
В этой статье будут рассмотрены 3 практических вопроса, с которыми я столкнулся при разработке приложения.
- Как работать с Video и Audio с максимальной точностью.
- Как оптимально обрабатывать данные с такой скоростью.
- Как оптимально обрабатывать данные, приходящие по websocket.
Перед рассмотрением каждого вопроса, хочу дать есть немного контекста.
Приложение позволяет загружать аудио и видео файлы, для последующего редактирования.
Для каждого типа файла, мы можем вырезать какой-то интервал, чтоб он не проигрывался вообще, либо замьютить (выключить звук) на каком-то выбранном интервале. Например для того, чтоб удалить или скрыть конфиденциальную информацию.
Также для видео есть дополнительная возможность, закрашивать объекты поверх видео, запускать аналитику на бэкенде, по трекингу объектов и дальнейшее закрашивание в плеере.
Перейдем к вопросам и решениям.
1) Как работать с Video и Audio с максимальной точностью
Задача: как нам обрабатывать вырезанные или замьюченные интервалы во время проигрывания с задержкой, которая будет меньше 250ms?
Проблема этой задачи состоит в том, что если мы будем использовать подписку на событие timeupdate, то точность у нас будет не более 250ms (это нам гарантирует документация), но минимальную нам никто не гарантирует, она зависит от загруженности системы. Такой вариант нам не подходит.
Так как же нам достичь максимальной точности?
Посмотрим на метод window.requestAnimationFrame(). Чем он нам может помочь?
В документации говорится:
«Вы должны вызывать этот метод всякий раз, когда готовы обновить анимацию на экране, чтоб запросить планирование анимации. Обычно запросы происходят 60 раз в секунду, но чаще всего совпадают с частотой обновления экрана.»
Таким образом, 60 раз в секунду это 1сек / 60 = 16.6мс.
И это то, что нам нужно!
Алгоритм действий будет следующий:
- Когда мы нажимаем кнопку проиграть, мы запускаем вызов window.requestAnimationFrame с callback-ом и сохраняем id для последующей остановки.
- На каждом вызове мы считываем текущую информацию о времени у Video или Audio и производим необходимые действия (в нашем случае проверяем вырезан или замьючен интервал, если да, то пропускаем его или убираем звук)
- Вызываем опять метод window.requestAnimationFrame с нашим callback-ом
- При нажатии паузы либо ухода со страницы, отменяем вызов используя id, который мы сохраняли.
handleTimeChangeByFrame = () => {
if (this.isStopped() || this.isDestroyed) {
this.stopTimeUpdateLoop();
return;
}
const { currentTime } = this.audio;
this.props.setCurrentTimeAudio(Math.floor(currentTime * 10) / 10);
this.timeUpdateRAFId = window.requestAnimationFrame(this.handleTimeChangeByFrame);
};
stopTimeUpdateLoop() {
window.cancelAnimationFrame(this.timeUpdateRAFId);
}
Разница более чем заметна!
2) Как оптимально обрабатывать данные с такой скоростью
Теперь мы знаем, как максимально эффективно работать с аудио и видео, но что, если нам нужно еще обрабатывать данные с такой скоростью?
Задача: необходимо на каждом фрэйме видео закрашивать объекты по координатам, координаты для каждого фрэйма нам приходят с бэкенда, объектов на фрэйме может быть большое количество.
Сразу видим, что обычным тегом video мы не отделаемся. Для этого можно использовать canvas и подключить его к тегу видео. Теперь наше видео будет отрисовывать на канвасе каждый фрейм.
Хорошо, с первой частью разобрались.
Теперь нужно понять, каким образом нам лучше хранить данные и в какой момент запрашивать.
Решение такое, мы загружаем данные для первых 600 фреймов от точки старта (это около 20 секунд видео), когда видео играет, мы начинаем запрашивать новую порцию из 600 фреймов в момент, когда до конца всех загруженных остается 100-200 фреймов (число выверенное опытным путем, тут все зависит от скорости бэкенда, если он не достаточно шустрый, можно и пораньше это делать и с другим количеством). Но не забываем очищать данные, которые нам уже не надо, бережем память:)
Как сохранять данные, чтоб поиск для каждого фрейма был оптимальным?
Мы можем хранить данные просто массивом, объектом или hash таблицей (Map).
Если мы попробуем хранить массивом, то в худшем случае, если у нас много объектов, то нам будет необходимо перебрать все элементы массива, что достаточно нагружает систему и FPS падает до 3-4.
Временная сложность: O(N)
Остается попробовать использовать объект или hash таблицу.
Изначально наши данные хранились объектом, key = objectId, value массив объектов с данными, на каких фреймах находится этот объект.
objectId: [
{
frameId,
x,
y,
width,
height,
},
{
frameId,
x,
y,
width,
height,
}
]В этом случае, чтоб нам найти все объекты на каждом фрэйме, нам опять же было необходимо итерировать в худшем случае по всем ключам и искать, содержится ли данный объект на данном фрэйме.
Временная сложность: O(NM)
Так нам точно не пойдет!
Hash таблица (Map) имеет основное преимущество для нас в том, что может иметь более высокую производительность в случаях частого добавления или удаления ключей.
Так как мы оперируем фреймами и у нас объекты для закрашивания для каждого фрейма, то попробуем хранить в виде key наш frameId, value будет массив (linked list), содержащий данные объектов с координатами.
frameId: [
{
objectId,
x,
y,
width,
height,
},
{
objectId,
x,
y,
width,
height,
}
]Таким образом, чтоб нам найти элементы для текущего фрейма, мы за константное время обратимся по frameId и достанем массив элементов, который и отрисуем. FPS в таком случае держится от 30-60.
