

Бывает так, что критерии поиска текстов слишком сложны, чтобы обойтись регулярными выражениями. В таких случаях на помощь приходит ML. Если из списка текстов выбрать самый подходящий для нас, можно выяснить похожесть всех остальных текстов на этот. Похожесть(similarity) это численная мера, чем выше – тем более текст похож, поэтому при сортировке по убыванию по этому параметру мы увидим наиболее подходящие нам тексты из выборки.
В качестве примера возьмем любой набор текстов. Здесь http://study.mokoron.com/ можно скачать небольшое csv с твитами. В реальной работе это могут быть разного рода комментарии, ответы от техподдержки, запросы пользователей. Так или иначе, импортировав все нужные библиотеки, загрузим в pandas наш список текстов и взглянем на первые из них:
import pandas as pd
import re
from gensim import corpora,models,similarities
from gensim.utils import tokenize
df = pd.read_csv('positive.csv',sep=";",names = [1,2,3,"text",4,5,6,7,8,9,10,11])[["text"]]
list(df.head(5)["text"].values)
['@first_timee хоть я и школота, но поверь, у нас то же самое :D общество профилирующий предмет типа)',
'Да, все-таки он немного похож на него. Но мой мальчик все равно лучше:D',
'RT @KatiaCheh: Ну ты идиотка) я испугалась за тебя!!!',
'RT @digger2912: "Кто то в углу сидит и погибает от голода, а мы ещё 2 порции взяли, хотя уже и так жрать не хотим" :DD http://t.co/GqG6iuE2…',Стандартный и привычный способ поиска нужных нам текстов – регулярные выражения. Они очень быстро выполняются даже на гигантских датасетах и отлично послужат нам в качестве фильтров. Для примера выберем случайные слова из тех, что мы только что видели и превратим их в регулярки:
regex_queries = ["школ.*","голод.*","страш.*",'[^а-яА-Я]ми[^а-яА-Я]']
for word in regex_queries:
df[word] = df["text"].str.count(word,flags=re.IGNORECASE)Звездочка с точкой .* показывает что после нужного нам фрагмента может быть любой набор символов. [^а-яА-Я] означает «любой символ, который не является русской буквой». Вообще для создания регулярных выражений удобно использовать сайт regex. Метод str.count библиотеки pandas применяет регулярное выражение массово на весь датасет, выдавая количество найденных регулярок. Флаг re.IGNORECASE это часть конфигурации библиотеки регулярных выражений regex, заставляющая ее искать вне зависимости от того, заглавные в тексте буквы или строчные.
Результат выполнения выглядит так:
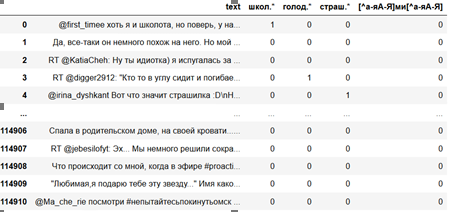
Этого иногда бывает достаточно, но даже если нет, такую предварительную работу всегда стоит проводить для облегчения фильтрации. Если мы точно знаем, что в тексте встретятся слова «бумажный носитель», но нам точно не подойдет «платежный документ», мы добавим «бума.*носит» и «платежн.*документ» и в дальнейшем отфильтруем их так, как нам надо.
Для непосредственного поиска похожих текстов стоит использовать реализацию doc2bow из библиотеки genism, поскольку помимо нужных нам моделей она предоставляет множество других полезных функций, например токенизацию со встроенной лемматизацией, что может быть полезно в случае, если предварительно обученные модели для лемматизации использовать нельзя.
Первым делом выделим тексты, по которым будет проводиться сравнение, далее называя их «опорные тексты». Скорее всего, после первого этапа поисков этот список расширится, поскольку модель предложит дополнительные варианты подходящих текстов. В качестве примера просто возьмем первые 5 твитов, главное помнить, что эти тексты так же должны быть в общем наборе.
texts_to_compare = list(df.head(5)["text"])
['@first_timee хоть я и школота, но поверь, у нас то же самое :D общество профилирующий предмет типа)',
'Да, все-таки он немного похож на него. Но мой мальчик все равно лучше:D',
'RT @KatiaCheh: Ну ты идиотка) я испугалась за тебя!!!',
'RT @digger2912: "Кто то в углу сидит и погибает от голода, а мы ещё 2 порции взяли, хотя уже и так жрать не хотим" :DD http://t.co/GqG6iuE2…',
'@irina_dyshkant Вот что значит страшилка :D\nНо блин,посмотрев все части,у тебя создастся ощущение,что авторы курили что-то :D']Теперь токенизируем все тексты в нашем датасете. На этом этапе осуществляется обработка текстов, который можно провести множеством способов при помощи множества библиотек. Самые распространённые способы включают в себя:
Удаление стоп слов, таких как «а», «и», «но» и прочее. Обычно для этого используются заранее собранные словари. Можно выполнить библиотекой NLTK
Понижение регистра слов до строчных. Большинство библиотек и чистый python сам по себе могут это делать. Некоторые, могут еще и удалить диакритические знаки, например gensim.
