
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
На конференциях и в неформальных беседах на работе нет-нет да и возникает разговор о важности работы QA-инженера и его роли в проекте. Это может быть и робкий вопрос коллеги-программиста «А, может, выпустим без QA?», и объёмный доклад.
Проблема, как мне кажется, связана с тем, что эффективность труда сотрудников отдела QA обратно пропорциональна количеству «срочных, внезапно возникающих» сложных задач. Назовём это «парадоксом немецкого сантехника», который получает зарплату, когда у него нет вызовов: чем меньше протечек и аварий на его участке, тем качественнее и эффективнее его работа. Но чем меньше у него вызовов, тем больше кажется со стороны, что он ничего не делает.

Типичный мем о важности QA
Поводом к написанию этой статьи стало общение с моим коллегой из другой компании, который недавно получил в работу целый проект по внедрению платежей и оказался в нём единственным QA-инженером. Он задался вопросом: как расставить приоритеты так, чтобы, с одной стороны, быть полезным команде, а с другой — иметь возможность обосновать собственную значимость для общего дела?
Ответить на этот вопрос мне помогли:
- десятилетний опыт работы QA-инженером в связанных с финансами проектах разной степени тестовой оснащённости и разным видением роли QA-специалиста;
- работа в Badoo, где организация процесса тестирования тщательно продумана и проверена многолетним опытом. О том, как организационно и технически устроен этот процесс, мы рассказывали в статье «Тестирование в Badoo "с высоты птичьего полёта"».
Итак, если вы, как и мой коллега, получили в работу целый проект по тестированию и не знаете, с чего начать, или просто задумываетесь о том, как организовать свою работу так, чтобы она была полезна команде (и чтобы пользу осознавали и вы, и команда), приятного чтения!
Содержание
- Заблуждения о работе QA-специалиста
- Четыре основные задачи QA инженера на каждом этапе проекта
— Ставим сигнализацию
— Организуем превентивные меры при внесении изменений
— Упрощаем доступ к тушению в труднодоступных местах и совершенствуем систему локализации пожара
— Развешиваем инструкции по пожарной безопасности - Почему именно такая приоритетность и может ли она измениться
- Выводы
Отрасль тестирования программного обеспечения сравнительно молода, поэтому для лучшего понимания процессов в ней имеет смысл провести аналогию с известными и хорошо развитыми отраслями. Я бы сравнил создание программного продукта со строительством современных модульных зданий, а деятельность QA-инженера — c работой специалиста по технической безопасности.
В зависимости от того, в каких условиях эксплуатируется здание, специалист по технической безопасности может заниматься разными вопросами: пожарной безопасностью, сейсмической устойчивостью конструкции, гидробезопасностью. Не уходя в дебри, остановимся на одном понятном всем направлении — пожарной безопасности.
В обязанности специалиста по пожарной безопасности не входит тушение пожаров. Он делает другое:
- сообщает о пожаре,
- помогает локализовать возгорание,
- исследует его причину,
- предупреждает возникновение пожара, выявляя места возможного возгорания,
- запрещает использование легковоспламеняющихся материалов,
- пишет инструкцию по безопасности и следит за её соблюдением.
Так же и специалист по тестированию.
QA-инженер не исправит баг в приложении, но может своевременно сообщить о его наличии, локализовать места появления багов в коде, уменьшить вероятность их появления, поделиться своими знаниями, чтобы коллеги, столкнувшись с похожей проблемой, легко могли решить её.
По сути, QA-инженеры при работе с кодом проекта решают те же задачи, что и специалисты по пожарной безопасности при строительстве здания:
- Организуют сигнализацию, сообщающую о пожаре, отвечая на вопрос «Как я узнаю, что в компоненте/интеграции есть ошибка?».
- Совершенствуют меры предупреждения пожара: «Как я буду в процессе изменений определять, что данный компонент не затронут и продолжает работать корректно? Можно ли откатиться назад, если в процессе изменений что-то пойдёт не так? Как минимизировать вероятность появления ошибки в коде?».
- Дают возможность определить причину пожара: «Если произойдёт ошибка в этом компоненте, как я смогу быстро понять, что она произошла именно здесь?».
- Разрабатывают инструкции по пожарной безопасности и следят за их соблюдением: «Что может быть непонятно другим участникам процесса при использовании этого компонента? Что может повлечь за собой неправильное использование и проблемы?».
Прежде чем мы последовательно разберём все задачи QA-инженеров, я расскажу о нескольких заблуждениях, связанных с восприятием QA в команде. С ними я столкнулся на своём профессиональном пути и считаю, что они мешают расставлять приоритеты задач так, чтобы QA-специалист был максимально эффективен.
Заблуждения о работе QA-специалиста
В большинстве компаний единственной обязанностью QA-инженера является организация превентивных мер. По крайней мере, в первую очередь вспоминают всегда о ней: эта часть работы сильно переоценена, что порождает множество стереотипов.
Мы в Badoo рассматриваем их как заблуждения.
Заблуждение 1: QA-инженер должен протестировать всё, что можно. Он не даёт ход тикету, пока не исправлены все обнаруженные в нём баги.
Распространяют этот миф либо начинающие тестировщики, либо «эффективные менеджеры», которые рассматривают организацию превентивных мер как единственную обязанность QA-специалиста.
Это заблуждение приводит к двум проблемам. Во-первых, выход новой функциональности задерживается из-за несущественных недостатков, а задержка может быть критична для бизнеса. Во-вторых, сильно страдает атмосфера в коллективе.
Заблуждение 2. Тестировщик — это кривору... низкоквалифицированный сотрудник, которому не удалось стать программистом. Поэтому в первую очередь он должен всё ломать.
