
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Обработка дубликатов – одна из самых больных тем в работе аналитика. В нашей платформе мы стараемся по максимуму автоматизировать этот процесс, чтобы снизить нагрузку на экспертов НСИ и увеличить производительность коллег с обработкой данных. Сегодня мы рассмотрим, как платформа помогает сформировать единую золотую запись на примере одного из самых распространенных и основных справочников — справочника «контрагенты».
Рассмотрим один из типовых сценариев. Предположим, что крупный дистрибьютор B2B получает товар от разных поставщиков и и продает клиентам — юр. лицам. Если на практике с ведением поставщиком все более-менее хорошо, то вот обработка клиентской базы порой требует целой выделенной команды экспертов. Это связано с тем, что обычно в компаниях используется несколько систем-источников данных о клиентах: ERP, CRM, открытые источники и др. Работа особенно осложняется тогда, когда в компании существует несколько подразделений, каждое из которых ведет собственную клиентскую базу в рамках одной территории. В этом случае часть данных по клиентам дублируется в переделах одной базы, а также неявно пересекается между разными клиентскими базами. В ERP-системе требуется серьезная обработка записей-дубликатов для получения так называемой эталонной записи, с которой в дальнейшем можно работать. В платформе “Юнидата” существует специальный механизм поиска и обработки записей-дубликатов, который успешно справляется с такими задачами.
Приступим
Основу работы платформы составляет метамодель используемого домена. Домен – это структурированный набор реестров, справочников. их атрибутов и связей между ними, которые все вместе описывают структуру данных предметной области. О самой метамодели мы поговорим позже, а сейчас посмотрим, как платформа позволяет работать с дубликатами записей в существующей модели данных. В нашем примере есть реестр «контрагенты», где основными атрибутами являются: наименование контрагента (обычно краткое и полное), ИНН, КПП, юридический и фактический адреса, адрес регистрации ЮЛ, и т.д.
Для обработки дубликатов платформа использует механизм консолидации. Суть консолидации состоит в том, что мы настраиваем определенные правила поиска дубликатов, определяем источники данных и для каждого источника данных задаем специальные веса, которые отвечают за уровень доверия поступившей информации от системы источника, а затем происходит слияние найденных системой дубликатов в единую эталонную запись. При этом записи-дубликаты пропадают из поисковой выдачи, но остаются в истории эталонной записи. Все настройки выполняются в интерфейсе администратора платформы и не требуют программирования. Если объединение записей выполнено ошибочно, то всегда существует возможность отменить объединение. Таким образом, большую часть работы с дубликатами берет на себя сама система, пользователю остается только контролировать данный процесс. Рассмотрим применение механизма консолидации на кейсах обозначенного примера.
Допустим, в интеграционную шину компании ввели платформу «Юнидата», в которую поступают данные о контрагентах из CRM-системы, ERP-системы и системы мобильных продаж. Платформа убирает дубликаты, обогащает и гармонизирует данные, а затем передает эталонные записи в системы-получатели.
Кейс 1. Совпадение по ИНН и КПП
Самый простой способ найти дубликаты контрагентов – это сравнить их по ИНН и КПП, в большинстве случаев достаточно даже одного ИНН. Для реализации такого правила поиска дублированных записей достаточно настроить правило точного совпадения по атрибутам ИНН и КПП.
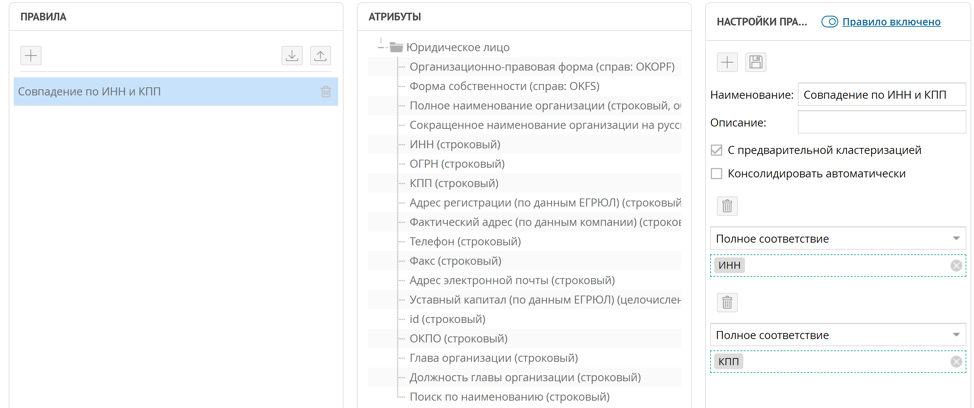
По такому правилу, когда в платформу поступает новая запись, автоматически запускается настроенное правило поиска дубликатов, если для правила установлена «предварительная кластеризация». Все найденные кортежи записей по совпадению ИНН и КПП собираются в кластеры дубликатов. В окне кластера дубликатов Unidata позволяет сформировать эталонную запись из записей-дубликатов.