Лемматизация, то есть приведение слова к словарной форме. Сложность этого действия зависит от языка, для русского языка этот процесс не прост и требует специальных библиотек. pymystem3 подойдет, но важно всегда контролировать качество.
Стемминг, или обрезка слов до корня. Это более экстремальный вариант лемматизации, который «чайник» может превратить в «чай». Выполняется если потеря смысла не страшна. Подходящая библиотека pymorphy и написанные под нее скрипты для русского языка в духе Стеммера Портера.
def tokenize_in_df(strin):
try:
return list(tokenize(strin,lowercase=True, deacc=True,))
except:
return ""
df["tokens"] = df["text"].apply(tokenize_in_df)
df.head(5)["tokens"].values
array([list(['first_timee', 'хоть', 'я', 'и', 'школота', 'но', 'поверь', 'у', 'нас', 'то', 'же', 'самое', 'd', 'общество', 'профилирующии', 'предмет', 'типа']),
list(['да', 'все', 'таки', 'он', 'немного', 'похож', 'на', 'него', 'но', 'мои', 'мальчик', 'все', 'равно', 'лучше', 'd']),
list(['rt', 'katiacheh', 'ну', 'ты', 'идиотка', 'я', 'испугалась', 'за', 'тебя']),
list(['rt', 'digger', 'кто', 'то', 'в', 'углу', 'сидит', 'и', 'погибает', 'от', 'голода', 'а', 'мы', 'еще', 'порции', 'взяли', 'хотя', 'уже', 'и', 'так', 'жрать', 'не', 'хотим', 'dd', 'http', 't', 'co', 'gqg', 'iue']),
list(['irina_dyshkant', 'вот', 'что', 'значит', 'страшилка', 'd', 'но', 'блин', 'посмотрев', 'все', 'части', 'у', 'тебя', 'создастся', 'ощущение', 'что', 'авторы', 'курили', 'что', 'то', 'd'])],
dtype=object)
В нашем примере мы применили только приведение к строчным буквам и удаление ударений в параметрах функции gensim.tokenize: lowercase=True, deacc=True.
Создадим словарь слов, которые есть во всем нашем наборе текстов:
dictionary = corpora.Dictionary(df["tokens"])
feature_cnt = len(dictionary.token2id)
dictionary.token2id
{'d': 0,
'first_timee': 1,
'же': 2,
'и': 3,
'нас': 4,
'но': 5,
'общество': 6,
'поверь': 7,
'предмет': 8,
'профилирующии': 9,
'самое': 10,
'типа': 11,
'то': 12,
'у': 13,
'хоть': 14,
'школота': 15,
'я': 16,
'все': 17,
'да': 18,
'лучше': 19,
…
Каждое новое слово получает свой номер. Для дальнейшего использования номера слов в словаре походят намного лучше, чем сами слова. Теперь нужно создать корпус, превратив наши токенизированные тексты в векторы (называются bow – bag of words – мешок слов). Вектор в данном случае — список пар значений «номер слова в словаре : количество таких слов в отдельном тексте».
corpus = [dictionary.doc2bow(text) for text in df["tokens"]]
corpus
[[(0, 1),
(1, 1),
(2, 1),
(3, 3),
(4, 1),
(5, 1),
(6, 1),
(7, 1),
(8, 1),
(9, 2),
(10, 1),
(11, 1),
(12, 1),
(13, 1),
(14, 2),
(15, 1),
(16, 1),
…
Прелесть такого вектора в том, что, в отличие от текстов, с ним можно проводить операции матричного умножения, под которые идеально заточены вычислительные мощности процессора и видеокарты, что делает обработку даже самых огромных наборов текстов очень быстрой.
