
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Автор статьи, перевод которой мы публикуем сегодня, говорит, что её цель — рассказать о разработке веб-скрапера на Python с использованием Selenium, который выполняет поиск цен на авиабилеты. При поиске билетов используются гибкие даты (+- 3 дня относительно указанных дат). Скрапер сохраняет результаты поиска в Excel-файле и отправляет тому, кто его запустил, электронное письмо с общими сведениями о том, что ему удалось найти. Задача этого проекта — помощь путешественникам в поиске наиболее выгодных предложений.

Если вы, разбираясь с материалом, почувствуете, что потерялись — взгляните на эту статью.
Вы вольны воспользоваться описываемой здесь системой так, как вам хочется. Я, например, применял её для поиска туров выходного дня и билетов в мой родной город. Если вы серьёзно настроены на поиск выгодных билетов — вы можете запустить скрипт на сервере (простой сервер, за 130 рублей в месяц, вполне для этого подойдёт) и сделать так, чтобы он запускался бы один-два раза в день. Результаты поиска будут приходить к вам по электронной почте. Кроме того, я рекомендую настроить всё так, чтобы скрипт сохранял бы Excel-файл с результатами поиска в Dropbox-папке, что позволит вам просматривать подобные файлы откуда угодно и в любое время.

Я пока не нашёл тарифов с ошибками, но полагаю, что это возможно
При поиске, как уже было сказано, используется «гибкая дата», скрипт находит предложения, находящиеся в пределах трёх дней от заданных дат. Хотя при запуске скрипта выполняется поиск предложений только по одному направлению, его несложно доработать для того, чтобы он мог бы собирать данные по нескольким направлениям полётов. С его помощью можно даже искать ошибочные тарифы, подобные находки могут оказаться весьма интересными.
Когда я впервые занялся веб-скрапингом, мне, честно говоря, это было не особенно интересно. Мне хотелось делать больше проектов в сфере прогнозного моделирования, финансового анализа, и, возможно, в области анализа эмоциональной окраски текстов. Но оказалось, что это очень интересно — разбираться с тем, как создать программу, которая собирает данные с веб-сайтов. По мере того, как я вникал в эту тему, я понял, что именно веб-скрапинг является «двигателем» интернета.
Возможно, вы решите, что это — слишком смелое заявление. Но подумайте о том, что компания Google началась с веб-скрапера, который Ларри Пейдж создал с использованием Java и Python. Роботы Google исследовали и исследуют интернет, пытаясь предоставить своим пользователям наилучшие ответы на их вопросы. У веб-скрапинга есть бесконечное множество вариантов применения, и даже если вам, в сфере Data Science, интересно что-то другое, то вам, чтобы обзавестись данными для анализа, понадобятся некоторые навыки скрапинга.
Некоторые из использованных здесь приёмов я нашёл в замечательной книге о веб-скрапинге, которой недавно обзавёлся. В ней можно найти множество простых примеров и идей по практическому применению изученного. Кроме того, там есть очень интересная глава об обходе проверок reCaptcha. Для меня это стало новостью, так как я и не знал о том, что существуют специальные инструменты и даже целые сервисы для решения подобных задач.
На простой и довольно безобидный вопрос, вынесенный в заголовок этого раздела, часто можно услышать положительный ответ, снабжённый парой историй из путешествий того, кому его задали. Большинство из нас согласится с тем, что путешествия — это прекрасный способ погружения в новые культурные среды и расширения собственного кругозора. Однако если задать кому-нибудь вопрос о том, нравится ли ему искать авиабилеты, то я уверен, что ответ на него будет уже далеко не таким позитивным. Собственно говоря, тут нам на помощь приходит Python.
Первой задачей, которую нам надо решить на пути создания системы поиска сведений по авиабилетам, будет подбор подходящей платформы, с которой мы будем брать информацию. Решение этой задачи далось мне нелегко, но в итоге я выбрал сервис Kayak. Я пробовал сервисы Momondo, Skyscanner, Expedia, да и ещё некоторые, но механизмы защиты от роботов на этих ресурсах были непробиваемыми. После нескольких попыток, в ходе которых, пытаясь убедить системы в том, что я человек, мне пришлось иметь дело со светофорами, пешеходными переходами и велосипедами, я решил, что мне больше всего подходит Kayak, несмотря даже на то, что и тут, если за короткое время загрузить слишком много страниц, тоже начинаются проверки. Мне удалось сделать так, чтобы бот отправлял бы запросы к сайту в интервалах от 4 до 6 часов, и всё нормально работало. Периодически сложности возникают и при работе с Kayak, но если вас начинают донимать проверками, то вам нужно либо разобраться с ними вручную, после чего запустить бот, либо подождать несколько часов, и проверки должны прекратиться. Вы, если нужно, вполне можете адаптировать код для другой платформы, а если вы так и сделаете — можете сообщить об этом в комментариях.
Если вы только начинаете знакомство с веб-скрапингом, и не знаете о том, почему некоторые веб-сайты всеми силами с ним борются, то, прежде чем приступать к своему первому проекту в этой области — окажите себе услугу и поищите в Google материалы по словам «web scraping etiquette». Ваши эксперименты могут завершиться скорее, чем вы думаете, в том случае, если вы будете заниматься веб-скрапингом неразумно.
