

Всем привет!
В данной статье мы напишем небольшую программу для решения задачи детектирования и распознавания объектов (object detection) в режиме реального времени. Программа будет написана на языке программирования Swift под платформу iOS. Для детектирования объектов будем использовать свёрточную нейронную сеть с архитектурой под названием YOLOv3. В статье мы научимся работать в iOS с нейронными сетями с помощью фреймворка CoreML, немного разберемся, что из себя представляет сеть YOLOv3 и как использовать и обрабатывать выходы данной сети. Так же проверим работу программы и сравним несколько вариаций YOLOv3: YOLOv3-tiny и YOLOv3-416.
Исходники будут доступны в конце статьи, поэтому все желающие смогут протестировать работу нейронной сети у себя на устройстве.
Object detection
Для начала, вкратце разберемся, что из себя представляет задача детектирования объектов (object detection) на изображении и какие инструменты применяются для этого на сегодняшний день. Я понимаю, что многие довольно хорошо знакомы с этой темой, но я, все равно, позволю себе немного об этом рассказать.
Сейчас очень много задач в области компьютерного зрения решаются с помощью свёрточных нейронных сетей (Convolutional Neural Networks), в дальнейшем CNN. Благодаря своему строению они хорошо извлекают признаки из изображения. CNN используются в задачах классификации, распознавания, сегментации и еще во множестве других.
Популярные архитектуры CNN для распознавания объектов:
- R-CNN. Можно сказать первая модель для решения данной задачи. Работает как обычный классификатор изображений. На вход сети подаются разные регионы изображения и для них делается предсказания. Очень медленная так как прогоняет одно изображение несколько тысяч раз.
- Fast R-CNN. Улучшенная и более быстрая версия R-CNN, работает по похожему принципу, но сначала все изображение подается на вход CNN, потом из полученного внутреннего представления генерируются регионы. Но по прежнему довольно медленная для задач реального времени.
- Faster R-CNN. Главное отличие от предыдущих в том, что вместо selective search алгоритма для выбора регионов использует нейронную сеть для их «заучивания».
- YOLO. Совсем другой принцип работы по сравнению с предыдущими, не использует регионы вообще. Наиболее быстрая. Более подробно о ней пойдет речь в статье.
- SSD. По принципу похожа на YOLO, но в качестве сети для извлечения признаков использует VGG16. Тоже довольная быстрая и пригодная для работы в реальном времени.
- Feature Pyramid Networks (FPN). Еще одна разновидность сети типа Single Shot Detector, из за особенности извлечения признаков лучше чем SSD распознает мелкие объекты.
- RetinaNet. Использует комбинацию FPN+ResNet и благодаря специальной функции ошибки (focal loss) дает более высокую точность (аccuracy).
В данной статье мы будем использовать архитектуру YOLO, а именно её последнюю модификацию YOLOv3.
Почему YOLO?

YOLO или You Only Look Once — это очень популярная на текущий момент архитектура CNN, которая используется для распознавания множественных объектов на изображении. Более полную информацию о ней можно получить на официальном сайте, там же можно найти публикации в которых подробно описана теория и математическая составляющая этой сети, а так же расписан процесс её обучения.
Главная особенность этой архитектуры по сравнению с другими состоит в том, что большинство систем применяют CNN несколько раз к разным регионам изображения, в YOLO CNN применяется один раз ко всему изображению сразу. Сеть делит изображение на своеобразную сетку и предсказывает bounding boxes и вероятности того, что там есть искомый объект для каждого участка.
Плюсы данного подхода состоит в том, что сеть смотрит на все изображение сразу и учитывает контекст при детектировании и распознавании объекта. Так же YOLO в 1000 раз быстрее чем R-CNN и около 100x быстрее чем Fast R-CNN. В данной статье мы будем запускать сеть на мобильном устройстве для онлайн обработки, поэтому это для нас это самое главное качество.
Более подробную информацию по сравнению архитектур можно посмотреть тут.
YOLOv3
YOLOv3 — это усовершенствованная версия архитектуры YOLO. Она состоит из 106-ти свёрточных слоев и лучше детектирует небольшие объекты по сравнению с её предшествиницей YOLOv2. Основная особенность YOLOv3 состоит в том, что на выходе есть три слоя каждый из которых расчитан на обнаружения объектов разного размера.