Именно этим займется модель tf-idf. Сама по себе аббревиатура TF-IDF расшифровывается как TF — term frequency, IDF — inverse document frequency, то есть отношение частоты употребления слова в отдельном тексте к частоте употребления слова во всех документах. Построенная на основе такой меры модель прекрасно подходит для поиска похожих текстов, поскольку позволяет сравнивать совокупные меры текстов между собой, строя матрицу похожести.
tfidf = models.TfidfModel(corpus)
index = similarities.SparseMatrixSimilarity(tfidf[corpus],num_features = feature_cnt)Как именно отработала эта модель мы сможем увидеть на примере, построив векторы наших опорных текстов и получив значения их похожестей из матрицы.
for text in texts_to_compare:
kw_vector = dictionary.doc2bow(tokenize(text))
df[text] = index[tfidf[kw_vector]]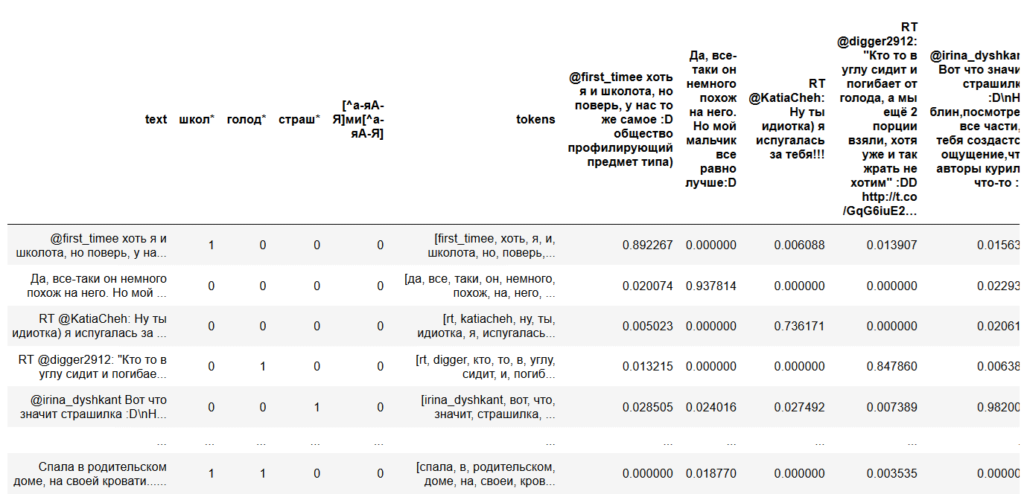
Теперь мы можем избавиться от заведомо непохожих текстов, посчитав сумму весов и оставив тексты с самыми высокими суммами. Результаты поиска слов при помощи регулярных выражений, между прочим, тоже можно включить в эту сумму, уменьшив их значимость.
df["sum"] = 0
for text in texts_to_compare:
df["sum"] = df["sum"]+df[text]
for word in regex_queries:
df["sum"] = df["sum"]+df[word]/5 Избавляться от лишних текстов можно обрезав по порогу суммы, или отсортировав по сумме и обрезав датасет по количеству текстов.
df["sum"].value_counts(bins=5)
(-0.0022700000000000003, 0.254] 113040
(0.254, 0.508] 1829
(0.508, 0.762] 31
(0.762, 1.016] 7
(1.016, 1.269] 4На этом этапе python уже не нужен, продолжать работать удобнее в excel:
df[df["sum"]>0.250].to_excel("похожие тексты.xlsx")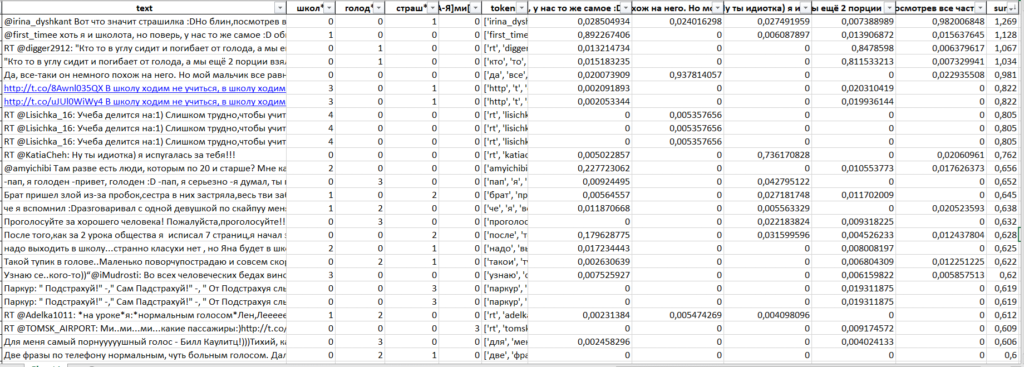
Проверка результата и поиск дополнительных текстов и слов для улучшения алгоритма комфортно проходит в Excel, за счет использования фильтров и сортировок.
Вот пример, отсортируем результат по похожести на самый первый опорный текст (он, разумеется, окажется на самом первом месте при сортировке):

Видно, что хоть мы и не указывали модели явно такие слова как «школота», «общество» и «предмет», она нашла по ним остальные тексты, поскольку эти слова оказались самыми значимыми.
После нахождения нужных текстов самые подходящие из них можно отправить в начало скрипта, добавив в список texts_to_compare, уточняя или углубляя поиск.
Ссылка на код



