Привет, меня зовут Игорь, и я разработчик решений на Tarantool в Mail.ru Group. Я работаю над витринами маркетинга в реальном времени для Мегафона. При мониторинге часто требуется использовать перцентили. Они позволяют понять, как система работает бóльшую часть времени, в отличие от усреднения значений, которое сильно подвержено влиянию выбросов. Если 9 из 10 запросов выполняются за 1 секунду, а один за 10 секунд, то среднее будет 1,9 секунды, а 50-перцентиль — 1 секунда. Это лишь один пример того, что среднее значение не подходит для мониторинга. Возникает необходимость считать перцентили, для этого мы добавили в tarantool/metrics Summary-коллектор.
Функциональность Summary-коллектора — расчет квантилей для наблюдаемых данных. Расскажу об алгоритме, который мы использовали для квантилей, и о том, как мы его реализовывали для tarantool/metrics.
Summary-коллектор
Алгоритм
-квантиль — это значение, которое случайная величина не превышает с вероятностью . Пример: 0,5-квантиль (она же 50-перцентиль), равная 1 секунде, для мониторига HTTP-запросов означает, что 50% запросов были обработаны меньше, чем за секунду. Чтобы посчитать квантиль для отсортированного массива размером , необходимо взять элемент с индексом . При таком подходе необходимо хранить все данные, а в метриках их может быть очень много. Если был 1 млрд запросов, то будет 1 млрд элементов массива — порядка 1 Гб данных.
Для решения этой проблемы существует несколько алгоритмов расчета приближенных значений квантилей на потоках данных. Мы взяли алгоритм, который использует Prometheus. Он «сжимает» исходные данные в отрезки из трех чисел: расстояние от начала предыдущего отрезка до начала текущего , длина текущего отрезка и приближенное значение квантили на этом отрезке .

Элементы исходного массива изображены зеленым, элементы «сжатого» массива — красным. Чтобы найти квантиль на сжатых данных, нужно пройтись по всем отрезкам, складывая расстояния, и найти тот, в который попадает значение . Тогда на рисунке 0,5-квантиль будет располагаться посередине зеленого массива, а приближенное значение будет принадлежать соответствующему красному отрезку.
Процесс компрессии подробно описан в исходной статье.
Реализация
Мы ориентировались на реализацию алгоритма на Go.
Заведем два массива, один — буфер, в который будут помещаться наблюдаемые значения, а второй — массив наблюдений для хранения структур для отрезков:
typedef struct {int Delta, Width; double Value; } sample;Алгоритм работает только с отсортированными значениями. Ограничим размер буфера 500 значениями, а размер массива наблюдений определим как — операция сжатия сокращает размер массива примерно вполовину, так что в среднем нам потребуется: 500 элементов несжатого массива с предыдущего шага + 500 элементов, которые вливаются в массив на текущем шаге + 2 элемента и для упрощения поиска в массиве.
Ход разработки
Разрабатывали итеративно: делаем версию, проверяем производительность c помощью профилировщика и сравниваем с версией на Go; думаем, как улучшить. Сравнивать будем с простым бенчмарком: делаем вставку 108 образцов, для гошной версии это занимает порядка 8 с. Теперь подробнее о каждом шаге:
1) pure-Lua версия — очень плохо, вставка занимает в среднем около 100 с.
В профилировщике видим следующее:
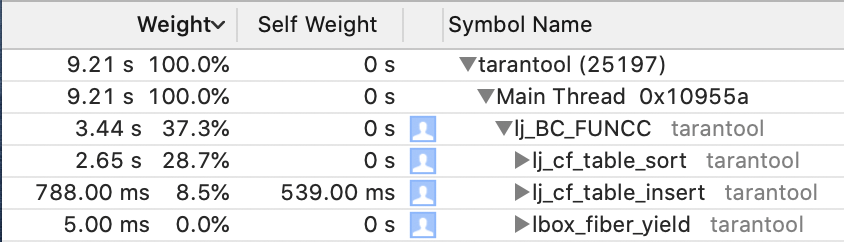
Код проседает на вставке наблюдений в массив (вызов table.insert) и сортировке буфера (table.sort). На помощь приходит ffi, или foreign function interface. Ffi позволяет обращаться к функциям из стандартной библиотеки C, а потом работать с ними в Lua, как с обычными Lua-объектами (ну, почти; например, индексация таблиц в Lua начинается с 1, а у массивов, созданных из С, всё еще с 0).
