В общем и целом распознавание лиц и идентификация людей по их результатам выглядит для аксакалов как подростковый секс — все о нем много говорят, но мало кто практикует. Понятно, что мы уже не удивляемся, что после загрузки фоточки с дружеских посиделок Facebook/VK предлагает отметить обнаруженных на снимке персон, но тут мы интуитивно знаем, что у соцсетей есть хорошее подспорье в виде графа связей персоны. А если такого графа нет? Впрочем, начнем по порядку.

Изначально распознавание лиц и идентификация по ним “свой/чужой” у нас выросла из исключительно бытовых нужд — к коллеге в подъезде повадились наркоманы, а постоянно следить за картинкой с установленной видеокамеры, да еще и разбирать, где сосед, а где незнакомец желания не было никакого.
Поэтому буквально за неделю на коленке был собран прототип, состоящий из IP-камеры, одноплатника, датчика движения и питоновской библиотеки распознавания лиц face_recognition. Поскольку что на одноплатнике, что на достаточно мощном железе питоновская библиотека была… скажем аккуратно, не очень быстрой, то процесс обработки решили построить следующим образом:
Весь процесс был склеен нашим любимым Erlang-ом и в процессе тестирования на коллегах доказал свою минимальную работоспособность.
Однако, собранный макет не нашел применения в реальной жизни — не из-за его технического несовершенства, которое, несомненно, было — как показывает имеющийся опыт, собранное на коленке в тепличных офисных условиях имеет очень нехорошую тенденцию ломаться в поле, причем в момент демонстрации заказчику, а из-за организационных — жители подъезда большинством отказались от какого-либо видеонаблюдения.
Проект ушел на полку и периодически потыкивался палкой на предмет демонстраций при продажах и позывах к реинкарнации в личном хозяйстве.
Все поменялось с момента, когда у нас появился более конкретный и вполне коммерческий проект на ту же тематику. Поскольку срезать углы в нем при помощи датчика движения не удалось бы прямо от постановки задачи, пришлось углубится в нюансы поиска и распознавания лиц в три головы (окей, две с половиной, если считать мою) непосредственно на потоке. И тут открылось откровение.
Беда в том, что большая часть открытого по данному вопросу представляет собой чисто академические зарисовки на тему того, что “мне надо было написать статью в журнал на модную тему и получить галочку за публикацию”. Нисколько не умаляю заслуги ученых — среди найденных бумаг было немало полезного и интересного, но, увы, вынужден констатировать, что воспроизводимость работы их кода, выложенного на Гитхаб, оставляет желать лучшего или выглядит вообще сомнительной затеей с бесполезно потраченным временем в итоге.
Многочисленные фреймворки для нейронных сетей и машинного обучения, зачастую, тоже были тяжелы на подход — для них распознавание лиц было отдельной узкой задачкой, малоинтересной в широком спектре проблем, которые они решали. Иными словами, взять готовый пример и запустить его на целевом железе чтобы просто проверить, как оно вообще работает и работает ли — не получалось. То не было примера, то необходимость его получения предполагала некислый квест из сборки определенных библиотек определенных версий под строго определенные ОС. Т.е. чтобы взять и полететь с ходу — буквально крохи наподобие той питоновской face_recognition, которую мы использовали для предыдущей поделки.
Спасли нас, как всегда, большие компании. И Intel, и Nvidia давно прочувствовали набирающие обороты и коммерческую привлекательность этого класса задач, ну а, будучи поставщиками в первую очередь оборудования, они раздают свои фреймворки для решения конкретных прикладных задач бесплатно.
Наш проект носил скорее не исследовательский, а экспериментальный характер, поэтому мы не стали анализировать и сравнивать решения отдельных вендоров, а просто взяли первое попавшееся с целью собрать готовый прототип и протестировать его боем, получив при этом максимально быстрый отклик. Поэтому выбор очень быстро упал на Intel OpenVINO — библиотеку для практического применения машинного обучения в прикладных задачах.