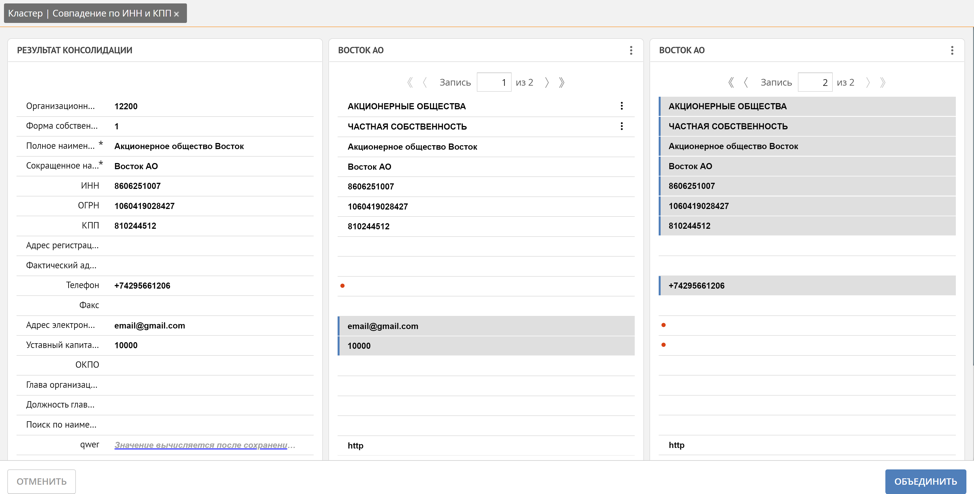
Здесь пользователь может вручную отследить, какая запись автоматически становится эталонной и при необходимости её скорректировать, вручную отметив значения атрибутов записей-дубликатов, которые должны войти в эталонную запись, или отметив всю запись целиком. Дополнительно Unidata поддерживает механизм обогащения недостающих значений на основании похожих записей. На примере телефон, почта и уставной капитал были автоматически получены из 2-х разных записей-дубликатов.
Как мы уже отметили, платформа при формировании кластера дубликатов автоматически определяет, как будет сформирована эталонная запись. Это происходит за счет упомянутых ранее весов доверия систем-источников. Чем выше вес системы, откуда поступила запись, тем значения её атрибутов более значимы для эталонной записи. Но часто бывают ситуации, когда значения определенных атрибутов для определенной системы-источника должны преобладать над всеми-другими, например, фактический адрес доставки клиента мы доверяем больше всего агенту, который непосредственно ведет переговоры на территории клиента и точно знает адрес, а значит в нашем примере системе мобильных продаж. Для решения таких задач в платформе существует возможность задавать веса не только для источников-данных, но и для атрибутов записи в разрезе каждого источника данных. Такая комбинация весов позволяет гибко настроить правила формирования эталонной записи.

Кейс 2. Нечеткое соответствие по наименованию ЮЛ
Хоть ИНН является обязательным атрибутом, но предположим, что по клиенту долго не обновлялась информация, у него произошла смена организационно-правовой формы. В этом случае в платформу придет уже запись с другим ИНН и совпадение по ИНН не сработает. В этом случае платформа позволяет сформировать правило нечеткого совпадения по значению атрибутов, в данном случае по наименованию ЮЛ.

Нечеткий поиск не имеет предварительной кластеризации, так как данная операция довольно ресурсоёмкая, а значит данное правило не сработает сразу при добавлении новой записи. Для запуска правил нечеткого поиска используется специальная операция поиска дубликатов, которая запускаются вручную администратором или системой по расписанию. После того, как дубли будут найдены, в специальном разделе интерфейса оператора данных можно будет посмотреть сформированные кластеры.
