
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Привет, Хабр!
Осенью прошлого года на Kaggle проходил конкурс по классификации нарисованных от руки картинок Quick Draw Doodle Recognition, в котором среди прочих поучаствовала команда R-щиков в составе Артема Клевцова, Филиппа Управителева и Андрея Огурцова. Подробно описывать соревнование не будем, это уже сделано в недавней публикации.
С фармом медалек в этот раз не сложилось, но было получено много ценного опыта, поэтому о ряде наиболее интересных и полезных на Кагле и в повседневной работе вещей хотелось бы рассказать сообществу. Среди рассмотренных тем: нелегкая жизнь без OpenCV, парсинг JSON-ов (на этих примерах рассматривается интеграции кода на С++ в скрипты или пакеты на R посредством Rcpp), параметризация скриптов и докеризация итогового решения. Весь код из сообщения в пригодном для запуска виде доступен в репозитории.
Содержание:
- Эффективная загрузка данных из CSV в базу MonetDB
- Подготовка батчей
- Итераторы для выгрузки батчей из БД
- Выбор архитектуры модели
- Параметризация скриптов
- Докеризация скриптов
- Использование нескольких GPU в облаке Google Cloud
- Вместо заключения
1. Эффективная загрузка данных из CSV в базу MonetDB
Данные в этом соревновании предоставляются не в виде готовых картинок, а в виде 340 CSV-файлов (по одному файлу на каждый класс), содержащих JSON-ы с координатами точек. Соединив эти точки линиями, мы получаем итоговое изображение размером 256х256 пикселей. Также для каждой записи приводится метка, была ли картинка корректно распознана используемым на момент сбора датасета классификатором, двухбуквенный код страны проживания автора рисунка, уникальный идентификатор, метка времени и название класса, совпадающее с именем файла. Упрощенная версия исходных данных весит 7.4 Гб в архиве и примерно 20 Гб после распаковки, полные данные после распаковки занимают 240 Гб. Организаторы гарантировали, что обе версии воспроизводят одни и те же рисунки, то есть полная версия является избыточной. В любом случае, хранение 50 млн. картинок в графических файлах или в виде массивов сразу было признано нерентабельным, и мы решили слить все CSV-файлы из архива train_simplified.zip в базу данных с последующей генерацией картинок нужного размера "на лету" для каждого батча.
В качестве СУБД была выбрана хорошо себя зарекомендовавшая MonetDB, а именно реализация для R в виде пакета MonetDBLite. Пакет включает в себя embedded-версию сервера базы данных и позволяет поднять сервер непосредственно из R-сессии и там же работать с ним. Создание базы данных и подключение к ней выполняются одной командой:
con <- DBI::dbConnect(drv = MonetDBLite::MonetDBLite(), Sys.getenv("DBDIR"))Нам понадобится создать две таблицы: одну для всех данных, другую для служебной информации о загруженных файлах (пригодится, если что-то пойдет не так и процесс придется возобновлять после загрузки нескольких файлов):
if (!DBI::dbExistsTable(con, "doodles")) {
DBI::dbCreateTable(
con = con,
name = "doodles",
fields = c(
"countrycode" = "char(2)",
"drawing" = "text",
"key_id" = "bigint",
"recognized" = "bool",
"timestamp" = "timestamp",
"word" = "text"
)
)
}
if (!DBI::dbExistsTable(con, "upload_log")) {
DBI::dbCreateTable(
con = con,
name = "upload_log",
fields = c(
"id" = "serial",
"file_name" = "text UNIQUE",
"uploaded" = "bool DEFAULT false"
)
)
}Самым быстрым способом загрузки данных в БД оказалась прямое копирование CSV-файлов средствами SQL — команда COPY OFFSET 2 INTO tablename FROM path USING DELIMITERS ',','\\n','\"' NULL AS '' BEST EFFORT, где tablename — имя таблицы и path — путь к файлу. При работе с архивом было обнаружено, что встроенная реализация unzip в R некорректно работает с рядом файлов из архива, поэтому мы использовали системный unzip (с помощью параметра getOption("unzip")).
#' @title Извлечение и загрузка файлов
#'
#' @description
#' Извлечение CSV-файлов из ZIP-архива и загрузка их в базу данных
#'
#' @param con Объект подключения к базе данных (класс `MonetDBEmbeddedConnection`).
#' @param tablename Название таблицы в базе данных.
#' @oaram zipfile Путь к ZIP-архиву.
#' @oaram filename Имя файла внури ZIP-архива.
#' @param preprocess Функция предобработки, которая будет применена извлечённому файлу.
#' Должна принимать один аргумент `data` (объект `data.table`).
#'
#' @return `TRUE`.
#'
upload_file <- function(con, tablename, zipfile, filename, preprocess = NULL) {
# Проверка аргументов
checkmate::assert_class(con, "MonetDBEmbeddedConnection")
checkmate::assert_string(tablename)
checkmate::assert_string(filename)
checkmate::assert_true(DBI::dbExistsTable(con, tablename))
checkmate::assert_file_exists(zipfile, access = "r", extension = "zip")
checkmate::assert_function(preprocess, args = c("data"), null.ok = TRUE)
# Извлечение файла
path <- file.path(tempdir(), filename)
unzip(zipfile, files = filename, exdir = tempdir(),
junkpaths = TRUE, unzip = getOption("unzip"))
on.exit(unlink(file.path(path)))
# Применяем функция предобработки
if (!is.null(preprocess)) {
.data <- data.table::fread(file = path)
.data <- preprocess(data = .data)
data.table::fwrite(x = .data, file = path, append = FALSE)
rm(.data)
}
# Запрос к БД на импорт CSV
sql <- sprintf(
"COPY OFFSET 2 INTO %s FROM '%s' USING DELIMITERS ',','\\n','\"' NULL AS '' BEST EFFORT",
tablename, path
)
# Выполнение запроса к БД
DBI::dbExecute(con, sql)
# Добавление записи об успешной загрузке в служебную таблицу
DBI::dbExecute(con, sprintf("INSERT INTO upload_log(file_name, uploaded) VALUES('%s', true)",
filename))
return(invisible(TRUE))
}В случае, если требуется преобразовать таблицу перед записью в БД, достаточно передать в аргумент preprocess функцию, которая будет преобразовывать данные.
Код для последовательной загрузки данных в базу:
# Список файлов для записи
files <- unzip(zipfile, list = TRUE)$Name
# Список исключений, если часть файлов уже была загружена
to_skip <- DBI::dbGetQuery(con, "SELECT file_name FROM upload_log")[[1L]]
files <- setdiff(files, to_skip)
if (length(files) > 0L) {
# Запускаем таймер
tictoc::tic()
# Прогресс бар
pb <- txtProgressBar(min = 0L, max = length(files), style = 3)
for (i in seq_along(files)) {
upload_file(con = con, tablename = "doodles",
zipfile = zipfile, filename = files[i])
setTxtProgressBar(pb, i)
}
close(pb)
# Останавливаем таймер
tictoc::toc()
}
# 526.141 sec elapsed - копирование SSD->SSD
# 558.879 sec elapsed - копирование USB->SSDВремя загрузки данных может варьироваться в зависимости от скоростных характеристик используемого накопителя. В нашем случае чтение и запись в пределах одного SSD или с флешки (исходный файл) на SSD (БД) занимает менее 10 минут.
