
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Я работаю тестировщиком на проекте, суть которого состоит в сборе и хранении различных данных и формировании на их основе разных отчетов и файлов-выгрузок. При формировании таких отчетов учитывается большое количество условий для отбора данных и поэтому при тестировании приходится много работать с SQL-запросами в БД. Но для проверки правильности отбора данных и поиска лишних/пропавших данных этого зачастую не хваетает, поэтому пришлось искать дополнительные инструменты для этого.
Поскольку у меня были уже какие-то базовые знания python, я решила попробовать написать небольшие скрипты, которые позволяли бы что-то делать с имеющимися данными и тем самым облегчать и ускорять процесс тестирования. В этой статье я расскажу, что из этого вышло.
Чтобы написать скрипт, нужно разобраться, что именно должен делать скрипт, какие данные нужно подать на вход и какие данные ожидаются на выходе.
Примерные шаги для сценария:
Затем нужно подумать о том, как и где можно получить входные данные. Это может быть вручную созданный файл с данными, выгрузка на UI данных в файл с учетом фильтров, файл с данными парсинга с помощью другого скрипта, файл выгрузки результатов SQL-запроса в БД (из БД можно быстро выгрузить данные в csv-файл), json-файл или xml-файл с данными из ответа на запрос к API и др.
Для написания скриптов на python нужно установить интерпретатор и подходящую IDE. Также лучше всего создать отдельную виртуальную среду под этот проект.
Для скриптов я использую разные библиотеки, какие-то из них являются встроенными библиотеками python, какие-то нужно устанавливать дополнительно:
Простейший каркас скрипта для работы с данными из файлов формата csv, json, Excel выглядит следующим образом:
В этом скрипте данные из файла нужного формата загружаются в дата-фрейм, отбираются нужные данные и над ними выполняются какие-то операции, затем данные записываются в новый Excel-файл.
Если нужно работать с данными, полученными в результате SQL-запроса к БД, то можно не экспортировать их в csv-файл, а сразу получать их в дата-фрейм, выполняя SQL-запрос в БД в самом скрипте:
Если же нужно получить данные из xml-файла, то можно воспользоваться предназначенными для этого библиотеками. Я использую встроенную библиотеку ElementTree.
Когда данные получены в дата-фрейм, то их можно сразу объединить с данными из другого дата-фрейма (аналоги join или union в SQL) или выполнить над ними какие-то операции, например, удалить дубли, убрать строки с пустыми значениями в определенных ячейках, сравнить данные в нескольких столбцах, отобрать нужные строки/столбцы и т.д. Подробнее можно почитать в документации для pandas.
А теперь включаем главный инструмент тестировщика и выделяем данные/фичи на своем проекте, для проверки которых пригодились бы подобные скрипты.
Для сценариев созданы файлы с небольшим количеством тестовых данных, сгенерированных с помощью generatedata. В реальности файлы с данными содержат десятки тысяч строк и большое количество столбцов.
Сценарий №1
Есть три файла в формате csv с данными. Для каждой строки с данными есть поле с уникальным идентификатором id. Данные из этих файлов отбираются с учетом определенных условий и заносятся в таблицу в БД, затем эти данные выводятся в отчете в виде таблицы на UI. Есть возможность выгрузки данных на UI в Excel-файл.
Предположим, что условия выбора данных для отчета из файлов-исходников следующие:
Задача тестировщика: Проверить, что строки с нужными объектами корректно отобраны из файлов-исходников и все эти объекты выводятся в отчете на UI.
Составляем сценарий для скрипта:
В итоговом файле данные будут содержать только один столбец с идентификатором id, если названия у столбцов в разных дата-фреймах совпадали, и может быть не понятно, какие столбцы/строки из какого были файла. Поэтому я либо называю столбцы с уникальным идентификатором разными названиями в файлах, либо в каждый файл добавляю отдельный столбец «Строки из файла такого-то» и в нем проставляю значения «Да» — потом при анализе итогового Excel-файла удобно делать фильтрацию по этому столбцу, т.к. они всегда содержат значение и, фильтруя по ним, можно уже понять, какие данные расходятся в соответствующих столбцах.