На картинке ниже приведено её схематическое устройство:
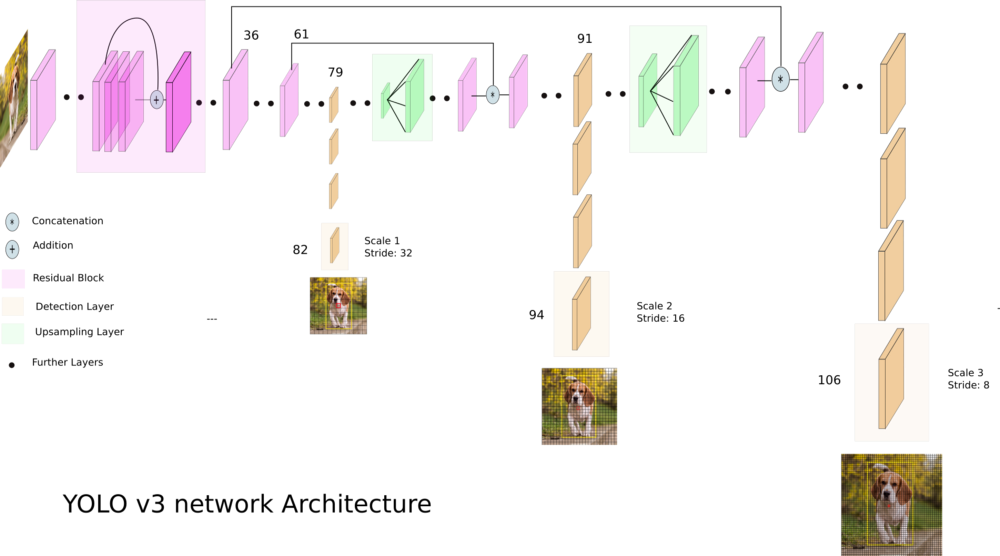
YOLOv3-tiny — обрезанная версия архитектуры YOLOv3, состоит из меньшего количества слоев (выходных слоя всего 2). Она более хуже предсказывает мелкие объекты и предназначена для небольших датасетов. Но, из-за урезанного строения, веса сети занимают небольшой объем памяти (~35 Мб) и она выдает более высокий FPS. Поэтому такая архитектура предпочтительней для использования на мобильном устройстве.
Пишем программу для распознавания объектов
Начинается самая интересная часть!
Давайте создадим приложение, которое будет распознавать различные объекты на изображении в реальном времени используя камеру телефона. Весь код будем писать языке программирования Swift 4.2 и запускать на iOS устройстве.
В данном туториале мы возьмём уже готовую сеть с весами предобученными на COCO датасете. В нем представлено 80 различных классов. Следовательно наша нейронка будет способна распознать 80 различных объектов.
Из Darknet в CoreML
Оригинальная архитектура YOLOv3 реализована с помощью фремворка Darknet.
На iOS, начиная с версии 11.0, есть замечательная библиотека CoreML, которая позволяет запускать модели машинного обучения прямо на устройстве. Но есть одно ограничение: программу можно будет запустить только на устройстве под управлением iOS 11 и выше.
Проблема в том, что CoreML понимает только определённый формат модели .coreml. Для большинства популярных библиотек, таких как Tensorflow, Keras или XGBoost, есть возможность напрямую конвертировать в формат CoreML. Но для Darknet такой возможности нет. Для того, что бы преобразовать сохраненную и обученную модель из Darknet в CoreML можно использовать различные варианты, например сохранить Darknet в ONNX, а потом уже из ONNX преобразовать в CoreML.
Мы воспользуемся более простым способом и будем использовать Keras имплементацию YOLOv3. Алгоритм действия такой: загрузим веса Darknet в Keras модель, сохраним её в формате Keras и уже из этого напрямую преобразуем в CoreML.
- Скачиваем Darknet. Загрузим файлы обученной модели Darknet-YOLOv3 отсюда. В данной статье я буду использовать две архитектуры: YOLOv3-416 и YOLOv3-tiny. Нам понадобится оба файла cfg и weights.