Еще несколько секунд требуется для создания столбца с целочисленной меткой класса и столбца-индекса (ORDERED INDEX) с номерами строк, по которому будет производиться выборка наблюдений при создании батчей:
message("Generate lables")
invisible(DBI::dbExecute(con, "ALTER TABLE doodles ADD label_int int"))
invisible(DBI::dbExecute(con, "UPDATE doodles SET label_int = dense_rank() OVER (ORDER BY word) - 1"))
message("Generate row numbers")
invisible(DBI::dbExecute(con, "ALTER TABLE doodles ADD id serial"))
invisible(DBI::dbExecute(con, "CREATE ORDERED INDEX doodles_id_ord_idx ON doodles(id)"))Для решения задачи формирования батча «на лету» нам необходимо было добиться максимальной скорости извлечения случайных строк из таблицы doodles. Для этого мы использовали 3 трюка. Первый заключался в том, чтобы сократить размерность типа, в котором хранится ID наблюдения. В исходном наборе данных для хранения ID требуется тип bigint, но количество наблюдений позволяет уместить их идентификаторы, равные порядковому номеру, в тип int. Поиск при этом происходит значительно быстрее. Вторым трюком было использование ORDERED INDEX — к этому решению пришли эмпирически, перебрав все доступные варианты. Третий состоял в использовании параметризованных запросов. Суть метода заключается в однократном выполнения команды PREPARE с последующим использованием подготовленного выражения при создании кучи однотипных запросов, но на деле выигрыш по сравнения с простым SELECT оказался в районе статистической погрешности.
Процесс заливки данных потребляет не более 450 Мб ОЗУ. То есть описанный подход позволяет ворочать датасеты весом в десятки гигабайт практически на любом бюджетном железе, включая некоторые одноплатники, что довольно круто.
Остается выполнить замеры скорости извлечения (случайных) данных и оценить масштабирование при выборке батчей разного размера:
library(ggplot2)
set.seed(0)
# Подключение к базе данных
con <- DBI::dbConnect(MonetDBLite::MonetDBLite(), Sys.getenv("DBDIR"))
# Функция для подготовки запроса на стороне сервера
prep_sql <- function(batch_size) {
sql <- sprintf("PREPARE SELECT id FROM doodles WHERE id IN (%s)",
paste(rep("?", batch_size), collapse = ","))
res <- DBI::dbSendQuery(con, sql)
return(res)
}
# Функция для извлечения данных
fetch_data <- function(rs, batch_size) {
ids <- sample(seq_len(n), batch_size)
res <- DBI::dbFetch(DBI::dbBind(rs, as.list(ids)))
return(res)
}
# Проведение замера
res_bench <- bench::press(
batch_size = 2^(4:10),
{
rs <- prep_sql(batch_size)
bench::mark(
fetch_data(rs, batch_size),
min_iterations = 50L
)
}
)
# Параметры бенчмарка
cols <- c("batch_size", "min", "median", "max", "itr/sec", "total_time", "n_itr")
res_bench[, cols]
# batch_size min median max `itr/sec` total_time n_itr
# <dbl> <bch:tm> <bch:tm> <bch:tm> <dbl> <bch:tm> <int>
# 1 16 23.6ms 54.02ms 93.43ms 18.8 2.6s 49
# 2 32 38ms 84.83ms 151.55ms 11.4 4.29s 49
# 3 64 63.3ms 175.54ms 248.94ms 5.85 8.54s 50
# 4 128 83.2ms 341.52ms 496.24ms 3.00 16.69s 50
# 5 256 232.8ms 653.21ms 847.44ms 1.58 31.66s 50
# 6 512 784.6ms 1.41s 1.98s 0.740 1.1m 49
# 7 1024 681.7ms 2.72s 4.06s 0.377 2.16m 49
ggplot(res_bench, aes(x = factor(batch_size), y = median, group = 1)) +
geom_point() +
geom_line() +
ylab("median time, s") +
theme_minimal()
DBI::dbDisconnect(con, shutdown = TRUE)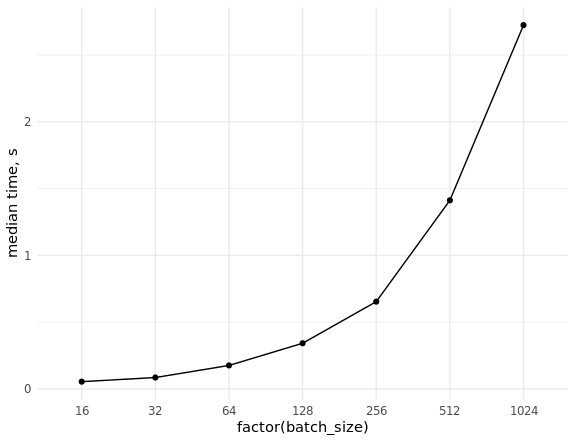
2. Подготовка батчей
Весь процесс подготовки батчей состоит из следующих этапов:
- Парсинг нескольких JSON-ов, содержащих векторы строк с координатами точек.
- Отрисовка цветных линий по координатам точек на изображении нужного размера (например, 256x256 или 128x128).
- Преобразование полученных изображений в тензор.
В рамках соревнования среди kernel-ов на Python задача решалась преимущественно средствами OpenCV. Один из наиболее простых и очевидных аналогов на R будет выглядеть следующим образом:
r_process_json_str <- function(json, line.width = 3,
color = TRUE, scale = 1) {
# Парсинг JSON
coords <- jsonlite::fromJSON(json, simplifyMatrix = FALSE)
tmp <- tempfile()
# Удаляем временный файл по завершению функции
on.exit(unlink(tmp))
png(filename = tmp, width = 256 * scale, height = 256 * scale, pointsize = 1)
# Пустой график
plot.new()
# Размер окна графика
plot.window(xlim = c(256 * scale, 0), ylim = c(256 * scale, 0))
# Цвета линий
cols <- if (color) rainbow(length(coords)) else "#000000"
for (i in seq_along(coords)) {
lines(x = coords[[i]][[1]] * scale, y = coords[[i]][[2]] * scale,
col = cols[i], lwd = line.width)
}
dev.off()
# Преобразование изображения в 3-х мерный массив
res <- png::readPNG(tmp)
return(res)
}
r_process_json_vector <- function(x, ...) {
res <- lapply(x, r_process_json_str, ...)
# Объединение 3-х мерных массивов картинок в 4-х мерный в тензор
res <- do.call(abind::abind, c(res, along = 0))
return(res)
}Рисование выполняется стандартными средствами R с сохранением во временный PNG, хранящийся в ОЗУ (в Linux временные директории R находятся в каталоге /tmp, смонтированном в ОЗУ). Затем этот файл считывается в виде трёхмерного массива с числами в диапазоне от 0 до 1. Это важно, поскольку более общепринятый BMP был бы прочитан в raw-массив с hex-кодами цветов.
Протестируем результат:
zip_file <- file.path("data", "train_simplified.zip")
csv_file <- "cat.csv"
unzip(zip_file, files = csv_file, exdir = tempdir(),
junkpaths = TRUE, unzip = getOption("unzip"))
tmp_data <- data.table::fread(file.path(tempdir(), csv_file), sep = ",",
select = "drawing", nrows = 10000)
arr <- r_process_json_str(tmp_data[4, drawing])
dim(arr)
# [1] 256 256 3
plot(magick::image_read(arr))
Сам батч будет формироваться следующим образом:
res <- r_process_json_vector(tmp_data[1:4, drawing], scale = 0.5)
str(res)
# num [1:4, 1:128, 1:128, 1:3] 1 1 1 1 1 1 1 1 1 1 ...
# - attr(*, "dimnames")=List of 4
# ..$ : NULL
# ..$ : NULL
# ..$ : NULL
# ..$ : NULLДанная реализация нам показалась неоптимальной, поскольку формирование больших батчей занимает неприлично много времени, и мы решили воспользоваться опытом коллег, задействовав мощную библиотеку OpenCV. На тот момент готового пакета для R не было (нет его и сейчас), поэтому была написана минимальная реализация требуемого функционала на C++ с интеграцией в код на R при помощи Rcpp.