Пример данных из файла example1_csv_1.csv:
Пример данных из файла report_UI.xlsx:
Скрипт на python выглядит следующим образом:
Ограничения:
Сценарий №2
В разделе есть данные в виде таблицы по определенным объектам из одного источника. Система будет получать данные из второго источника (интеграция) и обновлять этими данными существующие данные таблицы. Каждая запись в таблице – это данные по одному объекту, который имеет уникальный идентификатор. Если из нового источника данные объекта по идентификатору совпадают с данными уже существующего объекта – то все поля существующей записи обновляются данными из нового источника (подтверждаются). Если же в таблице еще нет объекта с идентификатором из второго источника – то в таблице создается новая запись с данными из нового источника. Данные из второй системы можно выгрузить заранее в json-файл.
Задача тестировщика: Заранее подготовить файл с данными для теста, чтобы после реализации доработки проверить, что существующие записи корректно обновляются и им проставляется признак подтверждения в БД, если было совпадение по идентификатору, и корректно создаются новые записи и им проставляется признак добавления в БД, если записи с таким идентификатором еще не было.
Составляем сценарий для скрипта:
Ограничения:
Сценарий №3
Выполняется запрос к API системы, в ответе на который приходят данные по объектам в формате json.
Задача тестировщика: Сравнить данные из ответа на запрос к API с данными из результата SQL-запроса в БД.
Составляем сценарий для скрипта:
Пример данных из файла example3_csv.csv:
Пример данных из файла example3_json.json:
Скрипт на python выглядит следующим образом:
Ограничения:
Если ответ на запрос к API приходит в xml формате, то нужно будет сначала распарсить нужные данные из xml-файла с помощью ElementTree или другой библиотеки и затем уже загружать их в дата-фрейм.
Сценарий №4
На UI выгружается xml-файл с данными по объектам, который формируется на лету из данных в БД с учетом определенных условий (например, учитываются статусы, даты, года или другие значения параметров для объектов).
Задача тестировщика: Сравнить уникальные идентификаторы id объектов из xml-файла, которые находятся в атрибуте тега company, с идентификаторами объектов из результата SQL-запроса в БД.
Составляем сценарий для скрипта:
Пример данных из файла example4_csv.csv:
Пример данных из файла example4_xml.xml:
Скрипт на python выглядит следующим образом:
Сценарий №5
На UI в разделе выводятся данные по объектам в виде таблицы. Есть возможность выгрузки данных в Excel-файл.
Задача тестировщика: Cравнить данные из таблицы раздела с данными, которые выгружаются в Excel-файл.
Составляем сценарий для скрипта:
Ограничения:
Также аналогичные скрипты можно использовать и просто для того, чтобы данные из json-файлов или csv-файлов переносить в Excel-файлы. Либо можно объединять данные из нескольких Excel-файлов по определенным столбцам и выгружать их в один новый Excel-файл.
Это всего лишь несколько примеров того, как можно использовать python+pandas для ускорения процесса тестирования и поиска багов. На самом деле у pandas намного больше возможностей для работы с данными, почитать об этом более подробно можно в документации к этой библиотеке.
Возможно на вашем проекте есть другие варианты для применения подобных скриптов и эта статья поможет начать их использовать в работе тестировщиков.
Поскольку у меня были уже какие-то базовые знания python, я решила попробовать написать небольшие скрипты, которые позволяли бы что-то делать с имеющимися данными и тем самым облегчать и ускорять процесс тестирования. В этой статье я расскажу, что из этого вышло.
Проектируем сценарий скрипта
Чтобы написать скрипт, нужно разобраться, что именно должен делать скрипт, какие данные нужно подать на вход и какие данные ожидаются на выходе.
Примерные шаги для сценария:
- Получаем файл с данными в таком-то формате (или несколько файлов)
- Получаем данные из файла/файлов
- Отбираем нужные данные
- Выполняем какие-то операции над данными
- Выгружаем данные в Excel-файл, если нужно (обычно такой формат самый удобный для дальнейшего анализа и хранения)
Затем нужно подумать о том, как и где можно получить входные данные. Это может быть вручную созданный файл с данными, выгрузка на UI данных в файл с учетом фильтров, файл с данными парсинга с помощью другого скрипта, файл выгрузки результатов SQL-запроса в БД (из БД можно быстро выгрузить данные в csv-файл), json-файл или xml-файл с данными из ответа на запрос к API и др.