Вот общий обзор того, что будет происходить в коде нашего веб-скрапера:
Надо отметить, что каждый проект Selenium начинается с веб-драйвера. Я использую Chromedriver, работаю с Google Chrome, но есть и другие варианты. Популярностью пользуются ещё PhantomJS и Firefox. После загрузки драйвера его нужно поместить в соответствующую папку, на этом подготовка к его использованию заканчивается. В первых строках нашего скрипта осуществляется открытие новой вкладки Chrome.
Учитывайте, что я, в своём рассказе, не пытаюсь открыть новые горизонты поиска выгодных предложений на авиабилеты. Существуют и гораздо более продвинутые приёмы поиска подобных предложений. Мне лишь хочется предложить читателям этого материала простой, но применимый на практике способ решения этой задачи.
Вот код, о котором мы говорили выше.
В начале кода можно видеть команды импорта пакетов, которые используются во всём нашем проекте. Так,
Проведём небольшой эксперимент и откроем в отдельном окне сайт kayak.com. Выберем город, из которого собираемся лететь, и город, в который хотим попасть, а также даты полётов. При выборе дат проверим, чтобы использовался диапазон +-3 дня. Я написал код с учётом того, что выдаёт сайт в ответ на подобные запросы. Если же вам, например, нужно искать билеты только на заданные даты, то высока вероятность того, что вам придётся доработать код бота. Рассказывая о коде, я делаю соответствующие пояснения, но если вы почувствуете, что запутались — дайте мне знать.
Теперь нажимаем на кнопку запуска поиска и смотрим на ссылку в строке адреса. Она должна быть похожа на ту ссылку, которую я использую в примере ниже, там, где объявляется переменная

Когда я использовал команду
Итак, мы открыли окно и загрузили сайт. Для того чтобы получить сведения о ценах и другую информацию, нам нужно воспользоваться технологией XPath или CSS-селекторами. Я решил остановиться на XPath и не ощутил нужды в применении CSS-селекторов, но вполне возможно работать и так. Перемещение по странице с использованием XPath может оказаться непростым делом, и даже если вы воспользуетесь теми методами, которые я описывал в этой статье, где применялось копирование соответствующих идентификаторов из кода страницы, я понял, что это, на самом деле, не оптимальный способ обращения к необходимым элементам. Кстати, в этой книге можно найти отличное описание основ работы со страницами с использованием XPath и CSS-селекторов. Вот как выглядит соответствующий метод веб-драйвера.

Итак, продолжаем работу над ботом. Воспользуемся возможностями программы для выбора самых дешёвых билетов. На следующем изображении красным выделен код селектора XPath. Для того чтобы просмотреть код, нужно щёлкнуть правой кнопкой мыши по интересующему вас элементу страницы и в появившемся меню выбрать команду Просмотреть код (Inspect). Эту команду можно вызывать для разных элементов страницы, код которых будет выводиться и выделяться в окне просмотра кода.
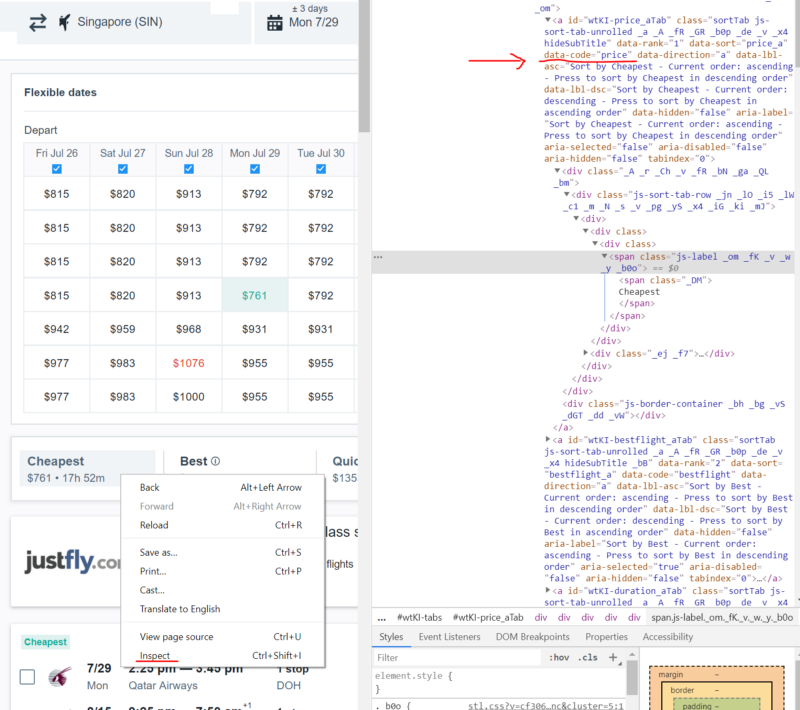
Просмотр кода страницы
Для того чтобы найти подтверждение моим рассуждениям о недостатках копирования селекторов из кода, обратите внимание на следующие особенности.
Вот что получается при копировании кода:
Для того чтобы скопировать нечто подобное, нужно щёлкнуть правой кнопкой мыши по интересующему вас участку кода и выбрать в появившемся меню команду Copy > Copy XPath.