Для решения задачи использовались следущие пакеты и библиотеки:
OpenCV для работы с изображениями и рисования линий. Использовали предварительно установленные системные библиотеки и заголовочные файлы, а также динамическую линковку.
xtensor для работы с многомерными массивами и тензорами. Использовали заголовочные файлы, включённые в одноимённый R-пакет. Библиотека позволяет работать с многомерными массивами, причём как в row major, так и в column major порядке.
ndjson для парсинга JSON. Данная библиотека используется в xtensor автоматически при её наличии в проекте.
RcppThread для организации многопоточной обработки вектора из JSON-ов. Использовали заголовочные файлы, предоставляемые этим пакетом. От более популярного RcppParallel пакет среди прочего отличается встроенным механизмом прерывания цикла (interrupt).
Стоит отметить, что xtensor оказался просто находкой: кроме того, что он обладает обширным функционалом и высокой производительностью, его разработчики оказались довольно отзывчивыми и оперативно и подробно отвечали на возникающие вопросы. С их помощью удалось реализовать преобразования матриц OpenCV в тензоры xtensor, а также способ объединения 3-х мерных тензоров изображений в 4-х мерный тензор правильной размерности (собственно батч).
https://thecoatlessprofessor.com/programming/unofficial-rcpp-api-documentation
https://docs.opencv.org/4.0.1/d7/dbd/group__imgproc.html
https://xtensor.readthedocs.io/en/latest/
https://xtensor.readthedocs.io/en/latest/file_loading.html#loading-json-data-into-xtensor
https://cran.r-project.org/web/packages/RcppThread/vignettes/RcppThread-vignette.pdf
Для компиляции файлов, использующих системные файлы и динамическую линковку с установленными в системе библиотеками, мы воспользовались механизмом плагинов, реализованным в пакете Rcpp. Для автоматического нахождения путей и флагов использовали популярную linux-утилиту pkg-config.
Rcpp::registerPlugin("opencv", function() {
# Возможные названия пакета
pkg_config_name <- c("opencv", "opencv4")
# Бинарный файл утилиты pkg-config
pkg_config_bin <- Sys.which("pkg-config")
# Проврека наличия утилиты в системе
checkmate::assert_file_exists(pkg_config_bin, access = "x")
# Проверка наличия файла настроек OpenCV для pkg-config
check <- sapply(pkg_config_name,
function(pkg) system(paste(pkg_config_bin, pkg)))
if (all(check != 0)) {
stop("OpenCV config for the pkg-config not found", call. = FALSE)
}
pkg_config_name <- pkg_config_name[check == 0]
list(env = list(
PKG_CXXFLAGS = system(paste(pkg_config_bin, "--cflags", pkg_config_name),
intern = TRUE),
PKG_LIBS = system(paste(pkg_config_bin, "--libs", pkg_config_name),
intern = TRUE)
))
})В результате работы плагина в процессе компиляции будут подставлены следующие значения:
Rcpp:::.plugins$opencv()$env
# $PKG_CXXFLAGS
# [1] "-I/usr/include/opencv"
#
# $PKG_LIBS
# [1] "-lopencv_shape -lopencv_stitching -lopencv_superres -lopencv_videostab -lopencv_aruco -lopencv_bgsegm -lopencv_bioinspired -lopencv_ccalib -lopencv_datasets -lopencv_dpm -lopencv_face -lopencv_freetype -lopencv_fuzzy -lopencv_hdf -lopencv_line_descriptor -lopencv_optflow -lopencv_video -lopencv_plot -lopencv_reg -lopencv_saliency -lopencv_stereo -lopencv_structured_light -lopencv_phase_unwrapping -lopencv_rgbd -lopencv_viz -lopencv_surface_matching -lopencv_text -lopencv_ximgproc -lopencv_calib3d -lopencv_features2d -lopencv_flann -lopencv_xobjdetect -lopencv_objdetect -lopencv_ml -lopencv_xphoto -lopencv_highgui -lopencv_videoio -lopencv_imgcodecs -lopencv_photo -lopencv_imgproc -lopencv_core"Код реализации парсинга JSON и формирования батча для передачи в модель приведён под спойлером. Предварительно добавляем локальную директорию проекта для поиска заголовочных файлов (нужно для ndjson):
Sys.setenv("PKG_CXXFLAGS" = paste0("-I", normalizePath(file.path("src"))))// [[Rcpp::plugins(cpp14)]]
// [[Rcpp::plugins(opencv)]]
// [[Rcpp::depends(xtensor)]]
// [[Rcpp::depends(RcppThread)]]
#include <xtensor/xjson.hpp>
#include <xtensor/xadapt.hpp>
#include <xtensor/xview.hpp>
#include <xtensor-r/rtensor.hpp>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <Rcpp.h>
#include <RcppThread.h>
// Синонимы для типов
using RcppThread::parallelFor;
using json = nlohmann::json;
using points = xt::xtensor<double,2>; // Извлечённые из JSON координаты точек
using strokes = std::vector<points>; // Извлечённые из JSON координаты точек
using xtensor3d = xt::xtensor<double, 3>; // Тензор для хранения матрицы изоображения
using xtensor4d = xt::xtensor<double, 4>; // Тензор для хранения множества изображений
using rtensor3d = xt::rtensor<double, 3>; // Обёртка для экспорта в R
using rtensor4d = xt::rtensor<double, 4>; // Обёртка для экспорта в R
// Статические константы
// Размер изображения в пикселях
const static int SIZE = 256;
// Тип линии
// См. https://en.wikipedia.org/wiki/Pixel_connectivity#2-dimensional
const static int LINE_TYPE = cv::LINE_4;
// Толщина линии в пикселях
const static int LINE_WIDTH = 3;
// Алгоритм ресайза
// https://docs.opencv.org/3.1.0/da/d54/group__imgproc__transform.html#ga5bb5a1fea74ea38e1a5445ca803ff121
const static int RESIZE_TYPE = cv::INTER_LINEAR;
// Шаблон для конвертирования OpenCV-матрицы в тензор
template <typename T, int NCH, typename XT=xt::xtensor<T,3,xt::layout_type::column_major>>
XT to_xt(const cv::Mat_<cv::Vec<T, NCH>>& src) {
// Размерность целевого тензора
std::vector<int> shape = {src.rows, src.cols, NCH};
// Общее количество элементов в массиве
size_t size = src.total() * NCH;
// Преобразование cv::Mat в xt::xtensor
XT res = xt::adapt((T*) src.data, size, xt::no_ownership(), shape);
return res;
}
// Преобразование JSON в список координат точек
strokes parse_json(const std::string& x) {
