
Введение
В данной статье мы хотели бы рассказать о том, как мы в команде Wargaming Platform знакомились с BigQuery, о задаче, которую необходимо было решать, и проблемах, с которыми мы столкнулись. Кроме того, расскажем немного о ценообразовании и об инструментах, имеющихся в BigQuery, с которыми нам удалось поработать, а также предоставим наши рекомендации, как можно сэкономить бюджет во время работы с BigQuery.
Знакомство с BigQuery
BigQuery — это бессерверное, масштабируемое облачное хранилище данных с мощной инфраструктурой от Google, которое имеет на борту RESTful веб-сервис. Имеет тесное взаимодействие с другими сервисами от Google. Создатели обещают молниеносное выполнение запросов с максимальной задержкой в RESTful до 1 секунды. BigQuery поддерживает диалект Standard SQL. Имеется возможность контроля доступа к данным и разграничение прав пользователей. Также есть возможность задавать квоты и лимиты для операций с БД. Доступ к BigQuery возможен через Google Cloud Console, с помощью внутренней консоли BigQuery, а также через вызовы BigQuery REST API как напрямую, так и через различные клиентские библиотеки java, python, .net и многие другие.

Есть возможность подключения через ODBC/JDBC-драйвер с помощью Magnitude Simba ODBC. В состав BigQuery входит довольно мощный визуальный SQL-редактор, в котором можно увидеть историю выполнения запросов, проанализировать потребляемый объём данных, не выполняя запрос, что позволяет существенно сэкономить финансы.
Ценообразование
BigQuery предлагает несколько вариантов ценообразования в соответствии с техническими потребностями. Все расходы, связанные с выполнением заданий BigQuery в проекте, оплачиваются через привязанный платёжный аккаунт.
Затраты формируются из двух составляющих:
хранение данных
обработка данных во время выполнения запросов.
Стоимость хранения зависит от объёма данных, хранящихся в BigQuery.
Active. Ежемесячная плата за данные, хранящиеся в таблицах или разделах, которые были изменены за последние 90 дней. Плата за активное хранение данных составляет 0,020 $ за 1 ГБ, первые 10 ГБ — бесплатно каждый месяц. Стоимость хранилища рассчитывается пропорционально за МБ в секунду.
Long-term. Плата за данные, хранящиеся в таблицах или разделах, которые не были изменены в течение последних 90 дней. Если таблица не редактируется в течение 90 дней подряд, стоимость хранения этой таблицы автоматически снижается примерно на 50%.
Что касается затрат на запрос, вы можете выбрать одну из двух моделей ценообразования:
On-demand. Цена зависит от объёма данных, обрабатываемых каждым запросом. Стоимость каждого терабайта обработанных данных составляет 5,00 $. Первый обработанный 1 ТБ в месяц бесплатно, минимум 10 МБ обрабатываемых данных на таблицу, на которую ссылается запрос, и минимум 10 МБ обрабатываемых данных на запрос. Важный момент: оплата происходит за обработанные данные, а не за данные, полученные после выполнения запроса.
Flat-rate. Фиксированная цена. В данной модели выделяется фиксированная мощность на выполнение запросов. Запросы используют эту мощность, и вам не выставляется счёт за обработанные байты. Мощность измеряется в слотах. Минимальное количество слотов — 100. Стоимость за 100 слотов — 2000 $ в месяц.
Стоит заметить, что хранение данных часто обходится значительно дешевле, чем обработка данных в запросах.
Бесплатные операции:
Загрузка данных. Не нужно платить за загрузку данных из облачного хранилища или из локальных файлов в BigQuery.
Копирование данных. Не нужно платить за копирование данных из одной таблицы BigQuery в другую.
Экспорт данных. Не нужно платить за экспорт данных из других сервисов, например из Google Analytics (GA).
Удаление наборов данных (датасетов), таблиц, представлений, партиций и функций.
Операции с метаданными таблиц. Не нужно платить за редактирование метаданных.
Чтение данных из метатаблиц __PARTITIONS_SUMMARY__ и __TABLES_SUMMARY__.