Вот что я использовал для определения кнопки Cheapest:
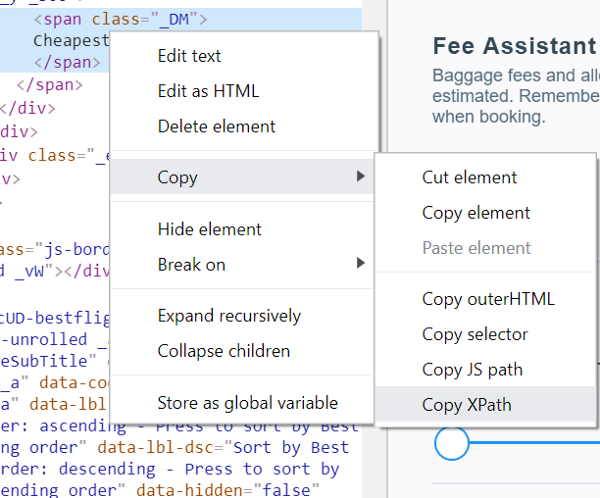
Команда Copy > Copy XPath
Совершенно очевидно то, что второй вариант выглядит гораздо проще. При его использовании выполняется поиск элемента a, у которого есть атрибут
Однако надо отметить, что копирование XPath-селекторов может пригодиться при работе с достаточно простыми сайтами, и если вас это устраивает, ничего плохого в этом нет.
Теперь подумаем о том, как быть, если нужно получить все результаты поиска в нескольких строках, внутри списка. Очень просто. Каждый результат находится внутри объекта с классом
Надо отметить, что если вам понятно вышесказанное, то вы без проблем должны понять большинство кода, который мы будем разбирать. В ходе работы этого кода к тому, что нам нужно (фактически — это элемент, в который обёрнут результат), мы обращаемся с использованием некоего механизма для указания пути (XPath). Делается это для того чтобы получить текст элемента и поместить его в объект, из которого можно считывать данные (сначала используется
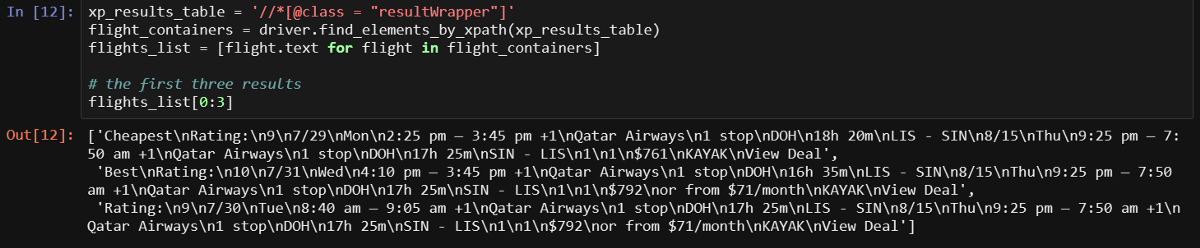
Выводятся первые три строки и мы можем чётко видеть всё, что нам нужно. Однако у нас есть и более интересные способы получения информации. Нам нужно брать данные из каждого элемента по-отдельности.
Легче всего написать функцию для загрузки дополнительных результатов, поэтому с неё и начнём. Мне хотелось бы максимизировать число перелётов, сведения о которых получает программа, и при этом не вызвать у сервиса подозрения, приводящие к проверке, поэтому я единожды щёлкаю по кнопке Load more results каждый раз когда отображается страница. В этом коде стоит обратить внимание на блок
Теперь, после долгого разбора этой функции (иногда я могу и увлечься), мы готовы к тому, чтобы объявить функцию, которая будет заниматься скрапингом страницы.
Я уже собрал большую часть того, что нужно, в следующей функции, называемой
Я постарался называть переменные так, чтобы код оказался бы понятным. Помните о том, что переменные, начинающиеся с
Теперь у нас имеется функция, которая позволяет загружать дополнительные результаты поиска и функция для обработки этих результатов. Данную статью на этом можно было бы и закончить, так как эти две функции дают всё необходимое для скрапинга страниц, которые можно открывать самостоятельно. Но мы пока не рассмотрели некоторые вспомогательные механизмы, о которых говорили выше. Например — это код для отправки электронных писем и ещё некоторые вещи. Всё это можно найти в функции
Для работы этой функции нужны сведения о городах и датах. Она, используя эти сведения, формирует ссылку в переменной
Я протестировал этот скрипт с использованием учётной записи Outlook (hotmail.com). Я не проверял его на правильность работы с аккаунтом Gmail, эта почтовая система весьма популярна, но есть масса возможных вариантов. Если же вы используете учётную запись Hotmail, то вам, для того чтобы всё заработало, достаточно ввести в код свои данные.
Если вы хотите разобраться с тем, что именно выполняется в отдельных участках кода этой функции, вы можете скопировать их и поэкспериментировать с ними. Эксперименты с кодом — это единственный способ как следует его понять.
Теперь, когда сделано всё то, о чём мы говорили, мы можем создать простой цикл, в котором вызываются наши функции. Скрипт запрашивает у пользователя данные о городах и датах. При тестировании с постоянным перезапуском скрипта вам вряд ли захочется каждый раз вводить эти данные вручную, поэтому соответствующие строки, на время тестирования, можно закомментировать, раскомментировав те, что идут ниже их, в которых жёстко заданы нужные скрипту данные.
Вот как выглядит тестовый запуск скрипта.