Для начала мы собрали стенд, представляющий собой традиционно комплект из неттопа с Core i3 процессором и IP-камеры из имеющихся на рынке китайских вендоров. Камера напрямую подключалась к неттопу и поставляла на него RTSP-поток с не очень большим FPS, исходя из предположения, что люди все-таки не будут бегать перед ней как на соревнованиях. Скорость обработки одного кадра (поиск и распознавание лиц) колебалась в районе десятков-сотен миллисекунд, что было вполне достаточно для встраивания еще и механизма поиска персон по имеющимся семплам. Кроме того, у нас был еще и резервный план — у Интела есть специальный сопроцессор для ускорения расчетов нейросетей Neural Compute Stick 2, которую мы могли бы задействовать, если процессора общего назначения нам бы не хватило. Но — пока обошлось.
После завершения сборки и проверки работоспособности базовых примеров — отличительная особенность SDK от Intel оказалась в пошаговом и весьма простом руководстве к примерам — мы приступили к сборке ПО.
Основная задача, стоявшая перед нами — поиск персоны в области видимости камеры, ее идентификация и своевременное оповещение о ее присутствии. Соответственно, помимо распознавания лиц и сопоставления их с образцами (как это делать, на тот момент, вызывало ничуть не меньше вопросов, чем все остальное) нам было необходимо обеспечить и второстепенные вещи интерфейсного плана. А именно — мы должны получать кадры с лицами необходимых персон с той же камеры для их последующей идентификации. Почему с той же камеры, думаю, тоже вполне очевидно — точка установки камеры на объекте и оптика объектива вносят определенные искажения, которые, предположительно, могут сказаться на качестве распознавания, используй мы другой источник, нежели средство слежения.
Т.е. помимо собственно обработчика потока нам потребуется как минимум видео-архив и анализатор видео-файлов, который позволит вычленить все обнаруженные лица с записи и сохранить наиболее подходящие из них как опорные.