- Из Darknet в Keras. Сначала склонируем репозиторий, переходим в папку репо и запускаем команду:
python convert.py yolov3.cfg yolov3.weights yolo.h5
где yolov3.cfg и yolov3.weights скачанные файлы Darknet. В итоге у нас должен появиться файл с расширением .h5 — это и есть сохраненная модель YOLOv3 в формате Keras. - Из Keras в CoreML. Остался последний шаг. Для того, что бы сконвертировать модель в CoreML нужно запустить скрипт на python (предварительно надо установить библиотеку coremltools для питона):
import coremltools coreml_model = coremltools.converters.keras.convert( 'yolo.h5', input_names='image', image_input_names='image', input_name_shape_dict={'image': [None, 416, 416, 3]}, # размер входного изображения для сети image_scale=1/255.) coreml_model.input_description['image'] = 'Input image' coreml_model.save('yolo.mlmodel')
Шаги которые описаны выше надо проделать для двух моделей YOLOv3-416 и YOLOv3-tiny.
Когда мы все это сделали у нас есть два файла: yolo.mlmodel и yolo-tiny.mlmodel. Теперь можно приступать к написанию кода самого приложения.
Создание iOS приложения
Полностью весь код приложения я описывать не буду, его можно посмотреть в репозитории ссылка на который будет приведена в конце статьи. Скажу лишь что у нас есть три UIViewController-a: OnlineViewController, PhotoViewController и SettingsViewController. В первом идет вывод камеры и онлайн детектирование объектов для каждого кадра. Во втором можно сделать фото или выбрать снимок из галереи и протестировать сеть на этих изображениях. В третьем находятся настройки, можно выбрать модель YOLOv3-416 или YOLOv3-tiny, а так же подобрать пороги IoU (intersection over union) и object confidence (вероятность того, что на текущем участке изображения есть объект).
Загрузка модели в CoreML
После того как мы преобразовали обученную модель из Darknet формата в CoreML, у нас есть файл с расширением .mlmodel. В моем случае я создал два файла: yolo.mlmodel и yolo-tiny.mlmodel, для моделей YOLOv3-416 и YOLOv3-tiny соответсвенно. Теперь можно подгружать эти файлы в проект в Xcode.
Создаем класс ModelProvider в нем будет хранится текущая модель и методы для асинхронного вызова нейронной сети на исполнение. Загрузка модели осуществляется таким образом:
private func loadModel(type: YOLOType) {
do {
self.model = try YOLO(type: type)
} catch {
assertionFailure("error creating model")
}
}
Класс YOLO отвечает непосредственно за загрузку .mlmodel файлов и обработку выходов модели. Загрузка файлов модели:
var url: URL? = nil
self.type = type
switch type {
case .v3_Tiny:
url = Bundle.main.url(forResource: "yolo-tiny", withExtension:"mlmodelc")
self.anchors = tiny_anchors
case .v3_416:
url = Bundle.main.url(forResource: "yolo", withExtension:"mlmodelc")
self.anchors = anchors_416
}
guard let modelURL = url else {
throw YOLOError.modelFileNotFound
}
do {
model = try MLModel(contentsOf: modelURL)
} catch let error {
print(error)
throw YOLOError.modelCreationError
}
Полный код ModelProvider.
import UIKit
import CoreML
protocol ModelProviderDelegate: class {
func show(predictions: [YOLO.Prediction]?,
stat: ModelProvider.Statistics,
error: YOLOError?)
}
@available(macOS 10.13, iOS 11.0, tvOS 11.0, watchOS 4.0, *)
class ModelProvider {
struct Statistics {
var timeForFrame: Float
var fps: Float
}
static let shared = ModelProvider(modelType: Settings.shared.modelType)
var model: YOLO!
weak var delegate: ModelProviderDelegate?