Тестовый запуск скрипта
Если вы добрались до этого момента — примите поздравления! Теперь у вас есть рабочий веб-скрапер, хотя я уже вижу множество путей его улучшения. Например, его можно интегрировать с Twilio, чтобы он, вместо электронных писем, отправлял бы текстовые сообщения. Можно воспользоваться VPN или ещё чем-нибудь для того, чтобы одновременно получать результаты с нескольких серверов. Есть ещё и периодически возникающая проблема с проверкой пользователя сайта на то, является ли он человеком, но и эту проблему можно решить. В любом случае, теперь у вас имеется база, которую вы, при желании, можете расширять. Например, сделать так, чтобы Excel-файл отправлялся бы пользователю в виде вложения в электронное письмо.

Если вы, разбираясь с материалом, почувствуете, что потерялись — взгляните на эту статью.
Что будем искать?
Вы вольны воспользоваться описываемой здесь системой так, как вам хочется. Я, например, применял её для поиска туров выходного дня и билетов в мой родной город. Если вы серьёзно настроены на поиск выгодных билетов — вы можете запустить скрипт на сервере (простой сервер, за 130 рублей в месяц, вполне для этого подойдёт) и сделать так, чтобы он запускался бы один-два раза в день. Результаты поиска будут приходить к вам по электронной почте. Кроме того, я рекомендую настроить всё так, чтобы скрипт сохранял бы Excel-файл с результатами поиска в Dropbox-папке, что позволит вам просматривать подобные файлы откуда угодно и в любое время.
Я пока не нашёл тарифов с ошибками, но полагаю, что это возможно
При поиске, как уже было сказано, используется «гибкая дата», скрипт находит предложения, находящиеся в пределах трёх дней от заданных дат. Хотя при запуске скрипта выполняется поиск предложений только по одному направлению, его несложно доработать для того, чтобы он мог бы собирать данные по нескольким направлениям полётов. С его помощью можно даже искать ошибочные тарифы, подобные находки могут оказаться весьма интересными.
Зачем нужен очередной веб-скрапер?
Когда я впервые занялся веб-скрапингом, мне, честно говоря, это было не особенно интересно. Мне хотелось делать больше проектов в сфере прогнозного моделирования, финансового анализа, и, возможно, в области анализа эмоциональной окраски текстов. Но оказалось, что это очень интересно — разбираться с тем, как создать программу, которая собирает данные с веб-сайтов. По мере того, как я вникал в эту тему, я понял, что именно веб-скрапинг является «двигателем» интернета.
Возможно, вы решите, что это — слишком смелое заявление. Но подумайте о том, что компания Google началась с веб-скрапера, который Ларри Пейдж создал с использованием Java и Python. Роботы Google исследовали и исследуют интернет, пытаясь предоставить своим пользователям наилучшие ответы на их вопросы. У веб-скрапинга есть бесконечное множество вариантов применения, и даже если вам, в сфере Data Science, интересно что-то другое, то вам, чтобы обзавестись данными для анализа, понадобятся некоторые навыки скрапинга.
Некоторые из использованных здесь приёмов я нашёл в замечательной книге о веб-скрапинге, которой недавно обзавёлся. В ней можно найти множество простых примеров и идей по практическому применению изученного. Кроме того, там есть очень интересная глава об обходе проверок reCaptcha. Для меня это стало новостью, так как я и не знал о том, что существуют специальные инструменты и даже целые сервисы для решения подобных задач.
Любите путешествовать?!
На простой и довольно безобидный вопрос, вынесенный в заголовок этого раздела, часто можно услышать положительный ответ, снабжённый парой историй из путешествий того, кому его задали. Большинство из нас согласится с тем, что путешествия — это прекрасный способ погружения в новые культурные среды и расширения собственного кругозора. Однако если задать кому-нибудь вопрос о том, нравится ли ему искать авиабилеты, то я уверен, что ответ на него будет уже далеко не таким позитивным. Собственно говоря, тут нам на помощь приходит Python.
Первой задачей, которую нам надо решить на пути создания системы поиска сведений по авиабилетам, будет подбор подходящей платформы, с которой мы будем брать информацию. Решение этой задачи далось мне нелегко, но в итоге я выбрал сервис Kayak. Я пробовал сервисы Momondo, Skyscanner, Expedia, да и ещё некоторые, но механизмы защиты от роботов на этих ресурсах были непробиваемыми. После нескольких попыток, в ходе которых, пытаясь убедить системы в том, что я человек, мне пришлось иметь дело со светофорами, пешеходными переходами и велосипедами, я решил, что мне больше всего подходит Kayak, несмотря даже на то, что и тут, если за короткое время загрузить слишком много страниц, тоже начинаются проверки. Мне удалось сделать так, чтобы бот отправлял бы запросы к сайту в интервалах от 4 до 6 часов, и всё нормально работало. Периодически сложности возникают и при работе с Kayak, но если вас начинают донимать проверками, то вам нужно либо разобраться с ними вручную, после чего запустить бот, либо подождать несколько часов, и проверки должны прекратиться. Вы, если нужно, вполне можете адаптировать код для другой платформы, а если вы так и сделаете — можете сообщить об этом в комментариях.
Если вы только начинаете знакомство с веб-скрапингом, и не знаете о том, почему некоторые веб-сайты всеми силами с ним борются, то, прежде чем приступать к своему первому проекту в этой области — окажите себе услугу и поищите в Google материалы по словам «web scraping etiquette». Ваши эксперименты могут завершиться скорее, чем вы думаете, в том случае, если вы будете заниматься веб-скрапингом неразумно.