Пишем скрипты на python с использованием pandas и других библиотек
Для написания скриптов на python нужно установить интерпретатор и подходящую IDE. Также лучше всего создать отдельную виртуальную среду под этот проект.
Для скриптов я использую разные библиотеки, какие-то из них являются встроенными библиотеками python, какие-то нужно устанавливать дополнительно:
- pandas — библиотека для анализа данных. Она позволяет работать с данными из файлов разных форматов, а также получать данные сразу из БД с помощью SQL-запроса. Данные из файлов загружаются в дата-фреймы (визуально — те же таблицы, что и в Excel), с данными в которых уже можно выполнять разные операции: объединять данные из разных дата-фреймов по аналогии с join/union в SQL, выбирать нужные данные по определенным условиям, сравнивать данные в разных столбцах дата-фрейма и т.д.
- openpyxl, xlrd — библиотеки для работы с Excel.
Простейший каркас скрипта для работы с данными из файлов формата csv, json, Excel выглядит следующим образом:
# Подключаем библиотеку pandas
import pandas as pd
# Загружаем данные из csv-файла в дата-фрейм
# (предварительно копируем файл с данными в папку со скриптом)
# При экспорте данных из БД в csv-файл лучше всего использовать разделитель ";"
df = pd.read_csv('./csv_file.csv', sep=';', encoding='utf-8')
# или
# Загружаем данные из json-файла в дата-фрейм
# (предварительно копируем файл с данными в папку со скриптом)
# df = pd.read_json('./json_file.json', encoding='utf-8')
# или
# Загружаем данные из Excel-файла в дата-фрейм, указав название листа в файле
# (предварительно копируем файл с данными в папку со скриптом)
# file_excel = 'Excel_file.xlsx'
# df = pd.ExcelFile(file_excel).parse('Лист1')
# Выполняем какие-то операции с данными в дата-фрейме и
# загружаем их в дата-фрейм final_df
# Выгружаем данные в Excel-файл, если нужно
# при этом указываем название для нового файла и название листа
# (файл будет создан в папке со скриптом)
writer = pd.ExcelWriter('Итог.xlsx')
final_df.to_excel(writer, 'Лист1')
writer.save()
В этом скрипте данные из файла нужного формата загружаются в дата-фрейм, отбираются нужные данные и над ними выполняются какие-то операции, затем данные записываются в новый Excel-файл.
Если нужно работать с данными, полученными в результате SQL-запроса к БД, то можно не экспортировать их в csv-файл, а сразу получать их в дата-фрейм, выполняя SQL-запрос в БД в самом скрипте:
# Подключаем библиотеку pandas
import pandas as pd
# Подключаем библиотеку для работы с БД, например для работы с PostgreSQL
# (если БД другая - ищем другую подходящую библиотеку)
import psycopg2
# Создаем подключение к БД
conn = psycopg2.connect(dbname='название_БД', host='хост', port='порт',
user='пользователь', password='пароль')
# Указываем нужный SQL-запрос
q = """select ...
from ...
where ..."""
# Загружаем данные в дата-фрейм, выполнив SQL-запрос
df = pd.read_sql_query(q, conn)
# Выполняем какие-то операции с данными в дата-фрейме и
# загружаем их в дата-фрейм final_df
# Выгружаем данные в Excel-файл, если нужно
# при этом указываем название для нового файла и название листа
# (файл будет создан в папке со скриптом)
writer = pd.ExcelWriter('Итог.xlsx')
final_df.to_excel(writer, 'Лист1')
writer.save()
Если же нужно получить данные из xml-файла, то можно воспользоваться предназначенными для этого библиотеками. Я использую встроенную библиотеку ElementTree.
Когда данные получены в дата-фрейм, то их можно сразу объединить с данными из другого дата-фрейма (аналоги join или union в SQL) или выполнить над ними какие-то операции, например, удалить дубли, убрать строки с пустыми значениями в определенных ячейках, сравнить данные в нескольких столбцах, отобрать нужные строки/столбцы и т.д. Подробнее можно почитать в документации для pandas.
Варианты использования скриптов
А теперь включаем главный инструмент тестировщика и выделяем данные/фичи на своем проекте, для проверки которых пригодились бы подобные скрипты.
Для сценариев созданы файлы с небольшим количеством тестовых данных, сгенерированных с помощью generatedata. В реальности файлы с данными содержат десятки тысяч строк и большое количество столбцов.