Распространителями этого мифа являются либо сами QA-инженеры c заниженной самооценкой, либо разработчики с завышенной самооценкой. У них рождается мысль, что если тестировщик что-то не сломал, то он плохой специалист.
В результате QA-инженер сосредотачивается не на задачах бизнеса, а на поиске багов (в большинстве случаев это разные задачи, если не диаметрально противоположные). В итоге он ищет заковыристые кейсы, с которыми столкнётся только малая доля пользователей, лишь бы найти баг и почувствовать свою значимость.
Заблуждение 3. Ответственность за выпуск релиза с багами лежит на тестировщике.
К счастью, в Badoo это заблуждение было преодолено ещё до того, как я присоединился к команде. Тем не менее я часто сталкивался с ним в других проектах.
От этого заблуждения страдает скорость решения проблем. Возникает дисбаланс ответственности между участниками команды: первый человек, к которому приходят за ответом на вопрос «Где фича?», — это последний человек в конвейере, доставляющем фичу.
Заблуждение 4. Проверка положительного кейса является единственной задачей QA-инженера.
Распространяют это заблуждение, как правило, люди, плохо знающие, что такое классы эквивалентности и граничные кейсы (теоретическая база для работы в QA). В результате тикеты приходят на тестирование без необходимой информации. «Зачем я буду тратить время на описание, если есть человек, который должен это воспроизвести? Пусть он и разбирается», — думает разработчик.
Помимо нездоровой атмосферы в команде, это заблуждение порождает следующую проблему: вместо полного покрытия тестами QA-специалист занимается в прямом смысле детективным расследованием, чтобы выяснить, что же сделал разработчик и как это протестировать.
Наиболее полную инструкцию по борьбе с первым, вторым и третьим заблуждениями я подсмотрел на конференции TestBash в Мюнхене (для просмотра доклада нужно зарегистрироваться на сайте ministryoftestingorg.com, но там есть бесплатный пакет).
Вкратце идея следующая:
QA-инженер — это человек, который должен максимально быстро предоставить максимально объективную информацию о состоянии фичи/проекта, которая позволит принять решение о релизе с учётом интересов бизнеса.
Тестировщик должен помнить, что иногда скорость доставки фичи критична для бизнеса, и бизнес готов мириться с некритичными проблемами, но не готов мириться с задержкой. Поэтому полезен не тот, кто нашёл как можно больше мелких недочётов, продемонстрировав внимание к деталям и прочие качества, которые можно встретить в описании вакансии тестировщика, а тот, кто максимально быстро предоставил объективную информацию о текущем состоянии продукта, которая позволит менеджерам принять решение о релизе и обозначить приоритеты по ближайшим исправлениям.
QA-инженер может получить эту информацию, используя определённую последовательность действий. Важно, что применение этой последовательности должно иметь фрактальный принцип. Именно с пояснения фрактального принципа мы начнём рассматривать четыре основные задачи QA-специалиста, обозначенных выше.
Четыре основные задачи QA-инженера на каждом этапе проекта
Вернёмся к аналогии с пожарной безопасностью. Представьте процесс строительства здания: если бы мы строили не «фрактально», то сперва возвели бы одну стену, оштукатурили её, покрасили, установили сигнализацию и только после этого переходили бы к другой стене. Фрактальный принцип означает, что на каждом этапе работы над проектом (архитектура, отдельная интеграция, работа над конкретным тикетом в Jira) должна закладываться тестируемость фичи (чтобы к окончанию строительства не оказалось, что провода для сигнализации вам надо провести в шахте, которую не предусмотрели в архитектуре здания). Для того чтобы реализовать это на любом уровне развития проекта (идея, реализация, обслуживание, рефакторинг, переход к новой версии), QA-инженер должен отвечать на вопросы в следующем порядке:
- Как я узнаю, что в этой функциональности появились новые ошибки?
- Как я смогу предупредить появление ошибок и уменьшить вероятность их появления?
- Как я быстро пойму, с чем связана ошибка?
- Будет ли мой опыт решения проблемы полезен в будущем мне или кому-то ещё?