Все операции UDF. Не нужно платить за операции создания, замены или вызова функций.
Wildcard-синтаксис
Wildcard-синтаксис позволяет выполнять запросы к нескольким таблицам, используя краткие операторы SQL. Wildcard-синтаксис доступен только в Standard SQL. Таблица с подстановочными знаками (wildcard) представляет собой объединение всех таблиц, соответствующих выражению с подстановочными знаками. Например, следующее предложение FROM использует выражение с подстановочными знаками table* для сопоставления всех таблиц в наборе данных test_dataset, которые начинаются со строки table:
FROM
`bq.test_dataset.table*`Запросы к таблице имеют следующие ограничения:
Не поддерживаются представления. Если таблица подстановочных знаков соответствует любому представлению в наборе данных, запрос возвращает ошибку. Это верно независимо от того, содержит ли ваш запрос WHERE в псевдостолбце _TABLE_SUFFIX для фильтрации представления.
В настоящее время кешированные результаты не поддерживаются для запросов к нескольким таблицам через wildcard-синтаксис, даже если установлен флажок «Использовать кешированные результаты». Если вы запускаете один и тот же запрос с подстановочными знаками несколько раз, вам будет выставлен счёт за каждый запрос.
Запросы, содержащие операторы DML, не могут использовать wildcard-синтаксис в таблицах в качестве цели запроса. Например, wildcard-синтаксис для таблиц может использоваться в предложении FROM запроса UPDATE, но не может использоваться в качестве цели операции UPDATE.
Wildcard-синтаксис для таблиц полезен, когда набор данных содержит несколько таблиц с одинаковыми именами, которые имеют совместимые схемы. Обычно такие наборы данных содержат таблицы, каждая из которых представляет данные за один день, месяц или год. Такой синтаксис полезен для сегментированных таблиц (sharded tables) — не путать с партиционированными таблицами.
Примеры использования:
Допустим, в BQ существуют набор данных test_dataset c таблицами, которые сегментированы по датам:
test_table_20200101
test_table_20200102
……...
test_table_20201231
Выборка всех записей за дату 2020-01-01:
select * from test_dataset.test_table_20200101Выборка всех записей за месяц:
select * from test_dataset.test_table_202001*Выборка всех записей за год:
select * from test_dataset.test_table_2020*Выборка всех записей за весь период:
select * from test_dataset.test_table_*Выборка всех записей из всего набора данных:
select * from test_dataset.*Для ограничения запроса таким образом, чтобы он просматривал произвольный набор таблиц, можно использовать псевдостолбец _TABLE_SUFFIX в предложении WHERE. Псевдостолбец _TABLE_SUFFIX содержит значения, соответствующие подстановочному знаку *. Например, чтобы получить все данные за 1 и 5 января, можно выполнить следующий запрос:
select *
from test_dataset.test_table_202001*
where _TABLE_SUFFIX="01" and _TABLE_SUFFIX="05"Партиционирование и шардирование таблиц
Партиционная таблица в BQ (partitioned table) — таблица, которая разделяется на сегменты (секции) по определённому признаку. Таблицы BigQuery можно разбивать на разделы по следующим признакам:
Ingestion Time. Таблицы разбиваются на разделы в зависимости от времени загрузки или времени поступления данных, которые содержат дополнительные зарезервированные поля _PARTITIONTIME, _PARTITIONDATE, хранящие дату создания записи.
Date/timestamp/datetime. Таблицы разбиты на разделы на основе столбца с типом timestamp, date или datetime. Если таблица партиционирована по столбцу с типом DATE, вы можете создавать партиции с ежедневной, ежемесячной или ежегодной гранулярностью. Каждый раздел содержит диапазон значений, где начало диапазона — это начало дня, месяца или года, а интервал диапазона составляет один день, месяц или год в зависимости от степени детализации разделения. Если таблица партиционирована по столбцам с типом TIMESTAMP или DATETIME, вы можете создавать разделы с любым типом гранулярности в единицах времени, включая HOUR.