auto j = json::parse(x);
// Результат парсинга должен быть массивом
if (!j.is_array()) {
throw std::runtime_error("'x' must be JSON array.");
}
strokes res;
res.reserve(j.size());
for (const auto& a: j) {
// Каждый элемент массива должен быть 2-мерным массивом
if (!a.is_array() || a.size() != 2) {
throw std::runtime_error("'x' must include only 2d arrays.");
}
// Извлечение вектора точек
auto p = a.get<points>();
res.push_back(p);
}
return res;
}
// Отрисовка линий
// Цвета HSV
cv::Mat ocv_draw_lines(const strokes& x, bool color = true) {
// Исходный тип матрицы
auto stype = color ? CV_8UC3 : CV_8UC1;
// Итоговый тип матрицы
auto dtype = color ? CV_32FC3 : CV_32FC1;
auto bg = color ? cv::Scalar(0, 0, 255) : cv::Scalar(255);
auto col = color ? cv::Scalar(0, 255, 220) : cv::Scalar(0);
cv::Mat img = cv::Mat(SIZE, SIZE, stype, bg);
// Количество линий
size_t n = x.size();
for (const auto& s: x) {
// Количество точек в линии
size_t n_points = s.shape()[1];
for (size_t i = 0; i < n_points - 1; ++i) {
// Точка начала штриха
cv::Point from(s(0, i), s(1, i));
// Точка окончания штриха
cv::Point to(s(0, i + 1), s(1, i + 1));
// Отрисовка линии
cv::line(img, from, to, col, LINE_WIDTH, LINE_TYPE);
}
if (color) {
// Меняем цвет линии
col[0] += 180 / n;
}
}
if (color) {
// Меняем цветовое представление на RGB
cv::cvtColor(img, img, cv::COLOR_HSV2RGB);
}
// Меняем формат представления на float32 с диапазоном [0, 1]
img.convertTo(img, dtype, 1 / 255.0);
return img;
}
// Обработка JSON и получение тензора с данными изображения
xtensor3d process(const std::string& x, double scale = 1.0, bool color = true) {
auto p = parse_json(x);
auto img = ocv_draw_lines(p, color);
if (scale != 1) {
cv::Mat out;
cv::resize(img, out, cv::Size(), scale, scale, RESIZE_TYPE);
cv::swap(img, out);
out.release();
}
xtensor3d arr = color ? to_xt<double,3>(img) : to_xt<double,1>(img);
return arr;
}
// [[Rcpp::export]]
rtensor3d cpp_process_json_str(const std::string& x,
double scale = 1.0,
bool color = true) {
xtensor3d res = process(x, scale, color);
return res;
}
// [[Rcpp::export]]
rtensor4d cpp_process_json_vector(const std::vector<std::string>& x,
double scale = 1.0,
bool color = false) {
size_t n = x.size();
size_t dim = floor(SIZE * scale);
size_t channels = color ? 3 : 1;
xtensor4d res({n, dim, dim, channels});
parallelFor(0, n, [&x, &res, scale, color](int i) {
xtensor3d tmp = process(x[i], scale, color);
auto view = xt::view(res, i, xt::all(), xt::all(), xt::all());
view = tmp;
});
return res;
}Этот код следует поместить в файл src/cv_xt.cpp и скомпилировать командой Rcpp::sourceCpp(file = "src/cv_xt.cpp", env = .GlobalEnv); также для работы потребуется nlohmann/json.hpp из репозитория. Код разделён на несколько функций:
to_xt— шаблонизированная фукнция для преобразования матрицы изображения (cv::Mat) в тензорxt::xtensor;
parse_json— функция парсит JSON-строку, извлекает координаты точек, упаковывая их в вектор;
ocv_draw_lines— из полученного вектор точек отрисовывает разноцветные линии;
process— объединяет вышеописанные функции, а также добавляет возможность шкалирования полученного изображения;
cpp_process_json_str— обёртка над функциейprocess, которая экспортирует результат в R-объект (многомерный массив);
cpp_process_json_vector— обёртка над функциейcpp_process_json_str, которая позволяет обрабатывать строковый вектор в многопоточном режиме.
Для отрисовки разноцветных линий использовалась цветовая модель HSV с последующей конвертацией в RGB. Протестируем результат:
arr <- cpp_process_json_str(tmp_data[4, drawing])
dim(arr)
# [1] 256 256 3
plot(magick::image_read(arr))
res_bench <- bench::mark(
r_process_json_str(tmp_data[4, drawing], scale = 0.5),
cpp_process_json_str(tmp_data[4, drawing], scale = 0.5),
check = FALSE,
min_iterations = 100
)
# Параметры бенчмарка
cols <- c("expression", "min", "median", "max", "itr/sec", "total_time", "n_itr")
res_bench[, cols]
# expression min median max `itr/sec` total_time n_itr
# <chr> <bch:tm> <bch:tm> <bch:tm> <dbl> <bch:tm> <int>
# 1 r_process_json_str 3.49ms 3.55ms 4.47ms 273. 490ms 134
# 2 cpp_process_json_str 1.94ms 2.02ms 5.32ms 489. 497ms 243
library(ggplot2)
# Проведение замера
res_bench <- bench::press(
batch_size = 2^(4:10),
{
.data <- tmp_data[sample(seq_len(.N), batch_size), drawing]
bench::mark(
r_process_json_vector(.data, scale = 0.5),
cpp_process_json_vector(.data, scale = 0.5),
min_iterations = 50,
check = FALSE
)
}
)
res_bench[, cols]
# expression batch_size min median max `itr/sec` total_time n_itr
# <chr> <dbl> <bch:tm> <bch:tm> <bch:tm> <dbl> <bch:tm> <int>
# 1 r 16 50.61ms 53.34ms 54.82ms 19.1 471.13ms 9
# 2 cpp 16 4.46ms 5.39ms 7.78ms 192. 474.09ms 91
# 3 r 32 105.7ms 109.74ms 212.26ms 7.69 6.5s 50
# 4 cpp 32 7.76ms 10.97ms 15.23ms 95.6 522.78ms 50
# 5 r 64 211.41ms 226.18ms 332.65ms 3.85 12.99s 50
# 6 cpp 64 25.09ms 27.34ms 32.04ms 36.0 1.39s 50
# 7 r 128 534.5ms 627.92ms 659.08ms 1.61 31.03s 50
# 8 cpp 128 56.37ms 58.46ms 66.03ms 16.9 2.95s 50
# 9 r 256 1.15s 1.18s 1.29s 0.851 58.78s 50
# 10 cpp 256 114.97ms 117.39ms 130.09ms 8.45 5.92s 50
# 11 r 512 2.09s 2.15s 2.32s 0.463 1.8m 50
# 12 cpp 512 230.81ms 235.6ms 261.99ms 4.18 11.97s 50
# 13 r 1024 4s 4.22s 4.4s 0.238 3.5m 50
# 14 cpp 1024 410.48ms 431.43ms 462.44ms 2.33 21.45s 50
ggplot(res_bench, aes(x = factor(batch_size), y = median,
group = expression, color = expression)) +
geom_point() +
geom_line() +
ylab("median time, s") +
theme_minimal() +
scale_color_discrete(name = "", labels = c("cpp", "r")) +
theme(legend.position = "bottom") 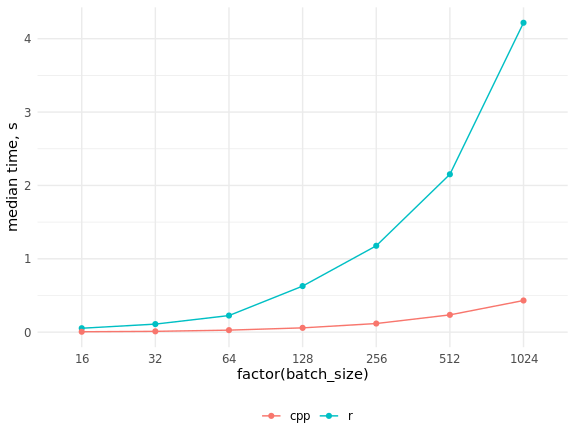
Как видим, прирост скорости оказался очень значительным, и догнать код на C++ при помощи параллелизации кода на R не представляется возможным.