Сценарий №1
Есть три файла в формате csv с данными. Для каждой строки с данными есть поле с уникальным идентификатором id. Данные из этих файлов отбираются с учетом определенных условий и заносятся в таблицу в БД, затем эти данные выводятся в отчете в виде таблицы на UI. Есть возможность выгрузки данных на UI в Excel-файл.
Предположим, что условия выбора данных для отчета из файлов-исходников следующие:
- В файлах могут быть дубли по id, в отчете запись с одним и тем же идентификатором должна учитываться только один раз (при этом выбираем просто одну любую из строк с таким идентификатором из данных).
- Строки с отсутствием данных в ячейке столбца reg_date не должны учитываться.
- На самом деле условий отбора может быть больше, также данные могут сравниваться с уже имеющимися в системе данными и в отчет уже будут выводиться только пересекающиеся данные по id, но для примера будем учитывать только два условия, указанных выше.
Задача тестировщика: Проверить, что строки с нужными объектами корректно отобраны из файлов-исходников и все эти объекты выводятся в отчете на UI.
Составляем сценарий для скрипта:
- Загружаем в дата-фреймы нужные данные из этих трех csv-файлов, объединяем данные в один дата-фрейм (по аналогии с union в SQL), удаляем строки с дублями по id, удаляем строки без данных в столбце reg_date.
- Выгружаем на UI данные итогового отчета в Excel-файл, удаляем ненужные данные, загружаем данные из него во второй дата-фрейм.
- Объединяем (merge) эти два дата-фрейма в один (по аналогии с outer join в SQL) по уникальному идентификатору и уже записываем полученные данные в Excel-файл для дальнейшего анализа.
- Дальше уже открываем полученный файл и с помощью фильтров анализируем строки с данными и смотрим, что все строки, выбранные из файлов-исходников с учетом условий, есть в файле выгрузки данных отчета, полученном на UI.
В итоговом файле данные будут содержать только один столбец с идентификатором id, если названия у столбцов в разных дата-фреймах совпадали, и может быть не понятно, какие столбцы/строки из какого были файла. Поэтому я либо называю столбцы с уникальным идентификатором разными названиями в файлах, либо в каждый файл добавляю отдельный столбец «Строки из файла такого-то» и в нем проставляю значения «Да» — потом при анализе итогового Excel-файла удобно делать фильтрацию по этому столбцу, т.к. они всегда содержат значение и, фильтруя по ним, можно уже понять, какие данные расходятся в соответствующих столбцах.
Пример данных из файла example1_csv_1.csv:
Пример данных из файла report_UI.xlsx:
Скрипт на python выглядит следующим образом:
# Подключаем библиотеку pandas
import pandas as pd
# Выбираем нужные столбцы из csv-файлов и загружаем в дата-фреймы
# (в файле не должно быть столбцов с одинаковым названием)
df_from_file1 = pd.read_csv('./example1_csv_1.csv', sep=';', encoding='utf-8',
usecols=['id', 'name', 'email', 'reg_date'])
df_from_file2 = pd.read_csv('./example1_csv_2.csv', sep=';', encoding='utf-8',
usecols=['id', 'name', 'email','reg_date'])
df_from_file3 = pd.read_csv('./example1_csv_3.csv', sep=';', encoding='utf-8',
usecols=['id', 'name', 'email', 'reg_date'])
# Объединяем предыдущие три дата-фрейма в один новый дата-фрейм
# (по аналогии с union в SQL)
df_from_csv = pd.concat([df_from_file1, df_from_file2, df_from_file3]).\
reset_index(drop=True)
print(df_from_csv)
# Удаляем строки с дубликатами по указанному столбцу
df_from_csv.drop_duplicates(subset='id', keep='first', inplace=True)
print(df_from_csv)
# Удаляем строки со значением NaN (нет значения) для столбца reg_date
df_from_csv = df_from_csv.dropna()
print(df_from_csv)
# Загружаем данные из Excel-файла выгрузки с UI в дата-фрейм,
# при этом указываем название листа в файле
# (предварительно копируем файл с данными в папку со скриптом)
file_excel = 'report_UI.xlsx'
df_from_excel = pd.ExcelFile(file_excel).parse('Лист1')
print(df_from_excel)
# Объединяем дата-фрейм с отобранными данными из файлов-исходников и
# дата-фрейм с данными из файла выгрузки с UI
# (по аналогии с outer join в SQL)
df = df_from_csv.merge(df_from_excel, left_on='id', right_on="Номер", how='outer')
print(df)
# Выгружаем данные в новый Excel-файл
writer = pd.ExcelWriter('Итог.xlsx')
df.to_excel(writer, 'Лист1')
writer.save()
Ограничения:
- При работе с файлами с очень большим количеством строк придется разбивать их на отдельные файлы (тут нужно пробовать, у меня редко бывают файлы более 30 000 строк).
