratedMulticlassTrainer
LbfgsMaximumEntropyMulticlassTrainer
NaiveBayesMulticlassTrainer
OneVersusAllTrainer
PairwiseCouplingTrainer
Первые эксперименты я проводил больше года назад, и тогда было доступно чуть меньше вариантов. Я выбрал SdcaMaximumEntropy.
Код пайплайна обучения модели:
static void TrainAndSaveModel()
{
mlContext = new MLContext();
LoadDataFromLocalDb();
SplitData();
var op = new TextFeaturizingEstimator.Options
{
CaseMode = TextNormalizingEstimator.CaseMode.Lower,
StopWordsRemoverOptions = new Microsoft.ML.Transforms.Text.CustomStopWordsRemovingEstimator.Options
{
StopWords = StopWords.GetStopWords("ru")
},
KeepNumbers = true,
KeepDiacritics = false,
KeepPunctuations = false
};
// Define data preparation estimator
IEstimator<ITransformer> pipeline = mlContext.Transforms.Conversion.MapValueToKey(inputColumnName: "AnswerMediaUniqueId", outputColumnName: "Label")
.Append(mlContext.Transforms.Text.FeaturizeText("QuestionTextFeaturized", op, "QuestionText"))
.Append(mlContext.Transforms.Categorical.OneHotHashEncoding(outputKind: Microsoft.ML.Transforms.OneHotEncodingEstimator.OutputKind.Indicator, inputColumnName: "QuestionMediaUniqueId", outputColumnName: "QuestionMediaUniqueIdHash"))
.Append(mlContext.Transforms.Concatenate("Features", "QuestionTextFeaturized", "QuestionMediaUniqueIdHash"))
.AppendCacheCheckpoint(mlContext)
.Append(mlContext.MulticlassClassification.Trainers.SdcaMaximumEntropy("Label", "Features", exampleWeightColumnName: "Weight"))
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));
// Train model
ITransformer trainedModel = pipeline.Fit(trainData);
// Save trained model
mlContext.Model.Save(trainedModel, trainData.Schema, modelPath);
// Evaluate
IDataView preprocessedTestData = trainedModel.Transform(testData);
Evaluate(preprocessedTestData);
Predict(modelPath);
}
Основная идея такая: берем входные сообщения и классифицируем по ответным стикерам.
Проблемы решения задачи с помощью ML.Net
Идея использовать класссификатор для построения чат-бота оказалась минимально рабочей. Но только минимально. Был получен первый результат: бот стал отвечать стикерами!

Но остались следующие проблемы:
1) Отсутствие вариативности в ответах. Бот всегда отвечал одинаково. Что с одной стороны логично (это всё-таки классификатор), а с другой – быстро надоедает.
2) Трудности переобучения модели. То ли в силу моей криворукости, то ли в недостатке примеров в документации в то время, быстро решить данный вопрос не удалось. Нужно было вручную обучать модель и подсовывать боту.
3) Количество поедаемой оперативной памяти. На мой взгляд это основная и нерешаемая в текущем контексте проблема. После обучения модели на десяти тысячах строк и выделении порядка 7 тысяч классов модель стала занимать около двух гигабайт памяти, что недопустимо, так как давало время задержки при запуске в минуты и занимало всю память сервера под Ubuntu.
Возможно, мною была выбрана неверная модель для обучения и сейчас в арсенале ML.Net есть более подходящий инструмент. В таком случае прошу знающих людей тыкнуть ссылкой.
Моя реализация алгоритма-говорилки
А точнее – показывалки. Всё-таки бот стикеры шлёт.
Этап 0. Сбор данных.