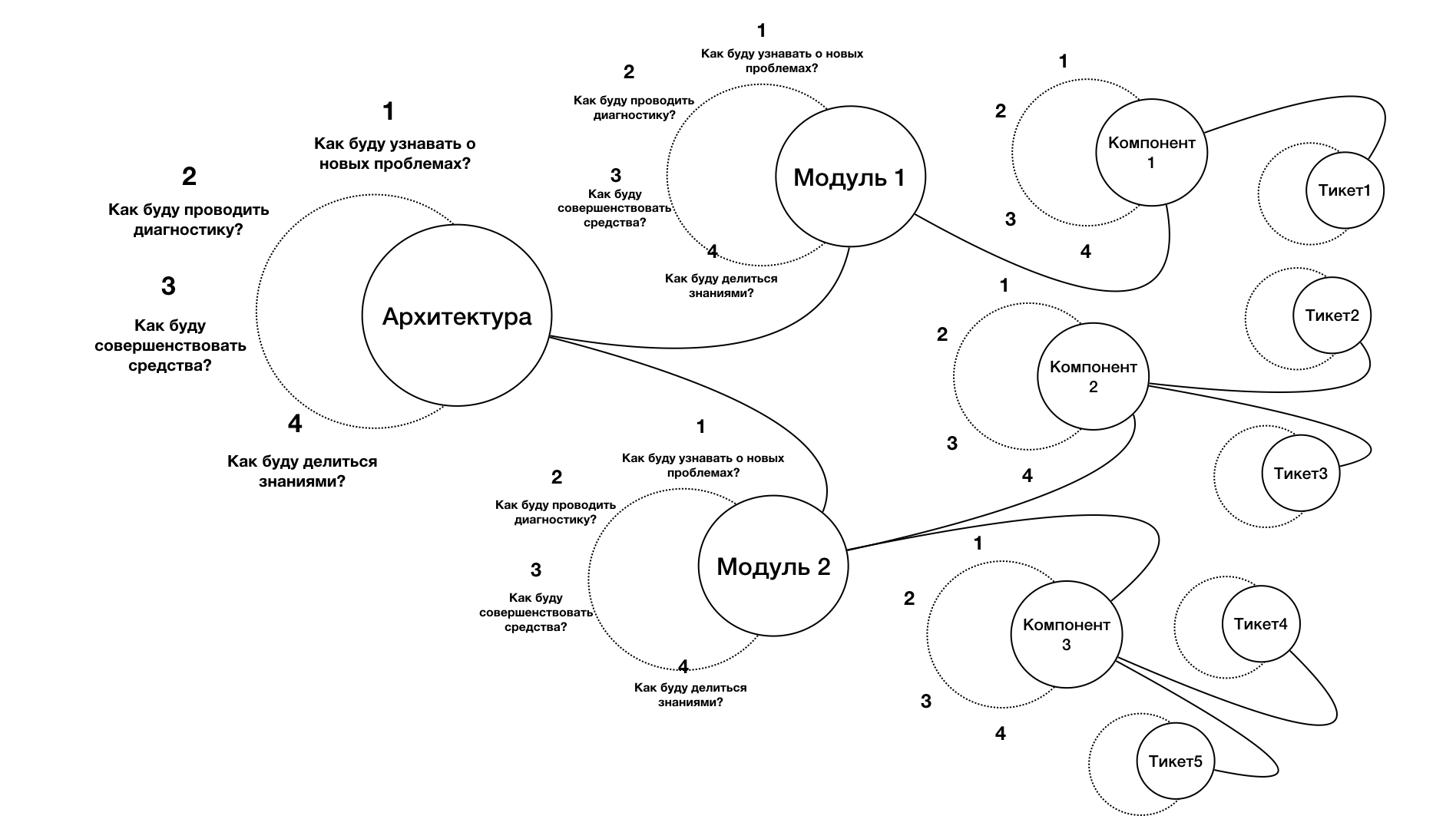
Давайте рассмотрим подробнее, как организовать решение каждого из этих вопросов на разных этапах развития проекта и на разных уровнях абстракции.
1. Ставим сигнализацию
Этот этап посвящён ответу на вопрос: «Как я узнаю, что в компоненте/интеграции на продакшене есть ошибка?». Ключевым моментом здесь является информация с продакшена.
В больших развитых проектах анализом информации с продакшена занимаются отделы сбора статистики и мониторинга. Рассмотрим, как эта часть работы затрагивает QA-инженера, на примере команды биллинга Badoo.
Мы тестируем более 70 разных платёжных интеграций в 250 странах мира, и часто статистика и логи оказываются единственными способами удостовериться в том, что в интеграциях в разных странах всё в порядке.
Например, в последнее время многие провайдеры (особенно СМС) для проведения платежей предоставляют SDK, внутри которого они сами получают информацию с сим-карты пользователя (MNC/MCC-код, IMSI, MSISDN). В этом случае проверить интеграцию невозможно без реальной сим-карты той страны, где необходимо проверить платёж.
Поэтому мы стараемся покрыть тестами максимально возможное количество интеграций, используя моки, фикстуры, стабы и прочие инструменты. Об этом можно почитать, например, в этой статье. Но иногда ошибка возникает именно в той части, где находится мок или фикстура, и даже если проблема не на нашей стороне, нашим пользователям от этого не легче. Мы должны принять все возможные меры по мониторингу ошибок и предотвращению последствий.
Кроме того, статистика и логи являются хорошей компенсацией последствий срабатывания пресловутого человеческого фактора — например, если при тестировании вы упустили особенности платёжных систем, связанные с законодательством той или иной страны (если вы принимаете платежи за рубежом) или работой мобильных операторов. Анализ статистики и логов станет некой страховкой (пусть и с запозданием).
1.1. Роль QA-инженера в установке сигнализации
На начальных этапах реализации проекта QA-инженер задает «неудобные» вопросы менеджерам и разработчикам:
- планируется ли отслеживание статистики, что она показывает, почему мы должны доверять этим метрикам;
- вопросы об архитектуре: предполагается ли увеличение количества метрик;
- как устроено логирование ошибок, что показывают ошибки, являются ли они информативными и полезными для QA-специалиста, для разработчиков, для других членов команды, которые будут участвовать в разборе ошибок.
Также QA-инженер даёт рекомендации по набору полезных метрик, которые позволят удостовериться, что в той или иной части кода всё работает корректно.
Например, вы внедряете интеграцию с новым платёжным провайдером. Вы можете предложить следующие метрики: сколько открытий формы провайдера было выполнено, сколько было закрыто без проведения платежа, сколько было завершённых платежей.
Также нужно выяснить следующее: после реализации функциональности в лог будут падать миллион сообщений "Unexpected data format", которые никому ни о чём не говорят, или же будет появляться детальное описание ошибки с указанием места падения и данных, с которыми эта ошибка произошла?
Как уже было сказано ранее, в развитых проектах этим занимаются отделы мониторинга и аналитики или внутри проекта выделены люди, занимающиеся мониторингом и аналитикой (причем это могут быть и менеджеры и разработчики). Однако если у вас на начальном этапе нет таких ролей, вполне естественно, что этим может заняться QA c последующей передачей этой обязанности другим участникам процесса.