3. Итераторы для выгрузки батчей из БД
R имеет заслуженную репутацию языка для обработки данных, помещающихся в ОЗУ, в то время как для Питона более характерна итеративная обработка данных, позволяющая легко и непринужденно реализовывать out-of-core вычисления (вычисления с использованием внешней памяти). Классическим и актуальным для нас в контексте описываемой задачи примером таких вычислений являются глубокие нейронные сети, обучаемые методом градиентного спуска с аппроксимацией градиента на каждом шаге по небольшой порции наблюдений, или мини-батчу.
Фреймворки для глубокого обучения, написанные на Python, имеют специальные классы, реализующие итераторы по данным: таблицами, картинкам в папках, бинарным форматам и пр. Можно использовать готовые варианты или же писать свои собственные для специфических задач. В R мы можем воспользоваться всеми возможностями питоновской библиотеки keras с его различными бекендами при помощи одноименного пакета, в свою очередь работающего поверх пакета reticulate. Последний заслуживает отдельной большой статьи; он не только позволяет запускать код на Python из R, но и обеспечивает передачу объектов между R- и Python-сессиями, автомагически выполняя все необходимые преобразования типов.
От необходимости хранить все данные в ОЗУ мы избавились за счет использования MonetDBLite, всю "нейросетевую" работу будет выполнять оригинальный код на Python, нам остается лишь написать итератор по данным, поскольку готового для такой ситуации нет ни на R, ни на Python. Требований к нему по сути всего два: он должен возвращать батчи в бесконечном цикле и сохранять свое состояние между итерациями (последнее в R простейшим образом реализуется при помощи замыканий). Ранее требовалось внутри итератора явным образом преобразовывать массивы R в numpy-массивы, но актуальная версия пакета keras делает это сама.
Итератор для обучающих и валидационных данных получился следующим:
train_generator <- function(db_connection = con,
samples_index,
num_classes = 340,
batch_size = 32,
scale = 1,
color = FALSE,
imagenet_preproc = FALSE) {
# Проверка аргументов
checkmate::assert_class(con, "DBIConnection")
checkmate::assert_integerish(samples_index)
checkmate::assert_count(num_classes)
checkmate::assert_count(batch_size)
checkmate::assert_number(scale, lower = 0.001, upper = 5)
checkmate::assert_flag(color)
checkmate::assert_flag(imagenet_preproc)
# Перемешиваем, чтобы брать и удалять использованные индексы батчей по порядку
dt <- data.table::data.table(id = sample(samples_index))
# Проставляем номера батчей
dt[, batch := (.I - 1L) %/% batch_size + 1L]
# Оставляем только полные батчи и индексируем
dt <- dt[, if (.N == batch_size) .SD, keyby = batch]
# Устанавливаем счётчик
i <- 1
# Количество батчей
max_i <- dt[, max(batch)]
# Подготовка выражения для выгрузки
sql <- sprintf(
"PREPARE SELECT drawing, label_int FROM doodles WHERE id IN (%s)",
paste(rep("?", batch_size), collapse = ",")
)
res <- DBI::dbSendQuery(con, sql)
# Аналог keras::to_categorical
to_categorical <- function(x, num) {
n <- length(x)
m <- numeric(n * num)
m[x * n + seq_len(n)] <- 1
dim(m) <- c(n, num)
return(m)
}
# Замыкание
function() {
# Начинаем новую эпоху
if (i > max_i) {
dt[, id := sample(id)]
data.table::setkey(dt, batch)
# Сбрасываем счётчик
i <<- 1
max_i <<- dt[, max(batch)]
}
# ID для выгрузки данных
batch_ind <- dt[batch == i, id]
# Выгрузка данных
batch <- DBI::dbFetch(DBI::dbBind(res, as.list(batch_ind)), n = -1)
# Увеличиваем счётчик
i <<- i + 1
# Парсинг JSON и подготовка массива
batch_x <- cpp_process_json_vector(batch$drawing, scale = scale, color = color)
if (imagenet_preproc) {
# Шкалирование c интервала [0, 1] на интервал [-1, 1]
batch_x <- (batch_x - 0.5) * 2
}
batch_y <- to_categorical(batch$label_int, num_classes)
result <- list(batch_x, batch_y)
return(result)
}
}Функция принимает на вход переменную с соединением с БД, номера используемых строк, число классов, размер батча, масштаб (scale = 1 соответствует отрисовке картинок 256х256 пикселей, scale = 0.5 — 128х128 пикселей), индикатор цветности (color = FALSE задает отрисовку в оттенках серого, при использовании color = TRUE каждый штрих рисуется новым цветом) и индикатор препроцессинга для сетей, предобученных на imagenet-е. Последний нужен для того, чтобы отшкалировать значения пикселей с интервала [0, 1] на интервал [-1, 1], который использовался при обучении поставляемых в составе keras моделей.
Внешняя функция содержит проверку типов аргументов, таблицу data.table со случайным образом перемешанными номерами строк из samples_index и номерами батчей, счетчик и максимальное число батчей, а также SQL-выражение для выгрузки данных из БД. Дополнительно мы определили внутри быстрый аналог функции keras::to_categorical(). Мы использовали для обучения почти все данные, оставив полпроцента для валидации, поэтому размер эпохи ограничивался параметром steps_per_epoch при вызове keras::fit_generator(), и условие if (i > max_i) срабатывало только для валидационного итератора.
Во внутренней функции происходит выборка индексов строк для очередного батча, выгрузка записей из БД с увеличением счетчика батчей, парсинг JSON-ов (функция cpp_process_json_vector(), написанная на C++) и создание массивов, соответствующих картинкам. Затем создаются one-hot векторы с метками классов, массивы со значениями пикселей и с метками объединяются в список, который и является возвращаемым значением. Для ускорения работы использовалось создание индексов в таблицах data.table и модификация по ссылке — без этих "фишек" пакета data.table довольно трудно представить эффективную работу со сколько-нибудь значительными объемами данных в R.