var predicted = 0
var timeOfFirstFrameInSecond = CACurrentMediaTime()
init(modelType type: YOLOType) {
loadModel(type: type)
}
func reloadModel(type: YOLOType) {
loadModel(type: type)
}
private func loadModel(type: YOLOType) {
do {
self.model = try YOLO(type: type)
} catch {
assertionFailure("error creating model")
}
}
func predict(frame: UIImage) {
DispatchQueue.global().async {
do {
let startTime = CACurrentMediaTime()
let predictions = try self.model.predict(frame: frame)
let elapsed = CACurrentMediaTime() - startTime
self.showResultOnMain(predictions: predictions, elapsed: Float(elapsed), error: nil)
} catch let error as YOLOError {
self.showResultOnMain(predictions: nil, elapsed: -1, error: error)
} catch {
self.showResultOnMain(predictions: nil, elapsed: -1, error: YOLOError.unknownError)
}
}
}
private func showResultOnMain(predictions: [YOLO.Prediction]?,
elapsed: Float, error: YOLOError?) {
if let delegate = self.delegate {
DispatchQueue.main.async {
let fps = self.measureFPS()
delegate.show(predictions: predictions,
stat: ModelProvider.Statistics(timeForFrame: elapsed,
fps: fps),
error: error)
}
}
}
private func measureFPS() -> Float {
predicted += 1
let elapsed = CACurrentMediaTime() - timeOfFirstFrameInSecond
let currentFPSDelivered = Double(predicted) / elapsed
if elapsed > 1 {
predicted = 0
timeOfFirstFrameInSecond = CACurrentMediaTime()
}
return Float(currentFPSDelivered)
}
}
Обработка выходов нейронной сети
Теперь разберемся как обрабатывать выходы нейронной сети и получаться соответсвующие bounding box-ы. В Xcode если выбрать файл модели то можно увидеть, что они из себя представляет и увидеть выходные слои.
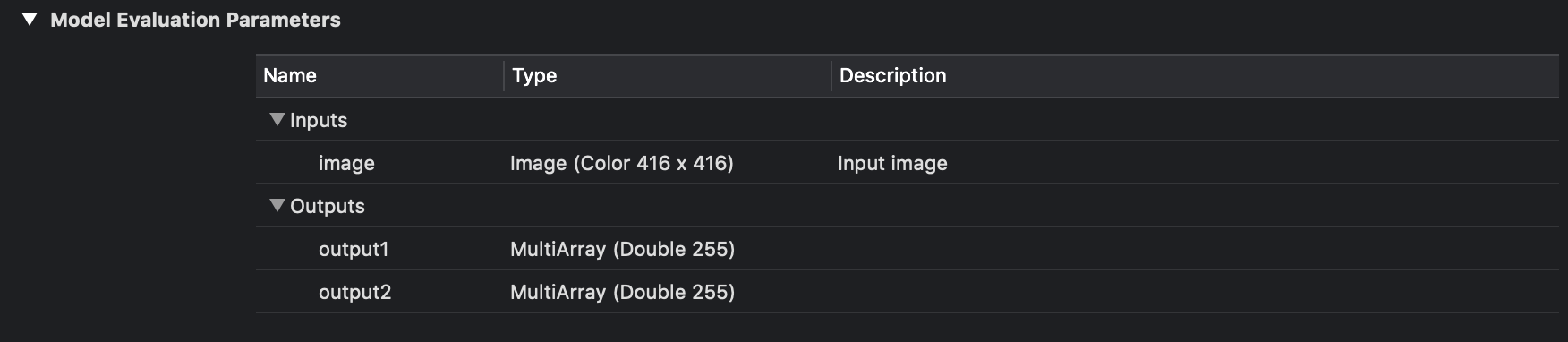
Вход и выход YOLOv3-tiny.
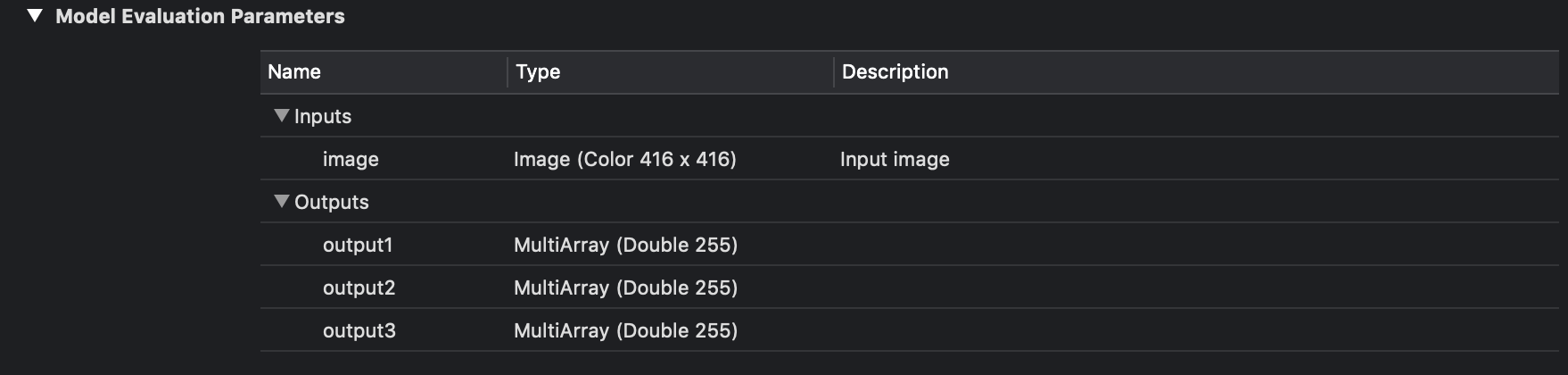
Вход и выход YOLOv3-416.
