Привет Хабр! По основной профессии я инженер по разработке нефтяных и газовых месторождений. Я только погружаюсь в Data Sciense и это мой первый пост, в котором хотел бы поделиться опытом применения машинного обучения в нефтяной сфере.

Предсказание добычи скважинами нефти и газа является одним из самых важных в нефтяной и газовой промышленности. Без обоснованного прогноза добычи невозможно принимать решения о рентабельности проектов, капитальных вложениях, бурении новых и операционном планировании эксплуатации существующих скважин.
В данной статье я хочу поделиться опытом создания модели машинного обучения применительно к нефтегазовой сфере. Цель построения модели была предсказать один из параметров работы скважин и проверить способность модели предсказать обводнённость существующих скважин и скважин, которые планируется пробурить (кандидаты на бурение).
Данные по добыче фактически являются временными рядами, что предполагает построение более сложной модели. С целью упрощения и ускорения было принято решение строить модель на конкретно выбранную дату.
Обзор: как прогнозируют добычу нефти и газа
В настоящий момент кроме классического аналитического способа оценки (эксель + метод матбаланса) общепринятым является построение геологической (статической) и гидродинамической (динамической) моделей, на основе которой принимаются решения.
Геологическая модель строится на основе скважинных данных (обычно с использованием сейсмики). В начале строится трехмерная сетка (каркас) продуктивных пластов. Далее каждой ячейке сетки присваивают такие свойства породы как пористость, проницаемость, водо- нефте- газонасыщенности, давление и прочие.
После этого на основе статической модели рассчитывается динамическая модель, которая отличается от геологической тем, что она рассчитывает как вышеуказанные параметры ячеек меняются во времени в зависимости от того сколько добывают скважины и наоборот. Динамическая модель помогает ответить на вопрос где бурить новые скважины и сколько возможно добыть нефти.
Гидродинамическая модель в 3D представлена на самой первой картинке (выше).
Недостаток подхода с построением полноценной гидродинамической модели в том, что на постройку модели нужно очень много времени (от нескольких месяцев до года и даже больше). Это зависит от количества скважин и имеющихся данных по месторождению. Более того, построенная гидродинамическая модель является сложной системой с высокой чувствительностью к входным данным. Поэтому любая некорректность в данных может привести к неверным результатам. Это не удивительно. Протяжённость месторождений достигает десятков километров. А типичный диаметр скважин находиться в пределах 10 - 15 см. Скважины в свою очередь, пробурены на глубины порядка 3-х километров и на расстояниях 250 - 1000 метров друг от друга. Таким образом, модель строится по крайне ограниченном данным, которые можно охарактеризовать как "точечные уколы".
Обычно скважину представляют себе как дырку в земле. Это не совсем так. Классическое определение скважины звучит так. Скважина - это цилиндрическая горная выработка, длинной многократно превышающей её диаметр. Типично - это 3-х километровое (бывает конечно и больше, бывает и меньше) отверстие в которую спущены несколько вложенных друг в друга колонн обсадных труб (для предотвращения обвалов). Пространство между колоннами обсадных труб и горной породой для герметичности цементируется. На поверхности устанавливается фонтанная арматура, которая герметизирует скважину от окружающей среды.
Скважины бурят не только для добычи нефти и газа. Через скважины получают подавляющее большинство данных о недрах.
Скважинные данные включают в себя:
данные полученные при спуске приборов в скважину (например давление, температура, глубина нефте/газо-насыщенного пласта, кажущееся сопротивление породы, радиоактивность и прочие..),
замеряемые на поверхности - количество добываемых нефти, газа и попутной воды, их состав.