Результаты замеров скорости работы на ноутбучном Core i5 выглядят следующим образом:
library(Rcpp)
library(keras)
library(ggplot2)
source("utils/rcpp.R")
source("utils/keras_iterator.R")
con <- DBI::dbConnect(drv = MonetDBLite::MonetDBLite(), Sys.getenv("DBDIR"))
ind <- seq_len(DBI::dbGetQuery(con, "SELECT count(*) FROM doodles")[[1L]])
num_classes <- DBI::dbGetQuery(con, "SELECT max(label_int) + 1 FROM doodles")[[1L]]
# Индексы для обучающей выборки
train_ind <- sample(ind, floor(length(ind) * 0.995))
# Индексы для проверочной выборки
val_ind <- ind[-train_ind]
rm(ind)
# Коэффициент масштаба
scale <- 0.5
# Проведение замера
res_bench <- bench::press(
batch_size = 2^(4:10),
{
it1 <- train_generator(
db_connection = con,
samples_index = train_ind,
num_classes = num_classes,
batch_size = batch_size,
scale = scale
)
bench::mark(
it1(),
min_iterations = 50L
)
}
)
# Параметры бенчмарка
cols <- c("batch_size", "min", "median", "max", "itr/sec", "total_time", "n_itr")
res_bench[, cols]
# batch_size min median max `itr/sec` total_time n_itr
# <dbl> <bch:tm> <bch:tm> <bch:tm> <dbl> <bch:tm> <int>
# 1 16 25ms 64.36ms 92.2ms 15.9 3.09s 49
# 2 32 48.4ms 118.13ms 197.24ms 8.17 5.88s 48
# 3 64 69.3ms 117.93ms 181.14ms 8.57 5.83s 50
# 4 128 157.2ms 240.74ms 503.87ms 3.85 12.71s 49
# 5 256 359.3ms 613.52ms 988.73ms 1.54 30.5s 47
# 6 512 884.7ms 1.53s 2.07s 0.674 1.11m 45
# 7 1024 2.7s 3.83s 5.47s 0.261 2.81m 44
ggplot(res_bench, aes(x = factor(batch_size), y = median, group = 1)) +
geom_point() +
geom_line() +
ylab("median time, s") +
theme_minimal()
DBI::dbDisconnect(con, shutdown = TRUE)
Если имеется достаточный объем ОЗУ, можно серьезно ускорить работу базы данных путем ее переноса в эту самую ОЗУ (для нашей задачи хватает 32 Гб). В линуксе по умолчанию монтируется раздел /dev/shm, занимающий до половины объема ОЗУ. Можно выделить и больше, отредактировав /etc/fstab, чтобы получилась запись вида tmpfs /dev/shm tmpfs defaults,size=25g 0 0. Обязательно перезагружаемся и проверяем результат, выполнив команду df -h.
Итератор для тестовых данных выглядит гораздо проще, поскольку тестовый датасет целиком помещается в ОЗУ:
test_generator <- function(dt,
batch_size = 32,
scale = 1,
color = FALSE,
imagenet_preproc = FALSE) {
# Проверка аргументов
checkmate::assert_data_table(dt)
checkmate::assert_count(batch_size)
checkmate::assert_number(scale, lower = 0.001, upper = 5)
checkmate::assert_flag(color)
checkmate::assert_flag(imagenet_preproc)
# Проставляем номера батчей
dt[, batch := (.I - 1L) %/% batch_size + 1L]
data.table::setkey(dt, batch)
i <- 1
max_i <- dt[, max(batch)]
# Замыкание
function() {
batch_x <- cpp_process_json_vector(dt[batch == i, drawing],
scale = scale, color = color)
if (imagenet_preproc) {
# Шкалирование c интервала [0, 1] на интервал [-1, 1]
batch_x <- (batch_x - 0.5) * 2
}
result <- list(batch_x)
i <<- i + 1
return(result)
}
}4. Выбор архитектуры модели
Первой из использованных архитектур была mobilenet v1, особенности которой разобраны в этом сообщении. Она присутствует в стандартной поставке keras и, соответственно, доступна в одноименном пакете для R. Но при попытке использовать ее с одноканальными изображениями выяснилось странное: входной тензор должен всегда иметь размерность (batch, height, width, 3), то есть число каналов поменять нельзя. В Python такого ограничения нет, поэтому мы поспешили и написали свою реализацию данной архитектуры, следуя оригинальной статье (без дропаута, который есть в keras-овском варианте):
library(keras)
top_3_categorical_accuracy <- custom_metric(
name = "top_3_categorical_accuracy",
metric_fn = function(y_true, y_pred) {
metric_top_k_categorical_accuracy(y_true, y_pred, k = 3)
}
)
layer_sep_conv_bn <- function(object,
filters,
alpha = 1,
depth_multiplier = 1,
strides = c(2, 2)) {
# NB! depth_multiplier != resolution multiplier
# https://github.com/keras-team/keras/issues/10349
layer_depthwise_conv_2d(
object = object,
kernel_size = c(3, 3),
strides = strides,
padding = "same",
depth_multiplier = depth_multiplier
) %>%
layer_batch_normalization() %>%
layer_activation_relu() %>%
layer_conv_2d(
filters = filters * alpha,
kernel_size = c(1, 1),
strides = c(1, 1)
) %>%
layer_batch_normalization() %>%
layer_activation_relu()
}
get_mobilenet_v1 <- function(input_shape = c(224, 224, 1),
num_classes = 340,
alpha = 1,
depth_multiplier = 1,
optimizer = optimizer_adam(lr = 0.002),
loss = "categorical_crossentropy",
metrics = c("categorical_crossentropy",
top_3_categorical_accuracy)) {
inputs <- layer_input(shape = input_shape)
outputs <- inputs %>%
layer_conv_2d(filters = 32, kernel_size = c(3, 3), strides = c(2, 2), padding = "same") %>%
layer_batch_normalization() %>%
layer_activation_relu() %>%
layer_sep_conv_bn(filters = 64, strides = c(1, 1)) %>%
layer_sep_conv_bn(filters = 128, strides = c(2, 2)) %>%
layer_sep_conv_bn(filters = 128, strides = c(1, 1)) %>%
layer_sep_conv_bn(filters = 256, strides = c(2, 2)) %>%
layer_sep_conv_bn(filters = 256, strides = c(1, 1)) %>%
layer_sep_conv_bn(filters = 512, strides = c(2, 2)) %>%
layer_sep_conv_bn(filters = 512, strides = c(1, 1)) %>%
layer_sep_conv_bn(filters = 512, strides = c(1, 1)) %>%
layer_sep_conv_bn(filters = 512, strides = c(1, 1)) %>%
layer_sep_conv_bn(filters = 512, strides = c(1, 1)) %>%
layer_sep_conv_bn(filters = 512, strides = c(1, 1)) %>%
layer_sep_conv_bn(filters = 1024, strides = c(2, 2)) %>%
layer_sep_conv_bn(filters = 1024, strides = c(1, 1)) %>%
layer_global_average_pooling_2d() %>%
layer_dense(units = num_classes) %>%
layer_activation_softmax()
model <- keras_model(
inputs = inputs,
outputs = outputs
)
model %>% compile(
optimizer = optimizer,
loss = loss,
metrics = metrics
)
return(model)
}Недостатки такого подхода очевидны. Моделей хочется проверить много, а переписывать каждую архитектуру вручную, наоборот, не хочется. Также мы были лишены возможности использовать веса моделей, предварительно обученных на imagenet-е. Как обычно, помогло изучение документации. Функция get_config() позволяет получить описание модели в пригодном для редактирования виде (base_model_conf$layers — обычный R-овский список), а функция from_config() выполняет обратное преобразование в модельный объект:
base_model_conf <- get_config(base_model)
base_model_conf$layers[[1]]$config$batch_input_shape[[4]] <- 1L
base_model <- from_config(base_model_conf)Теперь не составляет труда написать универсальную функцию для получения любой из поставляемых в составе keras моделей с обученными на imagenet-е весами или без них:
get_model <- function(name = "mobilenet_v2",
input_shape = NULL,
weights = "imagenet",
pooling = "avg",
num_classes = NULL,
optimizer = keras::optimizer_adam(lr = 0.002),
loss = "categorical_crossentropy",
metrics = NULL,
color = TRUE,
compile = FALSE) {
# Проверка аргументов
checkmate::assert_string(name)
checkmate::assert_integerish(input_shape, lower = 1, upper = 256, len = 3)
checkmate::assert_count(num_classes)
checkmate::assert_flag(color)
checkmate::assert_flag(compile)
# Получаем объект из пакета keras
model_fun <- get0(paste0("application_", name), envir = asNamespace("keras"))
# Проверка наличия объекта в пакете
if (is.null(model_fun)) {
stop("Model ", shQuote(name), " not found.", call. = FALSE)
}
base_model <- model_fun(
input_shape = input_shape,
include_top = FALSE,
weights = weights,
pooling = pooling
)
# Если изображение не цветное, меняем размерность входа
if (!color) {
base_model_conf <- keras::get_config(base_model)
base_model_conf$layers[[1]]$config$batch_input_shape[[4]] <- 1L
base_model <- keras::from_config(base_model_conf)
}
predictions <- keras::get_layer(base_model, "global_average_pooling2d_1")$output
predictions <- keras::layer_dense(predictions, units = num_classes, activation = "softmax")
model <- keras::keras_model(
inputs = base_model$input,
outputs = predictions
)
if (compile) {
keras::compile(
object = model,
optimizer = optimizer,
loss = loss,
metrics = metrics
)
}
return(model)
}При использовании одноканальных изображений предобученные веса не используются. Это можно было бы исправить: при помощи функции get_weights() получить веса модели в виде списка из R-овских массивов, изменить размерность первого элемента этого списка (взяв какой-то один цветовой канал или усреднив все три), а затем загрузить веса обратно в модель функцией set_weights(). Мы этот функционал так и не добавили, поскольку на этом этапе уже было понятно, что продуктивнее работать с цветными картинками.