Как можно видеть на изображении выше у нас есть три для YOLOv3-416 и два для YOLOv3-tiny выходных слоя в каждом из которых предсказываются bounding box-ы для различных объектов.
В данном случае это обычный массив чисел, давайте же разберемся как его парсить.
Модель YOLOv3 в качестве выхода использует три слоя для разбиения изображения на различную сетку, размеры ячеек этих сеток имеют такие значения: 8, 16 и 32. Допустим на входе у нас есть изображение размером 416x416 пикселей, тогда выходные матрицы (сетки) будут иметь размер 52x52, 26x26 и 13x13 (416/8 = 52, 416/16 = 26 и 416/32 = 13). В случае с YOLOv3-tiny все тоже самое только вместо трех сеток имеем две: 16 и 32, то есть матрицы размерностью 26x26 и 13x13.
После запуска загруженно CoreML модели на выходе мы получим два (или три) объекта класса MLMultiArray. И если посмотреть свойство shape у этих объектов, то увидим такую картину (для YOLOv3-tiny):
Как и ожидалось размерность матриц будет 26x26 и 13x13.Но что обозначат число 255? Как уже говорилось ранее, выходные слои это матрицы размерностью 52x52, 26x26 и 13x13. Дело в том, что каждый элемент данной матрицы это не число, это вектор. То есть выходной слой это трех-мерная матрица. Этот вектор имеет размерность B x (5 + C), где B — количество bounding box в ячейке, C — количество классов. Откуда число 5? Причина такая: для каждого box-a предсказывается вероятность что там есть объект (object confidence) — это одно число, а оставшиеся четыре — это x, y, width и height для предсказанного box-a. На рисунке ниже показано схематичное представление этого вектора:

Cхематичное представление выходного слоя (feature map).
Для нашей сети обученной на 80-ти классах, для каждой ячейки сетки разбиения предсказывается 3 bounding box-a, для каждого из них — 80 вероятностей классов + object confidence + 4 числа отвечающие за положение и размер этого box-a. Итого: 3 x (5 + 80) = 255.
Для получения этих значений из класса MLMultiArray лучше воспользоваться сырым указателем на массив данных и адресной арифметикой:
let pointer = UnsafeMutablePointer<Double>(OpaquePointer(out.dataPointer)) // получение сырого указателя
if out.strides.count < 3 {
throw YOLOError.strideOutOfBounds
}
let channelStride = out.strides[out.strides.count-3].intValue
let yStride = out.strides[out.strides.count-2].intValue
let xStride = out.strides[out.strides.count-1].intValue
func offset(ch: Int, x: Int, y: Int) -> Int { // функция доступа по оффсетам
return ch * channelStride + y * yStride + x * xStride
}
Теперь необходимо обработать вектор из 255 элементов. Для каждого box-a нужно получить распределение вероятностей для 80 классов, сделать это можно сделать с помощью функции softmax.
Что такое softmax
Функция преобразует вектор размерности K в вектор той же размерности, где каждая координата полученного вектора представлена вещественным числом в интервале [0,1] и сумма координат равна 1.где K — размерность вектора.