В развитых проектах после определения рисков можно выявить, какая статистика, какие логи помогут понять, что компонент/интеграция не работает, промониторить статистику сразу же после выкладки изменений кода.
1.2. Какие реализации сигнализации возможны
Реализаций триггеров ошибок может быть множество. О технической реализации сбора метрик можно прочитать в нашей статье о мониторинге. А в этом разделе я расскажу о способах представления метрик, которые мы используем в Badoo, и тех, которые мне кажутся перспективными по опыту других проектов.
Мы фиксируем либо количество платежей (запросов сервиса, открытий окна), либо сумму платежа (или другую количественную характеристику), строим график по временным отрезкам, агрегируем данные в зависимости от критичности компонента в разных временных интервалах (минута, час, день).
Если что-то идёт не так (не завершается платёж, не открывается окно или, наоборот, дублируется окно и т. д.), график показывает это внезапными падениями или всплесками.
Чтобы сгладить графики, можно использовать алгоритмы из технического анализа:
- сглаживание (moving average): может быть простым, экспоненциальным, взвешенным; основное предназначение — превратить график из «лесенки» в сглаженную кривую, что позволит увидеть аномалии, исключив моменты активности пользователей;
- индикатор канала (CCI): в трейдинге этот инструмент показывает отклонение цены от скользящей средней (moving average), в мониторинге он может сигнализировать о какой-то аномалии, например, с метриками, которые должны оставаться в диапазоне значений;
- различные производные для определения скорости изменений и динамики скорости.
Под чек-суммами я подразумеваю сбор одних и тех же данных из разных источников и их последующую сверку. Такой способ идеально подходит, например, для проверки рефакторинга или модификации структур баз данных с целью рефакторинга, когда у нас есть старый работающий код/база и новый код/база. Принцип работы простой: собираем агрегированную информацию, которая должна остаться неизменной, из обоих источников, делаем сверку.
Например, у нас в базе данных есть таблица, хранящая записи о нотификациях от платёжного провайдера, в которой мы фиксируем все нотификации, с информацией о пользователе и платеже, и таблица, в которой фиксируется, сколько денег мы получили от конкретного пользователя.

В качестве чек-суммы можно использовать следующий запрос:
select balance.user, balance.amount, notification.amount, IF (balance.amount<>notification.amount, 'Fail', 'OK') as alert from
(select user, amount from Balance) as balance
left join
(select a.user, IFNULL(b.total,0) as amount from
(select user from Notifications where type = 'initial' group by user order by user) as a left join
(select user, sum(amount) as total from Notifications where type = 'success' group by user order by user) as b on
a.user = b.user) as notification
on balance.user = notification.user;В результате запроса мы должны получить следующую таблицу:
| user |
amount |
amount |
alert |
| user1 |
5 |
5 |
OK |
| user2 |
10 |
10 |
OK |
| user3 |
7 |
0 |
Fail |
Очень подробно о том, как может быть организован сбор логов для одного из компонентов системы, мы рассказывали в статье «Сбор и анализ логов демонов в Badoo».
Имея метрики, на следующем этапе можно начинать разрабатывать системы прогнозирования их поведения. Здесь математический инструментарий просто неисчерпаем: от стохастических осцилляторов из трейдинга, которые показывают отклонения графика от среднестатистических исторических показателей, до машинного обучения. В Badoo мы делаем прогнозы на основе машинного обучения.
Выводы
Несмотря на то, что сбором и анализом метрик и логов ошибок в больших проектах могут заниматься специалисты по мониторингу и аналитике, вы должны озаботиться получением доступа к этим данным на проде хотя бы в режиме read only. В большинстве случаев это оказывается единственным способом проверить функциональность (например, платёжные интеграции в других странах) или понять, что что-то идёт не так.
Если всё уже реализовано, попросите доступ к этим компонентам у аналитиков и разработчиков, чтобы удостовериться в том, что в проекте в данный момент нет пожаров, и просматривайте их после каждого релиза. Если же не реализовано, то будет логично, если именно вы станете инициатором сбора такой информации на начальных этапах развития проекта.
Это позволит быстро реагировать на критические ситуации и подстраховаться на тот случай, если не всё удастся протестировать и что-то пойдёт не так в не покрытом тестами коде.
2. Организуем превентивные меры при внесении изменений
На этом этапе QA-инженер должен работать в двух направлениях:
- Исследовать, в каком состоянии находится продукт после внесения изменений. Если есть проблемы, можно ли их минимизировать?
- Следить за тем, есть ли план действий на случай возникновения пропущенных ошибок.
2.1. Исследование состояния продукта после внесения изменений
Как только тикет переходит от разработчика к QA-специалисту, кто-то обязательно начинает интересоваться: «Как там задача?» Если QA-инженер ответит, что только получил её в работу, этот же человек появится через пять минут с вопросом «А сейчас?».

Коллеги делают это не потому, что хотят досадить вам.
Скорость доставки фичи, особенно если это что-то новое для рынка, критична для бизнеса. Компании часто готовы выпустить фичу даже с ошибками (если они не являются блокирующими для заявленной функциональности), но сделать это раньше конкурентов.
Поэтому, чтобы в любой момент времени иметь возможность рассказать историю о продукте, которая будет полезна бизнесу, я предлагаю использовать следующую последовательность при проверке:
- Проверить положительный кейс.
- Проанализировать и проверить отрицательные и эдж-кейсы, критичные для бизнеса (!).