Как всегда мы взяли привычные Erlang и PostgreSQL в качестве клея между ffmpeg, приложениями на OpenVINO и API мессенжера для оповещения. Помимо этого нам потребовалось web-UI для обеспечения минимального набора процедур по управлению комплексом, который наш коллега-фронтэндер запилил на VueJS.
Логика работы была проста:
Выглядит это примерно так:
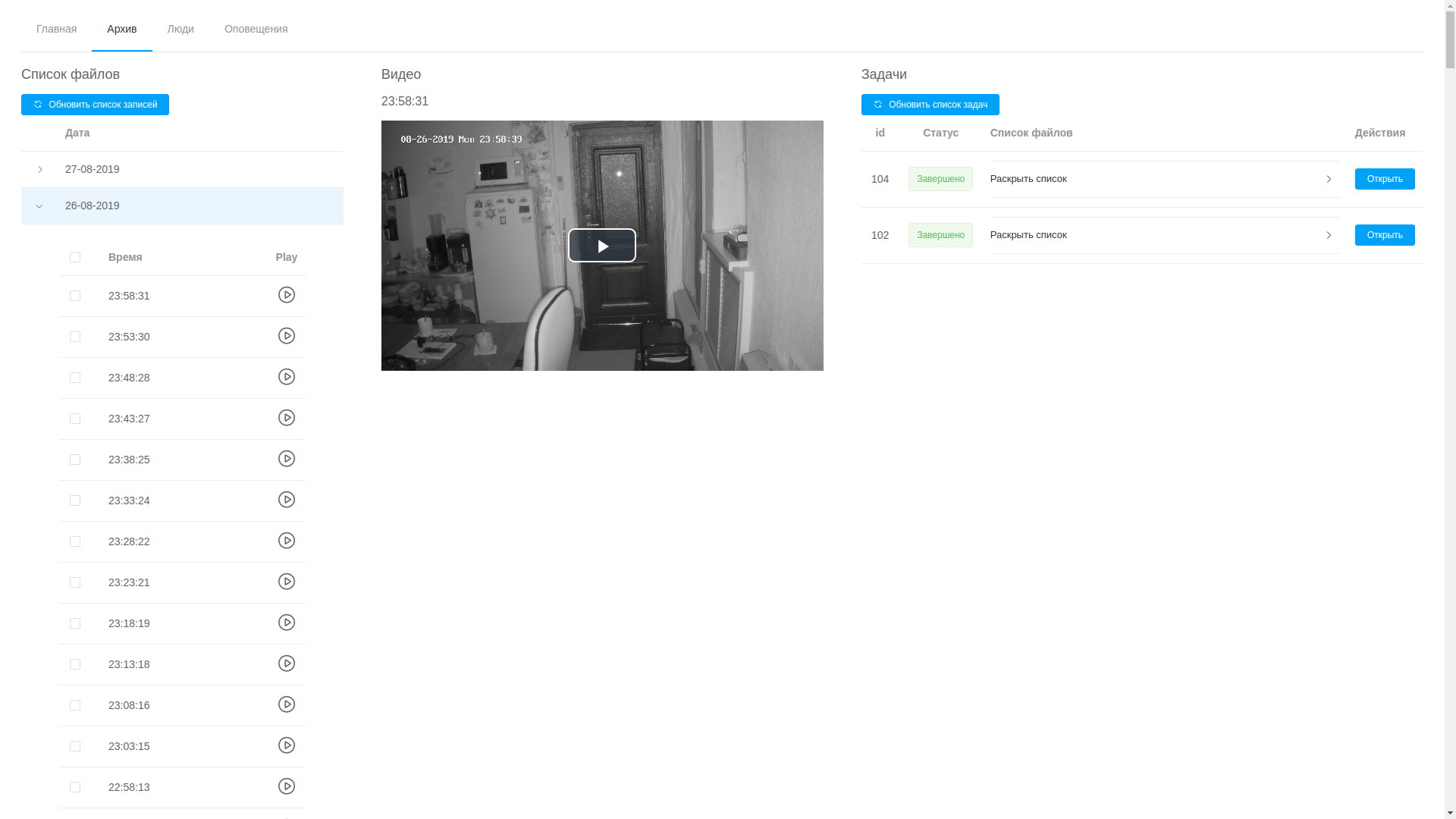
Просмотр архива
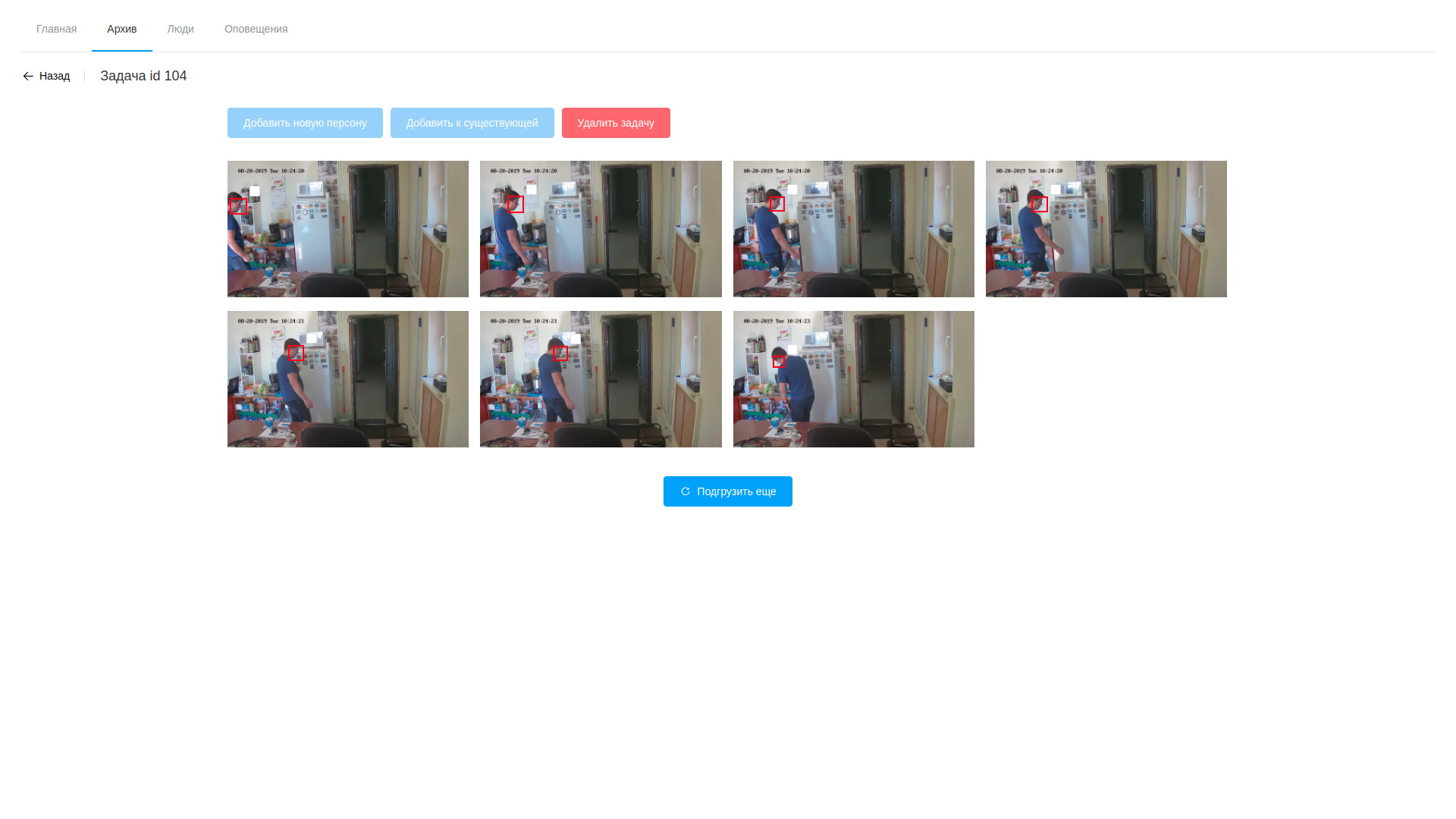
Результаты анализа видео
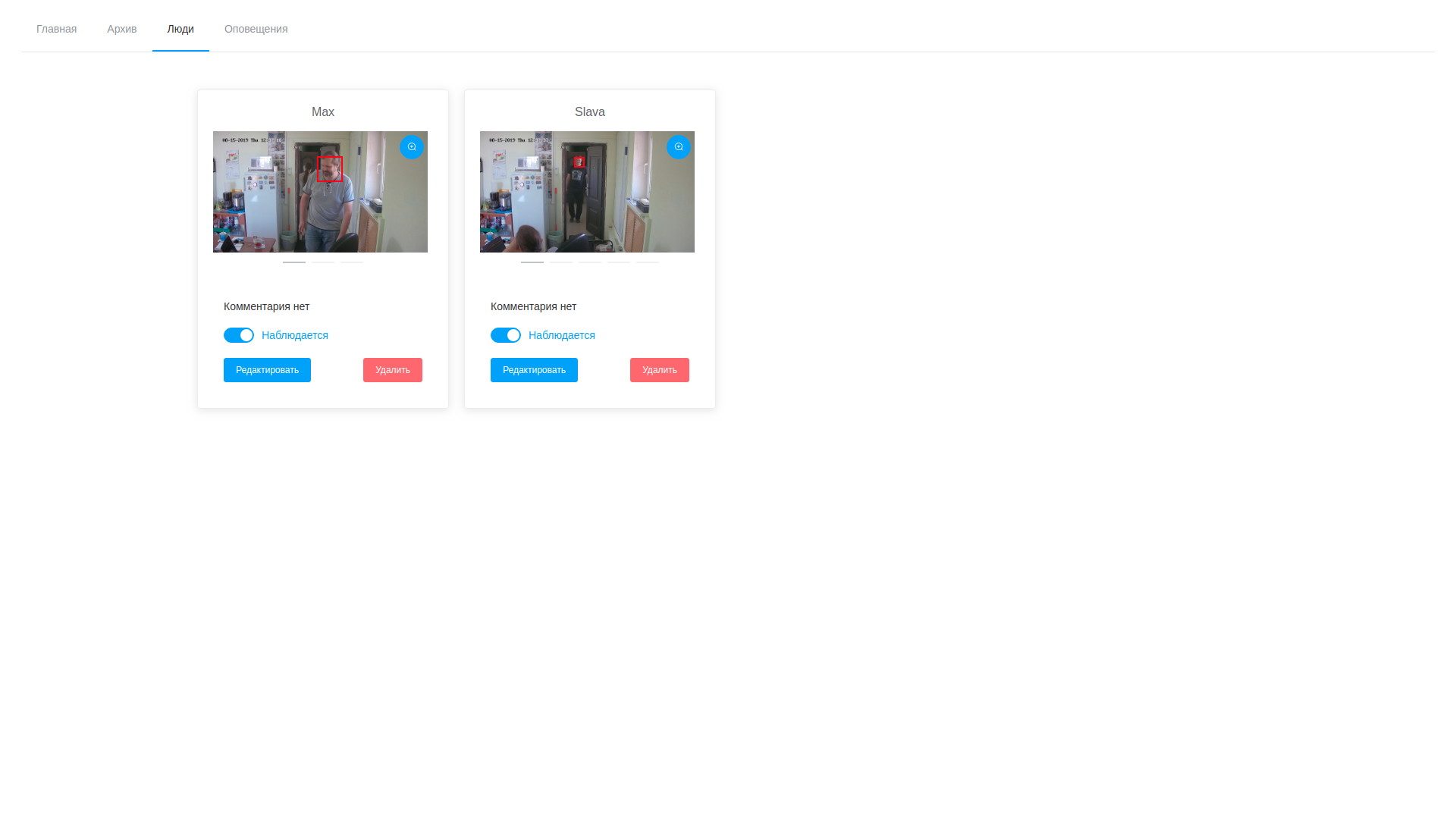
Список наблюдаемых личностей
Полученное решение во многом спорно и местами даже неоптимально как с точки зрения производительности, так и с точки зрения сокращения времени реакции. Но, повторюсь, у нас не было цели получить продуктивную систему сразу, а просто пройти этот путь и набить максимальное количество шишек, определить узкие пути и потенциальные неочевидные проблемы.