По типу основного добываемого флюида скважины можно разделить на нефтяные и газовые. В данной статье рассматриваются нефтяные скважины. Это значит, что на поверхности мы получаем нефть с растворённым в ней газом и попутную воду. Как правило в начале эксплуатации скважин добывается чистая нефть, но позже скважина обводняется и доля воды увеличивается. Когда доля воды увеличивается, а доля нефти уменьшается до определённого предела - скважина перестаёт быть рентабельной и её останавливают. Обводнённость выражают в процентах и рассчитывают как отношение количества добытой воды к добытой жидкости т.е. Qнефти/(Qнефти + Qводы)*100%
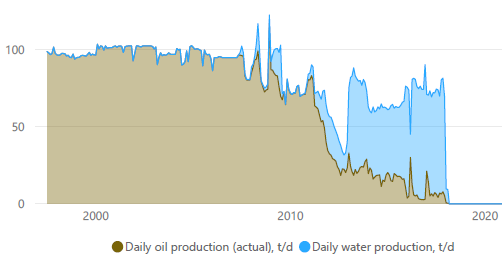
Типичный профиль добычи нефти во времени (в данном случае по годам) выглядит вот так:
Построение модели
Входными данными для обучения модели были выбраны следующие параметры скважин:
Cum oil: накопленная добыча нефти
Days: количество дней работы скважины (до момента обводнения (и её остановки по нерентабельности) или до текущего момента в случае если скважина в работе).
In prod: скважина в работе/остановлена по обводнению
Q oil: текущий дебит нефти
wct: текущая обводнённость
Top perf: глубина верха интервала перфорации - глубина верха и низа
Bottom perf: глубина низа интервала перфорации
ST: 0 - основной ствол скважины, 1 - боковой ствол
x, y: координаты скважины
Импортируем необходимые библиотеки
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
import pylab
from pylab import rcParams
import plotly.express as px
import plotly.graph_objects as go
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import r2_score as r2, mean_absolute_error as mae, mean_squared_error as mse, accuracy_score
from sklearn.metrics.pairwise import euclidean_distancesЗагружаем исходные данные на определённую дату из экселя и визуализируем датафрейм.
data_path = 'art_df.xlsx'
df = pd.read_excel(data_path, sheet_name='artificial')
df
Проверяем местоположение скважин - строим карту местоположений скважин. В данном случае это карта забоев (нижних точек окончаний скважин).
ax = df.plot(kind='scatter', x='x', y='y')
df[['x','y','Well']].apply(lambda row: ax.text(*row),axis=1);
rcParams['figure.figsize'] = [11, 8]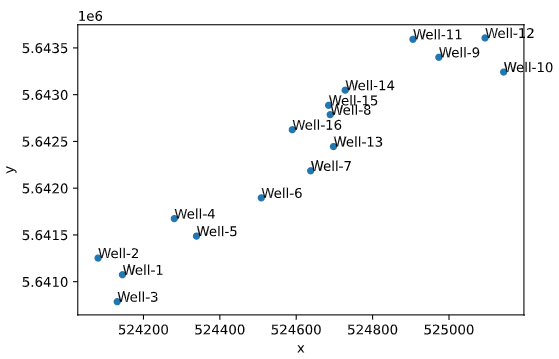
В процессе построения модели было выявлено, что загрузка координат скважин в модель "как есть" работает неплохо. Но значительное улучшение качества модели происходит если трансформировать координаты в матрицу расстояний между скважинами. Таким образом мы даём возможность алгоритму сразу распознать, что ближайшие скважины имеют больший вес, чем удалённые.
Конструирование признаков
Рассчитываем матрицу евклидовых расстояний между скважинами из их координат.
distance = pd.DataFrame(euclidean_distances(df[['x', 'y']]))
distance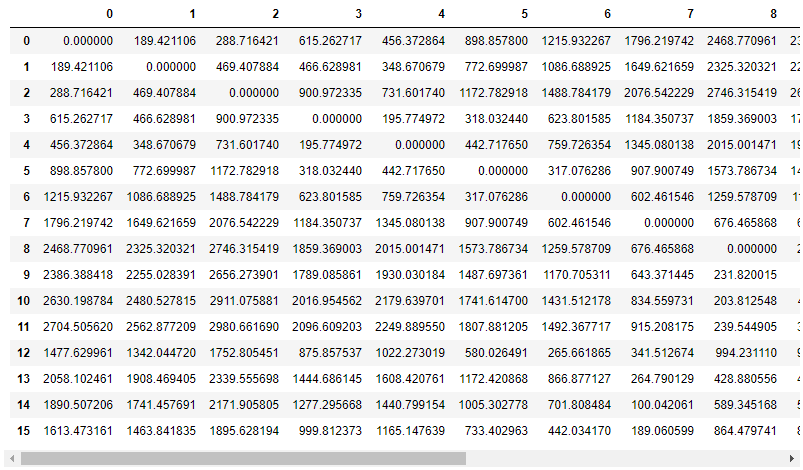
Извлекаем список имён скважин. Присваиваем имена скважин колонкам матрицы расстояний.