Сохраняем временно все сообщения пользователей, затем раз в сутки ищем такие последовательности: сообщение – стикер, следующий после сообщения. Сохраняем такие последовательности как сущность Диалог:
Cущность Диалог
public class Dialog
{
public int Id { get; set; }
// Question
public string QuestionText { get; set; }
public int? QuestionMediaId { get; set; }
public Media QuestionMedia { get; set; }
// Answer
public int? AnswerMediaId { get; set; }
public Media AnswerMedia { get; set; }
// Meta
public bool ConvertedToWords { get; set; } = false;
}
Попутно сохраняем стикеры и гифки в отдельную таблицу:
public class Media
{
public int Id { get; set; }
public string MediaUniqueId { get; set; }
public string MediaId { get; set; }
public string Emoji { get; set; }
public bool IsAnimatedSticker { get; set; }
public string SetName { get; set; }
/// <summary>
/// Is GIF
/// </summary>
public bool IsAnimation { get; set; }
/// <summary>
/// Is Sticker
/// </summary>
public bool IsSticker { get; set; }
/// <summary>
/// Is Banned
/// </summary>
public bool IsBanned { get; set; }
/// <summary>
/// Need To Moderate
/// </summary>
public bool NeedToModerate { get; set; }
}
Этап 1. Обучение.
После получения диалогов – проводим обучение. Для этого преобразуем каждый диалог в сущность WordMedia – таблица связки для слов, используемых в диалоге и ответных стикеров.
WordMedia
public class WordMedia
{
public int WordId { get; set; }
public Word Word { get; set; }
public int MediaId { get; set; }
public Media Media { get; set; }
public int Count { get; set; }
}
public class Word
{
public int Id { get; set; }
public string Value { get; set; }
public bool IsStopWord { get; set; }
}
Листинг обучения
public async Task<WordMedia> CreateOrUpdateAsync(string word, int mediaId, long? userId)
{
if (string.IsNullOrEmpty(word))
return null;
Word gotWord = words.Find(word);
if (gotWord != null)
{
WordMedia wm = await wordMedias.Get(gotWord.Id, mediaId);
if (wm != null)
{
// прибавлять только если это другой пользователь или никакой не указан
if (userId == null || !await userMedias.Exists(userId, mediaId))
{
wm.Count++;
await CreateUserMedia(userId, mediaId);
return await wordMedias.Update(wm);
}
else
{
return wm;
}
}
else
{
await CreateUserMedia(userId, mediaId);
return await wordMedias.Create(new WordMedia
{
WordId = gotWord.Id,
MediaId = mediaId,
Count = 1
});
}
}
else
{
Word newWord;
newWord = await words.Create(new Word
{
Value = word,
IsStopWord = textAnalizer.IsStopWord(word)
});
await CreateUserMedia(userId, mediaId);
return await wordMedias.Create(new WordMedia
{
WordId = newWord.Id,
MediaId = mediaId,
Count = 1
});
}
}Разберём на примере. Пусть входное сообщение «Мама мыла раму», ответный стикер имеет id=42. Тогда разбиваем предложение на 3 слова: мама, мыть, рама. Для приведения слов в нормальную форму используем DeepMorphy. Для проверки, является ли слово стоп-словом (а, ты, ведь, мы) словарь в библиотеке dotnet-stop-words.
Таким образом у нас получается таблица:
WordId | MediaId | Count |
Мама | 42 | 1 |
Мыть | 42 | 1 |
Рама | 42 | 1 |
|
|
|
Дальше пусть будет такой диалог: «папа мыл машину» - стикер с машиной и идентификатором 161.
После этого диалога таблица WordMedias изменилась:
WordId | MediaId | Count |
Мама | 42 | 1 |
Мыть | 42 | 1 |
Рама | 42 | 1 |
Папа | 161 | 1 |
Мыть | 161 | 1 |
Машина | 161 | 1 |
И последний диалог: «мой до дыр» - и стикер с id 42.
WordId | MediaId | Count |
Мама | 42 | 1 |
Мыть | 42 | 2 |
Рама | 42 | 1 |
Папа | 161 | 1 |
Мыть | 161 | 1 |
Машина | 161 | 1 |
До | 42 | 1 |
Дыра | 42 | 1 |
Как видно из таблицы, такое представление данных похоже на Цепь Маркова первого порядка. Представим данные в виде графа:

Пусть бот получил такое сообщение: «Привет. А я только помылся.» Так как кроме мыть(ся) в данном случае в базе нет слов, то ответ будет – 42.