Начало работы
Вот общий обзор того, что будет происходить в коде нашего веб-скрапера:
- Импорт необходимых библиотек.
- Открытие вкладки Google Chrome.
- Вызов функции, которая запускает бота, передавая ему города и даты, которые будут использоваться при поиске билетов.
- Эта функция получает первые результаты поиска, отсортированные по критерию наибольшей привлекательности (best), и нажимает на кнопку для загрузки дополнительных результатов.
- Ещё одна функция собирает данные со всей страницы и возвращает фрейм данных.
- Два предыдущих шага выполняются с использованием типов сортировки по цене билетов (cheap) и по скорости перелёта (fastest).
- Пользователю скрипта отправляется электронное письмо, содержащее краткую сводку о ценах билетов (самые дешёвые билеты и средняя цена), а фрейм данных со сведениями, отсортированными по трём вышеупомянутым показателям, сохраняется в виде Excel-файла.
- Все вышеописанные действия выполняются в цикле через заданный промежуток времени.
Надо отметить, что каждый проект Selenium начинается с веб-драйвера. Я использую Chromedriver, работаю с Google Chrome, но есть и другие варианты. Популярностью пользуются ещё PhantomJS и Firefox. После загрузки драйвера его нужно поместить в соответствующую папку, на этом подготовка к его использованию заканчивается. В первых строках нашего скрипта осуществляется открытие новой вкладки Chrome.
Учитывайте, что я, в своём рассказе, не пытаюсь открыть новые горизонты поиска выгодных предложений на авиабилеты. Существуют и гораздо более продвинутые приёмы поиска подобных предложений. Мне лишь хочется предложить читателям этого материала простой, но применимый на практике способ решения этой задачи.
Вот код, о котором мы говорили выше.
from time import sleep, strftime
from random import randint
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import smtplib
from email.mime.multipart import MIMEMultipart
# Используйте тут ваш путь к chromedriver!
chromedriver_path = 'C:/{YOUR PATH HERE}/chromedriver_win32/chromedriver.exe'
driver = webdriver.Chrome(executable_path=chromedriver_path) # Этой командой открывается окно Chrome
sleep(2)В начале кода можно видеть команды импорта пакетов, которые используются во всём нашем проекте. Так,
randint применяется для того, чтобы бот «засыпал» бы на случайное число секунд прежде чем начать новую операцию поиска. Обычно без этого не обходится ни один бот. Если запустить вышеприведённый код, будет открыто окно Chrome, которое бот будет использовать для работы с сайтами.Проведём небольшой эксперимент и откроем в отдельном окне сайт kayak.com. Выберем город, из которого собираемся лететь, и город, в который хотим попасть, а также даты полётов. При выборе дат проверим, чтобы использовался диапазон +-3 дня. Я написал код с учётом того, что выдаёт сайт в ответ на подобные запросы. Если же вам, например, нужно искать билеты только на заданные даты, то высока вероятность того, что вам придётся доработать код бота. Рассказывая о коде, я делаю соответствующие пояснения, но если вы почувствуете, что запутались — дайте мне знать.
Теперь нажимаем на кнопку запуска поиска и смотрим на ссылку в строке адреса. Она должна быть похожа на ту ссылку, которую я использую в примере ниже, там, где объявляется переменная
kayak, хранящая URL, и используется метод get веб-драйвера. После нажатия на кнопку поиска на странице должны появиться результаты.Когда я использовал команду
get больше двух-трёх раз в течение нескольких минут, мне предлагали пройти проверку с использованием reCaptcha. Эту проверку можно пройти вручную и продолжить эксперименты до тех пор, пока система не решит устроить новую проверку. Когда я тестировал скрипт, создалось такое ощущение, что первый сеанс поиска всегда проходит без проблем, поэтому, если вы хотите поэкспериментировать с кодом, вам придётся лишь периодически вручную проходить проверку и оставлять код выполняться, используя длительные интервалы между сеансами поиска. Да и, если вдуматься, человеку вряд ли понадобятся сведения о ценах на билеты, полученные с 10-минутными интервалами между операциями поиска.Работа со страницей с использованием XPath
Итак, мы открыли окно и загрузили сайт. Для того чтобы получить сведения о ценах и другую информацию, нам нужно воспользоваться технологией XPath или CSS-селекторами. Я решил остановиться на XPath и не ощутил нужды в применении CSS-селекторов, но вполне возможно работать и так. Перемещение по странице с использованием XPath может оказаться непростым делом, и даже если вы воспользуетесь теми методами, которые я описывал в этой статье, где применялось копирование соответствующих идентификаторов из кода страницы, я понял, что это, на самом деле, не оптимальный способ обращения к необходимым элементам. Кстати, в этой книге можно найти отличное описание основ работы со страницами с использованием XPath и CSS-селекторов. Вот как выглядит соответствующий метод веб-драйвера.
Итак, продолжаем работу над ботом. Воспользуемся возможностями программы для выбора самых дешёвых билетов. На следующем изображении красным выделен код селектора XPath. Для того чтобы просмотреть код, нужно щёлкнуть правой кнопкой мыши по интересующему вас элементу страницы и в появившемся меню выбрать команду Просмотреть код (Inspect). Эту команду можно вызывать для разных элементов страницы, код которых будет выводиться и выделяться в окне просмотра кода.