well_names = df['Well']
distance.columns = well_namesОбъединяем датасет параметров работы скважин с матрицей расстояний между скважинами. Таким образом в датасет добавляем новый признак - удалённость, который является весом скважин друг на друга.
df_distance = pd.concat([df.drop(['x', 'y'], axis=1), distance], axis=1)
df_distance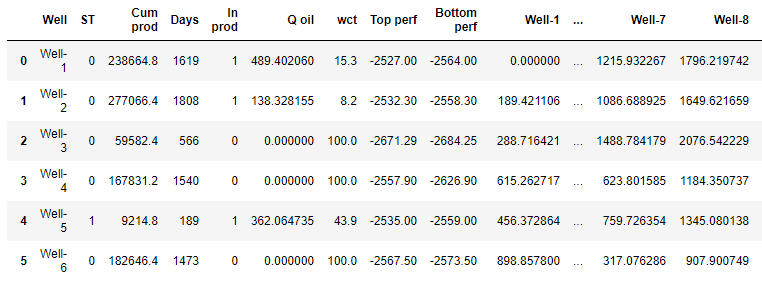
Проверка модели
Ввиду малого количества данных протестируем модель методом слепого тестирования. Создаём тренировочный дата сет, удаляя из него скважины, выбранные для теста и прогноза
df_train_1 = df_distance.drop([12, 13, 14, 15], axis=0)
df_train_1
Создаём тестовый датасет
df_test_1 = df_distance.loc[[12, 13]]
df_test_1
Создаём тренировочный DataFrame признаков X_1. Удаляем категорийный признак (имя скважины) и предсказываемое значение wct.
x_1 = df_train_1.drop(['Well', 'wct'], axis=1)
x_1
Создаём тренировочный вектор целевых значений y_1
y_1 = df_train_1['wct']Создаём тестовый вектор целевых значений y_test_1
y_test_1 = df_test_1['wct']В качестве алгоритма был выбран обычный Random Forest Reggressor, как наиболее универсальный алгоритм, подходящий для большинства типов данных.
x_test_1 = df_test_1.drop(['Well', 'wct'], axis=1)
model = RandomForestRegressor(random_state=42, max_depth=14)
model.fit(x_1, y_1)
y_pred_train_1 = model.predict(x_1)
y_pred_1 = model.predict(x_test_1)
print('Predicted values from train data:')
r2_train = r2(y_1, y_pred_train_1)
mae_train = mae(y_1, y_pred_train_1)
mse_train = mse(y_1, y_pred_train_1)
print(f'R2 train: {r2_train.round(4)}')
print(f'MAE train: {mae_train.round(4)}')
print(f'MSE train: {mse_train.round(4)}')
print('Predicted values from test data:')
r2_test = r2(y_test_1, y_pred_1)
mae_test = mae(y_test_1, y_pred_1)
mse_test = mse(y_test_1, y_pred_1)
print(f'R2 test: {r2_test.round(4)}')
print(f'MAE test: {mae_test.round(4)}')
print(f'MSE test: {mse_test.round(4)}')
modelPredicted values from train data:
R2 train: 0.8832
MAE train: 8.2855
MSE train: 131.1208
Predicted values from test data:
R2 test: 0.8758
MAE test: 3.164
MSE test: 11.4485
RandomForestRegressor(max_depth=14, random_state=42)R2 метрика на тренировочной метрике превышает R2 на тестовой 1%. Это означает, что модель отлично обучилась.