- Часто в файлах (обычно формата Excel) от заказчиков/аналитиков могут быть данные с пробелами или другими невидимыми знаками в ячейках, в этом случае такие скрипты использовать не получится без чистки исходных данных.
Сценарий №2
В разделе есть данные в виде таблицы по определенным объектам из одного источника. Система будет получать данные из второго источника (интеграция) и обновлять этими данными существующие данные таблицы. Каждая запись в таблице – это данные по одному объекту, который имеет уникальный идентификатор. Если из нового источника данные объекта по идентификатору совпадают с данными уже существующего объекта – то все поля существующей записи обновляются данными из нового источника (подтверждаются). Если же в таблице еще нет объекта с идентификатором из второго источника – то в таблице создается новая запись с данными из нового источника. Данные из второй системы можно выгрузить заранее в json-файл.
Задача тестировщика: Заранее подготовить файл с данными для теста, чтобы после реализации доработки проверить, что существующие записи корректно обновляются и им проставляется признак подтверждения в БД, если было совпадение по идентификатору, и корректно создаются новые записи и им проставляется признак добавления в БД, если записи с таким идентификатором еще не было.
Составляем сценарий для скрипта:
- Выгружаем на UI данные из таблицы раздела в Excel-файл (если нет такой возможности, то всегда можно экспортировать данные из результата SQL-запроса, используемого в коде для вывода данных в эту таблицу на UI) и залить данные из него в первый дата-фрейм.
- Получаем json-файл с данными из второго источника и загружаем их во второй дата-фрейм.
- Объединяем данные (merge — по аналогии с outer join в SQL) из двух полученных дата-фреймов в один новый дата-фрейм по уникальному идентификатору и выгружаем данные из него в Excel-файл, по которому уже в будущем будет проводиться тестирование. В этом файле будет сразу видно, какие строки должны были обновиться в таблице раздела, а какие должны были добавиться вновь.
Ограничения:
- При работе с файлами с очень большим количеством строк придется разбивать их на отдельные файлы (тут нужно пробовать, у меня редко бывают файлы более 30 000 строк).
- Если в json-файле есть несколько уровней вложенности объектов/массивов данных – то из внутренних уровней они будут загружены в ячейку как объект/массив, поэтому работать без какой-либо подготовки с json-файлами с помощью pandas удобно только для данных без лишней вложенности объектов/массивов.
Сценарий №3
Выполняется запрос к API системы, в ответе на который приходят данные по объектам в формате json.
Задача тестировщика: Сравнить данные из ответа на запрос к API с данными из результата SQL-запроса в БД.
Составляем сценарий для скрипта:
- Выполняем SQL-запрос в БД, экспортируем данные из результата запроса в csv-файл, загрузжаем эти данные в первый дата-фрейм.
- Сохраняем данные из ответа на запрос к API в json-файл, загружаем данные из файла во второй дата-фрейм.
- Объединяем данные (merge — по аналогии с outer join в SQL) из двух полученных дата-фреймов в один новый дата-фрейм по уникальному идентификатору и выгружаем данные из него в Excel-файл, в котором уже будем сравнивать данные по столбцам с помощью функций самого Excel.
- Либо данные по столбцам в общем дата-фрейме можно сравнить с помощью pandas, выгружая при этом строки с одинаковыми/разными данными в столбцах в новый дата-фрейм/Excel-файл для анализа.
Пример данных из файла example3_csv.csv:
Пример данных из файла example3_json.json:
[
{
"id": "16421118-4116",
"name_json": "Tempor Consulting",
"email_json": "Nullam.lobortis.quam@estNunc.net",
"tel_json": "1-821-805-8791",
"reg_date_json": "12-11-16",
"city_json": "Natales"
},
{
"id": "16040210-2206",
"name_json": "Odio Etiam Incorporated",
"email_json": "arcu@imperdietullamcorper.edu",
"tel_json": "1-730-291-6084",
"reg_date_json": "26-06-05",
"city_json": "Viddalba"
},
...