Просмотр кода страницы
Для того чтобы найти подтверждение моим рассуждениям о недостатках копирования селекторов из кода, обратите внимание на следующие особенности.
Вот что получается при копировании кода:
//*[@id="wtKI-price_aTab"]/div[1]/div/div/div[1]/div/span/spanДля того чтобы скопировать нечто подобное, нужно щёлкнуть правой кнопкой мыши по интересующему вас участку кода и выбрать в появившемся меню команду Copy > Copy XPath.
Вот что я использовал для определения кнопки Cheapest:
cheap_results = ‘//a[@data-code = "price"]’Команда Copy > Copy XPath
Совершенно очевидно то, что второй вариант выглядит гораздо проще. При его использовании выполняется поиск элемента a, у которого есть атрибут
data-code, равный price. При использовании первого варианта осуществляется поиск элемента id которого равен wtKI-price_aTab, при этом XPath-путь до элемента выглядит как /div[1]/div/div/div[1]/div/span/span. Подобный XPath-запрос к странице сделает своё дело, но — лишь один раз. Я прямо сейчас могу сказать, что id изменится при следующей загрузке страницы. Последовательность символов wtKI динамически изменяется при каждой загрузке страницы, в результате код, в котором она используется, после очередной перезагрузки страницы окажется бесполезным. Поэтому уделите некоторое время на то, чтобы разобраться с XPath. Эти знания сослужат вам хорошую службу.Однако надо отметить, что копирование XPath-селекторов может пригодиться при работе с достаточно простыми сайтами, и если вас это устраивает, ничего плохого в этом нет.
Теперь подумаем о том, как быть, если нужно получить все результаты поиска в нескольких строках, внутри списка. Очень просто. Каждый результат находится внутри объекта с классом
resultWrapper. Загрузка всех результатов может быть выполнена в цикле, напоминающем тот, что будет показан ниже.Надо отметить, что если вам понятно вышесказанное, то вы без проблем должны понять большинство кода, который мы будем разбирать. В ходе работы этого кода к тому, что нам нужно (фактически — это элемент, в который обёрнут результат), мы обращаемся с использованием некоего механизма для указания пути (XPath). Делается это для того чтобы получить текст элемента и поместить его в объект, из которого можно считывать данные (сначала используется
flight_containers, затем — flights_list).Выводятся первые три строки и мы можем чётко видеть всё, что нам нужно. Однако у нас есть и более интересные способы получения информации. Нам нужно брать данные из каждого элемента по-отдельности.
За работу!
Легче всего написать функцию для загрузки дополнительных результатов, поэтому с неё и начнём. Мне хотелось бы максимизировать число перелётов, сведения о которых получает программа, и при этом не вызвать у сервиса подозрения, приводящие к проверке, поэтому я единожды щёлкаю по кнопке Load more results каждый раз когда отображается страница. В этом коде стоит обратить внимание на блок
try, который я добавил из-за того, что иногда кнопка нормально не загружается. Если вы тоже с этим столкнётесь — закомментируйте вызовы этой функции в коде функции start_kayak, которую мы рассмотрим ниже.# Загрузка большего количества результатов для того, чтобы максимизировать объём собираемых данных
def load_more():
try:
more_results = '//a[@class = "moreButton"]'
driver.find_element_by_xpath(more_results).click()
# Вывод этих заметок в ходе работы программы помогает мне быстро выяснить то, чем она занята
print('sleeping.....')
sleep(randint(45,60))
except:
passТеперь, после долгого разбора этой функции (иногда я могу и увлечься), мы готовы к тому, чтобы объявить функцию, которая будет заниматься скрапингом страницы.
Я уже собрал большую часть того, что нужно, в следующей функции, называемой
page_scrape. Иногда возвращаемые данные об этапах пути оказываются объединёнными, для их разделения я использую простой метод. Например, когда в первый раз пользуюсь переменными section_a_list и section_b_list. Наша функция возвращает фрейм данных flights_df, это позволяет нам разделить результаты, полученные при использовании разных методов сортировки данных, а позже — объединить их.def page_scrape():
"""This function takes care of the scraping part"""
xp_sections = '//*[@class="section duration"]'
sections = driver.find_elements_by_xpath(xp_sections)
sections_list = [value.text for value in sections]
section_a_list = sections_list[::2] # так мы разделяем информацию о двух полётах
section_b_list = sections_list[1::2]