- Провести регрессию.
- Проверить прочие отрицательные кейсы (не вошедшие в п. 2).
- Проверить прочие эдж-кейсы (не вошедшие в п. 2).

Положительный кейс
При проверке положительного кейса мы должны удостовериться, что то, что заявлено как основная фича, работает.
Отрицательные и эдж-кейсы, критичные для бизнеса
Кейсы, которые мы проверяем во вторую очередь, должны быть критичны для бизнеса. То есть ещё до проведения тестирования мы должны проанализировать, в каких отрицательных и эдж-кейсах баги могут сильно испортить нам жизнь. Это требует от QA-инженера либо знания бизнес-процессов, либо совместной работы с заказчиком фичи.
Приведу пример, когда негативный или эдж-кейс становится критичным для бизнеса.
Ситуация: ваше приложение предлагает промоакцию — скидку на первую покупку. При повторной покупке скидки быть не должно. Технически система реализована таким образом, что промопредложение и оказание услуги являются асинхронными, то есть пользователь получает предложение в одной части кода, а скидка предоставляется в другой. В обоих случаях выполняется проверка возможности сделать скидку. При оказании услуги, если эта проверка провалена, приложение просто предоставляет сервис по обычной цене.
Очевидно, может возникнуть ситуация, когда пользователь вошёл в сервис одновременно с двух устройств и на каждом увидел сообщение о скидке. Если после этого он совершит покупку с одного девайса, при покупке со второго скидка не будет применена, несмотря на то, что он видел промопредложение. Это эдж-кейс — не каждый человек использует одновременно два устройства. Но поскольку речь идёт о промопредложении и оказании услуги за отличную от стандартной цену, это может закончиться для компании в лучшем случае чарджбэком, в худшем — претензиями со стороны пользователей. Таким образом, любые кейсы, которые касаются изменения цены за услугу, даже если они лежат в плоскости эдж-кейсов, должны входить в п. 2 — отрицательные и эдж-кейсы, критичные для бизнеса.
Регрессия
Писать и спорить о регрессии можно очень долго. Я могу лишь выделить ряд положений, которые мы применяем в Badoo в отделе биллинга, и следование которым позволяет мне считать себя полезным участником команды.
Юнит-тесты, написанные программистами, нужно проверять самому. Создание юнит-тестов — это обязанность программистов. Если ваши программисты не пишут юнит-тесты (что равносильно стрельбе себе в ногу), нужно сделать так, чтобы они это делали. Если же пишут, то проверка юнит-тестов должна быть не только задачей программистов.
Получите команды для запуска юнит-тестов в разных окружениях и делайте проверку после каждого изменения. В Badoo мы можем проверять юнит-тесты на мастере (стабильной ветке в Git, содержащей код, который в данный момент работает на проде), на dev-ветке (ветке с изменениями), на коде, который готовится к выкладке на прод. И даже с такими возможностями 30% задач при моей проверке переоткрываются из-за падающих юнит-тестов, написанных разработчиками. Это человеческий фактор, и в силах QA-инженера уменьшить его влияние.
Автоматизация регрессии — это очень хорошо, но всегда нужно помнить, что у автоматизации есть своя цена. И эта цена гораздо выше, чем кажется на первый взгляд. Подробнее об этом вы можете почитать в статье моего коллеги Виктора Короневича.
Формула оценки эффективности автоматизации проста: автоматизация имеет смысл, если время регрессии превышает время, которое в среднем даётся на тестирование изменений. Также при организации автоматизации важно выделять отдельную единицу в команде для поддержки инфраструктуры автотестов (об этом тоже всегда следует помнить, оценивая стоимость автоматизации).
Во время регрессии исключительно важно понимать, какие изменения были внесены в код. QA-инженер должен разбираться в коде по двум причинам:
- понимание кода позволяет определить необходимое и достаточное покрытие тестами для регрессии и тем самым сократить время регрессии;
- чтение кода позволяет выйти на новый уровень тестирования.
В Badoo Jira объединена с Git и позволяет получить код, который менял программист в рамках отдельного тикета. Зная, в какие классы вносились изменения, QA-инженер может значительно сократить регрессию: если изменения касались небазовых классов, то проверять лишь небольшую часть кода, если базовых — расширить покрытие. Подробнее об интеграции Jira и Git можно прочитать здесь.
Кроме того, чтение кода позволяет QA-специалисту перейти на новый уровень тестирования. Подробнее читайте в книге «Рефакторинг. Улучшение существующего кода» Мартина Фаулера.
Прочие отрицательные и эдж-кейсы
Это те кейсы, которые у QA-инженера, считающего, что он непременно должен что-то сломать, заменяют кейсы, критичные для бизнеса, и не дают провести полноценную регрессию. Как правило, ошибки из этой категории, как шутят программисты, впоследствии из багов переходят в фичи. Самое важное здесь — определить, не относится ли, случайно, кейс к категории критичных для бизнеса, и если нет, то поступиться своим профессиональным эго и забыть, что вы потратили не один час рабочего времени, чтобы его найти. Для команды и продукта это будет гораздо ценнее, чем продолжать настаивать на починке такого кейса.
Реализация «муравьиного алгоритма» в отделе QA
Отдельно хотелось бы остановиться на проверке положительного кейса. В моей практике на удивление часто оказывалось, что, чтобы воспроизвести этот самый положительный кейс, необходимо было провести настоящее детективное расследование. Потому что то, что написано в тикете, — это по разным причинам не всегда то, что сделал программист.