2) Lua + ffi — заменим создание буфера на создание массива double:
local ffi = require('ffi')
…
array = ffi.new('double[?]', max_samples)
for i = 0, max_samples - 1 do
array[i] = math.huge
endСортировать такой массив будем средствами стандартной библиотеки С:
ffi.cdef[[ void qsort(void *base, size_t nitems, size_t size, int (*compar)(const void *, const void*));
int cmpfunc (const void * a, const void * b);]]Функцию-компаратор для double нужно написать на С и подключить как динамическую библиотеку. Пишем компаратор:
int cmpfunc (const void * a, const void * b) {
if (*(double*)a > *(double*)b)
return 1;
else if (*(double*)a < *(double*)b)
return -1;
else
return 0;
}Собираем его:
gcc -c -o metrics/quantile.o metrics/quantile.c
gcc -shared -o metrics/libquantile.so metrics/quantile.oПодключаем библиотеку в Lua-коде:
local dlib_path = package.search('libquantile', package.cpath)
local dlib = ffi.load(dlib_path)Теперь можно заполнить массив double и вызвать сортировку:
local DOUBLE_SIZE = ffi.sizeof('double')
ffi.C.qsort(array, len, DOUBLE_SIZE, dlib.cmpfunc)Тестируем производительность и получаем прирост в 3 раза, в среднем до 30 с. Проседание происходило из-за того, что размер таблиц в Lua не фиксированный, тип элементов тоже никак не указывается заранее. Это позволяет гибче работать с таблицами, но снижает производительность (подробнее о Lua-таблицах можно почитать здесь). Ffi позволяет перейти от Lua-таблиц к С-массивам с фиксированным размером, поэтому вставка и вычисление размера массива теперь обходятся в вместо . Сортировка тоже происходит гораздо быстрее благодаря зафиксированным типам и, соответственно, фиксированным размерам элементов. Но при таком решении появилась зависимость от gcc, что усложняет поставку приложений. Поэтому пришлось избавиться от C-кода.
3) Lua + ffi + самописная сортировка — время работы простейшего варианта быстрой сортировки на Lua получилось всего лишь на пару секунд хуже, чем вариант с сишной библиотекой. Это значение вместе с отсутствием gcc нас удовлетворило, и мы решили остановиться на нем.
Расход памяти
metrics.quantile использует два массива:
- Буфер размером
max_samples * sizeof(double)= байт. - Массив наблюдений размером
(2 * max_samples + 2) * sizeof(struct sample)= байт. Размер массива наблюдений может увеличиваться при изменении наблюдаемых значений на несколько порядков.
Влияние на производительность
Провели нагрузочное тестирование Яндекс.Танком (подробнее здесь). Приложение с выключенными метриками:
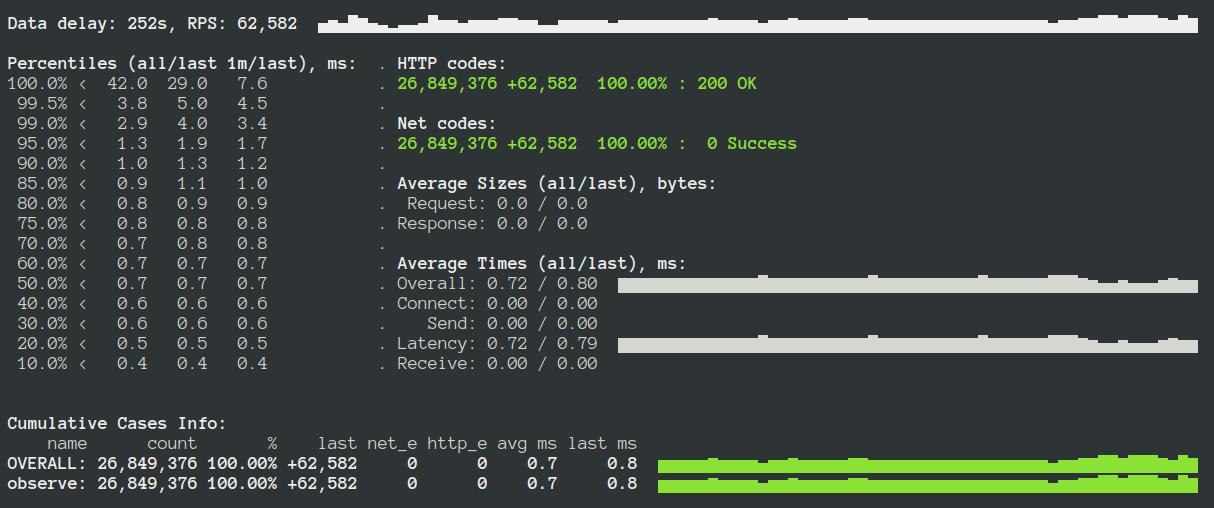
При использовании Summary-коллектора:

Просело на ~10%, это та цена производительности, которую нужно платить за использование метрик. Если вы хотите избежать сильной просадки, нужно пользоваться коллектором аккуратно, например, замерять только часть запросов.