Другой пример: «Мама мыла машину». Разбиваем на слова и ищем по таблице WordMedias. Мама – 42(1), мыть – 42(2), 161(1), машина – 161(1). Суммируем оба варианта ответа: 42 – 3, 161 – 2. Выигрывает вариант «стикер под номером 42».
Код выбора нескольких лучших вариантов ответа
public IQueryable<KeyValuePair<int, float>> GetBestMediaIds(List<int> wordIds, int count)
{
bool IsStopWord(int wordId)
{
var word = context.Words.Where(w => w.Id == wordId).FirstOrDefault();
return word.IsStopWord;
}
Dictionary<int, float> GetWeights(IEnumerable<WordMedia> wmedias, float weightCoeff)
{
Dictionary<int, float> mediaWeights = new Dictionary<int, float>();
foreach (var wm in wmedias)
{
if (!mediaWeights.TryGetValue(wm.MediaId, out float curWeight))
{
mediaWeights.Add(wm.MediaId, (float)(wm.Count * weightCoeff));
}
else
{
mediaWeights[wm.MediaId] += (float)(wm.Count * weightCoeff);
//бонус синергии
mediaWeights[wm.MediaId] *= 100f;
}
}
return mediaWeights;
}
Dictionary<int, float> allMediaWeights = new Dictionary<int, float>();
var wordMedias = context.WordMedias.Where(w => wordIds.Contains(w.WordId))
.Include(w => w.Word)
.Include(m => m.Media)
.ToList();
// remove banned medias
wordMedias.RemoveAll(wm => wm.Media.IsBanned);
var stopWordMedias = wordMedias.Where(w => w.Word.IsStopWord);
var normalWordMedias = wordMedias.Where(w => !w.Word.IsStopWord);
var stopMediaWeights = GetWeights(stopWordMedias, 1f / 1000000f);
var normalMediaWeights = GetWeights(normalWordMedias, 1);
// union dics
foreach (var n in normalMediaWeights)
{
foreach (var s in stopMediaWeights)
{
if (s.Key == n.Key)
{
normalMediaWeights[n.Key] += s.Value;
}
}
}
allMediaWeights = new Dictionary<int, float>(normalMediaWeights);
foreach (var s in stopMediaWeights)
{
bool foundStopInNormal = false;
foreach (var n in normalMediaWeights)
{
if (s.Key == n.Key)
{
foundStopInNormal = true;
}
}
if (!foundStopInNormal)
{
allMediaWeights.TryAdd(s.Key, s.Value);
}
}
var bestMediaIds = allMediaWeights.OrderByDescending(m => m.Value).Take(count).AsQueryable();
return bestMediaIds;
}Самописный вариант оказался не хуже «коробочного»:
Далее рассмотрим проблемы, возникающие при накоплении большого количества данных.
Проблема модерации
Так как это большой коллективный чан со стикерами и гифками, то, следовательно, получаем иногда неприличные изображения. Решение – нужен специально обученный алгоритм(читаем как человек) по выявлению и блокированию вредного контента. Так же даём возможность пользователям жаловаться самостоятельно (команда /ban по неугодной картинке).
Проблема спама в отдельных каналах
После запуска оказалось что некоторые каналы используются для спама однотипной информации вроде рекламы казино или чего-то похуже. Что делать? – отключаем сохранение сообщений в таких чатах. Опять нам помогает специально обученный человек.
Проблема спама конкретными людьми
Некоторые люди имеют обыкновение слать одни и те же стикеры много раз (с целью сломать алгоритм или просто не могут устоять - очень уж красивые картинки). Решение – добавляем таблицу UserWordMedia:
UserWordMedia
/// <summary>
/// Таблица, показывающая отправлял ли уже пользователь такой стикер. Чтобы не сильно увеличивать вероятность стикера
/// если один человек будет постоянно его слать
/// </summary>
public class UserWordMedia
{
public long? UserId { get; set; }
public int MediaId { get; set; }
public Media Media { get; set; }
}
Если пользователь будет слать стикер многократно – сохранится только первый раз.