Integer range. Таблицы разделены по целочисленному столбцу. BigQuery позволяет разбивать таблицы на разделы на основе определённого столбца INTEGER с указанием значений начала, конца и интервала. Запросы могут указывать фильтры предикатов на основе столбца секционирования, чтобы уменьшить объём сканируемых данных.
Шард-таблица в BQ (sharded table) — совокупность таблиц, имеющих одну схему и сегментированных по датам. Другими словами, под шард-таблицами понимается разделение больших наборов данных на отдельные таблицы и добавление суффикса к имени каждой таблицы. Имена таблиц имеют шаблон tablename_YYMMDD, где YYMMDD — шаблон даты. В отличие от партиционированных таблиц, шард-таблица не имеет колонки, по которой будет происходить сегментация данных. Обращение к шард-таблицам возможно с помощью синтаксиса wildcard-table. Шард-таблицы и запрос к ним с помощью оператора UNION могут имитировать партиционирование.
Партиционированные таблицы работают лучше, чем шард-таблицы. Когда вы создаёте шард-таблицы, BigQuery должен поддерживать копию схемы и метаданных для каждой таблицы с указанием даты. Кроме того, когда используются шард-таблицы с указанием даты, BigQuery может потребоваться для проверки разрешений для каждой запрашиваемой таблицы. Это влечёт за собой увеличение накладных расходов на запросы и влияет на производительность.
Кластеризация таблиц
Когда вы создаёте кластеризованную таблицу в BigQuery, данные таблицы автоматически сортируются на основе содержимого одного или нескольких столбцов в схеме таблицы. Указанные столбцы используются для размещения связанных данных. При кластеризации таблицы с использованием нескольких столбцов важен порядок указанных столбцов. Порядок указанных столбцов определяет порядок сортировки данных. Кластеризация может улучшить производительность определённых типов запросов, таких как запросы, использующие предложения фильтра, и запросы, которые объединяют данные. Когда данные записываются в кластеризованную таблицу, BigQuery сортирует данные, используя значения в столбцах кластеризации. Когда вы выполняете запрос, содержащий в фильтре данные на основе столбцов кластеризации, BigQuery использует отсортированные блоки, чтобы исключить сканирование ненужных данных. Вы можете не увидеть значительной разницы в производительности запросов между кластеризованной и некластеризованной таблицей, если размер таблицы или раздела меньше 1 ГБ.
Пример из жизни. Работа с GDPR
Нам пришлось столкнуться с задачей анонимизации данных по регламенту GDPR для Google Analytics (GA) в BigQuery. Задача заключалась в том, что каждый день в BigQuery импортировались данные из Google Analytics (GA). Поскольку в GA хранились персональные данные пользователей, для удалённых пользователей необходимо было очищать персональную информацию по регламенту GDPR. Данные, которые необходимо было анонимизировать, находились в поле с типом array. Аккаунт BigQuery, который нам предоставили, работал с ценовой моделью On-demand, в которой стоимость рассчитывалась из обработанных данных каждого запроса. Данные хранились в шард-таблицах. Google не рекомендует использовать шардированные таблицы и предлагает взамен партиционирование + кластеризацию, но, к сожалению, в Google Analytics (GA) это стандартная структура хранения данных. При экспорте данных из Google Analytics в BQ создаётся шард-таблица ga_sessions_, сегментированная по датам. В таблице находится порядка 16 полей, для нашей задачи необходимы были поля:
fullVisitorId (string) — уникальный идентификатор посетителя GA (также известный как идентификатор клиента)
customDimensions (array) — поле с типом array, содержит пользовательские данные, которые устанавливаются для каждого сеанса пользователя.
В поле customDimensions хранятся значения (идентификаторы), которые нам необходимо анонимизировать. Значения хранятся под определёнными индексами в массиве customDimensions.
Решение задачи
Мы создали в BQ таблицу opted_out_visitors для хранения пользователей, информацию о которых необходимо анонимизировать.