Для проверки положительного кейса, чтобы QA-инженер не превращался в персонажа романа Агаты Кристи, у нас в отделе принято писать сообщение для QA-специалиста. Оно содержит информацию о том, что было сделано в тикете и какие особенности существуют при воспроизведении положительного кейса. Я называю это «стратегией муравья» (автором идеи «муравьиных алгоритмов» является Марко Дориго из Брюссельского свободного университета).
Сообщение для QA решает множество задач:
- ускоряет процесс воспроизведения положительного кейса, способствует быстрому исправлению багов, пока все участники процесса находятся в контексте решаемой задачи, и позволяет провести более тщательное исследование за пределами положительного кейса;
- добавляет осознанности в процесс: очень часто, когда разработчик начинает писать сообщение, он переосмысливает текущую реализацию и в ряде случаев сам переоткрывает тикет.
В основе сообщения для QA лежит принцип функционирования колонии муравьёв. Сами муравьи являются довольно примитивными существами, но социальность делает их очень эффективными в решении задач. В частности, при поиске еды муравьи используют феромоны. Каждый муравей оставляет дорожку из феромонов, по которой он может возвратиться назад и повторить свой путь. По ней могут пройти и другие муравьи. Чем сильнее ощущаются феромоны на дорожке, тем больше вероятность того, что колония муравьёв пройдёт именно по ней.
Аналогичный принцип имеет смысл использовать при работе над задачей. Завершили этап — описали, что было сделано. В этом случае, когда задача дойдёт до последнего этапа и попадёт к QA-инженеру, ему не нужно будет выяснять детали воспроизведения положительного кейса и он сможет сосредоточиться на своей работе.
В сообщении для QA имеет смысл указывать:
- что именно было сделано в тикете: как показывает практика, названия и описания задачи недостаточно, потому что в процессе работы возникает большое количество изменений, допусков и исключений, которые ни программист, ни заказчик часто не считают нужным вносить в тикет;
- как воспроизвести положительный кейс;
- особые условия для воспроизведения кейса (A/B-тест, патчи, скрипты и прочее).
2.2. Наличие плана Б
Существенным вопросом, которым в идеале также должна заниматься вся команда, является план Б — возможность быстро откатить изменения при обнаружении пожара сразу после деплоя. Так же, как и в случае с метриками, реализация плана Б впоследствии переходит от QA-отдела к другой команде. Если речь идёт об откате изменений — к команде релиз-инженеров, но, если этот процесс не организован, логично, что этим вопросом будет заниматься QA-специалист.
Здесь так же, как и в случае с сигнализацией, роль QA-инженера варьируется в зависимости от уровня организации проекта. В Badoo эта задача решена на уровне релиз-менеджмента: все изменения, которые должны оказаться на проде, проверяются в специальном окружении — на предпроде. Релиз какое-то время не закрывается, если на проде после него обнаруживаются критические ошибки: его можно откатить назад. Подробнее об организации релизов мы уже рассказывали.
Но даже в этом случае может возникнуть необходимость отката отдельного тикета. Например, изменение производится в уже работающей части приложения и предполагает изменение структуры базы данных. Выкладка предполагается по следующему сценарию:
- проверить, как работает старый код с новой базой;
- выложить новый код, который будет работать со старой базой данных;
- сделать изменение в базе данных и заполнить её в соответствии с новыми правилами;
- осуществить мгновенное переключение на использование новой структуры базы данных.
QA-инженер в этом случае должен пройтись по всем этапам и убедиться, что есть возможность откатиться к состоянию «старый код — новая база», потому что откат изменений в базе данных более трудоёмкий, чем откат кода.
Выводы
При организации превентивных мер нужно помнить следующее: чтобы быть полезным команде, вы должны не ломать продукт, а быть готовым рассказать о его текущем состоянии, учитывая требования бизнеса. Организуйте работу команды так, чтобы на последнем этапе вам были известны все данные, которые менялись в процессе. И убедитесь, что, если что-то пойдёт не так, у команды в распоряжении будет работающий план Б.
Эти шаги позволят уменьшить объём работы по организации превентивных мер и освободить ресурсы для других активностей, о которых многие забывают.
3. Упрощаем доступ к тушению в труднодоступных местах и совершенствуем систему локализации пожара
Это моя любимая часть.
При тестировании мы не всегда можем использовать «честные» методы. Иногда программисты пишут патчи, которые нужно применить, чтобы проверить что-то. Или сам QA-инженер создаёт тестовые данные, которые призваны обмануть систему, но проверить кейс.
Вы не раз будете обращаться к патчам, генераторам данных и прочим «нечестным» методам, поэтому имеет смысл сразу оформить их в документ, а лучше — в программный код.
Наличие системы, которая сохраняет все «нечестные» методы работы (моки, стабы, генераторы данных), решает сразу несколько задач:
- оптимизирует вашу дальнейшую работу за счёт автоматизации рутинных операций;
- держит вас в тонусе как IT-специалиста, потому что вы работаете с кодом;
- мотивирует, потому что вы занимаетесь тем, что вам интересно;
- способствует лучшему пониманию процессов и кода, потому что вы выступаете в роли менеджера и разработчика микропроекта.
Парадоксально, но иногда это вызывает максимальное сопротивление со стороны менеджеров и разработчиков. Однажды (на одном из предыдущих мест работы) у меня состоялся примерно такой диалог с менеджером проекта:
— Мне нужен плагин, который будет генерить тестовые данные для нашей системы.
— Ставь тикет на разработчиков.
— Но мне он нужен сейчас, и я могу написать его сам!
— Понимаешь, тебе платят деньги не за то, чтобы ты писал код. Если ты будешь писать код, то потратишь больше времени, чем программисты, а значит, компании твой код обойдётся дороже.