Сравним предсказанную обводнённость с фактической на тестовой выборке, которая не использовалась при обучении модели (blind test)
df_y_test = pd.DataFrame({'Well': df_test_1['Well'],
'wct predicted, %': y_pred_1.round(1),
'wct actual, %': y_test_1.round(1),
'difference': (y_pred_1 - y_test_1).round(1)})
df_y_test
Сравним предсказанную обводнённость с фактической на тренировочной выборке
df_y_train = pd.DataFrame({'Well': df_train_1['Well'],
'wct predicted, %': y_pred_train_1.round(1),
'wct actual, %': y_1.round(1),
'difference': (y_pred_train_1 - y_1).round(1)})
df_y_train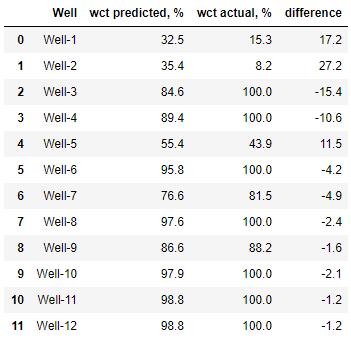
Вычислим среднее отклонение обводнённости:
round(sum(abs(y_pred_train_1 - y_1)) / len(y_1), 1)8.3
Видим, что среднее отклонение по обводнённости составляет 8%, что является приемлемым результатом.
Создание модели на всех доступных данных
Создаём тренировочный дата сет, удаляя из него скважины, выбранные для прогноза
df_train_2 = df_distance.drop([14, 15], axis=0)Создаём датасет для прогнозирования из скважин, удалённых на предыдущем шаге.
Предсказываемый параметр WCT (обводнённость) сейчас = NaN.
df_fc = df_distance.loc[[14, 15]]Создаём тренировочный DataFrame признаков x_2. Удаляем категорийный признак (имя скважины) и предсказываемое значение wct.
x_2 = df_train_2.drop(['Well', 'wct'], axis=1)Создаём тренировочный вектор целевых значений y_2 и обучаем модель.
y_2 = df_train_2['wct']
x_fc = df_fc.drop(['Well', 'wct'], axis=1)
model = RandomForestRegressor(random_state=42, max_depth=14)
model.fit(x_2, y_2)
y_pred_train_2 = model.predict(x_2)
y_fc = model.predict(x_fc)
print('Predicted values from train data:')
r2_train = r2(y_2, y_pred_train_2)
mae_train = mae(y_2, y_pred_train_2)
mse_train = mse(y_2, y_pred_train_2)
print(f'R2 train: {r2_train.round(4)}')
print(f'MAE train: {mae_train.round(4)}')
print(f'MSE train: {mse_train.round(4)}')
print('Forecasted values could be compared with real data!')
modelPredicted values from train data:
R2 train: 0.9095
MAE train: 6.5196
MSE train: 89.9625
RandomForestRegressor(max_depth=14, random_state=42)R2 повысилось. Или модель переобучилась или большее количество данных помогло точнее настроить модель
Сравним предсказанную обводнённость с фактической на тренировочной выборке.
df_y_train = pd.DataFrame({'Well': df_train_2['Well'],
'wct predicted, %': y_pred_train_2.round(1),
'wct actual, %': y_2.round(1),
'difference': (y_pred_train_2 - y_2).round(1)})
df_y_train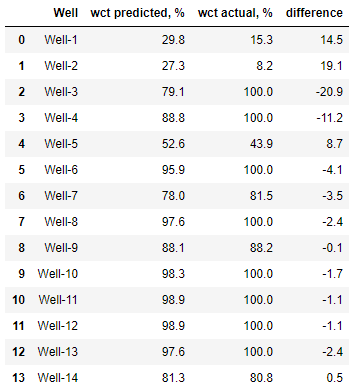
round(sum(abs(y_pred_train_2 - y_2)) / len(y_2), 1)6,5
Величина средней ошибки обводнённости снизилась до 6,5. Отлично!