Основную массу экспериментов мы проделали с использованием mobilenet версии 1 и 2, а также resnet34. В этом соревновании хорошо себя показали более современные архитектуры, такие как SE-ResNeXt. К сожалению, в нашем распоряжении готовых реализаций не было, а свои собственные мы не написали (но обязательно напишем).
5. Параметризация скриптов
Для удобства весь код для запуска обучения был оформлен в виде единственного скрипта, параметризованного при помощи docopt следующим образом:
doc <- '
Usage:
train_nn.R --help
train_nn.R --list-models
train_nn.R [options]
Options:
-h --help Show this message.
-l --list-models List available models.
-m --model=<model> Neural network model name [default: mobilenet_v2].
-b --batch-size=<size> Batch size [default: 32].
-s --scale-factor=<ratio> Scale factor [default: 0.5].
-c --color Use color lines [default: FALSE].
-d --db-dir=<path> Path to database directory [default: Sys.getenv("db_dir")].
-r --validate-ratio=<ratio> Validate sample ratio [default: 0.995].
-n --n-gpu=<number> Number of GPUs [default: 1].
'
args <- docopt::docopt(doc)Пакет docopt представляет собой реализацию http://docopt.org/ для R. С его помощью скрипты запускаются простыми командами вида Rscript bin/train_nn.R -m resnet50 -c -d /home/andrey/doodle_db или ./bin/train_nn.R -m resnet50 -c -d /home/andrey/doodle_db, если файл train_nn.R является исполняемым (эта команда запустит обучение модели resnet50 на трехцветных изображениях размеров 128х128 пикселей, база данных должна находиться в папке /home/andrey/doodle_db). В список можно добавить скорость обучения, вид оптимизатора и любые другие настраиваемые параметры. В процессе подготовки публикации выяснилось, что архитектуру mobilenet_v2 из актуальной версии keras в R использовать нельзя из-за неучтенных в R-пакете изменений — ждем, пока пофиксят.
Этот подход позволил значительно ускорить эксперименты с разными моделями по сравнению с более традиционным запуском скриптов в RStudio (в качестве возможной альтернативы отметим пакет tfruns). Но главное преимущество состоит в возможности легко управлять запуском скриптов в докере или просто на сервере, не устанавливая для этого RStudio.
6. Докеризация скриптов
Мы использовали докер с целью обеспечения переносимости среды для обучения моделей между членами команды и для оперативного развёртывания в облаке. Начать знакомство с этим относительно непривычным для R-программиста инструментом можно с этой серии публикаций или с видеокурса.
Докер позволяет как создавать собственные образы «с нуля», так и использовать другие образы в качестве основы для создания собственных. При анализе имеющихся вариантов мы пришли к выводу, что установка драйверов NVIDIA, CUDA+cuDNN и питоновских библиотек — довольно объёмная часть образа, и решили взять за основу официальный образ tensorflow/tensorflow:1.12.0-gpu, добавив туда необходимые R-пакеты.
Итоговый докер-файл получился таким:
FROM tensorflow/tensorflow:1.12.0-gpu
MAINTAINER Artem Klevtsov <a.a.klevtsov@gmail.com>
SHELL ["/bin/bash", "-c"]
ARG LOCALE="en_US.UTF-8"
ARG APT_PKG="libopencv-dev r-base r-base-dev littler"
ARG R_BIN_PKG="futile.logger checkmate data.table rcpp rapidjsonr dbi keras jsonlite curl digest remotes"
ARG R_SRC_PKG="xtensor RcppThread docopt MonetDBLite"
ARG PY_PIP_PKG="keras"
ARG DIRS="/db /app /app/data /app/models /app/logs"
RUN source /etc/os-release && \
echo "deb https://cloud.r-project.org/bin/linux/ubuntu ${UBUNTU_CODENAME}-cran35/" > /etc/apt/sources.list.d/cran35.list && \
apt-key adv --keyserver keyserver.ubuntu.com --recv-keys E084DAB9 && \
add-apt-repository -y ppa:marutter/c2d4u3.5 && \
add-apt-repository -y ppa:timsc/opencv-3.4 && \
apt-get update && \
apt-get install -y locales && \
locale-gen ${LOCALE} && \
apt-get install -y --no-install-recommends ${APT_PKG} && \
ln -s /usr/lib/R/site-library/littler/examples/install.r /usr/local/bin/install.r && \
ln -s /usr/lib/R/site-library/littler/examples/install2.r /usr/local/bin/install2.r && \
ln -s /usr/lib/R/site-library/littler/examples/installGithub.r /usr/local/bin/installGithub.r && \
echo 'options(Ncpus = parallel::detectCores())' >> /etc/R/Rprofile.site && \
echo 'options(repos = c(CRAN = "https://cloud.r-project.org"))' >> /etc/R/Rprofile.site && \
apt-get install -y $(printf "r-cran-%s " ${R_BIN_PKG}) && \
install.r ${R_SRC_PKG} && \
pip install ${PY_PIP_PKG} && \
mkdir -p ${DIRS} && \
chmod 777 ${DIRS} && \
rm -rf /tmp/downloaded_packages/ /tmp/*.rds && \
rm -rf /var/lib/apt/lists/*
COPY utils /app/utils
COPY src /app/src
COPY tests /app/tests
COPY bin/*.R /app/
ENV DBDIR="/db"
ENV CUDA_HOME="/usr/local/cuda"
ENV PATH="/app:${PATH}"
WORKDIR /app
VOLUME /db
VOLUME /app
CMD bash
Для удобства используемые пакеты были вынесены в переменные; основная часть написанных скриптов копируется внутрь контейнеров при сборке. Также мы изменили командную оболочку на /bin/bash для удобства использования содержимого /etc/os-release. Это позволило избежать необходимости указывать версию ОС в коде.