— Но у вас же всё равно нет ресурсов сейчас, чтобы сделать этот тикет.
— Значит, ты будешь проверять всё, генерируя данные вручную.
К сожалению, во многих компаниях считается, что написание кода QA-специалистом — это неэффективно. И как было приятно узнать, что в Badoo именно эта часть работы со стороны QA-инженера не просто востребована, но и является одним из условий для профессионального и карьерного роста! У меня существует договорённость с руководителем, что до 20% времени я могу тратить на свой проект (а это один день в неделю).
Результат такого подхода можно увидеть на многих конференциях с участием моих коллег. От себя добавлю классификацию инструментов, которые могут быть полезны в работе QA-инженера.
3.1. Наглядное представление информации
Сюда относятся различные бьютифаеры для представления запросов в читабельном виде, конструкторы запросов, отчётов, форматтеры логов и прочие инструменты.
Профит от внедрения таких инструментов основан на свойстве человеческой памяти, которая способна удерживать не более семи целостных объектов в один момент времени. Всякий раз, когда вам нужно выполнить процедуру извлечения информации, вы занимаете часть своей кратковременной памяти (это при условии, что процедура извлечения у вас доведена до автоматизма). Форматирование информации способствует тому, что вы не удерживаете её в кратковременной памяти, а извлекаете, когда она вам необходима, а значит, можете замечать более сложные закономерности в данных и принимать качественно другие решения.
3.2. Предоставление информации о состоянии системы
К этой группе можно отнести команды, скрипты и приложения, которые позволяют быстро выявить состояние элементов системы: инфраструктуры, счётчиков для пользователей, конкретного платежа. Это могут быть просто сохранённые в базу данных запросы, Linux-команды или страница с данными о пользователе, а может быть целое приложение-чекер, которое проверяет, все ли части девелоперского окружения в данный момент функционируют нормально и запуск теста имеет смысл, потому что падение не будет связано с инфраструктурными проблемами.
3.3. Быстрое приведение системы в нужное состояние
Часто, когда вы тестируете продукт, нужно привести его в требуемое состояние; и сделать это оказывается сложнее, чем просто войти в аккаунт пользователя. Например, по условию теста ваш пользователь должен быть зарегистрирован более чем семь дней назад, или вы хотите проверить обновление месячной подписки на сервис. В этом случае имеет смысл сохранить запросы, которые могут сделать подобные вещи.
У нас в Badoo есть много инструментов, которые мы используем для приведения системы в нужное состояние. Например, QA API и инструмент для создания моков платёжных чеков Apple.
Но не нужно придумывать что-то специально. Подобные проекты хороши, когда их внедрение продиктовано потребностями более чем одного человека — в этом случае они получают должную поддержку и переходят на новый уровень, когда ими начинают пользоваться коллеги, а не только вы.
Просто систематизируйте информацию, собирайте патчи, команды, рутинные действия, которые вы выполняете очень часто, и попробуйте их для начала собрать в отдельный документ, а потом по мере возможности автоматизируйте.
Выводы
Создание дополнительных инструментов — увлекательный процесс, который, к сожалению, часто ведётся QA-специалистами больше вопреки, чем благодаря. Не пытайтесь сразу создать универсальный инструмент — для начала просто начните систематизировать рутинные операции, которые вы выполняете регулярно. Сделайте инструмент для себя, а потом предложите пользоваться им другим.
Помните: автоматизировать имеет смысл, если это сделает представление информации наглядным, предоставит данные о состоянии критичных для работы компонентов, быстро приведёт систему в нужное состояние.
Помимо сокращения количества рутинных операций, умение автоматизировать свою работу повысит вашу ценность как специалиста в области ИТ.
4. Развешиваем инструкции по пожарной безопасности
Я не открою Америку, если скажу, что документация — это хорошо. Если в ближайшее время планируется масштабировать проект, перераспределять роли и обязанности членов команды, а также если в ней появляется новый человек, то создание документации стоит поднять в приоритете выше предыдущего пункта. Когда появляется функциональность, которую будут проверять несколько человек, имеет смысл делиться знаниями.
4.1. Рекомендации по написанию тестовой документации
Есть несколько принципов, которых мы в Badoo придерживаемся при написании документации:
- то, что автору документации кажется очевидным, не является очевидным для всех;
- ссылки и автогенерируемое содержимое всегда ценнее, чем тонны текста;
- хорошим тоном мы считаем, если текст построен по принципу пирамиды Минто.
Написали документацию? Дайте почитать кому-то ещё: то, что очевидно вам, может быть не очевидно для других. Есть вероятность, что через сутки вы и сами не разберете весь поток мыслей, который набросали. А ещё лучше — попросите поучаствовать в процессе коллегу-разработчика, оставив ему одну маленькую главу.
Когда я описываю функциональность, которую только что протестировал, я отдаю один небольшой раздел о том, как она реализована, на откуп разработчику — чтобы он в двух предложениях мог сформулировать запрограммированный принцип работы. Это значительно увеличивает осознанность: часто на этом этапе возникают какие-то новые идеи.
Важный момент: если вы описываете кейс воспроизведения чего-либо, то проверьте, что все условия оговорены до того момента, как они первый раз оказываются существенными. Очень плохо, если последующий шаг ссылается на что-то, что должно быть сделано на предыдущих шагах. Например, я часто встречаю подобные описания кейса:
- Залогиньтесь пользователем.
- Откройте страницу с выбором способа оплаты и выберите мобильный платёж.
- Если ваш пользователь зарегистрирован более семи дней назад, вы увидите платёжную форму агрегатора Global Charge.