Собранная система тестировалась в тепличных офисных условиях в течение недели. За это время были отмечены следующие наблюдения:
Что предстоит? Проверка системы боем, оптимизация цикла обработки обнаружений, упрощение процедуры поиска событий в видео-архиве, добавление большего количества данных в анализ (возраст, пол, эмоции) и еще 100500 мелких и не очень задачек, которые еще предстоит сделать. Но первый шаг в пути из тысячи шагов мы уже сделали. Если кто поделится своим опытом в решении подобных задач или даст интересные ссылки по этому вопросу — буду весьма признателен.
Изначально распознавание лиц и идентификация по ним “свой/чужой” у нас выросла из исключительно бытовых нужд — к коллеге в подъезде повадились наркоманы, а постоянно следить за картинкой с установленной видеокамеры, да еще и разбирать, где сосед, а где незнакомец желания не было никакого.
Поэтому буквально за неделю на коленке был собран прототип, состоящий из IP-камеры, одноплатника, датчика движения и питоновской библиотеки распознавания лиц face_recognition. Поскольку что на одноплатнике, что на достаточно мощном железе питоновская библиотека была… скажем аккуратно, не очень быстрой, то процесс обработки решили построить следующим образом:
- датчик движения определяет, есть ли движение в доверенной ему области пространства и сигнализирует о его наличии;
- написанный сервис на базе gstreamer-а, который постоянно получает поток с IP-камеры, отрезает 5 секунд до и 10 секунд после детектирования и скармливает это на анализ библиотеке распознавания;
- та, в свою очередь, просматривает видео, находит там лица, сопоставляет их с известными образцами и в случае обнаружения неизвестных отдает видео в Telegram-канал, в дальнейшем предполагалось там же сделать управление, чтобы сразу отсечь ложно-положительные срабатывания — например, когда сосед повернулся к камере не тем боком, что на семплах.
Весь процесс был склеен нашим любимым Erlang-ом и в процессе тестирования на коллегах доказал свою минимальную работоспособность.
Однако, собранный макет не нашел применения в реальной жизни — не из-за его технического несовершенства, которое, несомненно, было — как показывает имеющийся опыт, собранное на коленке в тепличных офисных условиях имеет очень нехорошую тенденцию ломаться в поле, причем в момент демонстрации заказчику, а из-за организационных — жители подъезда большинством отказались от какого-либо видеонаблюдения.
Проект ушел на полку и периодически потыкивался палкой на предмет демонстраций при продажах и позывах к реинкарнации в личном хозяйстве.
Все поменялось с момента, когда у нас появился более конкретный и вполне коммерческий проект на ту же тематику. Поскольку срезать углы в нем при помощи датчика движения не удалось бы прямо от постановки задачи, пришлось углубится в нюансы поиска и распознавания лиц в три головы (окей, две с половиной, если считать мою) непосредственно на потоке. И тут открылось откровение.