Схема таблицы:
[
{
"name": "fullVisitorId",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "date",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "customDimensions",
"type": "RECORD",
"mode": "REPEATED",
"fields": [
{
"name": "index",
"type": "INTEGER"
},
{
"name": "value",
"type": "STRING"
}
]
}
]В данной таблице мы храним копию данных из ga_sessions_, которые подпадают под регламент GDPR.
При получении запроса на удаление пользователя в нашей системе мы находили в таблицах GA данные пользователя для анонимизации и добавляли значения в таблицу opted_out_visitors:
INSERT INTO `dataset`.opted_out_visitors (
SELECT fullVisitorId, date, customDimensions
FROM `dataset`.`ga_sessions_*`, UNNEST(customDimensions) AS cd
WHERE cd.index=11 and cd.value="1111111")где cd.index=11 — индекс массива customDimensions, в котором хранятся идентификаторы пользователя, а cd.value="1111111" — идентификатор пользователя, данные которого необходимо почистить в таблицах GA. Собственно, в данной таблице мы имеем идентификатор пользователя в сеансе GA (fullVisitorId), данные пользователя (customDimensions) для анонимизации и дату, когда пользователь оставил за собой следы. После добавления данных в таблицу opted_out_visitors чистим значение, которое необходимо заменить.
UPDATE `dataset`.`opted_out_visitors`
SET customDimensions = ARRAY(
SELECT (index, IF(index = 3, "GDPR", value))
FROM UNNEST(customDimensions)
)
where 1=1Осталось почистить значения в оригинальных таблицах GA. Для этого мы раз в 7 дней запускаем скрипт, который обновляет данные в ga_sessions для каждой даты в opted_out_visitors:
MERGE `dataset`.`ga_sessions_20200112` S
USING `dataset`.`opted_out_visitors` O
ON S.fullVisitorId = O.fullVisitorId
WHEN MATCHED and O.date='20200112' THEN
UPDATE SET S.customDimensions = O.customDimensionsПосле этого очищаем таблицу opted_out_visitors.
Многие читатели могут подумать, зачем так запариваться, создавать отдельную таблицу opted_out_visitors, хранить там идентификаторы из ga_sessions с анонимизированными данными, а потом всё это мержить раз в N дней. Дело в том, что каждая таблица ga_sessions занимает около 10 ГБ, и с каждым днём количество таблиц увеличивалось. Если бы мы выполняли анонимизацию данных каждый раз при поступлении запроса на удаление, мы получили бы огромные затраты в BigQuery. Но и с данным подходом нам не удалось добиться минимальных затрат. После анализа всех запросов мы выявили, что проблемным местом является запрос поиска анонимных данных и добавления в таблицу opted_out_visitors.
INSERT INTO `dataset`.opted_out_visitors (
SELECT
fullVisitorId,
date,
customDimensions
FROM
`dataset`.`ga_sessions_*`,
UNNEST(customDimensions) AS cd
WHERE cd.index=11 and cd.value="1111111"
)В данном запросе мы обращаемся к таблице ga_sessions_ за весь период, откуда получаем данные из столбца customDimensions (напомним, что этот столбец имеет тип array, который может хранить в себе любой объём данных). В итоге один запрос весил около 40 ГБ, так как BigQuery сканировал все таблицы ga_sessions_ и искал информацию в столбце customDimensions. Таких запросов в день было 50–80. Таким образом, меньше чем за день мы тратили весь бесплатный месячный трафик (1 ТБ).
Оптимизация
Поскольку проблема заключалась в чтении данных из customDimensions каждый раз, когда пользователь удалялся, было решено отказаться от постоянного обращения к данному столбцу при удалении пользователя и хранить только минимальную информацию, которая понадобится в дальнейшем для поиска и удаления анонимных данных. В итоге таблица opted_out_visitors была упразднена, и была создана новая таблица opted_out_users_id, в которую мы добавляем только идентификатор пользователя user_id и идентификатор, которым будем заменять анонимные данные.