Проблема последовательности слов
В описанном варианте предложение «мама мыла раму» и «рама мыла маму» идентичны, что несколько печально. Попробуем научить бота видеть различия.
Для этого нам понадобится ещё пара таблиц – Sequence и SeqMedia.
Sequence и SeqMedia
public class Sequence
{
public int Id { get; set; }
public int WordId { get; set; }
public Word Word { get; set; }
public int Position { get; set; }
public DateTime CreatedTime { get; set; } = DateTime.Now;
public DateTime UpdatedTime { get; set; }
}
public class SeqMedia
{
public int SequenceId { get; set; }
public int MediaId { get; set; }
public Media Media { get; set; }
public int Count { get; set; }
public DateTime CreatedTime { get; set; } = DateTime.Now;
public DateTime UpdatedTime { get; set; }
}
Таблица Sequence хранит последовательности из слов, а SeqMedia – их соответствие с выбираемым стикером.
Новая функциональность по определению ответного стикера была введена, но данных для последовательностей в разы меньше чем для отдельных слов, поэтому комбинируем оба подхода и определяем лучший стикер для ответа.
Вариативность ответа
До сих пор была описана ситуация, при которой ответ всегда одинаков – лучший из имеющихся вариант. Добавим небольшую вариативность: получим 10 лучших ответов и отдадим один из них случайно.
Описание функционала бота
Мы прошлись последовательно от момента появления идеи и до текущего состояния бота, настало время показать его. Имя ему – Стикольщик (да, потому что он шлёт стикеры).

Бот живёт в множестве чатов, анализирует, как люди отвечают стикерами или GIF'ками на сообщения и перенимает соответствующие паттерны общения. Своего рода коллективное бессознательное.
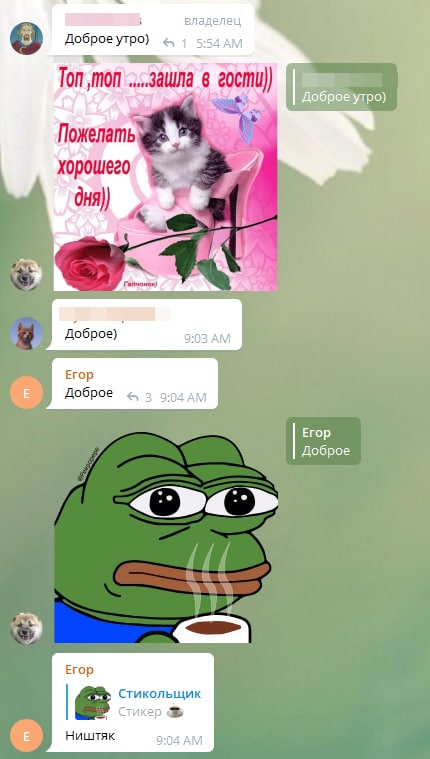
Примеры переписок с участием бота:


Для регулирования говорливости бота доступна команда /chance. Например, чтобы установить вероятность ответа 10% нужно написать в чате с ботом:
/chance 10 - в личных сообщениях;
/chance@StickerStickyBot 10 - в групповых чатах.
/ban – в ответ на неугодный стикер (отправляет его на модерацию)
Также есть возможность выбирать стикеры и гифки в инлайн-режиме. Бота можно вызывать в любом(!) чате, написав его имя @StickerStickyBot с указанием текста, выбрать стикер или гифку и отправить.
Стек разработки - asp.net core, c#, библиотека для работы с bot API - Telegram.Bot.
Хостинг - виртуальная машина в облаке Hetzner. Одно из лучших предложений, что нашёл по хостингам. Плюс по реферальной ссылке получилось 2 месяца бесплатно.
Ссылка на бота
Так же был создан сайт, на котором собраны все увиденные ботом стикеры. Но его описание выходит за рамки статьи. Единственное, скажу, что там собралось уже больше 18 тысяч наборов стикеров.
Спасибо за внимание. С удовольствием почитаю комментарии, особенно предложения по работе с ML или другие идеи по улучшению алгоритма адекватного ответа.