]
Скрипт на python выглядит следующим образом:
# Подключаем библиотеку pandas
import pandas as pd
# Загружаем данные из csv-файла в дата-фрейм
# (предварительно копируем файл с данными в папку со скриптом)
# При экспорте данных из БД в csv-файл лучше всего использовать разделитель ";"
df_from_csv = pd.read_csv('./example3_csv.csv', sep=';', encoding='utf-8')
print(df_from_csv)
# Загружаем данные из json-файла в дата-фрейм
# (предварительно копируем файл с данными в папку со скриптом)
df_from_json = pd.read_json('./example3_json.json', encoding='utf-8')
print(df_from_json)
# Объединяем дата-фреймы в один новый дата-фрейм
# (по аналогии с outer join в SQL)
df_csv_json = df_from_csv.merge(df_from_json, left_on='id',
right_on="id", how='outer')
print(df_csv_json)
# Выгружаем данные в Excel-файл, если нужно посмотреть,
# что все объекты из одного файла-исходника есть во втором,
# при этом указываем название для нового файла и название листа
# (файл будет создан в папке со скриптом)
# writer = pd.ExcelWriter('Итог.xlsx')
# df_csv_json.to_excel(writer, 'Лист1')
# writer.save()
# Либо сравниваем данные по двум соответствующим столбцам
# (например, name_csv и name_json) и
# выгружаем строки с отличающимися данными в Excel-файл для анализа
# (при этом выбираем также нужные столбцы для этих строк)
unequal_data_df = df_csv_json.loc[df_csv_json['name_csv'] !=
df_csv_json['name_json']]
unequal_data_df = unequal_data_df[['id', 'name_csv', 'name_json']]
print(unequal_data_df)
writer = pd.ExcelWriter('Разные_name.xlsx')
unequal_data_df.to_excel(writer, 'Лист1')
writer.save()
Ограничения:
- При работе с файлами с очень большим количеством строк придется разбивать их на отдельные файлы (тут нужно пробовать, у меня редко бывают файлы более 30 000 строк).
- Если в json-файле есть несколько уровней вложенности объектов/массивов данных – то из внутренних уровней они будут загружены в ячейку как объект/массив, поэтому работать без какой-либо подготовки с json-файлами с помощью pandas удобно только для данных без лишней вложенности объектов/массивов.
- Часто данные в ответе на запрос к API приходят обработанными по сравнению с данными из результата SQL-запроса в БД, поэтому для сравнения таких данных между файлами нужно будет приводить данные из SQL-запроса к нужному виду.
Если ответ на запрос к API приходит в xml формате, то нужно будет сначала распарсить нужные данные из xml-файла с помощью ElementTree или другой библиотеки и затем уже загружать их в дата-фрейм.
Сценарий №4
На UI выгружается xml-файл с данными по объектам, который формируется на лету из данных в БД с учетом определенных условий (например, учитываются статусы, даты, года или другие значения параметров для объектов).
Задача тестировщика: Сравнить уникальные идентификаторы id объектов из xml-файла, которые находятся в атрибуте тега company, с идентификаторами объектов из результата SQL-запроса в БД.
Составляем сценарий для скрипта:
- Сохраняем данные из ответа на запрос к API в xml-файл, получаем из этого файла нужные данные с помощью библиотеки ElementTree, загружаем данные в первый дата-фрейм.
- Выполняем SQL-запрос в БД, экспортируем данные из результата запроса в csv-файл, загрузжаем эти данные во второй дата-фрейм.
- Объединяем данные (merge — по аналогии с outer join в SQL) из двух полученных дата-фреймов в один новый дата-фрейм по уникальному идентификатору и выгружаем данные из него в Excel-файл.
- Дальше уже открываем полученный файл и анализируем строки с данными.