Функция softmax на Swift:
private func softmax(_ x: inout [Float]) {
let len = vDSP_Length(x.count)
var count = Int32(x.count)
vvexpf(&x, x, &count)
var sum: Float = 0
vDSP_sve(x, 1, &sum, len)
vDSP_vsdiv(x, 1, &sum, &x, 1, len)
}
Для получения координат и размеров bounding box-a нужно воспользоваться формулами:
где — предсказанные x, y координаты, ширина и высота соответственно, — функция сигмоиды, а — значения якорей(anchors) для трех box-ов. Эти значения определяются во время тренировки и заданы в файле Helpers.swift:
let anchors1: [Float] = [116,90, 156,198, 373,326] //якоря для первого выходного слоя
let anchors2: [Float] = [30,61, 62,45, 59,119] //якоря для второго выходного слоя
let anchors3: [Float] = [10,13, 16,30, 33,23] //якоря для третьего выходного слоя
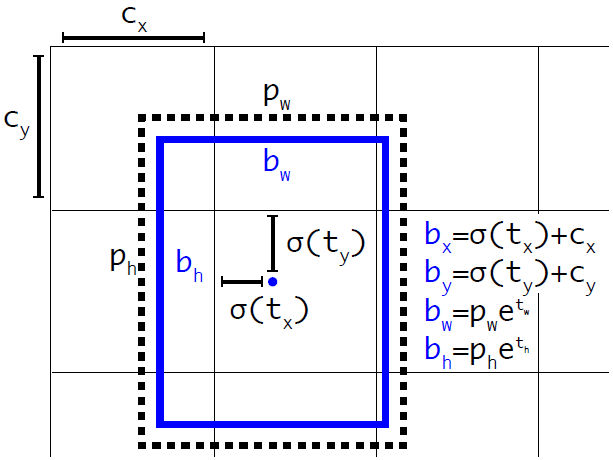
Схематическое изображение расчета положения bounding box-а.
Полный код обработки выходных слоев.
private func process(output out: MLMultiArray, name: String) throws -> [Prediction] {
var predictions = [Prediction]()
let grid = out.shape[out.shape.count-1].intValue
let gridSize = YOLO.inputSize / Float(grid)
let classesCount = labels.count
print(out.shape)
let pointer = UnsafeMutablePointer<Double>(OpaquePointer(out.dataPointer))
if out.strides.count < 3 {
throw YOLOError.strideOutOfBounds
}
let channelStride = out.strides[out.strides.count-3].intValue
let yStride = out.strides[out.strides.count-2].intValue
let xStride = out.strides[out.strides.count-1].intValue
func offset(ch: Int, x: Int, y: Int) -> Int {
return ch * channelStride + y * yStride + x * xStride
}
for x in 0 ..< grid {
for y in 0 ..< grid {
for box_i in 0 ..< YOLO.boxesPerCell {
let boxOffset = box_i * (classesCount + 5)
let bbx = Float(pointer[offset(ch: boxOffset, x: x, y: y)])
let bby = Float(pointer[offset(ch: boxOffset + 1, x: x, y: y)])
let bbw = Float(pointer[offset(ch: boxOffset + 2, x: x, y: y)])
let bbh = Float(pointer[offset(ch: boxOffset + 3, x: x, y: y)])
let confidence = sigmoid(Float(pointer[offset(ch: boxOffset + 4, x: x, y: y)]))
if confidence < confidenceThreshold {
continue
}
let x_pos = (sigmoid(bbx) + Float(x)) * gridSize
let y_pos = (sigmoid(bby) + Float(y)) * gridSize
let width = exp(bbw) * self.anchors[name]![2 * box_i]
let height = exp(bbh) * self.anchors[name]![2 * box_i + 1]
for c in 0 ..< 80 {
classes[c] = Float(pointer[offset(ch: boxOffset + 5 + c, x: x, y: y)])
}
softmax(&classes)
let (detectedClass, bestClassScore) = argmax(classes)
let confidenceInClass = bestClassScore * confidence
if confidenceInClass < confidenceThreshold {
continue
}
predictions.append(Prediction(classIndex: detectedClass,
score: confidenceInClass,
rect: CGRect(x: CGFloat(x_pos - width / 2),
y: CGFloat(y_pos - height / 2),
width: CGFloat(width),
height: CGFloat(height))))
}
}
}
return predictions
}
Non max suppression
После того как получили координаты и размеры bounding box-ов и соответсвующие вероятности для всех найденных объектов на изображении можно начинать отрисовывать их поверх картинки. Но есть одна проблема! Может Возникнуть такая ситуация когда для одного объекта предсказано несколько box-ов c достаточно высокими вероятностями. Как быть в таком случае? Тут нам на помощь приходит довольно простой алгоритм под названием Non maximum suppression.
Порядок действия алгоритма такой:
- Ищем bounding box с наибольшей вероятностью принадлежности к объекту.