Временная сложность: O(1)
Вроде очевидное решение, но как показывает практика — не всегда очевидно.
3) Как оптимально обрабатывать данные, приходящие по websocket
Задача: у нас есть объект на фрейме (либо несколько объектов), ниже, на таймлайне у нас отображаются интервалы, на каких фреймах содержатся объекты.
Цифры — это номера фреймов.
Зеленым закрашены интервалы, где у нас есть объекты.
Оранжевым, текущая позиция (60-й фрейм)
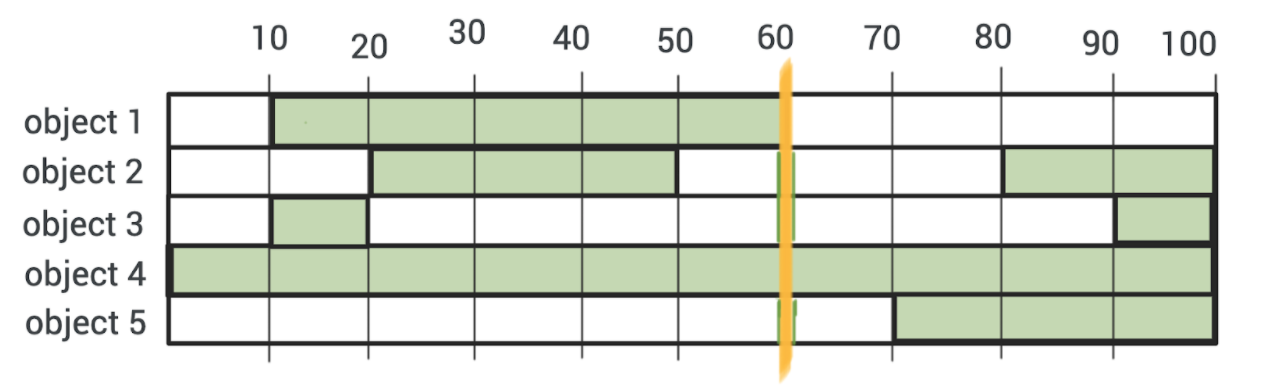
В данном примере интервалы выглядят как:
object 1: [
[10, 60],
],
object 2: [
[20, 50],
[80, 100],
],
...После запуска трекинга объекты будут искаться в разные стороны, относительно выбранного фрейма до существующего интервала (либо начала / конца видео).
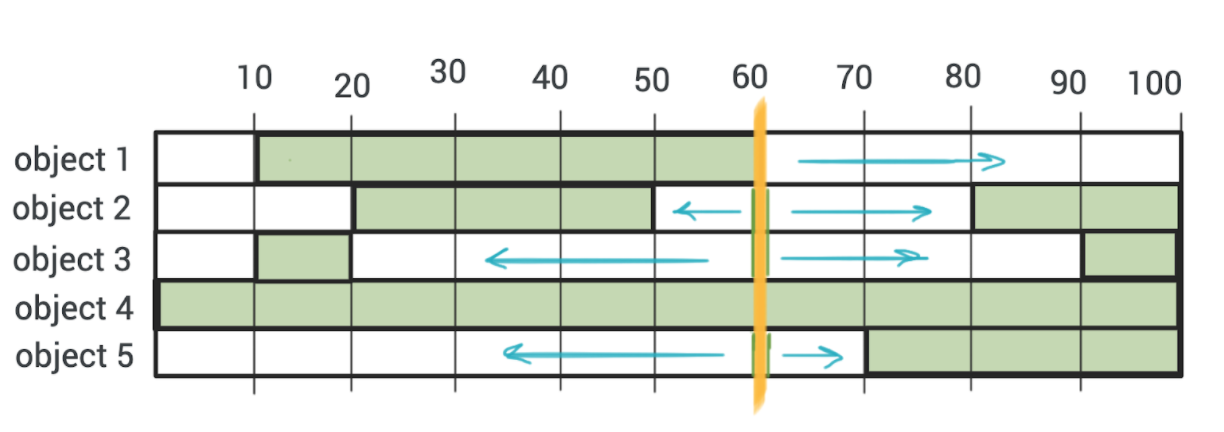
В результате этого трекинга объектов, по вебсокетам нам приходили координаты объектов для каждого фрейма, один месседж = один фрейм. Нам надо было расширять эти интервалы для каждого объекта, если они становились рядом — мержить и затем отображать пользователю в реальном времени.
Такое частое вызывание функции обновления интервалов и последующего рендера их ложило страницу просто до 0 FPS и видео не могло даже проиграться.
Выход был такой, что каждый мессадж вебсокета должен отдавать батч фреймов, т.е для одного объекта был массив координат с N-го фрейма по N + 30, таким образом мы сократили частоту вызова функции обновления интервала и рендера в 30 раз и мы знали, что у нас новый интервал это от [N, N + 30] и мы могли для каждого объекта обновить (смержить интервалы).
Это помогло разгрузить страницу до 15-20 FPS.
Функция обновления интервала и мержинга была написана кастомно. Но в один прекрасный день, решая задачи на литкоде в контексте попалась такая задачка (Merge Intervals) и она один в один совпадала с текущей задаче. Изучив алгоритмы ее решения и применив, удалось поднять FPS еще на 5 — 10.
Кастомное решение имело временную сложность: O(N^2)
Правильный алгоритм: O(NlogN)
Заключение
Такие оптимизации позволили довести наш редактор до приемлемой скорости работы и предоставить конечному пользователю не замечать нюансов и нагрузки системы, а видеть, как все идет как по маслу.
Обращайте внимание на то, как вы храните данные, отталкиваясь от задачи, правильная структура данных и алгоритм дает значительный прирост производительности.


: высокая производительность и нативное партиционирование")