Беда в том, что большая часть открытого по данному вопросу представляет собой чисто академические зарисовки на тему того, что “мне надо было написать статью в журнал на модную тему и получить галочку за публикацию”. Нисколько не умаляю заслуги ученых — среди найденных бумаг было немало полезного и интересного, но, увы, вынужден констатировать, что воспроизводимость работы их кода, выложенного на Гитхаб, оставляет желать лучшего или выглядит вообще сомнительной затеей с бесполезно потраченным временем в итоге.
Многочисленные фреймворки для нейронных сетей и машинного обучения, зачастую, тоже были тяжелы на подход — для них распознавание лиц было отдельной узкой задачкой, малоинтересной в широком спектре проблем, которые они решали. Иными словами, взять готовый пример и запустить его на целевом железе чтобы просто проверить, как оно вообще работает и работает ли — не получалось. То не было примера, то необходимость его получения предполагала некислый квест из сборки определенных библиотек определенных версий под строго определенные ОС. Т.е. чтобы взять и полететь с ходу — буквально крохи наподобие той питоновской face_recognition, которую мы использовали для предыдущей поделки.
Спасли нас, как всегда, большие компании. И Intel, и Nvidia давно прочувствовали набирающие обороты и коммерческую привлекательность этого класса задач, ну а, будучи поставщиками в первую очередь оборудования, они раздают свои фреймворки для решения конкретных прикладных задач бесплатно.
Наш проект носил скорее не исследовательский, а экспериментальный характер, поэтому мы не стали анализировать и сравнивать решения отдельных вендоров, а просто взяли первое попавшееся с целью собрать готовый прототип и протестировать его боем, получив при этом максимально быстрый отклик. Поэтому выбор очень быстро упал на Intel OpenVINO — библиотеку для практического применения машинного обучения в прикладных задачах.
Для начала мы собрали стенд, представляющий собой традиционно комплект из неттопа с Core i3 процессором и IP-камеры из имеющихся на рынке китайских вендоров. Камера напрямую подключалась к неттопу и поставляла на него RTSP-поток с не очень большим FPS, исходя из предположения, что люди все-таки не будут бегать перед ней как на соревнованиях. Скорость обработки одного кадра (поиск и распознавание лиц) колебалась в районе десятков-сотен миллисекунд, что было вполне достаточно для встраивания еще и механизма поиска персон по имеющимся семплам. Кроме того, у нас был еще и резервный план — у Интела есть специальный сопроцессор для ускорения расчетов нейросетей Neural Compute Stick 2, которую мы могли бы задействовать, если процессора общего назначения нам бы не хватило. Но — пока обошлось.
После завершения сборки и проверки работоспособности базовых примеров — отличительная особенность SDK от Intel оказалась в пошаговом и весьма простом руководстве к примерам — мы приступили к сборке ПО.
Основная задача, стоявшая перед нами — поиск персоны в области видимости камеры, ее идентификация и своевременное оповещение о ее присутствии. Соответственно, помимо распознавания лиц и сопоставления их с образцами (как это делать, на тот момент, вызывало ничуть не меньше вопросов, чем все остальное) нам было необходимо обеспечить и второстепенные вещи интерфейсного плана. А именно — мы должны получать кадры с лицами необходимых персон с той же камеры для их последующей идентификации. Почему с той же камеры, думаю, тоже вполне очевидно — точка установки камеры на объекте и оптика объектива вносят определенные искажения, которые, предположительно, могут сказаться на качестве распознавания, используй мы другой источник, нежели средство слежения.
Т.е. помимо собственно обработчика потока нам потребуется как минимум видео-архив и анализатор видео-файлов, который позволит вычленить все обнаруженные лица с записи и сохранить наиболее подходящие из них как опорные.
Как всегда мы взяли привычные Erlang и PostgreSQL в качестве клея между ffmpeg, приложениями на OpenVINO и API мессенжера для оповещения. Помимо этого нам потребовалось web-UI для обеспечения минимального набора процедур по управлению комплексом, который наш коллега-фронтэндер запилил на VueJS.