- Пробегаем по всем bounding box-ам которые тоже относятся к этому объекту.
- Удаляем их если Intersection over Union (IoU) с первым bounding box-ом больше заданного порога.
IoU считается по простой формуле:
Расчет IoU.
static func IOU(a: CGRect, b: CGRect) -> Float {
let areaA = a.width * a.height
if areaA <= 0 { return 0 }
let areaB = b.width * b.height
if areaB <= 0 { return 0 }
let intersection = a.intersection(b)
let intersectionArea = intersection.width * intersection.height
return Float(intersectionArea / (areaA + areaB - intersectionArea))
}
Non max suppression.
private func nonMaxSuppression(boxes: inout [Prediction], threshold: Float) {
var i = 0
while i < boxes.count {
var j = i + 1
while j < boxes.count {
let iou = YOLO.IOU(a: boxes[i].rect, b: boxes[j].rect)
if iou > threshold {
if boxes[i].score > boxes[j].score {
if boxes[i].classIndex == boxes[j].classIndex {
boxes.remove(at: j)
} else {
j += 1
}
} else {
if boxes[i].classIndex == boxes[j].classIndex {
boxes.remove(at: i)
j = i + 1
} else {
j += 1
}
}
} else {
j += 1
}
}
i += 1
}
}
После этого работу непосредственно с результатами предсказания нейронной сети можно считать законченной. Далее необходимо написать функции и классы для получение видеоряда с камеры, вывода изображения на экран и отрисовки предсказанных bounding box-ов. Весь этот код в данной статье описывать не буду, но его можно будет посмотреть в репозитории.
Еще стоит упомянуть, что я добавил небольшое сглаживание bounding box-ов при обработки онлайн изображения, в данном случае это обычное усреднение положения и размера предсказанного квадрата за последние 30 кадров.
Тестирование работы программы
Теперь протестируем работу приложения.
Еще раз напомню: В приложении есть три ViewController-а, один для обработки фотографий или снимков, второй для обработки онлайн видео потока, третий для настройки работы сети.
Начнем с третьего. В нем можно выбрать одну из двух моделей YOLOv3-tiny или YOLOv3-416, подобрать confidence threshold и IoU threshold, так же можно включить или выключить онлайн сглаживание.
Теперь посмотрим как работает обученная нейронка с реальными изображениями, для этого возьмем фотографию из галереи и пропустим её через сеть. Ниже на картинке представлены результаты работы YOLOv3-tiny с разными настройками.

Разные режимы работы YOLOv3-tiny. На левой картинке обычный режим работы. На средней — порог IoU = 1 т.е. как будто отсутствует Non-max suppression. На правой — низкий порог object confidence, т.е. отображаются все возможные bounding box-ы.
Далее приведен результат работы YOLOv3-416. Можно заметить, что по сравнению с YOLOv3-tiny полученные рамки более правильные, а так же распознаны более мелкие объекты на изображении, что соответствует работе третьего выходного слоя.

Изображение обработанное с помощью YOLOv3-416.
При включении онлайн режима работы обрабатывался каждый кадр и для него делалось предсказание, тесты проводились на iPhone XS поэтому результат получился довольно приемлемый для обоих вариантов сети. YOLOv3-tiny в среднем выдает 30 — 32 fps, YOLOv3-416 — от 23 до 25 fps. Устройство на котором проходило тестирование довольно производительное, поэтому на более ранних моделях результаты могут отличатся, в таком случае конечно предпочтительнее использовать YOLOv3-tiny. Еще один важный момент: yolo-tiny.mlmodel (YOLOv3-tiny) занимает около 35 Мб, в свою очередь yolo.mlmodel (YOLOv3-416) весит около 250 Мб, что очень существенная разница.
Заключение
В итоге было написано iOS приложение которое с помощью нейронной сети может распознавать объекты на изображении. Мы увидели как работать с библиотекой CoreML и как с её помощью исполнять различные, заранее обученные, модели (кстати обучать с её помощью тоже можно). Задача распознавания объекта решалась с помощью YOLOv3 сети. На iPhone XS данная сеть (YOLOv3-tiny) способна обрабатывать изображения с частотой ~30 кадров в секунду, что вполне достаточно для работы в реальном времени.
Полный код приложения можно посмотреть на GitHub.