[
{
"name": "user_id",
"type": "STRING",
"mode": "REQUIRED",
},
{
"name": "anonymized_id",
"type": "STRING",
"mode": "REQUIRED",
}
]Каждый раз, когда к нам приходит запрос на удаления пользователя, в opted_out_users_id мы добавляем user_id и anonymized_id
INSERT INTO `dataset`.opted_out_users_id (user_id, anonymized_id)
SELECT
user_id, anonymized_id
FROM
(select '{user_id}' as user_id, '{anonymized_id}' as anonymized_id)
WHERE
NOT (EXISTS (
SELECT 1
FROM `dataset`.opted_out_users_id
WHERE `dataset`.opted_out_users_id.user_id = '{user_id}'
)
)Теперь при добавлении новой записи в opted_out_users_id мы тратим около 15 КБ, что значительно меньше, чем когда мы работали напрямую со столбцом customDimensions. Далее, раз в 7 дней нам необходимо запускать скрипт, который будет анонимизировать необходимые значения в ga_sessions_. Так как ga_sessions_ — это шард-таблицы, сегментированные по датам, мы не можем обратиться к таблицам через wildcard-синтаксис ga_sessions_* в операторах UPDATE, INSERT, MERGE. Придётся найти даты, где удалённые пользователи были замечены, и далее обращаться напрямую к каждой таблице ga_sessions_{date}. Для этого перед анонимизацией данных мы находим все даты, где фигурируют удалённые пользователи.
SELECT
ga.date,
ARRAY_AGG(DISTINCT oous.user_id) AS accounts
FROM `dataset.opted_out_users_id` AS oous
LEFT JOIN (
SELECT
`dataset.ga_sessions_*`.date, cd.index AS index,
cd.value AS value
FROM `dataset.ga_sessions_*`,
unnest(`dataset.ga_sessions_*`.customDimensions) AS cd
) AS ga ON oous.user_id = ga.value AND ga.index = 3
GROUP BY ga.dateЗапрос возвращает всех пользователей, сгруппированных по датам. В данном запросе мы потребляем порядка 30 ГБ трафика, что вполне допустимо для нас, т. к. запрос выполняется раз в 7 дней. Ну что же, теперь можно выполнить анонимизацию.
UPDATE `dataset`.`ga_sessions_{date}` as ga
SET customDimensions=ARRAY(
SELECT (
index,
CASE
WHEN index = {lookup_field} THEN
ac.anonymized_id
WHEN index in cleanup_fields THEN
null
else
value
end
)
FROM unnest(ga.customDimensions)
)
FROM `dataset`.`opted_out_users_id` as ac
WHERE ac.user_id=(
SELECT value
FROM unnest(ga.customDimensions) WHERE index=3
)В данном запросе для удалённых пользователей в столбце customDimensions производим замену user_id на anonymize_id, которые расположены в индексе с номером lookup_field, а для остальных индексов, которые расположены в cleanup_fields, чистим значения, устанавливая для них null. Запрос потребляет около 7 ГБ трафика, что также приемлемо для нас. В итоге в сумме все наши запросы не выходят за рамки бесплатного лимита 1 ТБ в месяц.
Итоги
Хочется сказать в конце, что BigQuery вполне достойное облачное хранилище данных. Для хранения небольшого количества данных можно уложиться в бесплатный лимит, но если ваши данные будут насчитывать терабайты и работать с данными вы будете часто, то и затраты будут высокими. С первого взгляда кажется, что 1 ТБ в месяц для запросов — это очень много, но подводный камень кроется в том, что BigQuery считает все данные, которые были обработаны во время выполнения запроса. И если вы работаете с обычными таблицами и попытаетесь выполнить какое-либо усечение данных в виде добавления WHERE либо LIMIT, то с грустью говорим вам, что BigQuery израсходует такой же объём трафика, как и при обычном запросе SELECT FROM. Однако если грамотно построить структуру вашей БД, вы сможете колоссально сэкономить свой бюджет в BigQuery.
Наши рекомендации:
Избегайте SELECT *.
Делайте запросы всегда только к тем полям, которые вам необходимы.Избегайте в таблицах полей с типами данных record, array (repeated record).
Запросы, в которых присутствуют данные столбцы, будут потреблять больше трафика, т. к. BigQuery придётся обработать все данные этого столбца.Старайтесь создавать секционированные таблицы (partitioned tables).