Дойдя до третьего шага, я уже должен был знать, что пользователь должен быть зарегистрирован более семи дней назад, и это должно было стать отдельным шагом в кейсе. Конечно, пример сильно упрощён. Если он кажется вам нереальным, просто попробуйте вспомнить ситуацию, когда вы описывали кому-то кейс воспроизведения ошибки, человек отвечал вам: «У меня всё работает», а потом оказывалось, что вы просто забыли указать все условия воспроизведения.
Когда мы находимся в контексте задачи, мы полагаем, что все находятся в том же контексте. Поэтому контекст важно задавать до того, как он станет существенным при воспроизведении ситуации.
Информация имеет свойство устаревать. В живых проектах это происходит очень быстро, поэтому ссылки на поддерживаемый и обновляемый контент всегда ценнее, чем его копирование или пересказ.
Если какой-то контент можно заменить на автогенерируемый (из кода или из другого источника), сделайте это.
И, наконец, принцип пирамиды Минто. В общих чертах о нём можно узнать здесь или здесь. Если очень коротко, то никто не обязан читать весь поток сознания, который вы излили в файл: документация должна быть построена таким образом, чтобы каждый мог максимально быстро найти именно ту информацию, которая ему необходима для решения задачи.
Используем выпадающие списки (расшифровки можно размещать прямо под тезисами):

Используем не более четырёх уровней вложения и не более четырёх тезисов, если это не описание последовательности действий.

Пример организации внутреннего выступления для коллег по тестированию платежей в App Store, который затем легко превратится в документацию
Выводы
Пишите документацию. Когда меняется состав команды или происходит слияние с другими командами, наличие документации экономит больше времени, чем вы потратите на написание.
Помните, что документацию будут читать другие люди. Поэтому всегда отслеживайте, является ли важным для неё контекст. Если контекст важен, задайте его в документации (а лучше привлеките коллегу или сами перечитайте свой поток сознания через сутки).
Информация устаревает. Поэтому используйте все возможности для автоматического создания контента на основе обновляемых данных. Ссылки на актуальную информацию всегда ценнее, чем страницы устаревшего текста.
Помните, что никто не должен читать весь ваш поток сознания. Форматируйте и представляйте информацию так, чтобы из неё можно было максимально быстро извлечь нужное для решения задачи здесь и сейчас. Одним из способов такой организации является принцип Минто.
Помимо фиксации и распространения информации, документация даст вам очень важное преимущество — целостное видение проекта.
Почему именно такая приоритетность и может ли она измениться
В начале статьи я обещал объяснить, почему я расположил эти пункты именно в таком порядке. Для этого обратимся к критичности ошибок. Ниже — ошибки, встречающиеся в нашей практике, в порядке уменьшения их критичности:
- пользователь произвёл оплату, но не получил сервис или получил не тот сервис (репутационные потери);
- пользователь не может произвести оплату по нашей вине или по вине платёжного провайдера: не работает точка входа в платёжную форму, сломана интеграция и т. д. (финансовые потери);
- прочие ошибки.
Наибольший вклад в своевременное реагирование на самые критичные ошибки и их профилактику вносят анализ логов и статистики. Среди критичных ошибок есть те, которые могут возникнуть не по нашей вине, но мы должны на них отреагировать: например, поломка на стороне платёжного провайдера, на которую мы можем отреагировать, переключив пользователя на другого провайдера или показав сообщение об ошибке. Анализ логов и статистики также помогает обнаружить ошибки, которые могут попасть на продакшн в результате человеческого фактора.
Весомый вклад в поиск ошибок вносят и превентивные меры. А совершенствование инструментов тестирования и ведение документации влияют на процесс работы с ошибками уже непрямым образом.
Может ли измениться приоритетность пунктов? Да, может. По опыту работы нашей команды, соотношение «локализация пожаров — тестирование» варьируется в зависимости от состава спринта. Если спринт — про новые сервисы и новые интеграции, то это соотношение 40/60, если про рефакторинг и фикс багов, то 60/40. Соответственно, в первом случае приоритетность может незначительно сместиться в сторону превентивных мер, оставив сигнализацию на втором месте.
Аналогично с парой «совершенствование инструментов — ведение документации». В зависимости от процессов в команде приоритеты могут меняться. Если намечается интеграционный проект или меняется состав команды, то документация может стать более приоритетной, чем разработка новых инструментов. Если же состав команды более-менее стабильный и структура задач подразумевает больше работу внутри отдела, а не интеграции, то разработка инструментов становится важнее.
Выводы
Работу QA-инженера можно сравнить с работой специалиста по пожарной безопасности при строительстве здания. Если вы хотите быть полезным своей команде и своевременно реагировать на проблемы, то:
- озаботьтесь получением данных о текущем состоянии системы там, где это критично для её функционирования: подойдут анализ логов и статистики, проверка чек-сумм — всё, что позволит вам максимально быстро понять, что в системе наблюдается сбой;
- обзаведитесь максимально быстрым способом получения максимально полной истории фичи/продукта: важно правильно расставить приоритеты и о наиболее критичных проблемах сообщать как можно раньше, а при нахождении некритичных находить баланс между интересами команды и своим профессиональным эго; кроме того, на этом этапе QA-инженер должен убедиться, что на случай если что-то пойдёт не так, есть план по откату изменений;
- совершенствуйте свои инструменты работы: начните с автоматизации рутинных операций — это будет держать вас в тонусе как IT-специалиста и будет очень хорошей мотивацией;
- и, наконец, не забывайте про документацию.
А вы с кем можете сравнить своего QA-инженера?