# Если вы наткнулись на reCaptcha, вам может понадобиться что-то предпринять.
# О том, что что-то пошло не так, вы узнаете исходя из того, что вышеприведённые списки пусты
# это выражение if позволяет завершить работу программы или сделать ещё что-нибудь
# тут можно приостановить работу, что позволит вам пройти проверку и продолжить скрапинг
# я использую тут SystemExit так как хочу протестировать всё с самого начала
if section_a_list == []:
raise SystemExit
# Я буду использовать букву A для уходящих рейсов и B для прибывающих
a_duration = []
a_section_names = []
for n in section_a_list:
# Получаем время
a_section_names.append(''.join(n.split()[2:5]))
a_duration.append(''.join(n.split()[0:2]))
b_duration = []
b_section_names = []
for n in section_b_list:
# Получаем время
b_section_names.append(''.join(n.split()[2:5]))
b_duration.append(''.join(n.split()[0:2]))
xp_dates = '//div[@class="section date"]'
dates = driver.find_elements_by_xpath(xp_dates)
dates_list = [value.text for value in dates]
a_date_list = dates_list[::2]
b_date_list = dates_list[1::2]
# Получаем день недели
a_day = [value.split()[0] for value in a_date_list]
a_weekday = [value.split()[1] for value in a_date_list]
b_day = [value.split()[0] for value in b_date_list]
b_weekday = [value.split()[1] for value in b_date_list]
# Получаем цены
xp_prices = '//a[@class="booking-link"]/span[@class="price option-text"]'
prices = driver.find_elements_by_xpath(xp_prices)
prices_list = [price.text.replace('$','') for price in prices if price.text != '']
prices_list = list(map(int, prices_list))
# stops - это большой список, в котором первый фрагмент пути находится по чётному индексу, а второй - по нечётному
xp_stops = '//div[@class="section stops"]/div[1]'
stops = driver.find_elements_by_xpath(xp_stops)
stops_list = [stop.text[0].replace('n','0') for stop in stops]
a_stop_list = stops_list[::2]
b_stop_list = stops_list[1::2]
xp_stops_cities = '//div[@class="section stops"]/div[2]'
stops_cities = driver.find_elements_by_xpath(xp_stops_cities)
stops_cities_list = [stop.text for stop in stops_cities]
a_stop_name_list = stops_cities_list[::2]
b_stop_name_list = stops_cities_list[1::2]
# сведения о компании-перевозчике, время отправления и прибытия для обоих рейсов
xp_schedule = '//div[@class="section times"]'
schedules = driver.find_elements_by_xpath(xp_schedule)
hours_list = []
carrier_list = []
for schedule in schedules:
hours_list.append(schedule.text.split('\n')[0])
carrier_list.append(schedule.text.split('\n')[1])
# разделяем сведения о времени и о перевозчиках между рейсами a и b
a_hours = hours_list[::2]
a_carrier = carrier_list[1::2]
b_hours = hours_list[::2]
b_carrier = carrier_list[1::2]
cols = (['Out Day', 'Out Time', 'Out Weekday', 'Out Airline', 'Out Cities', 'Out Duration', 'Out Stops', 'Out Stop Cities',
'Return Day', 'Return Time', 'Return Weekday', 'Return Airline', 'Return Cities', 'Return Duration', 'Return Stops', 'Return Stop Cities',
'Price'])
flights_df = pd.DataFrame({'Out Day': a_day,
'Out Weekday': a_weekday,
'Out Duration': a_duration,
'Out Cities': a_section_names,
'Return Day': b_day,
'Return Weekday': b_weekday,
'Return Duration': b_duration,
'Return Cities': b_section_names,
'Out Stops': a_stop_list,
'Out Stop Cities': a_stop_name_list,
'Return Stops': b_stop_list,
'Return Stop Cities': b_stop_name_list,
'Out Time': a_hours,
'Out Airline': a_carrier,
'Return Time': b_hours,
'Return Airline': b_carrier,
'Price': prices_list})[cols]
flights_df['timestamp'] = strftime("%Y%m%d-%H%M") # время сбора данных
return flights_dfЯ постарался называть переменные так, чтобы код оказался бы понятным. Помните о том, что переменные, начинающиеся с
a относятся к первому этапу пути, а b — ко второму. Переходим к следующей функции.Вспомогательные механизмы
Теперь у нас имеется функция, которая позволяет загружать дополнительные результаты поиска и функция для обработки этих результатов. Данную статью на этом можно было бы и закончить, так как эти две функции дают всё необходимое для скрапинга страниц, которые можно открывать самостоятельно. Но мы пока не рассмотрели некоторые вспомогательные механизмы, о которых говорили выше. Например — это код для отправки электронных писем и ещё некоторые вещи. Всё это можно найти в функции
start_kayak, которую мы сейчас и рассмотрим.Для работы этой функции нужны сведения о городах и датах. Она, используя эти сведения, формирует ссылку в переменной
kayak, которая используется для перехода на страницу, на которой будут находиться результаты поиска, отсортированные по их наилучшему соответствию запросу. После первого сеанса скрапинга мы поработаем с ценами, находящимися в таблице, в верхней части страницы. А именно, найдём минимальную цену билета и среднюю цену. Всё это, вместе с предсказанием, выдаваемым сайтом, будет отправлены по электронной почте. На странице соответствующая таблица должна быть в левом верхнем углу. Работа с этой таблицей, кстати, может вызвать ошибку при поиске с использованием точных дат, так как в таком случае таблица на странице не выводится.def start_kayak(city_from, city_to, date_start, date_end):
"""City codes - it's the IATA codes!
Date format - YYYY-MM-DD"""
kayak = ('https://www.kayak.com/flights/' + city_from + '-' + city_to +
'/' + date_start + '-flexible/' + date_end + '-flexible?sort=bestflight_a')
driver.get(kayak)
sleep(randint(8,10))
# иногда появляется всплывающее окно, для проверки на это и его закрытия можно воспользоваться блоком try
try:
xp_popup_close = '//button[contains(@id,"dialog-close") and contains(@class,"Button-No-Standard-Style close ")]'
driver.find_elements_by_xpath(xp_popup_close)[5].click()
except Exception as e:
pass
sleep(randint(60,95))
print('loading more.....')