Если грамотно разбить таблицу по партициям, в запросах, в которых будет происходить фильтрация по партиционированному полю, можно значительно снизить потребление трафика, т. к. BigQuery обработает только партицию таблицы, указанную в фильтре запроса.Старайтесь добавлять кластеризацию в ваших секционированных таблицах.
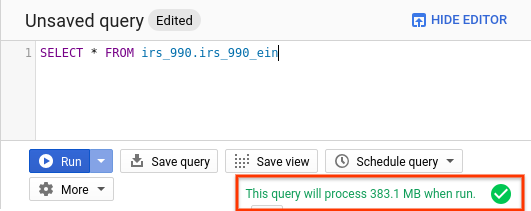
Кластеризация позволяет отсортировать данные в ваших таблицах по заданным столбцам, что также сократит потребление трафика. При использовании фильтрации по кластеризованным столбцам в запросах BigQuery обработает только тот диапазон данных, который включает значения из вашего фильтра.Для подсчёта обработанных данных всегда используйте Cloud Console BigQuery.
Когда вы вводите запрос в Cloud Console, валидатор запроса проверяет синтаксис запроса и предоставляет оценку количества прочитанных байтов. Эту оценку можно использовать для расчёта стоимости запроса в калькуляторе цен.
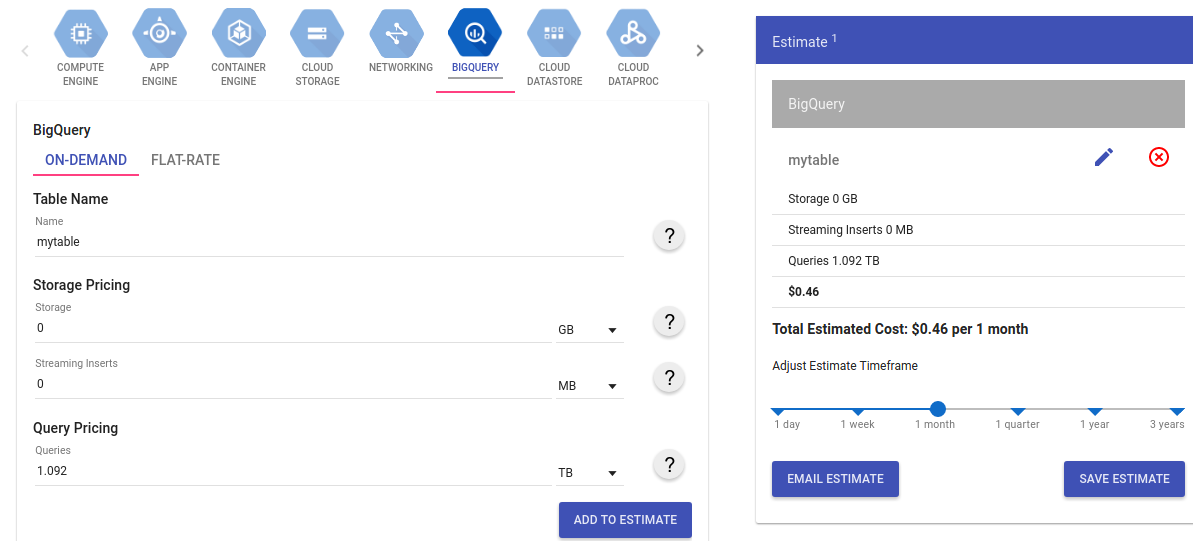
Используйте калькулятор для оценки стоимости хранения данных и выполнения запросов: https://cloud.google.com/products/calculator/.
Для оценки стоимости запросов в калькуляторе необходимо ввести количество байтов, обрабатываемых запросом, в виде Б, КБ, МБ, ГБ, ТБ. Если запрос обрабатывает менее 1 ТБ, оценка составит 0 долларов, поскольку BigQuery предоставляет 1 ТБ в месяц бесплатно для обработки запросов по требованию. Аналогичные действия можно выполнить и для оценки хранения данных.



")