Пример данных из файла example4_csv.csv:
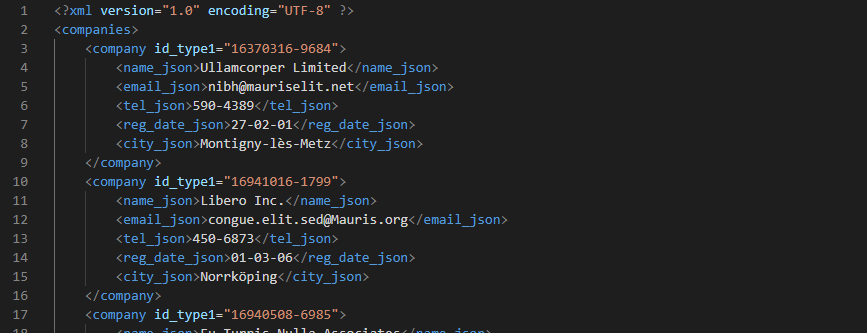
Пример данных из файла example4_xml.xml:
Скрипт на python выглядит следующим образом:
# Подключаем библиотеку ElementTree
from xml.etree import ElementTree
# Подключаем библиотеку pandas
import pandas as pd
# Загружаем данные из xml-файла в объект парсера
# (предварительно копируем файл с данными в папку со скриптом)
tree = ElementTree.parse("example4_xml.xml")
# Получаем корневой элемент
root = tree.getroot()
# Создаем список, в который будут добавляться данные
data_list = []
i = 1
# Выбираем нужные данные - значения атрибута id_type1 или id_type2
for child in root.iter("companies"):
for child_1 in child.iter("company"):
data_list.append({"Номер": i, "id": child_1.get("id_type1")
or child_1.get("id_type2"),
"Из выгрузки xml": "Да"})
i += 1
# Загружаем данные из списка data_list в дата-фрейм
df_from_xml = pd.DataFrame.from_dict(data_list, orient='columns')
print(df_from_xml)
# Загружаем данные из csv-файла в дата-фрейм
df_from_csv = pd.read_csv('./example4_csv.csv', sep=';', encoding='utf-8')
print(df_from_csv)
# Объединяем дата-фреймы в один дата-фрейм
# (по аналогии с outer join в SQL)
df = df_from_csv.merge(df_from_xml, left_on='id', right_on="id", how='outer')
print(df)
# Выгружаем данные в Excel-файл
# при этом указываем название для нового файла и название листа
# (файл будет создан в папке со скриптом)
writer = pd.ExcelWriter('Итог.xlsx')
df.to_excel(writer, 'Лист1')
writer.save()
Сценарий №5
На UI в разделе выводятся данные по объектам в виде таблицы. Есть возможность выгрузки данных в Excel-файл.
Задача тестировщика: Cравнить данные из таблицы раздела с данными, которые выгружаются в Excel-файл.
Составляем сценарий для скрипта:
- Просим у разработчиков SQL-запрос в БД из кода, который отвечает за вывод данных в таблицу раздела на UI.
- Выполняем этот SQL-запрос в БД, выгружаем данные в csv-файл, загружаем данные из него в первый дата-фрейм.
- Выгружаем на UI данные из таблицы раздела в Excel-файл и загружаем данные из него во второй дата-фрейм.
- Объединяем данные (merge — по аналогии с outer join в SQL) из двух полученных дата-фреймов в один новый дата-фрейм по уникальному идентификатору и выгрузжаем данные из него в Excel-файл, в котором уже будем сравнивать данные по столбцам с помощью функций самого Excel.
- Либо данные по столбцам в общем дата-фрейме можно сравнить с помощью pandas, выгружая при этом строки с одинаковыми/разными данными в столбцах в новый дата-фрейм/Excel-файл для анализа.
Ограничения:
- Часто количество строк с объектами, которые можно выгрузить в Excel-файл на UI, ограничивают, поэтому такой скрипт подойдет только для проверки тех разделов, где в файл выгрузки выгружаются все объекты из таблицы раздела.
Также аналогичные скрипты можно использовать и просто для того, чтобы данные из json-файлов или csv-файлов переносить в Excel-файлы. Либо можно объединять данные из нескольких Excel-файлов по определенным столбцам и выгружать их в один новый Excel-файл.
Заключение
Это всего лишь несколько примеров того, как можно использовать python+pandas для ускорения процесса тестирования и поиска багов. На самом деле у pandas намного больше возможностей для работы с данными, почитать об этом более подробно можно в документации к этой библиотеке.
Возможно на вашем проекте есть другие варианты для применения подобных скриптов и эта статья поможет начать их использовать в работе тестировщиков.



")