Логика работы была проста:
- под управлением control plane на Erlang ffmpeg пишет поток с камеры в видео пятиминутными срезами, отдельный процесс следит за тем, чтобы записи хранились в строго оговоренном объеме и зачищает наиболее старые по достижению этого порога;
- через web-UI можно просмотреть любую запись, они выстроены в хронологическом порядке, что, хоть и не без труда, позволяет вычленить нужный фрагмент и отправить его на обработку;
- обработка заключается в анализе видео и выделении кадров с обнаруженными лицами, это как раз делает ПО на базе OpenVINO (надо сказать, тут у нас получилось немного срезать угол — ПО для анализа потока и анализа файлов практически идентичное, из-за чего большая часть ушла в общую библиотеку, а сами утилиты отличаются только цепочкой обработки а-ля модульный gstreamer). Обработка проходит по видео, вычленяя найденные лица при помощи специально обученной нейросети. Полученные фрагменты кадра, содержащие лица, попадают в другую нейросеть, которая формирует 256-элементный вектор, являющийся, по сути координатами опорных точек лица человека. Этот вектор, обнаруженный кадр и координаты лица сохраняются в БД;
- далее, после завершения обработки оператор открывает многообразие выдернутых кадров, ужасается их количеству и приступает к поиску целевых персон. Выбранные семплы можно добавить уже к существующей персоне или же создать новую. После завершения обработки задачи результаты анализа удаляются за исключением сохраненных векторов, сопоставленных с записями о наблюдаемых;
- соответственно, мы можем в любой момент посмотреть и кадры и вектора обнаружения и отредактировать, удалив неудачные семплы;
- параллельно циклу обнаружения в фоне всегда работает сервис анализа потока, который делает все тоже самое, но уже с потоком с камеры. Он выделяет лица в наблюдаемом потоке и производит их сравнение с образцами из БД, что базируется на простом предположении, что вектора одной персоны будут ближе к друг другу, чем ко всем остальным векторам. Происходит попарное вычисление дистанции между векторами, по достижении порога срабатывания в БД кладется запись об обнаружении и кадр. Помимо этого происходит добавление персоны в стоп-лист на ближайшее время, что позволяет избежать многократных уведомлений об одном и том же человеке;
- control plane периодически проверяет журнал обнаружения и в случае появления новых записей нотифицирует сообщением с прилагаемым фото и выделением лица через мессанжер тем, кому это разрешено согласно настройкам.
Выглядит это примерно так:
Просмотр архива
Результаты анализа видео
Список наблюдаемых личностей
Полученное решение во многом спорно и местами даже неоптимально как с точки зрения производительности, так и с точки зрения сокращения времени реакции. Но, повторюсь, у нас не было цели получить продуктивную систему сразу, а просто пройти этот путь и набить максимальное количество шишек, определить узкие пути и потенциальные неочевидные проблемы.
Собранная система тестировалась в тепличных офисных условиях в течение недели. За это время были отмечены следующие наблюдения:
- есть четкая зависимость качества распознавания от качества исходных семплов. Если наблюдаемый человек проходит через зону наблюдения слишком быстро, то с большой долей вероятности он не оставит данные для семплирования и не будет обнаружен. Впрочем, думаю, это вопрос тонкой настройки системы, включая освещение и параметры видеопотока;
- поскольку система оперирует распознаванием элементов лиц (глаз, носа, рта, надбровных дуг и т.д.), то ее легко обмануть выставлением визуального препятствия между лицом и камерой (волосы, темные очки, надетый капюшон и т.п.) — лицо, скорее всего, будет найдено, но сопоставление с образцами не пройдет из-за сильного расхождения векторов обнаружения и семплов;
- обычные очки влияют не слишком значительно — у нас были примеры положительных срабатываний на людях в очках и ложно-отрицательные срабатывания на людях, которые надевали очки для проверки;
- если борода была на исходных семплах, а потом ее не стало, то количество срабатываний уменьшается (автор этих строк подровнял свою бороду до 2 мм и количество срабатываний на нем уменьшилось вдвое);
- ложно-положительные срабатывания также имели место, это повод для дальнейшего погружения в математику вопроса и, возможно, решение вопроса о частичном соответствии векторов и оптимальной методике расчета расстояния между ними. Впрочем, тестирование в полевых условиях должно вскрыть еще больше проблем в этом аспекте.
Что предстоит? Проверка системы боем, оптимизация цикла обработки обнаружений, упрощение процедуры поиска событий в видео-архиве, добавление большего количества данных в анализ (возраст, пол, эмоции) и еще 100500 мелких и не очень задачек, которые еще предстоит сделать. Но первый шаг в пути из тысячи шагов мы уже сделали. Если кто поделится своим опытом в решении подобных задач или даст интересные ссылки по этому вопросу — буду весьма признателен.