Предсказываем обводнённость по боковым стволам:
df_y_test = pd.DataFrame({'Well': df_test_1['Well'],
'wct predicted, %': y_pred_1.round(1),
'wct actual, %': y_test_1.round(1),
'difference': (y_pred_1 - y_test_1).round(1)})
df_y_test
Выводим список признаков в порядке убывания их важности и строим диаграмму важности признаков.
model.feature_importances_
feature_importances = pd.DataFrame()
feature_importances['feature_name'] = x_2.columns.tolist()
feature_importances['importance'] = model.feature_importances_
feature_importances = feature_importances.sort_values(by='importance', ascending=False)
feature_importancesfig = px.bar(feature_importances,
x=feature_importances['importance'],
y=feature_importances['feature_name'],
title="Feature importances")
fig.update_layout(yaxis={'categoryorder':'total ascending'})
fig.show()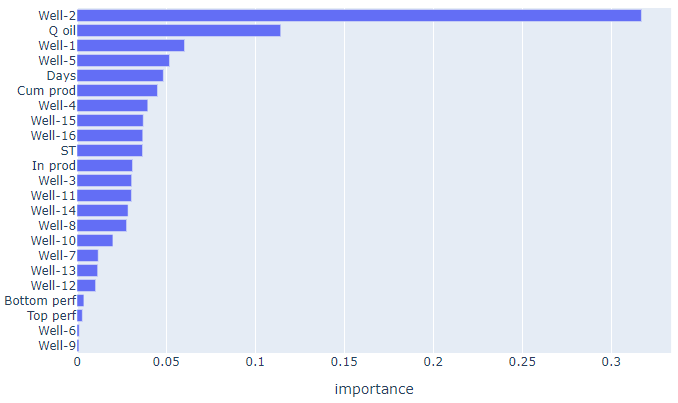
Видим, что наиболее важный признак - это расстояние до 2-й скважины. Возможно стоит проанализировать признаки дополнительно и исключить какие то из них из обучения.
Сравнительный график реальных и предсказанных значений. Чем дальше скважина от красной линии - тем хуже она предсказана.
fig = px.scatter(x=y_pred_train_2, y=y_2, title="True vs Predicted values",
text=df_train_2['Well'], width=850, height=800)
fig.add_trace(go.Scatter(x=[0,100], y=[0,100], mode='lines', name='True=Predicted',
line = dict(color='red', width=1, dash='dash')))
fig.update_xaxes(title_text='Predicted')
fig.update_yaxes(title_text='True')
fig.show()
Вывод
Предсказание параметров работы скважин возможно различными методами. Одни из них являются очень сложными и трудозатратными (геолого- гидродинамические модели), другие простыми и быстрыми (матбаланс, кривые падения добычи).
Данный пример построения модели и сравнение прогноза с реальными данными позволяет сделать вывод, что даже очень простая модель "без наворотов" хорошо предсказывает параметры работы скважин. Это означает, что что в копилку инженера по разработке месторождений нефти и газа добавляется ещё один метод выполнения рабочих задач, который к тому же позволяет решить поставленную задачу в весьма сжатые сроки.
Примечания
Данная модель имеет важное ограничение. У любого месторождения существует контур нефтеносности - та область за пределами которой пробуренная скважина будет "сухой" - там нет нефти.

Данная модель слабо чувствительна к местоположению. Модель "не знает", что за пределами определённой зоны нефти нет. Для решения этой проблемы можно найти и загрузить данные по "сухим" скважинам которые были пробурены по окружению и не нашли нефть. Также можно создать искусственные данные на контуре нефтеносности с нулевыми дебитами по нефти. В данном примере, я не применял ни одни из способов дабы не усложнять модель.
Цель исследования была в том, чтобы оценить применимость методов машинного обучения в этой области. Задача выбрать наилучший алгоритм не ставилась, поэтому сравнения разных алгоритмов не проводилось.
Скважинные данные не являются открытыми данными, а являются собственностью компании, владеющей лицензией на разработку месторождения. Поэтому для иллюстрации выполнной работы были сгенерированы искусственные скважинные данные, которые доступны для данной работы.
Исходный код вместе с текстом статьи доступен здесь: https://github.com/alex-kalinichenko/re/tree/master/wct_fc