# load_more()
print('starting first scrape.....')
df_flights_best = page_scrape()
df_flights_best['sort'] = 'best'
sleep(randint(60,80))
# Возьмём самую низкую цену из таблицы, расположенной в верхней части страницы
matrix = driver.find_elements_by_xpath('//*[contains(@id,"FlexMatrixCell")]')
matrix_prices = [price.text.replace('$','') for price in matrix]
matrix_prices = list(map(int, matrix_prices))
matrix_min = min(matrix_prices)
matrix_avg = sum(matrix_prices)/len(matrix_prices)
print('switching to cheapest results.....')
cheap_results = '//a[@data-code = "price"]'
driver.find_element_by_xpath(cheap_results).click()
sleep(randint(60,90))
print('loading more.....')
# load_more()
print('starting second scrape.....')
df_flights_cheap = page_scrape()
df_flights_cheap['sort'] = 'cheap'
sleep(randint(60,80))
print('switching to quickest results.....')
quick_results = '//a[@data-code = "duration"]'
driver.find_element_by_xpath(quick_results).click()
sleep(randint(60,90))
print('loading more.....')
# load_more()
print('starting third scrape.....')
df_flights_fast = page_scrape()
df_flights_fast['sort'] = 'fast'
sleep(randint(60,80))
# Сохранение нового фрейма в Excel-файл, имя которого отражает города и даты
final_df = df_flights_cheap.append(df_flights_best).append(df_flights_fast)
final_df.to_excel('search_backups//{}_flights_{}-{}_from_{}_to_{}.xlsx'.format(strftime("%Y%m%d-%H%M"),
city_from, city_to,
date_start, date_end), index=False)
print('saved df.....')
# Можно следить за тем, как прогноз, выдаваемый сайтом, соотносится с реальностью
xp_loading = '//div[contains(@id,"advice")]'
loading = driver.find_element_by_xpath(xp_loading).text
xp_prediction = '//span[@class="info-text"]'
prediction = driver.find_element_by_xpath(xp_prediction).text
print(loading+'\n'+prediction)
# иногда в переменной loading оказывается эта строка, которая, позже, вызывает проблемы с отправкой письма
# если это прозошло - меняем её на "Not Sure"
weird = '¯\\_(ツ)_/¯'
if loading == weird:
loading = 'Not sure'
username = 'YOUREMAIL@hotmail.com'
password = 'YOUR PASSWORD'
server = smtplib.SMTP('smtp.outlook.com', 587)
server.ehlo()
server.starttls()
server.login(username, password)
msg = ('Subject: Flight Scraper\n\n\
Cheapest Flight: {}\nAverage Price: {}\n\nRecommendation: {}\n\nEnd of message'.format(matrix_min, matrix_avg, (loading+'\n'+prediction)))
message = MIMEMultipart()
message['From'] = 'YOUREMAIL@hotmail.com'
message['to'] = 'YOUROTHEREMAIL@domain.com'
server.sendmail('YOUREMAIL@hotmail.com', 'YOUROTHEREMAIL@domain.com', msg)
print('sent email.....')Я протестировал этот скрипт с использованием учётной записи Outlook (hotmail.com). Я не проверял его на правильность работы с аккаунтом Gmail, эта почтовая система весьма популярна, но есть масса возможных вариантов. Если же вы используете учётную запись Hotmail, то вам, для того чтобы всё заработало, достаточно ввести в код свои данные.
Если вы хотите разобраться с тем, что именно выполняется в отдельных участках кода этой функции, вы можете скопировать их и поэкспериментировать с ними. Эксперименты с кодом — это единственный способ как следует его понять.
Готовая система
Теперь, когда сделано всё то, о чём мы говорили, мы можем создать простой цикл, в котором вызываются наши функции. Скрипт запрашивает у пользователя данные о городах и датах. При тестировании с постоянным перезапуском скрипта вам вряд ли захочется каждый раз вводить эти данные вручную, поэтому соответствующие строки, на время тестирования, можно закомментировать, раскомментировав те, что идут ниже их, в которых жёстко заданы нужные скрипту данные.
city_from = input('From which city? ')
city_to = input('Where to? ')
date_start = input('Search around which departure date? Please use YYYY-MM-DD format only ')
date_end = input('Return when? Please use YYYY-MM-DD format only ')
# city_from = 'LIS'
# city_to = 'SIN'
# date_start = '2019-08-21'
# date_end = '2019-09-07'
for n in range(0,5):
start_kayak(city_from, city_to, date_start, date_end)
print('iteration {} was complete @ {}'.format(n, strftime("%Y%m%d-%H%M")))
# Ждём 4 часа
sleep(60*60*4)
print('sleep finished.....')Вот как выглядит тестовый запуск скрипта.
Тестовый запуск скрипта
Итоги
Если вы добрались до этого момента — примите поздравления! Теперь у вас есть рабочий веб-скрапер, хотя я уже вижу множество путей его улучшения. Например, его можно интегрировать с Twilio, чтобы он, вместо электронных писем, отправлял бы текстовые сообщения. Можно воспользоваться VPN или ещё чем-нибудь для того, чтобы одновременно получать результаты с нескольких серверов. Есть ещё и периодически возникающая проблема с проверкой пользователя сайта на то, является ли он человеком, но и эту проблему можно решить. В любом случае, теперь у вас имеется база, которую вы, при желании, можете расширять. Например, сделать так, чтобы Excel-файл отправлялся бы пользователю в виде вложения в электронное письмо.