Дополнительно был написан небольшой баш-скрипт, позволяющий запускать контейнер с различными командами. Например, это могут быть скрипты для обучения нейросетей, ранее помещенные внутрь контейнера, или же командная оболочка для отладки и мониторинга работы контейнера:
#!/bin/sh
DBDIR=${PWD}/db
LOGSDIR=${PWD}/logs
MODELDIR=${PWD}/models
DATADIR=${PWD}/data
ARGS="--runtime=nvidia --rm -v ${DBDIR}:/db -v ${LOGSDIR}:/app/logs -v ${MODELDIR}:/app/models -v ${DATADIR}:/app/data"
if [ -z "$1" ]; then
CMD="Rscript /app/train_nn.R"
elif [ "$1" = "bash" ]; then
ARGS="${ARGS} -ti"
else
CMD="Rscript /app/train_nn.R $@"
fi
docker run ${ARGS} doodles-tf ${CMD}Если этот баш-скрипт запустить без параметров, внутри контейнера будет вызван скрипт train_nn.R со значениями по умолчанию; если первый позиционный аргумент — это "bash", то контейнер запустится в интерактивном режиме с командной оболочкой. Во всех остальных случаях происходит подстановка значений позиционных аргументов: CMD="Rscript /app/train_nn.R $@".
Стоит обратить внимание, что директории с исходными данными и базой данных, а также директория для сохранения обученных моделей монтируются внутрь контейнера из хостовой системы, что позволяет получить доступ к результатам работы скриптов без лишних манипуляций.
7. Использование нескольких GPU в облаке Google Cloud
Одной из особенностей соревнования были весьма шумные данные (см. заглавную картинку, позаимствованную у @Leigh.plt из ODS-слака). Бороться с этим помогают батчи большого размера, и мы после экспериментов на ПК с 1 GPU решили освоить обучение моделей на нескольких GPU в облаке. Использовали GoogleCloud (хорошее руководство по основам работы) из-за большого выбора доступных конфигураций, приемлемых цен и бонусных $300. От жадности был заказан инстанс с 4хV100 с SSD и кучей ОЗУ, и это было большой ошибкой. Деньги такая машина кушает быстро, на экспериментах без отработанного пайплайна можно разориться. С учебными целями лучше брать K80. А вот большой объем ОЗУ пригодился — облачный SSD не впечатлил быстродейcтвием, поэтому базу данных при каждом запуске инстанса переносили на dev/shm.
Наибольший интерес представляет фрагмент кода, отвечающий за использование нескольких GPU. Сначала модель создается на CPU с использованием менеджера контекста, совсем как на Питоне:
with(tensorflow::tf$device("/cpu:0"), {
model_cpu <- get_model(
name = model_name,
input_shape = input_shape,
weights = weights,
metrics =(top_3_categorical_accuracy,
compile = FALSE
)
})Затем нескомпилированная (это важно) модель копируется на заданное количество доступных GPU, и лишь после этого компилируется:
model <- keras::multi_gpu_model(model_cpu, gpus = n_gpu)
keras::compile(
object = model,
optimizer = keras::optimizer_adam(lr = 0.0004),
loss = "categorical_crossentropy",
metrics = c(top_3_categorical_accuracy)
)Классический прием с заморозкой всех слоев, кроме последнего, обучением последнего слоя, разморозкой и дообучением модели целиком для нескольких GPU реализовать не удалось.
За обучением следили без использования tensorboard, ограничившись записью логов и сохранением моделей с информативными именами после каждой эпохи:
# Шаблон имени файла лога
log_file_tmpl <- file.path("logs", sprintf(
"%s_%d_%dch_%s.csv",
model_name,
dim_size,
channels,
format(Sys.time(), "%Y%m%d%H%M%OS")
))
# Шаблон имени файла модели
model_file_tmpl <- file.path("models", sprintf(
"%s_%d_%dch_{epoch:02d}_{val_loss:.2f}.h5",
model_name,
dim_size,
channels
))
callbacks_list <- list(
keras::callback_csv_logger(
filename = log_file_tmpl
),
keras::callback_early_stopping(
monitor = "val_loss",
min_delta = 1e-4,
patience = 8,
verbose = 1,
mode = "min"
),
keras::callback_reduce_lr_on_plateau(
monitor = "val_loss",
factor = 0.5, # уменьшаем lr в 2 раза
patience = 4,
verbose = 1,
min_delta = 1e-4,
mode = "min"
),
keras::callback_model_checkpoint(
filepath = model_file_tmpl,
monitor = "val_loss",
save_best_only = FALSE,
save_weights_only = FALSE,
mode = "min"
)
)8. Вместо заключения
Ряд проблем, с которыми мы столкнулись, победить пока не получилось:
- в keras нет готовой функции для автоматического поиска оптимальной скорости обучения (аналога
lr_finderв библиотеке fast.ai); приложив некоторые усилия, можно портировать на R сторонние реализации, например, эту; - как следствие предыдущего пункта, не получилось подобрать правильную скорость обучения при использовании нескольких GPU;
- не хватает современных архитектур нейросетей, особенно предобученных на imagenet-е;
- нет one cycle policy и discriminative learning rates (сosine annealing по нашей просьбе был реализован, спасибо skeydan).
Что полезного удалось вынести из этого соревнования:
- На относительно маломощном железе можно без боли работать с приличными (кратно превышающими размер ОЗУ) объемами данных. Пакет data.table экономит память за счет in-place модификации таблиц, что позволяет избежать их копирования, и при правильном использовании его возможностей почти всегда демонстрирует наибольшую скорость среди всех известных нам инструментов для скриптовых языков. Сохранение данных в БД позволяет во многих случаях вообще не думать о необходимости втискивать весь датасет в ОЗУ.
- Медленные функции на R можно заменить быстрыми на C++ при помощи пакета Rcpp. Если вдобавок использовать RcppThread или RcppParallel, получаем кроссплатформенные многопоточные реализации, поэтому код на уровне R параллелить не требуется.
- Пакетом Rcpp можно пользоваться без серьезных знаний C++, необходимый минимум изложен здесь. Заголовочные файлы для ряда крутых сишных библиотек типа xtensor доступны на CRAN, то есть формируется инфраструктура для реализации проектов, интегрирующих в R готовый высокопроизводительный код на C++. Дополнительное удобство — подсветка синтаксиса и статический анализатор кода на С++ в RStudio.
- docopt позволяет запускать самодостаточные скрипты с параметрами. Это удобно для использования на удаленном сервере, в т.ч. под докером. В RStudio проводить многочасовые эксперименты с обучением нейросетей неудобно, да и сама установка IDE на сервере не всегда оправдана.
- Докер обеспечивает переносимость кода и воспроизводимость результатов между разработчиками с разными версиями ОС и библиотек, а также простоту запуска на серверах. Запустить весь пайплайн для обучения можно всего одной командой.
- Google Cloud — бюджетный способ поэкспериментировать на дорогом железе, но нужно вдумчиво выбирать конфигурации.
- Замерять скорость работы отдельных фрагментов кода очень полезно, особенно при сочетании R и C++, а с пакетом bench — еще и очень легко.
В целом этот опыт был очень полезным, и мы продолжаем работать над решением некоторых из озвученных проблем.

![[Конспект админа] Как подружиться с DHCP и не бояться APIPA](/upload/resize_cache/iblock/bd6/105_70_0/bd6248e543dec95b2c5b3950042a7774.jpg "[Конспект админа] Как подружиться с DHCP и не бояться APIPA")