Использование
tarantoolctl rocks install metrics 0.5.0local metrics = require('metrics') -- подключаем метрики
-- Создаем summary коллектор
local http_requests_latency = metrics.summary(
'http_requests_latency', 'HTTP requests latency',
{[0.5]=0.01, [0.9]=0.01, [0.99]=0.01}
)
-- наблюдаем значение:
local latency = math.random(1, 10)
http_requests_latency:observe(latency)Поддерживается экспорт в JSON, Prometheus и Graphite. Вот так могут выглядеть собранные результаты в Grafana:
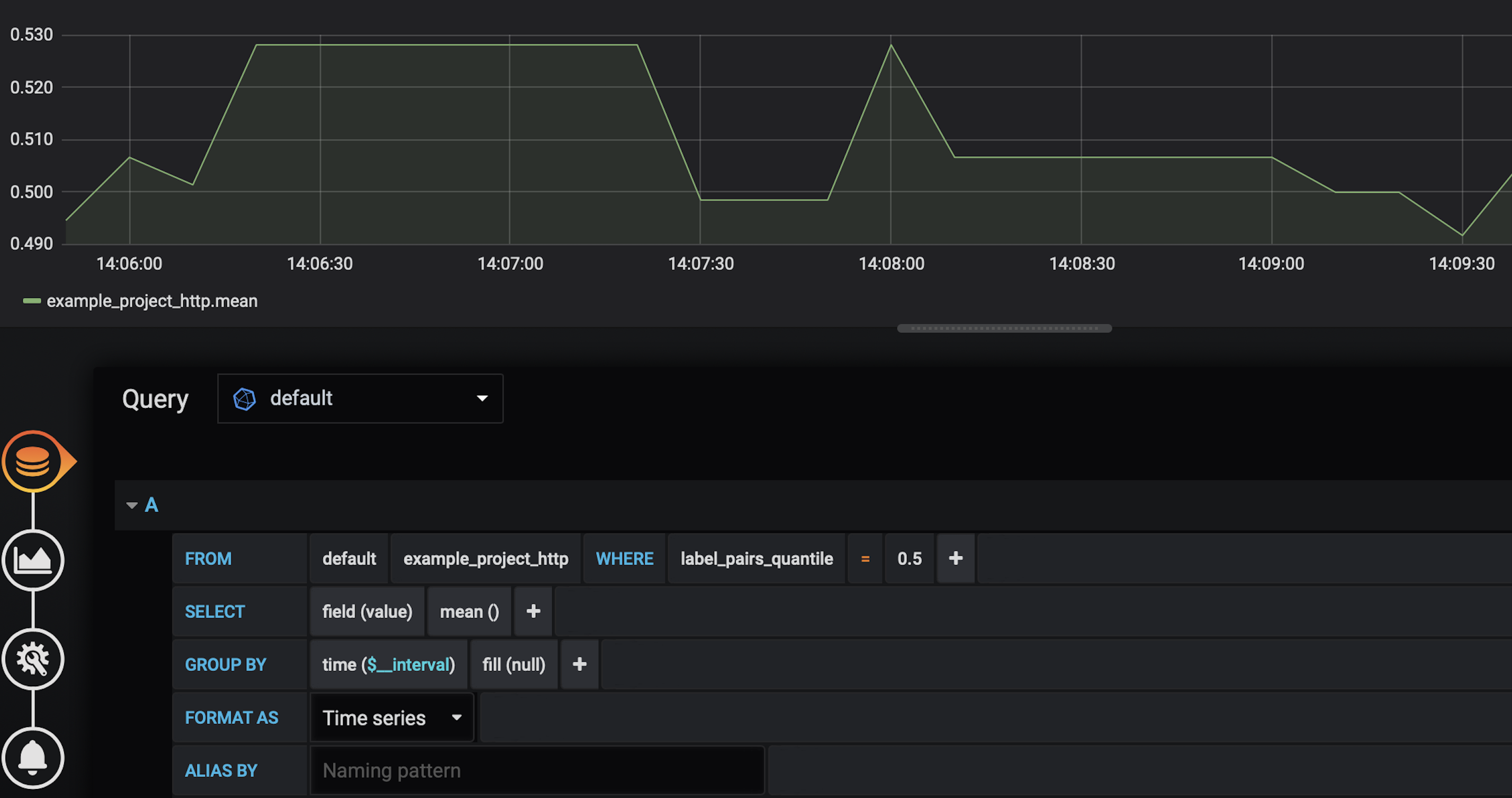
Итоги
Мы написали Summary-коллектор для tarantool/metrics. При разработке столкнулись с проблемой производительности, которую решили с помощью ffi. Новый коллектор можно использовать для мониторинга величин, которые выставляются по квантилям, например задержки HTTP-запросов. Summary можно использовать во всех продуктах на Tarantool, где важно время отклика сервиса, например в высоконагруженных приложениях, где HTTP-запросы обращаются к большим объемам данных. Наблюдение за этой метрикой позволит понять, какие запросы нагружают систему.
Ссылки
- Скачать Tarantool можно на официальном сайте
- Получить помощь можно в Telegram-чате.
- Документация tarantool/metrics
- Summary-коллектор в документации Prometheus
- Алгоритм расчета квантилей
- Нагрузочное тестирование Tarantool
- Подробнее о Lua-таблицах