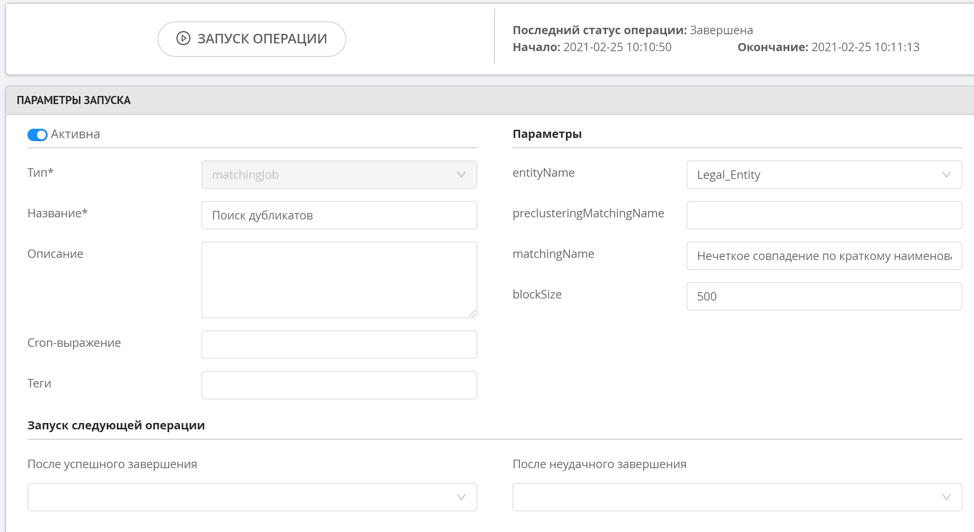

Нечеткий поиск дубликатов работает таким образом, что мы определяем похожие строковые значения, которые отличаются на 1-2 символа либо требуют не более двух перестановок (расстояние Левенштейна), так же есть возможность поиска по n-граммам. Такой подход позволяет с высокой точностью найти похожие записи, при этом не загружать ресурсы на вычисление всех возможных строковых манипуляций, в случае если строки сильно отличаются друг от друга.
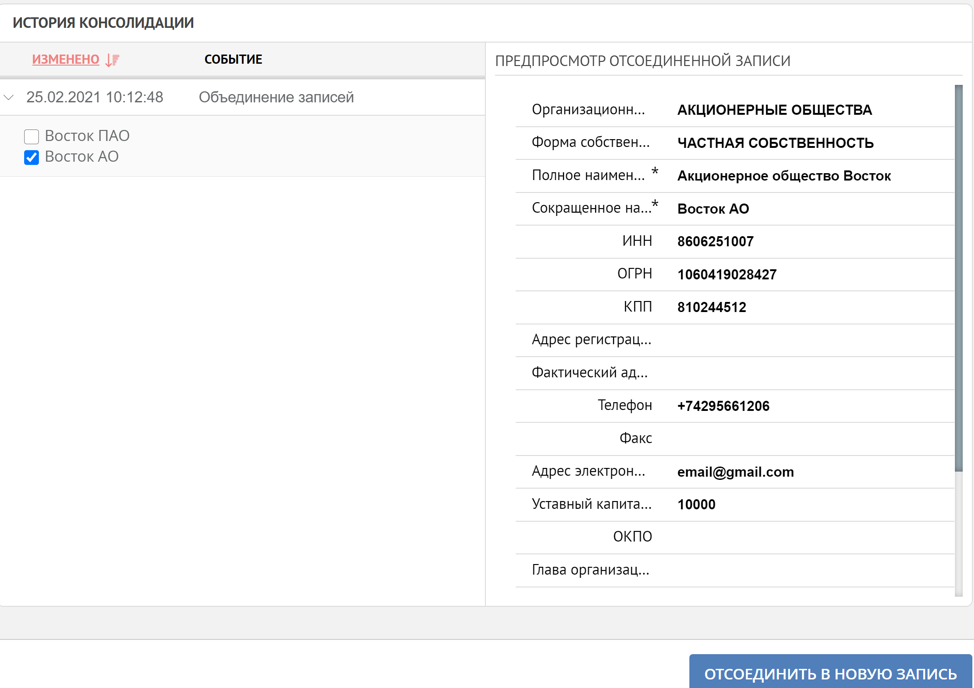
Таким образом, мы продемонстрировали в простых типовых кейсах принципы работы платформы при работе с дубликатами записей. Обработка дубликатов может выполняться как полностью под контролем пользователя, так и автоматически. В случае, если консолидация данных произошла ошибочно, то, как было упомянуто в начале, в системе всегда существует возможность посмотреть историю формирования эталонной записи и при необходимости запустить обратный процесс.
Мы не останавливаемся на достигнутом, исследуем новые алгоритмы и подходы при работе с дубликатами, стремимся обеспечить максимальное качество данных во множестве систем предприятия.


 файла в 1С-Битрикс")

